L06: Final Projects & Practical Tips
Week 3 · Thu Jan 22 2026 08:00:00 GMT+0800 (中国标准时间)
L06: Final Projects & Practical Tips
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
1. Transformer 回顾(L05 Quick Summary)


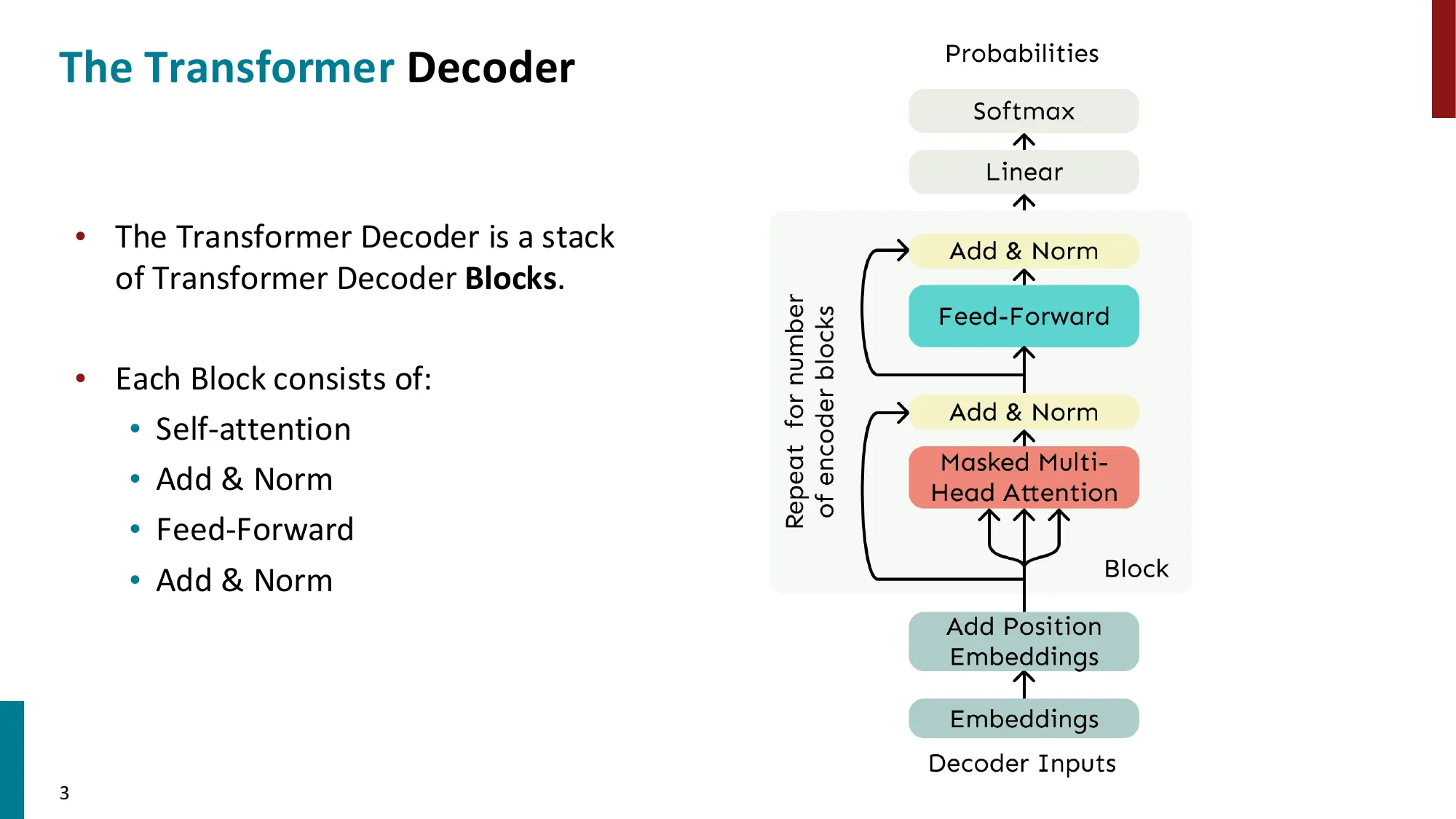




- Transformer Decoder(GPT 类):
- 堆叠 Decoder Blocks:Masked Multi-Head Self-Attention Add & Norm FFN Add & Norm
- 因果掩码(Causal Mask):位置 只能看到 的位置
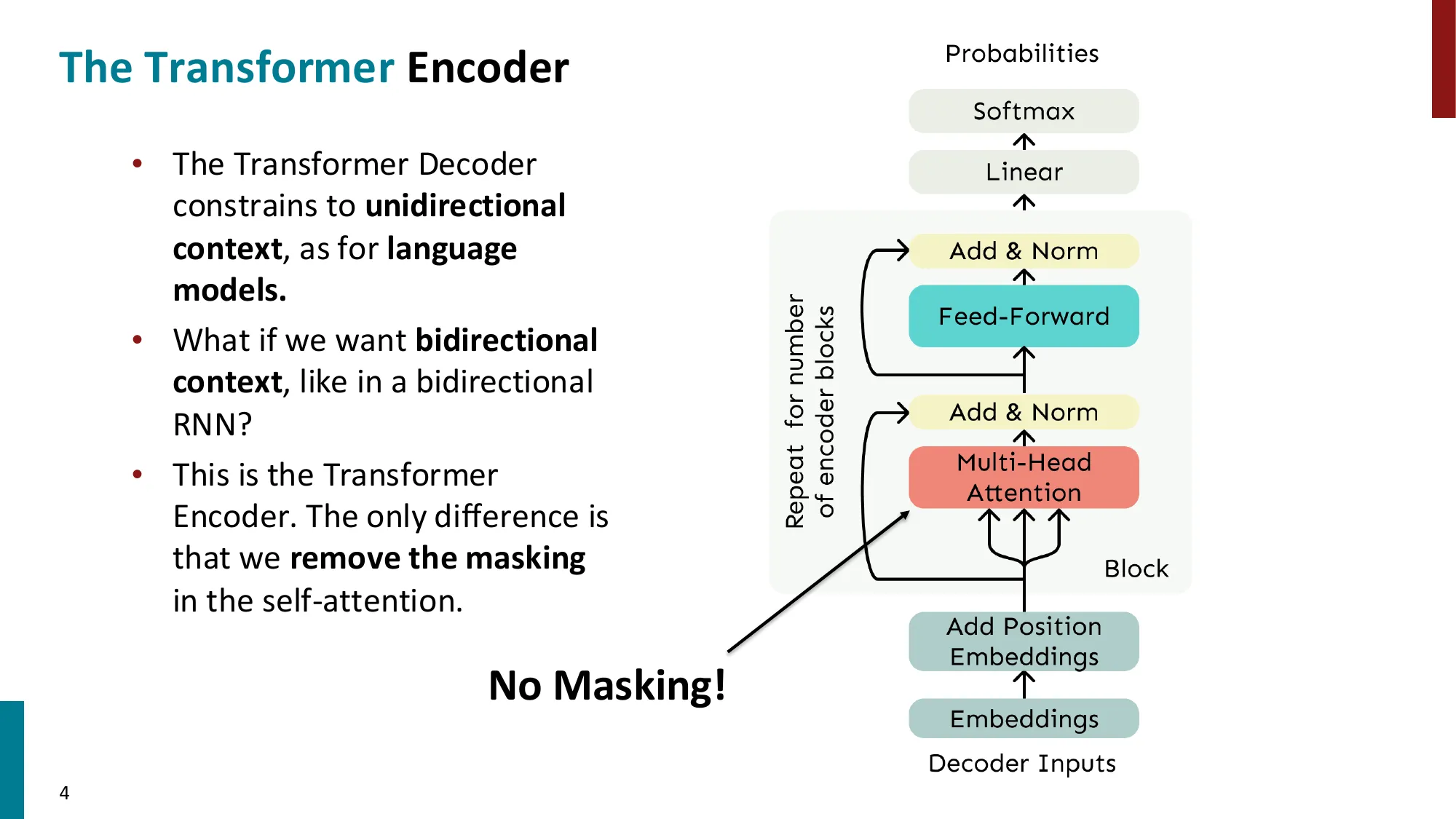
- Transformer Encoder(BERT 类):
- 与 Decoder 相同结构,但去掉 masking 双向上下文
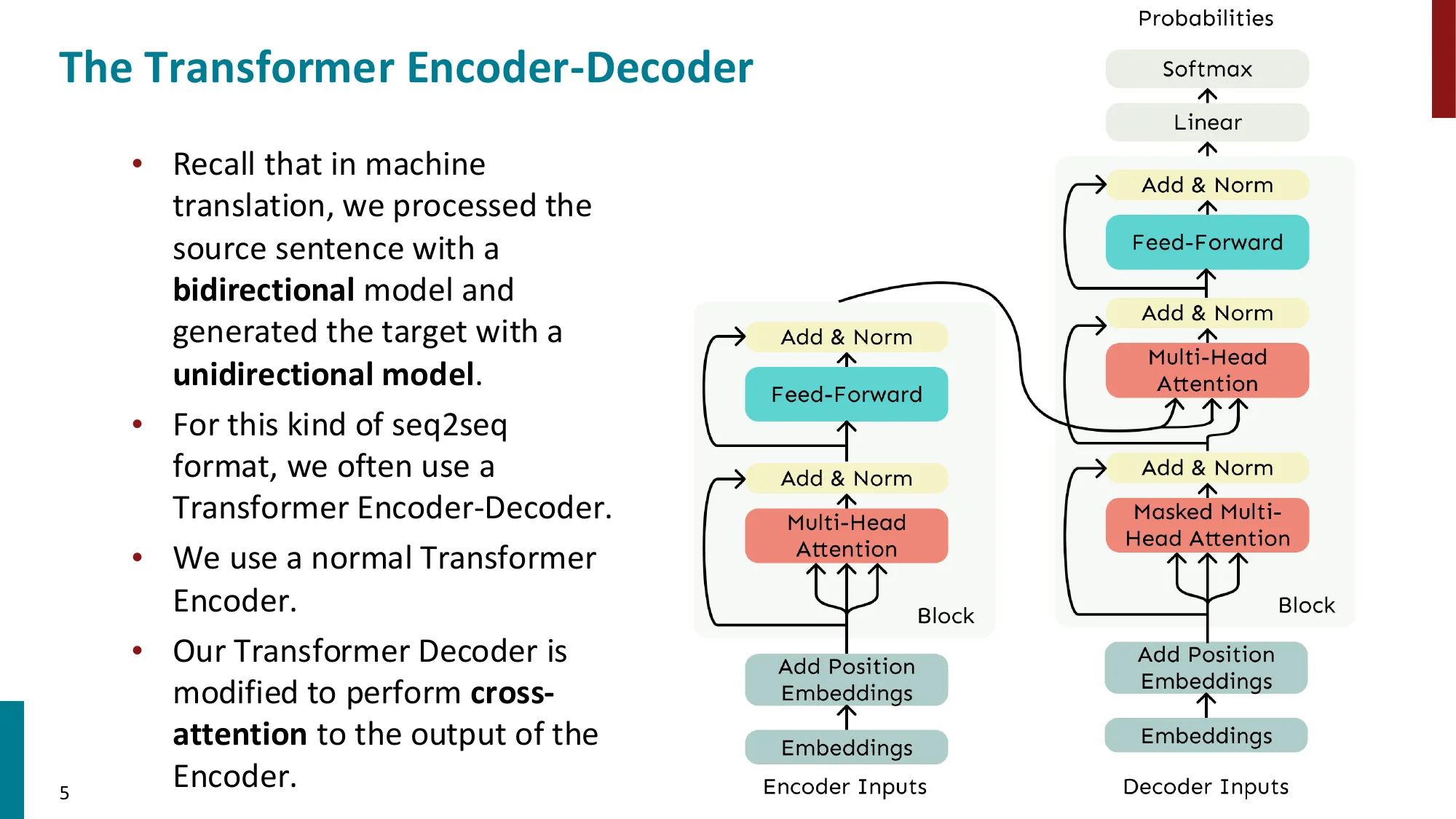
- Transformer Encoder-Decoder(T5 类):
- Encoder 双向编码 + Decoder 因果生成
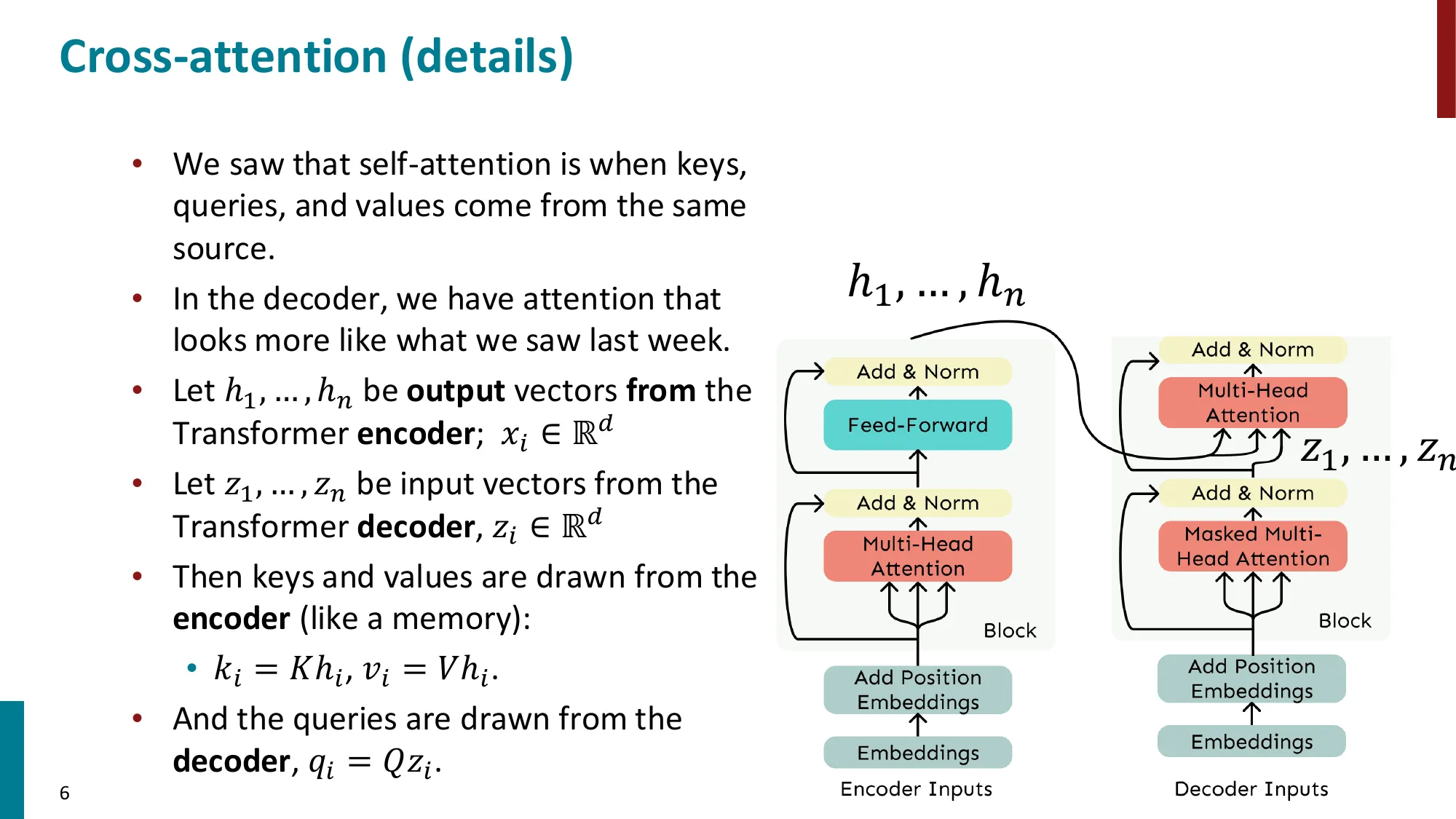
- Cross-Attention:K/V 来自 Encoder,Q 来自 Decoder
- , (encoder 输出)
- (decoder 输入)
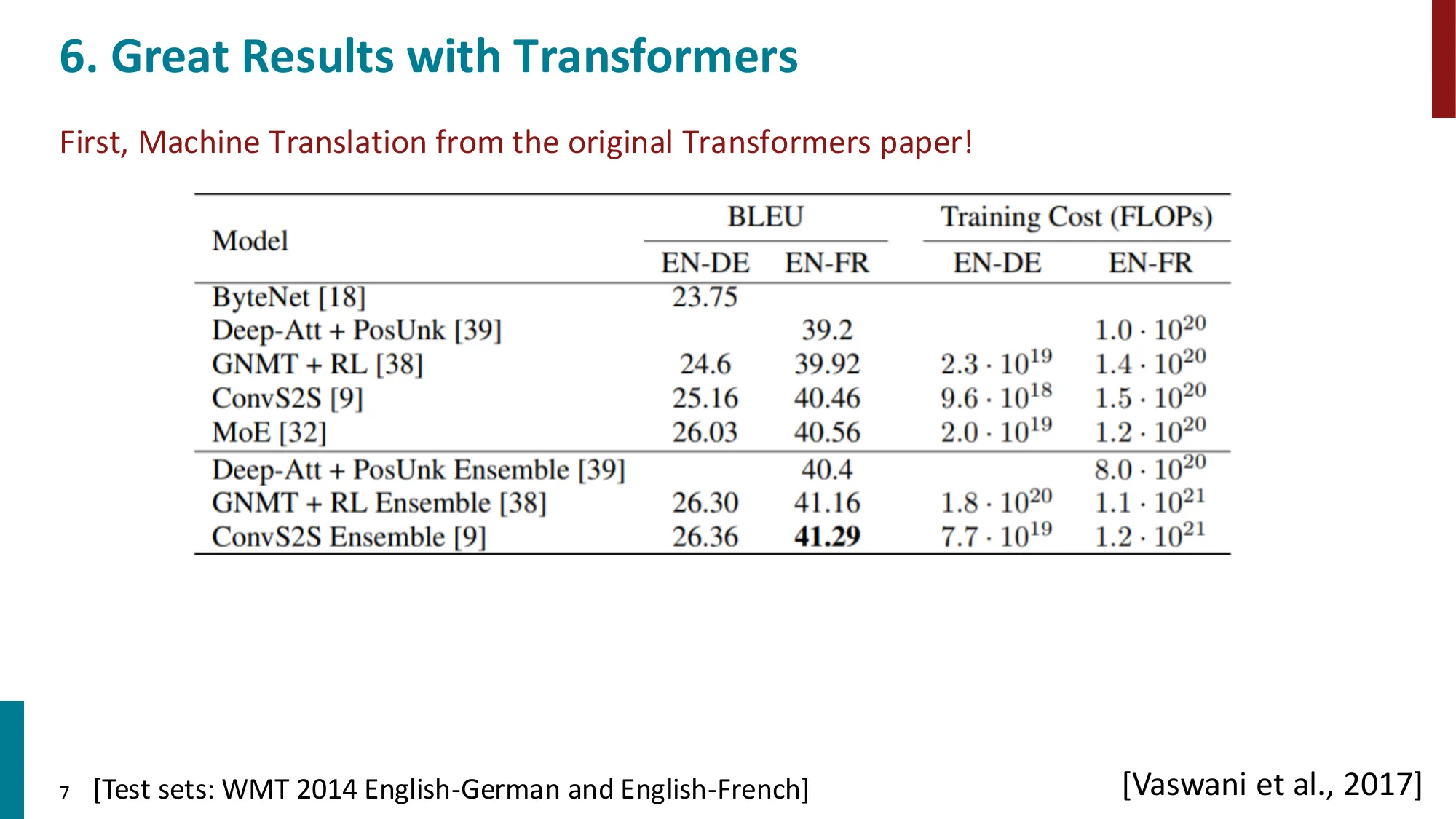
- MT 上的优异表现(Vaswani et al., 2017):WMT 2014 EN-DE/EN-FR SOTA
- 文档生成:Transformer 全面超越 seq2seq-attention baseline
- 待改进:
- 二次注意力复杂度
- 位置表示方案的演进:absolute relative (Shaw 2018) RoPE (Su 2021) DeRoPE (Xiong 2026)
- 实践结论:大 LM 几乎都使用标准二次注意力
📐 三种 Transformer 架构的注意力矩阵对比
Encoder(BERT) — 双向全注意力:
注意力矩阵无约束,每个 token 可关注所有 token(包括未来位置)。
Decoder(GPT) — 因果掩码:
softmax 后 的位置权重为 0,保证自回归生成的因果性。
Encoder-Decoder(T5) — Cross-Attention:
其中 是 Decoder 隐状态, 是 Encoder 输出。Q 来自 Decoder,K/V 来自 Encoder — 注意力矩阵维度为 。
RoPE 位置编码(Su et al., 2021):
其中 。优势:相对位置 仅依赖 (平移不变性),且无需额外参数。
📚 已收录至 拓展阅读知识库
🔢 注意力复杂度的具体数字
| 模型 | 序列长度 | 注意力 FLOPs(每层) | 参数量 |
|---|---|---|---|
| GPT-2 Small | 1,024 | 117M | |
| GPT-3 | 2,048 | 175B | |
| Llama 3 (8B) | 8,192 | 8B |
注意力 FLOPs 随序列长度平方增长。这就是为什么 128K 上下文的模型需要 FlashAttention 等内核优化——否则单层注意力的计算量就超过整个 FFN。
⚠️ 常见误区
-
误区:线性注意力(如 Mamba)已取代标准 Transformer → 正确:截至 2026,所有主流 LLM(GPT-4, Claude, Gemini, Llama 3)仍使用标准 注意力。线性注意力/SSM 在长序列上有优势,但在短到中等长度上未能匹敌标准注意力的质量。
-
误区:Encoder-Decoder 架构已过时 → 正确:T5/UL2 等 Encoder-Decoder 模型在翻译、摘要等 seq2seq 任务上仍有结构性优势(双向编码 + 因果解码),但在通用 LLM 场景中 Decoder-only 更灵活且更容易扩展。
2. 课程评分政策回顾

- 4 次作业(48%):6% + 3 14%
- Final Project(49%):proposal 8% + milestone 6% + poster/web summary 3% + report 32%
- Participation(3%)
- Late day policy:6 天免费延期;之后每天扣 1% 总成绩;单次作业最多延期 3 天
- 协作政策:可使用现有代码/资源,但必须标注来源,按个人贡献评分
💡 为什么 Final Project 占 49%?
CS224N 的核心设计理念:NLP 是实践驱动的学科。四次作业教你基础工具(反向传播、Transformer 实现、LLM 评估),但真正的学习发生在 Final Project 中——从选题、文献调研、实验设计到论文写作的完整研究闭环。这也是为什么顶尖团队的 Custom Project 经常直接投 ACL/EMNLP workshop。
3. Final Project 两大选项






- Default Final Project(小 GPT + 下游任务):
- 2026 新版:构建并实验一个小 GPT 模型
- PyTorch 起始代码
- 任务:实现 GPT-2(attention + transformer block) 微调做情感分析(Rotten Tomatoes) 扩展改进(paraphrasing / sonnet generation / hardware efficiency)
- 适合人群:研究经验有限、想要引导和明确目标、约半数学生选择
- Custom Final Project(自选课题):
- 需要课程审批
- 由 mentor(TA/prof/postdoc/PhD)提供反馈
- 必须同时涉及人类语言和神经网络
- 适合人群:已有研究方向/兴趣、想要独立探索
- 两种选项工作量相当,都有机会获 Best Project Awards
- 团队:1-3 人,鼓励组队;多人团队期望更大工作量
- 语言/框架不限(但几乎所有人都用 PyTorch)
🔢 Default vs Custom Project 对比
| 维度 | Default Project | Custom Project |
|---|---|---|
| 课题 | 构建小 GPT + 微调 | 自选(需审批) |
| 难度 | 有明确引导 | 开放式探索 |
| 代码 | PyTorch 起始代码 | 从零开始 |
| 指导 | 统一 TA 指导 | 分配 mentor(TA/PhD) |
| 典型产出 | 情感分析 + paraphrasing | 可投 workshop 论文 |
| 适合人群 | ~50% 学生选择 | 有研究经验/兴趣 |
| 要求 | 实现 + 实验 + 报告 | 必须涉及人类语言 + 神经网络 |
Default Project 的三个扩展方向(选一):
- Paraphrase generation:输入句子 → 生成语义相同但措辞不同的句子
- Sonnet generation:生成符合格律的十四行诗
- Hardware efficiency:在固定计算预算下最大化性能
⚠️ 常见误区
-
误区:Custom Project 比 Default 更容易拿高分 → 正确:两者评分标准不同但工作量相当,Custom 的自由度意味着更高的失败风险(选题太大、数据不可获取、baseline 不清楚)。
-
误区:一个人做 Custom Project 也可以 → 正确:虽然允许 1 人团队,但 Custom Project 的工作量预期按团队大小线性增长,1 人做需要极好的时间管理。
4. Project Proposal(8%,3-4 页,Feb 10 截止)



- 内容要求:
- 找一篇与课题相关的关键论文
- 写论文摘要 + 你从中提取的关键思路
- 描述计划做什么、如何创新
- 提出合理的 milestone(中期目标)
- Custom Project 额外需要:项目计划、相关文献、模型类型、数据来源、评估方法
- 评分标准:
- Research paper review:summative(总结性评价)
- Project plan:formative(形成性评价)
- 关键:数据是否合适/可获取、评估方案是否现实、是否有 baseline 对比
💡 好的 Proposal 长什么样?
一份 A+ proposal 的核心要素:
- 明确的研究问题:不是”我要做情感分析”,而是”现有情感分析模型在讽刺语境下 F1 仅 42%,我要通过引入语境窗口扩展将其提升到 60%+”
- 可量化的 baseline:已有方法在你的数据集上的具体数字
- 可获取的数据:URL、大小、格式、是否需要预处理
- 现实的时间线:Milestone 应该是中间可交付产物(如”第 5 周完成数据预处理和 baseline 复现”),而不是模糊的”探索”
- 失败预案:如果主方案不 work,Plan B 是什么?
📐 Proposal 的四步结构与论文批判性阅读框架
Proposal 四步结构:
Step 1:找一篇关键论文
选一篇与你的课题直接相关的核心论文——不一定是最新,但必须是你的方法/任务的重要奠基工作。评分标准:这篇论文是否真的和你的项目核心相关?你是否真正读懂了它?
Step 2:写批判性摘要(Critical Review)
这是 Proposal 中唯一 summative 评分的部分(其余都是 formative)。评分看的是你是否真正理解了这篇论文,而不是你的项目方向是否最终成功。
批判性阅读的 5 个核心问题(直接来自 CS224N slides):
| # | 问题 | 你应该回答什么 |
|---|---|---|
| 1 | 研究问题是什么? | 这篇论文解决了什么具体问题?为什么这个问题重要? |
| 2 | 方法是什么? | 核心技术贡献是什么?架构/算法的关键设计决策是什么? |
| 3 | 结果如何? | 在哪些数据集/基准上,提升了多少?与 baseline 相比如何? |
| 4 | 局限性与失败模式 | 这个方法在什么情况下不 work?假设条件是什么?潜在的批评是什么? |
| 5 | 你会怎么做? | 如果你来做 follow-up,自然的下一步是什么?这直接引出你的 Proposal 方向 |
Step 3:描述你的方案(Project Plan)
这部分是 formative 评分——评分看你是否认真思考了,而不是你的方案是否”正确”。需要包含:
- 任务定义:输入 ,输出 ,形式化定义任务(e.g., sequence classification, span extraction)
- 数据集:具体数据集名称、大小、来源 URL、标注格式、是否公开可获取
- Baseline 方法:最简单可行的基线(e.g., bag-of-words logistic regression, pretrained BERT fine-tune)
- 你的创新点:相对 baseline,你改了什么?为什么你认为这会 work?
- 评估指标:具体用什么指标(Accuracy/F1/BLEU/ROUGE/Exact Match),为什么这个指标适合你的任务?
- 所需资源:需要多少 GPU 小时?有没有计算限制?
Step 4:提出 Milestone
Milestone 是 中间可交付产物,而非意向声明:
| 时间节点 | 坏的 Milestone(❌) | 好的 Milestone(✅) |
|---|---|---|
| 第 3 周末 | ”探索数据集" | "完成数据预处理,输出 train/dev/test 统计数据,确认 label 分布” |
| 第 5 周末 | ”实现 baseline" | "Baseline(BERT fine-tune)在 dev 上达到 BLEU ≥ 25,复现论文中的数字” |
| 第 7 周末 | ”改进模型" | "完成 Method A 和 Method B 的对比实验,至少一个提升 baseline ≥ 2 分” |
| Final | ”写报告" | "完成 8 页报告,包含 ablation study 和 error analysis” |
评分重点:Milestone 的评分者会看——数据是否真的可以获取?评估方案是否现实?是否有明确的 baseline 对比?
🔢 完整 Proposal 框架示例
以”讽刺检测”为例,展示一个 Custom Project 的完整 Proposal 骨架:
论文选择:“Detecting Sarcasm in Social Media: The Role of Incongruity”(或类似相关论文)
批判性摘要(Critical Review 示例):
问题:社交媒体中的讽刺(sarcasm)导致情感分析准确率大幅下降,但讽刺的语言信号极其隐晦。
方法:作者提出基于 incongruity(字面语义 vs 情感倾向的不一致性)的特征,结合 SVM 分类器。
结果:在 Twitter 数据集上 F1 = 0.73,相比 bag-of-words baseline (+12%)。
局限性:仅依赖词汇特征,无法捕获语境依赖(e.g., “Yeah, because traffic jams are SO fun”需要知道说话者的情绪);数据集偏向英语推文,跨平台泛化差。
我的 follow-up:用预训练语言模型(RoBERTa)捕获长程上下文,引入对话历史建模讽刺的语境依赖性。
项目计划:
| 要素 | 描述 |
|---|---|
| 任务 | 二分类:给定推文 ,预测是否包含讽刺 |
| 数据集 | SARC 2.0(Reddit 讽刺语料,来自 HuggingFace,共 1.3M 条,已标注) |
| Baseline | RoBERTa-base fine-tune,dev F1 目标 ≥ 0.75 |
| 创新 | 引入对话上下文(父帖子)作为额外输入,使用 Cross-Attention 融合 |
| 评估 | F1-score(讽刺类别),与 baseline 的绝对提升 |
| 计算 | RTX 3090 × 1,训练约 2 小时/实验 |
Milestones:
- Week 3:数据下载 + 预处理完成,train/dev/test 划分,SARC 数据格式理解
- Week 5:Baseline(RoBERTa fine-tune)复现,dev F1 ≥ 0.75
- Week 7:上下文融合模型实现 + 对比实验(+上下文 vs -上下文)
- Final:消融实验 + error analysis + 8 页报告
⚠️ Proposal 常见失误
-
论文选择太泛:选了综述(survey)而不是具体方法论文 → 正确:选一篇提出具体模型/方法的实证论文,你要能解释清楚它的技术细节
-
Critical Review 变成摘要抄写:把 Abstract 翻译了一遍就交了 → 正确:必须有你的批判性判断,尤其是局限性和 follow-up 方向
-
Milestone 是意向而非交付物:写”继续探索数据集”→ 正确:每个 milestone 必须有一个可以验证是否完成的具体产出(数字、文件、结果)
-
数据集”待定”:没有确认数据是否真的可以获取就提交 Proposal → 正确:提交前必须实际下载数据集,确认格式和大小,甚至跑通一个 toy experiment
-
评估指标不匹配任务:生成任务用 Accuracy,分类任务用 BLEU → 正确:评估指标必须是任务标准指标(分类→F1/Accuracy,生成→BLEU/ROUGE/BERTScore,QA→EM/F1)
5. 寻找研究课题和数据的实用建议





























- 关注 ACL/EMNLP/NAACL/NeurIPS/ICML/ICLR 等顶会近期论文
- 数据来源:
- HuggingFace Datasets
- Kaggle
- 论文附带的数据集
- 公开 API 和网络爬虫
- 课题方向示例:
- LLM pre-training / post-training
- 多模态 LLM
- Agentic AI
- 推理能力
- 评估和 red-teaming
- 多语言 NLP
- 科学发现
- 语音和音频 ML
- TA 的研究专长(可查 office hours 安排)匹配课题方向
🔢 2025-2026 热门课题方向与资源
| 方向 | 数据集示例 | 评估指标 | 难度 |
|---|---|---|---|
| LLM 推理 | GSM8K, MATH, ARC | Pass@1, Chain-of-Thought 正确率 | ★★★ |
| 多模态 LLM | VQAv2, COCO Captions | CIDEr, VQA Accuracy | ★★★★ |
| Agent/工具使用 | WebShop, ALFWorld | Success Rate, Step Efficiency | ★★★★ |
| Red Teaming | HarmBench, TrustLLM | Attack Success Rate, Safety Score | ★★★ |
| 高效微调 | Alpaca, FLAN | MMLU, MT-Bench | ★★ |
| 多语言 NLP | XNLI, TyDi QA | Cross-lingual F1 | ★★★ |
关键数据源:
- HuggingFace Datasets:最全面的 NLP 数据集仓库
- Kaggle:标注好的竞赛数据集
- 论文附录:顶会论文通常附带代码和数据链接
- 合成数据:用 GPT-4/Claude 生成训练数据(注意声明)
🔗 课题方向与课程内容的映射
- L02-L04 基础:词向量 → 情感分析(Default Project 核心)
- L05-L07 Transformer/预训练 → LLM 效率优化、架构探索
- L08-L09 后训练/PEFT → LoRA 变体实验、对齐研究
- L10 RAG/Agents → 工具使用、Agent 评估
- L11 评估 → 基准设计、Red Teaming
- L12-L13 推理 → Chain-of-Thought、推理增强
- L14 分词/多语言 → 低资源语言 NLP
- L16 社会影响 → 幻觉检测、偏见缓解
📐 选题框架:Nails vs Hammers + 五种项目类型
两种选题思路(CS224N Slide 23):
| 思路 | 起点 | 路径 | 典型心态 |
|---|---|---|---|
| Nails(问题驱动) | 我关心的问题/应用 | 问题 → 寻找合适方法 | ”临床 NLP 里的命名实体识别太差了,我来改进它” |
| Hammers(方法驱动) | 我感兴趣的技术/模型 | 方法 → 寻找适合的应用 | ”我想搞懂 sparse attention,找个任务来验证它” |
两种思路都 work,但有细微差别:Nails 倾向于产出影响力更大的工作(因为有明确的实际需求),Hammers 更适合你已经在某个技术方向深耕的情况。
五种项目类型(CS224N Slide 24):
| 类型 | 描述 | 难度 | 适合人群 |
|---|---|---|---|
| 1. 应用型 | 把已有 NLP 方法应用到新任务或新领域 | ★★ | 有明确应用场景,无强烈方法创新意愿 |
| 2. 复现型 | 实现并复现一篇论文的方法,在新数据上实验 | ★★ | 想深度理解某个模型,复现+改进 |
| 3. 模型创新型 | 提出新的神经网络架构或训练方法 | ★★★★ | 有 ML 背景,想做原创工作 |
| 4. 分析/可解释性型 | 研究现有模型的行为、表示或局限性 | ★★★ | 对”为什么”比”更高分数”更感兴趣 |
| 5. 其他 | 理论分析、人类行为研究、标注数据集 | 视情况 | 有特殊背景(语言学/认知科学等) |
最常见的陷阱:选了类型 3(模型创新)但时间不够,导致什么都没做出来。建议:先以类型 1 或 2 为基础建立 baseline,再尝试创新——这样至少有东西可以报告。
寻找灵感的起点(CS224N Slide 31):
- ACL Anthology(aclanthology.org):所有 ACL/EMNLP/NAACL/EACL 论文,免费公开,按年份和任务过滤
- NeurIPS / ICML / ICLR proceedings:ML 方向的 NLP 论文,往往方法更 cutting-edge
- arXiv cs.CL / cs.AI / cs.LG:最新预印本,提前了解未发表工作
- Past CS224N Projects(cs224n.stanford.edu/past-projects):最被低估的资源 — 直接看 Stanford 学生做过什么,找空白点
- Google Scholar 关键词告警:设置你感兴趣的 topic,每周自动推送新论文
追踪 SOTA 的工具(CS224N Slide 32):
- Papers with Code(paperswithcode.com):每个 benchmark 的 SOTA 排行榜 + 代码链接,一目了然
- nlpprogress.com:NLP 各任务的进展总结
- HuggingFace Leaderboards:Open LLM Leaderboard, MTEB 等
“冰球要滑向球将去的地方”(Gretzky):不要去做别人已经做烂的方向。CS224N 2026 最有潜力的方向:
- LLM 后训练(RLHF/DPO/Constitutional AI)— 方法多,理解尚不充分
- 多模态推理(视觉-语言-音频融合)— 数据越来越多
- Agentic AI(工具使用、规划、记忆)— 2025 年爆发,研究空白还很多
- 长上下文理解与记忆管理 — 位置编码/KV cache 压缩是热点
- 模型可解释性与安全对齐 — 监管压力推动学术需求
📐 数据获取全景:来源、格式与注意事项
数据收集策略层次(从优到劣):
1. 使用现有公开标注数据集(最推荐)
↓ 没有合适的
2. 复用现有数据 + 重新标注(部分任务适用)
↓ 还不够
3. 众包标注(MTurk、Prolific、Label Studio)
↓ 经费不足
4. 弱监督 / 远程监督(自动生成噪声标签)
↓ 最后手段
5. LLM 合成数据(注意声明,有争议)核心数据源速查表:
| 来源 | 网址 | 特点 | 适用场景 |
|---|---|---|---|
| HuggingFace Datasets | huggingface.co/datasets | 5000+ 数据集,一行代码加载,格式统一 | 所有 NLP 任务首选 |
| Papers with Code | paperswithcode.com/datasets | 按 benchmark 组织,附带排行榜 | 找标准评测数据集 |
| LDC | ldc.upenn.edu | 高质量语言资源,覆盖冷门语言和任务 | 需 Stanford 机构访问(免费) |
| statmt.org | statmt.org | WMT 系列翻译数据集 | 机器翻译 |
| Kaggle | kaggle.com/datasets | 竞赛数据,标注质量参差不齐 | 有趣的 NLP 应用场景 |
| Common Crawl | commoncrawl.org | 原始网页数据,PB 级 | 预训练、领域自适应 |
| Google Dataset Search | datasetsearch.research.google.com | 搜索引擎,索引了大量数据集元数据 | 找冷门/跨领域数据 |
| UCI ML Repository | archive.ics.uci.edu/ml | 传统 ML 数据集,部分有文本 | 分类/回归任务 |
HuggingFace Datasets 使用示例:
from datasets import load_dataset
# 加载 SST-2(情感分析)
dataset = load_dataset("glue", "sst2")
# {'train': 67349 examples, 'validation': 872, 'test': 1821}
# 加载 SQuAD(阅读理解)
squad = load_dataset("squad")
# 加载中文情感数据
cn_sentiment = load_dataset("seamew/ChnSentiCorp")LDC(Linguistic Data Consortium)特别说明:
- Stanford 有 LDC 机构会员资格,学生可免费获取大量标注语料
- 包括:OntoNotes(多任务标注)、Penn Treebank(句法分析)、ACE(实体/关系/事件)、各语种平行语料
- 获取方式:通过 Stanford library 系统申请,邮件到 ldc@ldc.upenn.edu
数据集类型矩阵:
| 任务类型 | 代表数据集 | 评估指标 |
|---|---|---|
| 文本分类 | SST-2, IMDB, AG News | Accuracy, F1 |
| 自然语言推断(NLI) | SNLI, MultiNLI, ANLI | Accuracy |
| 问答(抽取式) | SQuAD 1.1/2.0, TriviaQA | EM, F1 |
| 问答(生成式) | NarrativeQA, ELI5 | ROUGE, BERTScore |
| 机器翻译 | WMT14/19/21, FLORES | BLEU, COMET |
| 摘要 | CNN/DailyMail, XSum, SAMSum | ROUGE-1/2/L |
| 命名实体识别 | CoNLL-2003, OntoNotes | Entity-level F1 |
| 对话/聊天 | MultiWOZ, DailyDialog | BLEU, Inform Rate |
| 代码生成 | HumanEval, MBPP, CodeContests | Pass@k |
| 推理 | GSM8K, MATH, ARC, HellaSwag | Accuracy |
📐 Train/Dev/Test 划分:为什么这是研究诚信问题
标准三分法:
每个集合的唯一职责:
| 数据集 | 用途 | 谁可以”看” | 使用频次 |
|---|---|---|---|
| Train | 模型参数更新 | 模型(通过梯度) | 每个 epoch 完整遍历 |
| Dev(Validation) | 超参数调整、模型选择、early stopping | 你(通过 dev metrics) | 每次实验结束后评估一次 |
| Test | 最终报告的唯一数字 | 仅在最终提交前用一次 | 一次 |
为什么 Test Set 要锁定?
假设你有 1000 个超参数组合,每次都在 test 上看结果再调:
即使每次”运气好的概率”只有 ,1000 次尝试后你几乎必然会找到一个”在 test 上表现特别好”但完全没有泛化能力的模型。这就是 test set overfitting(评测集过拟合),也叫 p-hacking 的 NLP 版本。
“Peeking” 的危害(CS224N 重点警告):
- 实验中途看了 test 结果,然后基于此决定是否继续某个方向
- 论文中报告的 test 结果因此虚高,无法复现
- 这是学术诚信问题,不仅是技术问题
小数据集的处理方案:
当数据量太少无法做三分法时:
- k-fold Cross Validation:将训练集分成 份,轮流用 份训练、1 份验证,报告均值±标准差
- Stratified Split:确保每个 split 中各类别比例与原始数据集一致(分类任务必做)
- Test Set 最小原则:至少保留 500-1000 个样本做 test(太小则评估有噪声)
报告结果的正确方式:
Dev Results(用于调参,仅供参考):
Model A (RoBERTa base): F1 = 84.2
Model B (RoBERTa large): F1 = 86.5 ← 选这个
Model C (+context): F1 = 87.1 ← 最终模型
Test Results(最终报告,只跑一次):
Baseline (BERT fine-tune): F1 = 79.3
Our Model (RoBERTa + context): F1 = 86.8
Previous SOTA: F1 = 85.2📐 实验策略:如何高效迭代并得到可信结论
CS224N 推荐的实验循环(Slides 51-53):
1. 极简版本先跑通(Sanity Check)
↓
2. 小数据集快速迭代(Debug Mode)
↓
3. 完整数据集 baseline(Baseline Established)
↓
4. 增量改进 + 消融实验(Systematic Improvement)
↓
5. Error Analysis → 发现下一个改进点(回到 4)
↓
6. Final evaluation on test set(一次)Step 1:Sanity Check(先过拟合一个 batch)
在开始任何调参之前,先用 10 个样本 让模型过拟合到接近 0 的 loss:
# 好习惯:先验证模型能学习
for batch in itertools.islice(train_loader, 1):
# 只用一个 batch,重复训练 100 步
for _ in range(100):
loss = model(batch)
loss.backward()
optimizer.step()
assert loss.item() < 0.01, "模型无法过拟合单个 batch,检查数据/模型实现"如果连 10 个样本都学不了,说明实现有 bug,不要急着跑完整数据集。
Step 2:小数据集快速迭代
用 1-5% 的训练数据(不超过 1000 个样本)做快速实验:
| 好处 | 具体数字 |
|---|---|
| 训练速度 | 完整数据集需要 2 小时/epoch → 小数据集 2 分钟/epoch |
| 迭代频率 | 1 天内可以跑 100+ 个实验,而不是 3 个 |
| Debug 效率 | 错误更快暴露,不会等 2 小时才发现 loss 是 NaN |
Step 3:通过防过拟合确保泛化
| 过拟合信号 | 对策 |
|---|---|
| Train loss 低,Dev loss 高 | 增加 Dropout(0.1 → 0.3),增加 Weight Decay |
| Dev 曲线震荡 | 降低学习率,增加 warmup steps |
| 不同 seed 结果差异大 | 增加训练数据,或报告均值±标准差 |
Step 4:消融实验(Ablation Study)是必须的
好的消融实验是回答”我的每个组件到底有没有用”:
Full Model: F1 = 87.1
- Context Window: F1 = 84.3 (-2.8, 上下文有效)
- Data Augment: F1 = 85.6 (-1.5, 数据增强有效)
- Large Backbone: F1 = 83.2 (-3.9, 大模型有效)
Baseline: F1 = 79.3每次只改一个变量——如果你同时改了架构和数据集,你无法知道提升来自哪里。
Step 5:Error Analysis 比提升指标更有价值
手动看 50-100 个模型预测错误的样本:
- 哪类错误最多?(系统性错误 vs 随机噪声)
- 是数据问题(标注错误)还是模型问题?
- 错误样本有没有共同特征(e.g., 长句子、特定领域词汇)?
Error analysis 往往直接指向下一个改进方向,比盲目调超参更有效率。
⚠️ 寻题与实验的常见陷阱
-
课题太大:“我要解决机器翻译” → 正确:缩小到”在低资源语言对(斯瓦希里语-英语)上,数据增强对 NLLB 的影响”——越具体越好
-
没有 baseline:“我的模型 BLEU=28.5,很高!” → 正确:没有 baseline 的数字没有意义。必须知道:人类表现多少?前人 SOTA 多少?最简单的 baseline 多少?
-
数据泄露:test 集中的样本也出现在训练集中(对于爬取数据尤其常见)→ 正确:训练前做去重(exact match + near-dedup),验证 test 分布与 train 不重叠
-
只报告最好的数字:跑了 20 个实验,只报告其中最好的一次 → 正确:报告多个 seed 的均值±标准差,或报告所有合理超参组合的范围
-
忽略计算预算:选了一个需要 8× A100 训练的 baseline → 正确:早期就确认计算资源是否可行,CS224N 提供免费 GPU quota,但有上限
-
Nails vs Hammers 混用:方向飘移——开始是”我要做讽刺检测”,写着写着变成”我要验证 sparse attention 的有效性” → 正确:选定一个框架后坚持,不要在途中根本性换方向
- CS224N 2026 Final Project Handout — 课程官网(Thursday 发布)
- Attention Is All You Need (Vaswani et al., 2017) — Attention Is All You Need
- Language Models are Unsupervised Multitask Learners (Radford et al., 2019 / GPT-2) — 待读
关联概念
作业提醒
- A3 发布(从零实现 Transformer + 理解 attention)
- A2 截止