L01: Introduction and the History of NLP
Week 1 · Tue Jan 06 2026 08:00:00 GMT+0800 (中国标准时间)
L01: Introduction and the History of NLP
Slides
Part 1: Course Introduction (Intro)
中英交替版(推荐)
英文原版
中文翻译版
Part 2: History of NLP (Manning)
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
1. 课程概览


















- 讲师:Diyi Yang & Yejin Choi(Stanford)
- 课程目标:掌握深度学习在 NLP 中的有效现代方法
- 基础:word vectors、RNN、attention、Transformers
- 前沿:pretraining、post-training、efficient adaptation、agents、reasoning、multimodality
- 作业安排:4 次作业(48%)+ Final Project(49%)+ Participation(3%)
- HW1:Jupyter Notebook 入门(本讲发布)
- HW2:神经网络基础 + 依赖解析
- HW3:从零实现 Transformer + 理解 attention
- HW4:LLM 评估 + red teaming
- Final Project:Default(实现小 GPT + 微调)或 Custom(自选课题,1-3 人团队)
📐 课程的数学基础层级
CS224N 覆盖的核心数学工具栈:
- 词向量:,通过最大化共现概率学得
- Softmax 分类器:
- 注意力:
- 语言模型:
每一层都是下一层的基础——理解注意力必须先理解矩阵乘法与 softmax。
🔢 数值/具体示例
课程作业难度梯度(以完成时间估算):
| 作业 | 核心任务 | 预估工时 |
|---|---|---|
| HW1 | Jupyter 入门,词向量可视化 | ~5h |
| HW2 | 手推反向传播,依赖解析(Arc-Eager) | ~15h |
| HW3 | 从零实现 Transformer(PyTorch) | ~20h |
| HW4 | LLM 评估 + red teaming | ~15h |
Final Project(Custom track):顶尖团队论文直接投 ACL/EMNLP workshop。
💡 为什么这样做?
CS224N 的课程设计遵循”先理解再使用”的哲学:不是教你调 transformers 库的 API,而是让你手写 Transformer——因为只有从底层理解,才能在遇到问题时知道去哪里查 bug,才能在新场景下设计新架构。
⚠️ 常见误区
- 误区:“深度学习 NLP 只需要会调库” → 正确:库封装了实现细节,但在调试、研究和创新时,必须理解底层数学——这正是本课程存在的理由。
2. NLP 的四个时代(Christopher Manning)
1940—1969:早期探索



















- Warren Weaver(1947):将翻译视为密码学问题
- 1954 Georgetown-IBM 实验:首次俄-英机器翻译演示(250 词汇)
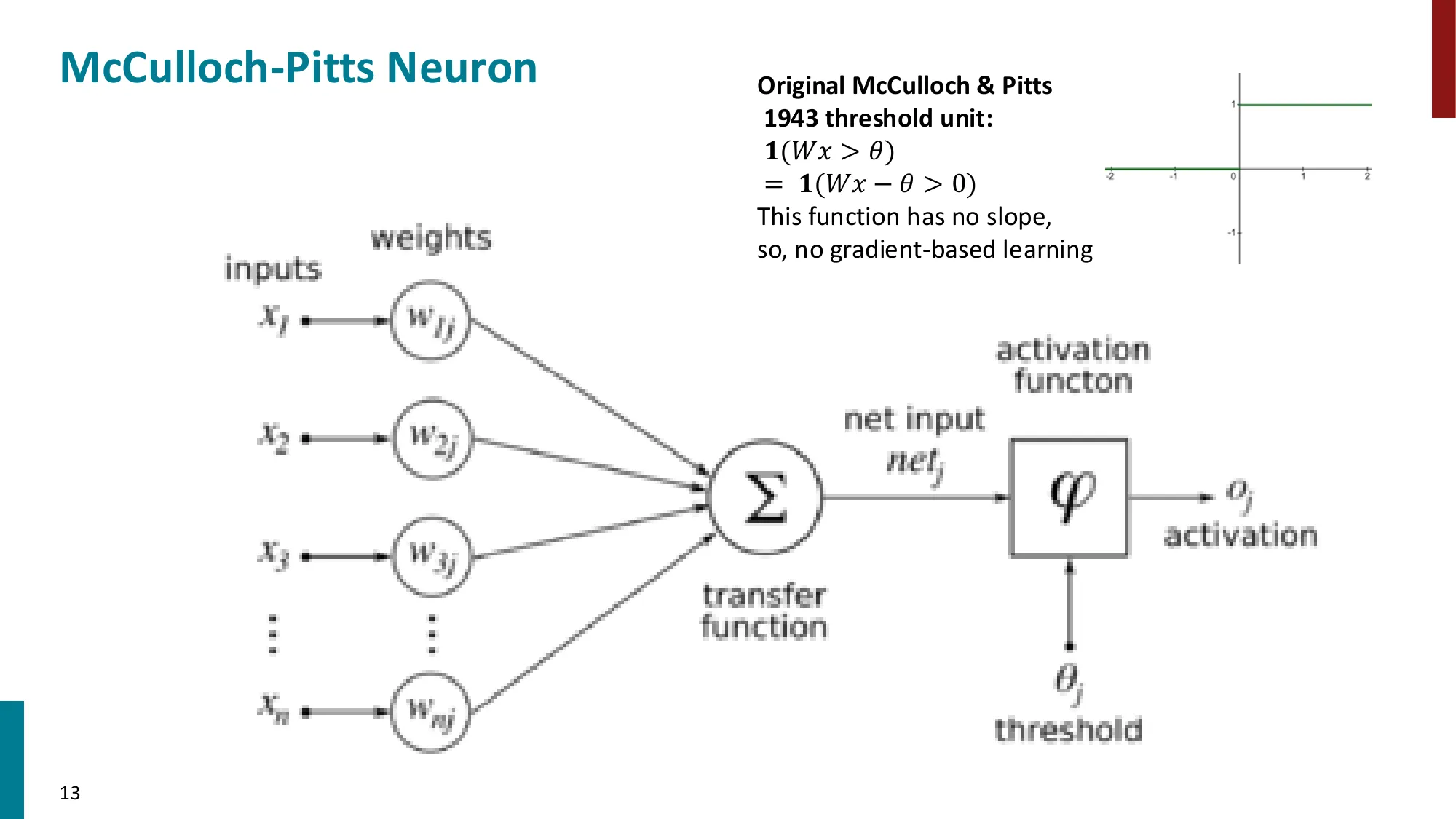
- McCulloch & Pitts(1943):首个神经网络数学模型
- Frank Rosenblatt(1958):感知机(Mark I Perceptron)
- 两大路线之争:符号 AI (Minsky, McCarthy) vs. 连接主义 (Wiener, Rosenblatt)
- 信息检索:Vannevar Bush “As We May Think”(1945),Cyril Cleverdon 引入基准测试
- David Glenn Hays:ACL 创始人,依赖句法分析
📐 感知机学习算法(Rosenblatt 1958)
感知机是神经网络的数学原型:
更新规则(错误驱动):
其中 是学习率, 是真实标签。
McCulloch-Pitts 神经元(1943)更早——纯逻辑门形式,无学习算法:,权重手工设定。
🔢 数值/具体示例
1954 Georgetown-IBM 实验:系统仅有 6 条语法规则 + 250 个词汇,演示了 60 个俄语句子的机器翻译。
结果被严重夸大——研究者声称 “3-5 年内机器翻译将解决”。实际上直到 2016 年神经 MT 出现,机器翻译才真正达到实用水平。这比预测晚了整整 60 年。
💡 为什么这样做?
这个时代的研究者相信语言是有限规则系统的产物(类比密码学):找到足够多规则,就能翻译任何句子。这个假设的致命问题是:自然语言的歧义性和上下文依赖性使规则数量爆炸——人类语言不是密码,而是无限创造性系统。
⚠️ 常见误区
- 误区:符号 AI 和连接主义(神经网络)是新的对立 → 正确:这场争论从 1950 年代就开始了,Minsky/McCarthy vs Wiener/Rosenblatt 的路线之争比大多数人认为的要早几十年。
1970—1992:手工构建的符号 NLP 系统






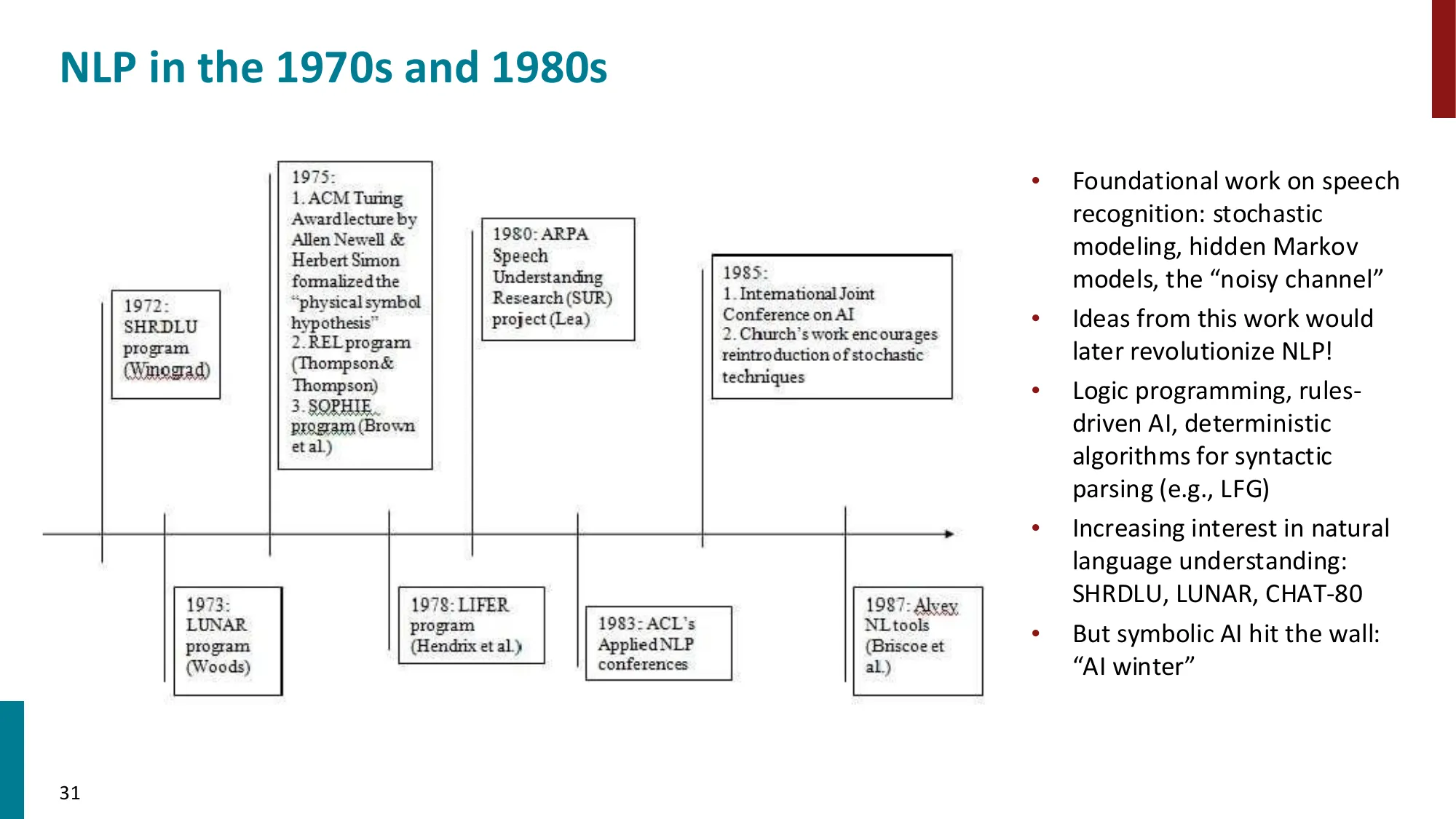
- 基于规则的系统,逐步形式化
- 词袋模型(Bag of Words)、TF-IDF
- 句法分析树(概率上下文无关文法 PCFG)
- 隐马尔可夫模型(HMM)
- 概念依赖理论(Conceptual Dependency,Schank)
- N-gram 语言模型
- IBM 统计机器翻译模型
- 话语结构追踪
1993—2012:统计/概率 NLP + 机器学习


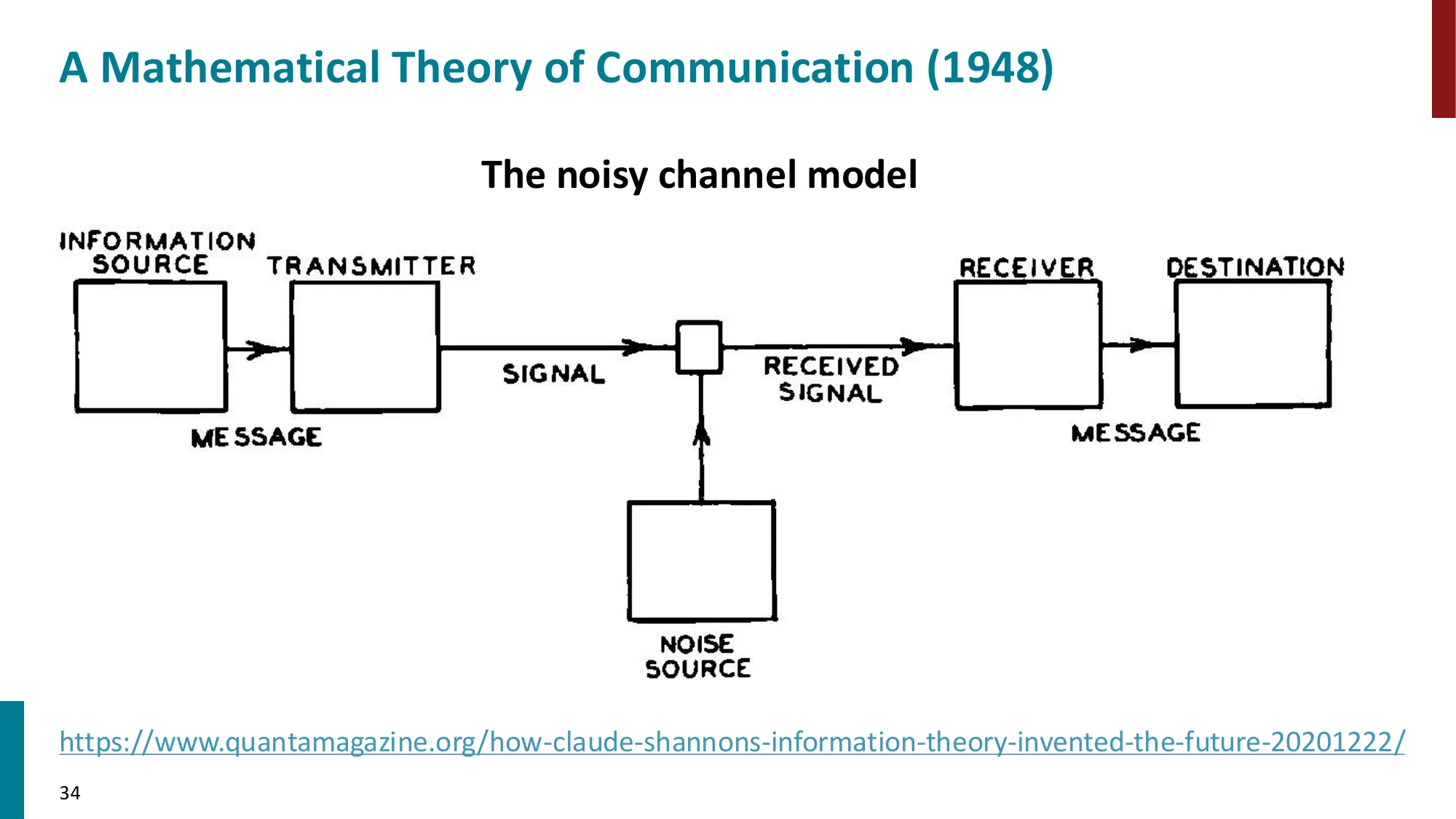

- 从规则到统计方法的范式转变
- 机器学习分类器:逻辑回归、SVM、CRF
- Word2Vec 词向量(Mikolov et al., 2013)和 GloVe(Pennington et al., 2014)
- Stanford Sentiment Treebank
- 共现矩阵 + 词嵌入
📐 Word2Vec Skip-gram 目标函数
这个时代的集大成者——Word2Vec(Mikolov et al., 2013):
Skip-gram 目标:给定中心词 ,最大化上下文词的概率
其中:
- :中心词向量
- :上下文词向量
- 计算 softmax 分母需遍历整个词汇表 (≈40万词),实践中用**负采样(Negative Sampling)**近似:
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
SVM 在 NLP 文本分类上的典型性能(Reuters-21578,多类文本分类):
- Bag-of-words + 朴素贝叶斯:~85% F1
- Bag-of-words + SVM(线性核):~90% F1
- Word2Vec 均值 + SVM:~92% F1
Word2Vec 词向量的经典类比关系:
这个数字在 Google News 语料(1000亿词)训练的 300 维向量上成立。
💡 为什么这样做?
统计/ML 时代的核心洞察:语言可以用分布式统计规律捕捉——“你能从它的邻居认出一个词”(Firth, 1957: “You shall know a word by the company it keeps”)。Word2Vec 把这个语言学直觉变成了可微分的优化目标,从而让向量空间天然编码语义关系。
⚠️ 常见误区
- 误区:统计 NLP 时代和深度学习时代是断裂的 → 正确:Word2Vec(2013)是连接两个时代的桥梁——它是统计方法(共现统计)+ 浅层神经网络的结合,词嵌入的思想直接延续到 BERT/GPT 的 embedding 层。
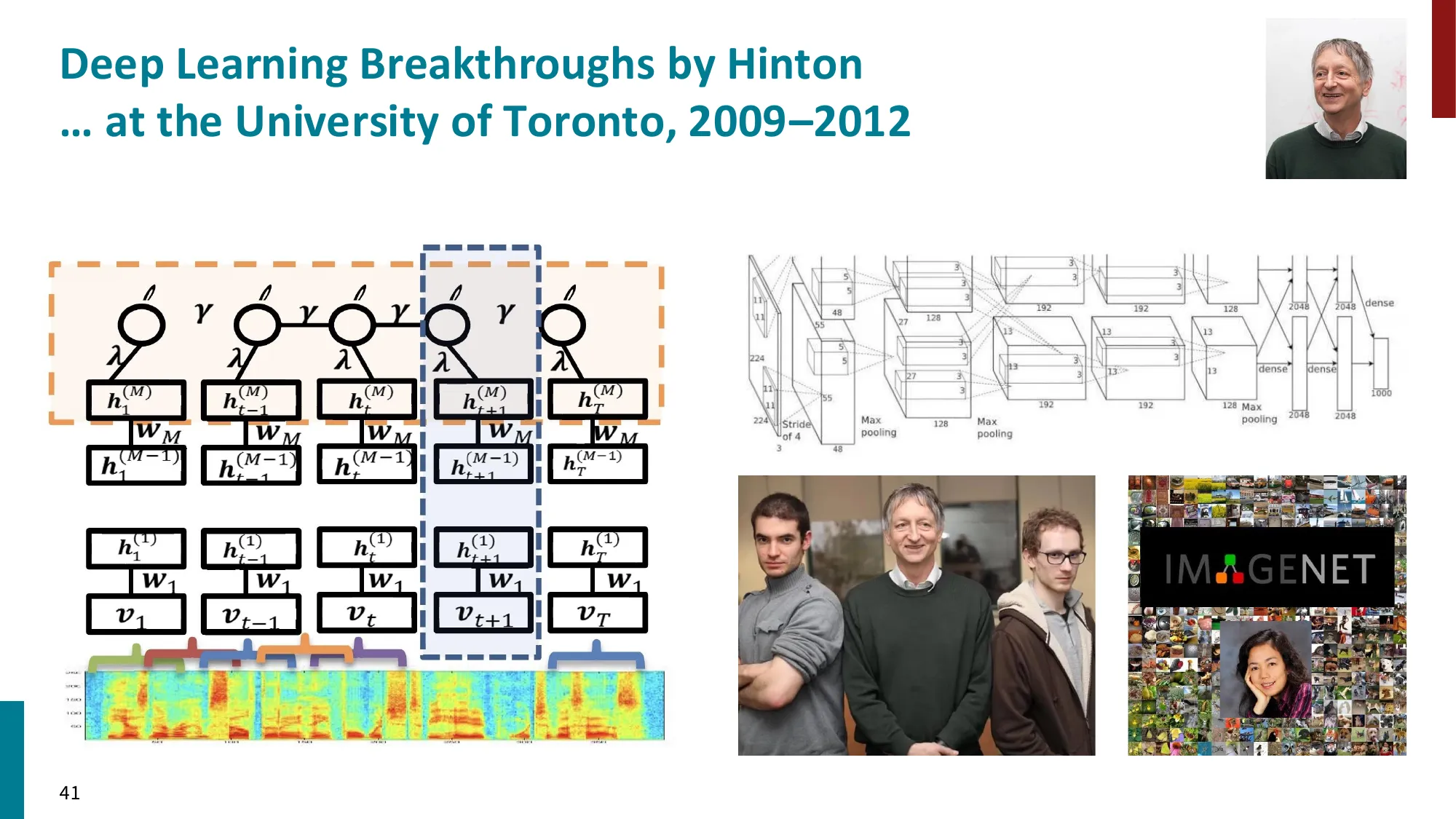
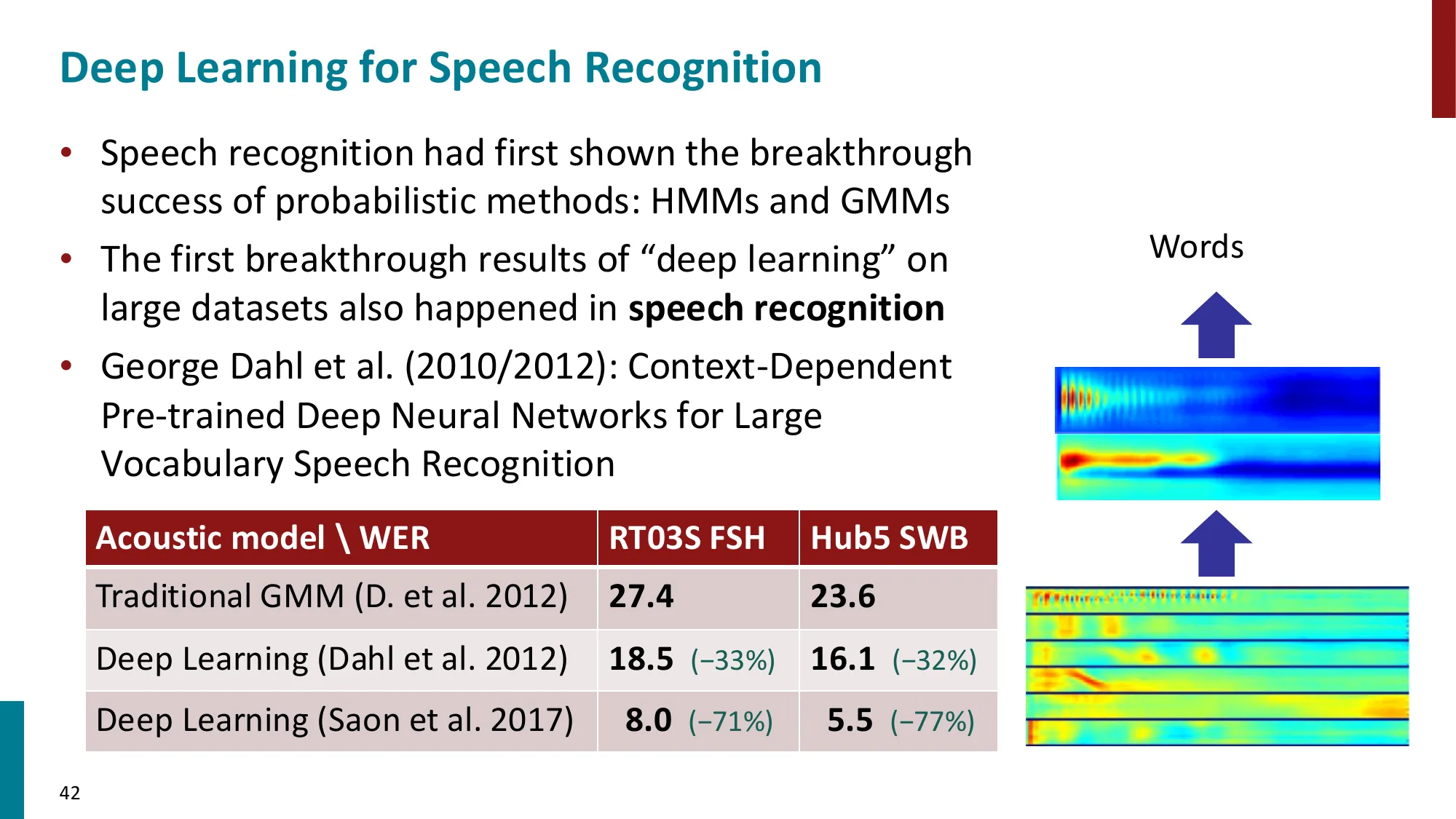
2013—至今:深度学习 / 神经网络时代




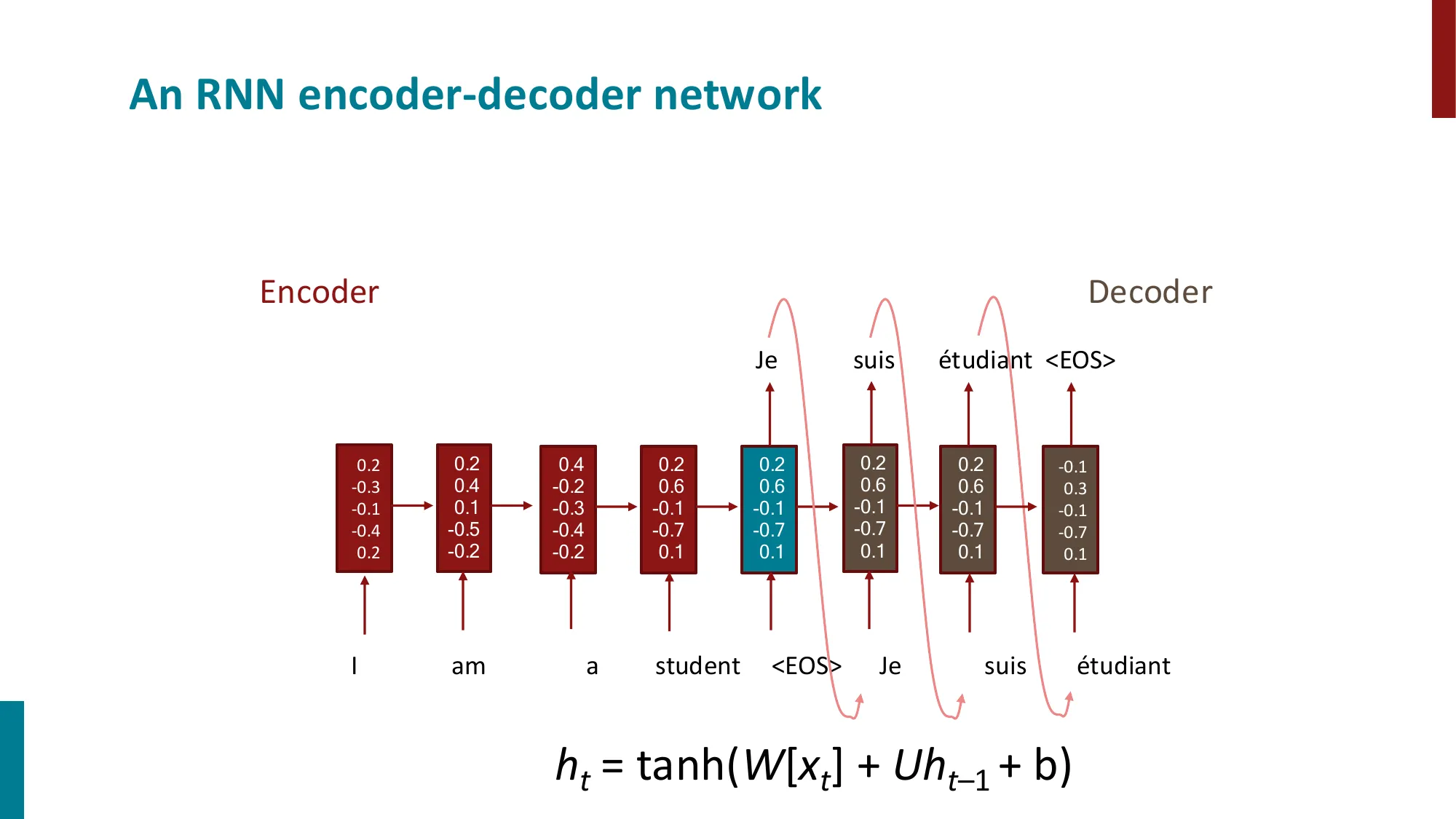
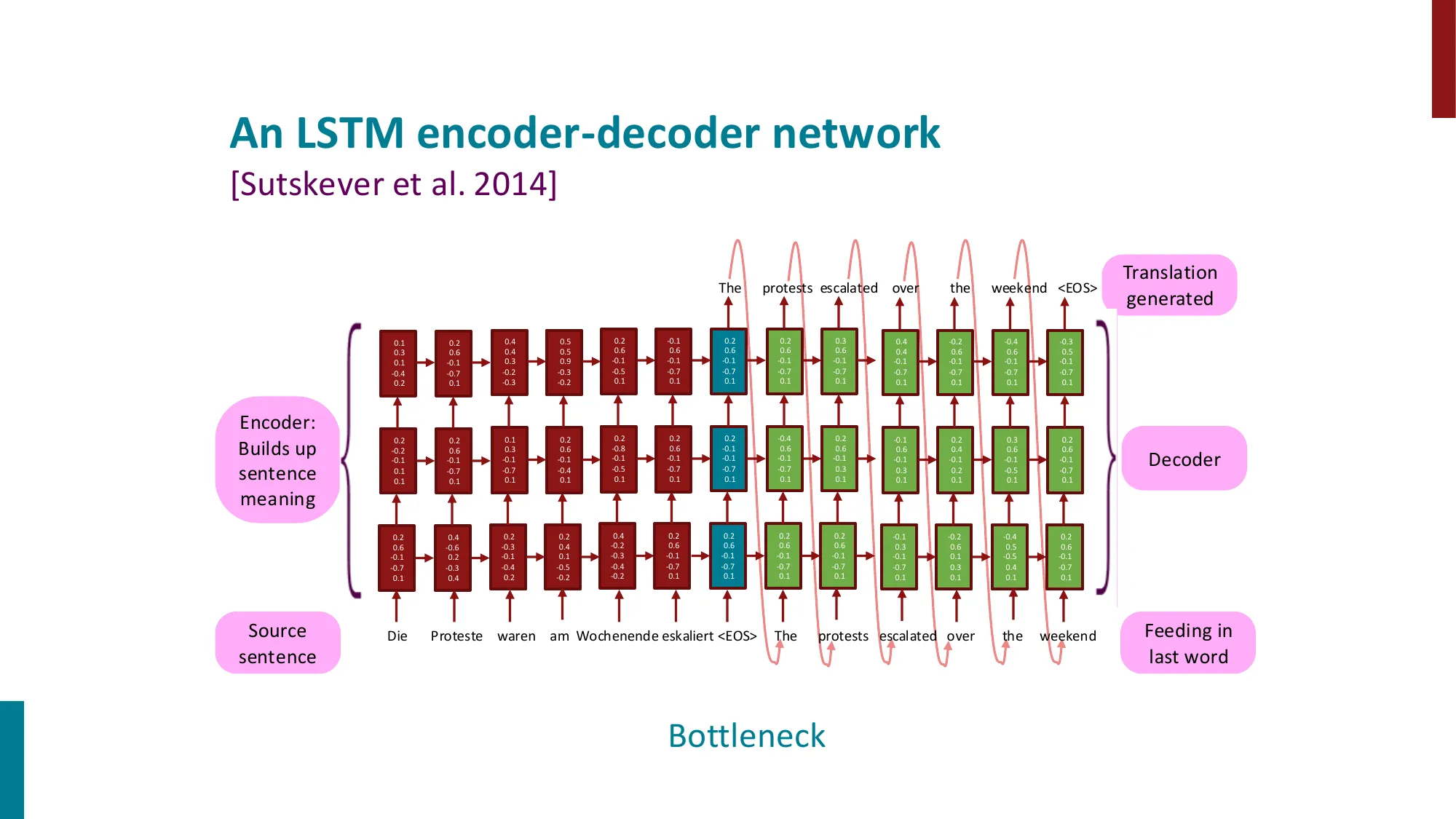
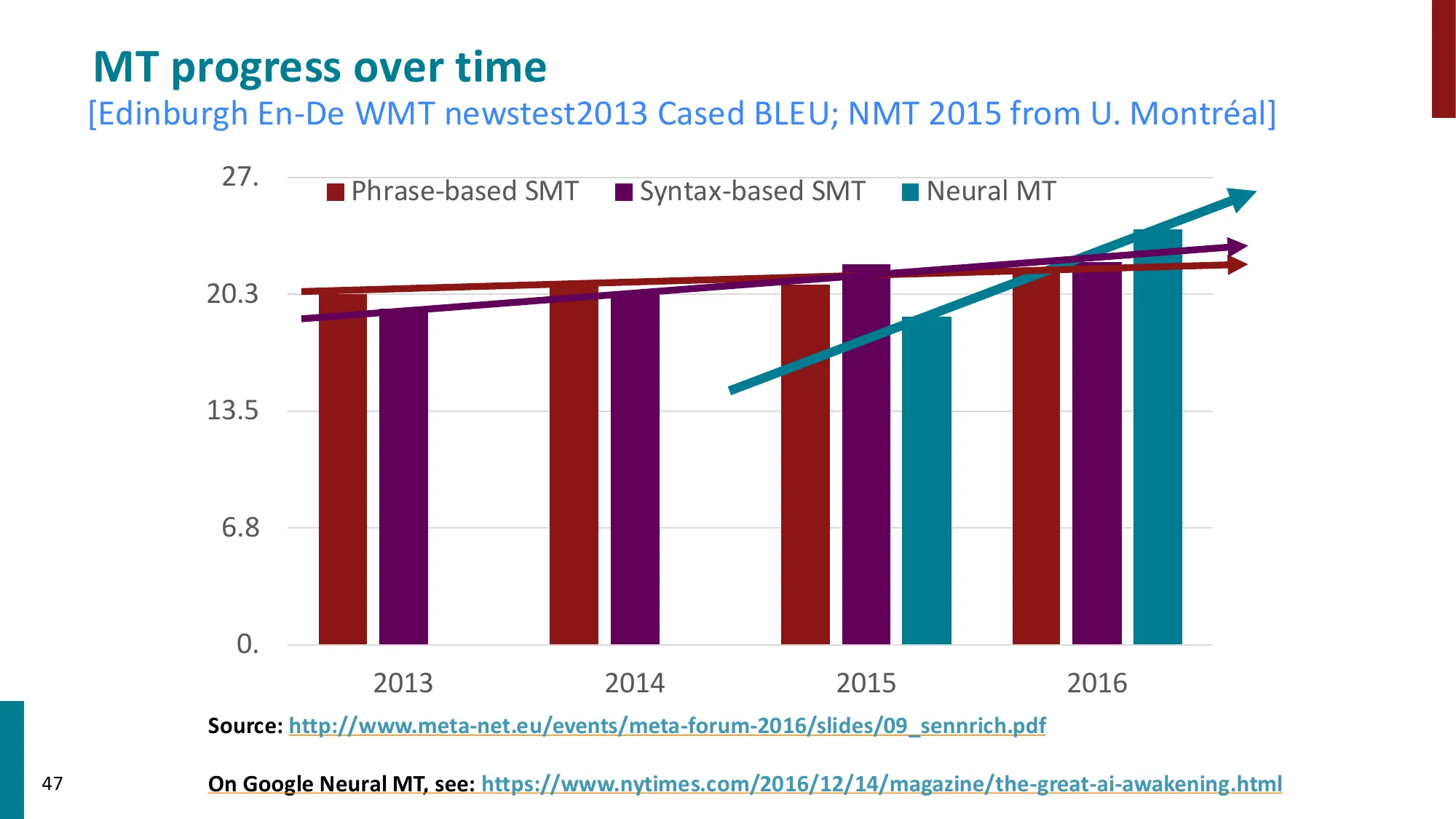

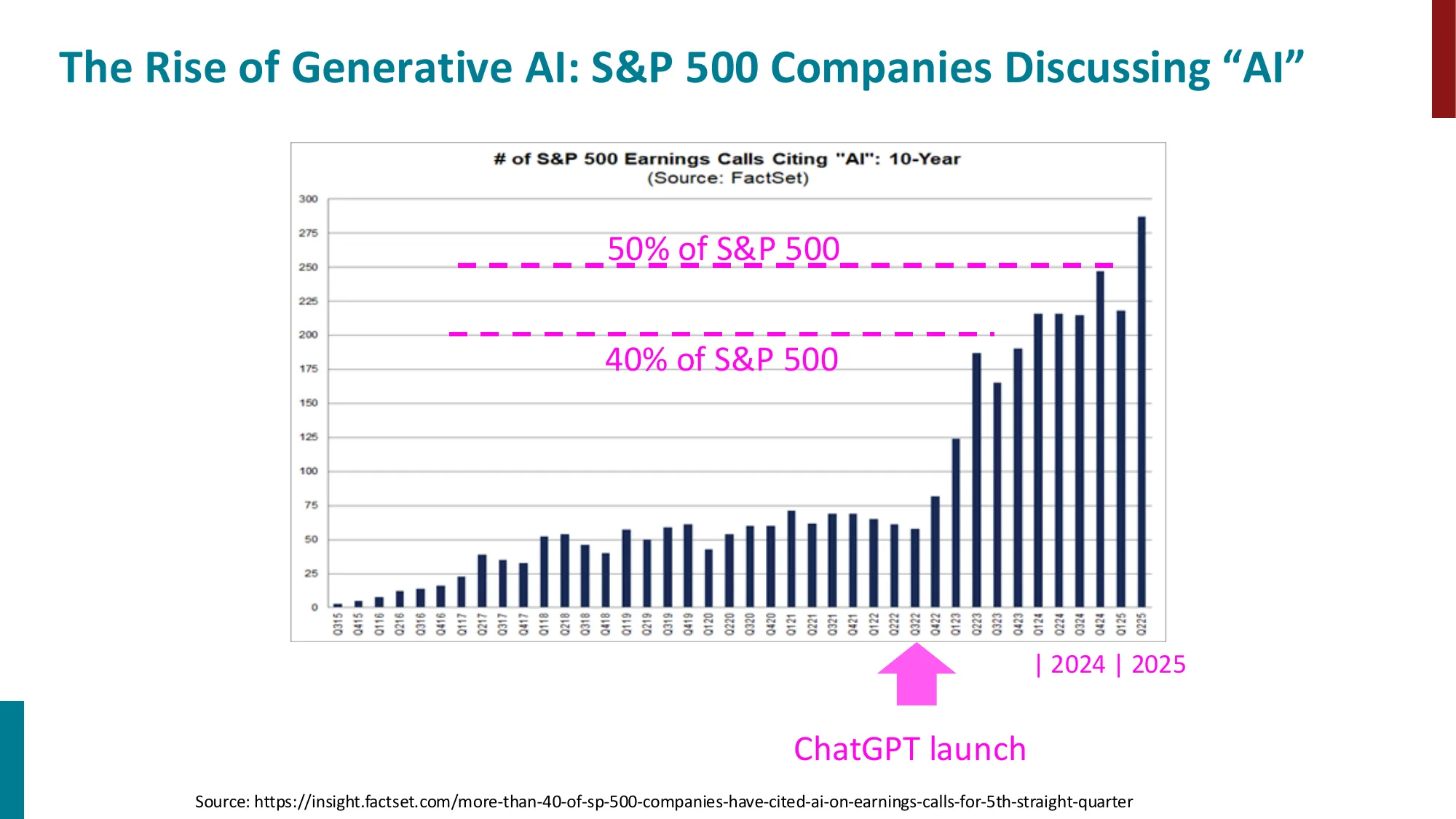




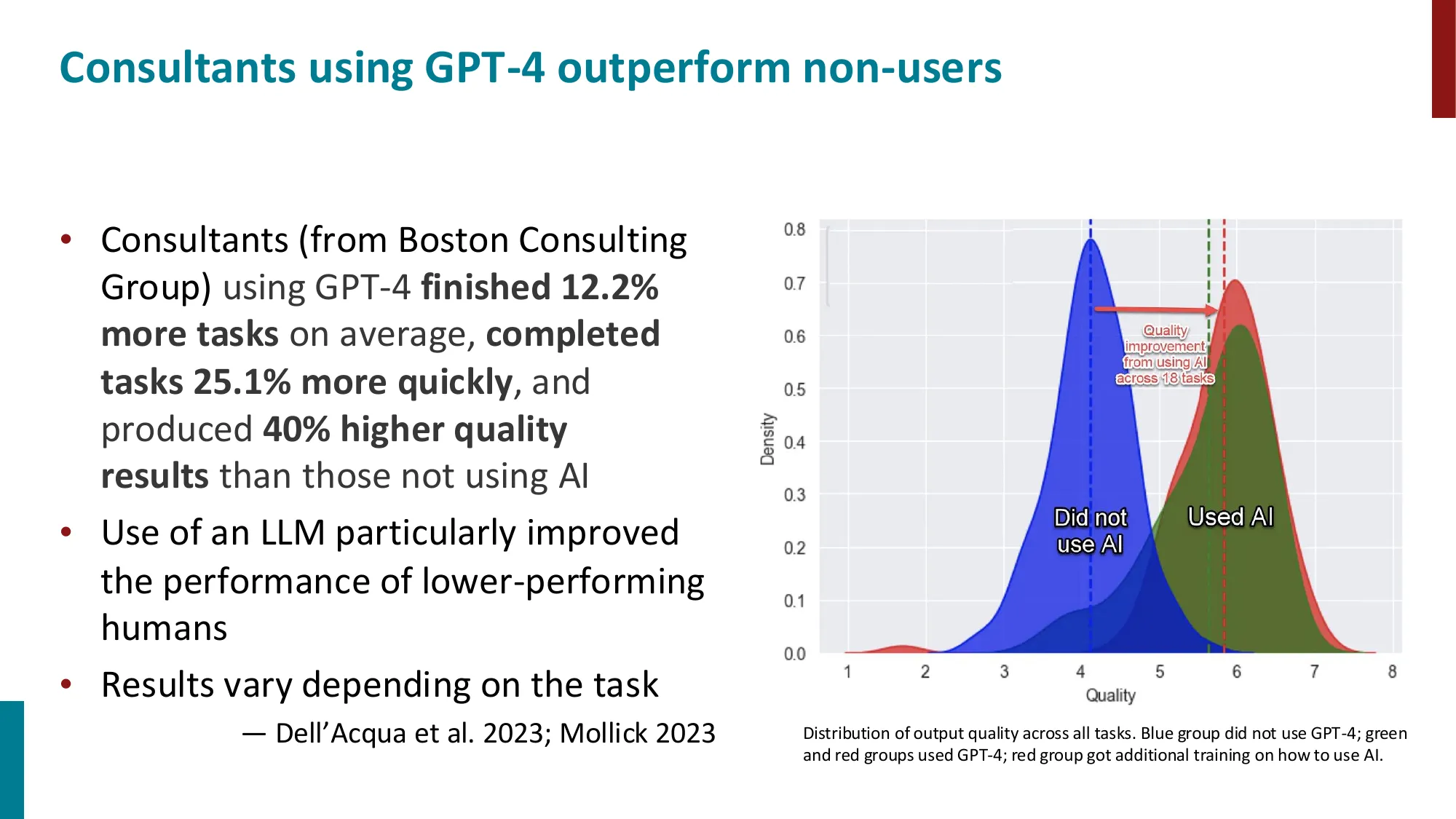

- Seq2Seq 模型(Sutskever et al., 2014)
- 注意力机制:“Attention Is All You Need”
- SQuAD 抽取式问答
- BERT/GPT 预训练范式的诞生与演变
- GLUE 基准测试
- 多语言模型(mBERT)
- Scaling Laws、Mamba(状态空间模型)
- RAG(检索增强生成)
- Agent 系统
- 推理能力(The Thinking LLM)
📐 Scaling Laws 与 Chinchilla 最优
Kaplan et al. (2020) Scaling Law:
其中 是 loss, 是模型参数量, 是训练 token 数,,。
Hoffman et al. (2022) Chinchilla:给定计算预算 (FLOPs),最优策略为:
即模型大小和数据量同等重要,应按 1:1 比例扩展(每参数约 20 个 token)。
实用推论:GPT-3(175B 参数,300B tokens)按 Chinchilla 标准严重”欠训练”——同等计算预算下,70B 参数训练 1.4T tokens 的 Chinchilla 模型性能更优。
Self-Attention 复杂度:
时间复杂度 ,这正是为什么长上下文是 LLM 工程的核心挑战。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
深度学习时代各里程碑的关键数字:
| 年份 | 系统 | 关键指标 |
|---|---|---|
| 2014 | Seq2Seq (LSTM) | WMT EN→FR BLEU: 34.8(首次超过 SMT) |
| 2017 | Transformer | WMT EN→DE BLEU: 28.4(+2 vs LSTM+Attention) |
| 2018 | BERT-Large | GLUE: 80.4(+7.7 vs 前 SOTA) |
| 2020 | GPT-3 (175B) | Few-shot SuperGLUE: 71.8(接近 fine-tuned BERT) |
| 2022 | Chinchilla (70B) | MMLU: 67.5(优于 Gopher 280B 的 60.0) |
| 2024 | GPT-4o / Claude 3.5 | MMLU > 90%,接近专家人类 |
💡 为什么这样做?
神经网络时代的革命性转变:不再设计特征,而是学习特征。Attention 机制的关键创新是:允许模型动态选择”关注哪些信息”,而不是固定地按距离衰减(RNN)或手工选窗口(CNN)。Scaling Law 揭示了一个更深刻的事实:语言能力是涌现(emergent)的,简单地扩大规模就能解锁新能力,而不需要专门设计每一项能力。
⚠️ 常见误区
- 误区:LLM 只是”更大的 n-gram 模型” → 正确:LLM 通过注意力机制学会了组合性推理和泛化,能处理从未见过的概念组合——这是 n-gram 无法做到的。
- 误区:Scaling Law 说明”数据越多越好,参数越多越好” → 正确:Chinchilla 告诉我们两者需要平衡,给定计算预算,一味堆参数而数据不足会浪费计算。
3. 关键学习目标
- 理解 NLP 中的范式转变(paradigm shifts)
- 理解我们对语言的假设如何塑造了每个时代的可能性
📐 四个时代的核心假设对比
| 时代 | 对语言的假设 | 核心技术 | 学习方式 |
|---|---|---|---|
| 早期探索 | 语言 = 有限规则系统(密码学类比) | 手工规则 | 无学习 |
| 符号 NLP | 语言 = 形式文法 + 逻辑 | HMM、PCFG | 统计估计参数 |
| 统计/ML | 语言 = 分布式统计规律 | SVM、CRF、词嵌入 | 手工特征 + 学习分类器 |
| 深度学习 | 语言能力是可涌现的 | Transformer、预训练 | 端到端学习所有特征 |
每次范式转变的根本原因:前一个假设遇到了难以克服的瓶颈(规则维护成本、稀疏数据问题、特征工程成本),而新技术恰好突破了这个瓶颈。
💡 为什么这样做?
Manning 讲这段历史不是为了怀旧——而是要让你理解:当前主流方法(LLM)也有其假设和局限。下一个范式转变会在哪里?可能是:推理能力的瓶颈、数据效率(人类用少得多的数据学习语言)、组合泛化能力。理解历史的目的是预见未来。
⚠️ 常见误区
- 误区:新时代完全取代旧时代 → 正确:现代 LLM 仍然使用词嵌入(源自统计时代)、注意力机制(可以视为软化的规则匹配)、贝叶斯推断(统计 NLP 的核心)——新时代是旧时代的整合与超越,不是完全抛弃。
推荐阅读
- Efficient Estimation of Word Representations in Vector Space (Mikolov et al., 2013a) — Word2Vec
- Distributed Representations of Words and Phrases (Mikolov et al., 2013b) — 待读
- GloVe: Global Vectors for Word Representation (Pennington et al., 2014) — GloVe
- Manning, C.D. (2022). Human Language Understanding & Reasoning. Daedalus 151(2): 127-138.