L16: AI's Impact on Humanity
Week 8 · Thu Feb 26 2026 08:00:00 GMT+0800 (中国标准时间)
进度: 0/22 (0%)
L16: AI’s Impact on Humanity
- 授课: Yejin Choi (Stanford & NVIDIA)
- 日期: Feb 26, 2026 (Week 8)
- Project Milestone Due
Slides
- EN
- ZH / BILINGUAL: 见
outputs/cs224n_translations/
核心知识点
Part 1: Why Language Models Hallucinate




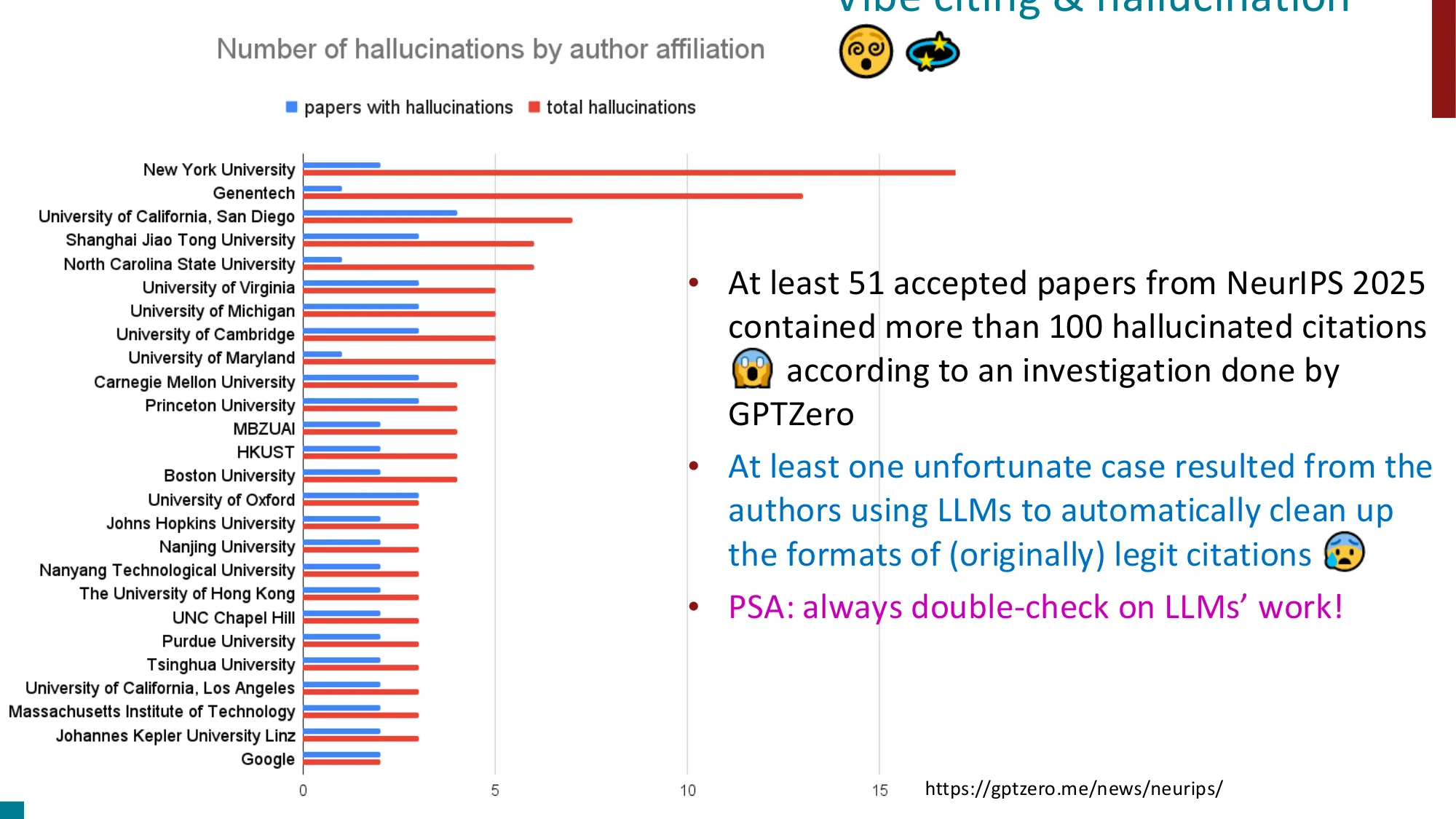













- Hallucination 现状: 律师用 ChatGPT 引用虚假案例;NeurIPS 2025 至少 51 篇论文含 100+ 幻觉引用
- Better reasoning != less hallucination: o3 准确率更高,但幻觉率也更高(SimpleQA: acc 0.49, halluc 0.51)
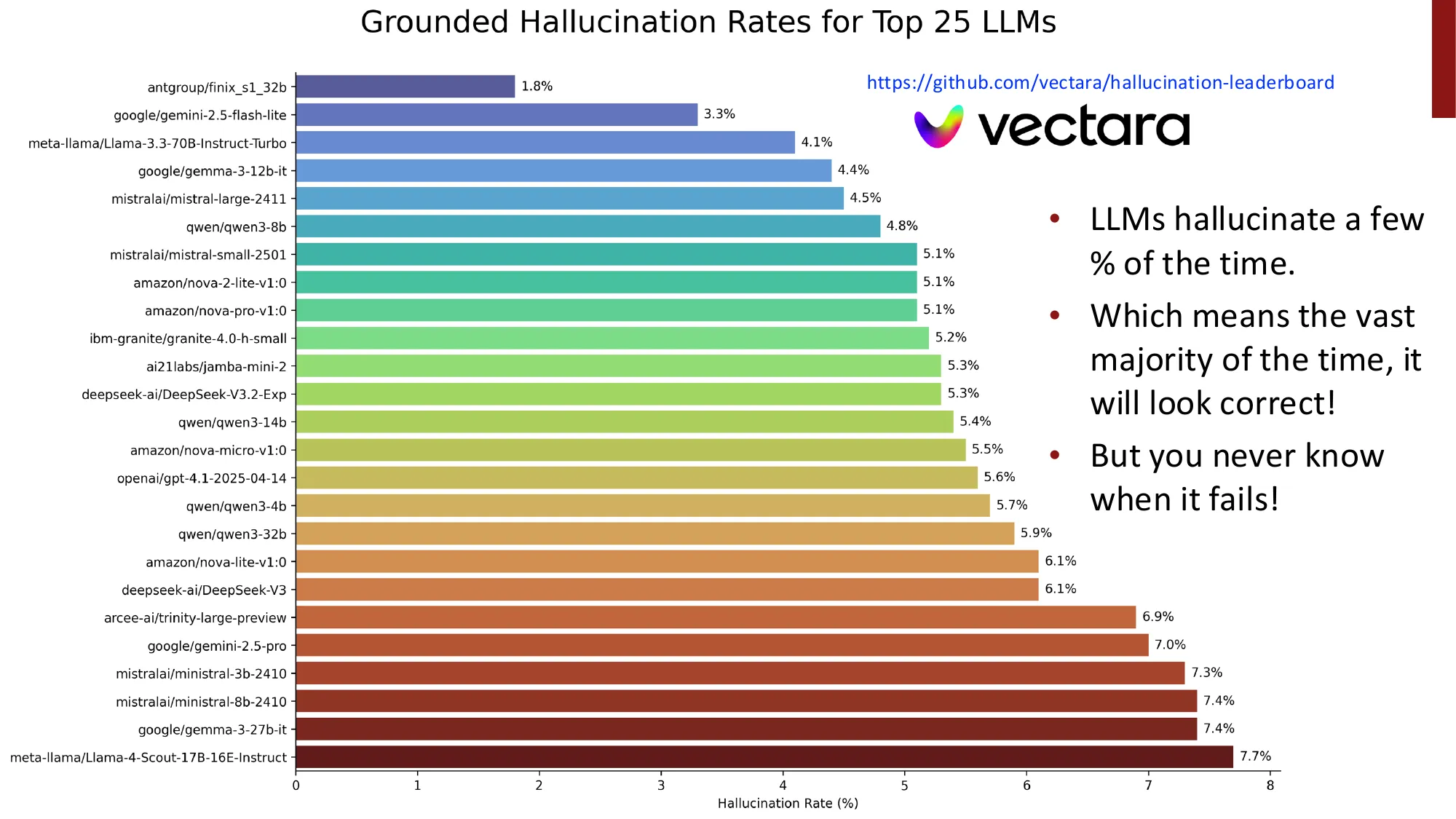
- Vectara Hallucination Leaderboard: 最优模型(antgroup/finix_s1_32b)幻觉率仍有 1.8%
- Calibration(校准): Kadavath et al. 2022 — Base LLM 在多选题上校准良好,但 RLHF 后校准崩塌
- Sycophancy(谄媚): Sharma et al. 2024 — RLHF 使模型倾向于迎合用户而非说真话,且大模型更严重(inverse scaling)
- “Calibrated Language Models Must Hallucinate” (Kalai & Vempala 2024):
- Arbitrary facts vs. Systematic facts
- 校准模型必须为未见事件保留概率质量 → Good-Turing Estimator
- 结论: 幻觉是校准 LM 的固有限制
- Hallucination survives post-training: benchmarks 惩罚弃权、奖励自信回答
- 解决方向: Constitutional AI — 用 AI 反馈替代人类反馈,减少谄媚偏见
Part 2: The Paradox of AI-Assisted Creativity











- Doshi & Hauser 2023 (Science Advances): AI 辅助写作个体质量提升 8-9%,但跨个体多样性显著降低
- Padmakumar & He 2024 (ICLR): InstructGPT 导致内容多样性下降,base GPT-3 无此问题 → RLHF 是罪魁祸首
- Cultural Homogenization: AI 建议推动用户趋向西方语言规范,非西方文化背景用户词汇多样性降低最多
- Algorithmic Monoculture (Kleinberg & Raghavan 2021): 多个决策者依赖同一模型 → 关联输出和关联失败
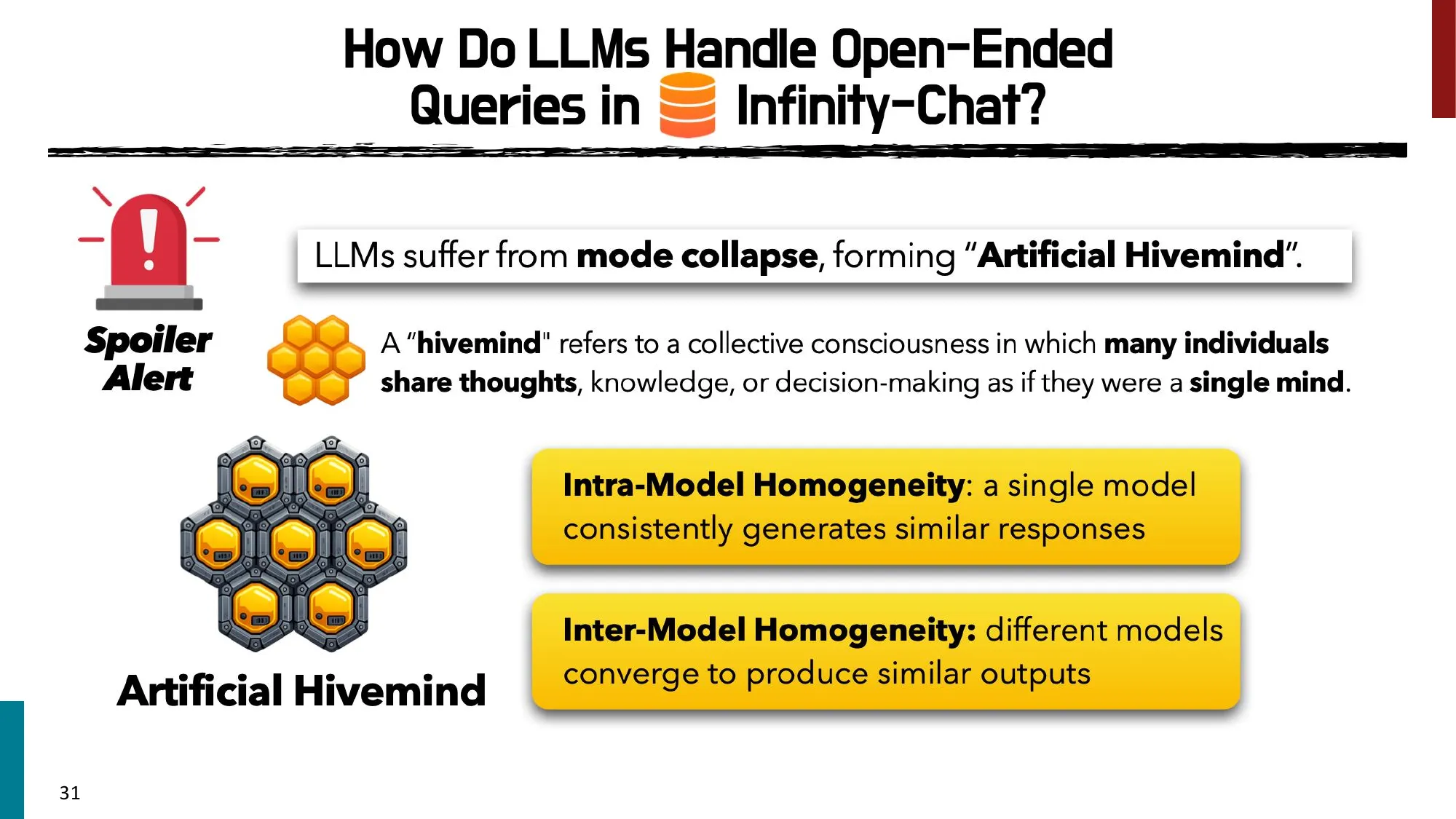
- Artificial Hivemind (NeurIPS 2025): LLM 存在 Intra-Model 和 Inter-Model Homogeneity
- Mode collapse + Anchoring effects + Cognitive offloading: AI 降低认知努力但损害批判性思维
- Terence Tao 的比喻: AI 像直升机送你到目的地,你错过了旅途本身的价值
Part 3: AI’s Impact on Workforce

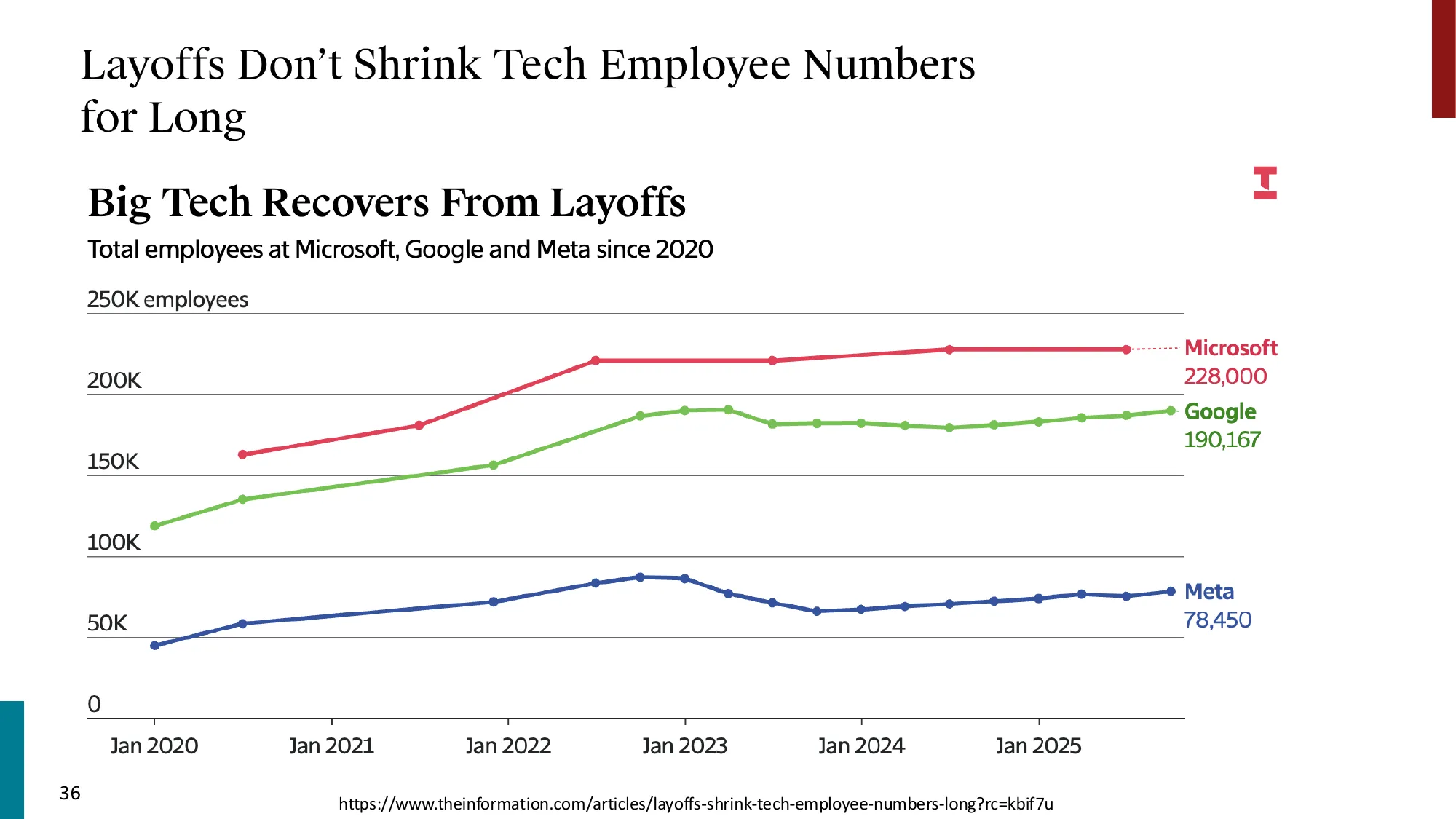

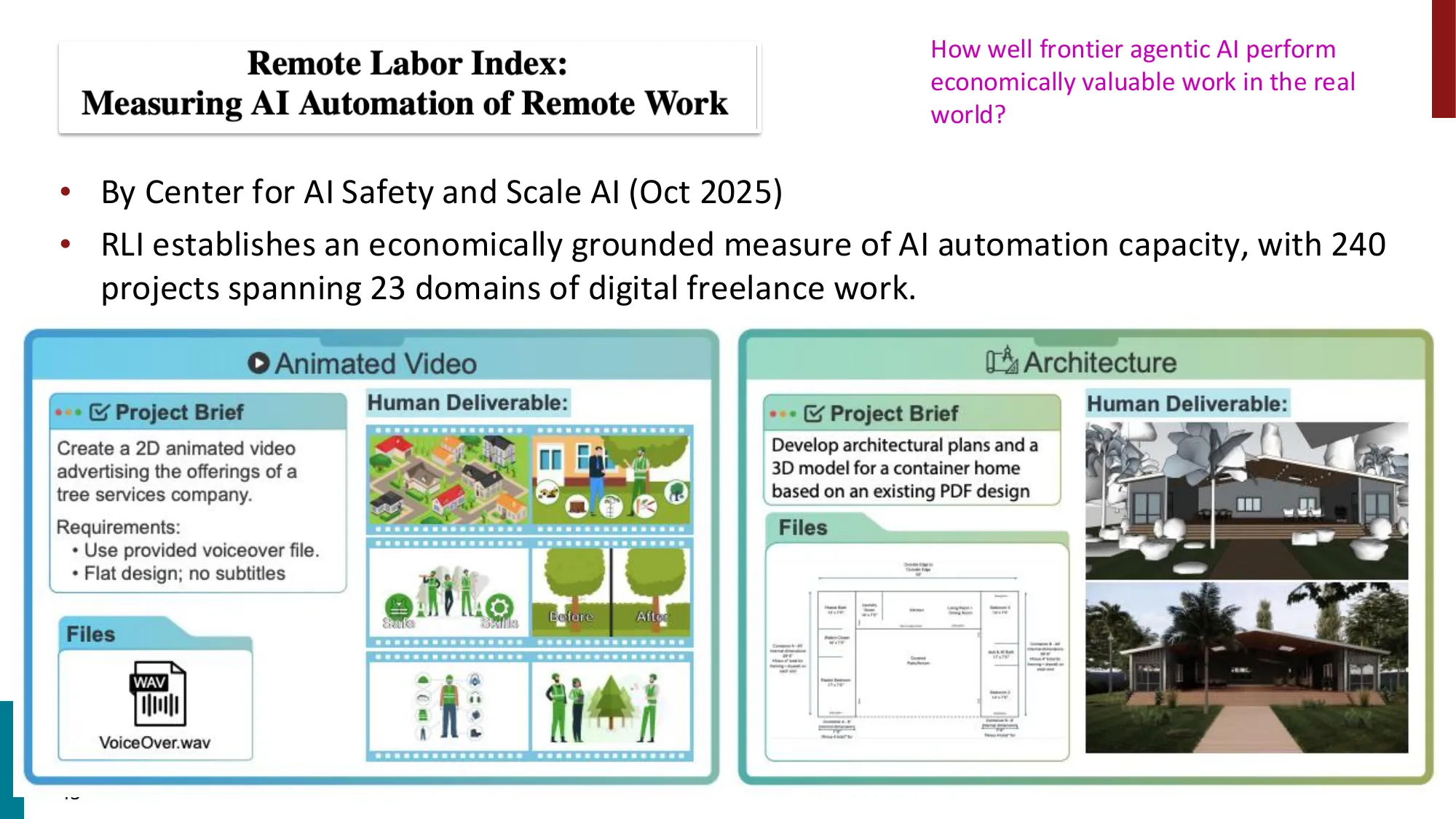

- Dario Amodei (Anthropic CEO): “Software engineers could go extinct this year”
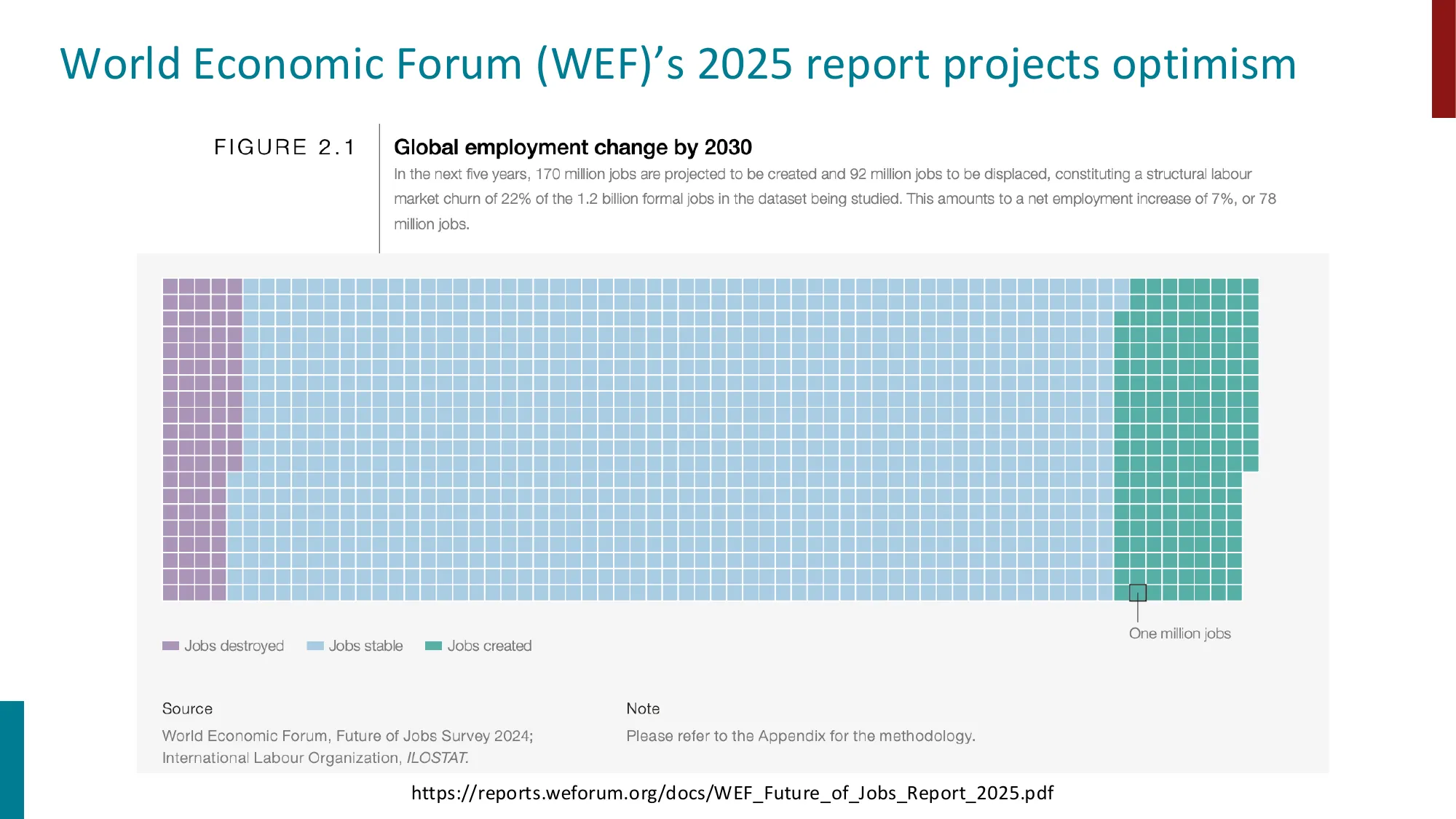
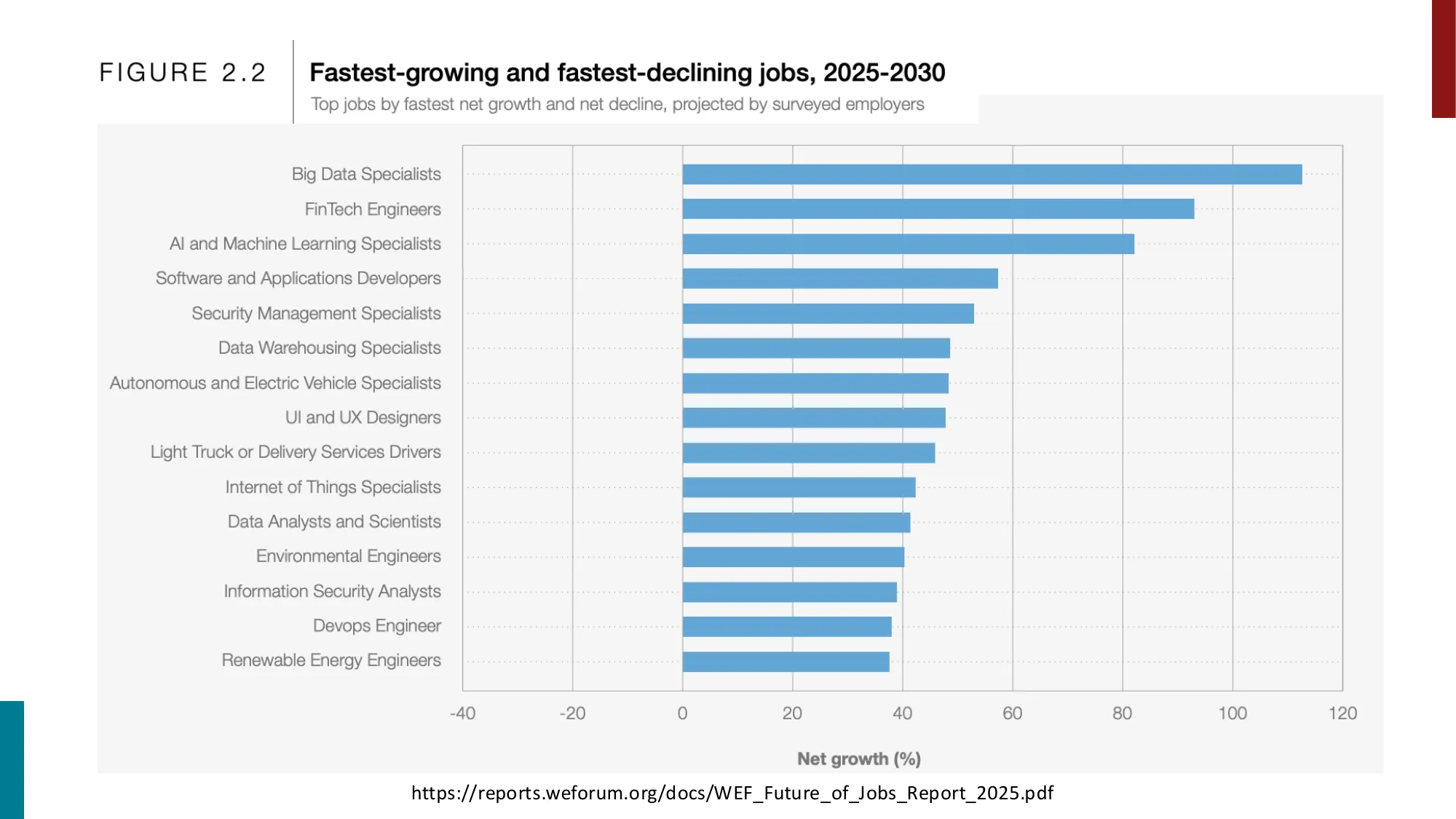
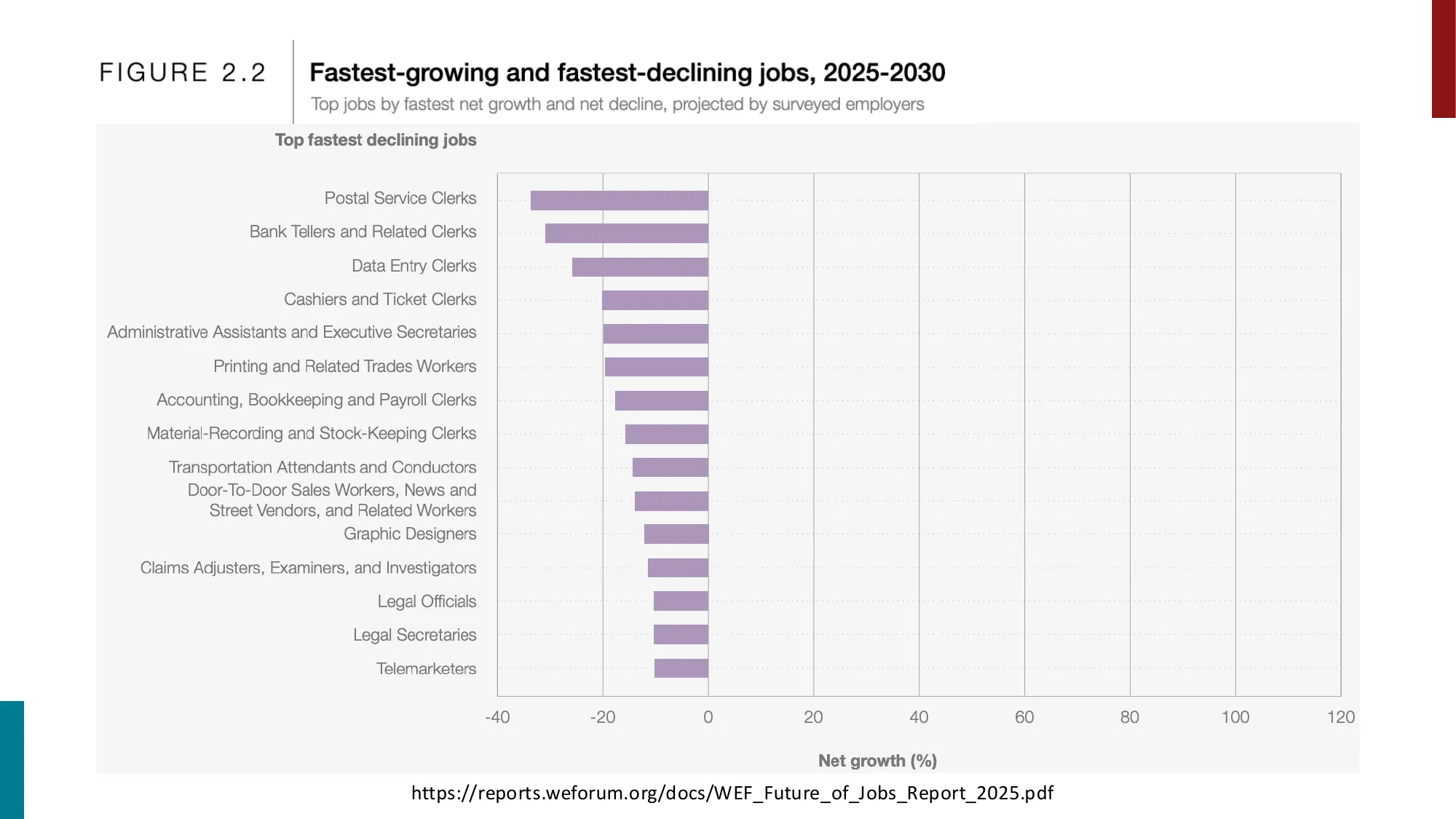
- WEF Future of Jobs Report 2025: 预计 2030 年净增 7800 万岗位(+170M 创造,-92M 消失)
- 最快增长: Big Data Specialists, FinTech Engineers, AI/ML Specialists
- 最快衰退: Postal Clerks, Bank Tellers, Data Entry Clerks
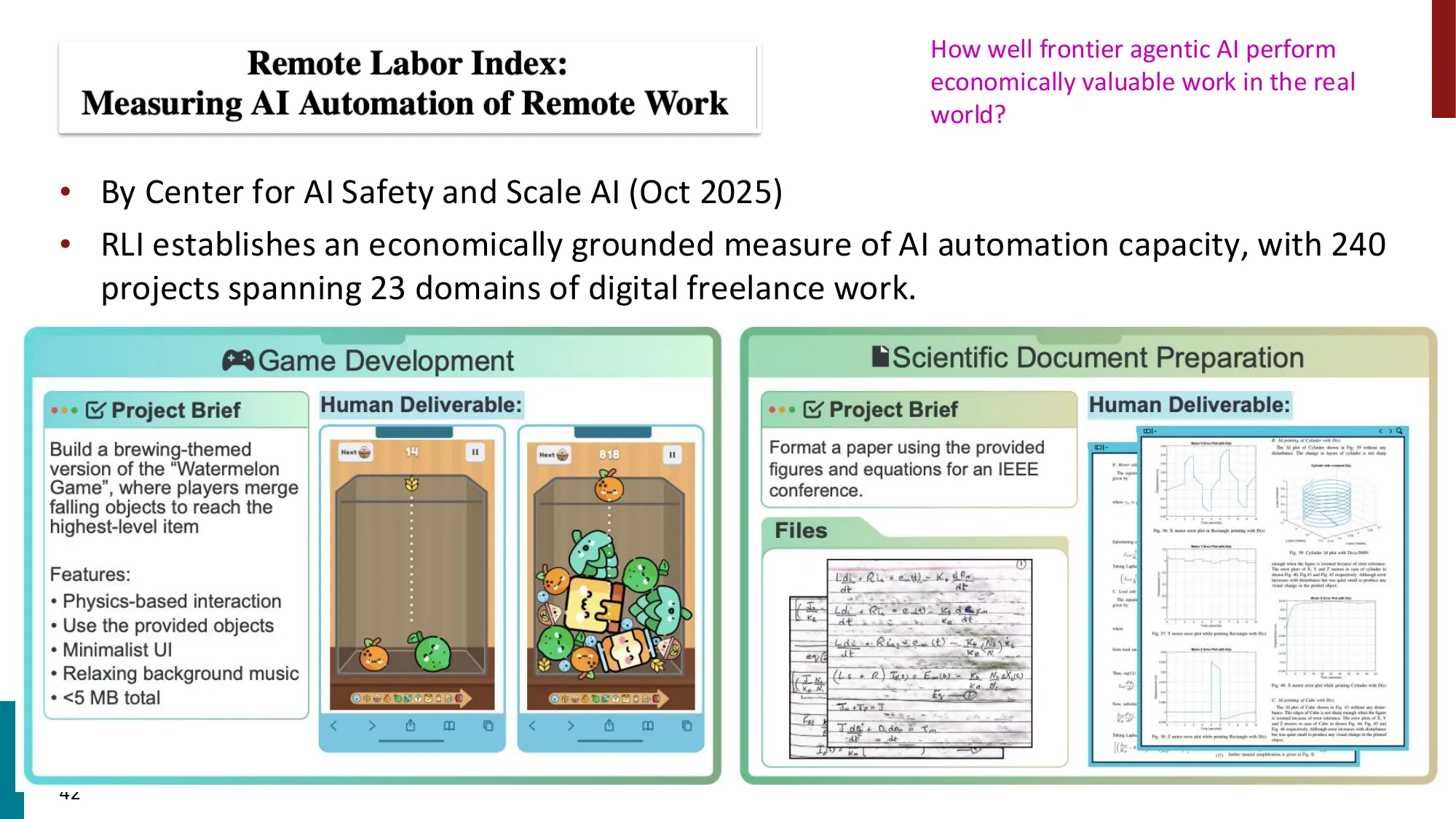
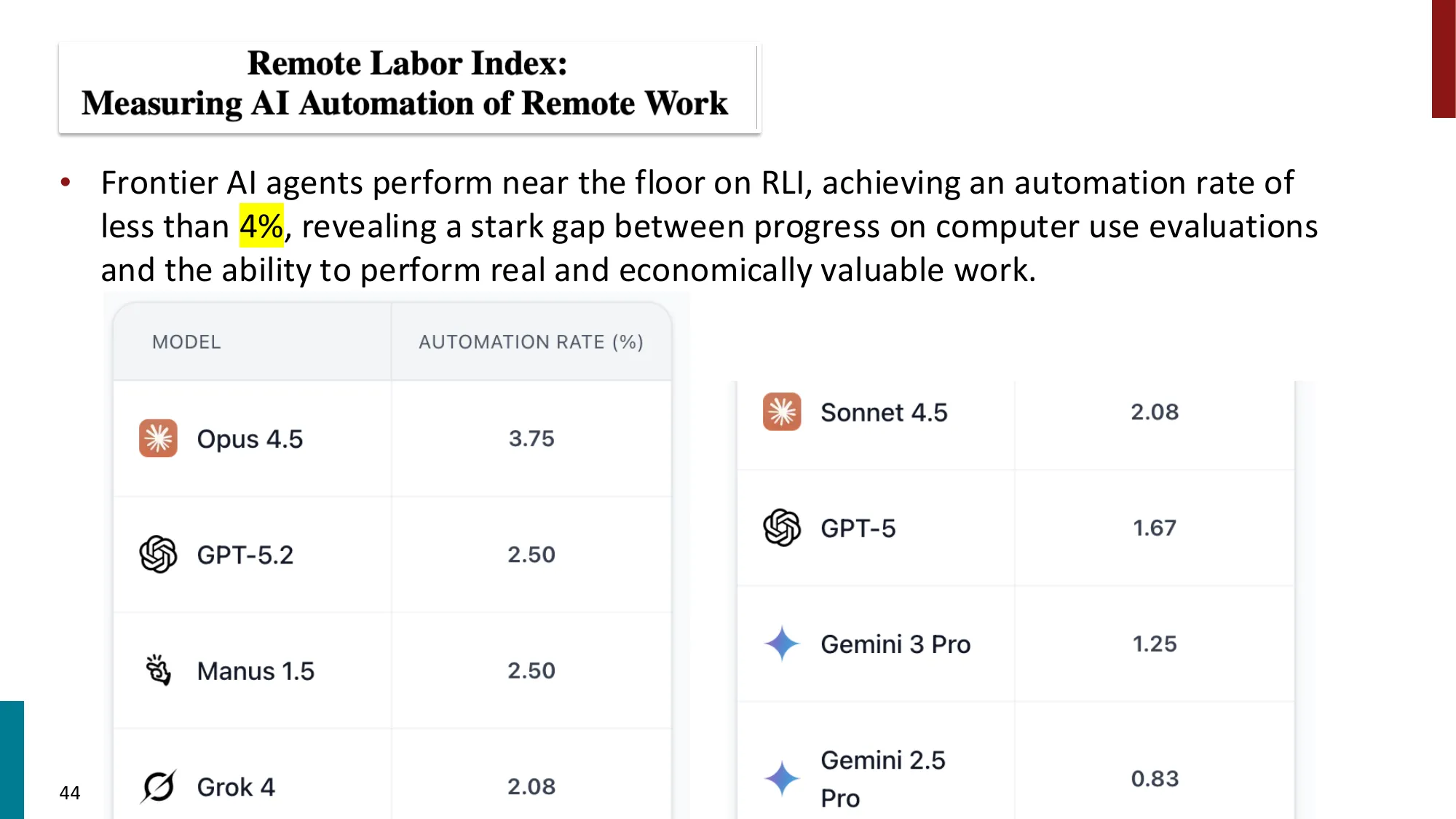
- Remote Labor Index (RLI): 前沿 AI agent 自动化率不足 4%(Opus 4.5 仅 3.75%)
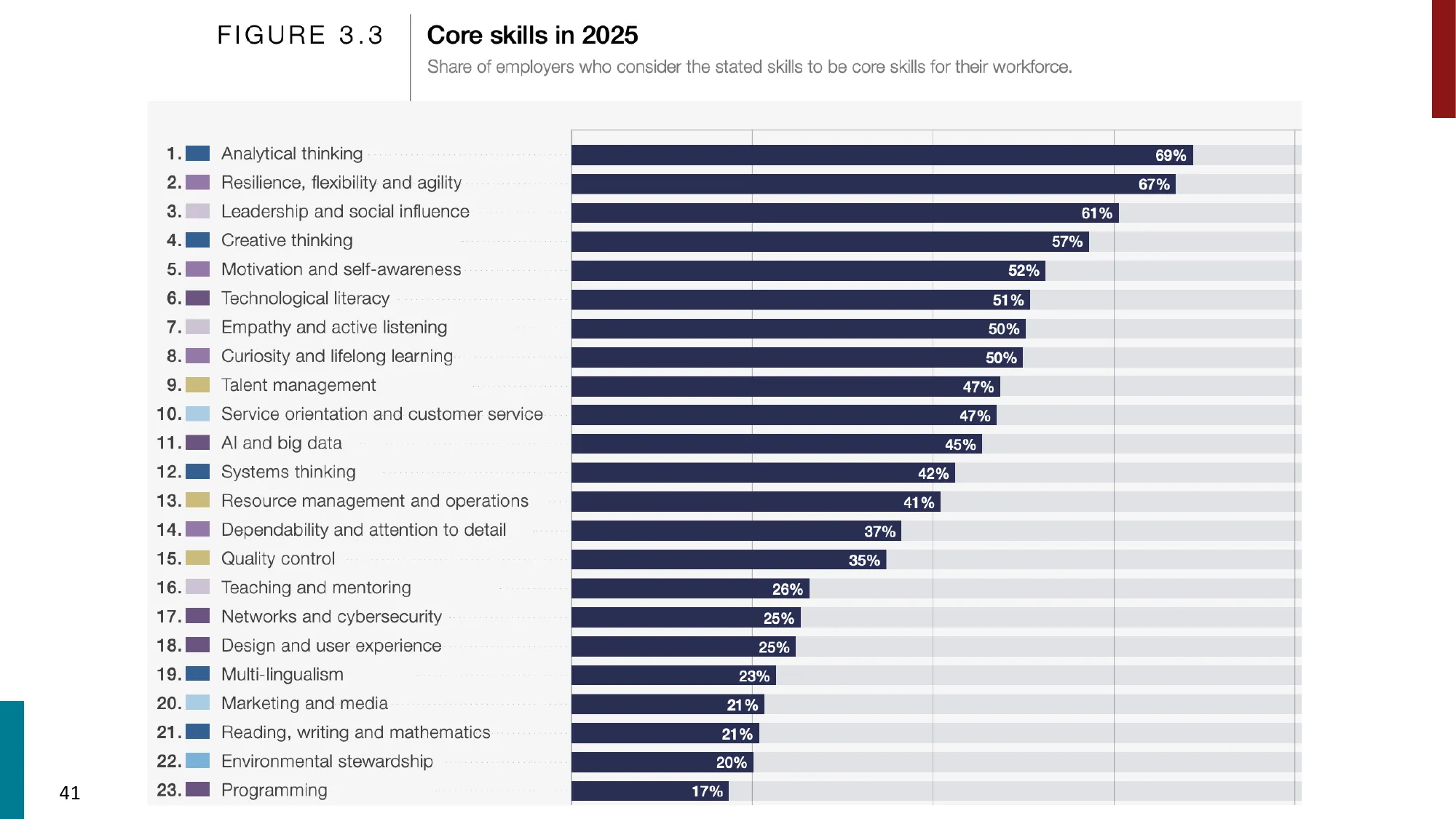
- 核心技能 2025: Analytical thinking (69%), Resilience (67%), Leadership (61%)
Part 4: The Challenges of Value Alignment


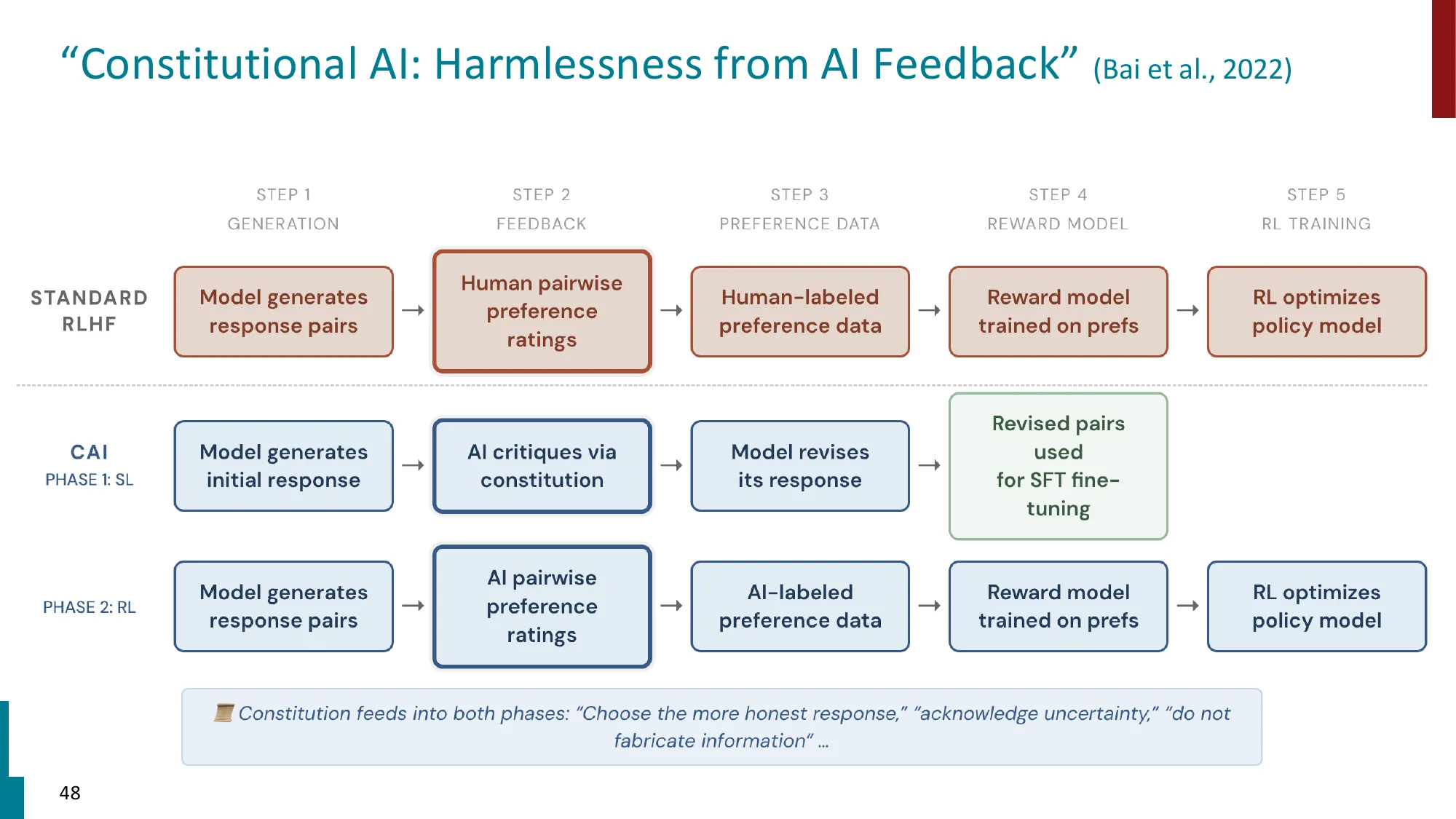
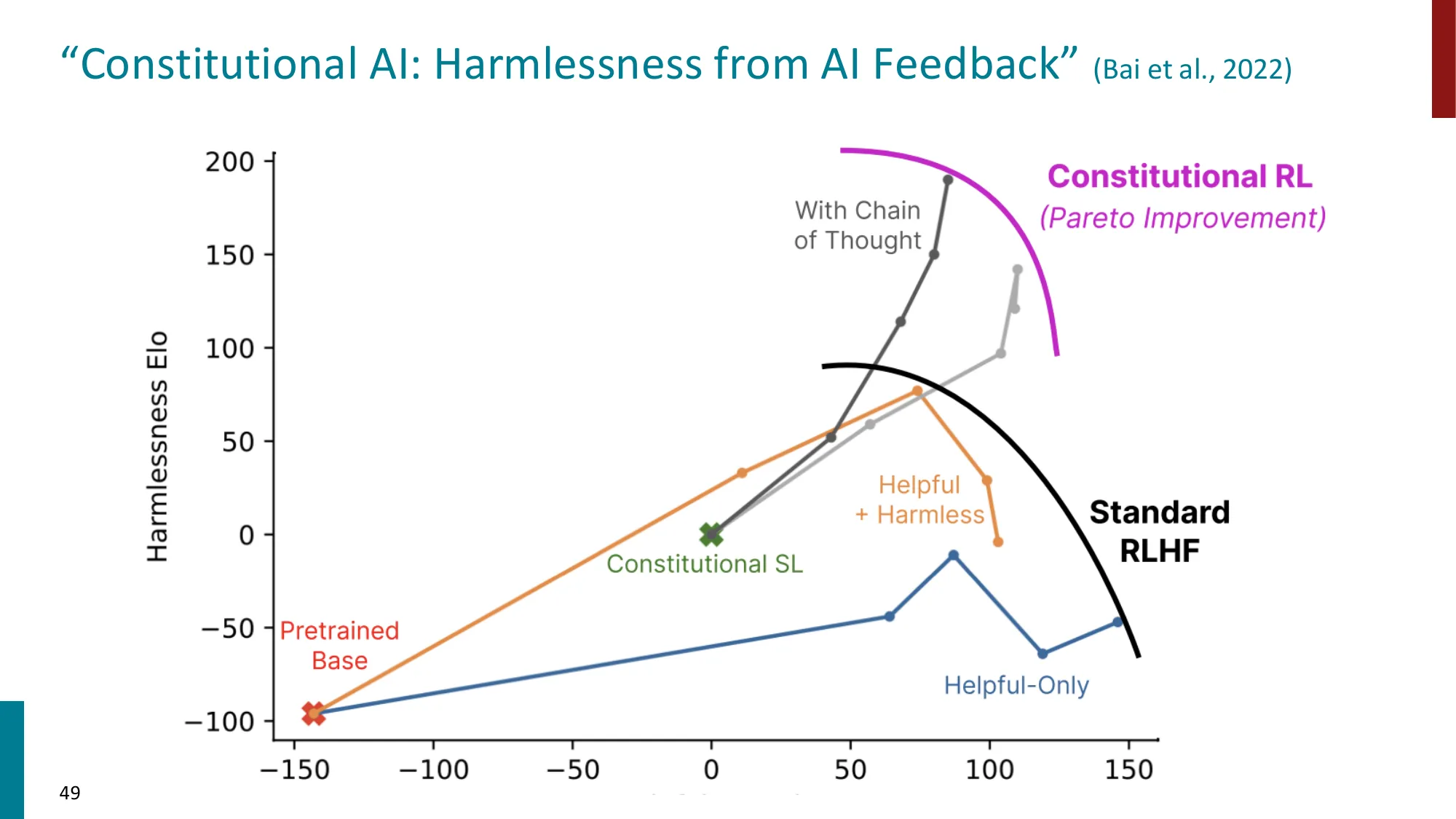
- Constitutional AI (Bai et al. 2022): 用 AI 生成的反馈替代人类偏好标注
- Phase 1 (SL): 模型生成 → AI 基于 constitution 批评 → 模型修订 → SFT
- Phase 2 (RL): AI 偏好标注 → reward model → RL 优化
- 结果: Constitutional RL 实现 Pareto 改进(同时提升 helpful 和 harmless)
Part 5: The Era of Smart Scaling (Yejin Choi 的研究)
- 暴力扩展时代终结: 数据有限(“The fossil fuel of AI”),Ilya Sutskever NeurIPS 2024
- 三条出路: (1) 有限数据学更好 (2) 合成数据 (3) 超越数据推理
- LRMs 崛起 (Large Reasoning Models): DeepSeek-R1, QwQ, o3 — 长思考 + RL + 探索学习
- ProRL (NeurIPS 2025): 在 1.5B 小模型上持续 RL → 可匹敌 4.5x 大模型
- 核心: Sustainable entropy via decoupled clipping (DAPO)
- 动态调节 epsilon_high 维持熵稳定,周期性重置参考策略
- Prismatic Synthesis (NeurIPS 2025): 梯度驱动的数据多样化
- G-Vendi Score: 用梯度表示数据点,密度矩阵的熵作为多样性度量
- 用 20x 小的 R1-32B 生成数据 + 零人类标注即可超越 baseline
- RLP (ICLR 2026): Reinforcement as a Pretraining Objective
- 在预训练阶段就注入推理能力,而非作为事后补丁
- 相比 BASE +19%, 相比 CPT +17%,且优势在 post-training 后复合增长
📐 Constitutional AI 的两阶段算法
Phase 1 — SL-CAI(监督学习):
- 给定有害 prompt ,让 LM 生成初始回应
- 给 LM 一条 constitution 原则 (如”请解释为什么上面的回应有害,并修订”)
- LM 生成批评 和修订回应
- 重复 次,得到
- 用 对做 SFT
Phase 2 — RL-CAI(强化学习):
- 用 AI 偏好标注替代人类标注:比较两个回应 ,选择符合 constitution 的那个
- 训练偏好模型(PM):
- 用 PM 做 RL 优化(RLHF 管道,但奖励信号来自 AI 而非人类)
关键优势:人类标注者需要接触有害内容(有心理健康风险),AI 偏好标注则不需要人类直接与有害材料交互。
📚 已收录至 拓展阅读知识库
🔗 与其他讲座的关联
- L08 Post-training:Constitutional AI 是 RLHF 的重要变体——用 AI 偏好替代人类偏好
- L19 开放问题:Yejin Choi 的”Smart Scaling”主题贯穿 L16 和 L19——ProRL 和 RLP 都是”以智取胜”而非”以量取胜”的代表
- L13 推理:LRM 的崛起是幻觉率提升的背景——“思考更多”有时意味着”更自信地犯错”(o3 的悖论)
推荐阅读
- Kadavath et al. 2022 — Language Models (Mostly) Know What They Know
- Sharma et al. 2024 — Towards Understanding Sycophancy in Language Models
- Kalai & Vempala 2024 — Calibrated Language Models Must Hallucinate
- Doshi & Hauser 2023 — Generative AI enhances individual creativity but reduces collective diversity
- Bai et al. 2022 — Constitutional AI: Harmlessness from AI Feedback
- ProRL (Liu et al. NeurIPS 2025) — Prolonged RL Expands Reasoning Boundaries in LLMs
- Prismatic Synthesis (Jung et al. NeurIPS 2025) — Gradient-based Data Diversification
- RLP (Hatamizadeh et al. ICLR 2026) — Reinforcement as a Pretraining Objective
关联概念
- Hallucination, RLHF, Sycophancy, Calibration
- Constitutional AI, Value Alignment
- Good-Turing Estimator, Mode Collapse
- Scaling Laws, Synthetic Data
- L08 Post-training
个人笔记
- Yejin Choi 的核心主张: effortless RL/SFT/synthetic data 的结论 != effortful 版本的结论
-
小模型 + 精心设计的算法可以打败暴力扩展 — 这与 AdaGrow 的”高效增长”理念高度一致