L07: Pretraining
Week 4 · Tue Jan 27 2026 08:00:00 GMT+0800 (中国标准时间)
L07: Pretraining
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
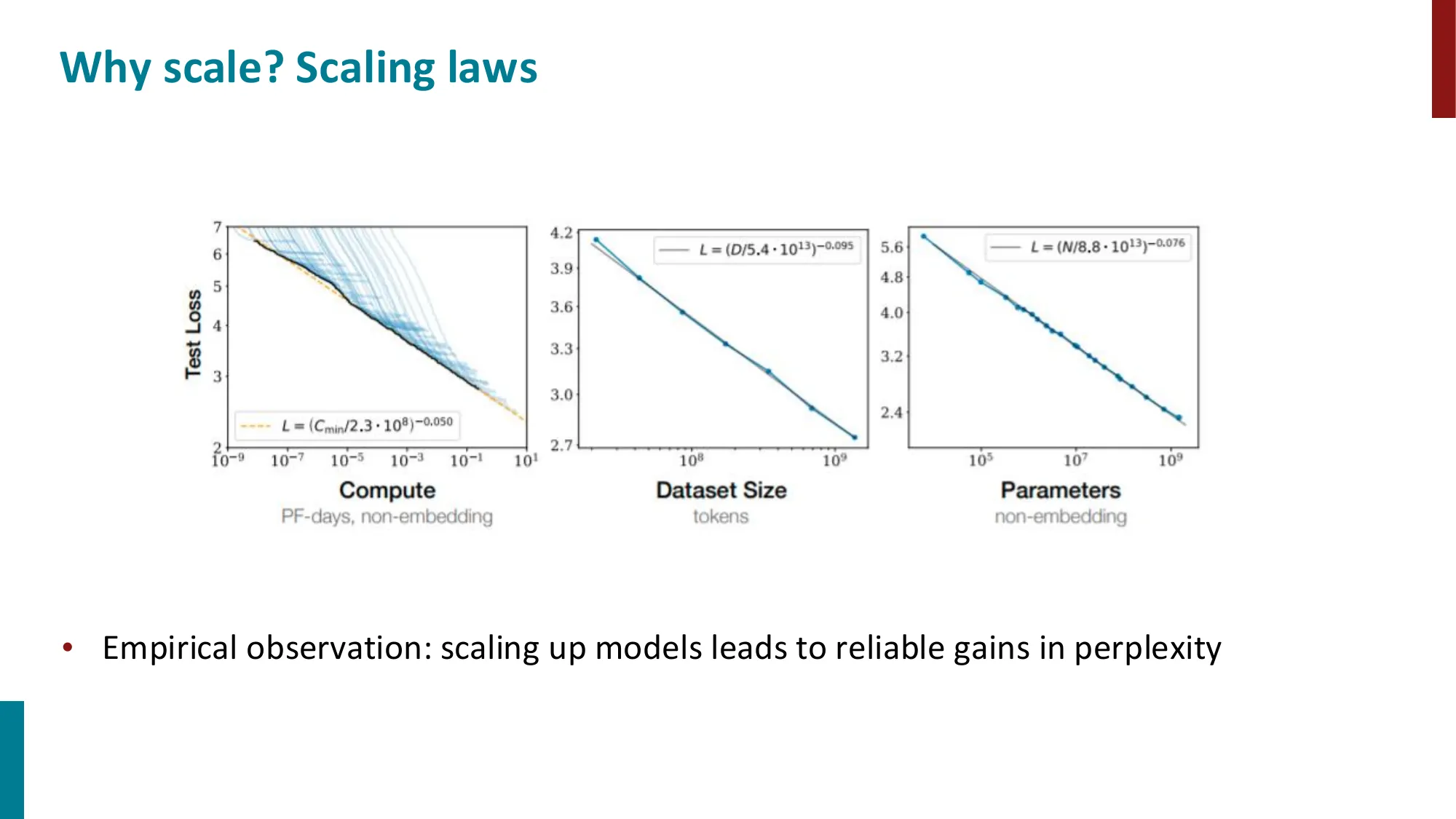
1. Pretraining 动机


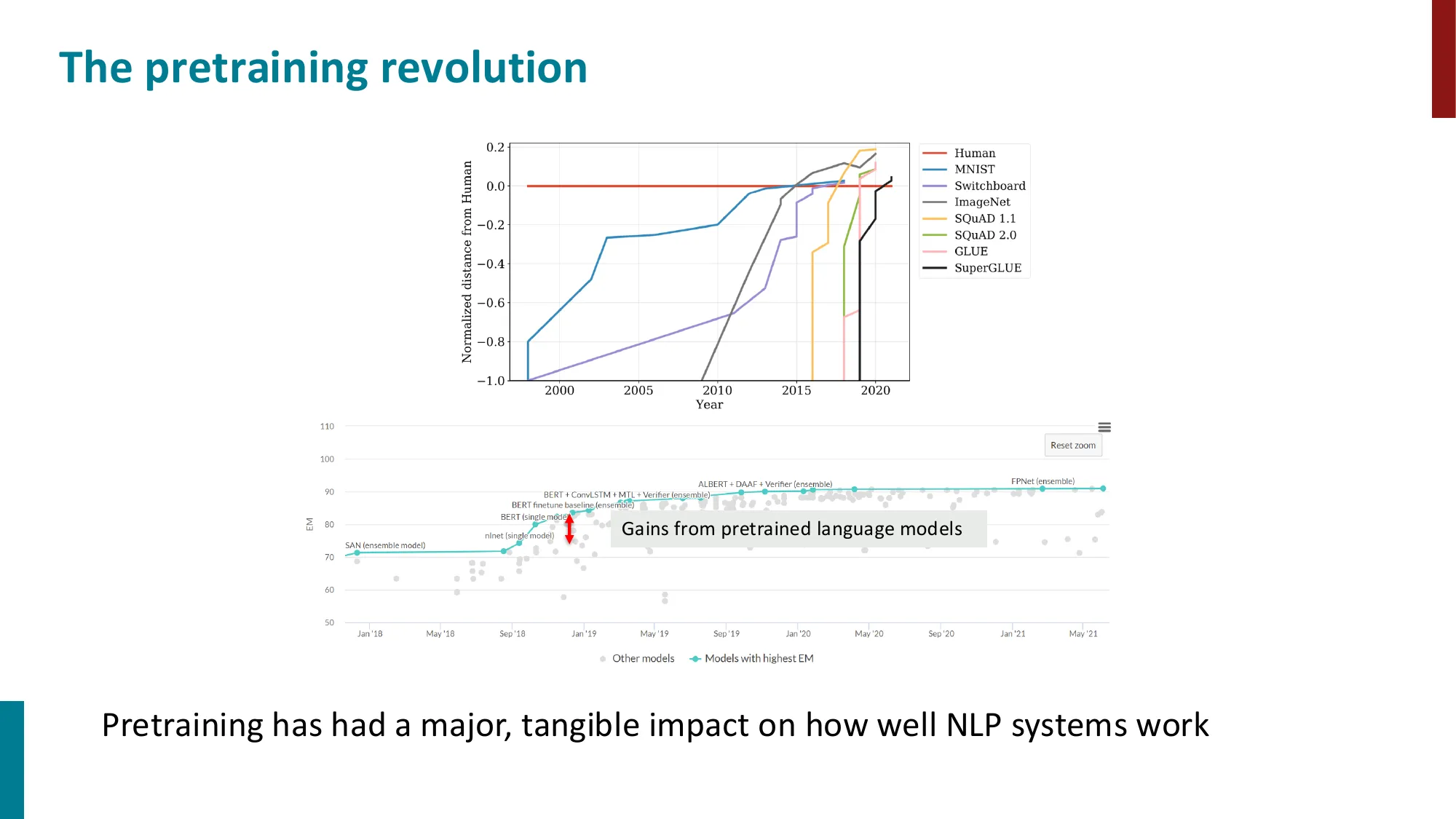
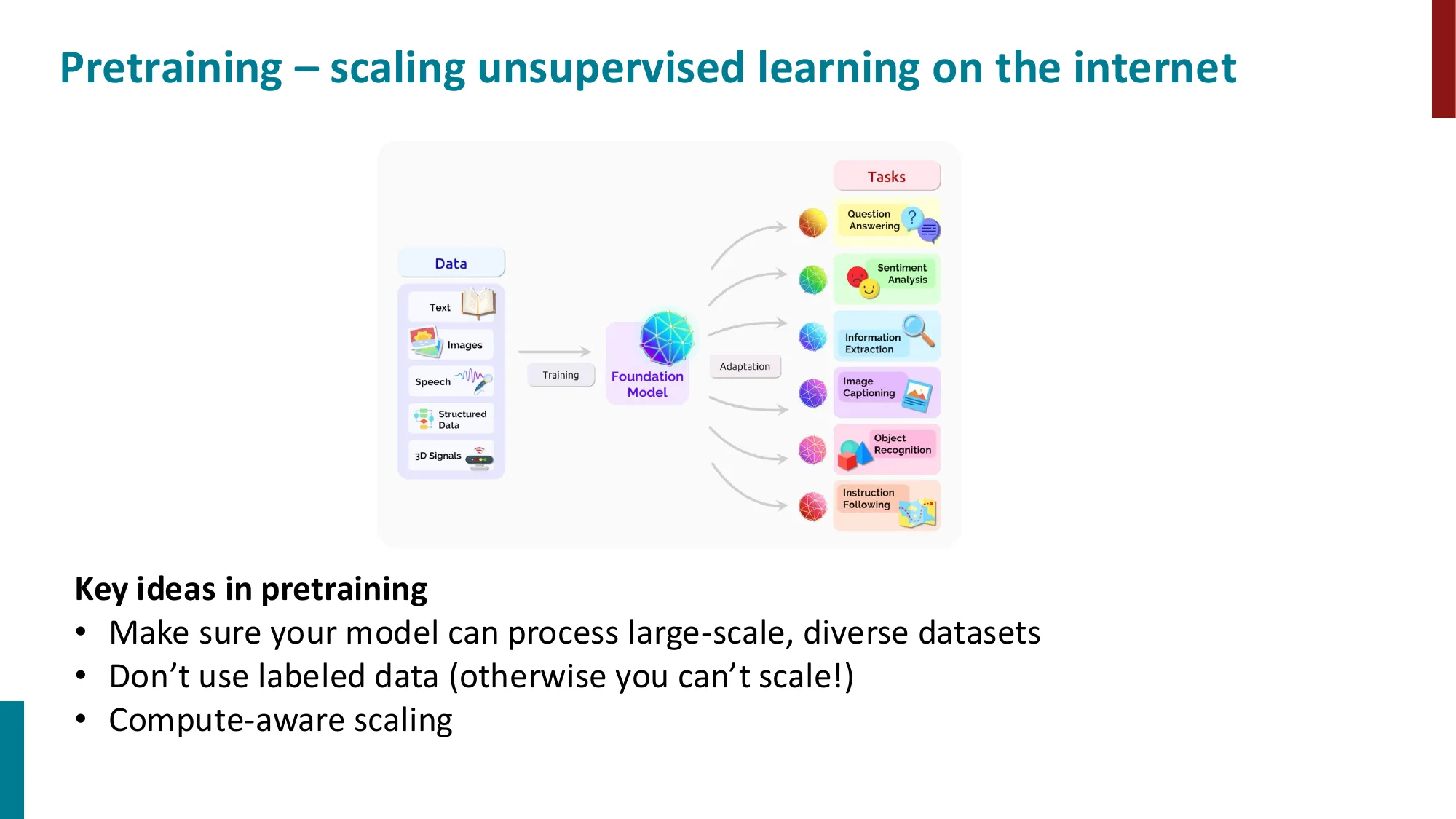
- 预训练革命:预训练语言模型极大提升了 NLP 系统性能(SQuAD、GLUE、SuperGLUE 等基准上的飞跃)
- 核心理念:在大规模无标注数据上训练 foundation model,再 adaptation 到下游任务
- 关键要素:大规模多样化数据 + 无需标注 + 计算感知缩放(compute-aware scaling)
📐 预训练 vs 随机初始化的样本效率
变量定义:设下游任务需要 个标注样本使预训练模型达到性能 ,随机初始化模型达到同等性能 所需样本数为 。
推导过程:预训练模型已经从大规模无标注数据 (数百亿 token)中习得语言的统计规律,其参数初始化点 在损失景观中已处于接近下游任务最优解的低谷附近。而随机初始化点 则处于高损失区域,需要更多梯度步才能到达同等低谷。
形式化地,fine-tuning 的优化路径为:
由于起点更优,同样的 步优化可以达到更低的损失,等效为:
结论:预训练模型在低资源场景下的样本效率比随机初始化高约 100 倍。
📚 已收录至 拓展阅读知识库
🔢 BERT vs 从头训练:SST-2 情感分析
实验设置:使用不同规模的训练数据在 SST-2(斯坦福情感树库二分类)上对比 BERT-Base(预训练)和等参数量 Transformer(随机初始化):
| 训练样本数 | 从头训练准确率 | Fine-tune BERT 准确率 |
|---|---|---|
| 100 | 52%(近随机) | 81% |
| 1,000 | 65% | 92% |
| 10,000 | 83% | 94% |
| 67,349(全量) | 91% | 95% |
关键结论:1,000 样本 fine-tune BERT 即可达到 92%,而从头训练需要 ~50,000 样本才能达到相近水平。
💡 为什么这样做?
预训练就像让模型”学会了阅读”——它从海量文本中习得了词汇、语法、事实知识和常识推理。当面对新任务(如情感分析)时,这相当于教一个识字的人”读出文章的情感”,而非从零开始教一个人认字。知识迁移发生在表示层面:预训练得到的上下文表示已经编码了丰富的语义信息,下游任务只需要学习”如何使用”这些表示。
⚠️ 常见误区
-
误区:预训练 NLP 模型可以直接迁移到任何领域 → 正确:领域差距大时(如蛋白质序列建模、医学影像报告、法律合同),通用 NLP 预训练可能没有优势,甚至不如在领域数据上从头训练的小模型。BioBERT、LegalBERT 等领域预训练模型的存在本身就说明了这一点。
-
误区:更大的预训练模型 fine-tune 后一定更好 → 正确:在数据极少(<100 样本)时,过大的模型可能过拟合,小而精的预训练模型(如 DistilBERT)反而更稳健。
2. 子词建模(Subword Modeling)


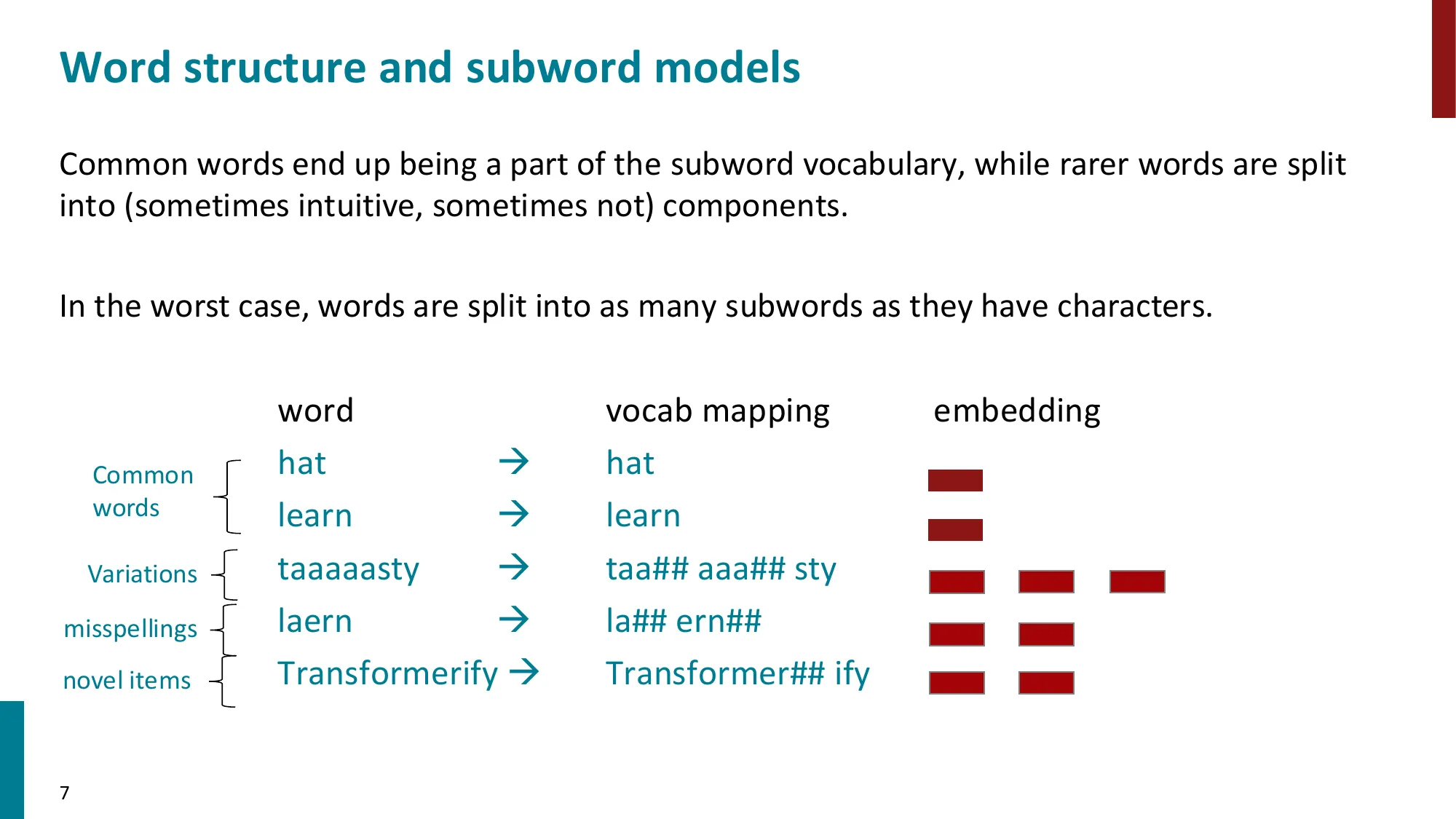
- 固定词表的问题:新词/拼写变体/罕见词映射为 UNK
- Byte-Pair Encoding (BPE):从字符开始,迭代合并最频繁的相邻 pair,直到达到目标词表大小
- 常见词保持完整,罕见词拆分为子词片段(如 Transformerify -> Transformer## ify)
- WordPiece 是 BPE 的变体,用于 BERT 等预训练模型
🔢 “unhappiness” 的 BPE 切分
假设已学到的合并规则(按优先级):
u + n→unh + a + p + p + i→happi(经过多次合并)n + e + s + s→ness
切分过程:
"unhappiness"
→ 初始字符序列: u n h a p p i n e s s
→ 应用规则 1: un h a p p i n e s s
→ 应用规则 2: un happi n e s s
→ 应用规则 3: un happi ness
→ 最终 tokens: ["un", "happi", "ness"]
→ token IDs: [2891, 14428, 1108] (GPT-2 词表中的实际 ID)对比:词级 tokenization 中 “unhappiness” 若不在词表则直接映射为 [UNK],丢失所有信息。
💡 为什么这样做?
子词 tokenization 解决了两个极端的缺陷:词级粒度对生僻词无能为力(UNK 问题),字符级粒度序列太长且语义被过度切碎。子词的核心洞察是:语言有形态结构——“un-”(否定前缀)、“-ness”(名词化后缀)在成千上万的单词中反复出现。通过给它们分配独立 token,模型可以学习前缀/后缀的语义,并将这些知识复用到从未见过的新词上。这本质上是将词法知识编码进了词表。
⚠️ 常见误区
-
误区:BPE 的切分结果是固定的语言学子词 → 正确:BPE 切分完全依赖训练语料的统计特性,与语言学无关。“ChatGPT” 在 GPT-2 词表中被切分为
["Chat", "G", "PT"],不符合语言学直觉,纯粹因为训练时这些子串共现频率高。 -
误区:BPE 词表越大越好 → 正确:词表过大会使 embedding 矩阵占用大量参数(词表大小 × 隐层维度),还会导致每个 token 的训练样本减少。GPT-4 使用约 100K 大小词表(cl100k_base),是平衡的结果。
3. 从词嵌入到全模型预训练

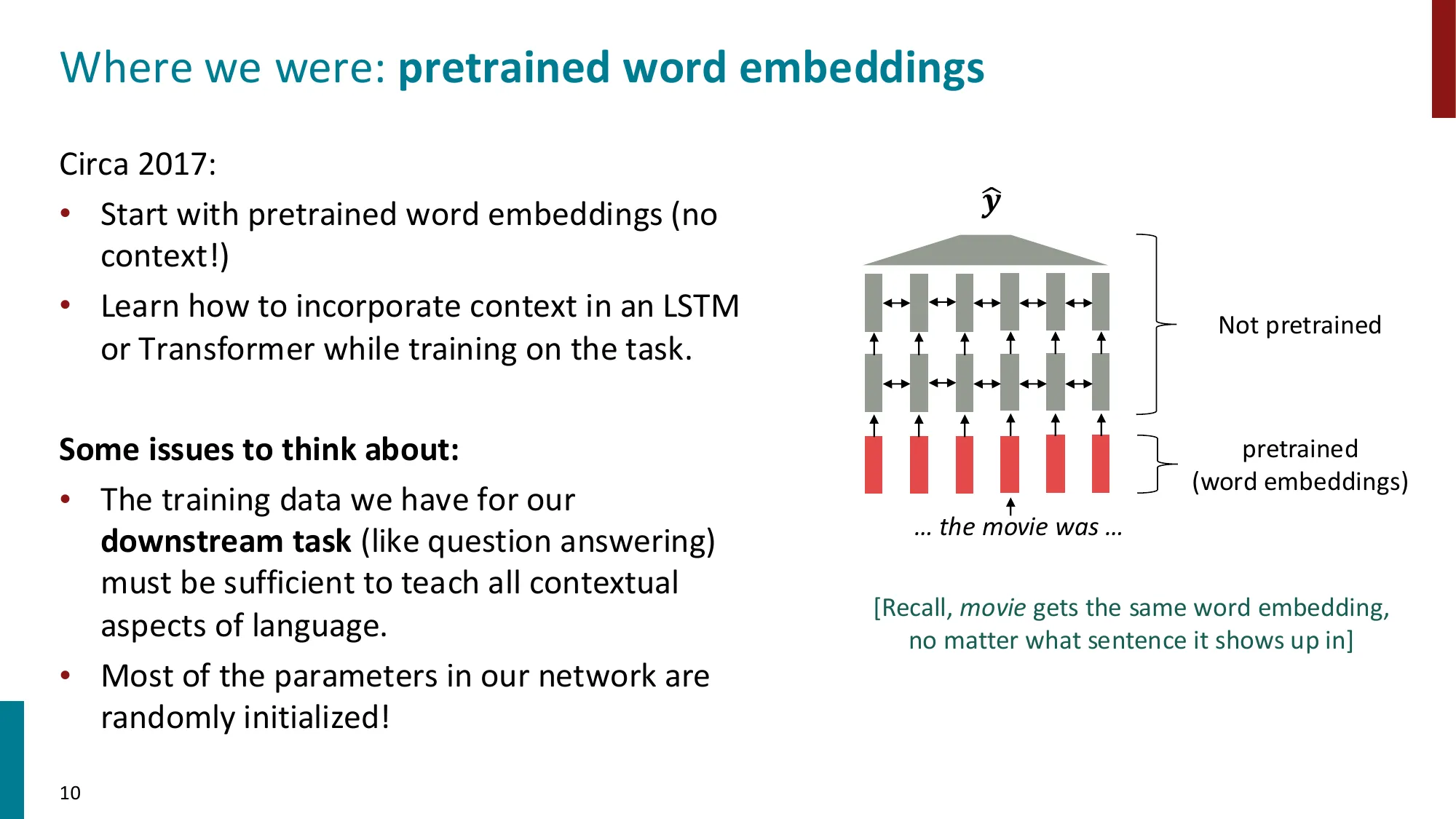
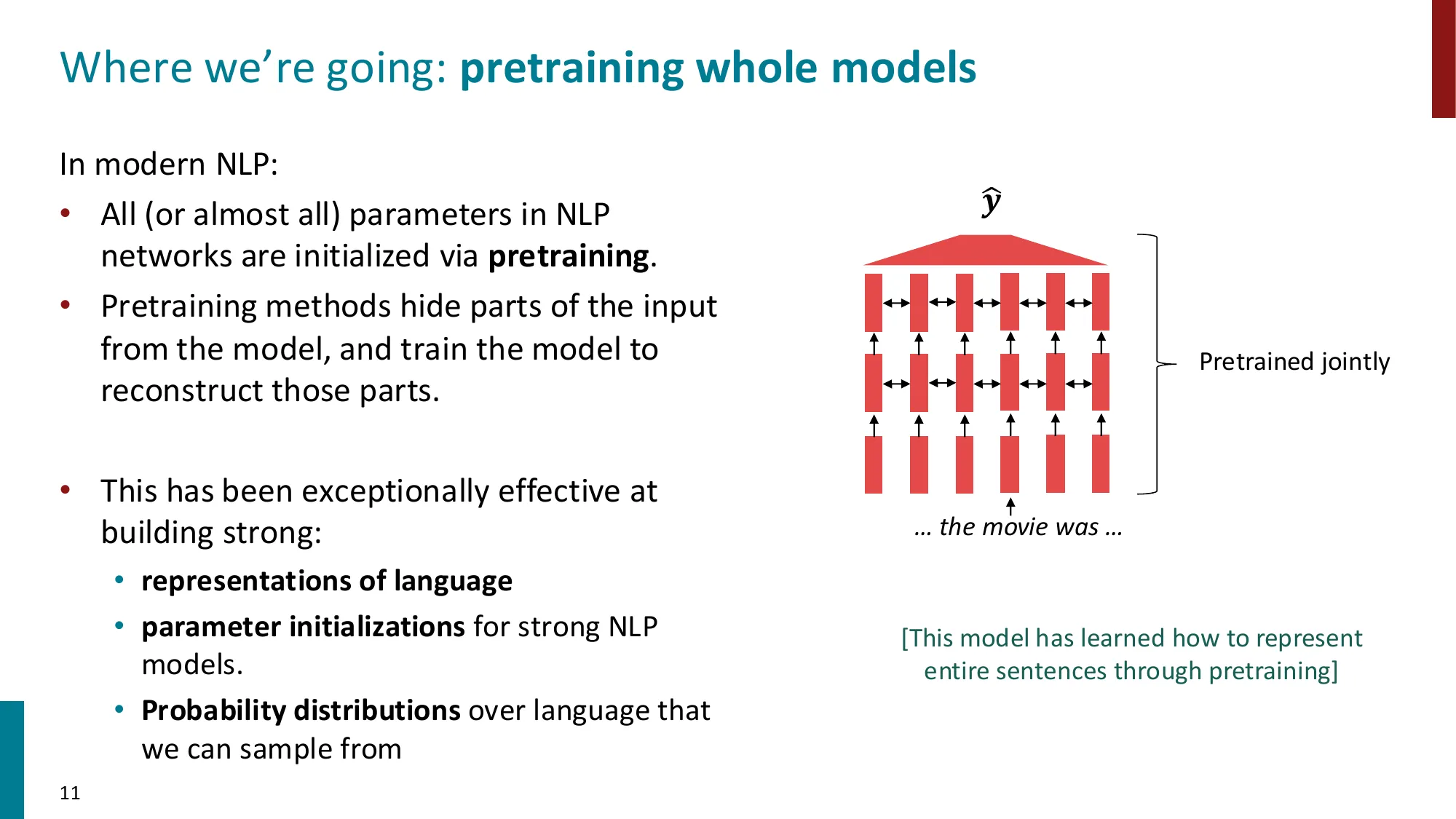





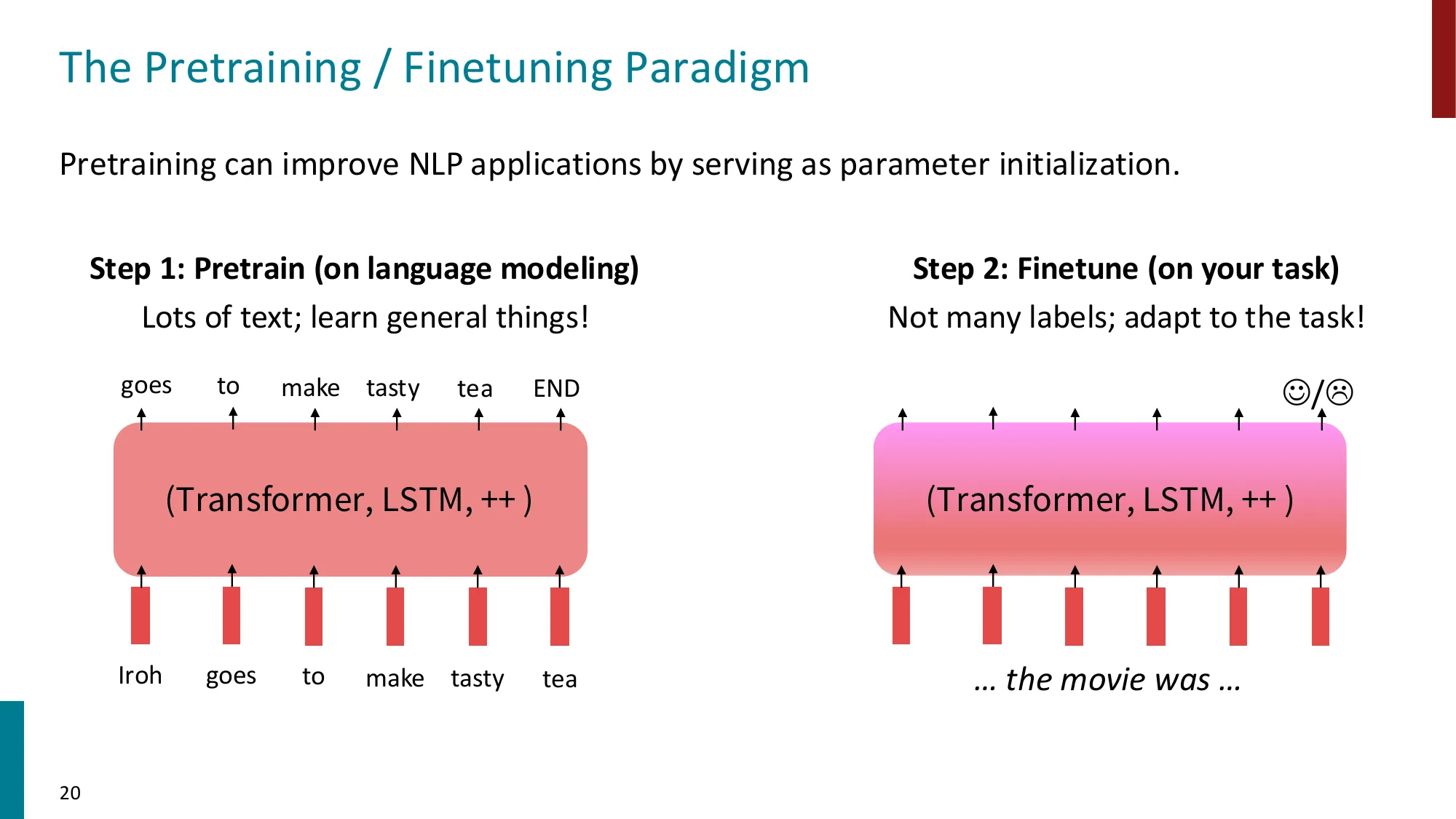
- 2017 年之前:仅预训练词嵌入层(如 Word2Vec、GloVe),其余参数随机初始化
- 问题:同一词在不同上下文中意义不同(“I record the record”)
- 现代方法:预训练整个模型,学习上下文化的语言表示 + 参数初始化 + 语言概率分布
📐 MLM 与 CLM 目标函数对比
Masked Language Modeling(BERT 类):
随机选择 15% 的 token 位置集合 ,要求模型从未被遮盖的上下文中预测这些位置的原始 token:
其中 表示去掉 mask 位置后的序列,注意力是双向的(每个位置可看到所有非 mask 位置)。
Causal Language Modeling(GPT 类):
给定前缀预测下一个 token,注意力通过 causal mask 强制单向:
关键区别:
- MLM:每个样本可以提供 15% × T 个训练信号,但需要特殊的 [MASK] token(预训练-微调不一致)
- CLM:每个样本只提供 T 个训练信号,但可以直接用于自回归生成,无训练-推理差异
📚 已收录至 拓展阅读知识库
🔢 BERT 的 [MASK] 策略数值示例
句子:“The cat sat on the mat”(6 个 token)
15% 采样:选 1 个位置,假设选中 “cat”(位置 2)
替换策略(每次独立随机):
- 80% 概率 →
[MASK]:输入变为 “The [MASK] sat on the mat” - 10% 概率 → 随机词(如 “dog”):输入变为 “The dog sat on the mat”
- 10% 概率 → 保持不变:输入仍为 “The cat sat on the mat”
三种情况下,模型均需在位置 2 输出原始词 “cat” 的概率最大化。
训练信号计算:设词表大小 ,模型在位置 2 输出 softmax 分布,最大化 。
💡 为什么这样做?
为什么 BERT 要 10% 保持原词? 如果只有 [MASK] 情形,模型会学到一个”捷径”——只在看到 [MASK] 时才认真预测,对其他 token 可以偷懒。10% 保持不变迫使模型对每一个 token 都维持上下文理解,因为任何位置都可能是”需要预测的位置”。这是一种精心设计的正则化技巧。
为什么 10% 随机替换? 在 fine-tuning 时,真实输入永远不包含 [MASK],随机替换有助于缩小预训练和微调之间的输入分布差距。
⚠️ 常见误区
-
误区:MLM 和 CLM 只是”双向 vs 单向”的简单区别 → 正确:两者有根本性的应用场景分歧。MLM 无法直接进行自回归生成(没有统一的 可供采样);CLM 在做分类等理解任务时天然处于劣势,因为每个 token 只能看到左侧上下文。
-
误区:BERT 的预训练-微调不一致([MASK] 仅在预训练出现)是无关紧要的 → 正确:这是 BERT 的真实局限,RoBERTa 通过动态 masking(每次 epoch 重新随机 mask,而非固定)部分缓解了这个问题。
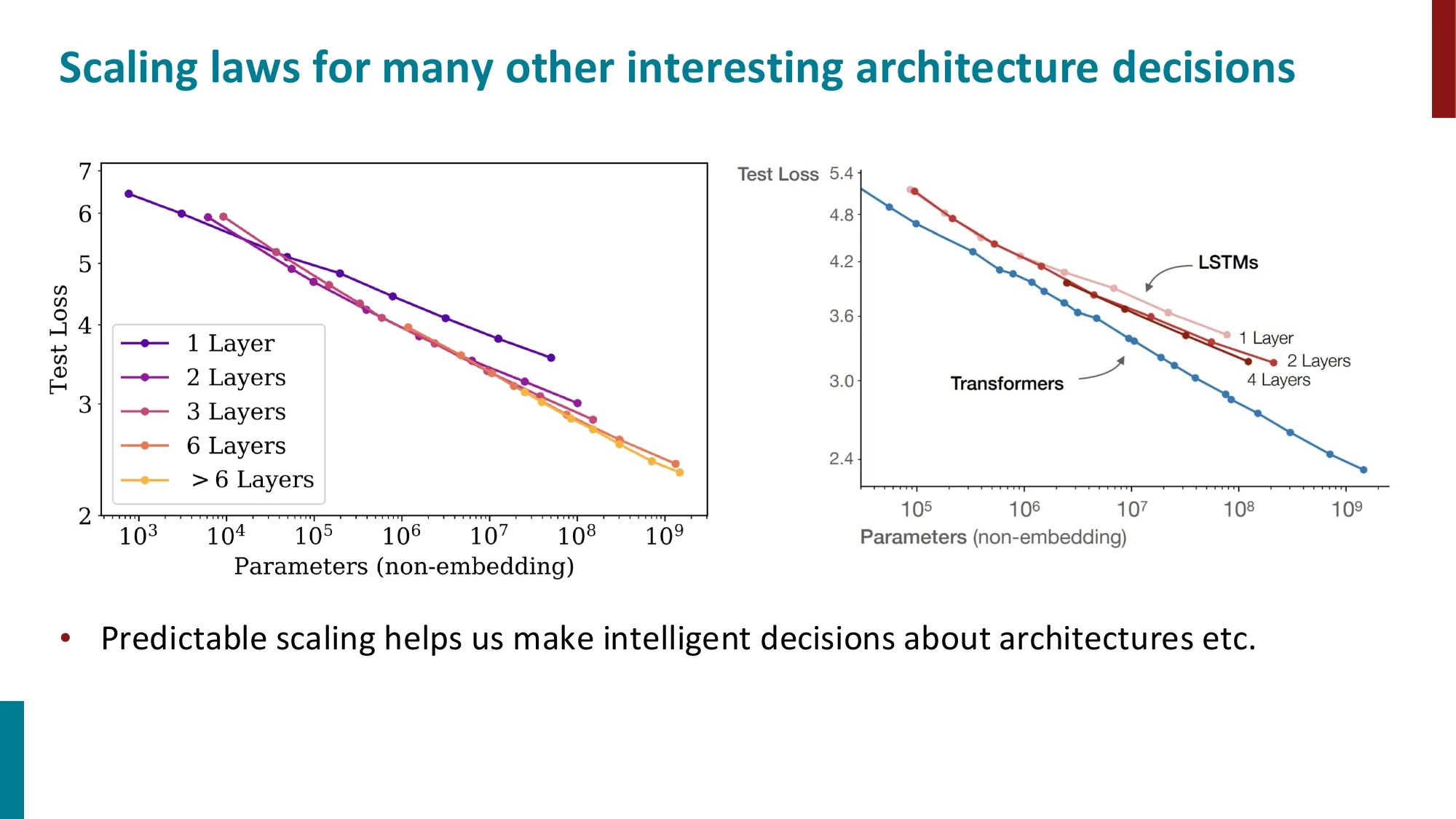
4. 三种预训练架构
Encoder(编码器)




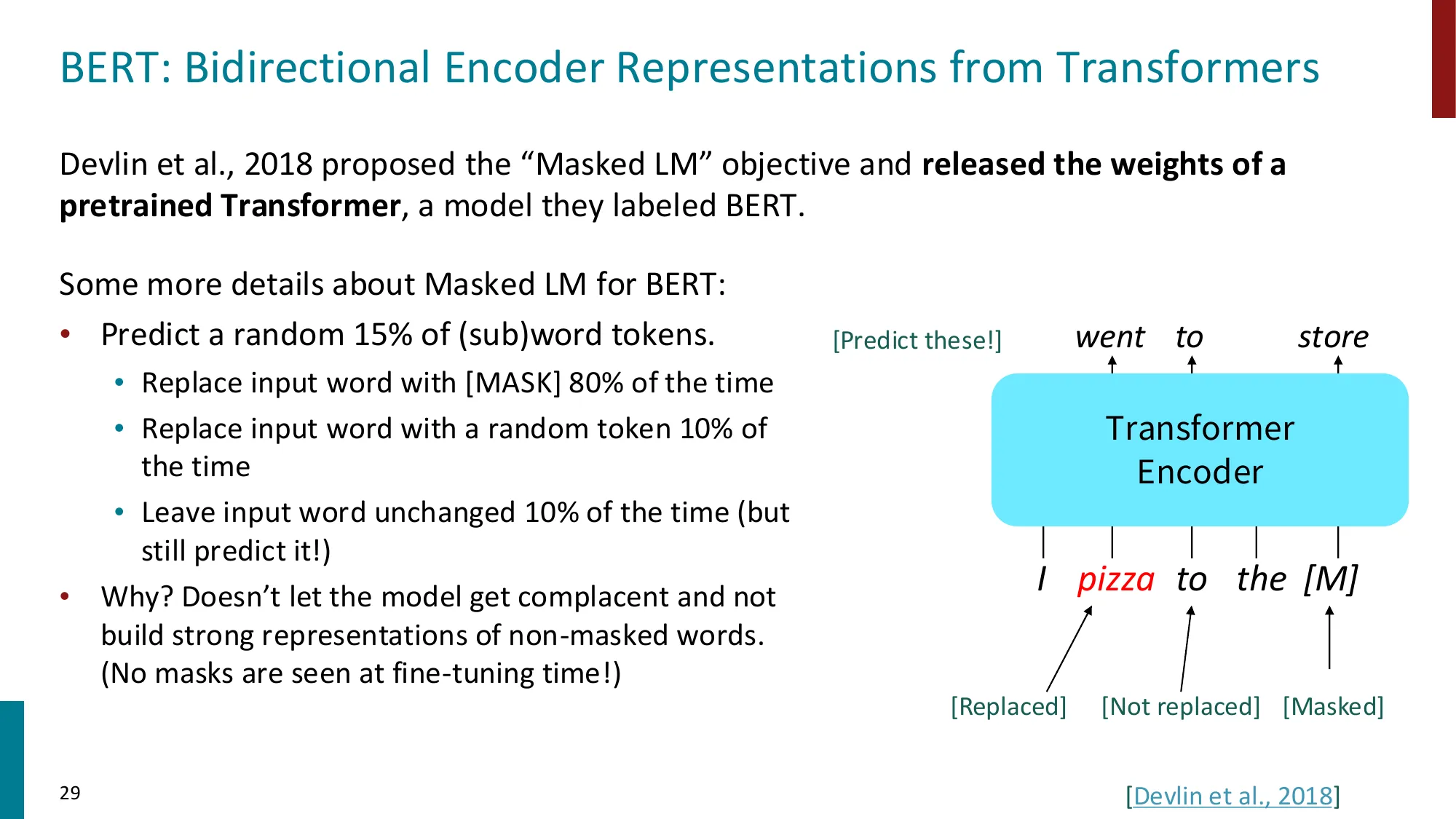
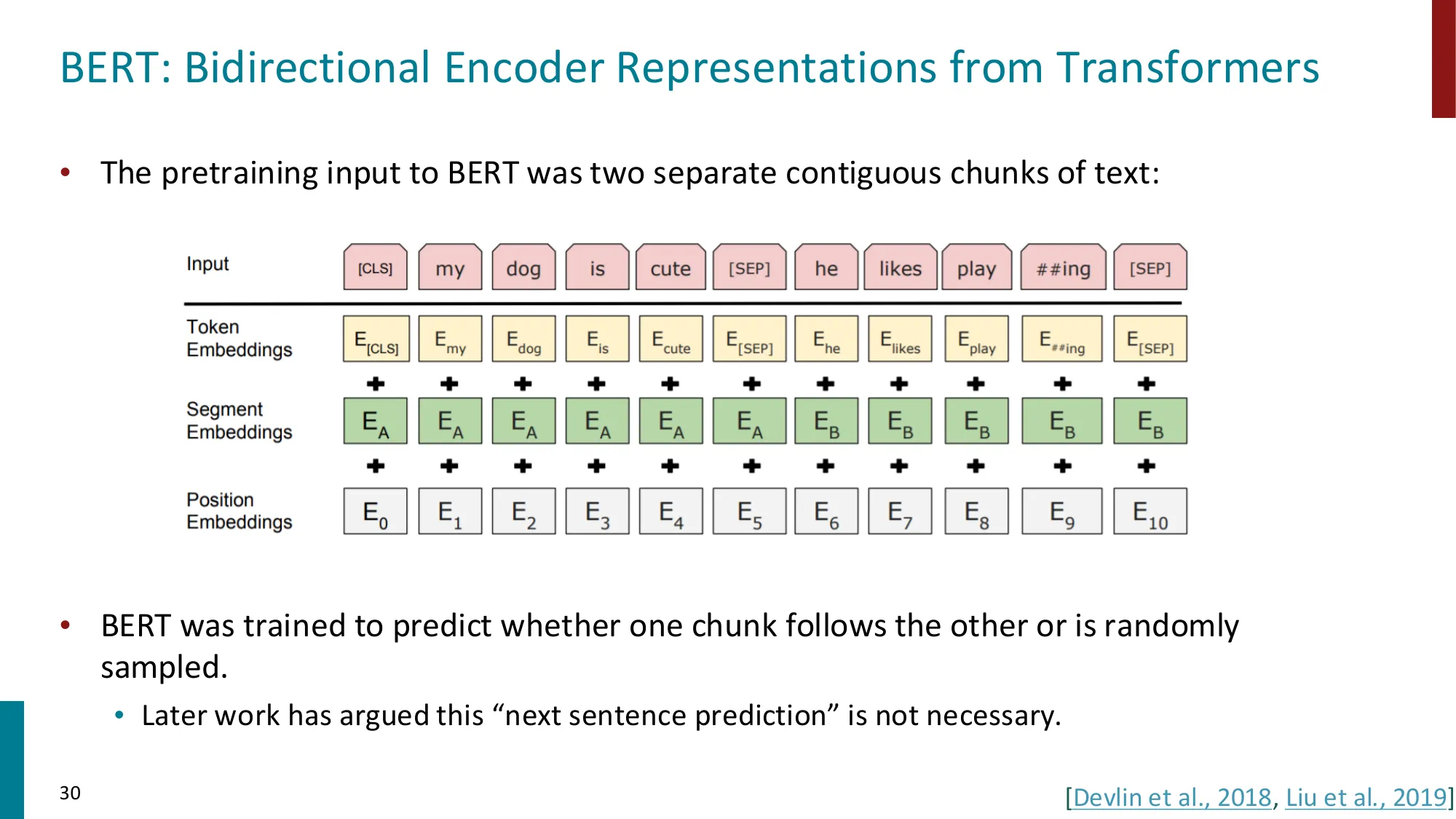

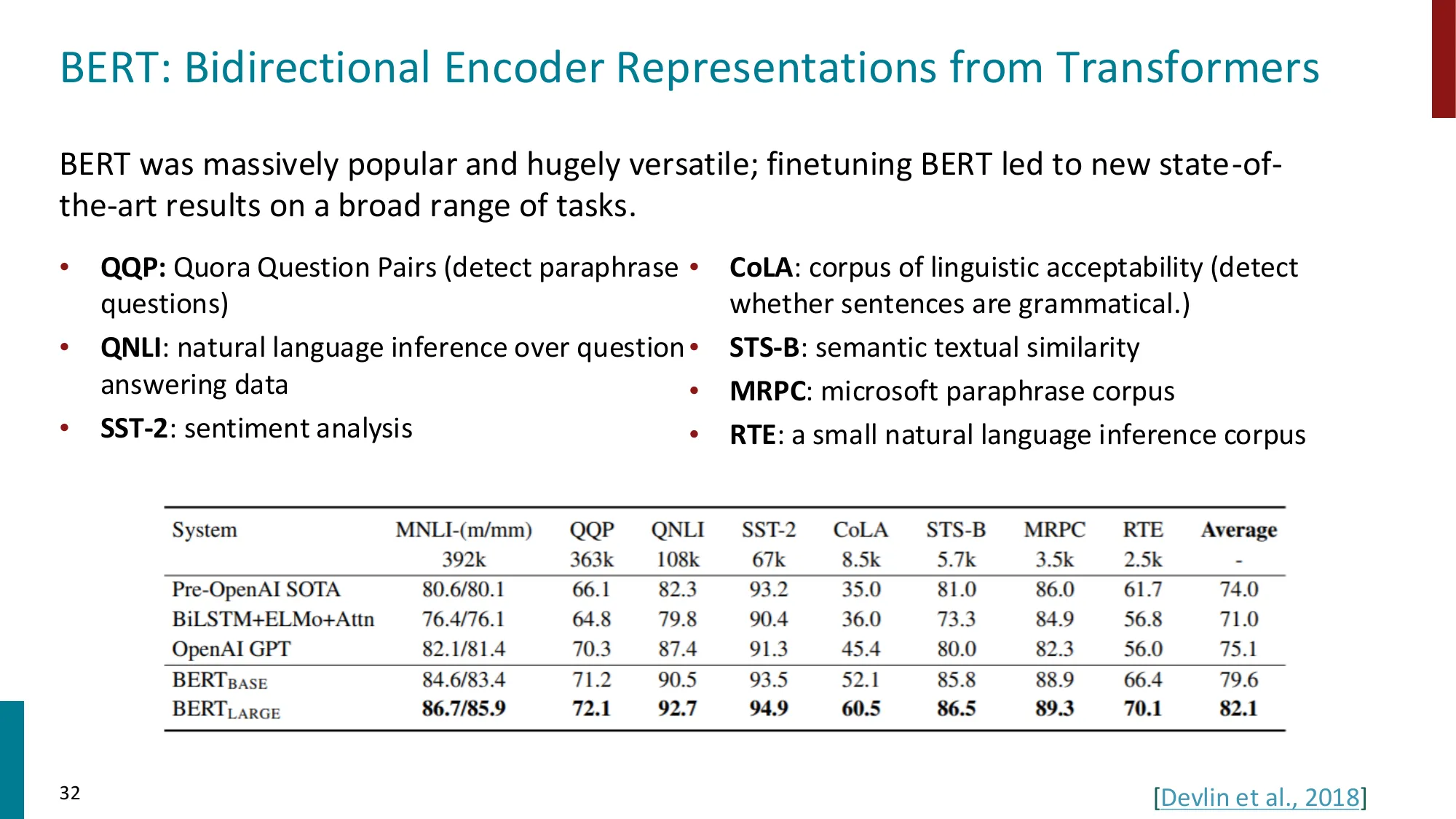

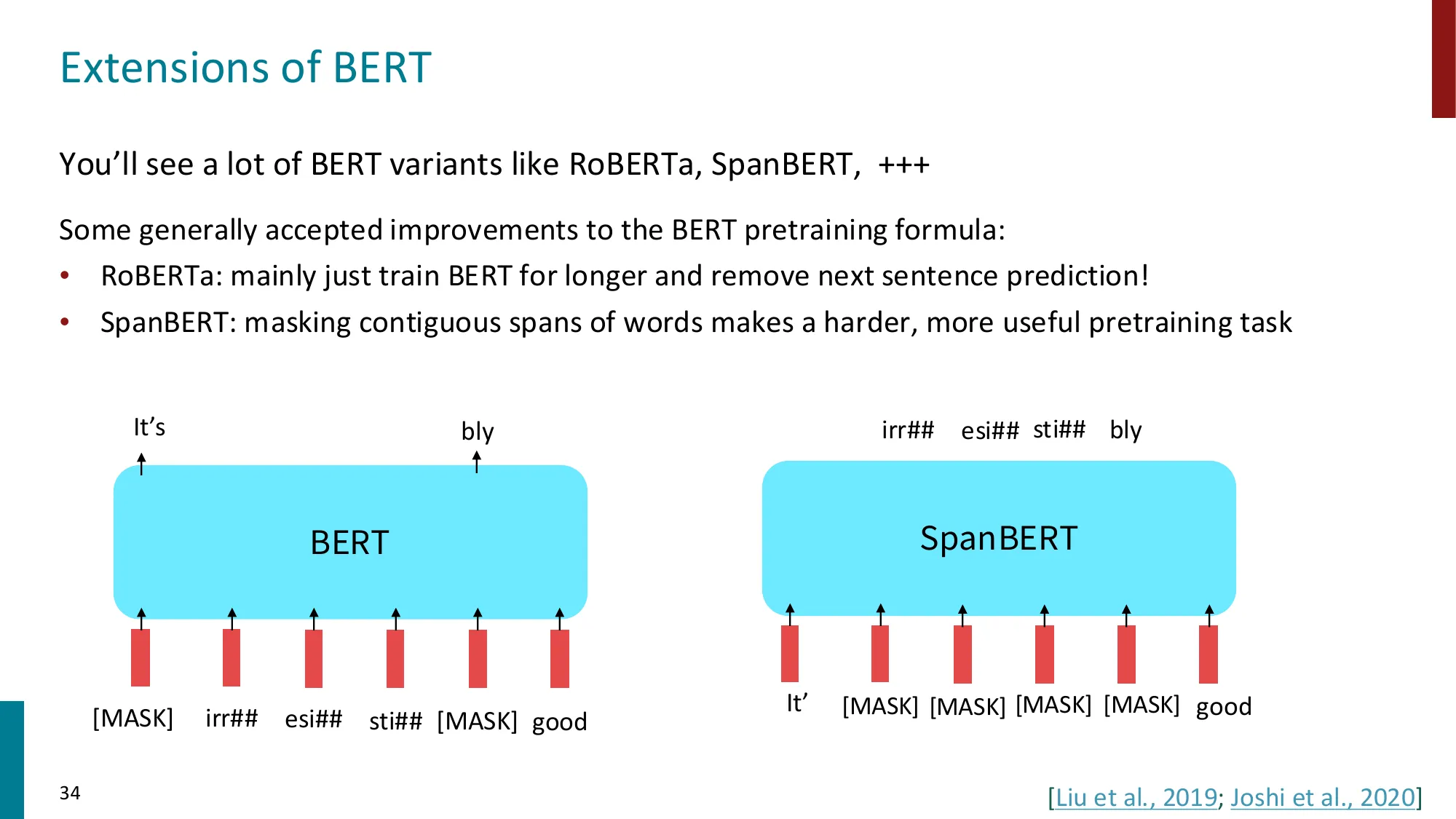

- 双向上下文,适合理解任务
- 预训练目标:Masked Language Model (MLM),随机遮盖 15% token 并预测
- 代表:BERT(110M/340M 参数,BookCorpus + Wikipedia)
- BERT 遮盖策略:80% [MASK] + 10% 随机替换 + 10% 保持不变
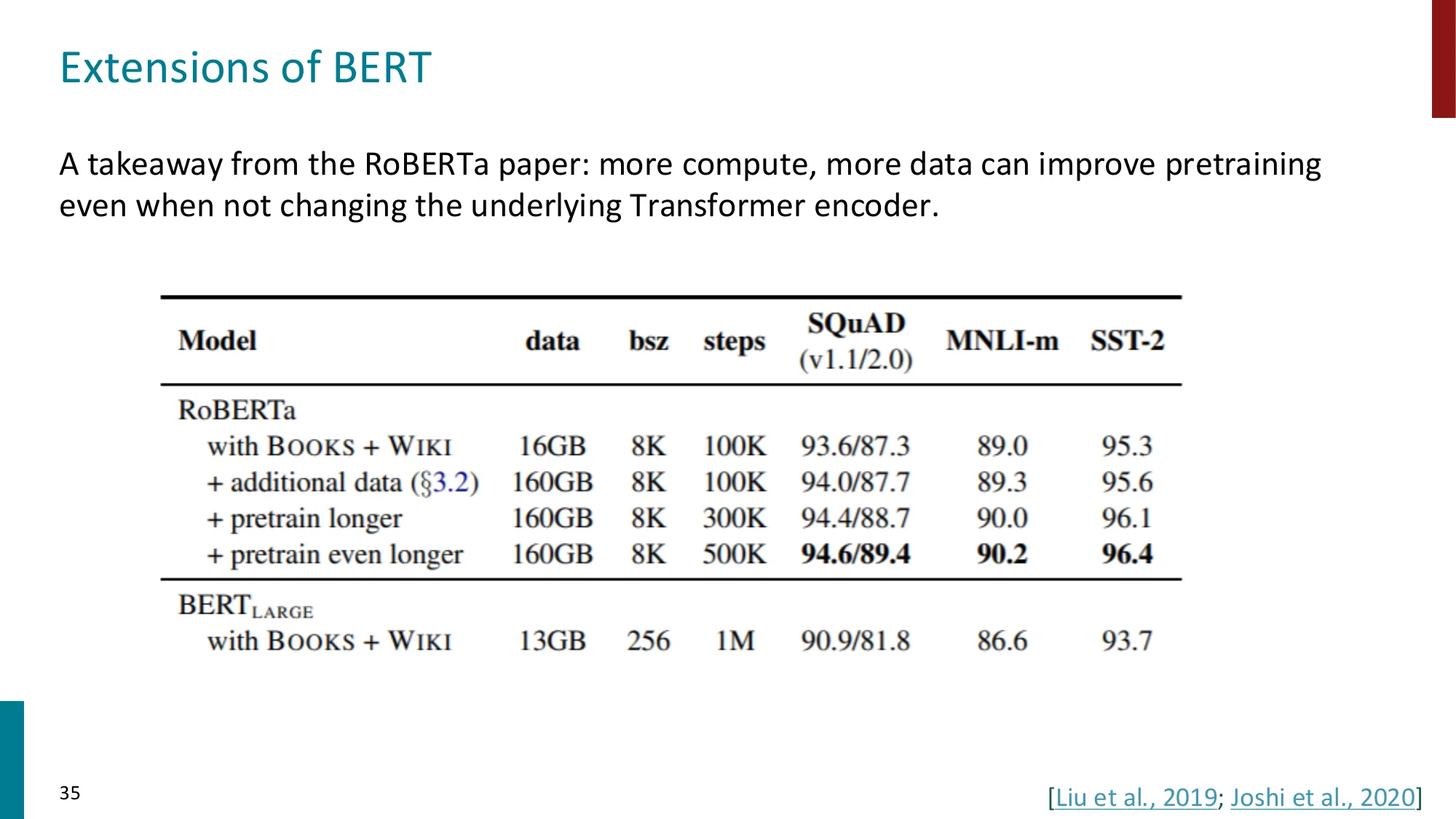
- 扩展:RoBERTa(更长训练、移除 NSP)、SpanBERT(连续 span 遮盖)
- GLUE 基准上全面 SOTA,但不适合生成任务
Encoder-Decoder(编码器-解码器)

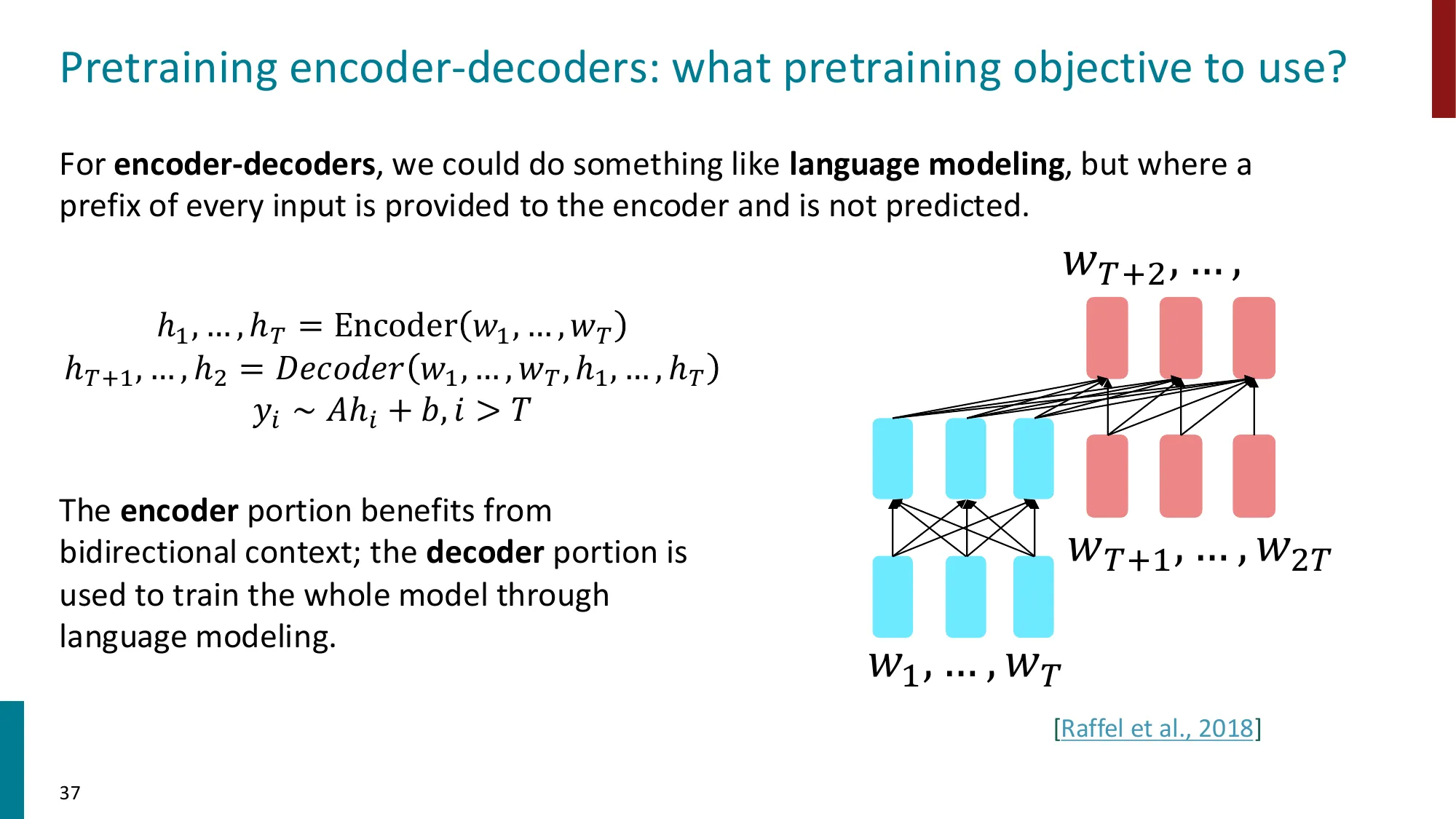
- 编码器提供双向上下文,解码器做自回归生成
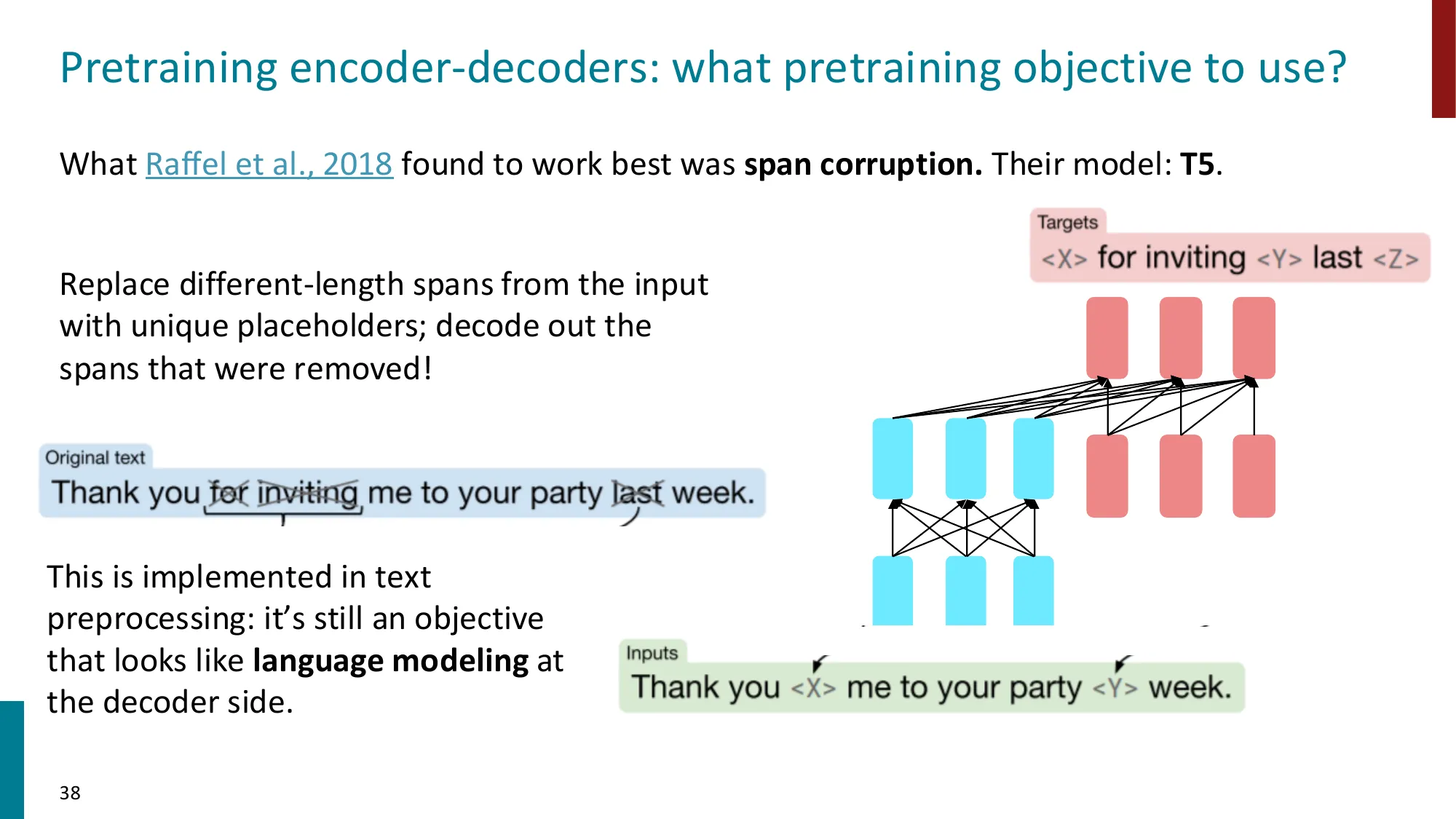
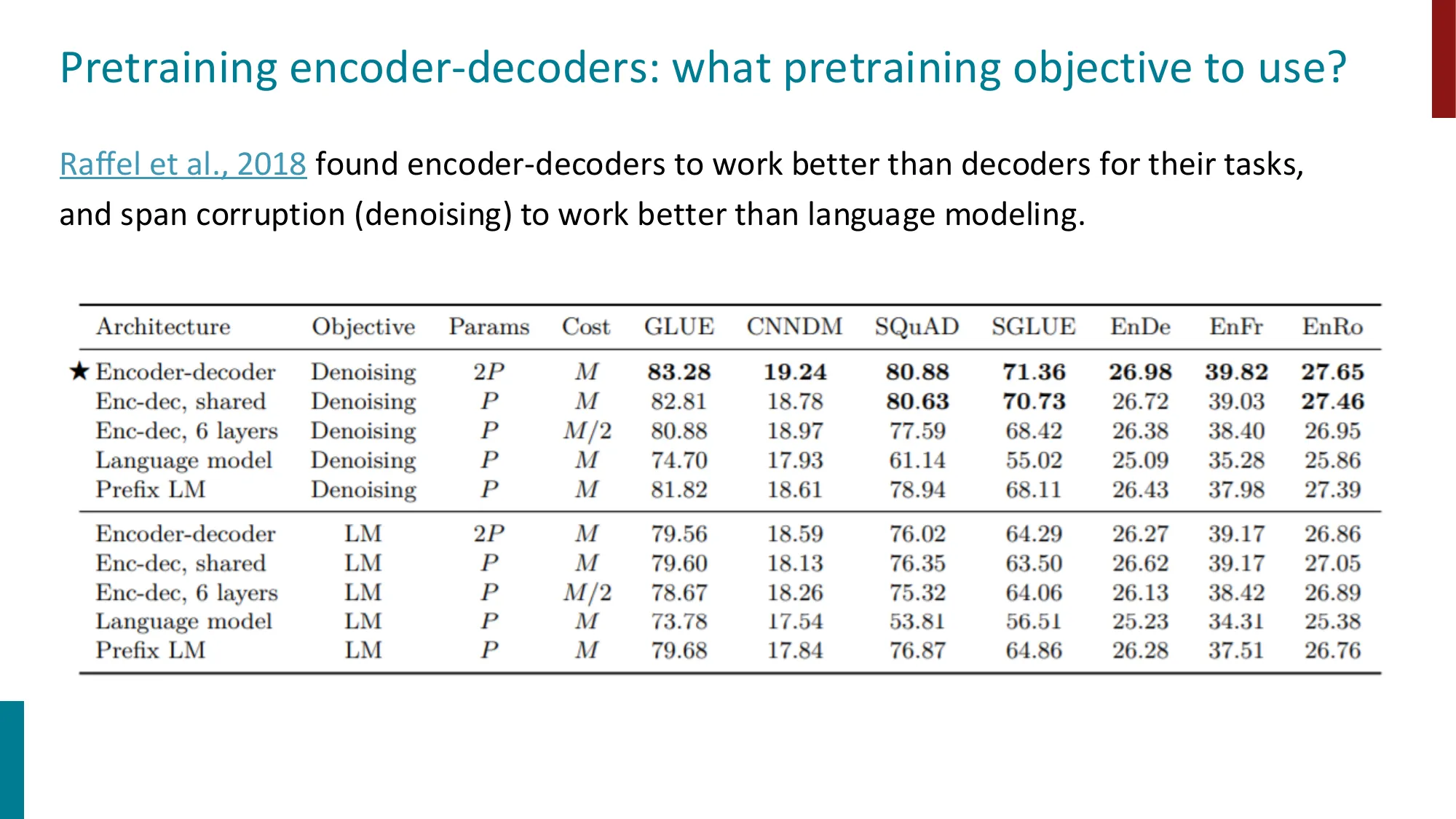
- 代表:T5(Raffel et al., 2018),预训练目标为 span corruption(用占位符替换 span,解码器生成被删除的 span)
- T5 发现 encoder-decoder + denoising 优于纯 decoder + LM
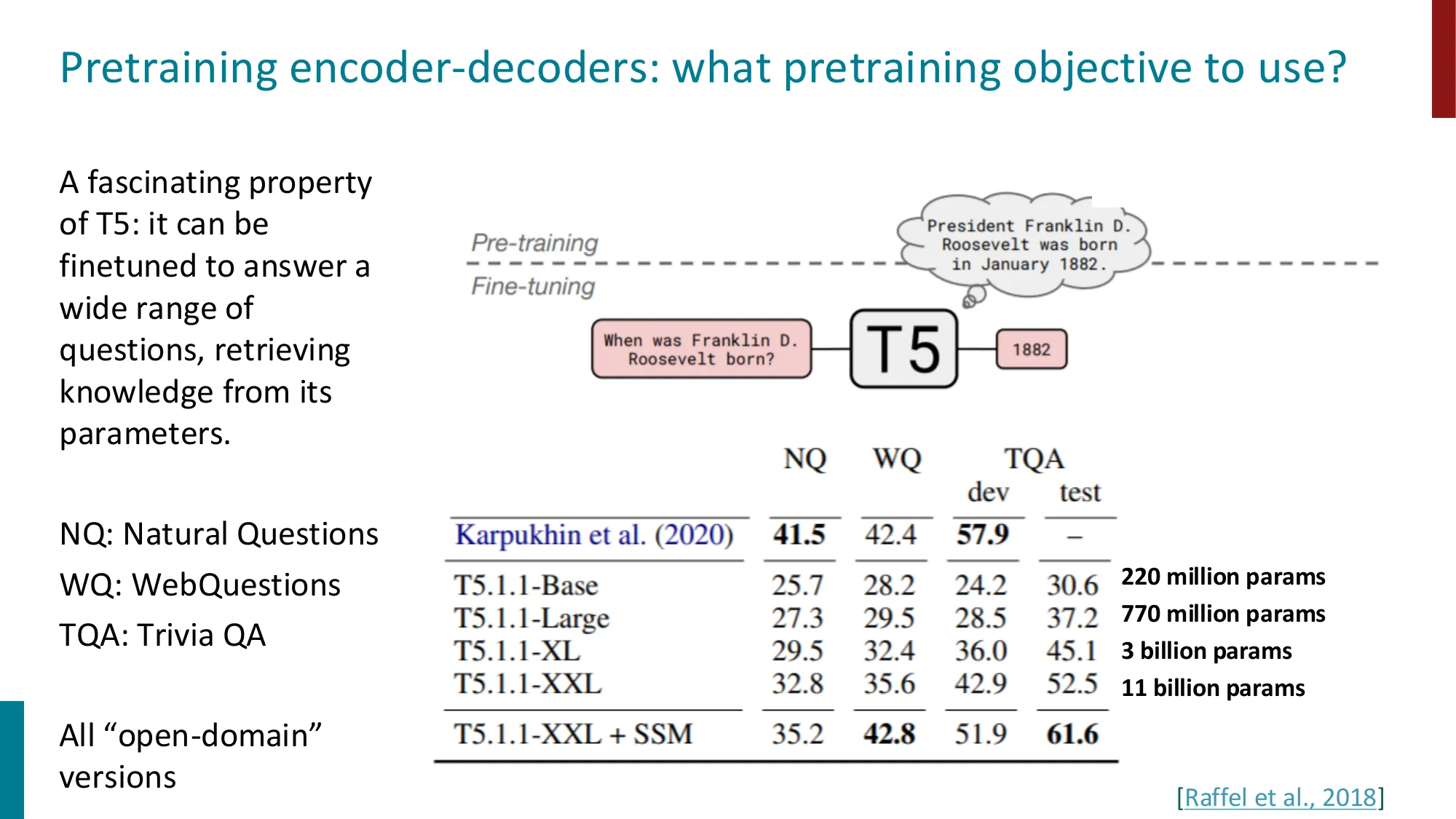
- T5 可微调回答开放域问题,知识存储在参数中
Decoder(解码器)
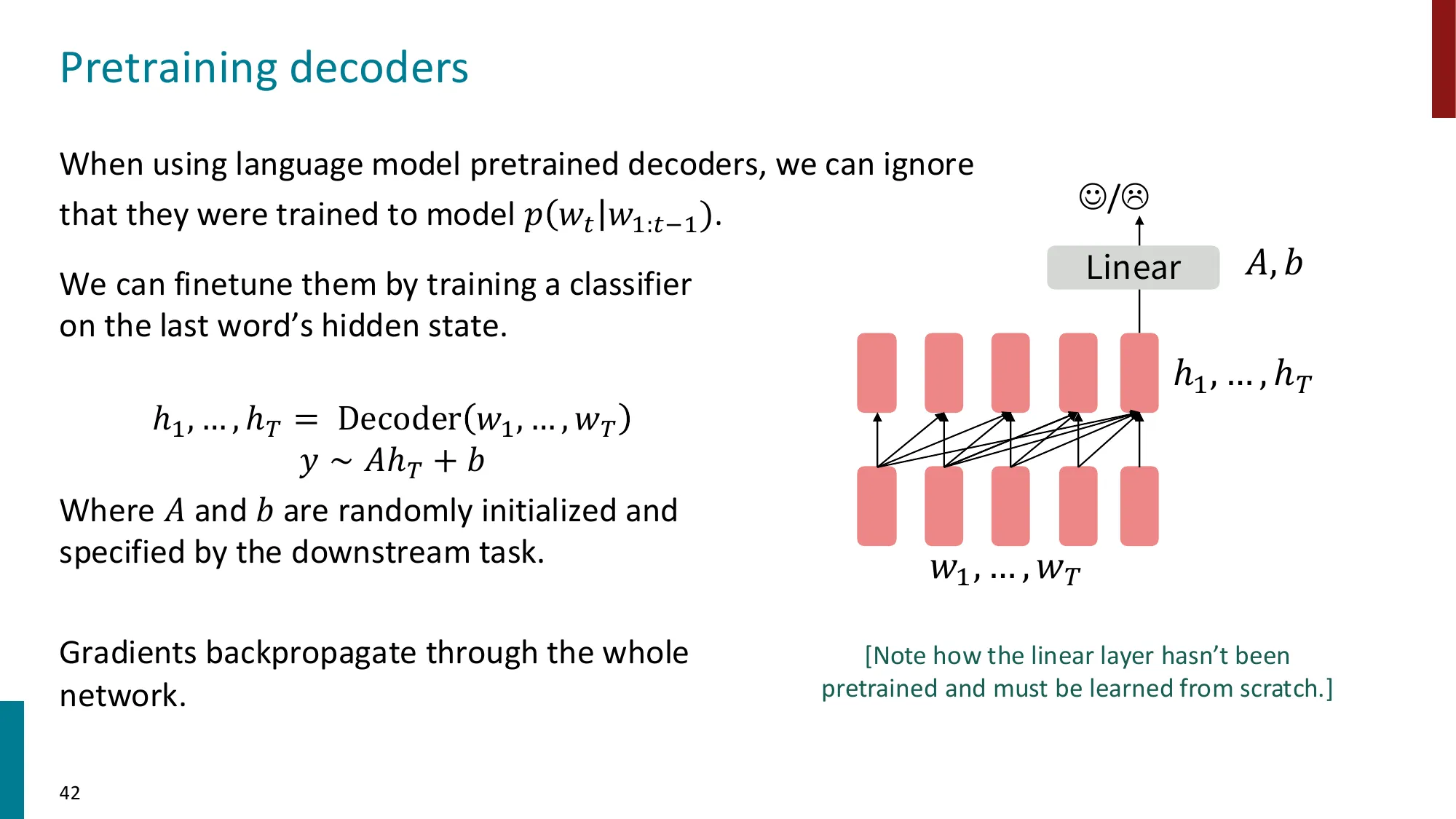






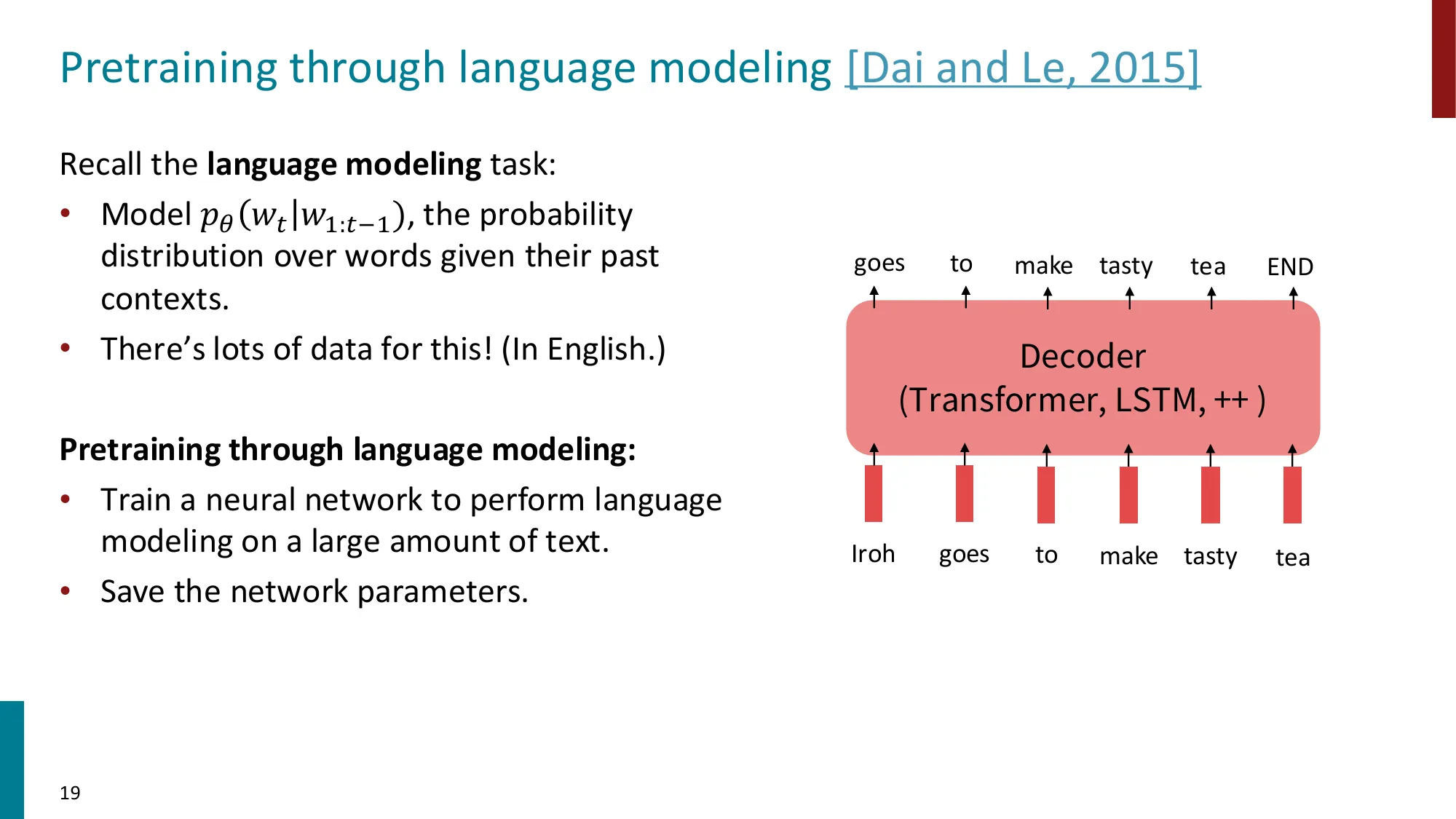
- 单向自回归,适合生成任务
- 预训练目标:标准语言建模
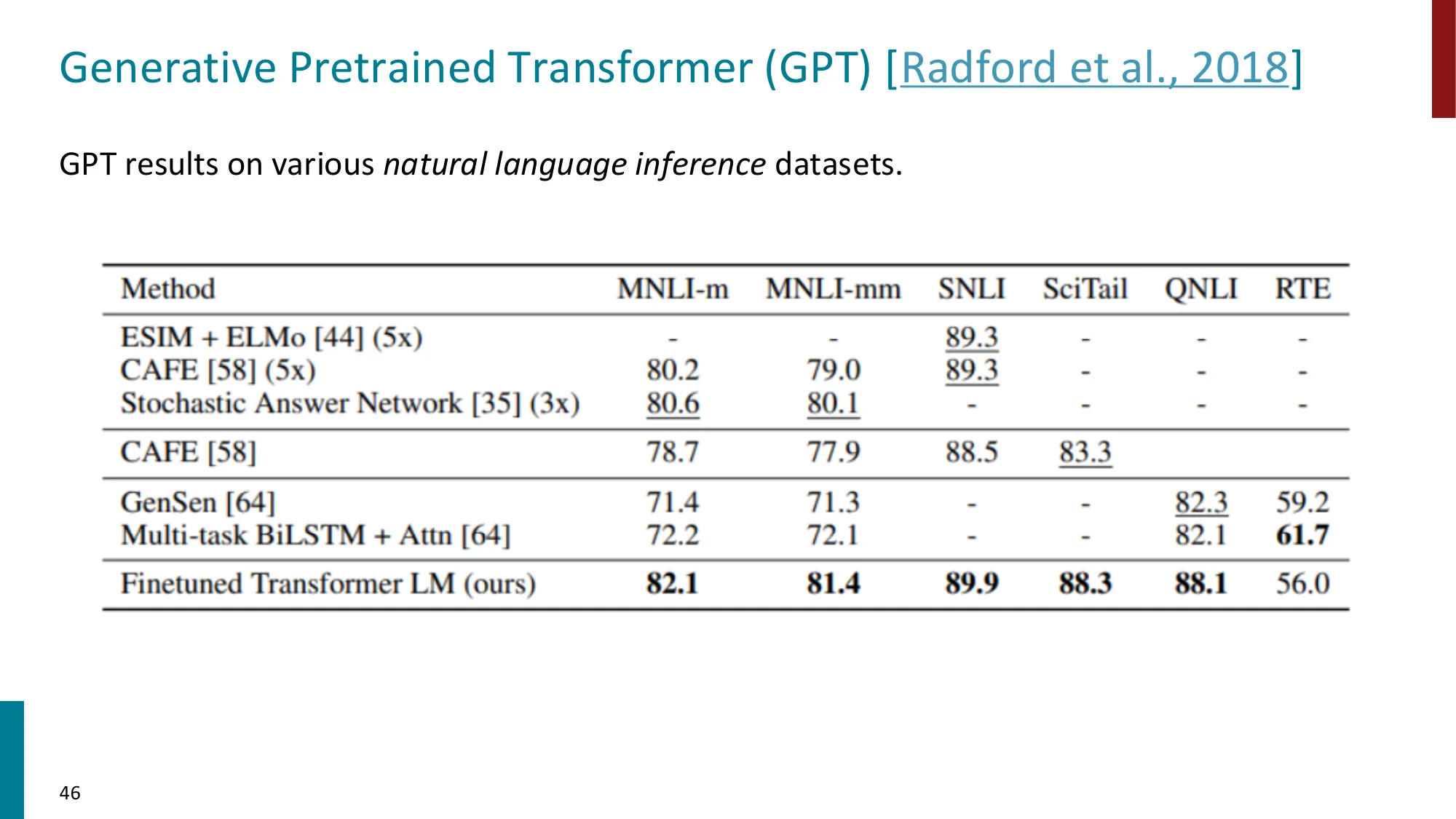
- GPT 演进:GPT (117M) -> GPT-2 (1.5B) -> GPT-3 (175B)
- 涌现能力:Zero-shot learning(GPT-2)、Few-shot / In-context learning(GPT-3)
- 当前最大的预训练模型几乎全是 Decoder
📐 三种架构的形式化对比
Encoder-only(BERT):双向注意力,输出每个位置的上下文表示:
注意力矩阵 ,无 mask(每个位置可看全局)。
Decoder-only(GPT):单向注意力(causal mask),输出自回归概率:
Encoder-Decoder(T5):encoder 双向处理输入,decoder 通过 cross-attention 条件生成:
参数规模对比(以 hidden=768, L=12, H=12 为基准):
| 模型 | 参数量 | 架构 | 预训练目标 |
|---|---|---|---|
| BERT-Base | 110M | Encoder-only | MLM + NSP |
| GPT-2-Base | 117M | Decoder-only | CLM |
| T5-Base | 250M | Encoder-Decoder | Span Corruption |
T5 参数量约为同规格 BERT 的 2.3 倍,因为 encoder 和 decoder 各自都有完整的 Transformer 层。
📚 已收录至 拓展阅读知识库
🔢 同一问题在三种架构下的处理
任务:将 “cat” 翻译为法语
Encoder-only(BERT):
输入: [CLS] translate 'cat' to French [SEP]
输出: [CLS] 的表示向量(无法直接生成)
→ 需要加一个线性分类头预测目标词(从词表中分类),不适合翻译Decoder-only(GPT):
输入: "Translate 'cat' to French:"
输出: 直接自回归生成 "chat"(逐 token 采样)
→ P("chat" | prompt) = P("ch"|prompt) × P("at"|"ch", prompt)Encoder-Decoder(T5):
Encoder 输入: "translate English to French: cat"
Encoder 输出: 双向上下文表示 H_enc
Decoder: 逐步生成,每步 cross-attend 到 H_enc
→ 输出: "chat"💡 为什么这样做?
没有”最好”的架构——完全取决于任务。2018-2022 年 NLP 学界偏爱 encoder-only(BERT 系)做理解任务,encoder-decoder(T5 系)做生成任务。2023 年后 LLM 界几乎全面转向 decoder-only,原因有三:(1) 预训练目标更简洁(标准 CLM,无需设计 masking 策略);(2) 更容易 scale(没有 encoder-decoder 间 cross-attention 的额外复杂度);(3) Few-shot / In-context learning 天然适合自回归框架。
⚠️ 常见误区
-
误区:“BERT 比 GPT 更好”或”GPT 比 BERT 更好” → 正确:完全取决于任务类型。BERT 在 GLUE 分类任务上长期 SOTA(2018-2020),GPT-3 在生成/few-shot 上碾压 BERT。用错架构等于拿锤子拧螺丝。
-
误区:Decoder-only 不能做分类任务 → 正确:GPT 可以通过 prompt 工程(如”这段话的情感是正面还是负面?答:“)将分类转化为生成,但通常需要更仔细的 prompt 设计,不如 BERT 的 [CLS] token 方案直接。
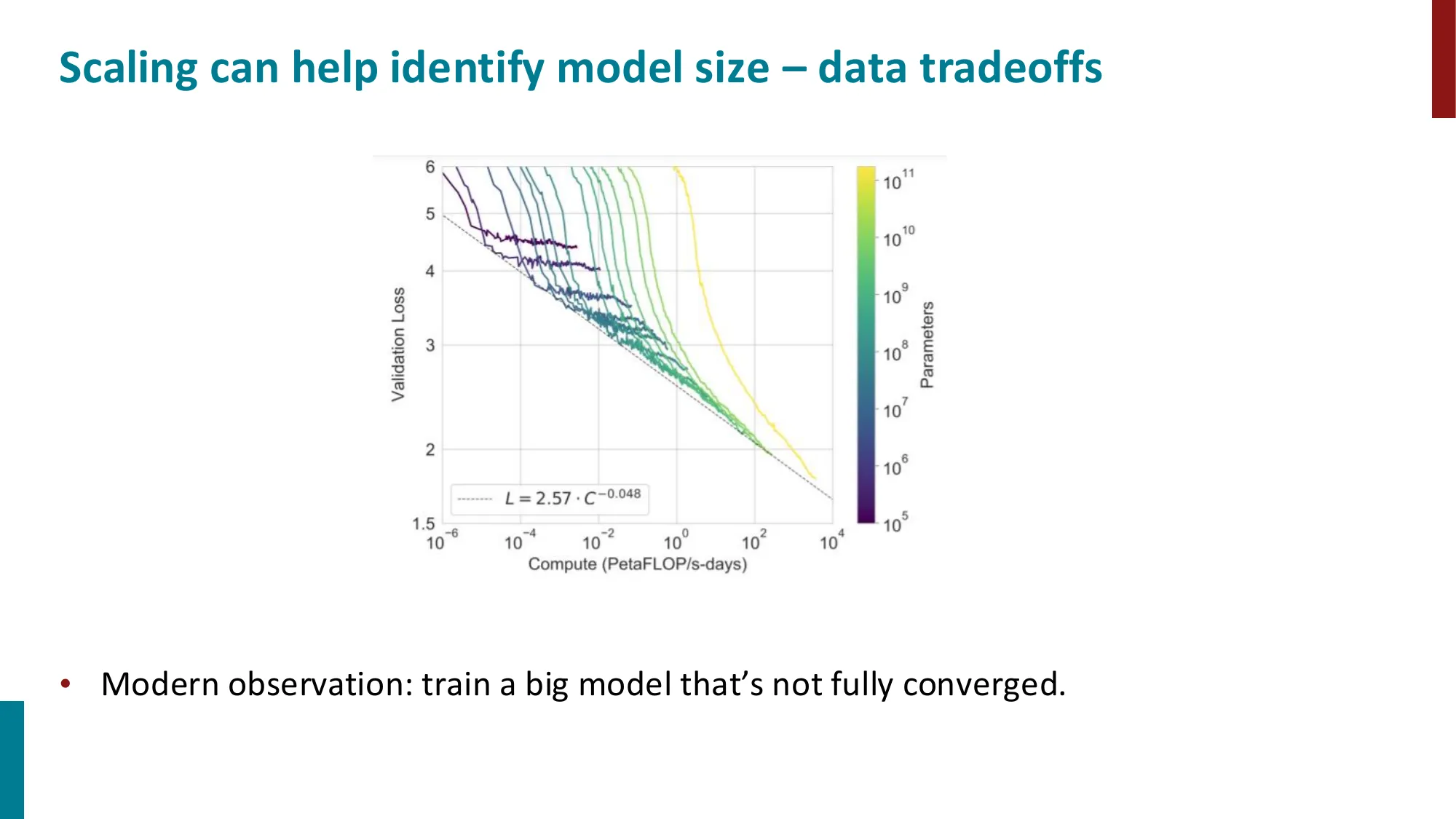
5. 预训练数据
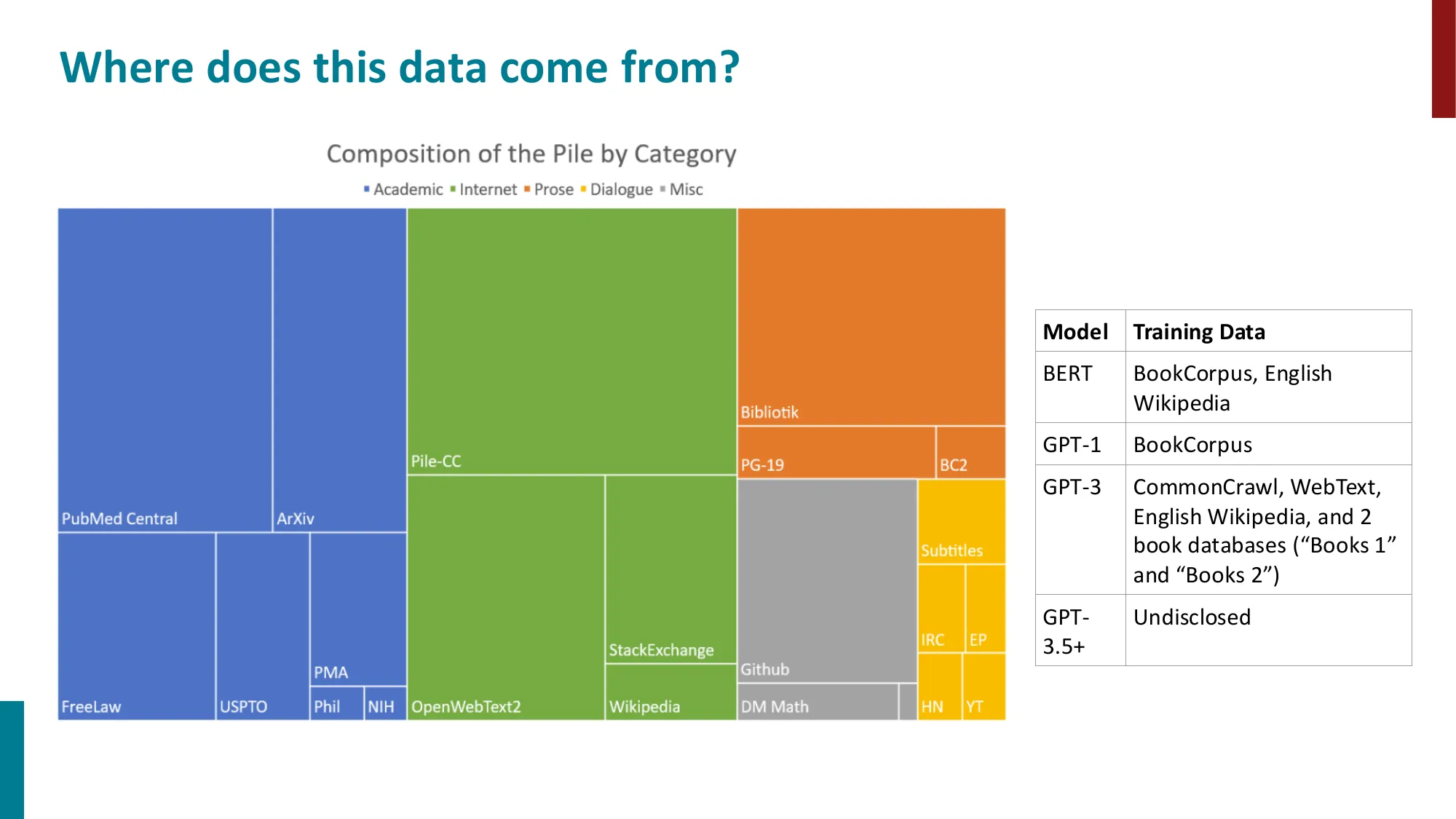
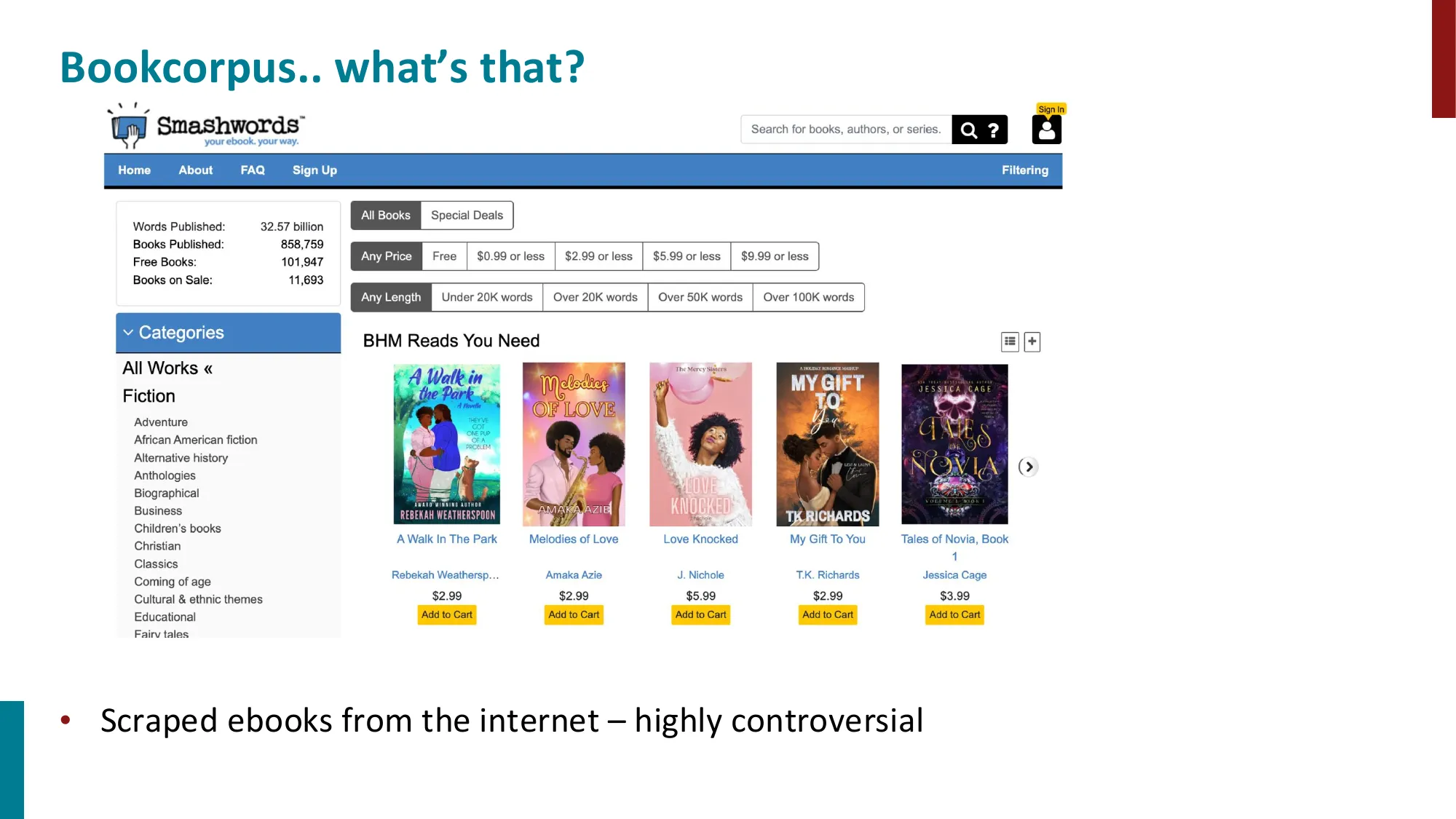
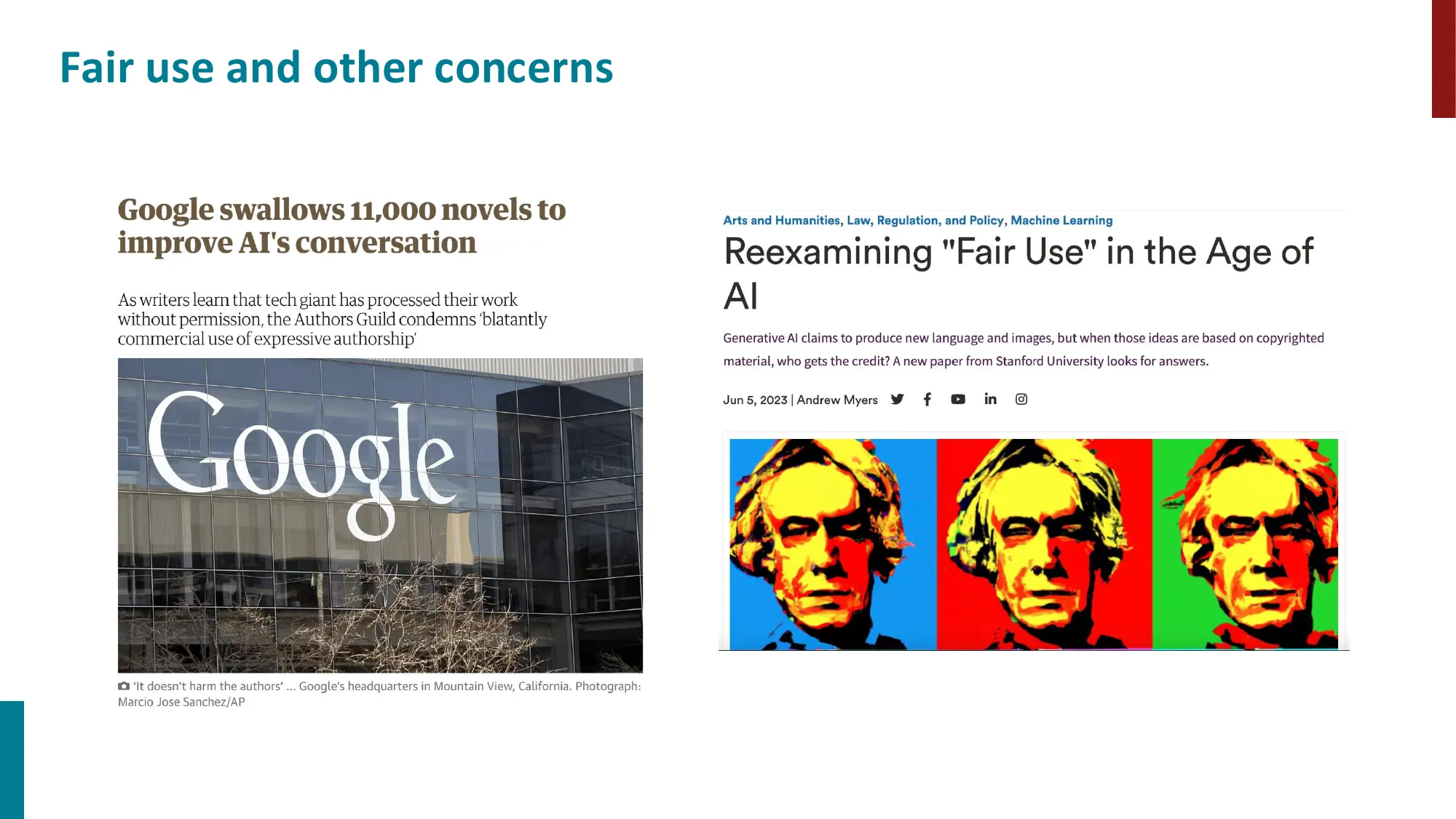
- The Pile 数据集:学术、网络、散文、对话等多类别
- 不同模型的训练数据量:BERT 3B token -> RoBERTa 30B -> GPT-3 200B -> Chinchilla 1.4T
- BookCorpus 的版权争议与 Fair Use 问题
📐 数据混合比例的优化框架
问题形式化:设有 个数据源 ,混合权重 ,满足 。
训练损失为各数据源损失的加权和:
目标是最小化在目标评估集(如多个下游任务)上的损失:
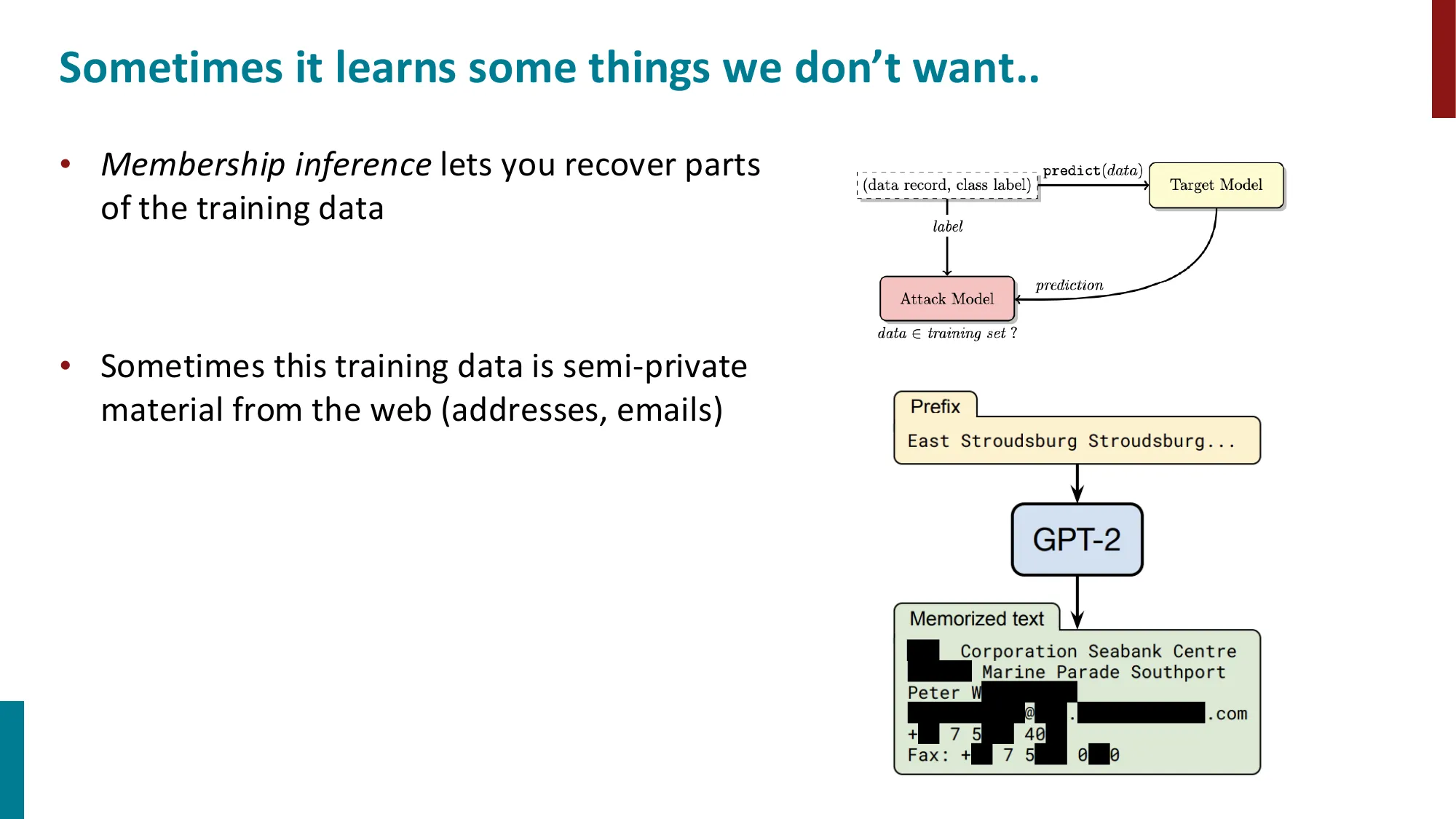
重复数据的危害:若数据 重复 次,等效权重从 变为 (归一化后),模型可能记忆训练样本(memorization),在成员推断攻击(membership inference)中表现脆弱。
Chinchilla 最优比例(Hoffmann et al., 2022):在固定算力预算 (FLOPs)下:
即模型参数量和训练 token 数应等比例增长,最优比约为 20 tokens per parameter。
📚 已收录至 拓展阅读知识库
🔢 Llama 3 数据来源分布(近似公开信息)
| 数据来源 | 占比 | 说明 |
|---|---|---|
| Common Crawl(网页) | ~80% | 经过质量过滤,去重 |
| GitHub 代码 | ~8% | 多语言代码 |
| Wikipedia / 书籍 | ~10% | 高质量长文本 |
| arXiv / StackExchange 等 | ~2% | 专业知识密集型 |
关键洞察:代码数据仅占 8%,但 Llama 3 的代码能力远超其比例暗示的水平。原因是代码数据的信息密度和质量远高于普通网页文本:代码有明确的逻辑结构、注释和测试,每个 token 携带的信息量更高。等效地,8% 的高质量代码数据的训练效益可能相当于 20%+ 的普通文本。
💡 为什么这样做?
数据是当代 LLM 的核心竞争壁垒,甚至比模型架构更重要。高质量数据形成正向飞轮:好模型吸引用户 → 用户交互产生高质量 feedback 数据 → 用于 RLHF 训练更好的模型。Google Search、OpenAI ChatGPT、Anthropic Claude 的核心优势都与数据飞轮紧密相关。这也解释了为什么数据来源的版权问题(如 The New York Times 起诉 OpenAI)是 AI 行业的核心法律争议。
⚠️ 常见误区
-
误区:“更多数据总是更好” → 正确:Chinchilla 论文(Hoffmann et al., 2022)证明,在固定算力下盲目扩大模型(如 Gopher 280B)而不匹配增加数据是浪费。最优策略是模型大小和数据量按比例增长(约 20 tokens/parameter)。GPT-3(175B 参数,300B tokens)按此标准是严重 undertrained 的。
-
误区:数据去重只是工程问题,不影响模型质量 → 正确:重复数据会让模型过拟合并产生逐字记忆(verbatim memorization),这不仅影响泛化能力,还有隐私和版权风险(模型可被诱导输出训练数据中的个人信息)。
6. Pretraining 教会模型什么?
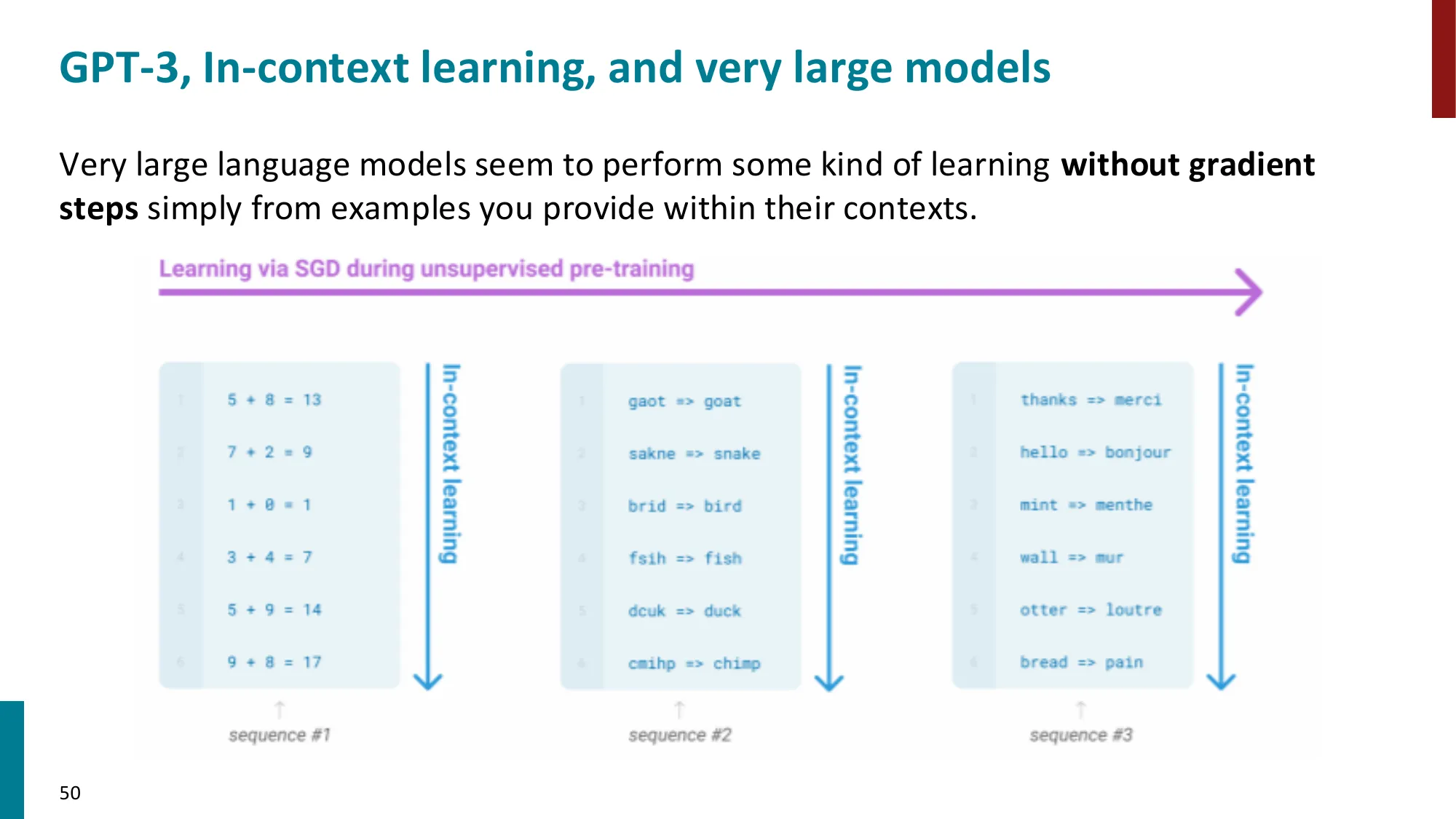




- 通过”完形填空”学习:事实知识、语法、指代、情感、逻辑推理(如 Fibonacci 序列)
- 语言模型即世界模型?可解数学题、写代码、规划菜单
🔢 词义消歧(WSD)探针实验
实验(Tenney et al., 2019,BERT Rediscovers the Classical NLP Pipeline):
对 “bank” 在以下两个上下文中提取 BERT 各层表示:
- 语境 A:“I walked along the bank of the river”(河岸)
- 语境 B:“I deposited money at the bank”(银行)
计算两种语境下 “bank” 表示的余弦相似度(越低说明区分越好):
| 层 | 余弦相似度 | 解读 |
|---|---|---|
| 1 | 0.82 | 几乎无区分(接近静态词向量) |
| 3 | 0.71 | 轻微区分 |
| 6 | 0.45 | 明显区分 |
| 9 | 0.21 | 强烈区分(语义已消歧) |
| 12 | 0.19 | 高层表示充分区分两种词义 |
结论:预训练让模型在高层形成了上下文敏感的词义表示,解决了 Word2Vec 无法区分多义词的根本问题。
💡 为什么这样做?
Pretraining 的本质是通过自监督信号间接学习语言理解的各个子任务——要预测 [MASK] 位置的词,模型必须先”理解”上下文的语法结构(才能正确地预测动词形式)、语义内容(才能预测语义合理的词)和事实知识(才能预测正确的命名实体)。所有这些能力都是作为”副产品”被学到的,而不是通过显式监督信号。这就是 pretraining 的神奇之处——一个简单的目标(预测下一词 / 预测 masked 词)蕴含了丰富的语言学习信号。
⚠️ 常见误区
-
误区:探针准确率高 = 模型”真正理解”了该语言学属性 → 正确:高探针准确率仅说明表示包含了某种信息,不代表模型在做下游任务时使用了这个信息。模型可能走捷径(spurious correlation)而不是真正利用语言学结构。这是 NLP 可解释性研究的核心困境。
-
误区:“语言模型 = 世界模型”,所以它理解物理世界 → 正确:LLM 学到的是文本中关于世界的描述,而非对世界本身的感知或推理。它可以解数学题是因为数学推理步骤在训练文本中大量出现,但这不等同于真正理解数学。Gary Marcus 等批评者将此称为”随机鹦鹉”(stochastic parrot)问题。
推荐阅读
- BERT — Devlin et al., 2018
- Llama3 — Meta, 2024
- Illustrated-BERT — Jay Alammar
- Contextual-Word-Representations — Smith, 2019
- Jurafsky & Martin, Ch10