L02: Word Vectors
Week 1 · Thu Jan 08 2026 08:00:00 GMT+0800 (中国标准时间)
L02: Word Vectors
Slides
中英交替版(推荐)
L02 双语 (PDF)
英文原版
L02 EN (PDF)
中文翻译版
L02 ZH (PDF)
核心知识点
1. 词义表示(How do we represent the meaning of a word?)
- 传统方法:WordNet(同义词集 + 上位词关系)
- 问题:缺乏细微差别、缺少新词、主观性强、无法计算相似度
- 离散符号表示:one-hot 向量
- 向量维度 = 词汇表大小(如 500,000+)
- 问题:任意两个词的 one-hot 向量正交,无法表示相似性
- 解决方案:学习将相似性编码到向量本身
💡 为什么 one-hot 向量不够用?
想象你有 500,000 个词,每个词都是一个 500,000 维向量,只有一个位置是 1,其余全是 0。
问:cat 和 kitten 有多相似?
- One-hot
cat = [0, 0, …, 1, …, 0]
- One-hot
kitten = [0, 0, …, 0, …, 1, 0]
- 余弦相似度 = 0(完全正交)
cat 和 car 有多相似?同样是 0。
One-hot 编码的世界里,所有词都一样陌生——这对任何需要”理解词义”的任务都是灾难性的。
分布式表示(稠密向量)的解决方案:让相似上下文的词有相似向量,cat 和 kitten 的向量点积应该很大,cat 和 chair 的点积应该很小。
⚠️ 常见误区
- 误区:词向量 = one-hot 向量 → 正确:词向量特指学到的稠密低维表示(如 300 维),one-hot 是符号表示不是”向量表示”语境下的词向量。
- 误区:WordNet 可以替代词向量 → 正确:WordNet 是人工构建的,无法捕捉细微语义差别(
good vs great vs excellent 的差异),且无法用于数值计算。
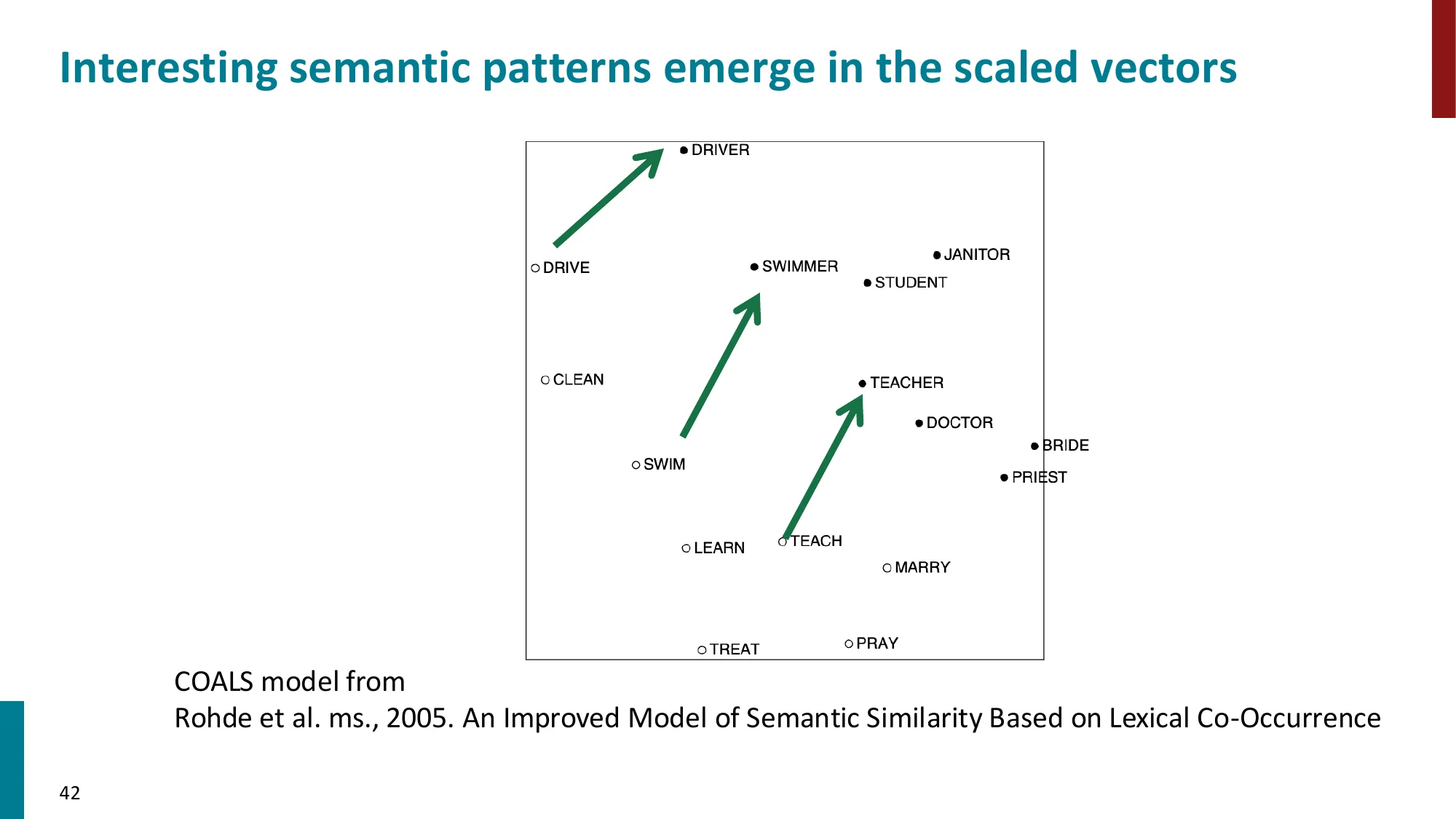
2. 分布语义学(Distributional Semantics)
- 核心思想:一个词的含义由频繁出现在其附近的词决定
- J. R. Firth (1957): “You shall know a word by the company it keeps”
- 上下文(context):固定大小窗口内的邻近词
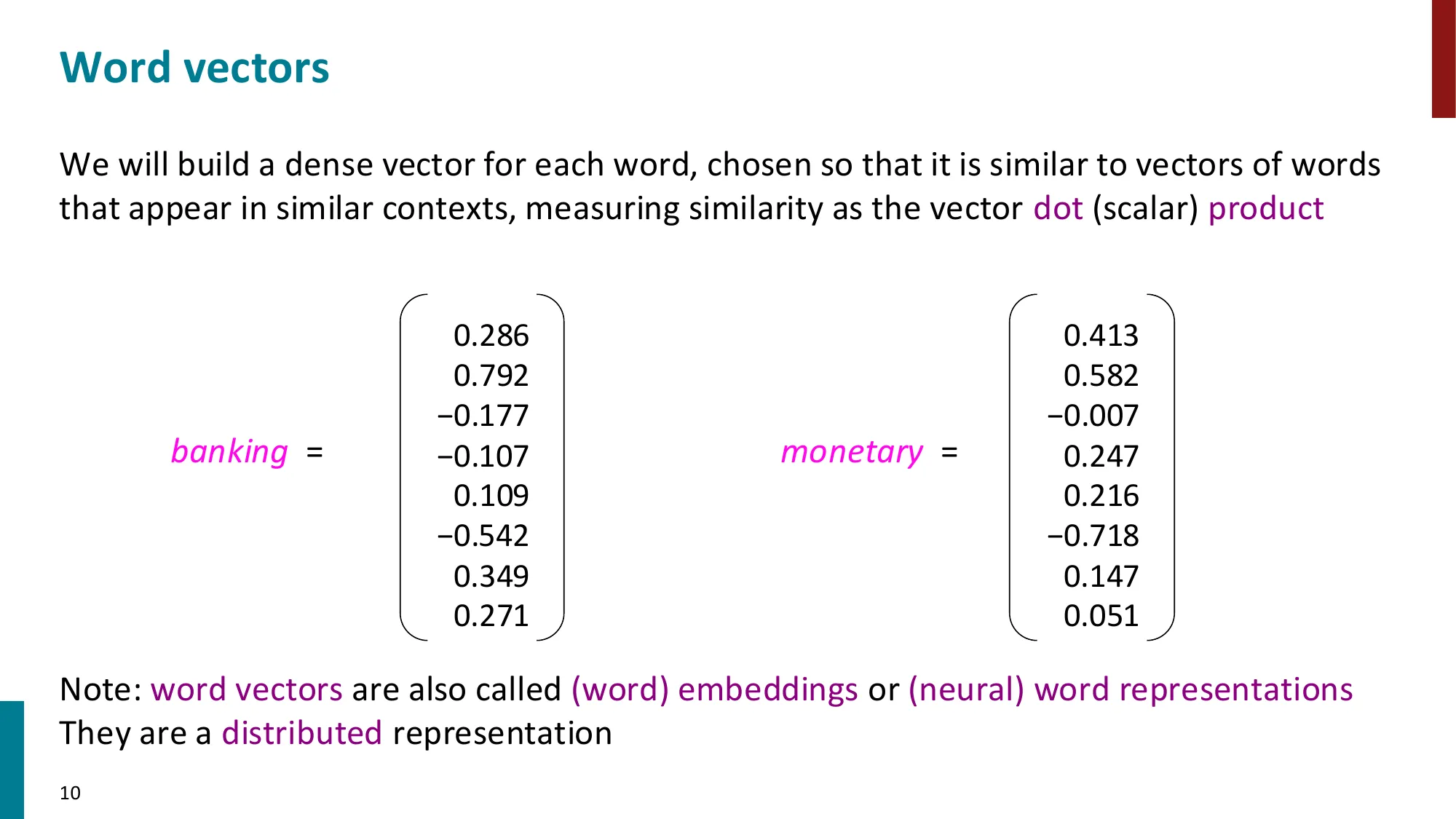
- 词向量(word vectors)= 词嵌入(word embeddings)= 分布式表示(distributed representation)
- 用稠密向量(如 d=300)表示每个词,使得相似上下文中的词有相似向量
- 相似度度量:向量点积(dot product)uTv=∑iuivi
📐 分布假说的数学表达
核心思想:“一个词的含义由其上下文决定”——这如何转化为可计算的目标?
步骤 1:定义”上下文”为以目标词为中心、半径 m 的窗口:
context(wt)={wt−m,…,wt−1,wt+1,…,wt+m}
步骤 2:如果词向量能够预测上下文词,说明向量已经编码了”上下文分布”(即词的含义):
好的词向量⇔给定中心词,能准确预测上下文词
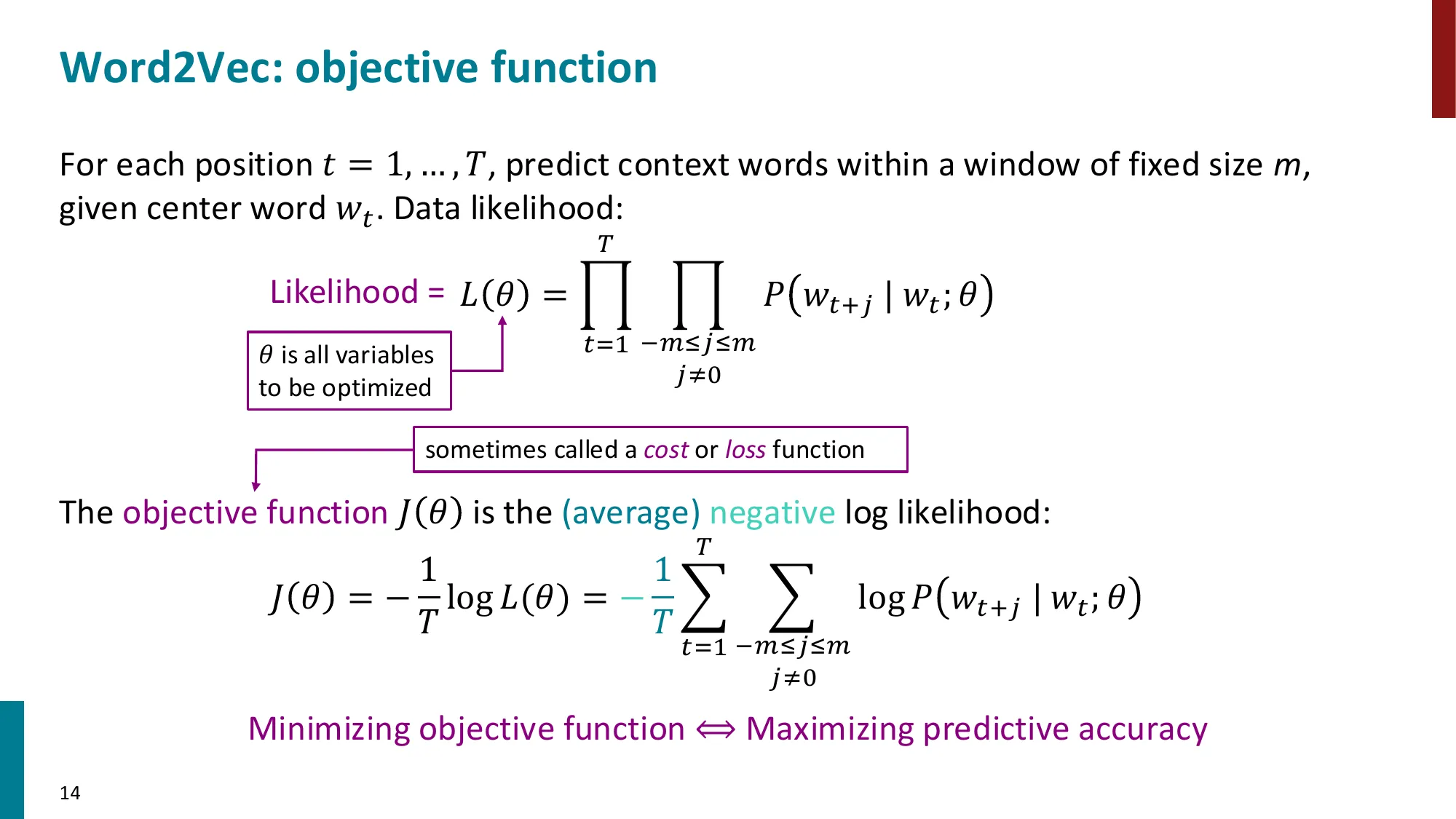
步骤 3:将”预测能力”定义为目标函数——最大化在所有位置 t 上,给定中心词预测上下文词的联合概率:
maximize∏t=1T∏−m≤j≤mj=0P(wt+j∣wt;θ)
取负对数(最小化形式):
minimizeJ(θ)=−T1∑t=1T∑−m≤j≤mj=0logP(wt+j∣wt;θ)
这就是 Word2Vec 的目标函数!分布假说 → 可微分的损失函数,一步完成。
📚 已收录至 拓展阅读知识库
🔢 点积相似度的计算
设定:两个 3 维词向量:
- vcat=[0.8,0.3,−0.1]
- vdog=[0.7,0.4,−0.2]
- vcar=[−0.2,0.1,0.9]
余弦相似度(归一化点积):
cos(cat,dog)=∥vcat∥⋅∥vdog∥vcatTvdog
计算:
- vcatTvdog=0.8×0.7+0.3×0.4+(−0.1)×(−0.2)=0.56+0.12+0.02=0.70
- ∥vcat∥=0.64+0.09+0.01=0.74≈0.860
- ∥vdog∥=0.49+0.16+0.04=0.69≈0.831
- cos(cat,dog)=0.70/(0.860×0.831)≈0.977(高相似度)
cos(cat,car)=(−0.16+0.03−0.09)/(…)≈−0.26(低/负相似度)
结论:cat 和 dog 向量相近,cat 和 car 向量方向相反。
⚠️ 常见误区
- 误区:窗口越大越好 → 正确:大窗口捕捉主题相似性(
bank + money),小窗口捕捉句法相似性(run + running)。不同任务最优窗口大小不同。
- 误区:点积 = 余弦相似度 → 正确:余弦相似度是归一化的点积。如果词向量的模长不一样,直接比较点积是不公平的。Word2Vec 通常用点积(不归一化),评估时才用余弦相似度。
3. Word2Vec 模型概览
- 框架:学习词向量的方法(Mikolov et al., 2013)
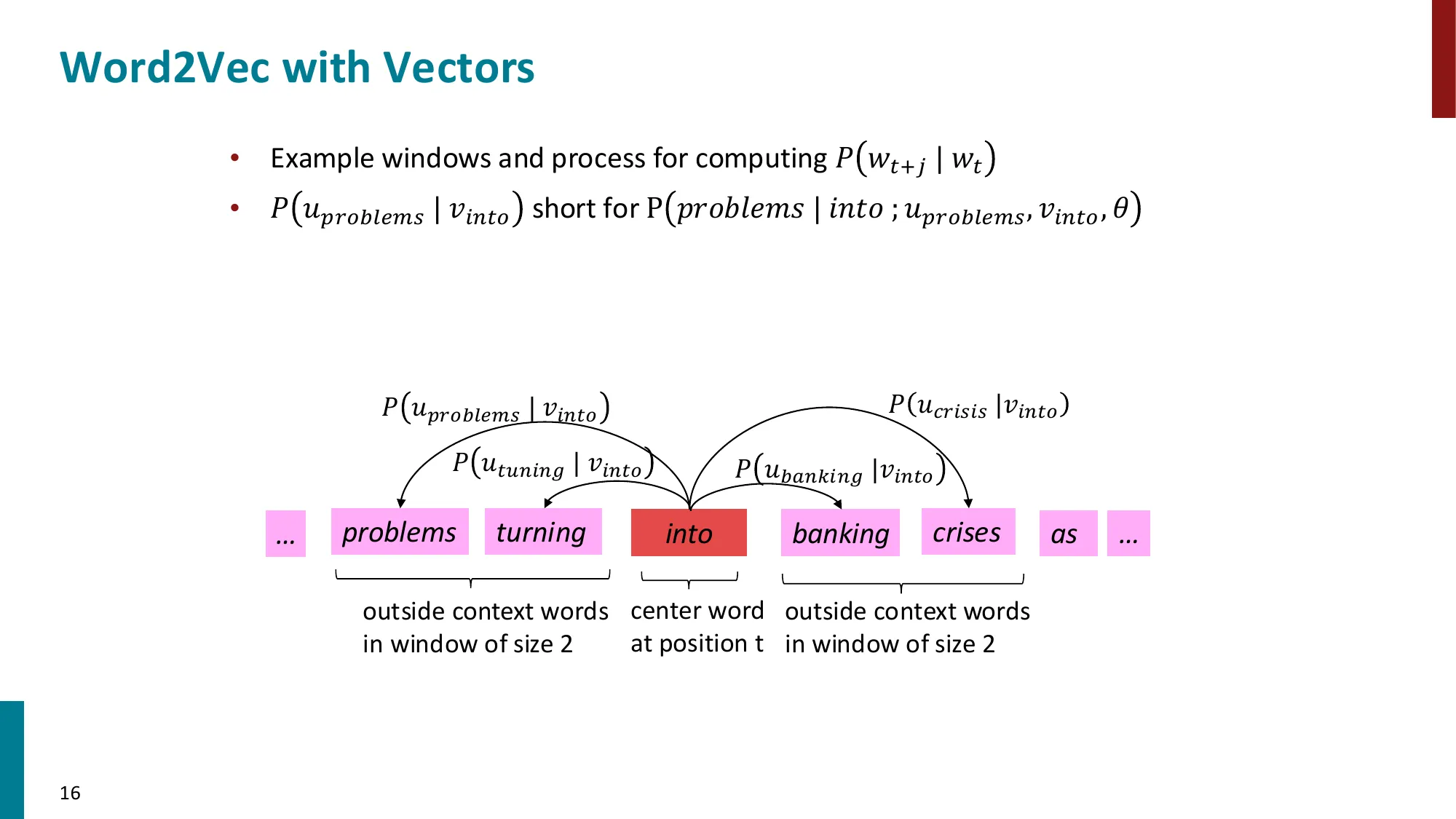
- Skip-gram 模型:给定中心词 c,预测上下文词 o
- 遍历文本每个位置 t,在窗口大小 m 内预测
- 每个词有两个向量:vw(作为中心词)和 uw(作为上下文词)
- 预测函数(softmax):
- P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
- 步骤:(1) 点积计算相似度 (2) 指数化使之为正 (3) 归一化得概率分布
- 目标函数(负对数似然):
- J(θ)=−T1∑t=1T∑−m≤j≤mj=0logP(wt+j∣wt;θ)
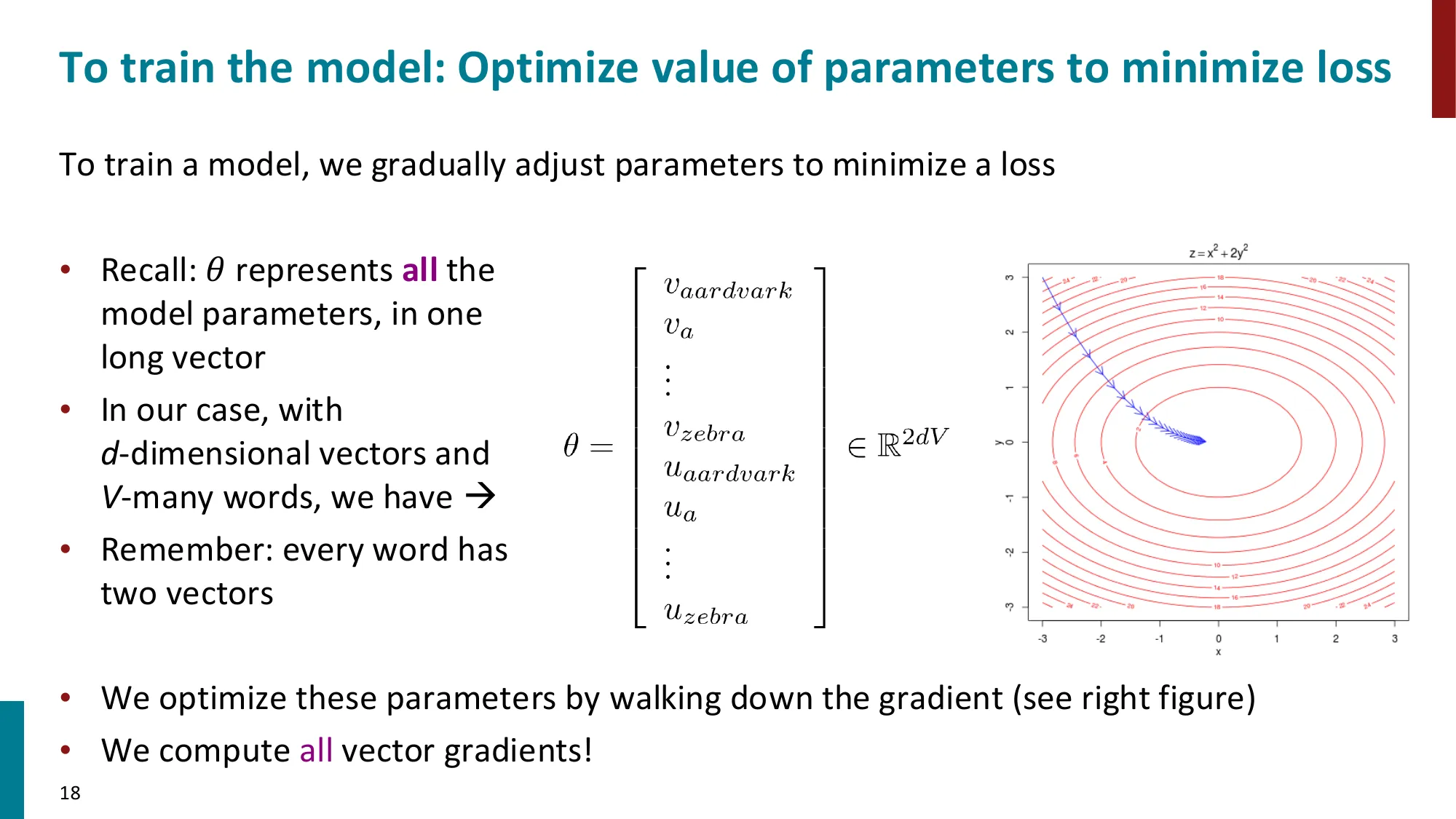
- 参数 θ∈R2dV:d 维向量 × V 个词 × 2(中心词 + 上下文词)
📐 Softmax 预测函数的由来
目标:给定中心词 c,如何建模上下文词 o 出现的概率 P(o∣c)?
第 1 步:相似度度量
用点积衡量中心词向量 vc 和上下文词向量 uo 的相似度:
score(o,c)=uoTvc=∑i=1duo,i⋅vc,i
点积越大,两个词在向量空间中越”接近”,越可能共现。
第 2 步:指数化(使所有分数为正)
原始点积可以是负数,不能直接当概率。用指数函数 exp(⋅) 映射到正数域:
exp(uoTvc)>0∀uo,vc
这保证了大的相似度 → 大的正数,小的(负的)相似度 → 接近 0 的正数。
第 3 步:归一化(使概率和为 1)
除以所有词的指数和,得到合法的概率分布:
P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
为什么用指数而不是其他函数?
指数函数有特殊性质:exp(a+b)=exp(a)exp(b),使得 softmax 的梯度形式特别简洁(见推导块 2)。此外,softmax 是最大熵原理下的唯一解——在所有满足均值约束的分布中,softmax 分布的信息熵最大。
 Slide 14 — Softmax 预测函数
Slide 14 — Softmax 预测函数
📚 已收录至 拓展阅读知识库
📐 对 vc 求梯度的完整推导
目标:计算 ∂vc∂logP(o∣c)
第 1 步:展开对数
logP(o∣c)=uoTvc−log∑w∈Vexp(uwTvc)
第 2 步:分别求导
第一项的导数(直接):
∂vc∂(uoTvc)=uo
第二项使用链式法则——令 S=∑w∈Vexp(uwTvc):
∂vc∂logS=S1⋅∂vc∂S=S1∑x∈Vexp(uxTvc)⋅ux
第 3 步:化简
=∑x∈VSexp(uxTvc)⋅ux=∑x∈VP(x∣c)⋅ux
第 4 步:合并结果
∂vc∂logP(o∣c)=uo−∑x∈VP(x∣c)ux
直觉:梯度 = 观察到的上下文向量 uo − 期望的上下文向量 E[ux]。这是在”推动 vc 靠近实际观察到的上下文词,远离平均的上下文词”。
 Slide 15 — 梯度推导过程
Slide 15 — 梯度推导过程
📚 已收录至 拓展阅读知识库
🔢 数值计算:3 个词的 Skip-gram
设定:词表 V={cat,dog,fish},嵌入维度 d=2
| 词 | 中心词向量 v | 上下文向量 u |
|---|
| cat | [0.5,0.3] | [0.2,0.8] |
| dog | [0.4,0.6] | [0.7,0.1] |
| fish | [0.1,0.9] | [0.3,0.5] |
任务:计算 P(dog∣cat)(中心词是 cat,预测上下文词 dog)
Step 1:计算点积 uwTvcat 对所有词:
ucatTvcat=0.2×0.5+0.8×0.3=0.34
udogTvcat=0.7×0.5+0.1×0.3=0.38
ufishTvcat=0.3×0.5+0.5×0.3=0.30
Step 2:指数化:
exp(0.34)=1.405,exp(0.38)=1.462,exp(0.30)=1.350
Step 3:归一化:
sum=1.405+1.462+1.350=4.217
P(dog∣cat)=4.2171.462=0.347
验证:P(cat∣cat)+P(dog∣cat)+P(fish∣cat)=0.333+0.347+0.320=1.000 ✓
观察:dog 的概率最高(0.347),因为 udog 和 vcat 的点积最大。训练的目标就是让共现频率高的词对有更大的点积。
 Slide 16 — Skip-gram 计算示例
Slide 16 — Skip-gram 计算示例
 Slide 17 — 梯度更新过程
Slide 17 — 梯度更新过程
💡 Skip-gram 为什么能学到词义?
把 Skip-gram 的训练想象成一个预测游戏:
- 给你一个中心词 “bank”
- 你要猜它周围会出现什么词
- 如果 “bank” 经常和 “money”, “deposit”, “account” 一起出现
- 模型就会让 vbank 和 umoney, udeposit 的点积变大
关键洞察:如果 “bank” 和 “financial” 周围出现的词很相似(都跟钱有关),那么它们的 v 向量也会被推到相近的位置——因为它们需要对相同的上下文词产生高概率。
这就是 “You shall know a word by the company it keeps” 的数学实现。
 Slide 18
Slide 18
⚠️ 常见误区
- 误区:每个词只有一个向量 → 正确:每个词有两个向量——vw(作为中心词时)和 uw(作为上下文词时)。参数空间是 θ∈R2dV,不是 RdV。
- 误区:Softmax 的分母只是 normalization trick → 正确:分母 ∑wexp(uwTvc) 实际上是配分函数 Z,它使得全概率和为 1。这正是训练代价昂贵的来源——每次计算都要遍历整个词表 V(∣V∣ 可达 10 万+)。
- 误区:梯度 uo−∑P(x∣c)ux 只更新 vc → 正确:还需要计算对 uo 的梯度(类似推导),同时更新两组向量。
 Slide 19
Slide 19
4. Word2Vec 目标函数梯度推导
- 对 vc 求偏导:∂vc∂logP(o∣c)=uo−∑x∈VP(x∣c)ux
- 对 uo 求偏导的类似推导
- 参数更新:沿负梯度方向更新所有向量
📐 对 uo 求梯度的完整推导
目标:计算 ∂uo∂logP(o∣c)
第 1 步:展开对数
logP(o∣c)=uoTvc−log∑w∈Vexp(uwTvc)
第 2 步:对 uo 求导
第一项:∂uo∂(uoTvc)=vc
第二项:在求和 ∑w∈Vexp(uwTvc) 中,只有 w=o 这一项包含 uo:
∂uo∂log∑w∈Vexp(uwTvc)=∑w∈Vexp(uwTvc)exp(uoTvc)⋅vc=P(o∣c)⋅vc
第 3 步:合并
∂uo∂logP(o∣c)=vc−P(o∣c)⋅vc=(1−P(o∣c))⋅vc
直觉:如果模型已经给 o 很高的概率(P(o∣c)≈1),梯度接近零——不需要更新。如果概率很低,梯度接近 vc——把 uo 推向 vc 的方向。
 Slide 20
Slide 20
📚 已收录至 拓展阅读知识库
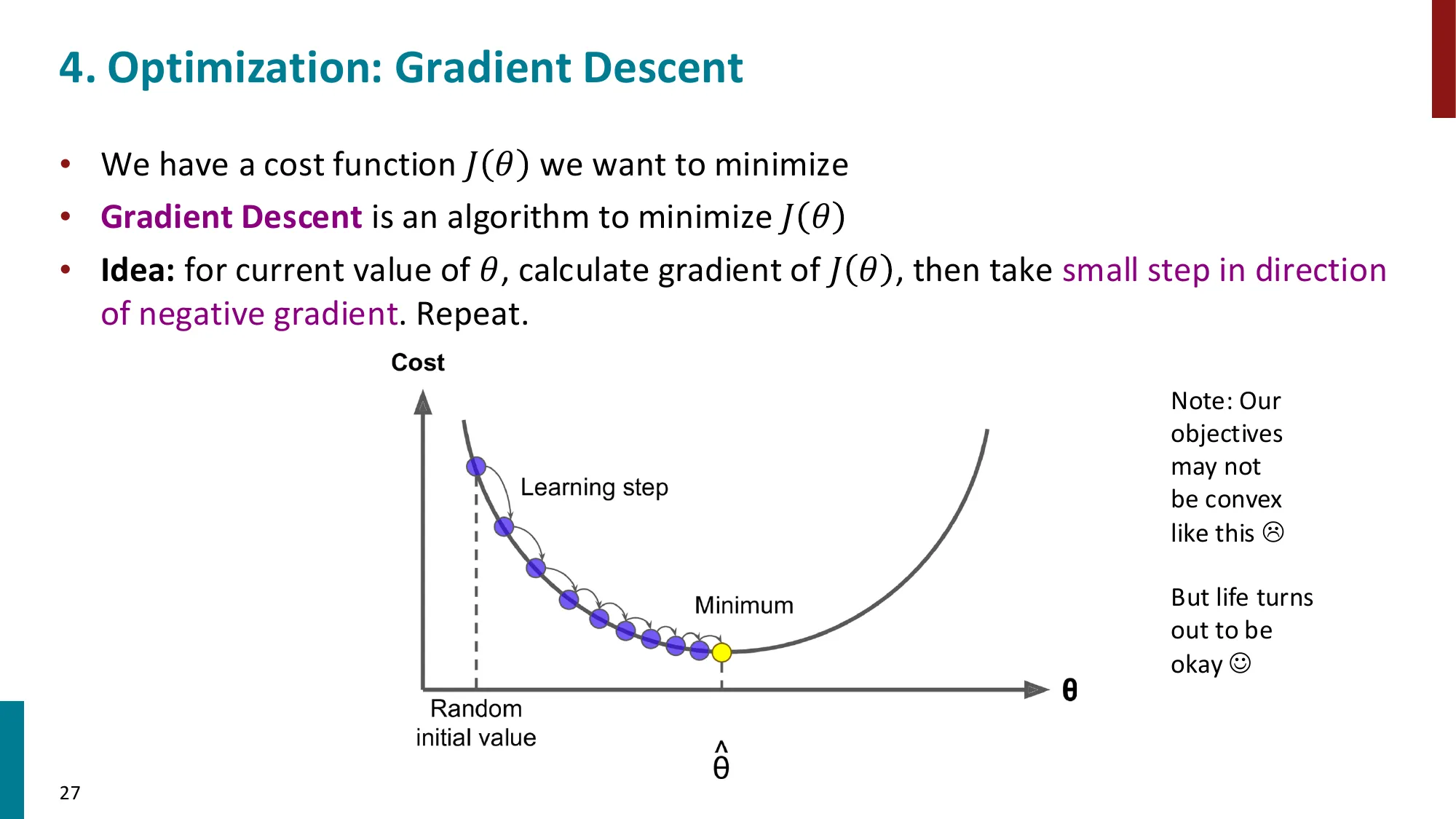
5. 优化基础:梯度下降
- 目标:最小化 J(θ)
- 梯度下降:计算 J(θ) 的梯度,沿负梯度方向迈小步
- 随机梯度下降(SGD):每次用小批量(mini-batch)采样近似梯度
- 更新规则:θnew=θold−α∇θJ(θ)
- 实际中:对全部词汇做 softmax 归一化代价太大 → 负采样(Negative Sampling)
- 只更新真实上下文词和少量随机”负样本”
- 目标函数:J(θ)=logσ(uoTvc)+∑k=1KEj∼P(w)[logσ(−ujTvc)]
🔢 SGD 更新一步示例
设定:词汇表 V={the, cat, sat, on, mat},d=2,学习率 α=0.1
中心词 “cat”,真实上下文词 “sat”,负样本 “the”(K=1):
- vcat=[0.5,0.3],usat=[0.4,0.6],uthe=[−0.2,0.1]
计算损失的梯度:
-
spos=usatTvcat=0.4×0.5+0.6×0.3=0.38
-
sneg=utheTvcat=−0.2×0.5+0.1×0.3=−0.07
-
∂vcat∂J=−(1−σ(0.38))usat−(−σ(−0.07))uthe
=−(1−0.594)[0.4,0.6]−(−0.517)[−0.2,0.1]
≈[−0.163,−0.244]+[0.103,−0.052]
=[−0.060,−0.296]
-
更新:vcatnew=[0.5,0.3]−0.1×[−0.060,−0.296]=[0.506,0.330]
观察:vcat 向 usat 方向移动,远离 uthe。
⚠️ 常见误区
- 误区:SGD 每步只更新一个词向量 → 正确:每步更新窗口内所有词的向量(2m 个上下文词 + 1 个中心词),以及 K 个负样本的向量。
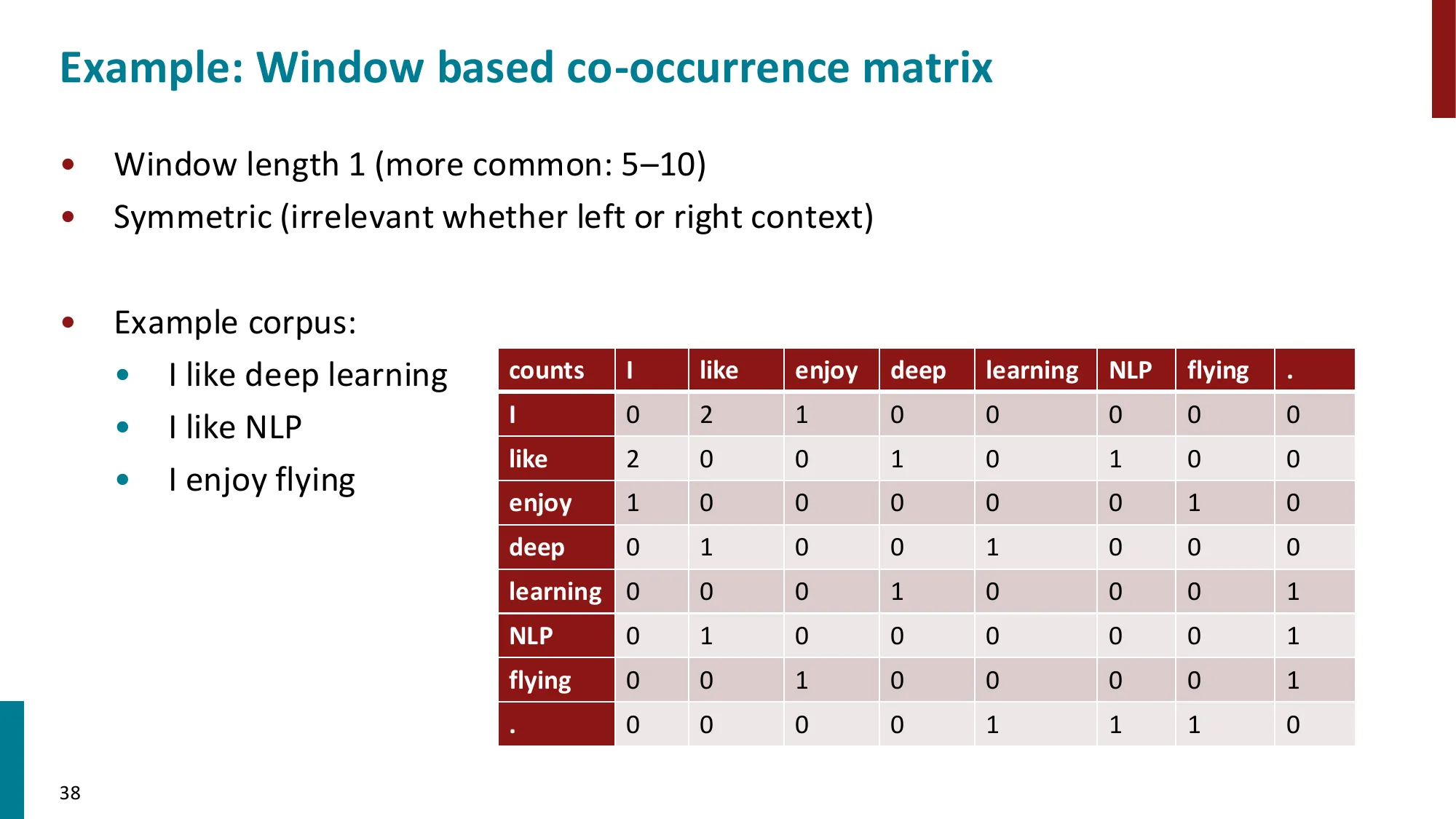
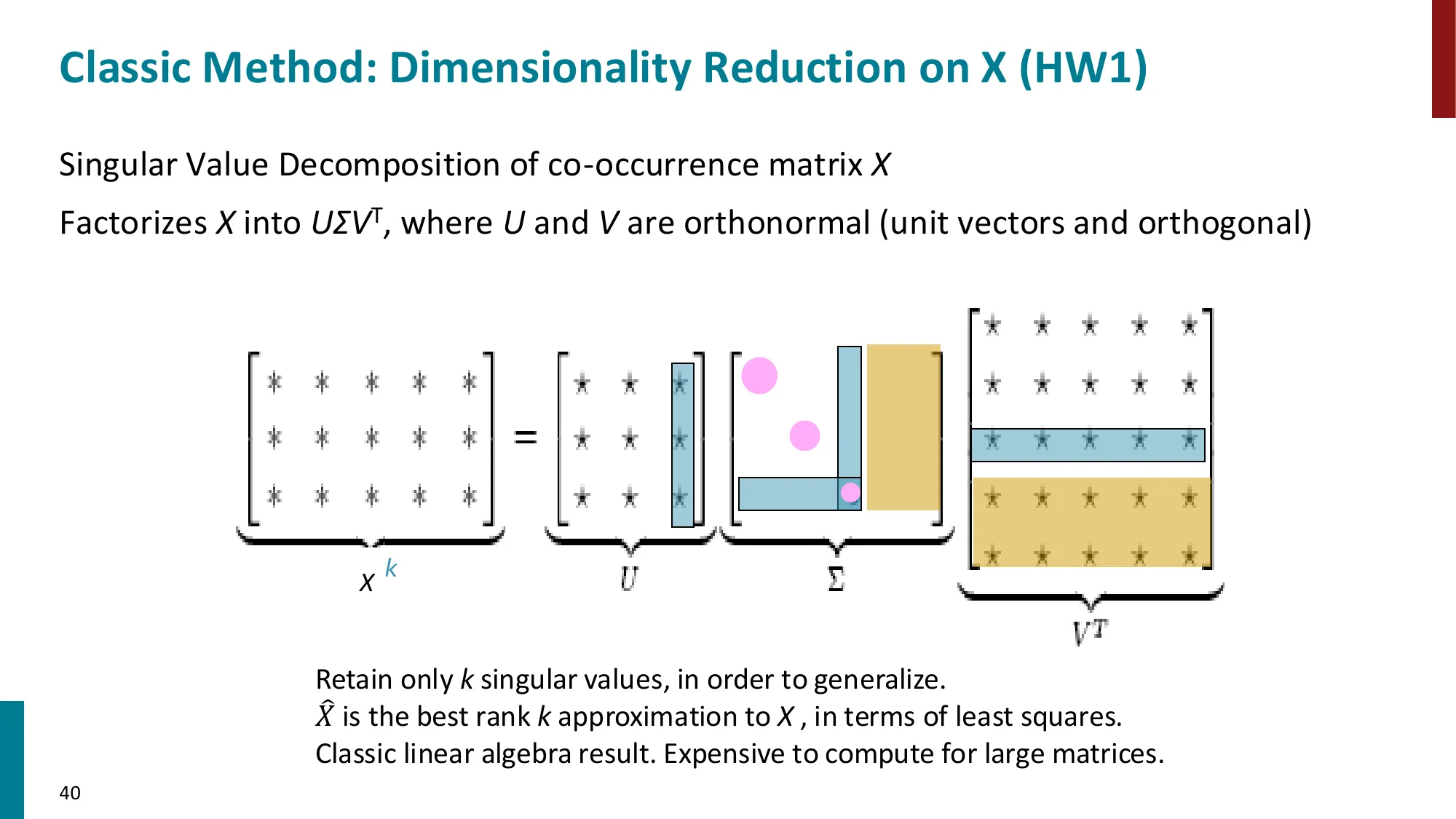
6. 共现矩阵与 GloVe
- 另一条路线:基于全局共现统计
- 构建词-词共现矩阵 X,对其做 SVD 降维
- GloVe(Pennington et al., 2014):结合全局统计和局部上下文窗口的优点
- 目标函数:J=∑i,j=1Vf(Xij)(wiTw~j+bi+b~j−logXij)2
- f(Xij):加权函数,限制高频词对的影响
- GloVe vs Word2Vec:本质上都在利用共现信息,只是方式不同
📐 GloVe 目标函数的推导动机
从 SVD 到 GloVe 的思路链:
第 1 步:构建词-词共现矩阵 X∈RV×V,Xij = 词 i 在词 j 的上下文中出现的次数。
第 2 步:SVD 分解 X=UΣVT,取前 d 列得到词向量。问题:X 极大(V≈500K),SVD 不可行;且共现矩阵中高频词(如 “the”)的影响过大。
第 3 步:GloVe 的洞察——点积 wiTw~j 应该逼近 logXij(对数共现):
wiTw~j≈logXij
为什么对数?因为共现次数跨越多个数量级(cat-the 共现 1000 次,cat-galaxy 共现 0 次),对数压缩这个差异。
第 4 步:加入偏置项 + 加权函数,构造最终目标:
J=∑i,j=1Vf(Xij)(wiTw~j+bi+b~j−logXij)2
其中 f(x)={(x/xmax)α1x<xmaxx≥xmax(α=0.75,限制高频词权重不超过 1)。
GloVe 的优势:只需遍历共现矩阵的非零元素,远小于全词汇表迭代;同时利用了全局统计而非局部窗口。
📚 已收录至 拓展阅读知识库
🔢 GloVe 共现比率的洞察
P(k∣w)= 词 k 在词 w 上下文中出现的概率:
| 词 k | P(k∣ice) | P(k∣steam) | 比率 P(k∣ice)/P(k∣steam) |
|---|
solid | 高 | 低 | >> 1 |
gas | 低 | 高 | << 1 |
water | 高 | 高 | ≈ 1 |
fashion | 低 | 低 | ≈ 1 |
洞察:比率 P(k∣w1)/P(k∣w2) 比单独的概率更能区分词义相关性。GloVe 的词向量点积就在拟合这个比率关系(通过对数转换变为差)。
⚠️ 常见误区
- 误区:GloVe 和 Word2Vec 是完全不同的方法 → 正确:从信息论角度,两者都在隐式分解某种形式的词-词共现矩阵(PPMI 矩阵)。Word2Vec 做局部窗口的 SGD,GloVe 做全局共现的加权最小二乘。
- 误区:Xij=0 的词对直接忽略即可 → 正确:GloVe 用 f(0)=0 自然处理(权重为 0),但需注意这意味着大量词对的信息被丢弃——稀疏数据是 GloVe 的挑战之一。
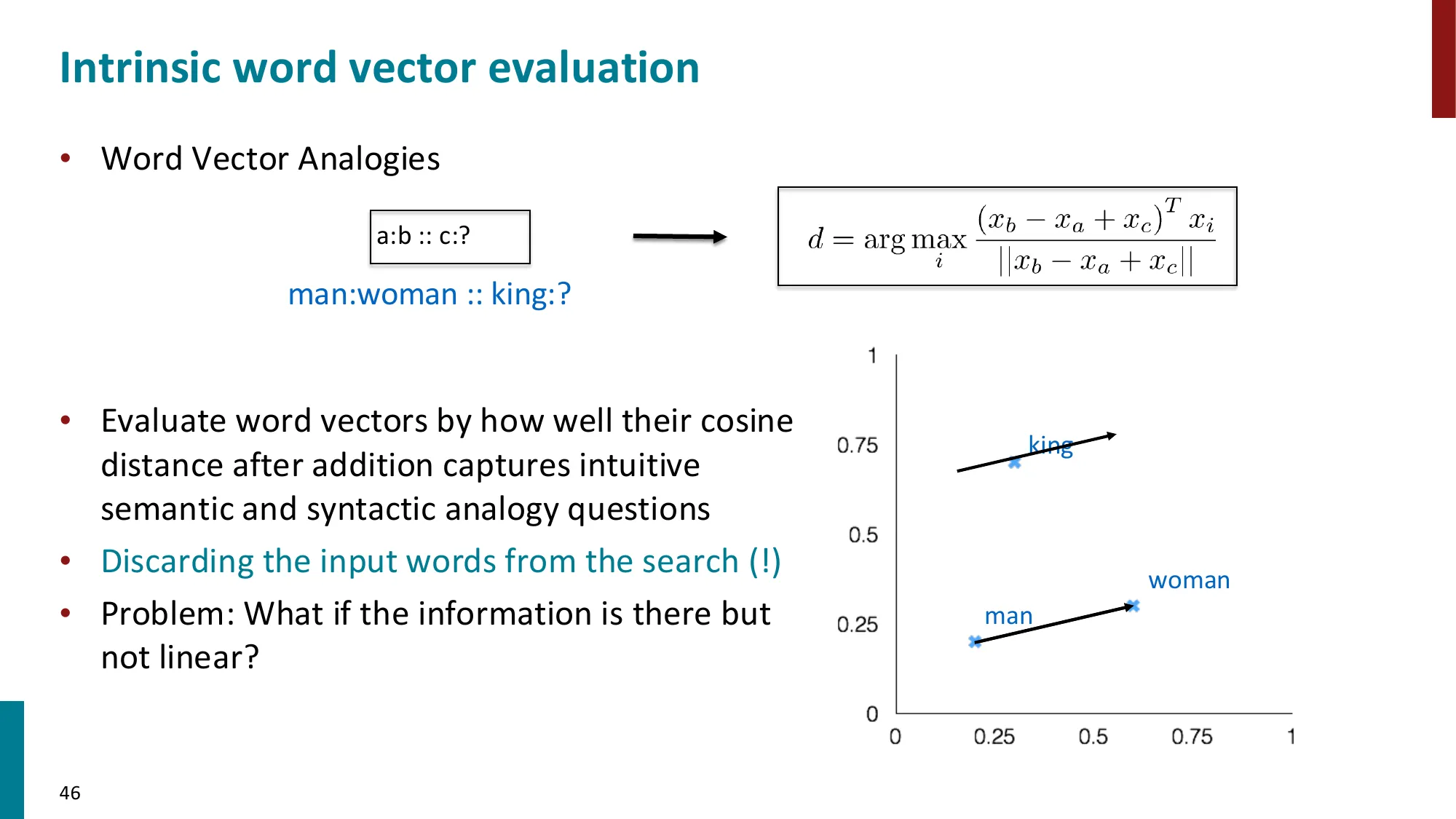
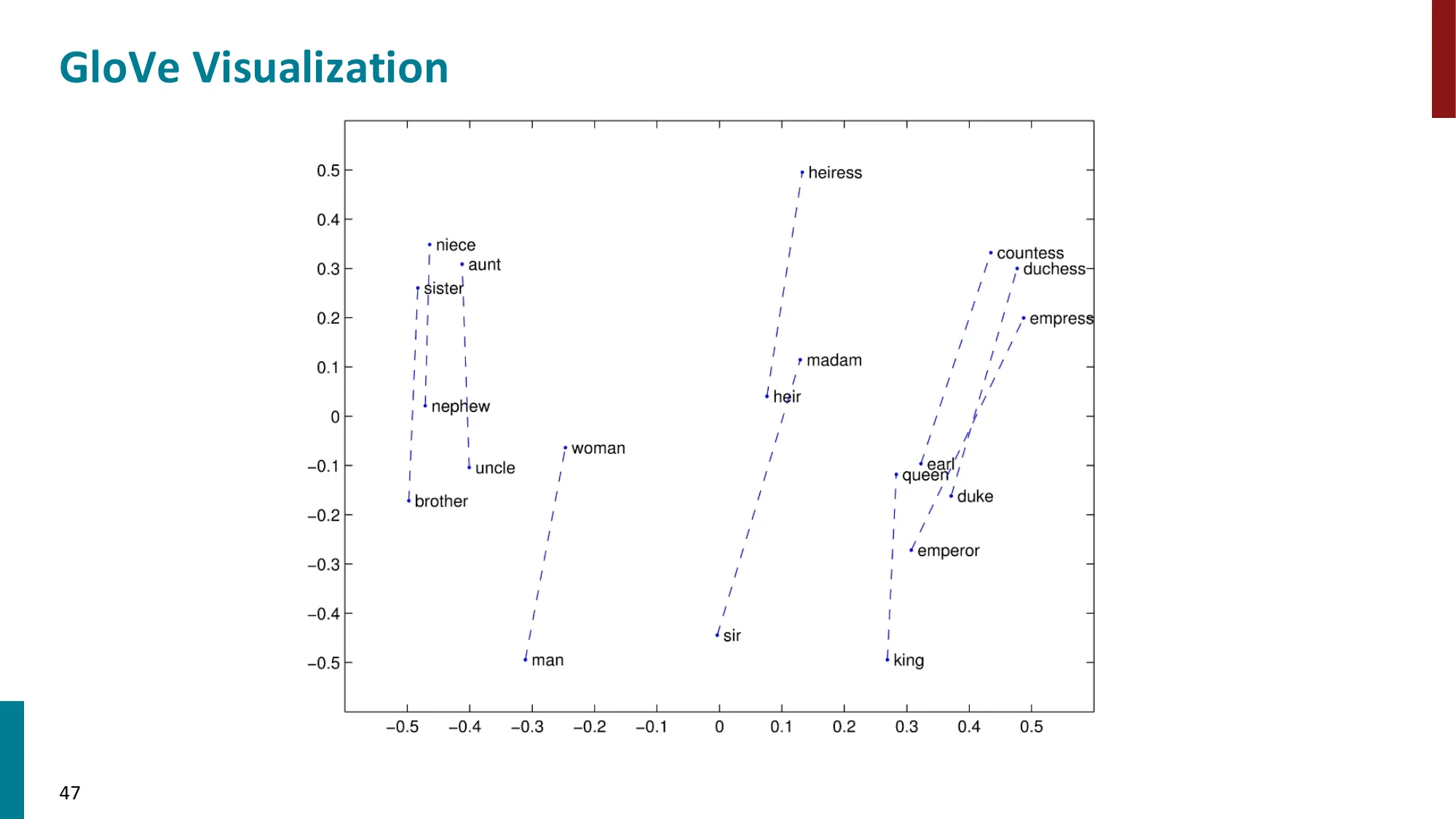
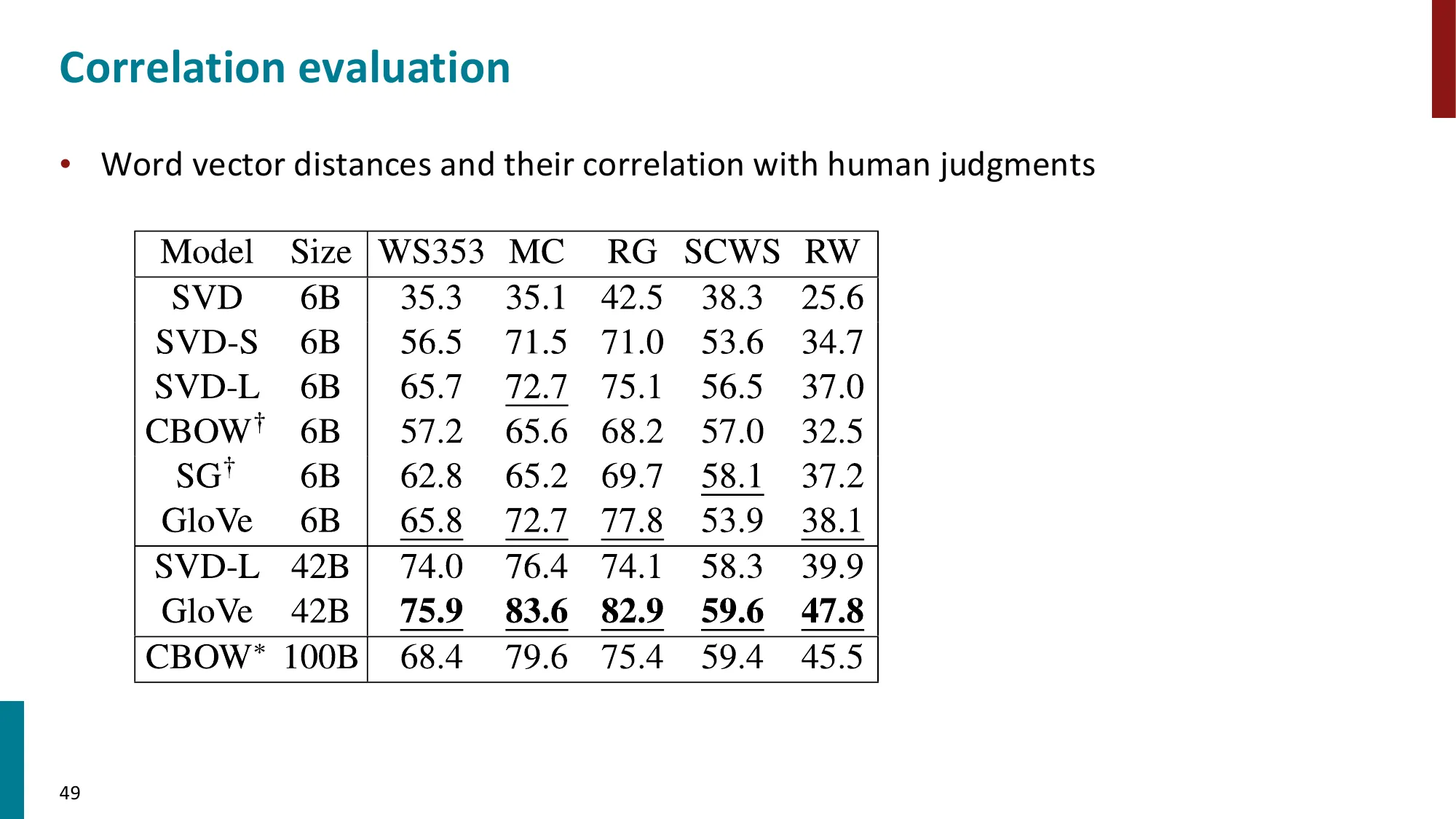
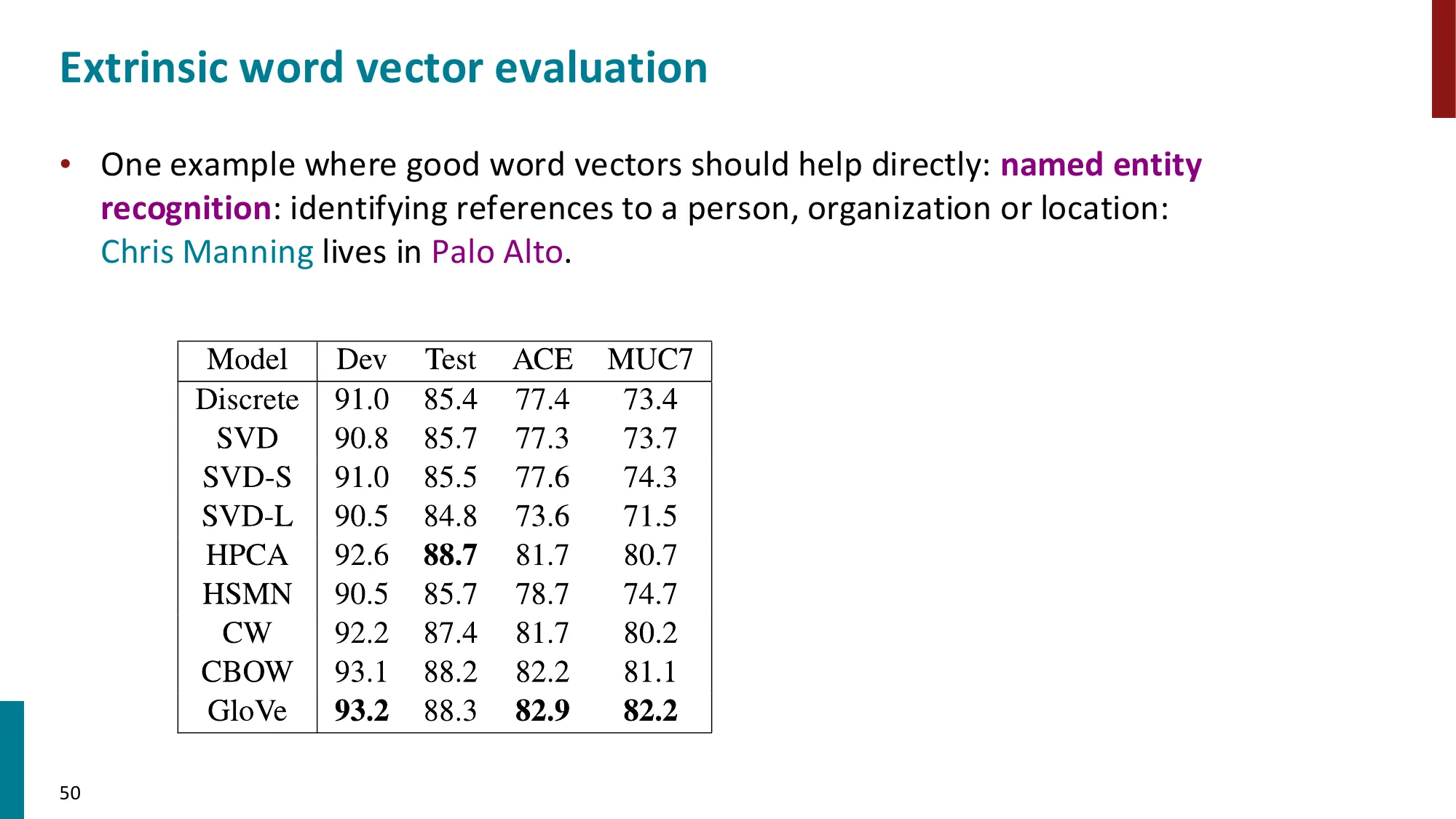
7. 词向量评估
- 内在评估(Intrinsic):词类比任务 a:b::c:?
- 例:man:woman :: king:? → queen
- 公式:d=argmaxi∥xb−xa+xc∥(xb−xa+xc)Txi
- 外在评估(Extrinsic):在下游任务(如 NER)上的表现
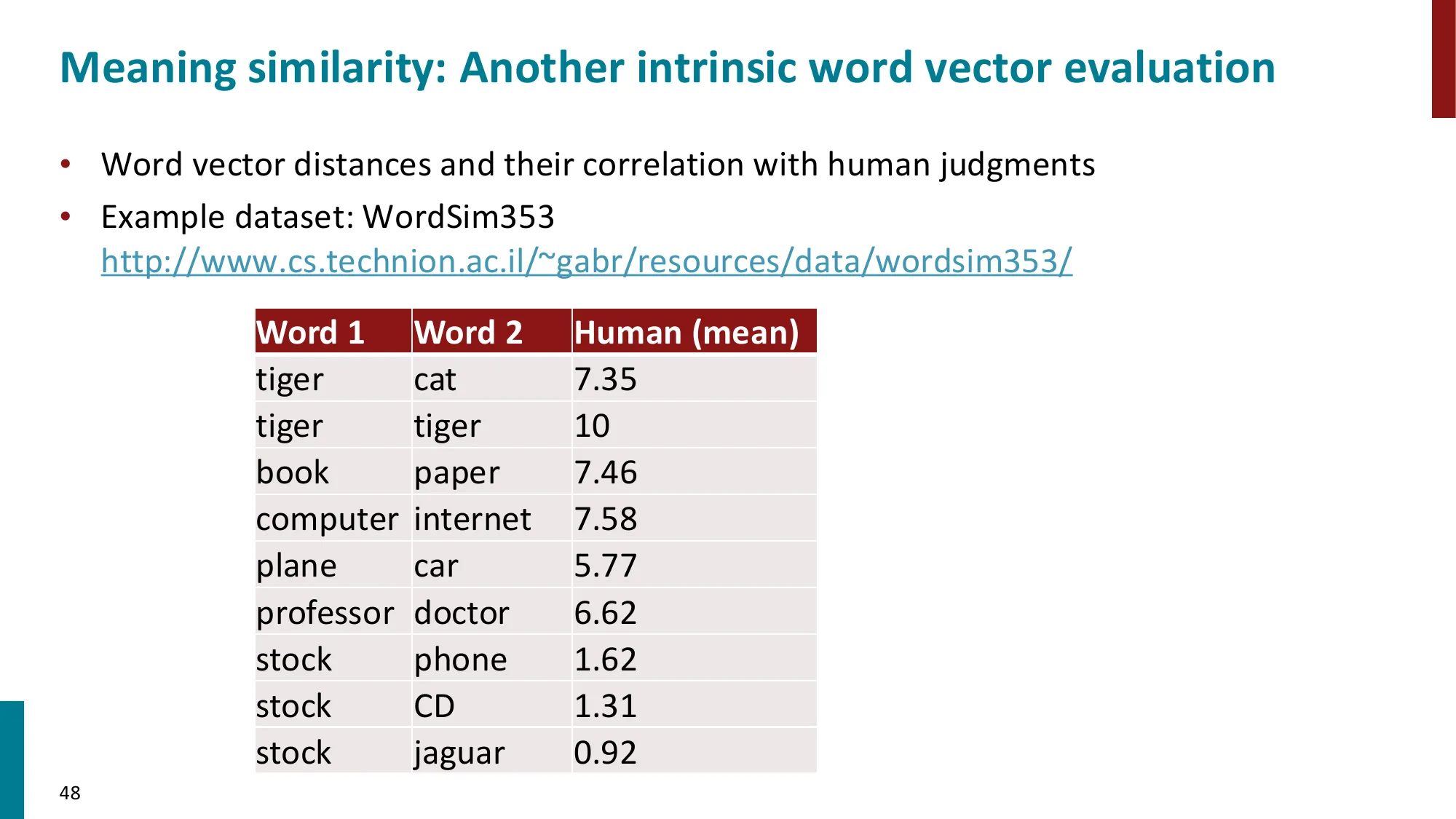
- 词相似度评估:WordSim353 等数据集,计算余弦相似度与人类判断的相关系数
📐 词类比评估公式解析
词类比任务:“man:woman :: king:?” 的向量求解:
公式:d=argmaxi∈/{a,b,c}∥vb−va+vc∥(vb−va+vc)Tvi
步骤 1:计算”方向向量”
Δ=vwoman−vman+vking
语义含义:vwoman−vman 捕捉”性别差异方向”(如果词向量学得好,这个向量对 gender 概念有固定方向),加上 vking 后得到”king 沿着 gender 方向偏移”的结果。
步骤 2:余弦相似度搜索
d=argmaxicos(Δ,vi)=argmaxi∥Δ∥⋅∥vi∥ΔTvi
分子中的 ∥Δ∥ 是常数,只需比较 ∥vi∥ΔTvi(或归一化后的点积)。
为什么排除 a,b,c? 否则 argmax 往往会返回 c 本身(vc 最接近 vc)。
🔢 内在 vs 外在评估对比
| 评估方式 | 示例 | 优点 | 缺点 |
|---|
| 内在(词类比) | “Paris:France :: Berlin:?” | 快速(分钟级),可独立运行 | 不直接反映任务效果 |
| 内在(词相似度) | cosim(cat, dog) vs 人类打分 | 有标准数据集(WordSim353) | 主观性强(人类打分有噪声) |
| 外在(NER 任务) | 用词向量的 NER F1 分数 | 直接反映下游效果 | 慢,受其他因素影响 |
WordSim353 示例:
- 人类打分
(cat, dog) = 7.79/10,模型余弦相似度 = 0.82 ✓
- 人类打分
(car, journey) = 5.85/10,模型相似度 = 0.43 ≈ ✓
- 两者 Spearman 相关系数越高,词向量越好
⚠️ 常见误区
- 误区:词类比准确率高 = 词向量质量好 → 正确:词类比任务有严重的语言偏见(主要测英语常见语义关系),非英语/小众领域效果不能反映词向量真实质量。
- 误区:余弦相似度越高越好 → 正确:余弦相似度的绝对值意义不大,重要的是排序是否与人类判断相关(Spearman 相关系数)。
- 内在评估陷阱:GloVe 在 WordSim353 上比 Word2Vec 好,但在某些下游任务(如句子分类)上 Word2Vec 更好。评估方式不同,结论可能相反。
推荐阅读
关联概念
个人笔记