L04: Language Models and Recurrent Neural Networks
Week 2 · Thu Jan 15 2026 08:00:00 GMT+0800 (中国标准时间)
L04: Language Models and Recurrent Neural Networks
Slides
中英交替版(推荐)
L04 双语 (PDF)
英文原版
L04 EN (PDF)
中文翻译版
L04 ZH (PDF)
核心知识点
1. 语言模型(Language Modeling)— 本课最重要的概念
- 定义:预测下一个词的任务
- 给定词序列 x(1),x(2),…,x(t),计算 P(x(t+1)∣x(t),…,x(1))
- 等价地:为一段文本赋予概率
- P(x(1),…,x(T))=∏t=1TP(x(t)∣x(t−1),…,x(1))
- 无处不在的应用:预测输入、搜索补全、语音识别、拼写纠错、机器翻译、对话、摘要…
- ChatGPT 本质就是一个语言模型!
- 下一词预测能解决的任务:常识(trivia)、句法(syntax)、共指(coreference)、情感(sentiment)、推理(reasoning)等
📐 语言模型概率的链式分解
联合概率 → 条件概率的乘积(链式法则 Chain Rule of Probability):
P(x(1),x(2),…,x(T))=P(x(1))⋅P(x(2)∣x(1))⋅P(x(3)∣x(1),x(2))⋯
推导:
P(A,B,C)=P(A)⋅P(B∣A)⋅P(C∣A,B)
这是概率论的基本恒等式(条件概率定义:P(B∣A)=P(A,B)/P(A)),无任何假设。
扩展到序列:
P(x(1),…,x(T))=∏t=1TP(x(t)∣x(t−1),…,x(1))
语言模型的任务:对每个 t,学习 P(x(t)∣x(t−1),…,x(1)),即给定历史预测下一个词。
困惑度(Perplexity):测量语言模型”有多惊讶”于给定文本:
PPL=exp(−T1∑t=1TlogP(x(t+1)∣x(≤t)))=exp(J)
PPL=k 意味着模型在每个位置的平均不确定性相当于在 k 个词中均匀随机猜测。PPL 越低,模型越好。
📚 已收录至 拓展阅读知识库
🔢 困惑度计算示例
设定:测试文本 “the cat sat”(3 个词,加上结束符共 3 步预测),模型给出的条件概率:
| 时间步 | 预测目标 | 条件概率 P(x(t+1)∣x(≤t)) |
|---|
| t=0 | “the” | 0.10(高频词) |
| t=1 | “cat” | 0.05 |
| t=2 | ”sat” | 0.20 |
计算:
- 平均对数概率 = 31[log(0.10)+log(0.05)+log(0.20)]
- =31[−2.303−2.996−1.609]=3−6.908=−2.303
- PPL=exp(2.303)≈10.0
解读:平均每步相当于在 10 个词里猜一个。
对比:随机猜测(词汇表 50,000 词)的 PPL = 50,000;GPT-4 在 PTB 数据集 PPL ≈ 2050;人类理解文本约 2040。
⚠️ 常见误区
- 误区:语言模型 = 生成式模型 → 正确:语言模型也可以是判别模型(如 masked LM,BERT)。经典语言模型是自回归的(给定前文预测下一词),但并非唯一形式。
- 误区:PPL 越低一定越好 → 正确:PPL 依赖测试集。在训练集上极低 PPL = 过拟合。此外,PPL 低不代表生成文本的质量好(可能重复、语义空洞)。
2. N-gram 语言模型
- N-gram:n 个连续词的片段
- unigram / bigram / trigram / 4-gram …
- 马尔可夫假设:x(t+1) 只依赖前 n−1 个词
- P(x(t+1)∣x(t),…,x(1))≈P(x(t+1)∣x(t),…,x(t−n+2))
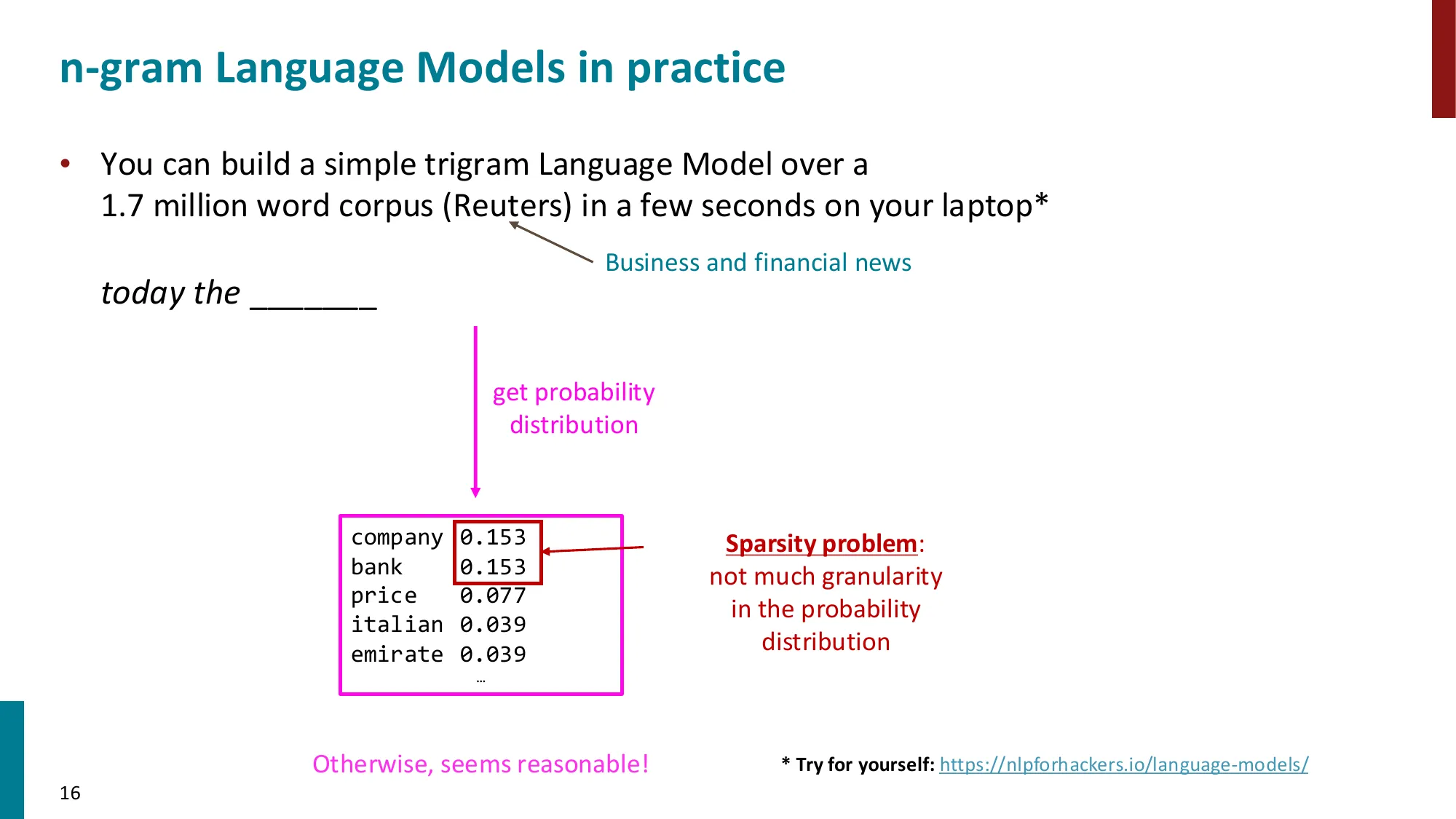
- 概率估计:计数法
- P(w∣context)≈count(context)count(context,w)
- 示例(4-gram):“students opened their” 出现 1000 次
- “students opened their books” 400 次 → P(books)=0.4
- “students opened their exams” 100 次 → P(exams)=0.1
- 稀疏性问题:
- 问题 1:n-gram 未在语料中出现 → 概率为 0 → 平滑(smoothing):给每个词加小 δ
- 问题 2:(n−1)-gram 未出现 → 无法计算 → 回退(backoff):用更短的 n-gram
- 存储问题:需要存储所有见过的 n-gram 的计数
- 生成文本:惊人地符合语法,但语义不连贯(上下文窗口太小)
📐 N-gram 概率估计与平滑
马尔可夫假设(N-gram 的核心):
P(x(t+1)∣x(t),…,x(1))≈P(x(t+1)∣x(t),…,x(t−n+2))
只保留最近 n−1 个词的历史,使得条件历史有限,可以通过计数估计。
最大似然估计(MLE):
P(w∣wt−n+2,…,wt)≈C(wt−n+2,…,wt)C(wt−n+2,…,wt,w)
其中 C(⋅) 是语料库中的计数。
稀疏性问题:如果分子为 0(n-gram 从未出现),概率为 0,且导致任何包含此 n-gram 的句子概率为 0。
解决方法 1 — Laplace 平滑(加一平滑):
Psmooth(w∣h)=∑w′[C(h,w′)+δ]C(h,w)+δ=C(h)+δ∣V∣C(h,w)+δ
通过给每个词加小量 δ=1,保证所有概率 > 0。
解决方法 2 — Kneser-Ney 回退(Backoff):
当 n-gram 未出现时,回退到 (n−1)-gram(递归直到 unigram):
PKN(w∣h)={max(C(h,w)−d,0)/C(h)+λ(h)⋅PKN(w∣h−1)PKN(w∣h−1)if C(h,w)>0otherwise
📚 已收录至 拓展阅读知识库
🔢 Bigram 概率计算示例
语料(玩具语料):
- “I like cats” (1 次)
- “I like dogs” (2 次)
- “cats like fish” (1 次)
Bigram 计数:(I, like)=3, (like, cats)=1, (like, dogs)=2, (cats, like)=1
计算 P(dogs∣like):
P(dogs∣like)=C(like)C(like, dogs)=32≈0.67
计算 P(fish∣like):
P(fish∣like)=C(like)C(like, fish)=30=0
加 Laplace 平滑(词汇表 ∣V∣=5,δ=1):
Psmooth(fish∣like)=3+50+1=81=0.125
⚠️ 常见误区
- 误区:n 越大越好 → 正确:n 越大,数据稀疏性越严重(多数 5-gram 从未在语料中出现)。实践中 n=5 已经是上限,且需要大量平滑。
- 误区:N-gram 已经过时 → 正确:N-gram 在工业界的特定场景(输入法、拼写检查)中依然使用,因为极其高效且可解释。理解 N-gram 有助于理解神经语言模型为什么更好。
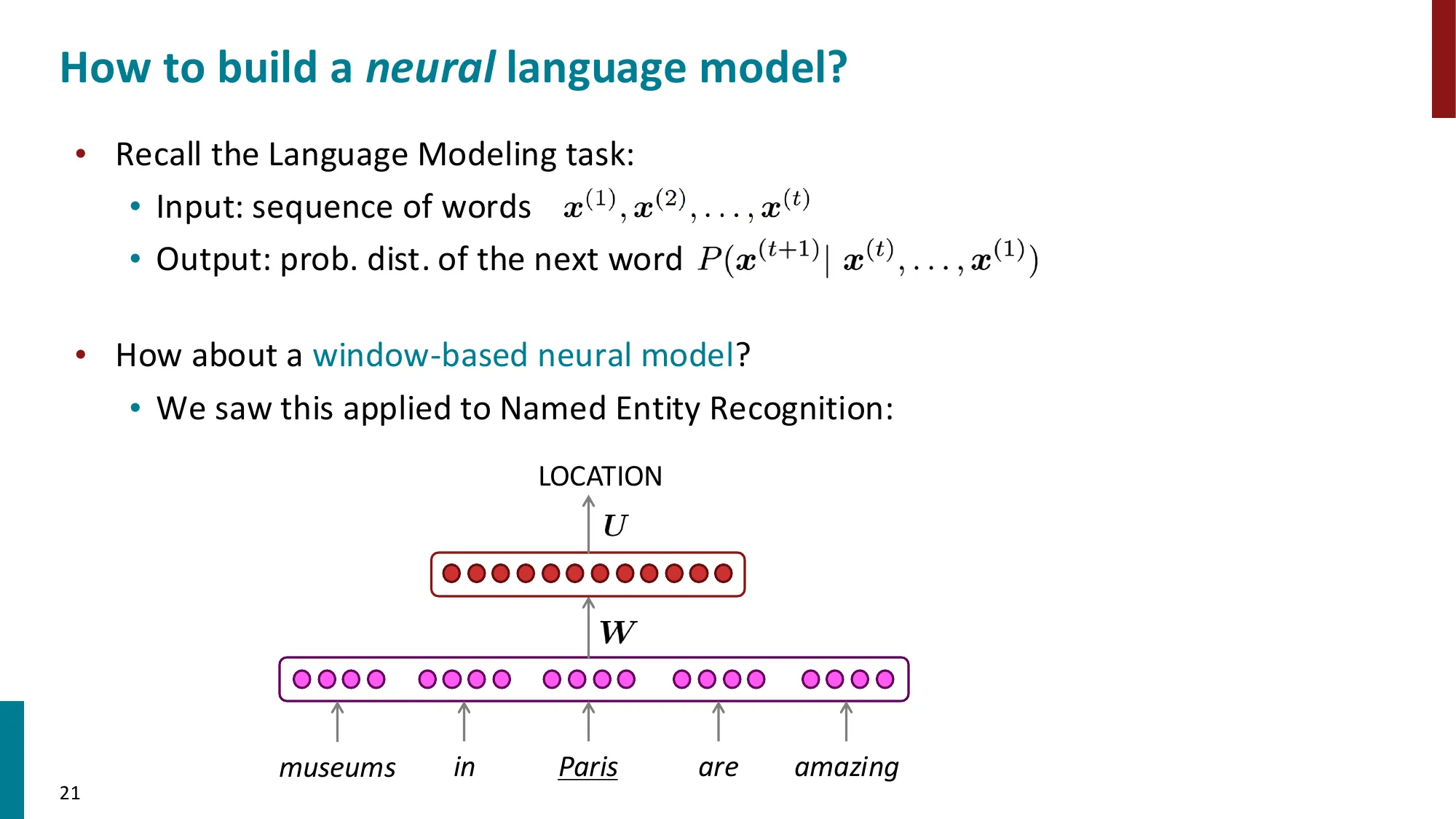
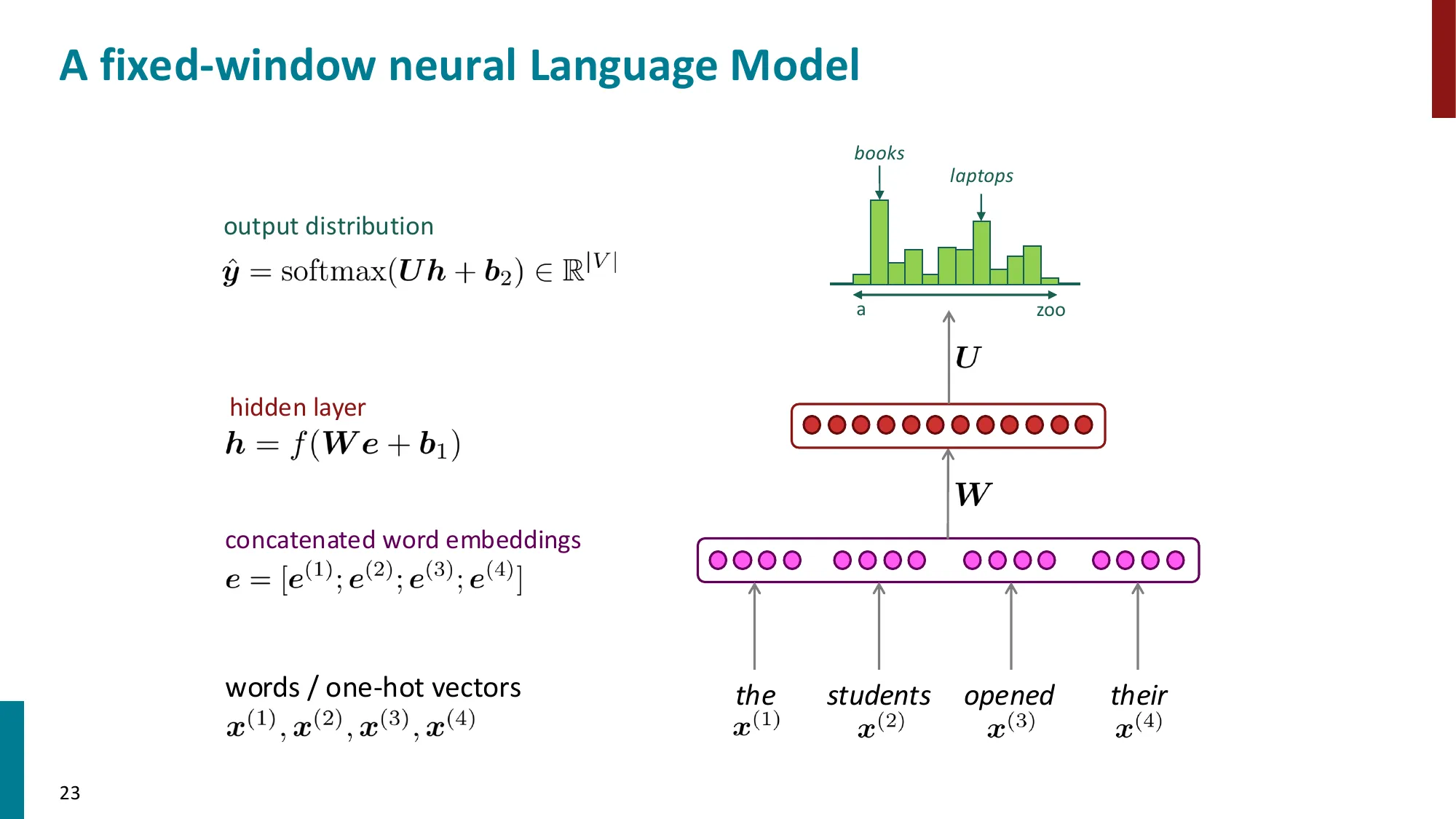
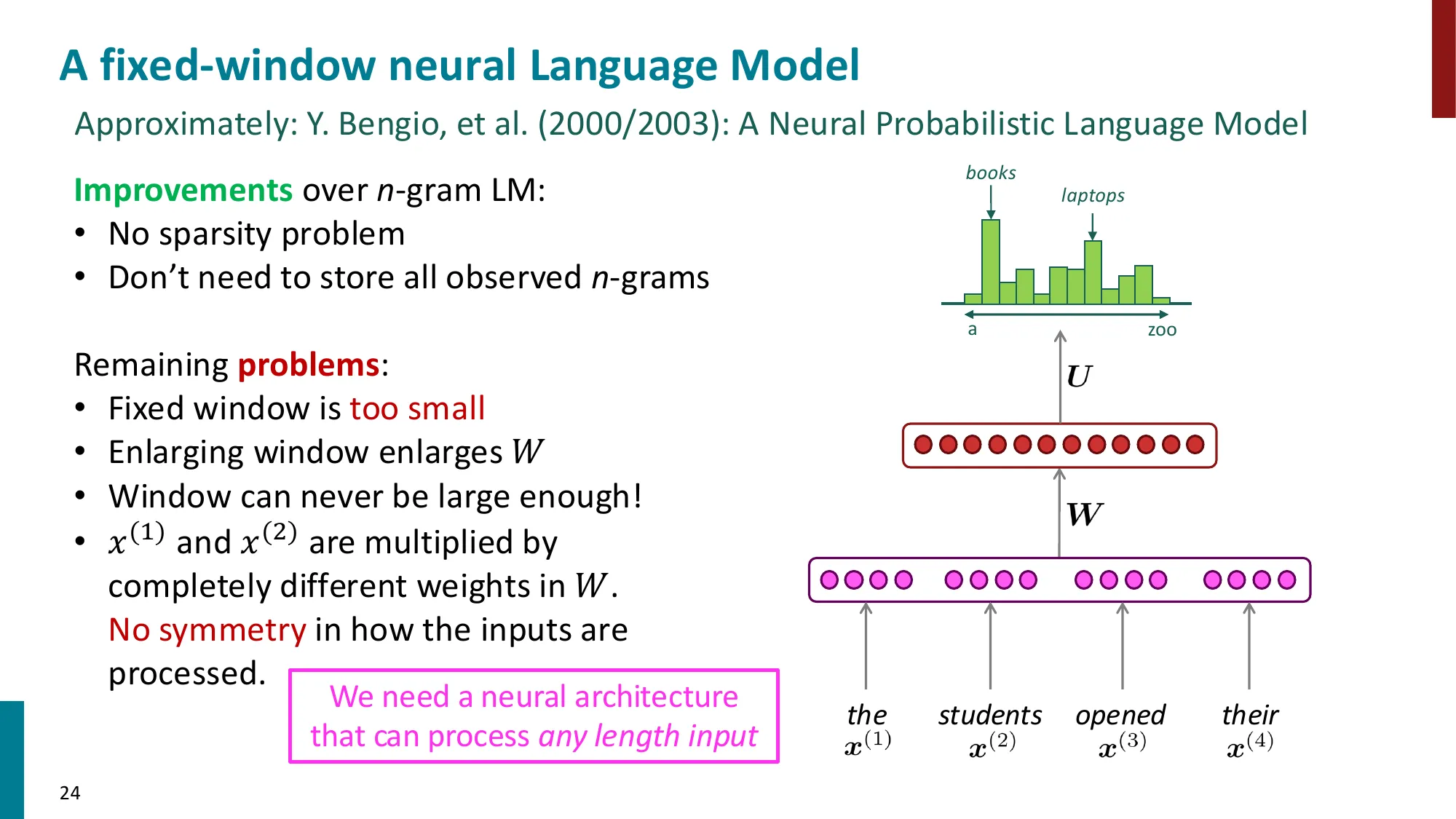
3. 固定窗口神经语言模型
 Slide 21
Slide 21
 Slide 22
Slide 22
 Slide 23
Slide 23
 Slide 24
Slide 24
- 改进 n-gram:用神经网络替代计数
- Bengio et al. (2003):首个神经语言模型
- 输入:固定窗口内词向量的拼接
- 隐藏层 + softmax 输出
- 优点:无稀疏性问题、无需存储所有 n-gram
- 问题:窗口大小固定,无法利用更远的上下文
💡 为什么从 N-gram → 神经语言模型是进步?
N-gram 的本质问题:用计数(频率)估计概率。问题是”the students opened their ___“和”the professors opened their ___“在语言学上极其相似,但 N-gram 把它们当成完全不同的 4-gram,无法共享任何信息。
神经语言模型的洞察:用词向量表示历史!
“students” 和 “professors” 的词向量很相似(都是人),所以网络自然会对这两个 context 给出相似的预测分布。
这就是”泛化”——神经网络通过连续表示,把相似的输入映射到相似的输出,而 N-gram 做不到。
局限:固定窗口(如 5 词)仍然无法捕捉远距离依赖,且不同位置使用不同的权重矩阵(W1,W2,…),无法共享参数。
⚠️ 常见误区
误区:固定窗口神经 LM 和 N-gram 一样 → 正确:固定窗口神经 LM 的”有效上下文”是词向量而非 one-hot,因此可以泛化到未见过的 n-gram。但两者都受固定窗口大小限制,这是 RNN 要解决的问题。
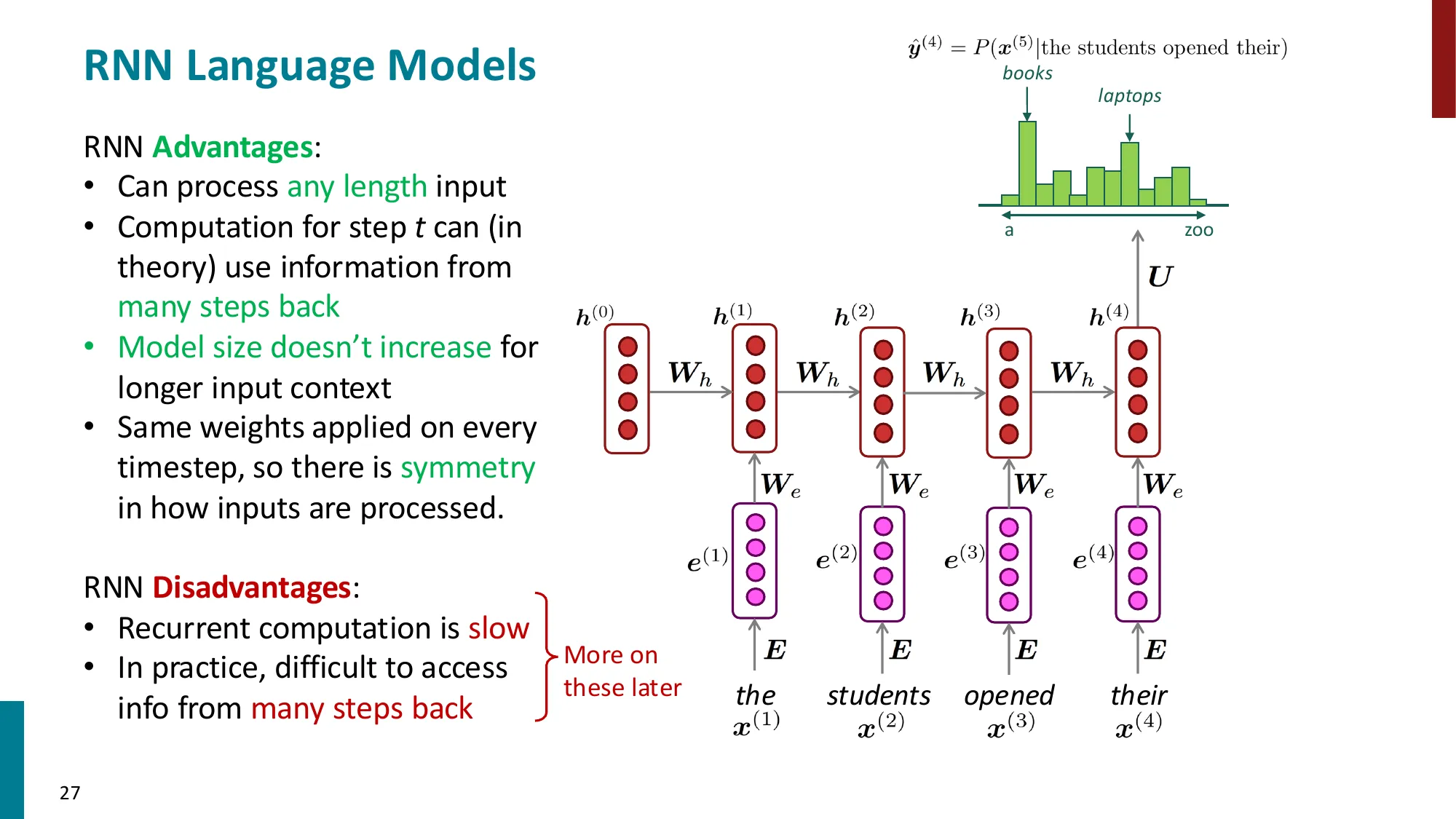
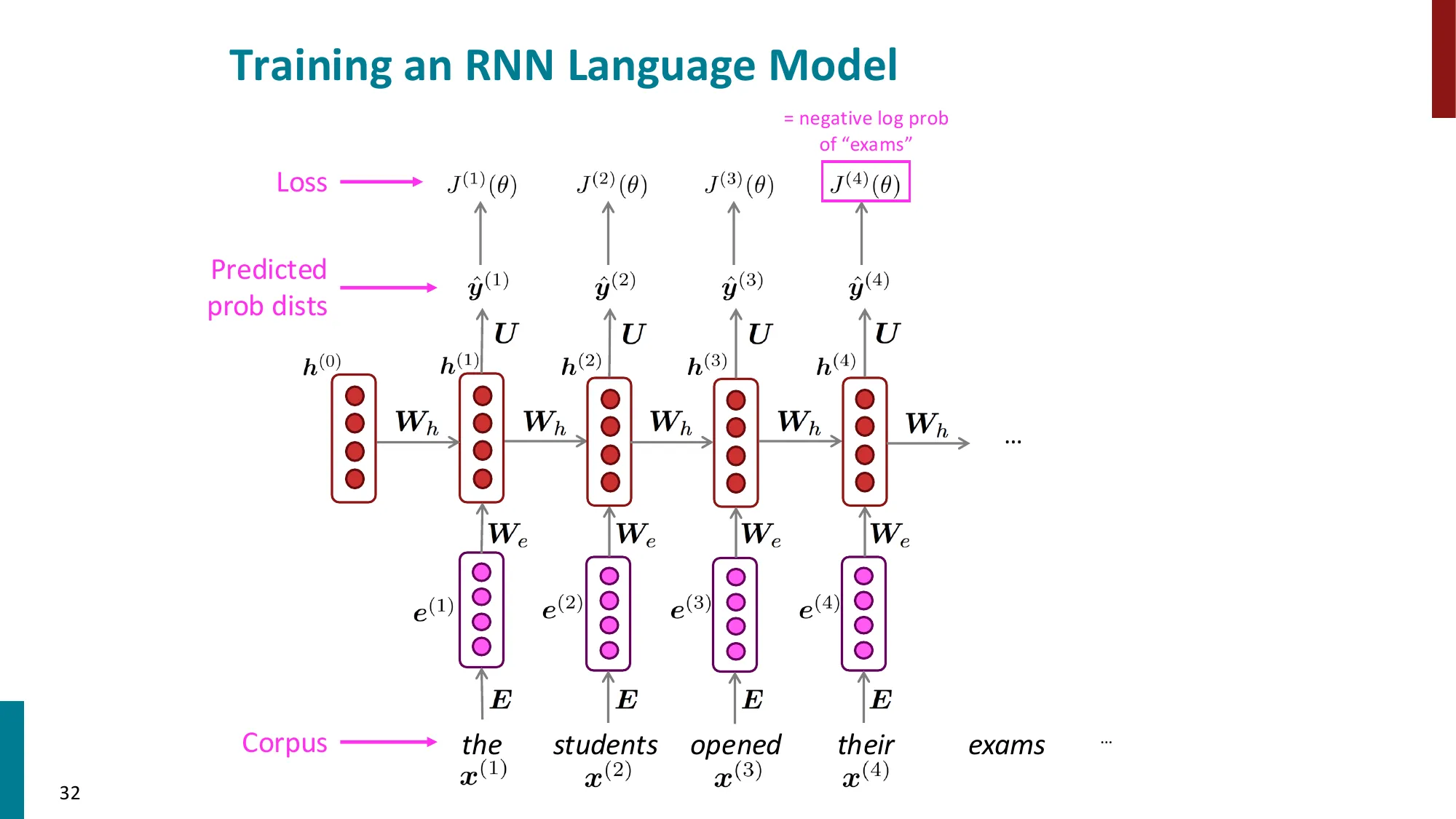
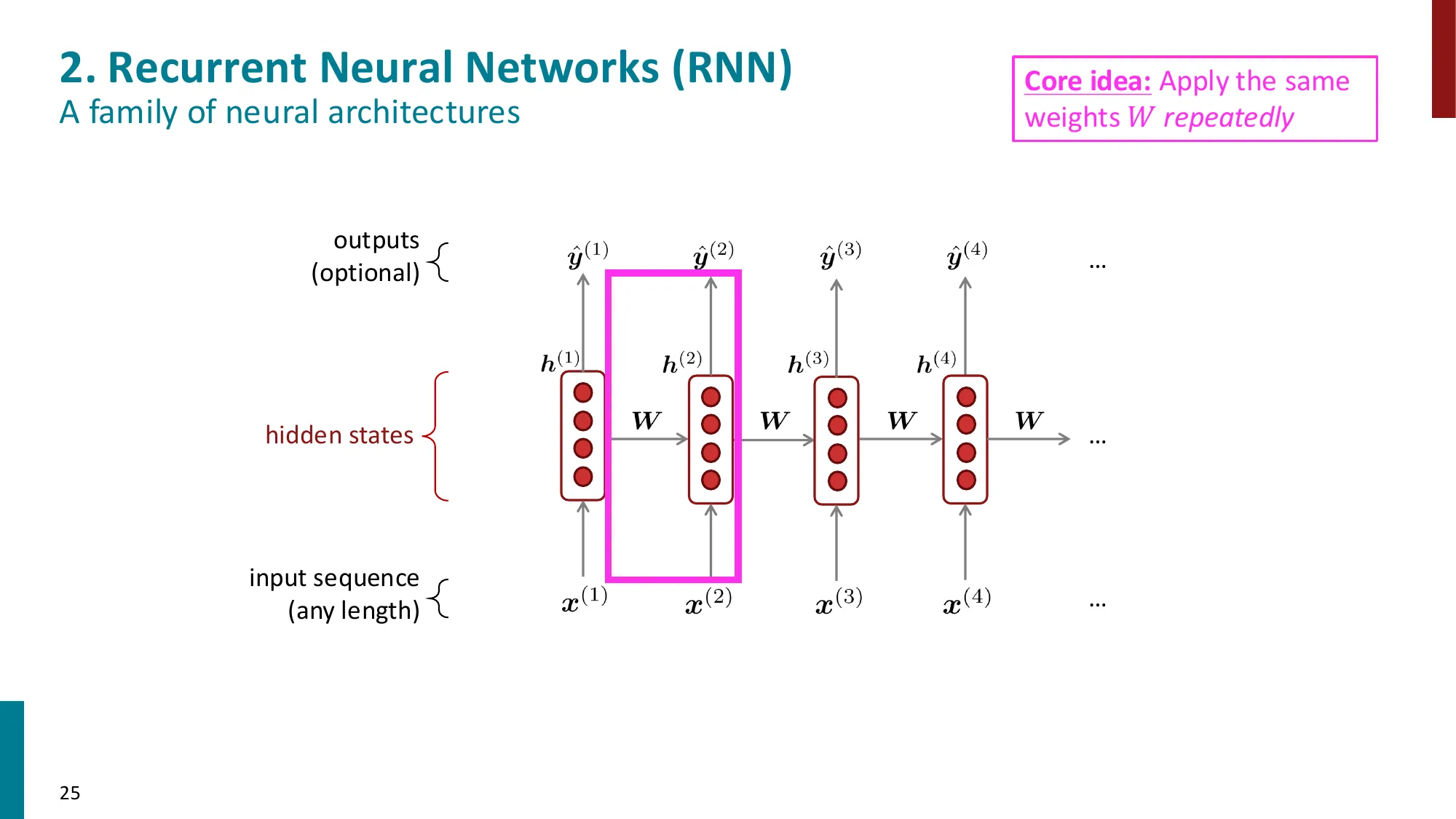
4. 循环神经网络(RNN)
- 核心思想:处理任意长度的序列,在每个时间步共享权重
- 隐状态更新:
- h(t)=σ(Whh(t−1)+Wxx(t)+b)
- 输出分布:y^(t)=softmax(Uh(t)+b2)
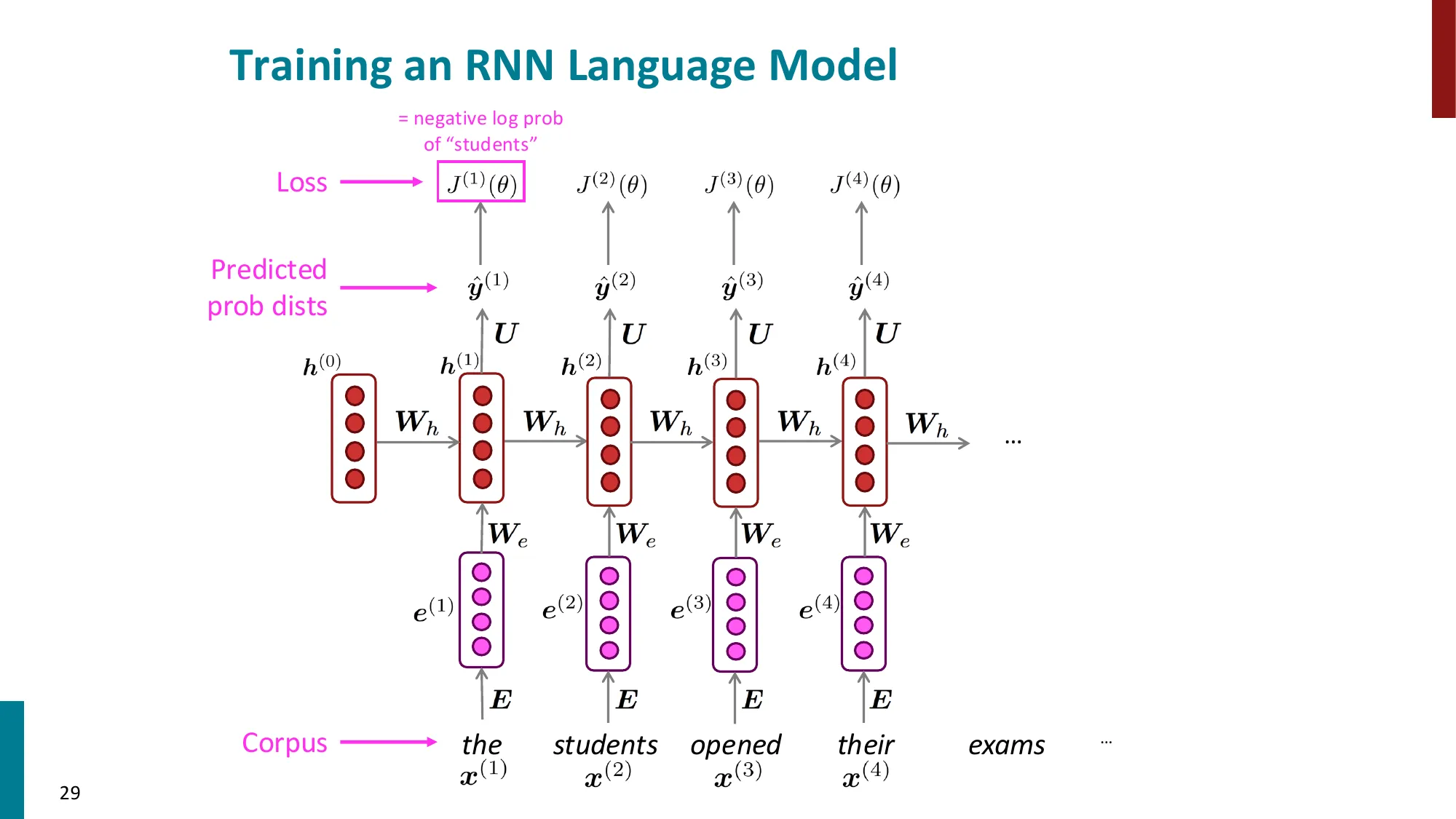
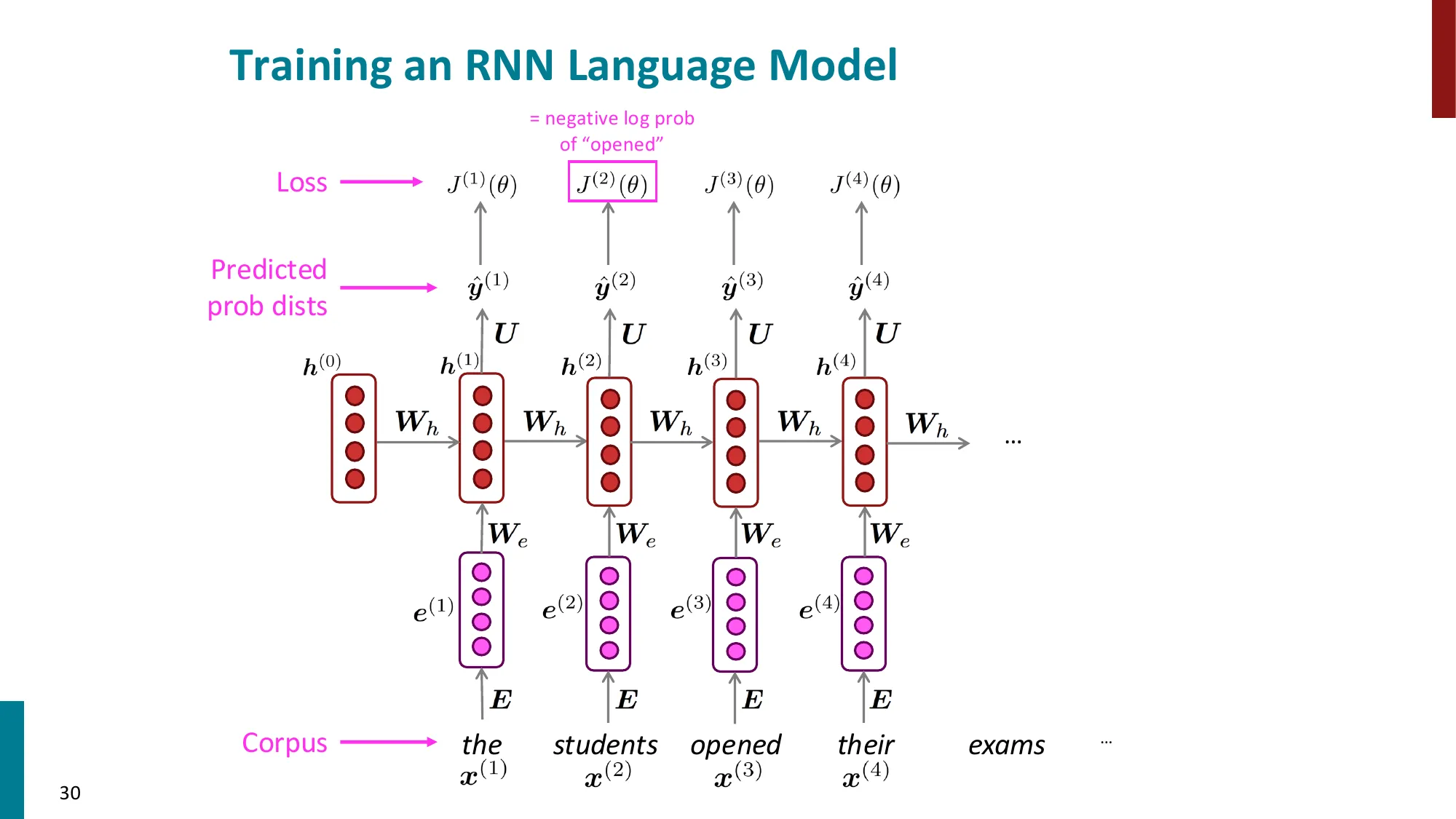
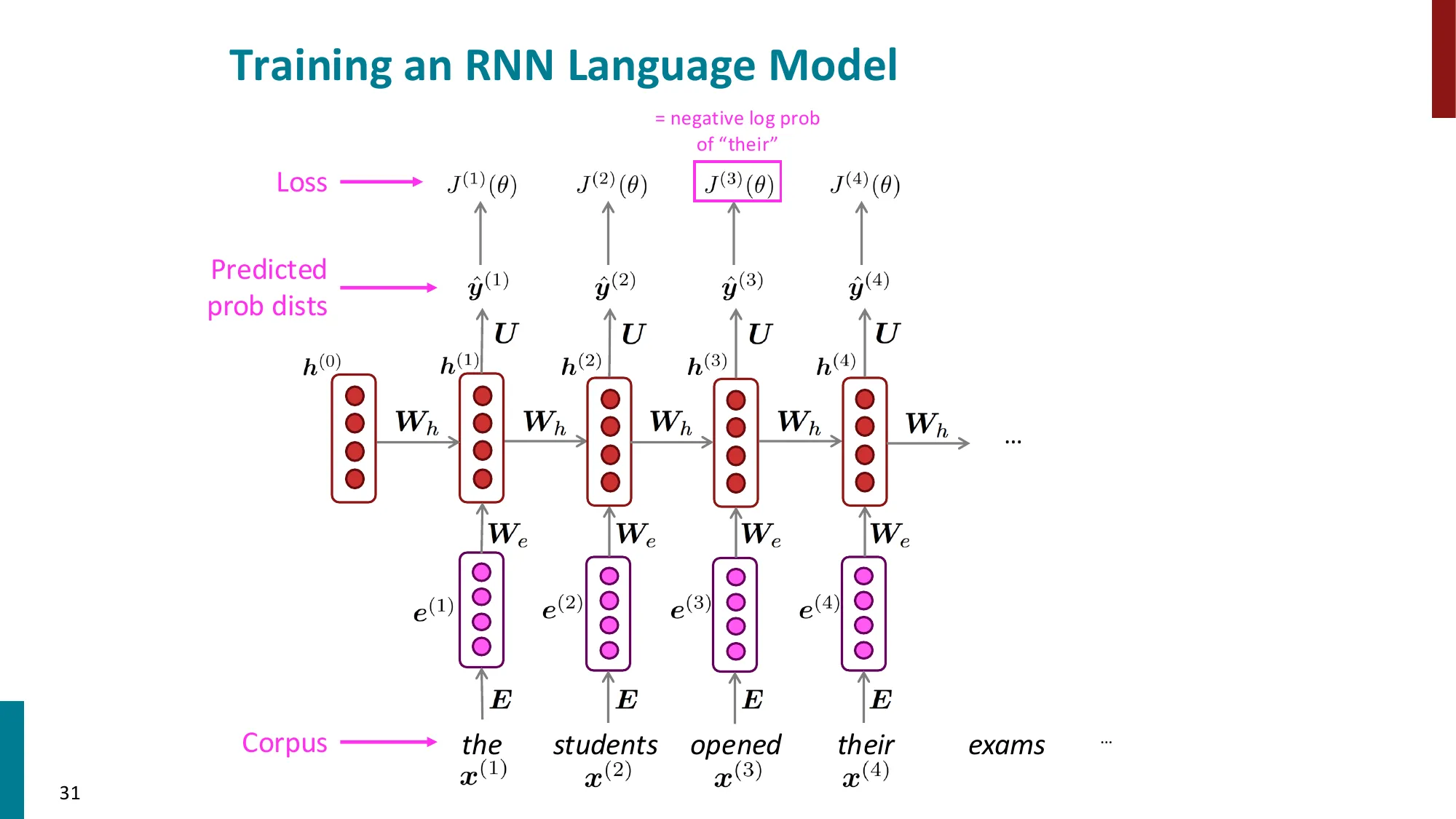
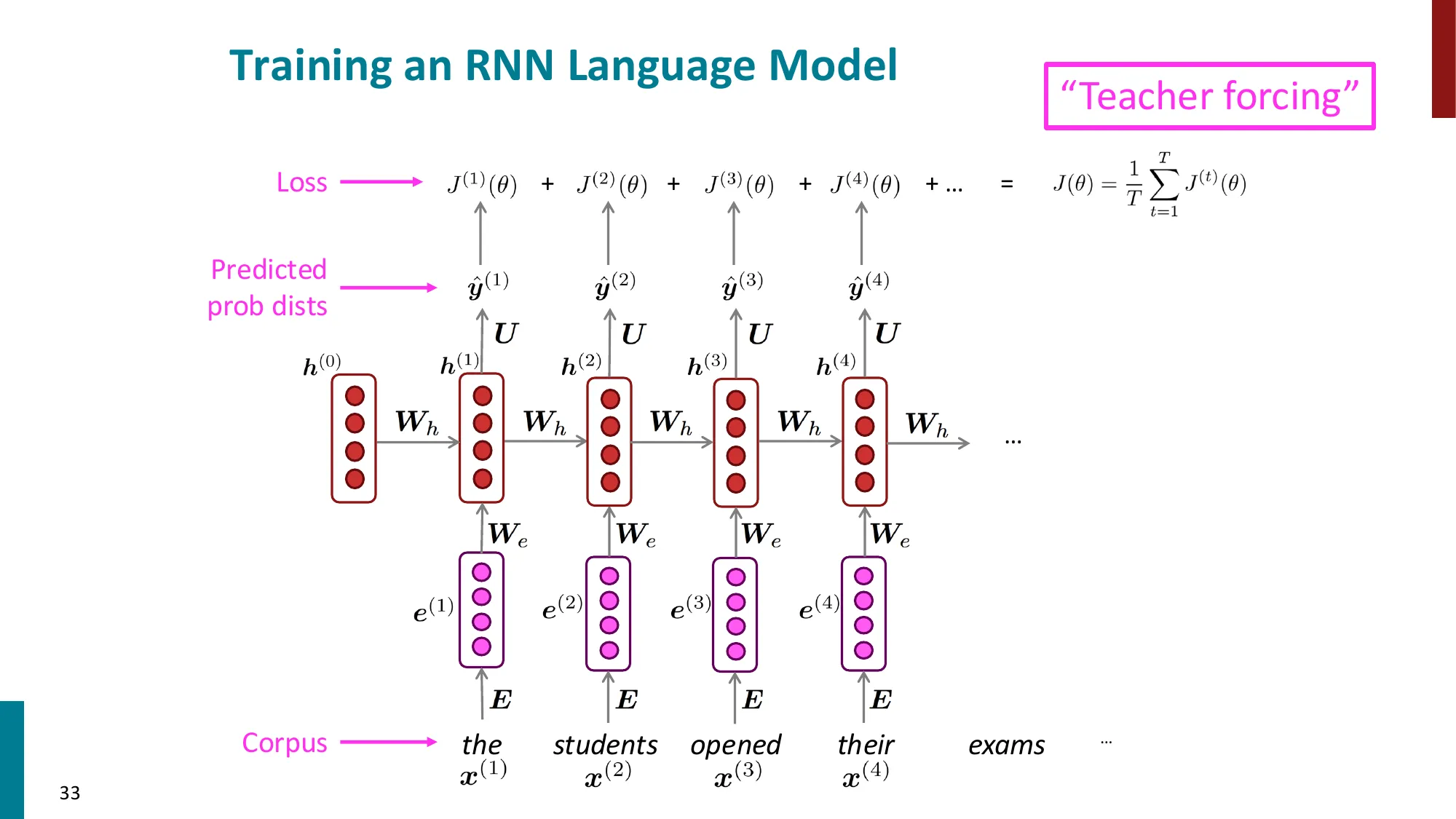
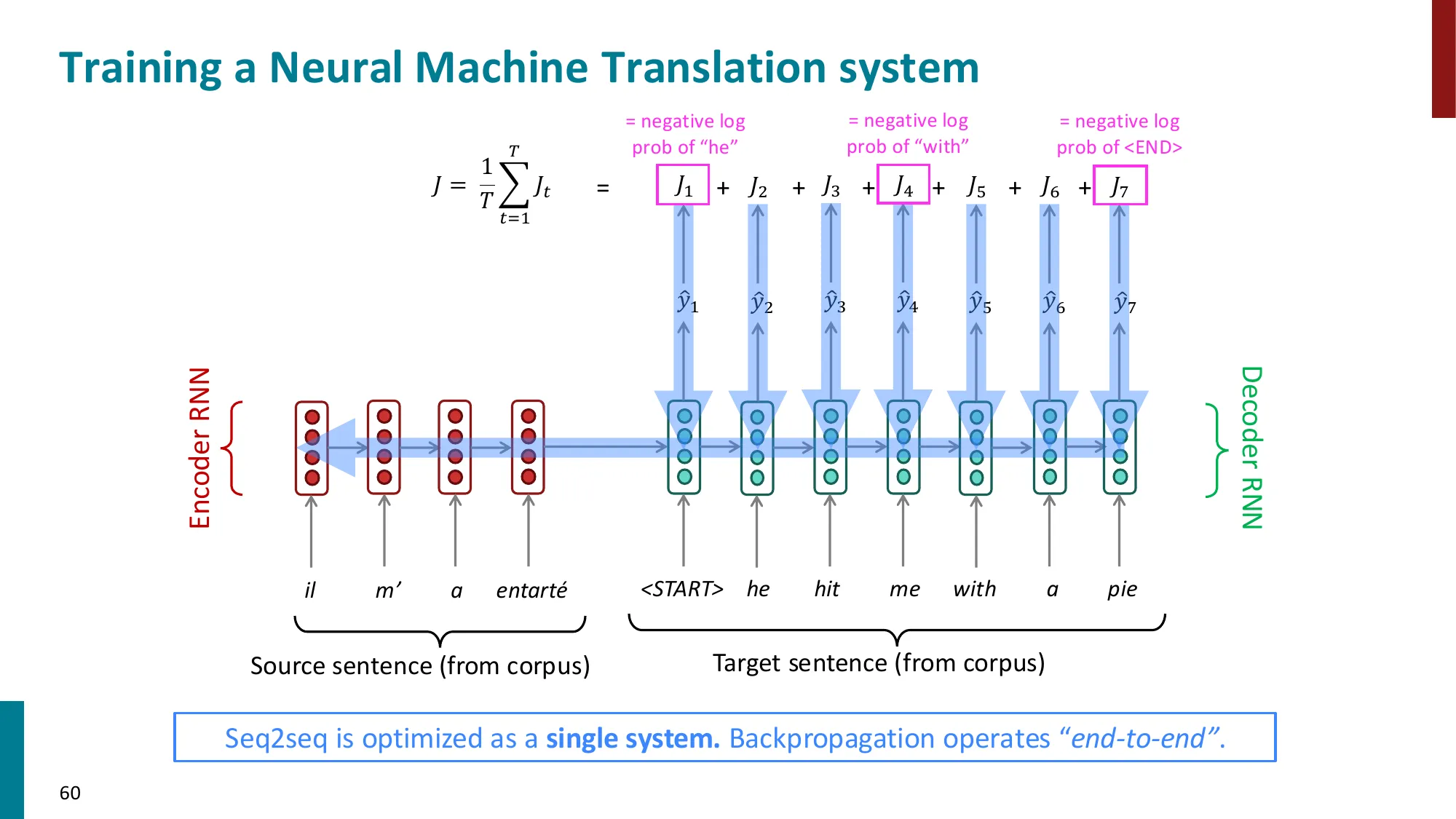
- 训练:对每个时间步计算交叉熵损失,总损失取平均
- J(θ)=T1∑t=1TJ(t)=−T1∑t=1TlogP(x(t+1)∣x(t),…,x(1))
- 评估指标:困惑度(Perplexity)
- PPL=exp(J(θ))=exp(−T1∑t=1TlogP(x(t+1)∣…))
- PPL 越低越好;等价于交叉熵损失的指数形式
- 优点:可处理任意长序列、理论上可利用远距离信息、模型大小不随输入增长
- 缺点:循环计算导致训练慢、实际中难以学习长距离依赖
📐 RNN 前向传播与 BPTT
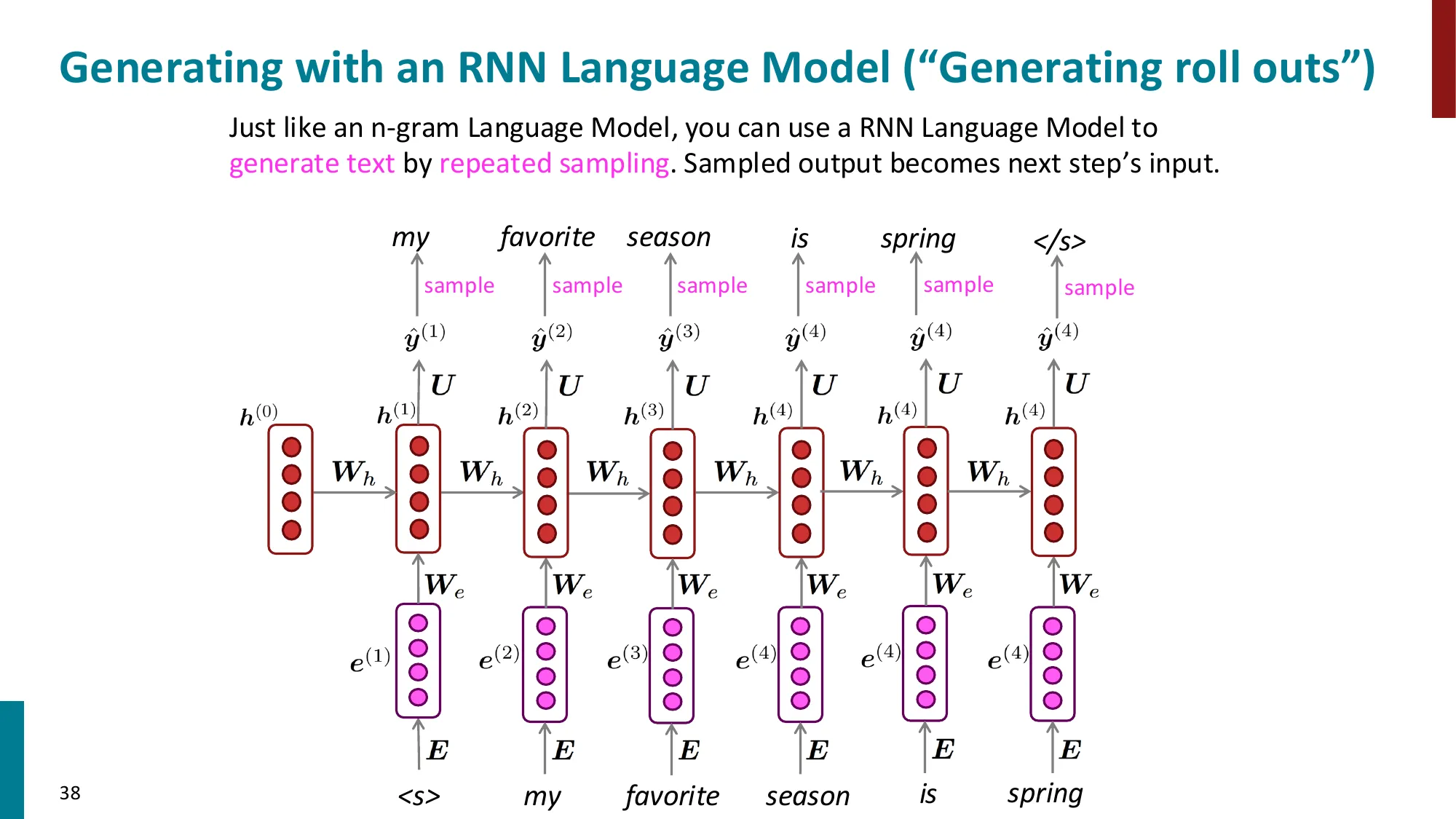
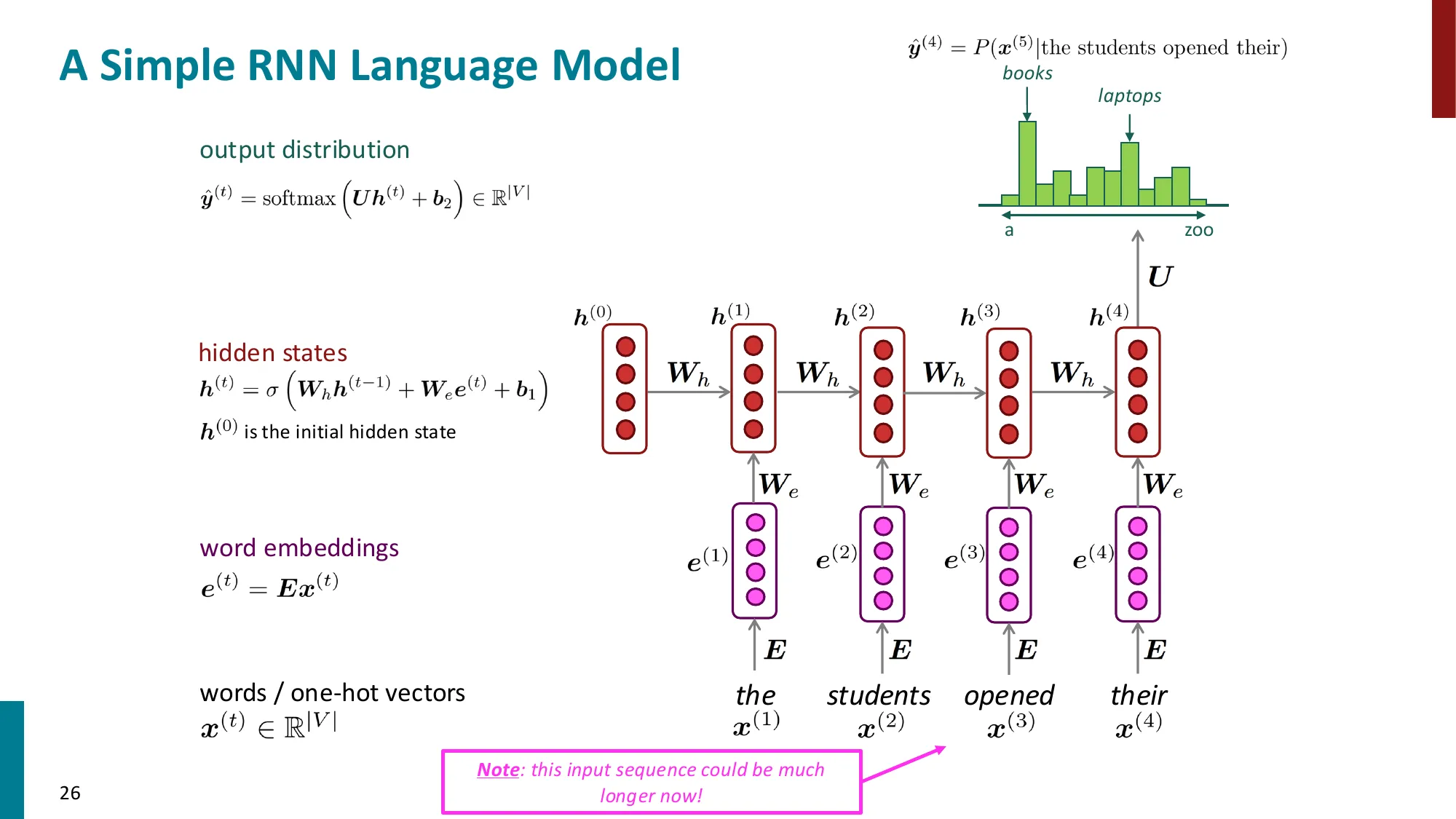
前向传播(Forward Pass):
给定词嵌入序列 x(1),…,x(T)(每个 x(t)∈Rd):
步骤 1:初始化 h(0)=0(或随机初始化)
步骤 2:逐步更新隐状态:
h(t)=σ(Whh(t−1)+Wxx(t)+bh)
其中 Wh∈Rn×n(隐藏到隐藏),Wx∈Rn×d(输入到隐藏)
步骤 3:每步输出分布(softmax 预测下一词):
y^(t)=softmax(Wyh(t)+by)
损失:J(t)=−logP(x(t+1)∣x(≤t))=−logy^x(t+1)(t)(正确词的对数概率)
总损失:J=T1∑t=1TJ(t)
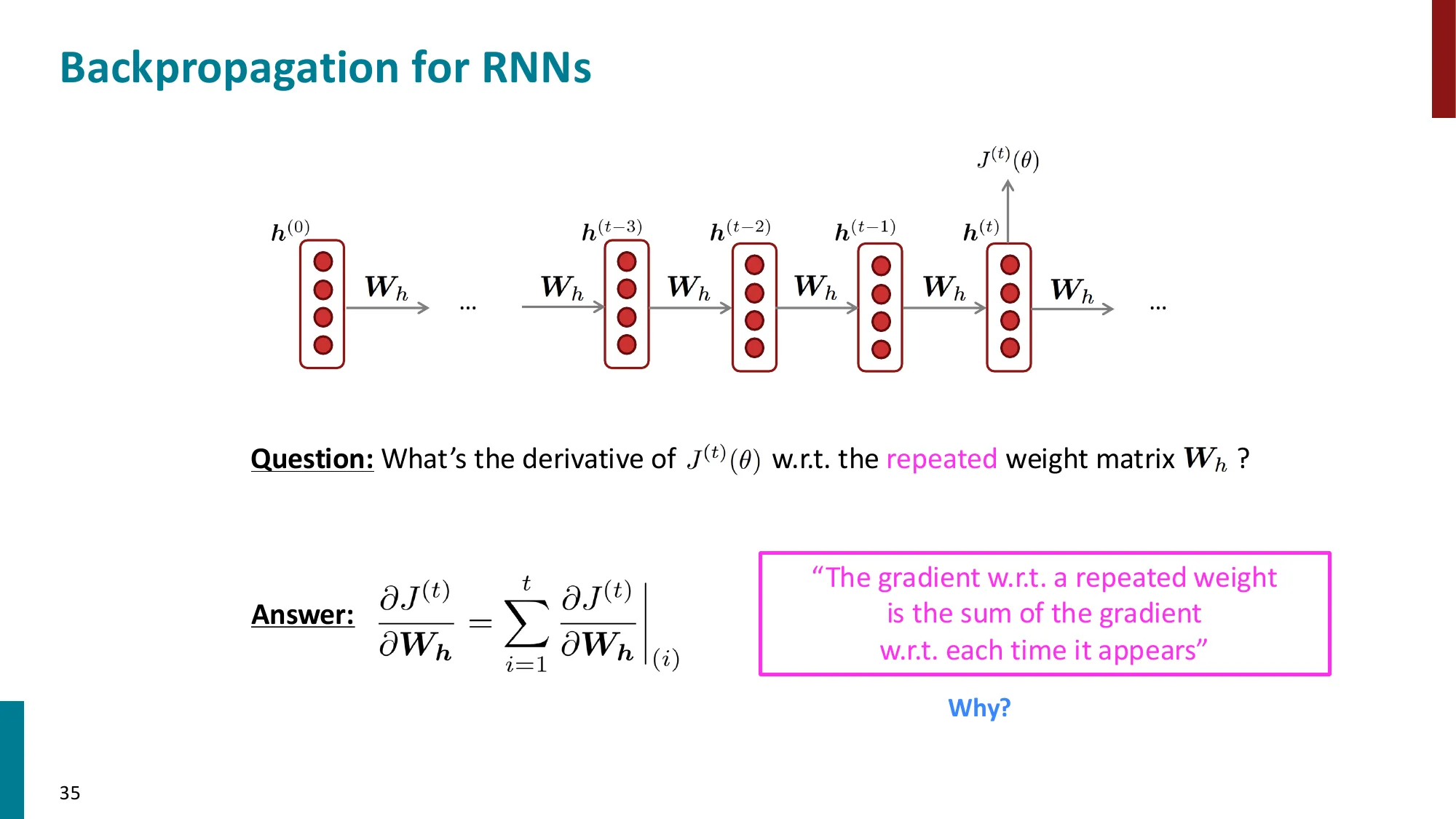
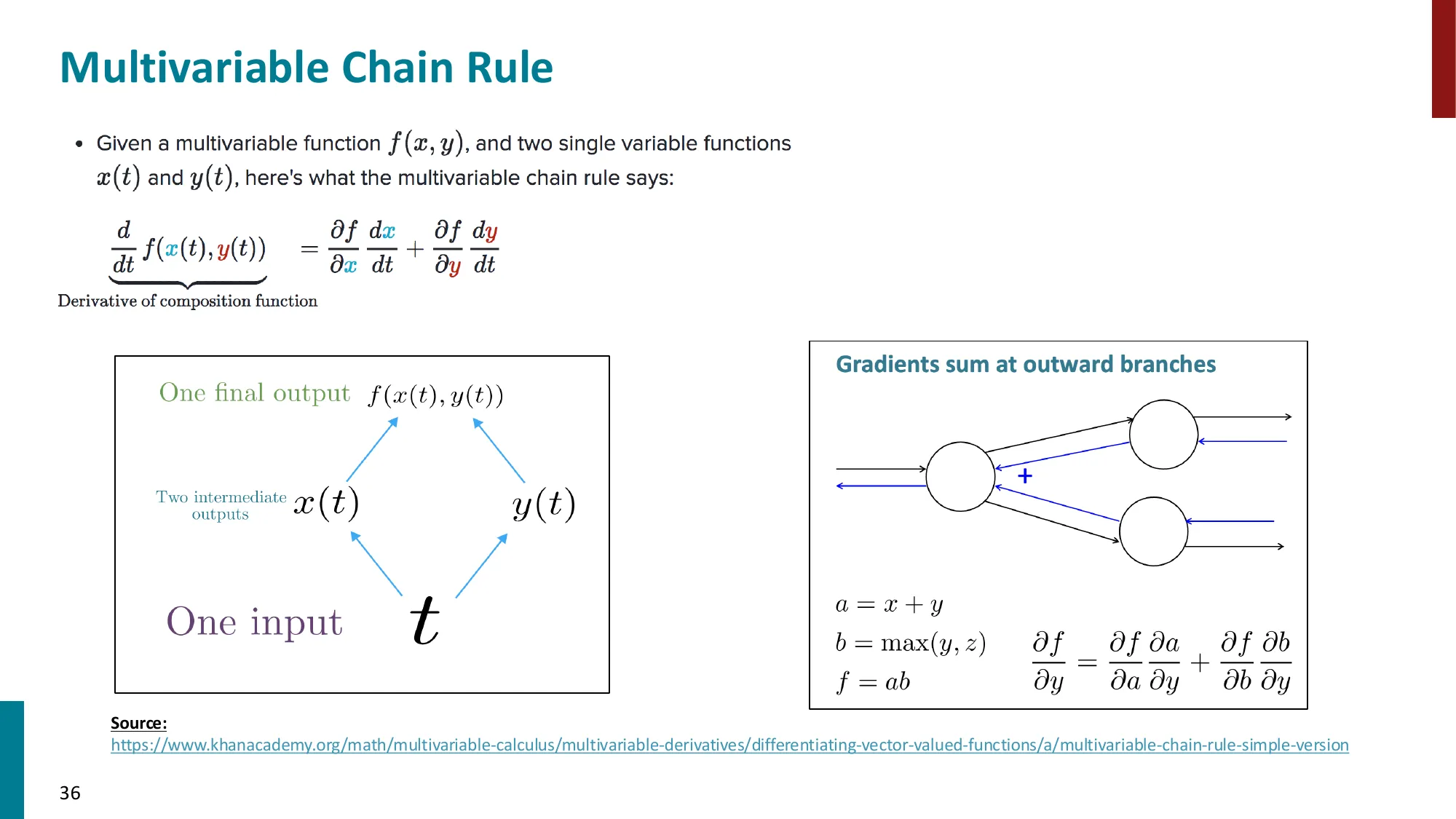
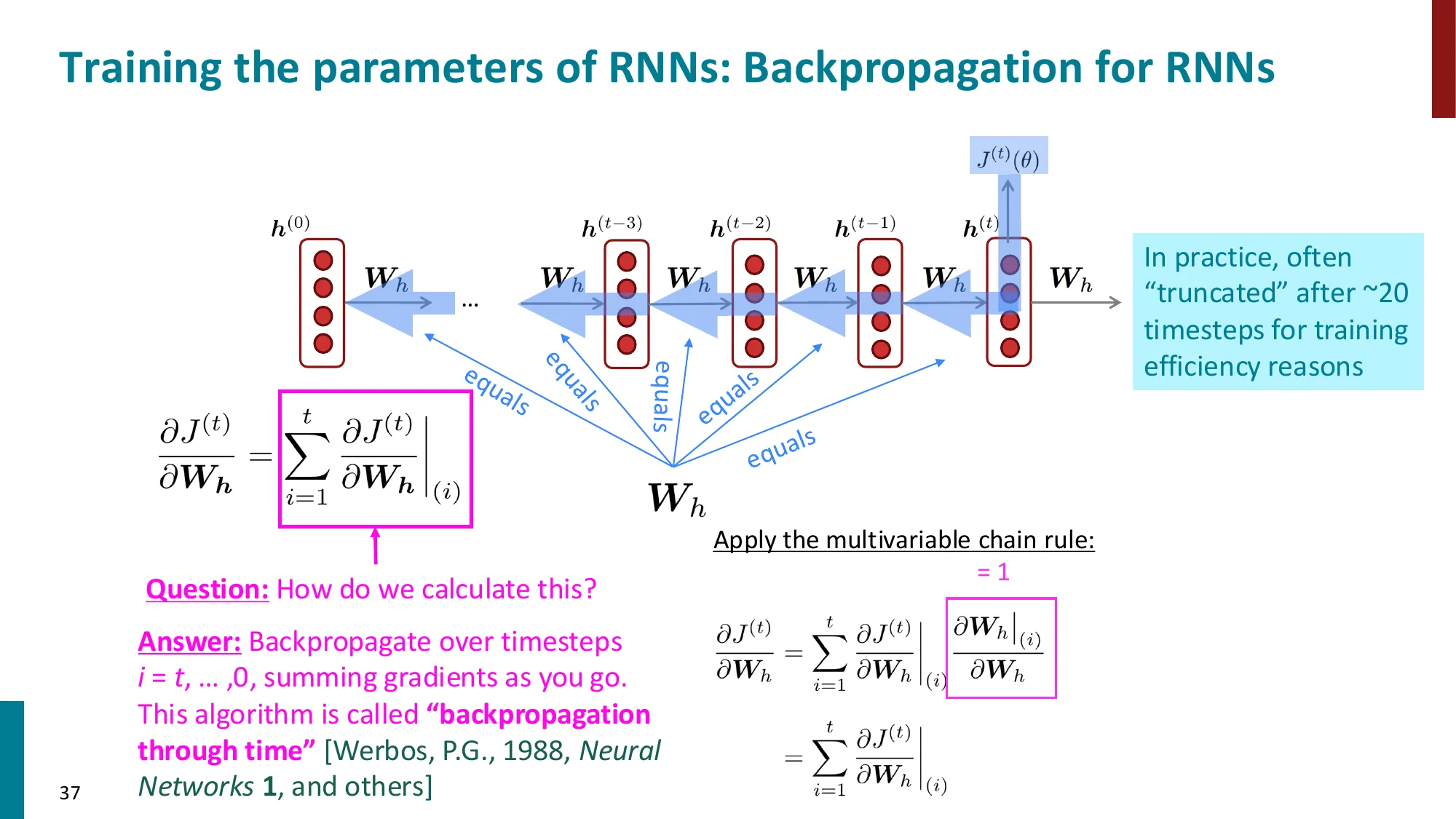
反向传播(BPTT — Backpropagation Through Time):
对 Wh 求梯度时,需要跨时间步回传:
∂Wh∂J(t)=∑k=1t∂h(t)∂J(t)⋅(∏j=k+1t∂h(j−1)∂h(j))⋅∂Wh∂h(k)
每一步的局部雅可比:∂h(j−1)∂h(j)=WhTdiag(σ′(z(j)))(其中 z(j)=Whh(j−1)+…)
📚 已收录至 拓展阅读知识库
🔢 小型 RNN 前向传播示例
设定:d=2(词向量维度),n=2(隐藏层维度),词汇表 ∣V∣=3
参数(小数值方便计算):
- Wh=[0.5000.5],Wx=[1001],bh=0
- 输入序列:x(1)=[0.8,0.2]T,x(2)=[0.3,0.7]T
计算:
- t=1:h(1)=tanh(Wh⋅0+Wx⋅x(1))=tanh([0.8,0.2]T)=[0.664,0.197]T
- t=2:z(2)=Whh(1)+Wxx(2)=[0.332+0.3,0.099+0.7]T=[0.632,0.799]T
h(2)=tanh([0.632,0.799]T)=[0.559,0.665]T
观察:h(2) 同时包含了 x(1) 和 x(2) 的信息(通过 h(1) 间接传入)。
⚠️ 常见误区
- 误区:RNN 的权重 Wh,Wx 在每个时间步都不同 → 正确:RNN 在所有时间步共享同一套权重(这是 RNN 的核心特性!)。共享权重使模型大小不随序列长度增长。
- 误区:BPTT 会计算所有历史时间步 → 正确:实践中常用”截断 BPTT(Truncated BPTT)“,只回传固定步数(如 100 步),平衡计算量和梯度信息。
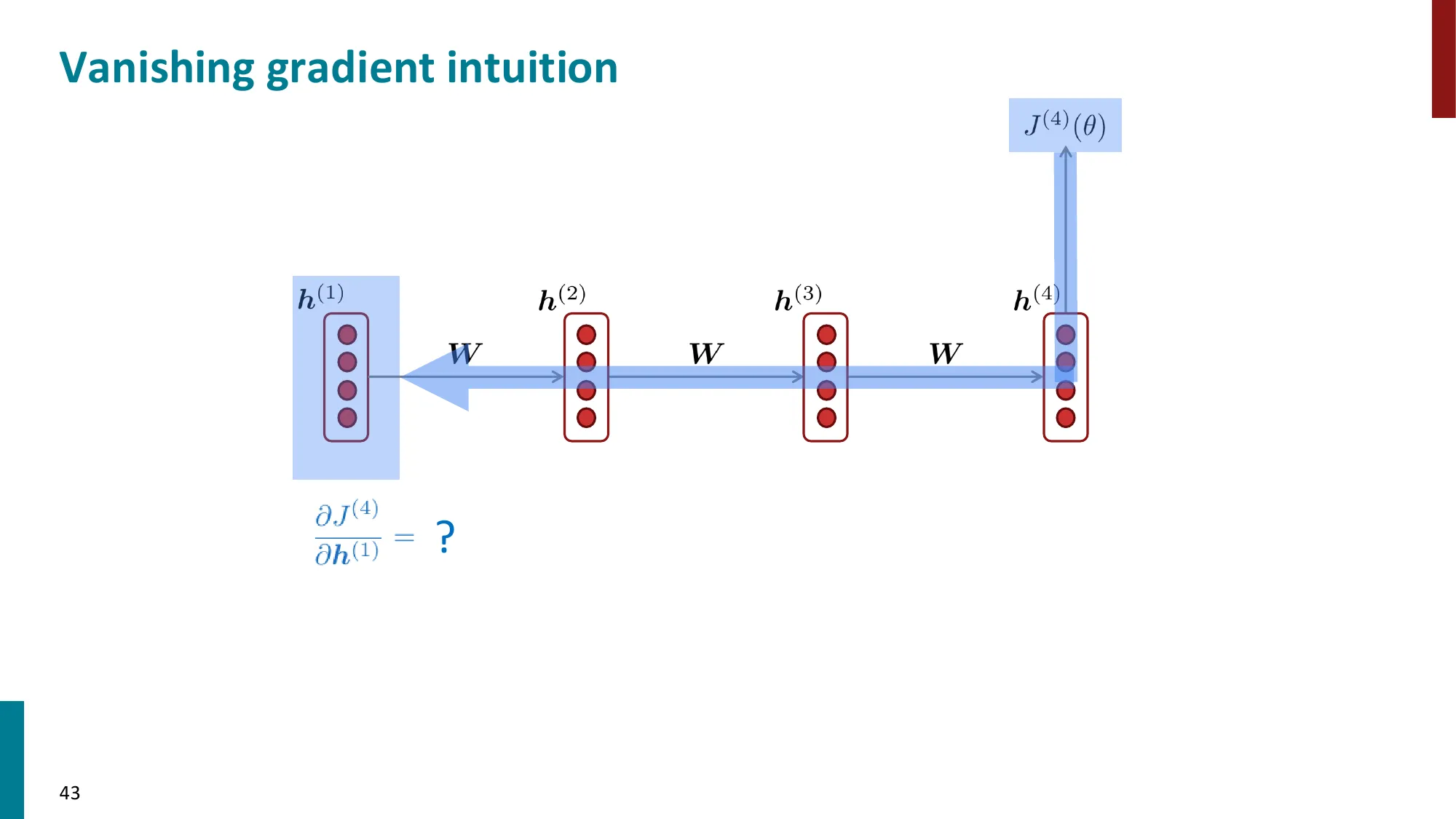
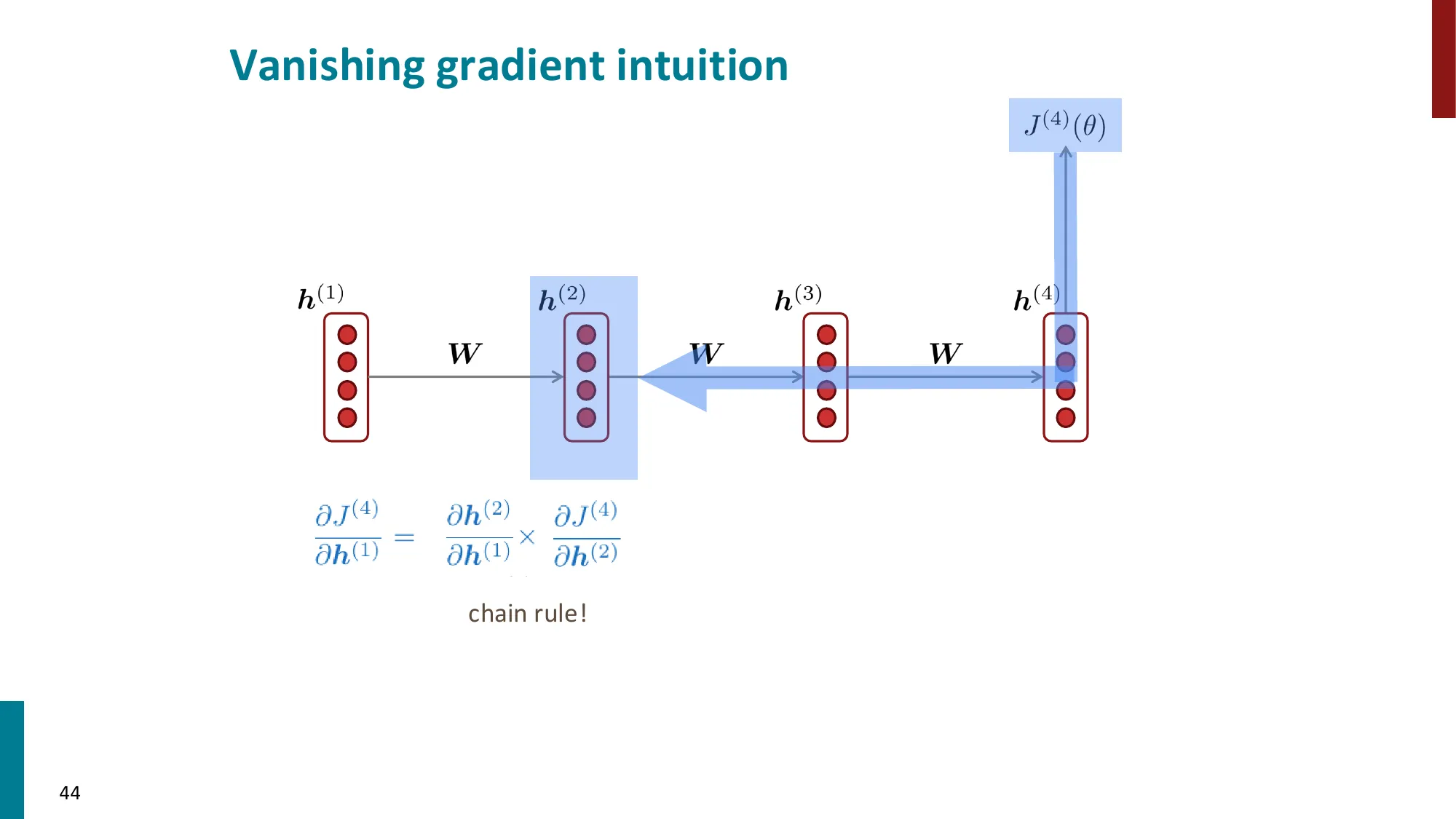
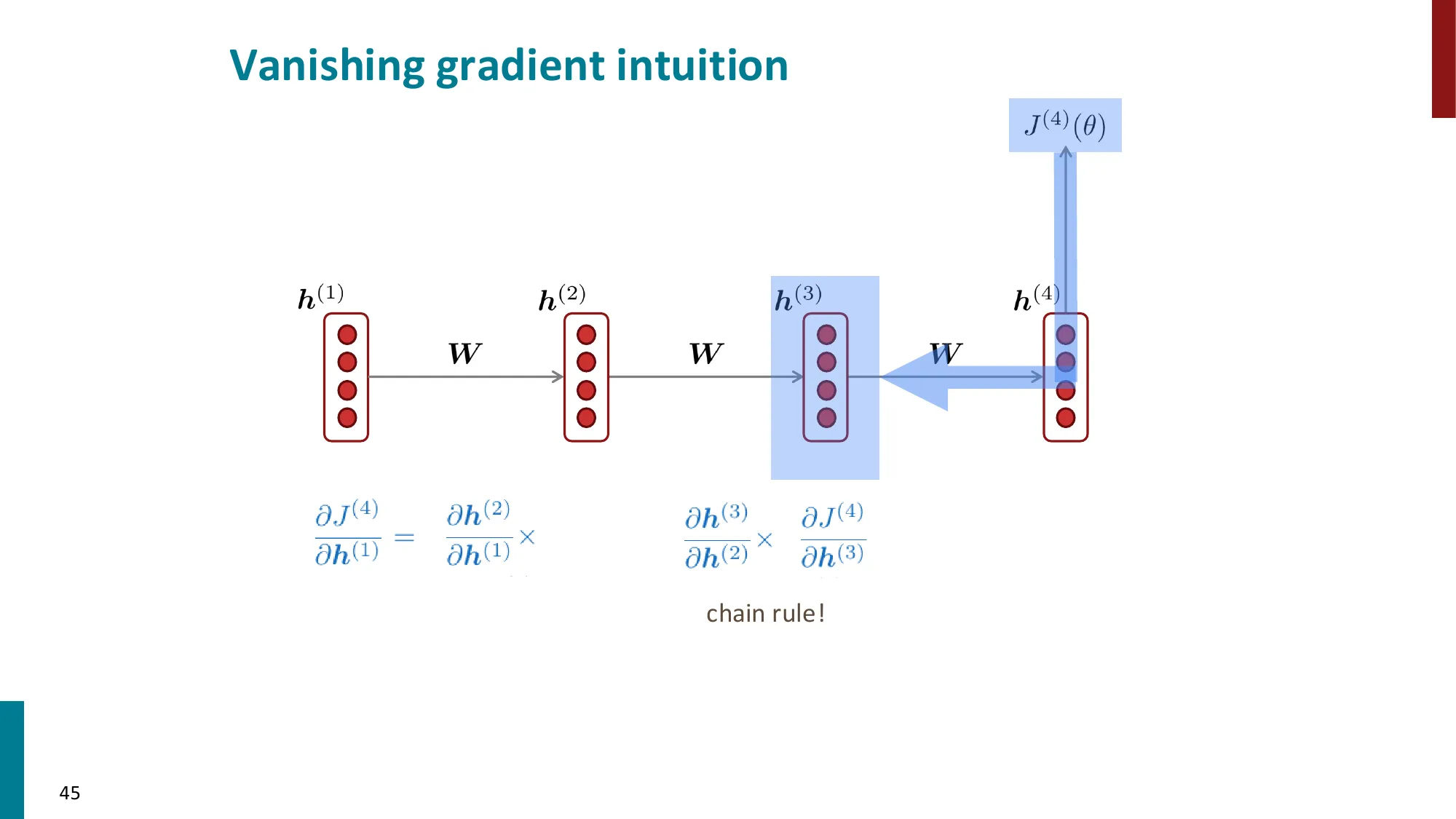
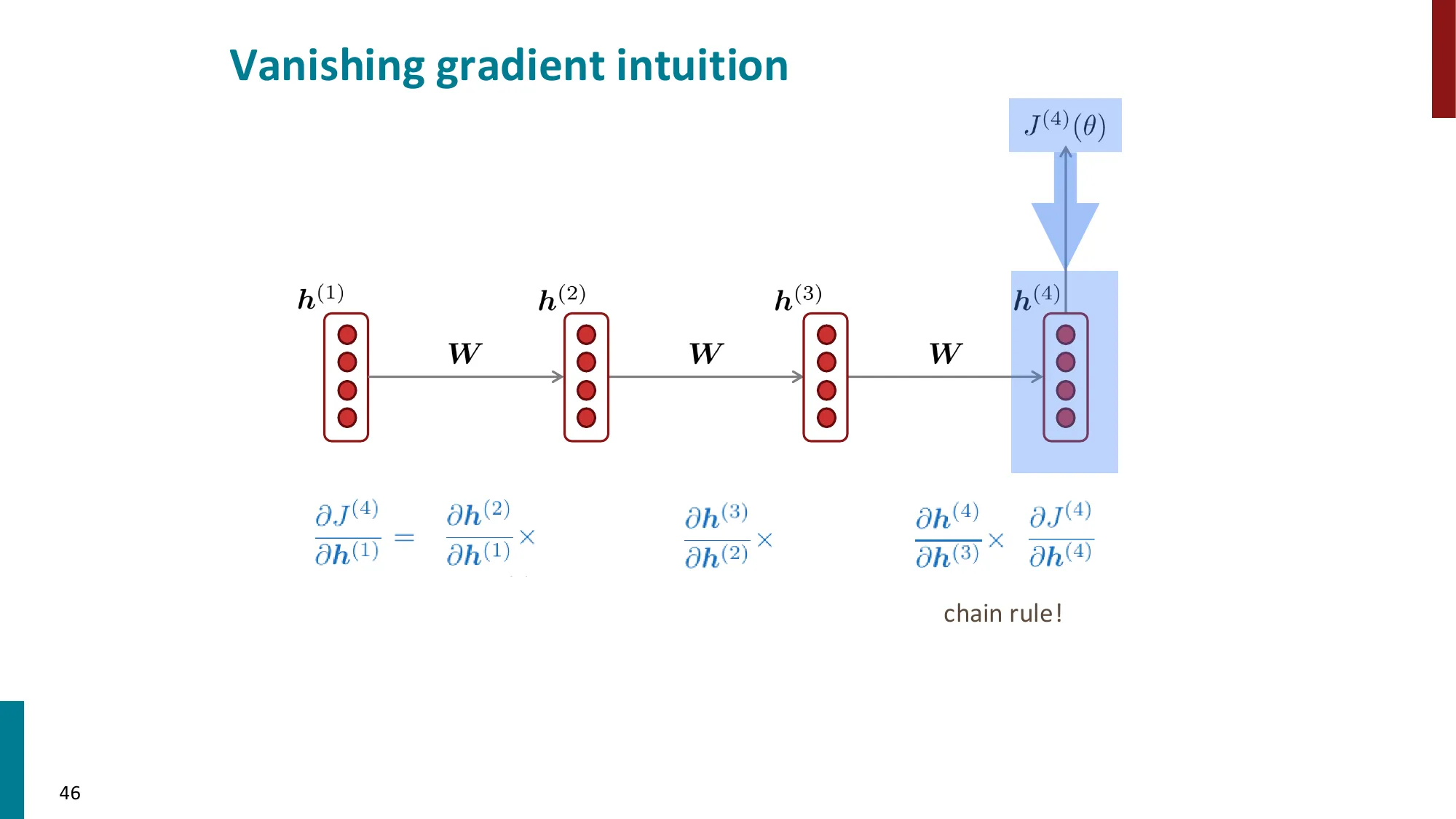
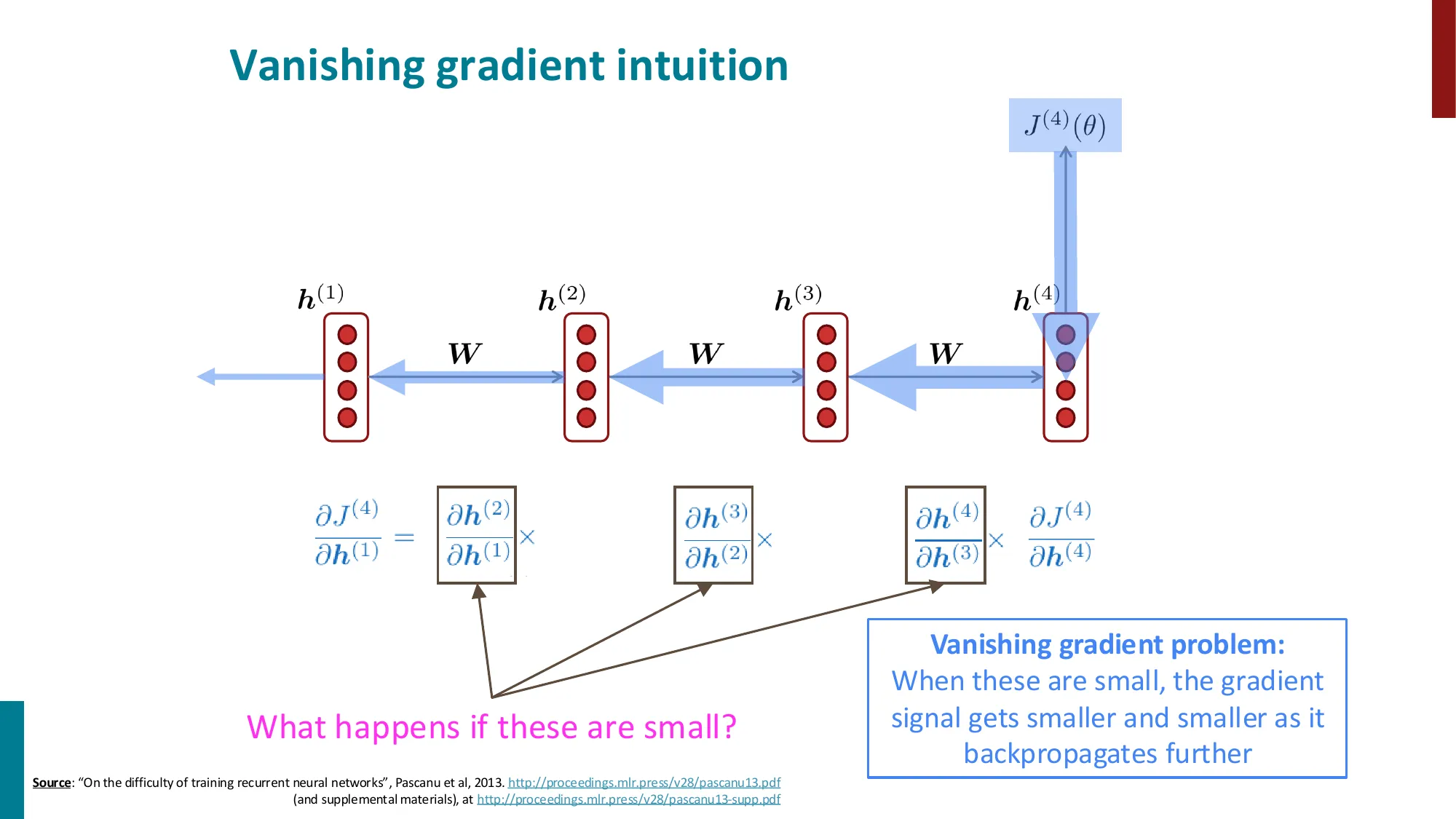
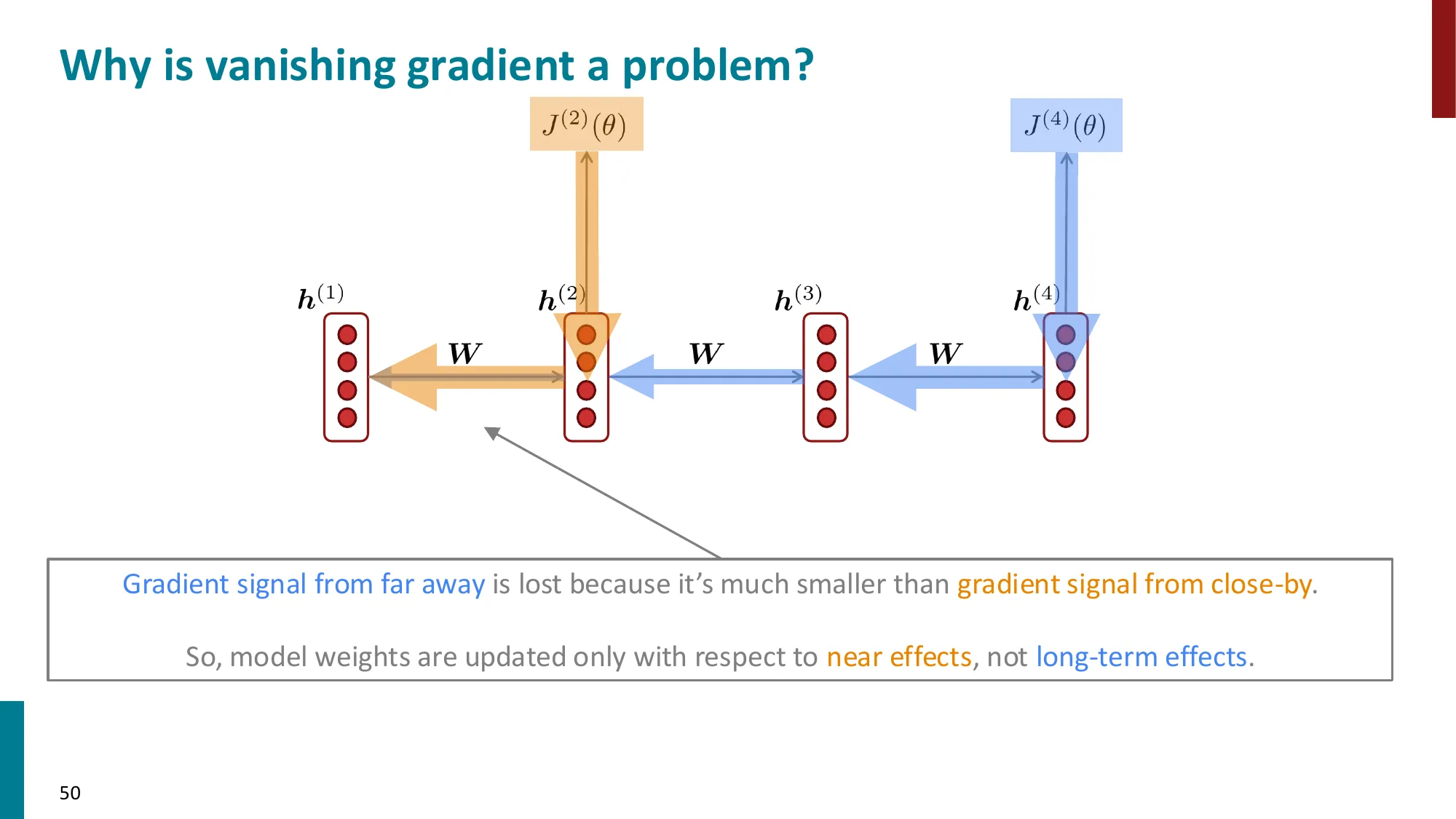
5. 梯度消失与梯度爆炸
- 梯度消失:
- ∂h(1)∂J(t)=∂h(1)∂h(2)×∂h(2)∂h(3)×⋯×∂h(t)∂J(t)
- 每一步乘以 Wh 的转置,如果特征值 < 1,连乘后趋近 0
- 结果:远距离信号丢失,模型只能学到近距离依赖
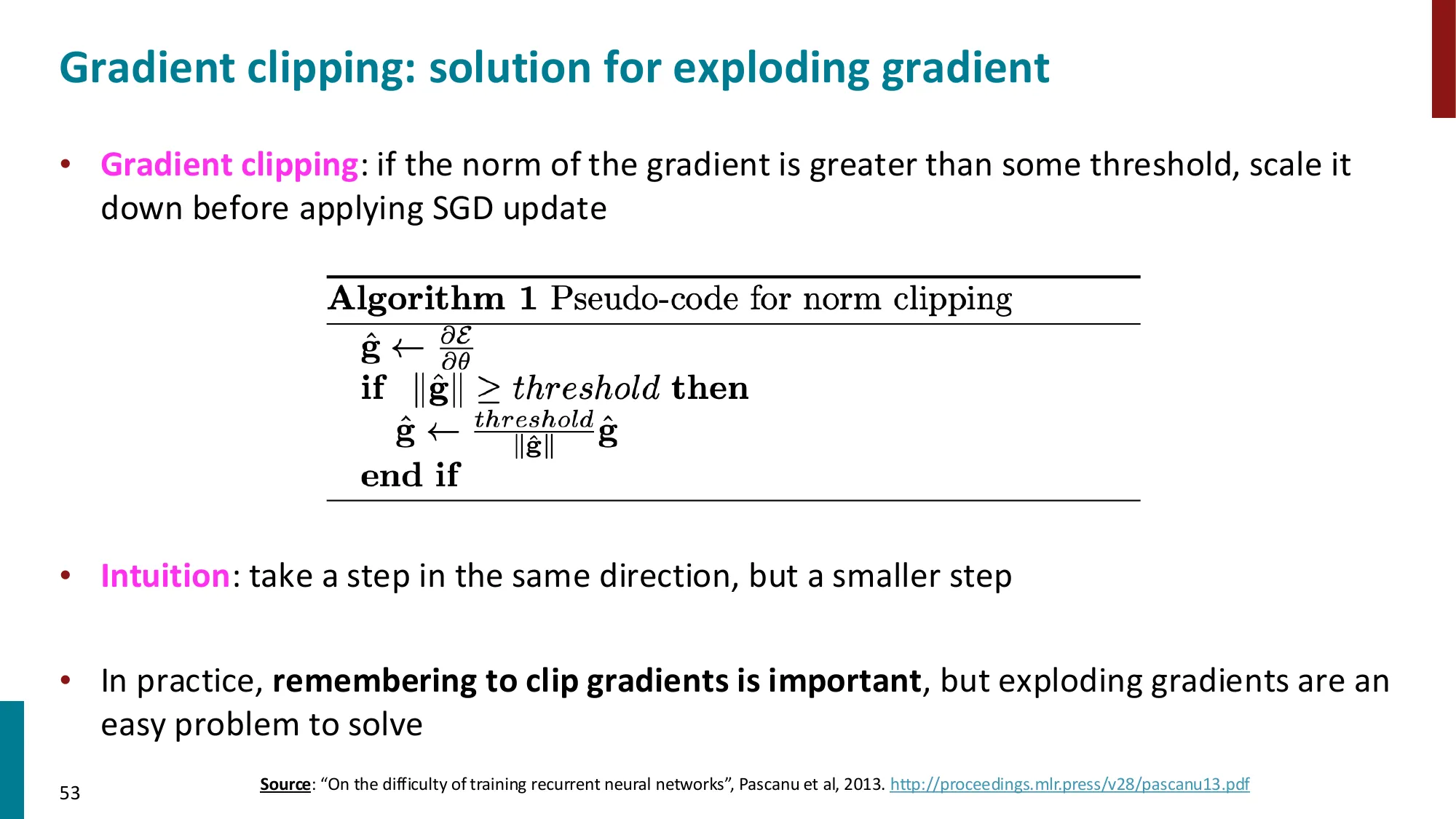
- 梯度爆炸:
- 特征值 > 1 时,梯度指数增长
- 解决方案:梯度裁剪(Gradient Clipping)
- 如果 ∥g^∥≥threshold,则 g^←∥g^∥thresholdg^
- 对 RNN-LM 的影响:无法学习长距离依赖(如 “tickets…tickets” 的跨句指代)
📐 梯度消失的数学原因
梯度链的展开(损失 J(t) 对早期隐状态 h(k) 的梯度):
∂h(k)∂J(t)=∂h(t)∂J(t)⋅∏j=k+1t∂h(j−1)∂h(j)
每一步的 Jacobian:
∂h(j−1)∂h(j)=WhT⋅diag(σ′(z(j)))
谱半径决定命运:设 WhT 的最大奇异值为 σ1,激活函数的最大导数为 γ:
- 如果 σ1γ<1:t−k 步后梯度 ∼(σ1γ)t−k→0(梯度消失)
- 如果 σ1γ>1:梯度 ∼(σ1γ)t−k→∞(梯度爆炸)
- 只有精确 =1 时梯度才稳定(实践中极难维持)
为什么激活函数导数也是关键:
- tanh′(z)=1−tanh2(z)∈(0,1],在饱和区趋向 0
- sigmoid 的导数最大值仅 0.25,梯度消失更严重
- ReLU 在 z>0 区域导数 = 1,但负值区域梯度 = 0
Gradient Clipping 只治”爆炸”:
if ∥g^∥≥threshold:g^←∥g^∥thresholdg^
这等比例缩小梯度向量,保持方向但限制大小。不能增大消失的梯度。
📚 已收录至 拓展阅读知识库
🔢 梯度消失的数值示意
标量简化:设 Wh=0.9,tanh′(z(j))=0.8(常数,简化):
每步缩减因子=0.9×0.8=0.72
| 距离(时间步数) | 梯度大小 |
|---|
| t−k=1 | 0.721=0.720 |
| t−k=5 | 0.725=0.193 |
| t−k=10 | 0.7210=0.037 |
| t−k=20 | 0.7220=0.001 |
20 步之前的信号梯度已衰减到 0.1%,实际上无法更新相关参数。
对比爆炸(Wh=1.1,σ′=1.0):
- t−k=10:1.110=2.59
- t−k=20:1.120=6.73
- t−k=50:1.150=117 → NaN
⚠️ 常见误区
- 误区:梯度消失 = 梯度为 0 → 正确:梯度消失是指数衰减,不是突然归零。距离 20 步时可能只有 0.001 的大小,小到无法驱动参数更新,但并不完全是 0。
- 误区:梯度裁剪可以防止梯度消失 → 正确:裁剪只防止爆炸(缩小过大的梯度)。防止消失需要架构改变(LSTM 的加法更新、残差连接)。
6. 解决梯度消失:LSTM
 Slide 50
Slide 50
- LSTM(Long Short-Term Memory):引入独立的记忆单元 c(t)
- 门控机制:
- 遗忘门(Forget gate):f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
- 输入门(Input gate):i(t)=σ(Wih(t−1)+Uix(t)+bi)
- 输出门(Output gate):o(t)=σ(Woh(t−1)+Uox(t)+bo)
- 记忆更新:c(t)=f(t)⊙c(t−1)+i(t)⊙c~(t)
- 隐状态:h(t)=o(t)⊙tanh(c(t))
- 关键:记忆单元的加法更新(而非乘法)使梯度更容易流过长序列
- 其他方案:GRU(更简化的门控)、残差连接、注意力机制
📐 LSTM 完整推导——为什么门控能缓解梯度消失?
LSTM 的核心区别:引入记忆单元(cell state) c(t),通过加法更新而非乘法更新传递信息。
所有门的计算(共 4 个):
ifoc~(t)=σσσtanh(W[h(t−1)x(t)]+b)
展开为:
- 遗忘门:f(t)=σ(Wf[h(t−1),x(t)]+bf)∈(0,1)n
- 输入门:i(t)=σ(Wi[h(t−1),x(t)]+bi)∈(0,1)n
- 候选记忆:c~(t)=tanh(Wc[h(t−1),x(t)]+bc)∈(−1,1)n
- 输出门:o(t)=σ(Wo[h(t−1),x(t)]+bo)∈(0,1)n
记忆单元(加法更新——关键!):
c(t)=f(t)⊙c(t−1)+i(t)⊙c~(t)
隐状态(输出):
h(t)=o(t)⊙tanh(c(t))
为什么加法更新能缓解梯度消失?
c(t) 对 c(t−1) 的梯度:
∂c(t−1)∂c(t)=f(t)
(忽略高阶项)。这是逐元素乘以遗忘门,而不是乘以大矩阵!
对比标准 RNN 的 ∂h(t−1)∂h(t)=WhTdiag(σ′)(矩阵乘法,连乘后快速衰减)。
如果遗忘门 f(t)≈1(不遗忘),梯度 ≈ 1,不消失也不爆炸。这类似于 ResNet 的残差连接!
📚 已收录至 拓展阅读知识库
🔢 LSTM 一步更新数值示例
设定:n=2(隐藏维度),当前状态:
- h(t−1)=[0.5,−0.3]T,c(t−1)=[0.8,0.2]T
- 输入 x(t)=[1.0,0.0]T
假设(为简化,直接给出门的激活值):
- f(t)=[0.9,0.8]T(遗忘大部分记忆)
- i(t)=[0.7,0.4]T(写入部分新信息)
- c~(t)=[0.6,−0.5]T(候选新记忆)
- o(t)=[0.6,0.7]T(输出多少到隐状态)
计算:
-
新记忆:c(t)=f⊙c(t−1)+i⊙c~
=[0.9×0.8,0.8×0.2]+[0.7×0.6,0.4×(−0.5)]
=[0.72,0.16]+[0.42,−0.20]=[1.14,−0.04]
-
新隐状态:h(t)=o⊙tanh(c(t))
tanh([1.14,−0.04])=[0.817,−0.040]
h(t)=[0.6×0.817,0.7×(−0.040)]=[0.490,−0.028]
观察:遗忘门 f=0.9(几乎保留过去记忆),输入门写入新信息,输出门控制最终输出。
⚠️ 常见误区
- 误区:LSTM 完全解决了梯度消失 → 正确:LSTM 大幅缓解梯度消失(通过记忆单元的加法路径),但并不完全消除。在极长序列(数千步)上仍然困难。Transformer 通过注意力机制进一步解决这个问题。
- 误区:遗忘门为 0 = 清除所有记忆 → 正确:f=0 时 c(t)=i⊙c~(t),完全丢弃过去记忆,完全用新信息。f=1 时完全保留记忆(加法更新不改变 c)。中间值 = 部分遗忘。
- 误区:LSTM 有 4 组权重矩阵,参数是 RNN 的 4 倍 → 正确:可以将 4 个门的权重矩阵拼为一个大矩阵 W∈R4n×(n+d),一次矩阵乘法完成所有门的计算(更高效)。
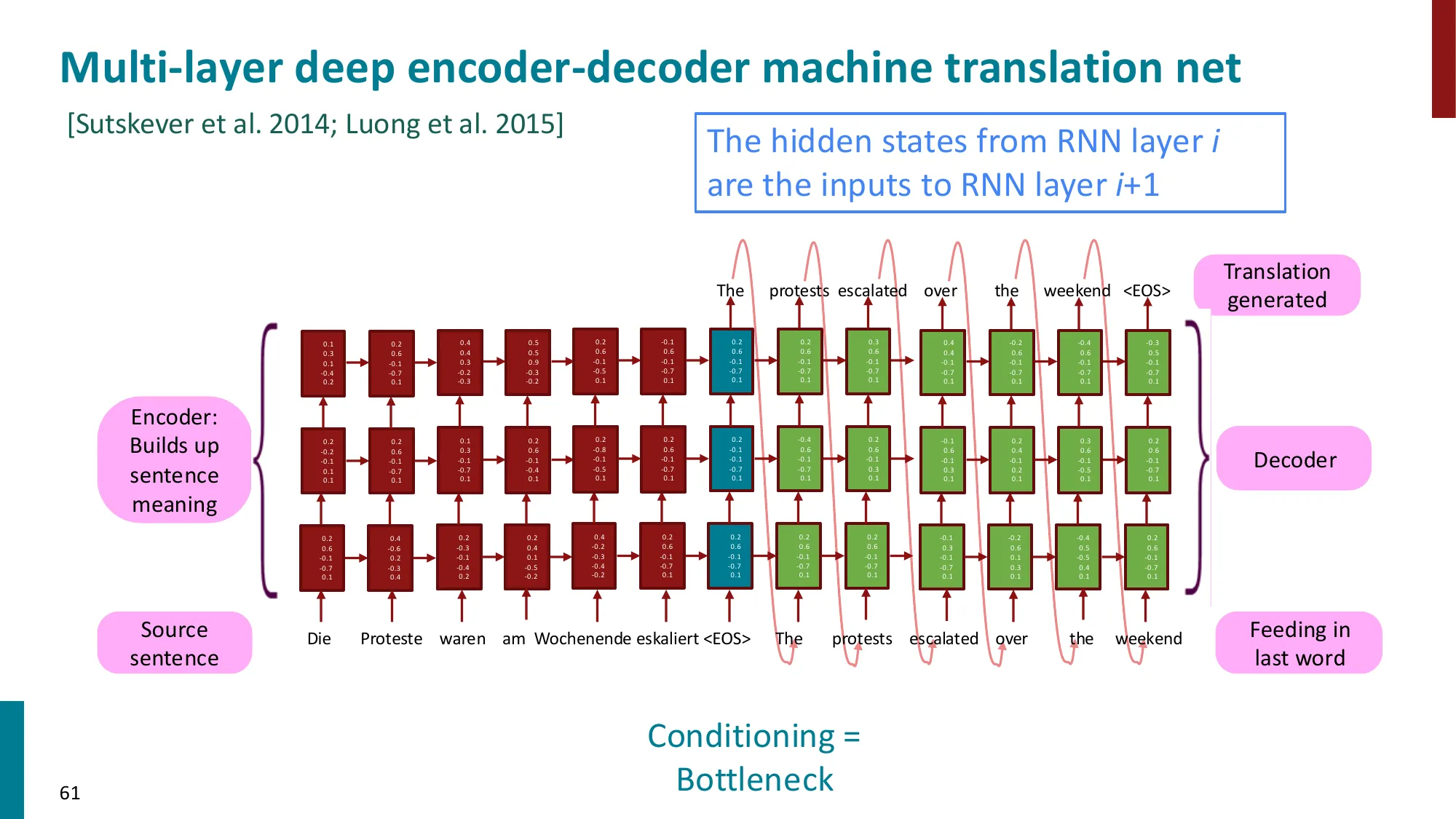
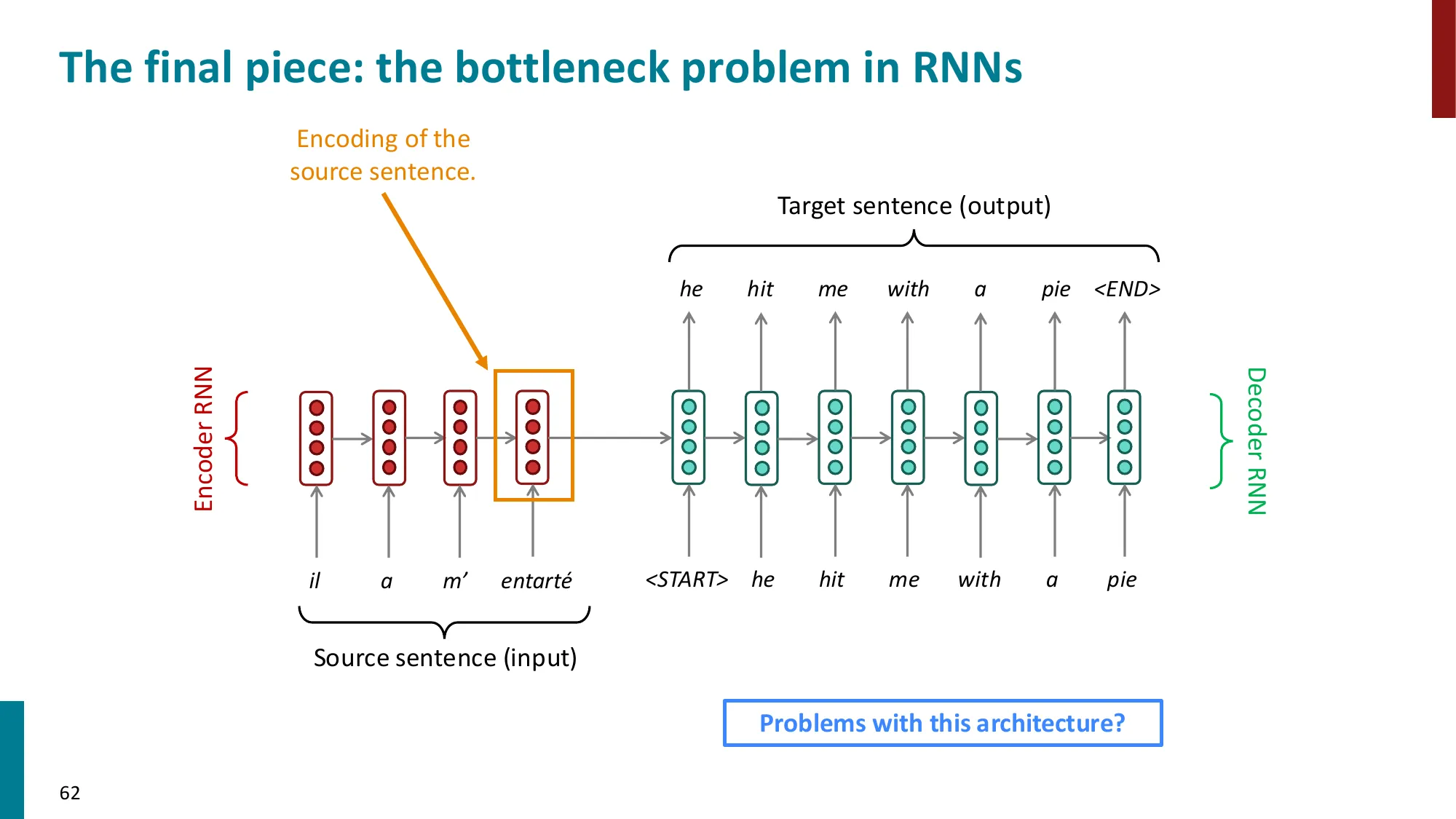
7. 机器翻译简介
- 从源语言 x 到目标语言 y 的翻译
- NMT 的成功:2014 年 seq2seq 首篇论文 → 2016 年 Google 全面替换 SMT
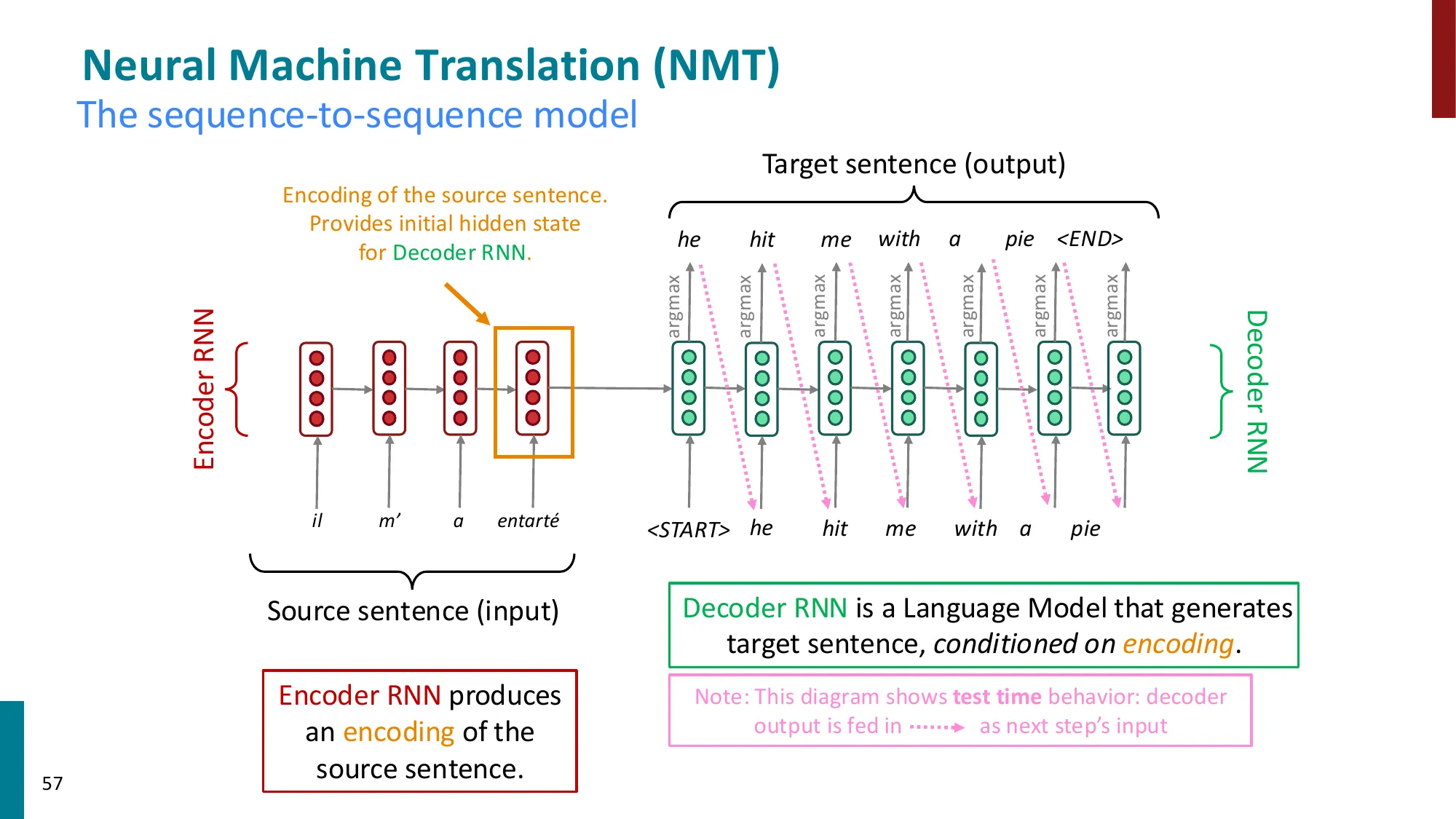
- Encoder-Decoder 架构:
- Encoder RNN 编码源句 → 上下文向量
- Decoder RNN 以此为条件生成目标句
- 条件语言模型:P(y∣x)=P(y1∣x)P(y2∣y1,x)⋯P(yT∣y1,…,yT−1,x)
📐 条件语言模型的训练目标
目标:最大化给定源句 x 时,目标句 y 的对数似然:
L=∑(x,y)∈datalogP(y∣x;θ)=∑(x,y)∑t=1∣y∣logP(yt∣y<t,x;θ)
Encoder-Decoder 分解:
- Encoder:henc=RNN(x1,…,xm),最终状态 henc(m) 作为初始 decoder 状态
- Decoder:hdec(t)=RNN(yt−1,hdec(t−1)),P(yt∣…)=softmax(Whdec(t))
瓶颈问题的数学表现:
- 整个源句 x1,…,xm 被压缩为一个向量 henc(m)∈Rn(固定维度)
- 无论源句多长(m=5 还是 m=100),都要压缩到同样大小的向量
- 信息论:固定容量的”瓶颈”对长句信息损失严重
解决方案(引出注意力):让 decoder 在每一步直接访问所有 encoder 隐状态 {henc(1),…,henc(m)},而非只用最后一个状态。
📚 已收录至 拓展阅读知识库
🔗 知识关联
- → L05 注意力机制:本节的瓶颈问题直接引发了注意力机制的发明(Bahdanau et al., 2015)
- → L05 Transformer:完全放弃 RNN,改用自注意力解决长距离依赖问题
- ← L03 反向传播:BPTT 是 L03 中讲的计算图反向传播在序列上的应用
- ← L02 Word2Vec:RNN-LM 的输入是词嵌入,与 L02 中的词向量直接对接
⚠️ 常见误区
- 误区:Seq2Seq 中 encoder 和 decoder 不共享权重 → 正确:这是设计选择,有些模型共享,有些不共享。通常 encoder 和 decoder 是不同的 RNN(不同参数)。
- 误区:Teacher forcing = 作弊 → 正确:Teacher forcing(训练时用真实目标词作为 decoder 输入,而非上一步预测词)是训练的标准方法,虽然会造成”暴露偏差”(训练 vs 推理时的分布差异),但实践中效果好。
推荐阅读
关联概念
作业提醒
个人笔记