L03: Backpropagation and Neural Networks
Week 2 · Tue Jan 13 2026 08:00:00 GMT+0800 (中国标准时间)
L03: Backpropagation and Neural Networks
Slides
中英交替版(推荐)
L03 双语 (PDF)
英文原版
L03 EN (PDF)
中文翻译版
L03 ZH (PDF)
核心知识点
1. 词向量评估回顾(Recap from L02)
- 内在评估 vs 外在评估
- 内在:特定子任务上评估(快速,但与真实任务关联不明确)
- 外在:在真实任务上评估(耗时,但直接反映效果)
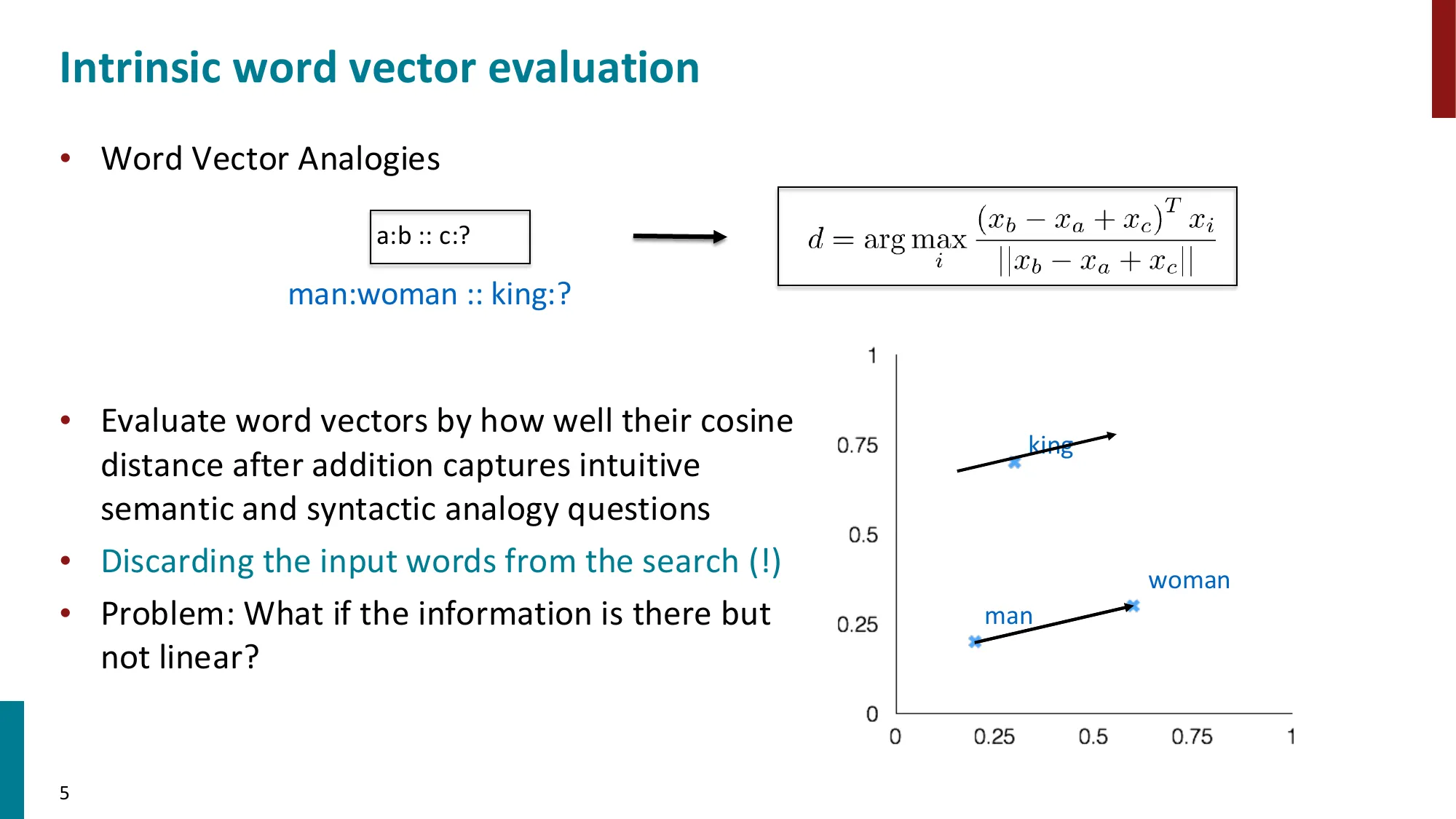
- 词类比(Word Analogies):d=argmaxi∥xb−xa+xc∥(xb−xa+xc)Txi
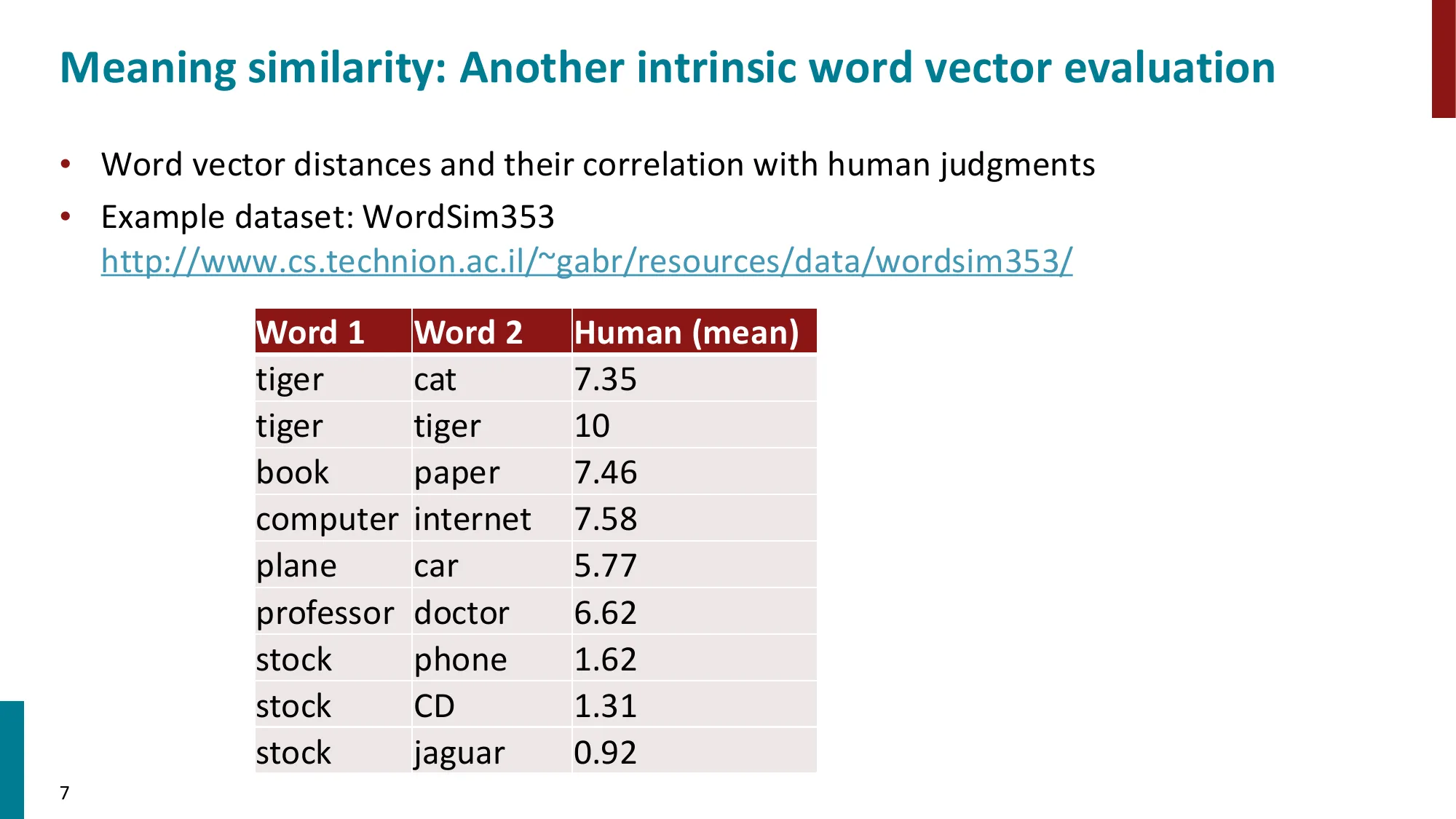
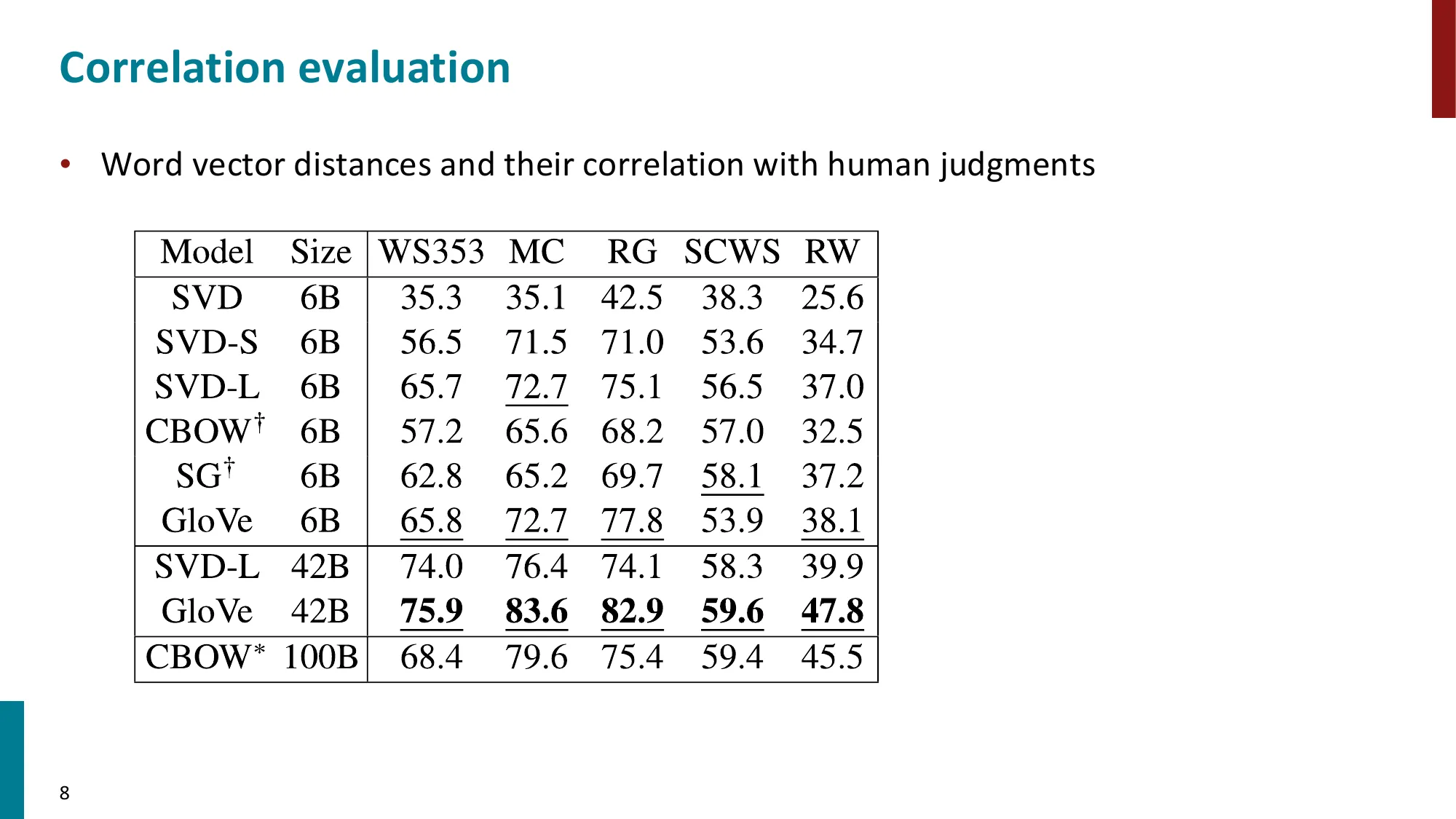
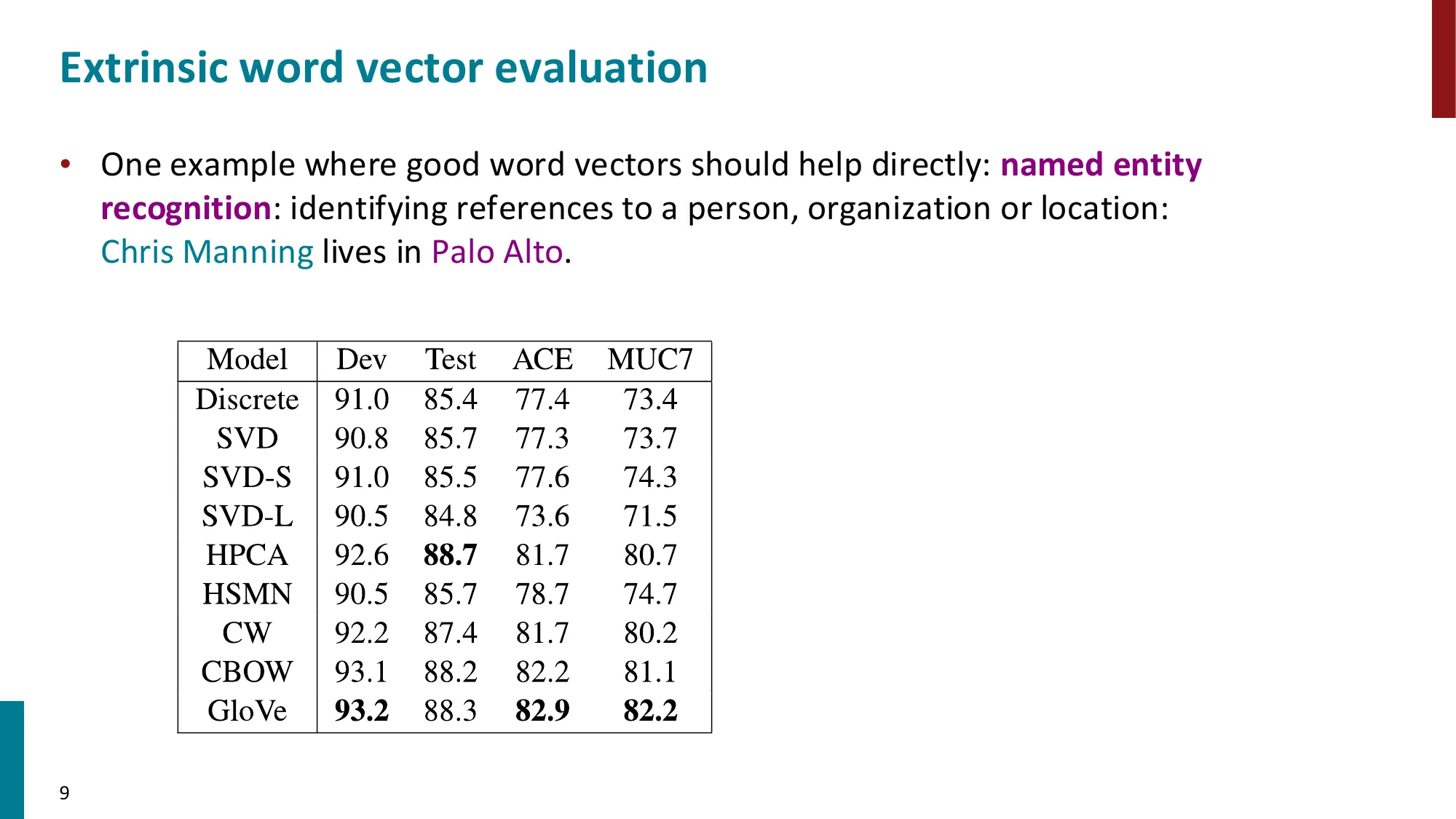
- 词相似度:WordSim353 数据集,GloVe 在多个基准上表现优异
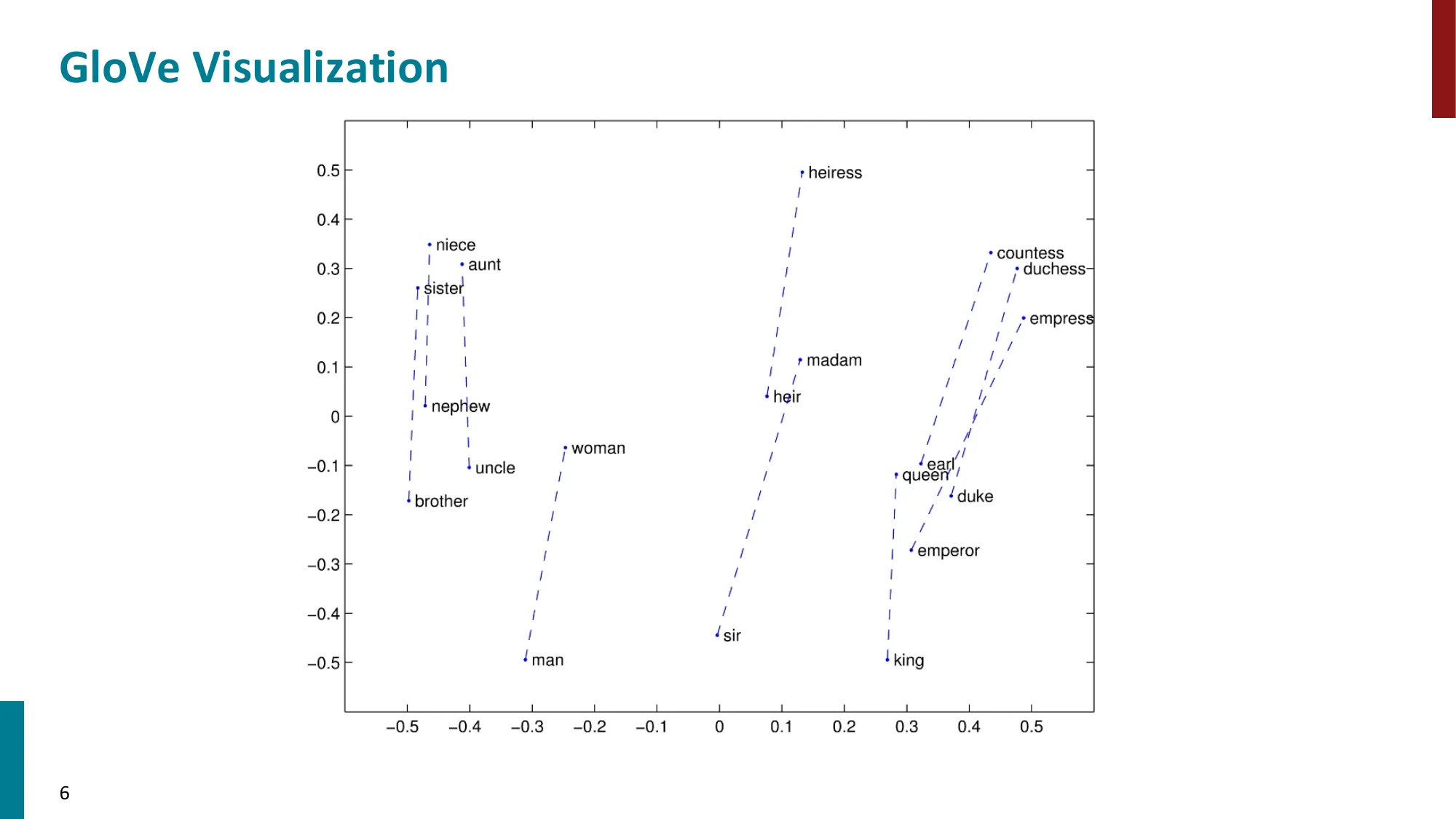
- GloVe 可视化:性别、皇室等语义关系在向量空间中呈现平行结构
📐 词类比公式完整推导
变量定义:
- xa = 词 a 的词向量(如 “man”)
- xb = 词 b 的词向量(如 “woman”)
- xc = 词 c 的词向量(如 “king”)
- d = 目标词(如 “queen”)的向量索引
- ∥⋅∥ = L2 范数(向量的欧几里得长度)
推导过程:
第 1 步:语义关系 = 向量差。“man → woman” 这个关系可以用 xb−xa 表示。训练良好的词向量满足 xb−xa≈xd−xc,即”性别关系”在向量空间中是一个稳定的偏移方向。
第 2 步:目标向量估计。将关系迁移到 xc,估计 d 的向量应当接近:
x^d=xb−xa+xc
第 3 步:在词汇表中搜索最近邻。直接用欧几里得距离不够稳定(向量长度不一致),改用余弦相似度:
cos(x^d,xi)=∥x^d∥⋅∥xi∥x^dTxi
第 4 步:当所有 xi 均已归一化(∥xi∥=1)时,分母中 ∥xi∥ 可省略:
d=argmaxi∥xb−xa+xc∥(xb−xa+xc)Txi
即对查询向量归一化后,直接做点积排名即可。
直觉:词向量空间是”语义坐标系”。不同词对之间的关系对应方向,语义相似 = 方向相同。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定(2维简化版):
| 词 | 向量 |
|---|
| man (xa) | [1.0, 0.0] |
| woman (xb) | [0.0, 1.0] |
| king (xc) | [0.9, 0.2] |
| queen (待找) | [?, ?] |
计算:
- 计算偏移向量:x^d=xb−xa+xc=[0,1]−[1,0]+[0.9,0.2]=[−0.1, 1.2]
- 归一化:∥x^d∥=0.01+1.44=1.45≈1.204,归一化后 ≈[−0.083, 0.997]
- 若词汇表中 queen 的向量为 [0.05,0.99](已归一化),则点积 ≈−0.083×0.05+0.997×0.99≈0.983,得分最高
结果:queen 得分最接近查询向量,被正确检索出。
💡 为什么这样做?
词向量空间的核心假设是:语义关系 = 方向向量。“性别关系”、“国家-首都关系”、“时态关系”等都对应向量空间中特定的方向。词类比本质上是:沿着已知关系的方向,在新的起点出发,找落脚点。
类比日常:你知道”北京在中国的东部”这个方向,再加上”法国”,就能猜到”巴黎在法国的中部偏北”——同样的逻辑。
⚠️ 常见误区
- 误区:直接用欧几里得距离找最近邻更直观 → 正确:词向量的模长不统一,高频词向量往往更长;余弦相似度对方向更敏感,与训练目标更一致
- 误区:分子分母的 ∥xb−xa+xc∥ 可以省略 → 正确:当比较不同查询时需要归一化;若只是对同一查询排名,分子的归一化不影响 argmax 结果,但规范写法应保留
- 误区:词类比评估 = 词相似度评估 → 正确:两者测量不同维度,类比测结构关系,相似度测语义距离
2. 深度学习分类:命名实体识别(NER)
- 任务:在文本中找到并分类命名实体(PER/LOC/ORG/DATE 等)
- 方法:窗口分类(Window Classification)
- 将中心词及其上下文窗口内的词向量拼接为输入 xwindow∈R5d
- 用二分类或多分类逻辑回归/神经网络判断
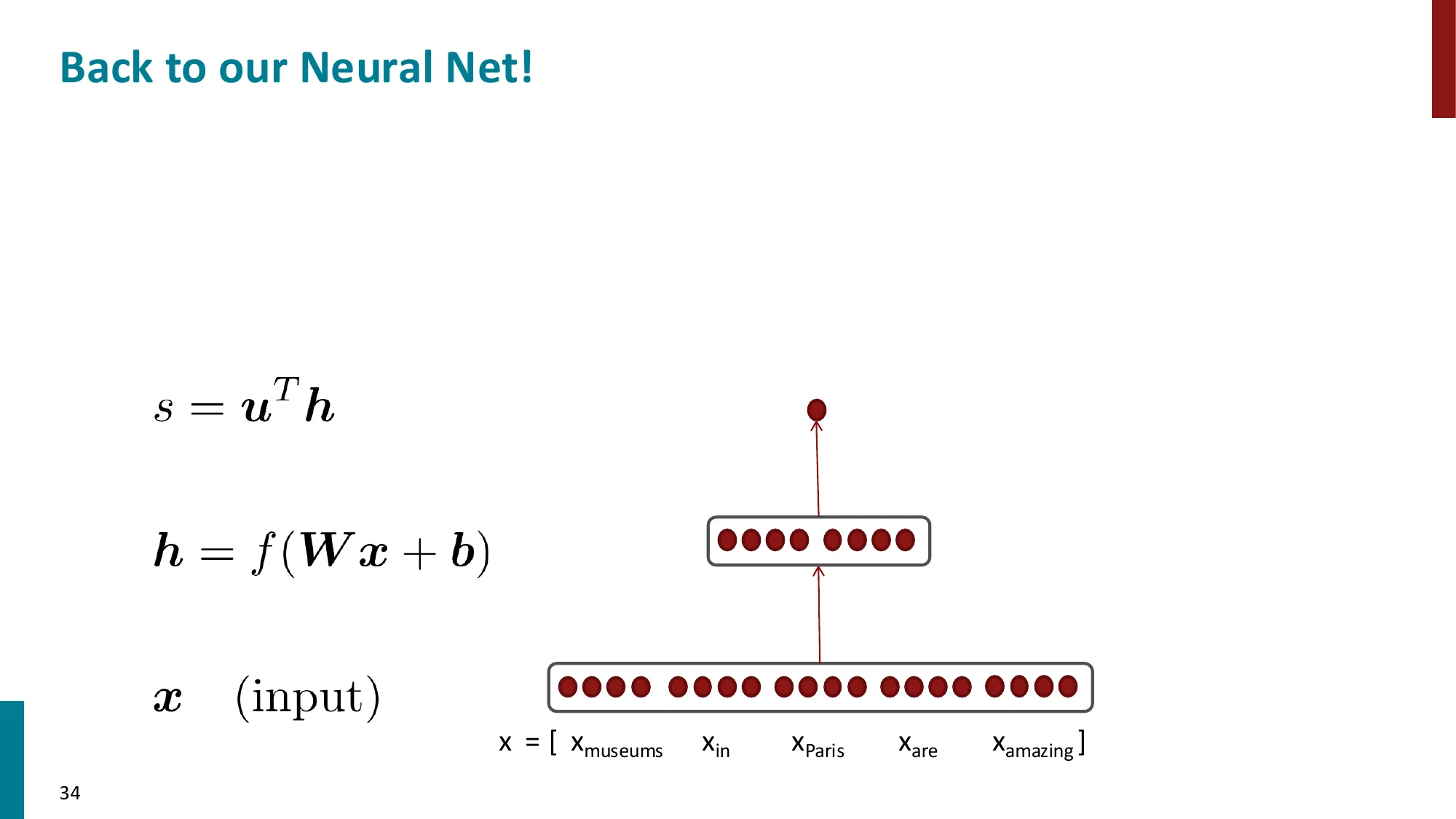
- 示例:判断 “Paris” 是否为 LOCATION
- x=[xmuseums,xin,xParis,xare,xamazing]T
📐 窗口分类输入构造与决策函数推导
变量定义:
- d = 词向量维度(如 d=300)
- w = 窗口半径(如 w=2,则窗口大小为 2w+1=5)
- xt∈Rd = 位置 t 的词向量
- xwindow∈R(2w+1)d = 窗口拼接向量
- W∈RC×(2w+1)d = 分类权重矩阵(C 为类别数)
推导过程:
第 1 步:拼接(concatenate)操作。对位置 t,取上下文窗口内所有词向量,按顺序拼接(不是求和、不是平均):
xwindow=xt−wxt−w+1⋮xt⋮xt+w∈R(2w+1)d
数学上等价于:xwindow=[xt−wT, xt−w+1T, …, xtT, …, xt+wT]T
第 2 步:线性分类决策函数:
y^=W⋅xwindow+b∈RC
其中 W∈RC×(2w+1)d,每一行对应一个类别的权重。
第 3 步:对二分类(是/否 LOCATION),输出层用 sigmoid:
p(LOC∣x)=σ(y^)=1+e−y^1
形状检查:W 是 (C)×((2w+1)d),xwindow 是 ((2w+1)d),乘积是 (C),加偏置 (C),形状一致。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:d=3,窗口大小 =3(w=1),判断中心词是否为 LOCATION
句子:“in Paris are”,中心词 = “Paris”
| 词 | 向量(d=3) |
|---|
| “in” (xt−1) | [0.2,0.1,0.5] |
| “Paris” (xt) | [0.8,0.9,0.3] |
| “are” (xt+1) | [0.1,0.3,0.2] |
计算:
- 拼接:xwindow=[0.2,0.1,0.5, 0.8,0.9,0.3, 0.1,0.3,0.2]T∈R9
- 设 W∈R1×9(二分类)= [0.1,0.2,−0.1,0.5,0.4,0.3,0.0,0.1,0.2],b=0.1
- y^=W⋅xwindow+b=0.02+0.02−0.05+0.40+0.36+0.09+0+0.03+0.04+0.1=1.01
- p=σ(1.01)≈0.733(73.3% 概率是 LOCATION)
💡 为什么这样做?
窗口分类的核心问题是:孤立地看一个词,无法判断它是不是命名实体。“Washington” 可以是人名也可以是地名,但”President Washington visited”和”Washington D.C. is”语境完全不同。
拼接上下文词向量,等于把”这个词周围的语境”打包成一个大向量,让分类器同时看到局部上下文。这是 NLP 中最基础的上下文特征提取思路。
⚠️ 常见误区
- 误区:窗口越大越好 → 正确:窗口是超参,太大引入噪声,太小上下文不足;NER 任务通常 w=2 已足够
- 误区:拼接 = 求和(或平均) → 正确:拼接保留了位置信息(哪个词在哪个位置),而求和/平均会丢失顺序信息
- 误区:每个词的向量是 one-hot → 正确:这里的 xt 已经是词嵌入(低维稠密向量),不是稀疏的 one-hot 编码
3. 神经网络分类器
- 传统 softmax 分类器:p(y∣x)=∑c=1Cexp(Wc⋅x)exp(Wy⋅x)
- 神经网络的关键区别:
- 同时学习权重矩阵 W 和分布式表示(词向量 x)
- 多层网络 + 非线性函数 → 非线性决策边界
- NER 二分类网络结构:
- x∈R5d(输入:5 个词的拼接向量)
- h=f(Wx+b)(隐藏层 + 非线性激活)
- s=uTh(评分)
- Jt(θ)=σ(s)=1+e−s1(sigmoid 输出概率)
📐 神经网络分类器完整前向传播推导
变量定义:
- x∈R5d = 窗口拼接词向量(输入层)
- W(1)∈Rm×5d = 第一层权重矩阵(m 为隐藏层维度)
- b(1)∈Rm = 第一层偏置
- f(⋅) = 逐元素非线性激活函数(如 tanh)
- h∈Rm = 隐藏层输出
- u∈Rm = 输出权重向量
- s∈R = 标量评分
推导过程:
第 1 步:线性变换。将输入投影到隐藏空间:
z(1)=W(1)x+b(1)∈Rm
展开矩阵乘法的第 i 个分量:zi(1)=∑j=15dWij(1)xj+bi(1)
第 2 步:逐元素非线性激活:
h=f(z(1))∈Rm,hi=f(zi(1))
第 3 步:输出评分(标量)。用权重向量 u 做内积:
s=uTh=∑i=1muihi∈R
第 4 步:转化为概率(二分类用 sigmoid):
p=σ(s)=1+e−s1∈(0,1)
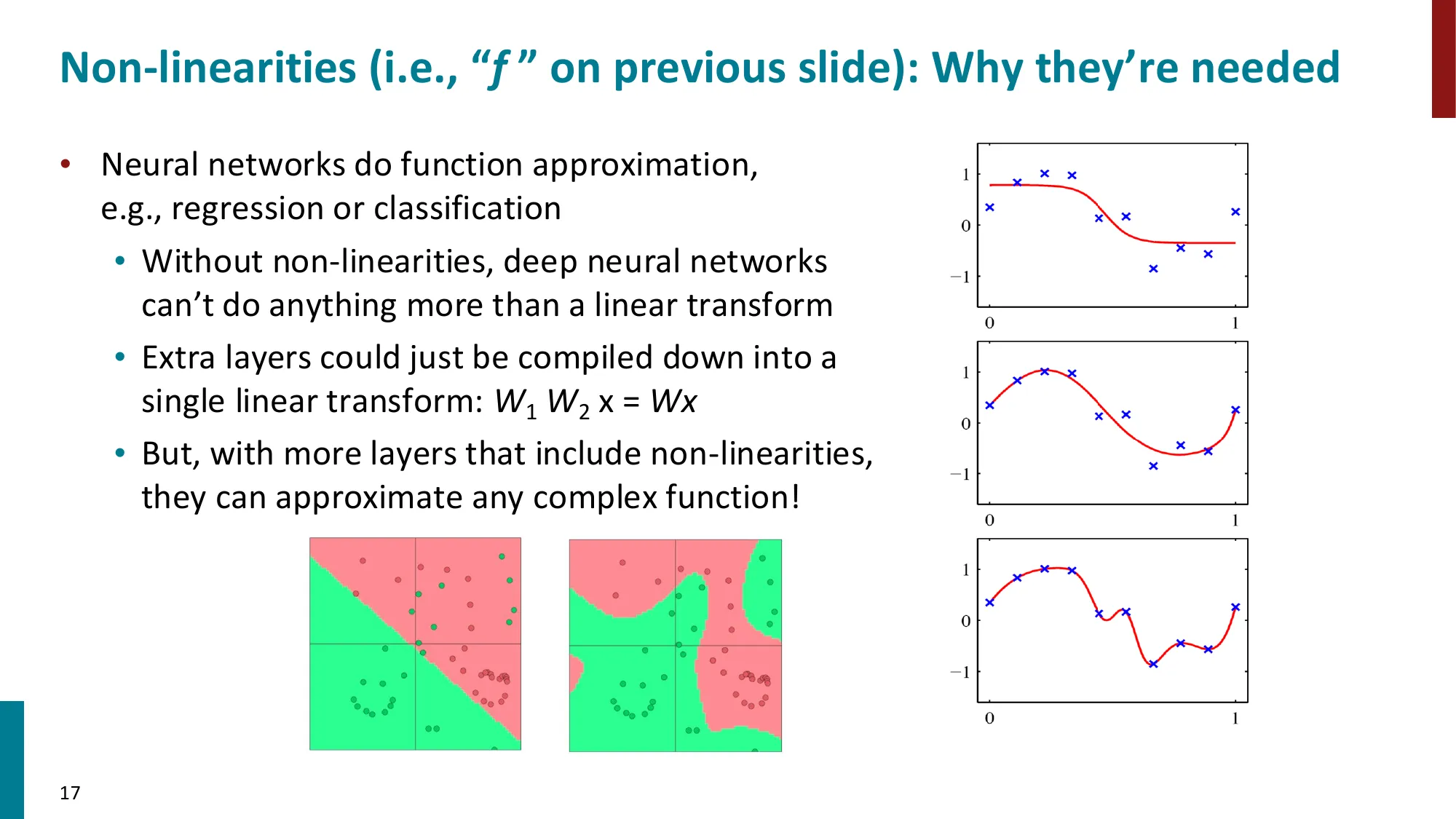
为什么需要非线性:若去掉 f,则 s=uT(W(1)x+b(1))=(uTW(1))x+uTb(1),等价于单层线性模型 s=wTx+c,无论堆多少层都如此。非线性是神经网络表达能力的根本来源。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:d=2,窗口大小 3(5d→ 此例简化为窗口大小 3,即输入维度 =3d=6),隐藏层 m=4,激活函数 tanh
W(1)=0.5−0.10.20.3−0.20.30.4−0.10.10.6−0.30.20.4−0.20.10.5−0.30.10.6−0.40.20.5−0.10.3∈R4×6
x=[0.2,0.1,0.5,0.8,0.9,0.3]T,b(1)=[0,0,0,0]T,u=[1,−1,1,−1]T
计算:
- z1(1)=0.5(0.2)−0.2(0.1)+0.1(0.5)+0.4(0.8)−0.3(0.9)+0.2(0.3)=0.1−0.02+0.05+0.32−0.27+0.06=0.24
- 类似计算其余分量(略),得 z(1)≈[0.24,0.61,0.14,0.02]T
- 激活:h=tanh(z(1))≈[0.235,0.545,0.140,0.020]T
- 评分:s=uTh=0.235−0.545+0.140−0.020=−0.190
- 概率:p=σ(−0.190)≈0.453(约 45% 概率为正类)
💡 为什么这样做?
神经网络的本质是特征变换器。第一层把原始词向量组合成”更抽象的特征”,激活函数引入非线性,使得决策边界可以弯曲——比线性分类器(只能画直线分割)强大得多。
类比:你想区分猫和狗,仅靠”耳朵长度”(一维)不够,但”耳朵长度 + 毛发颜色组合”(非线性特征)就能做到。神经网络自动学习哪些特征组合有用。
⚠️ 常见误区
- 误区:s=uTh 输出的是概率 → 正确:s 是原始评分(可正可负,无界),经过 sigmoid 才变成 (0,1) 区间的概率
- 误区:二分类用 sigmoid,多分类也用 sigmoid → 正确:多分类用 softmax(对所有类别归一化),二分类才用 sigmoid(等价于 2 类 softmax)
- 误区:偏置 b 不重要 → 正确:偏置允许决策边界不过原点,大幅提升模型灵活性
4. 非线性激活函数
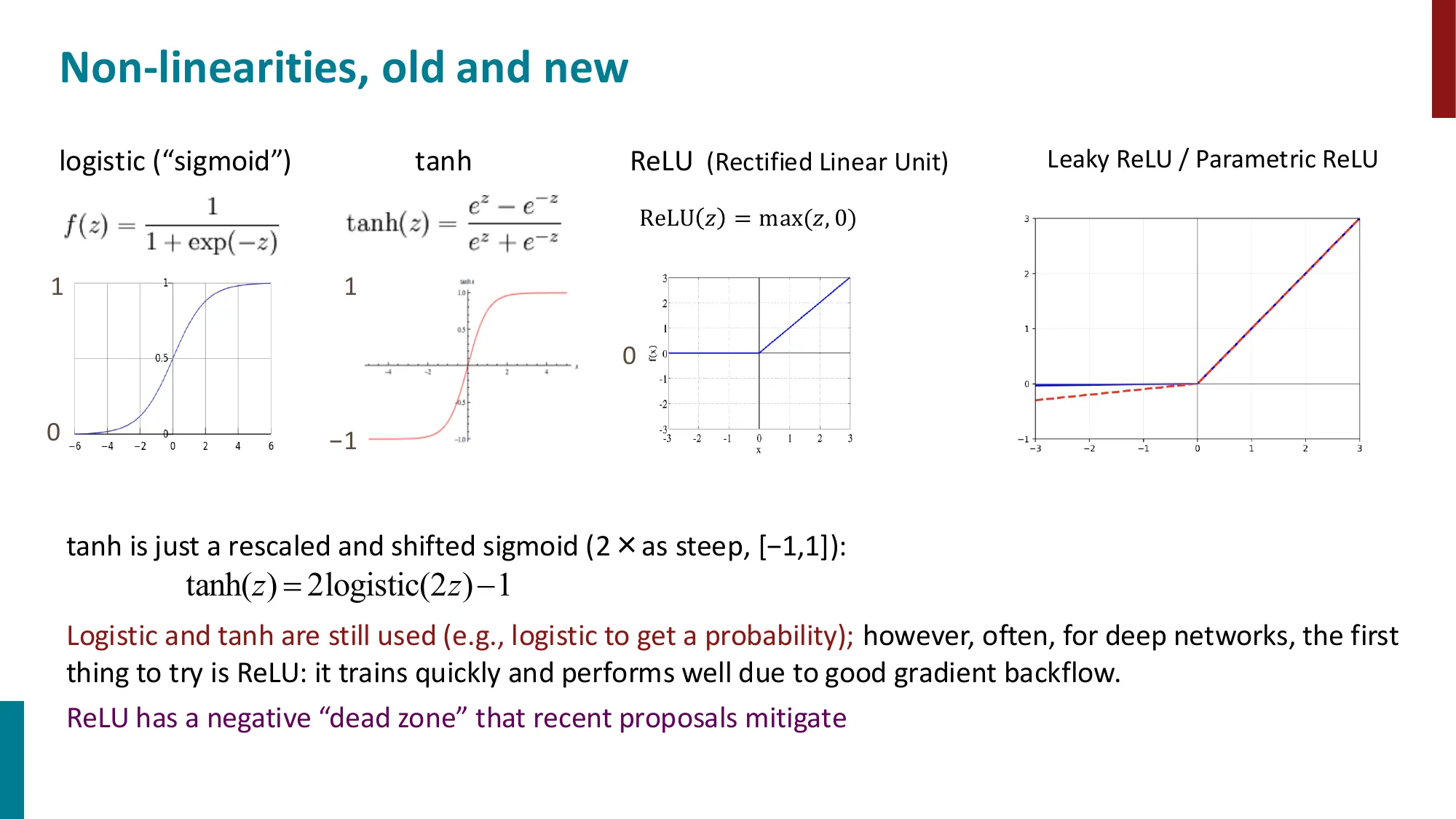
- Sigmoid / Logistic:f(z)=1+exp(−z)1,范围 (0,1)
- tanh:tanh(z)=ez+e−zez−e−z,范围 (−1,1)
- tanh(z)=2⋅logistic(2z)−1
- ReLU:ReLU(z)=max(z,0)
- 训练快,梯度回传好;但有”死区”(负值区梯度为 0)
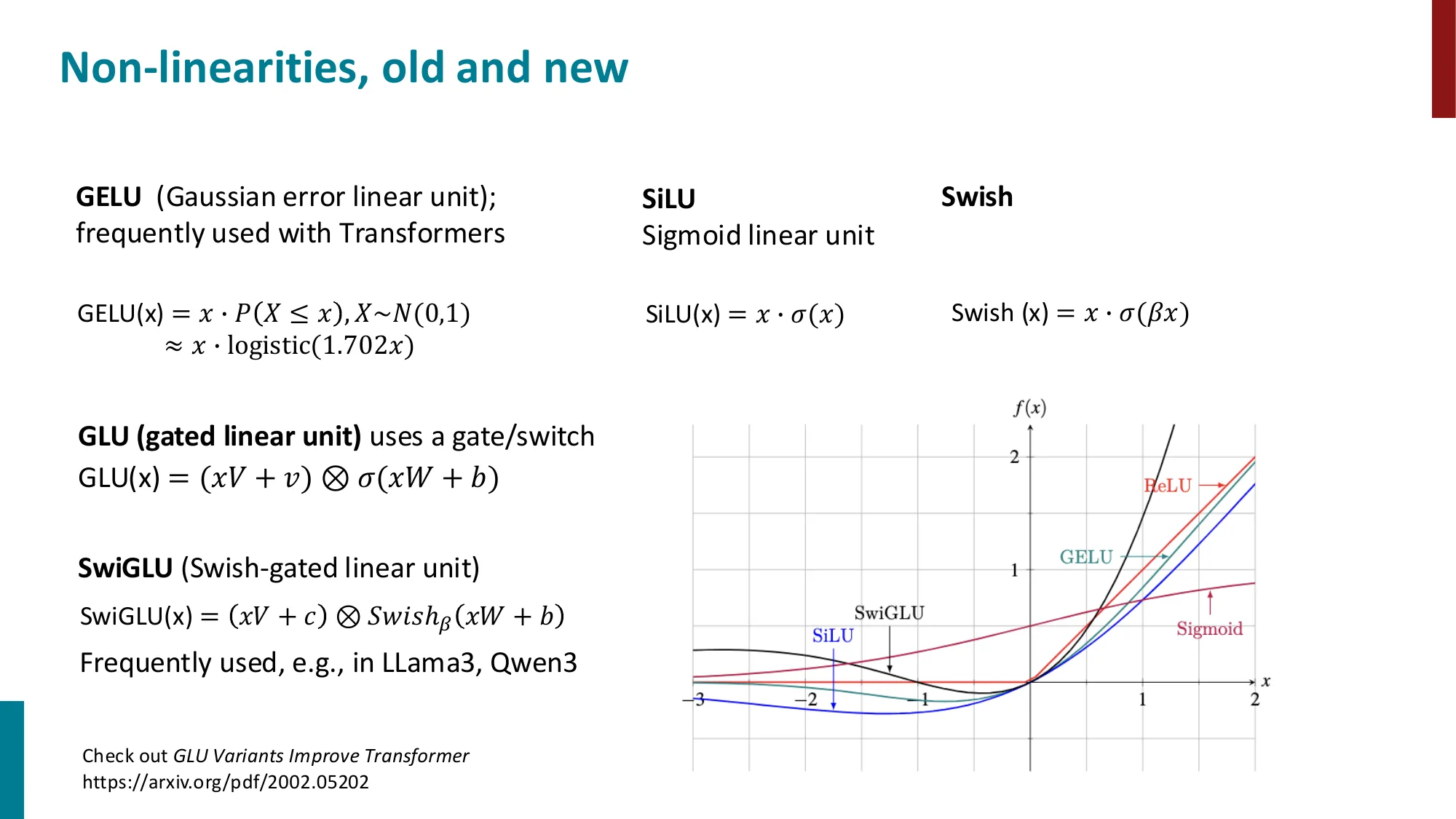
- GELU:GELU(x)=x⋅P(X≤x),近似 x⋅logistic(1.702x)
- SwiGLU:SwiGLU(x)=(xV+c)⊗Swishβ(xW+b)
- 非线性的必要性:没有非线性,多层网络退化为单一线性变换 W1W2x=Wx
5. 交叉熵损失(Cross-Entropy Loss)
- 目标:最大化正确类别 y 的概率 = 最小化负对数概率
- 交叉熵:H(p,q)=−∑c=1Cp(c)logq(c)
- 当 p 为 one-hot 时,简化为 −logp(yi∣xi)
📐 交叉熵损失从 MLE 到公式完整推导
变量定义:
- θ = 模型参数
- ptrue(c) = 真实分布(one-hot,正确类别为 1,其余为 0)
- qθ(c∣x) = 模型预测的概率分布(softmax 输出)
- H(p,q) = 交叉熵(p 和 q 的交叉熵)
- N = 训练样本数
推导过程:
第 1 步:最大似然估计(MLE)。给定数据集 {(xi,yi)}i=1N,最大化所有样本的联合对数似然:
maxθ∑i=1Nlogpθ(yi∣xi)
第 2 步:等价于最小化负对数似然(NLL):
minθ−∑i=1Nlogpθ(yi∣xi)=minθ∑i=1NNLLi
第 3 步:与交叉熵的联系。交叉熵的定义:
H(ptrue,qθ)=−∑c=1Cptrue(c)logqθ(c∣x)
当 ptrue 为 one-hot(ptrue(y)=1,其余为 0),所有 c=y 的项乘以 0 消失:
H(ptrue,qθ)=−1⋅logqθ(y∣x)=−logpθ(y∣x)
因此:最小化交叉熵 = 最大化正确类别的 log 概率 = MLE。
第 4 步:整个数据集的平均损失(除以 N 以便不同大小数据集可比):
J(θ)=−N1∑i=1Nlogpθ(yi∣xi)=N1∑i=1NH(ptrue(i),qθ(⋅∣xi))
第 5 步:softmax + cross-entropy 合并简化。若 pθ(c∣x)=softmax(sc)=∑jesjesc,则:
−logpθ(y∣x)=−sy+log∑jesj
这正是 PyTorch 的 F.cross_entropy(内部做 log-softmax + NLL)。
📚 已收录至 拓展阅读:交叉熵损失与 MLE(含 KL 散度、二元交叉熵、Label Smoothing 扩展)
🔢 数值计算示例
设定:3 类分类(类别 0/1/2),正确标签为类别 1
| 变量 | 值 |
|---|
| one-hot label p | [0,1,0] |
| 模型 softmax 输出 q | [0.3,0.5,0.2] |
计算:
- 展开:H(p,q)=−0⋅log(0.3)−1⋅log(0.5)−0⋅log(0.2)
- 化简:=−log(0.5)=log2≈0.693
对比(若预测更准 q=[0.1,0.8,0.1]):H=−log(0.8)≈0.223,损失更低。
对比(若预测错误 q=[0.1,0.1,0.8]):H=−log(0.1)≈2.303,损失很高。
结论:正确类别预测概率越高,交叉熵越低,梯度信号越弱(已经”学好了”)。
💡 为什么用交叉熵而不是 MSE?
信息论视角:交叉熵 H(p,q) 度量的是”用 q 编码 p 事件所需的平均比特数”。p 和 q 越接近,H(p,q) 越小(趋近于 H(p,p)= 熵)。最小化交叉熵就是让模型预测分布尽量接近真实分布。
梯度优势:对 softmax 输出用 MSE,梯度中会出现 σ′(z)(sigmoid 导数),在饱和区几乎为零;而交叉熵的梯度是 y^−y(预测值减真实值),简洁且无饱和问题。
⚠️ 常见误区
- 误区:交叉熵 = 信息熵 → 正确:信息熵 H(p)=−∑plogp 只取决于真实分布;交叉熵 H(p,q)=−∑plogq 还取决于模型预测;两者相差一个 KL 散度:H(p,q)=H(p)+DKL(p∥q)
- 误区:多标签(multi-label)分类用 softmax + cross-entropy → 正确:多标签(一个样本可属于多个类别)应用 binary cross-entropy(每个标签独立的 sigmoid);softmax 强制概率之和为 1,不适合多标签
- 误区:log 底数是 10 → 正确:机器学习中统一用自然对数(底数 e),单位是 nats(比特用 log2,但实践中混用,因为只相差常数倍,不影响优化)
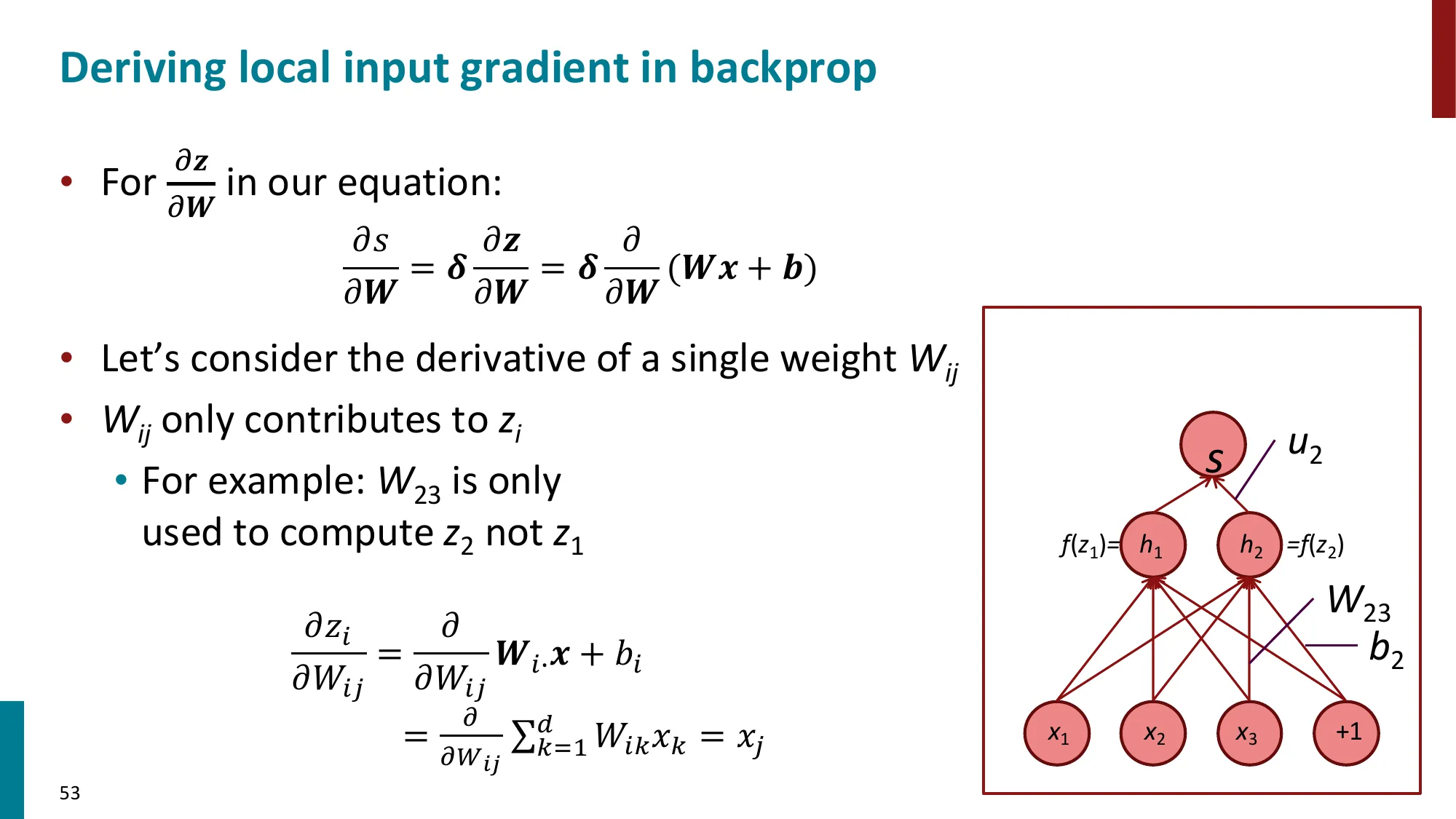
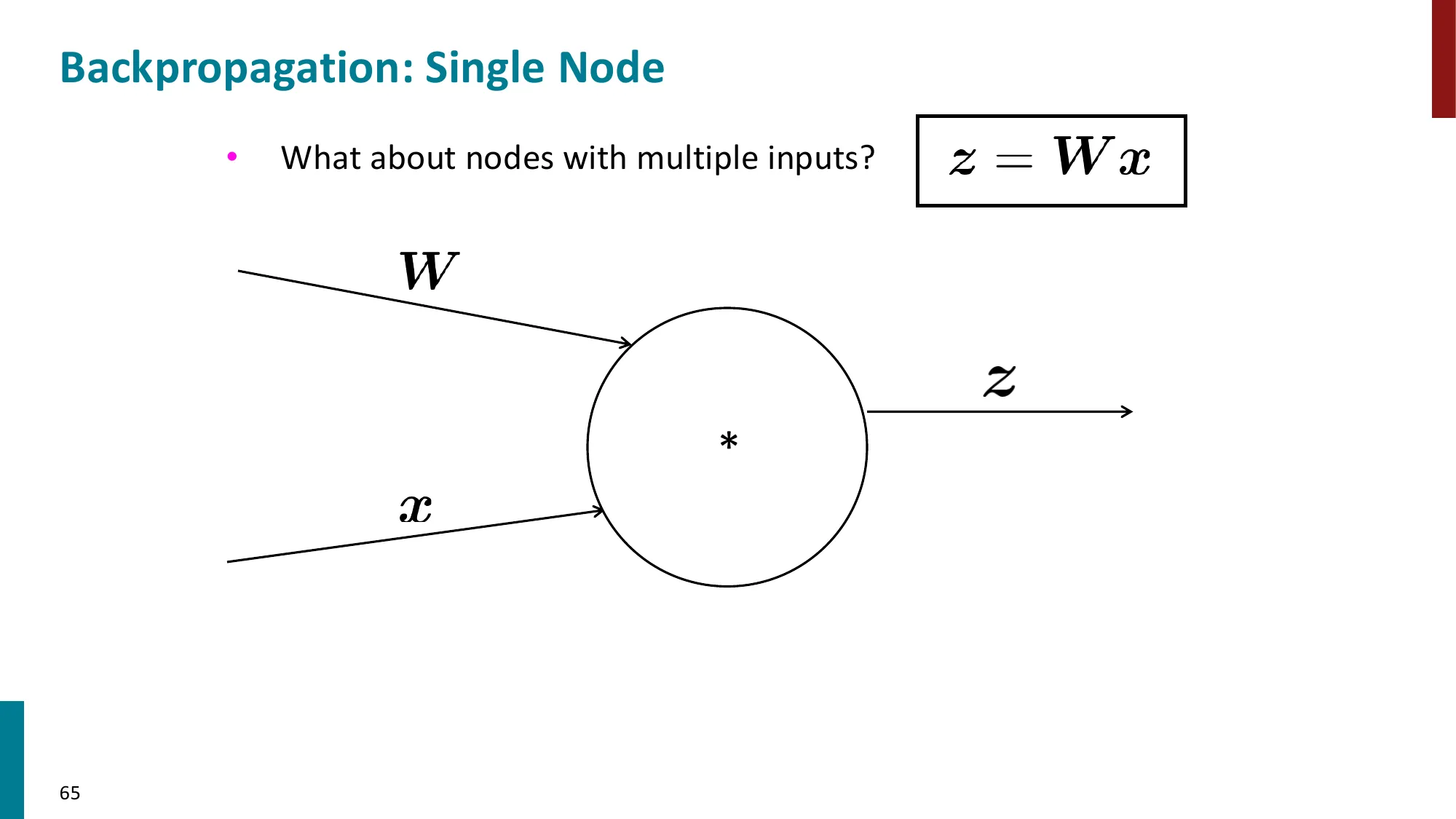
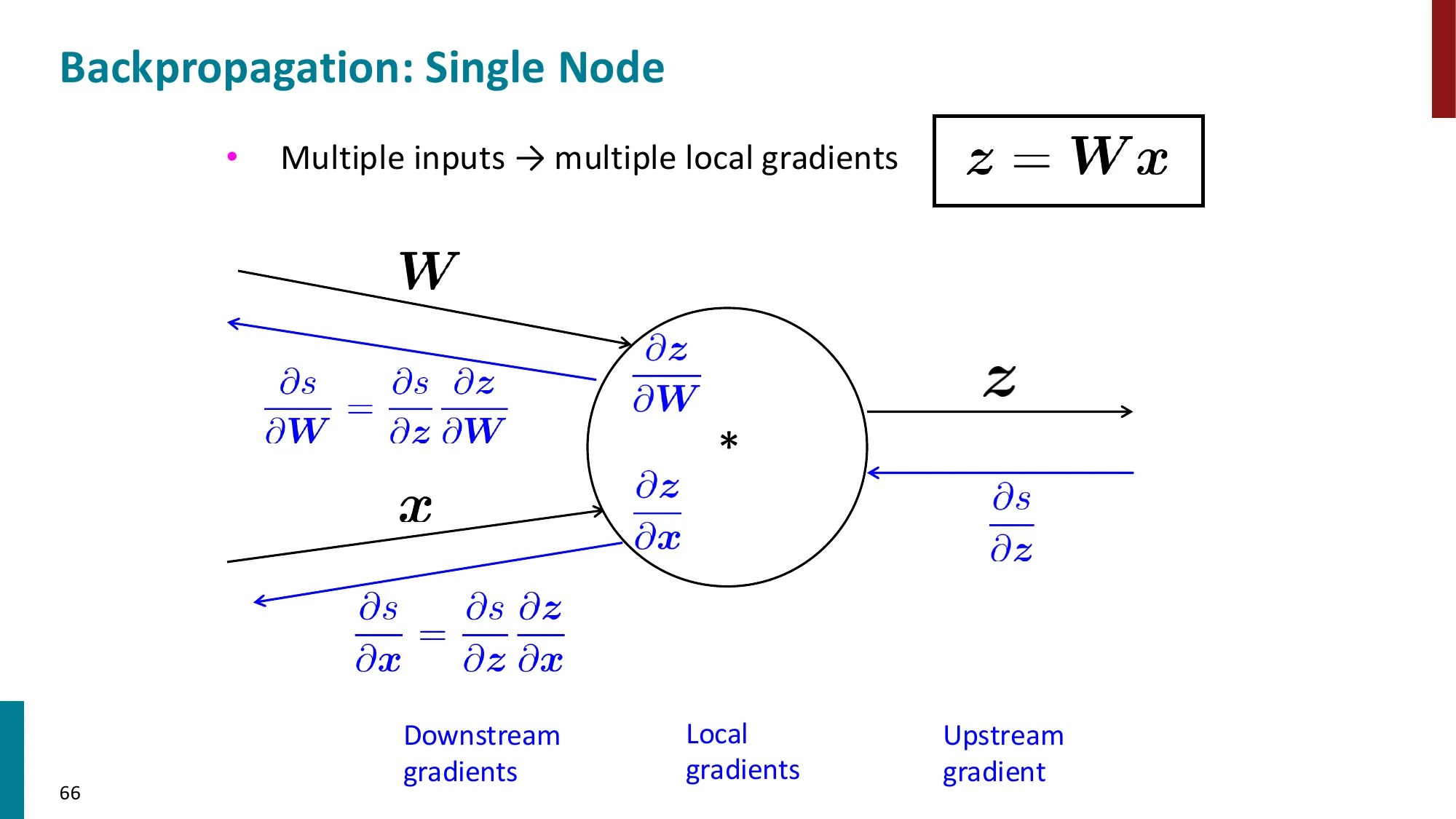
6. 矩阵微积分(Matrix Calculus)
- 雅可比矩阵(Jacobian):∂x∂f∈Rm×n,其中 (∂x∂f)ij=∂xj∂fi
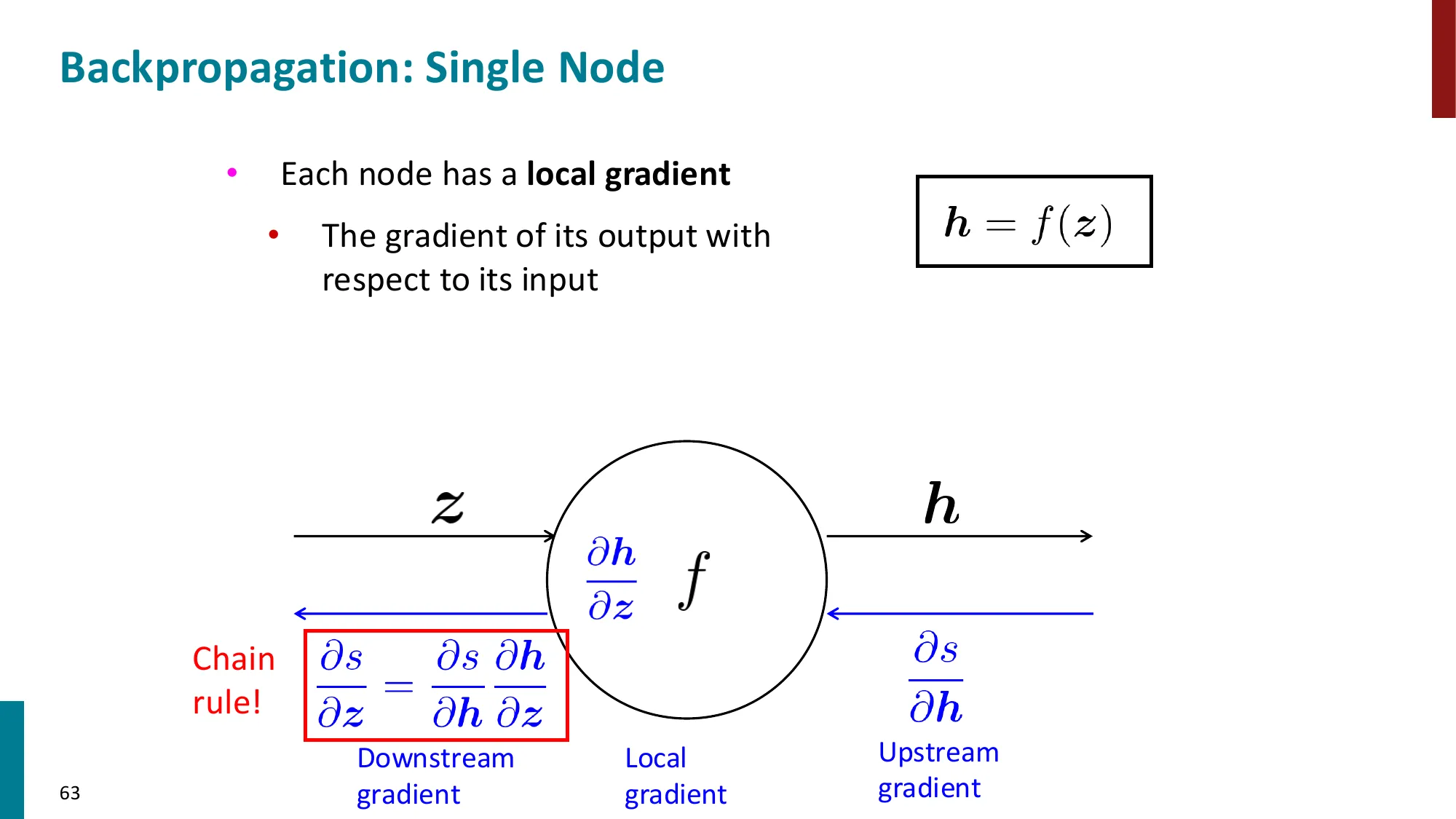
- 链式法则的矩阵形式:∂x∂s=∂x∂h⋅∂h∂s
- 实用规则:
- ∂x∂(Wx+b)=W
- ∂x∂f(z)=diag(f′(z))(逐元素非线性)
- ∂b∂(uTh)=uTdiag(f′(z))
- 形状约定(shape convention):梯度形状与参数形状相同(便于 SGD 更新)
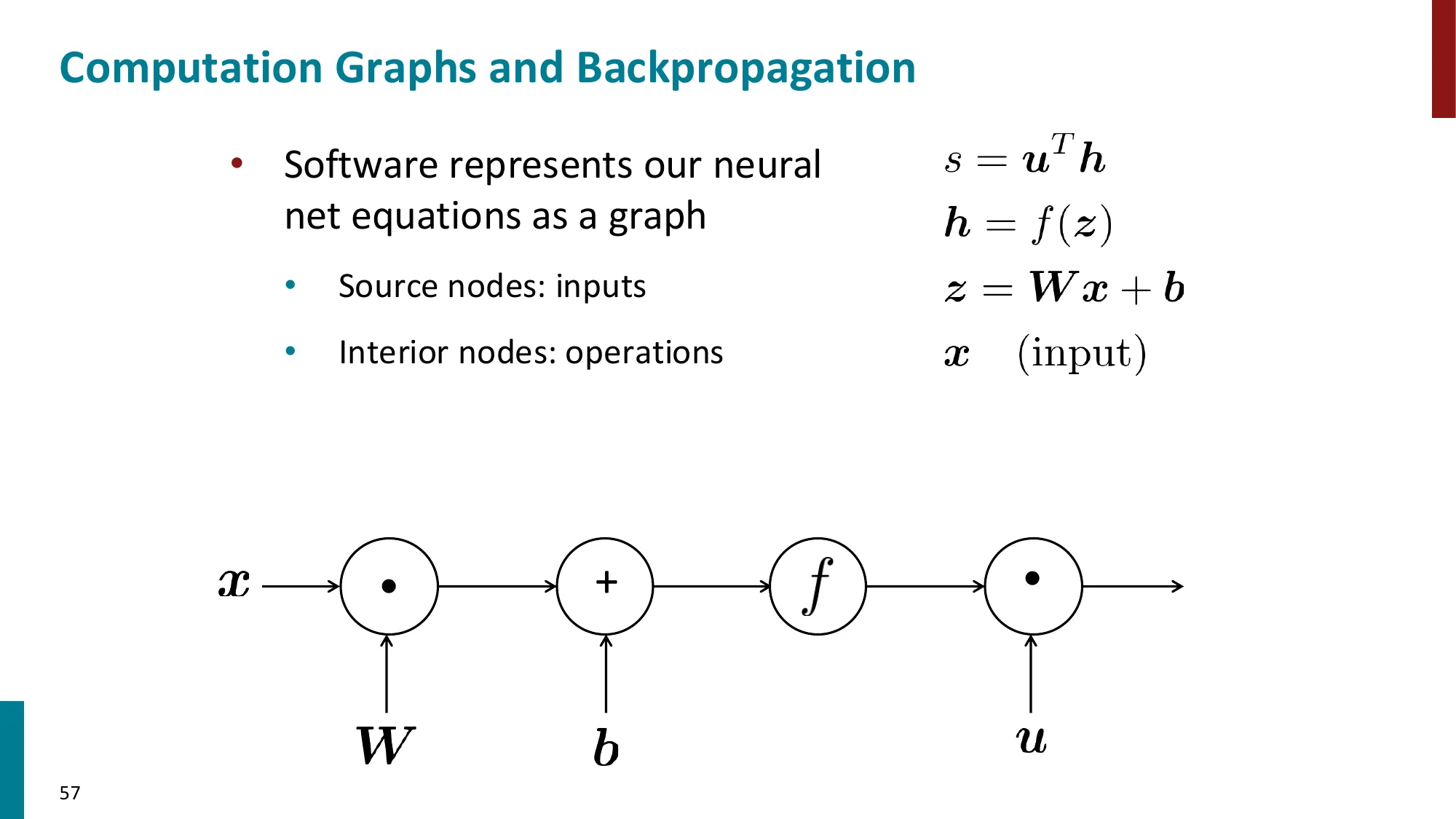
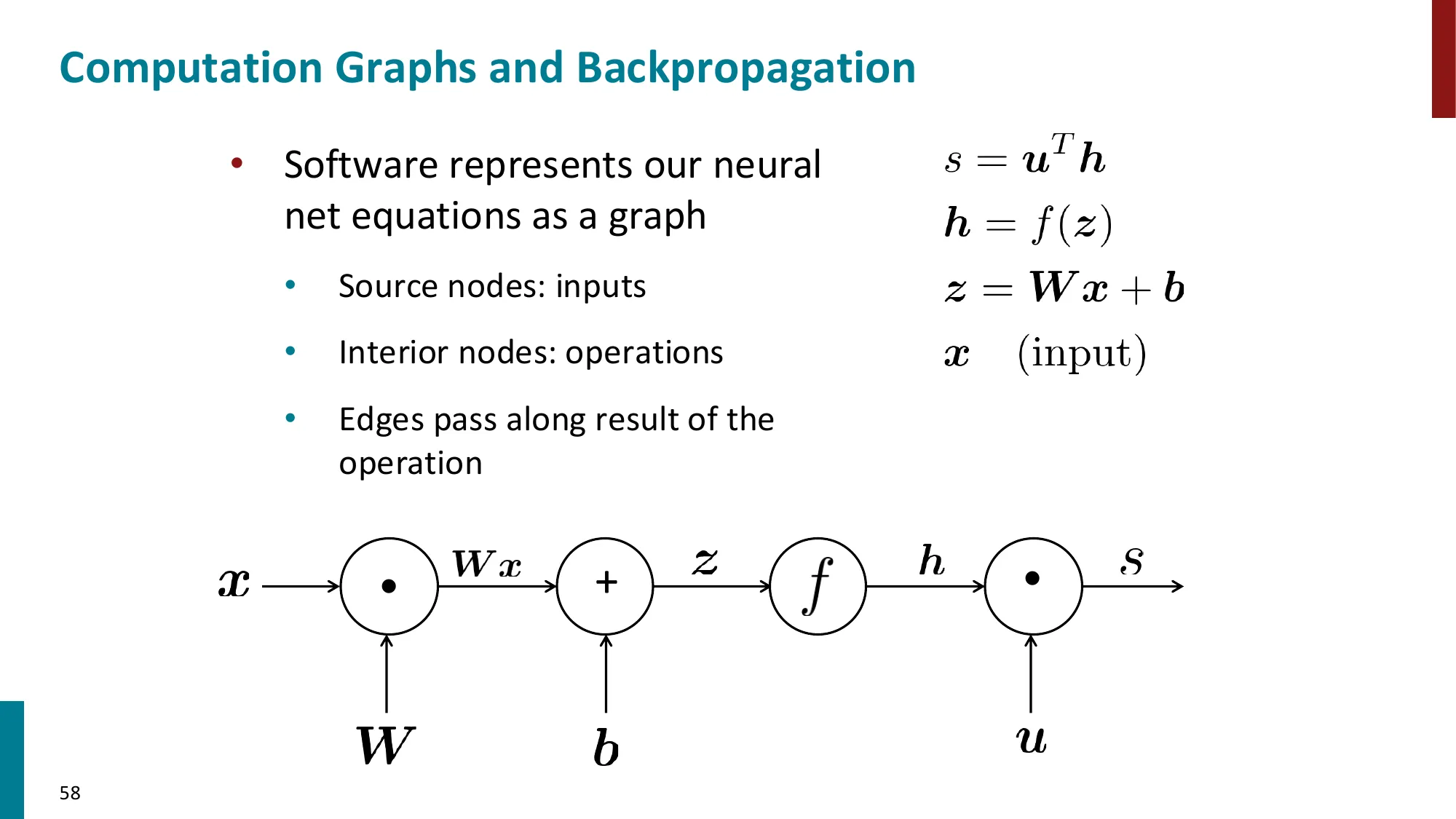
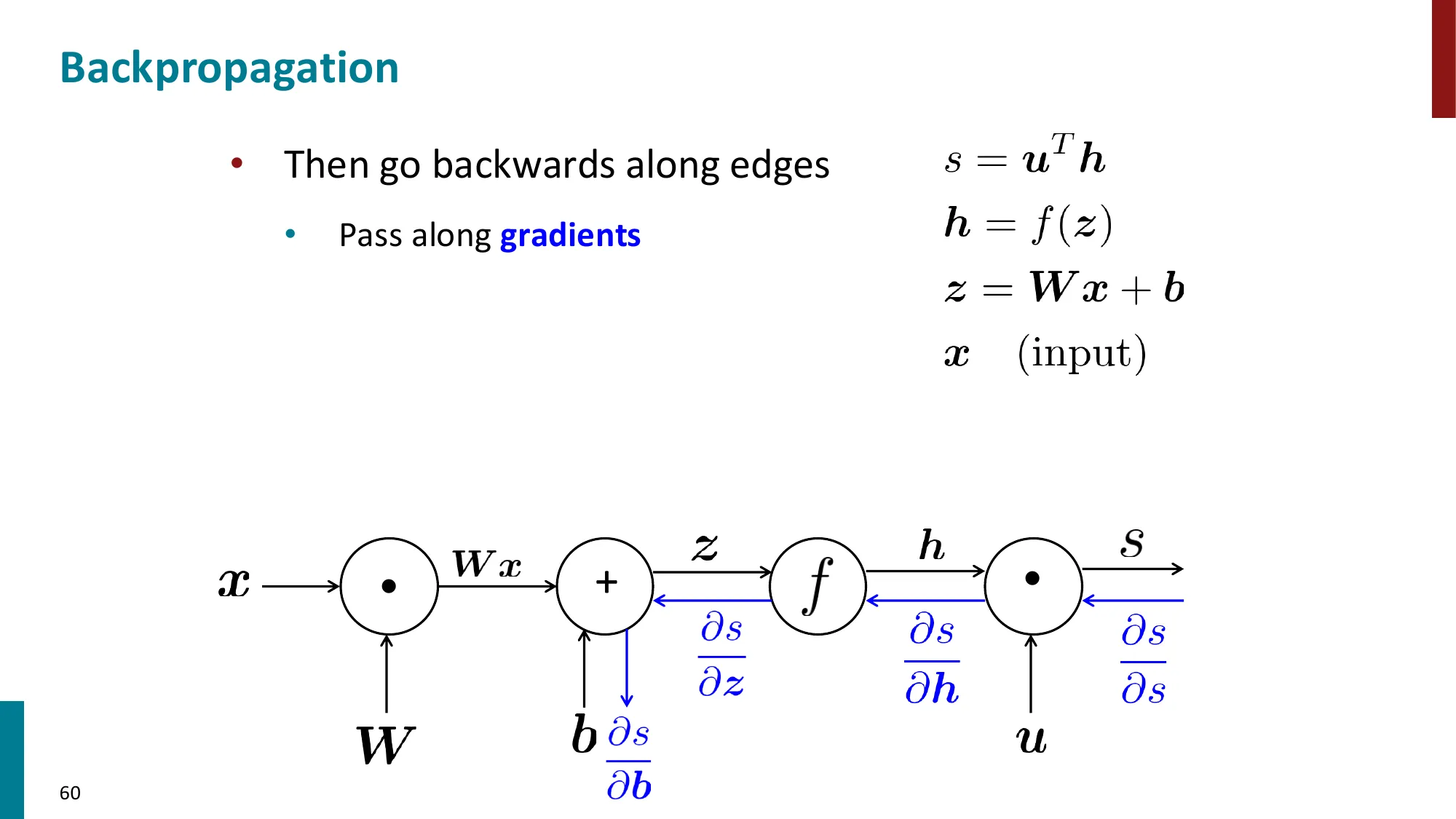
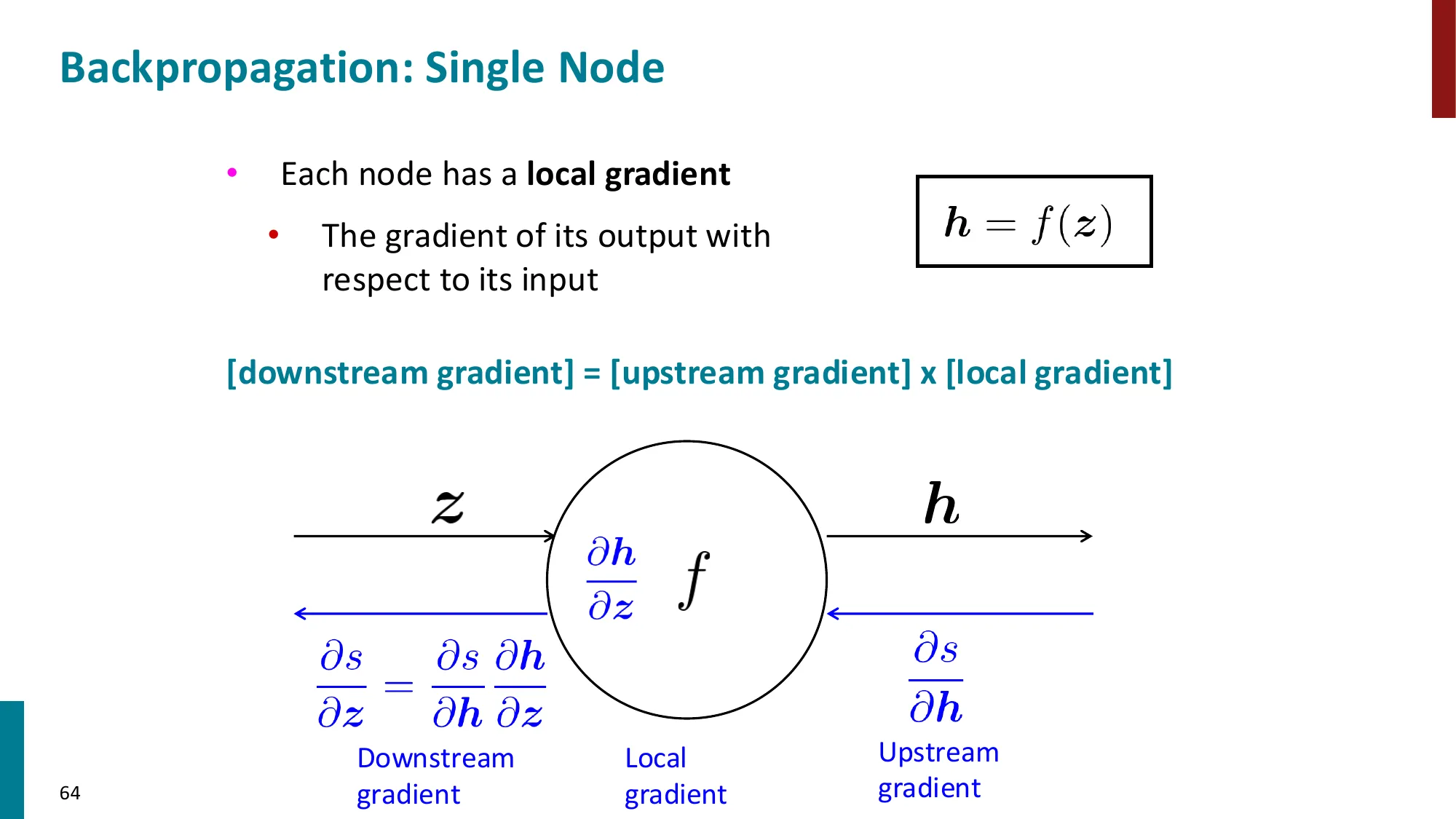
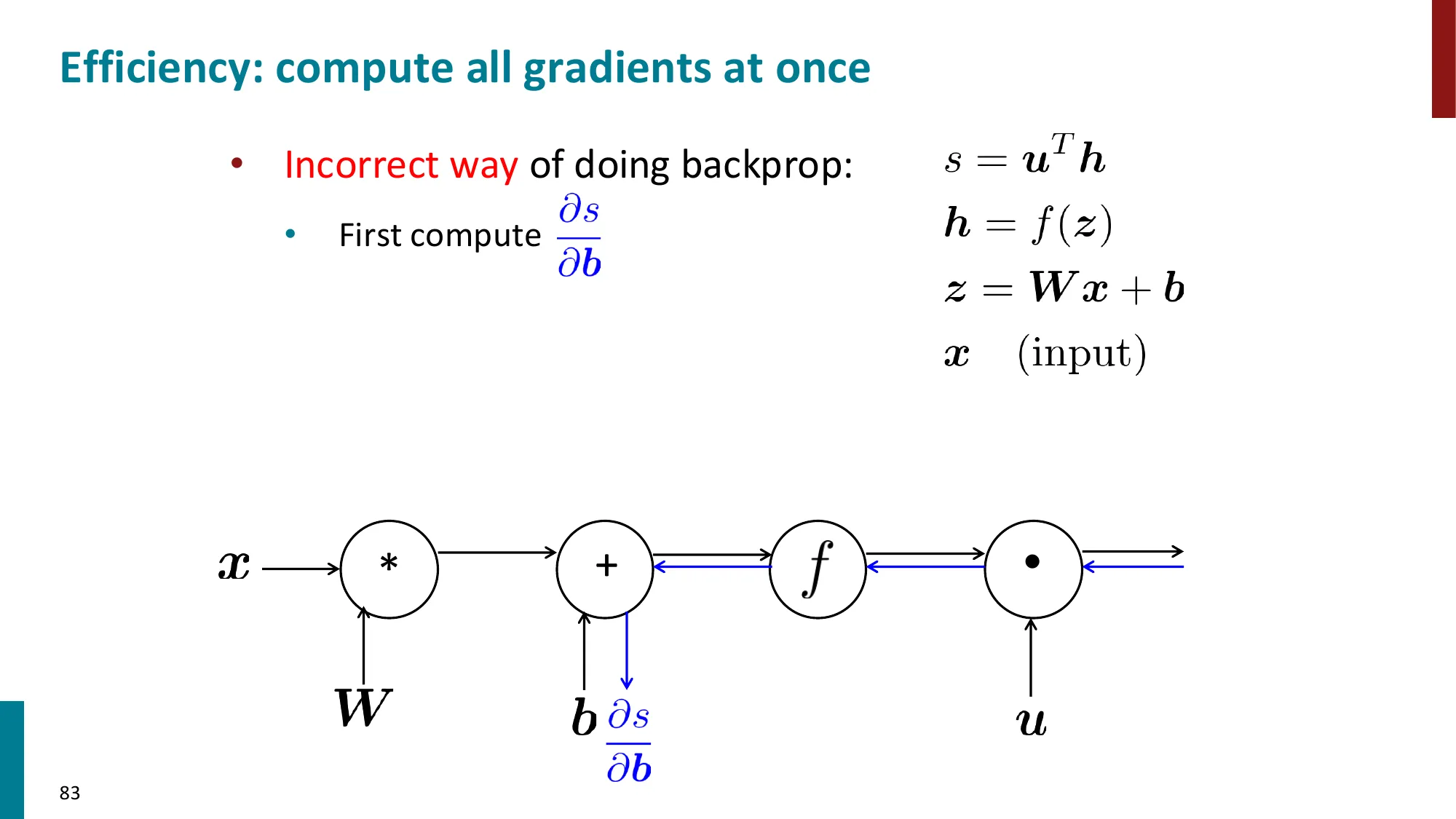
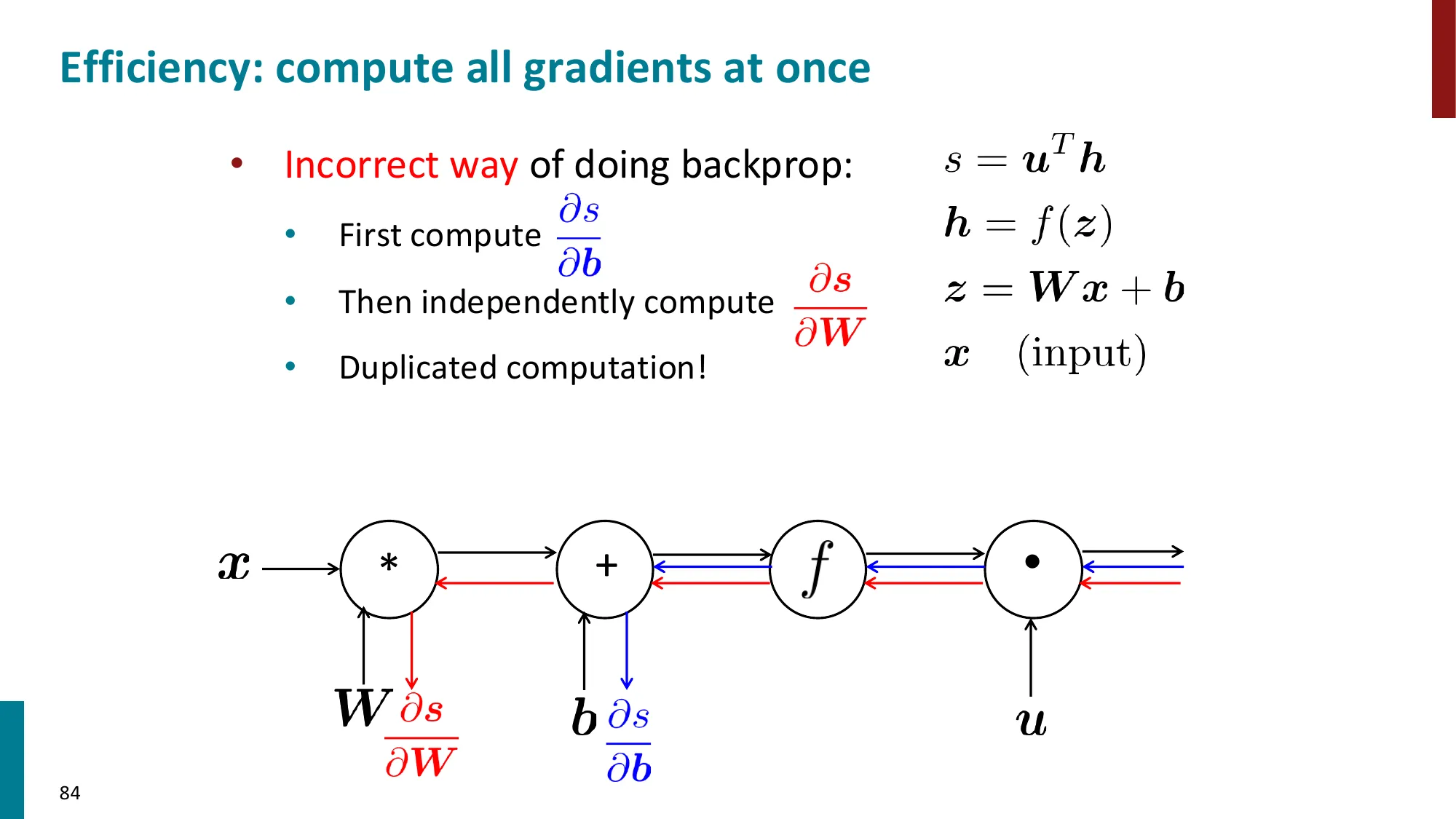
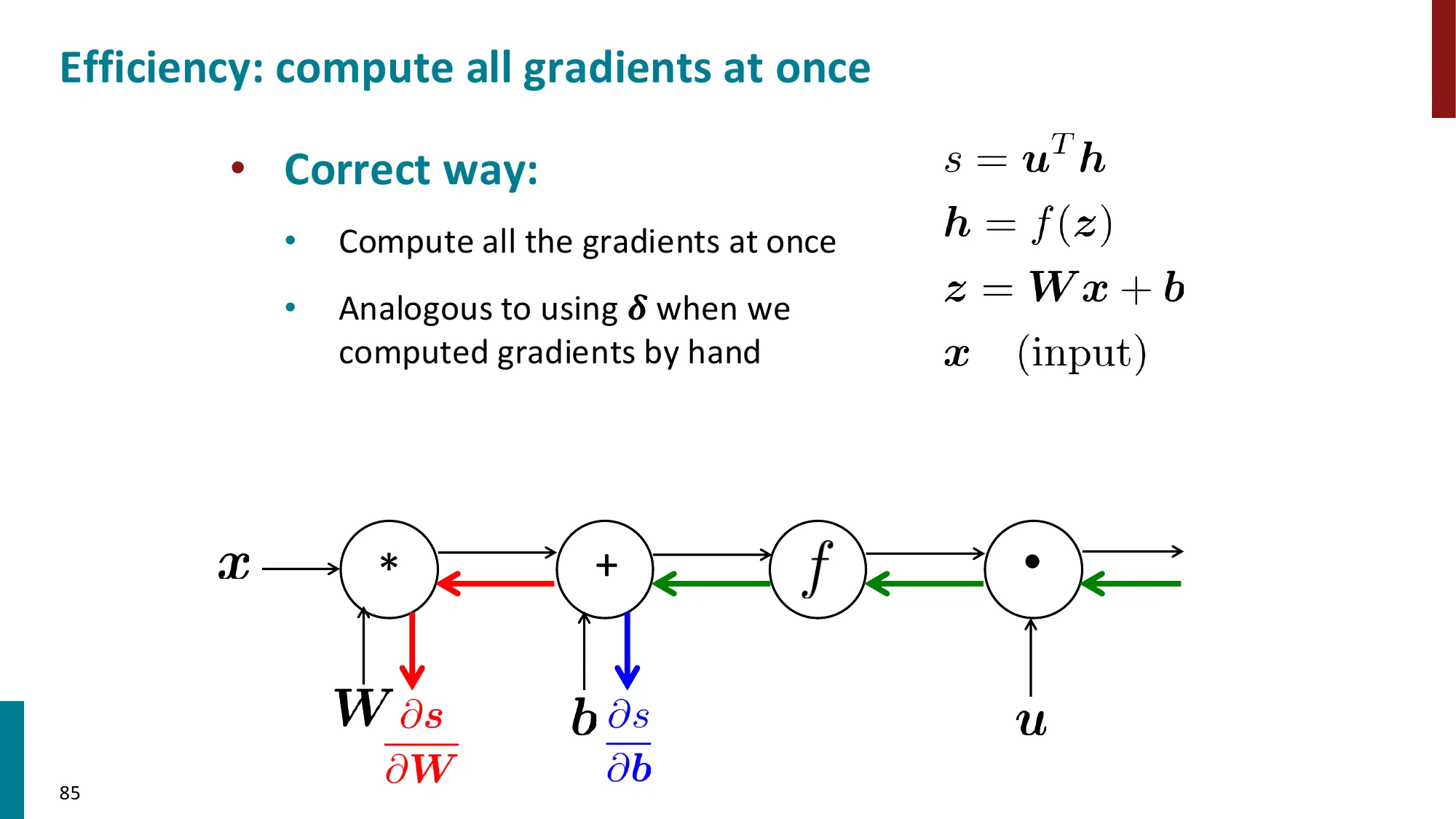
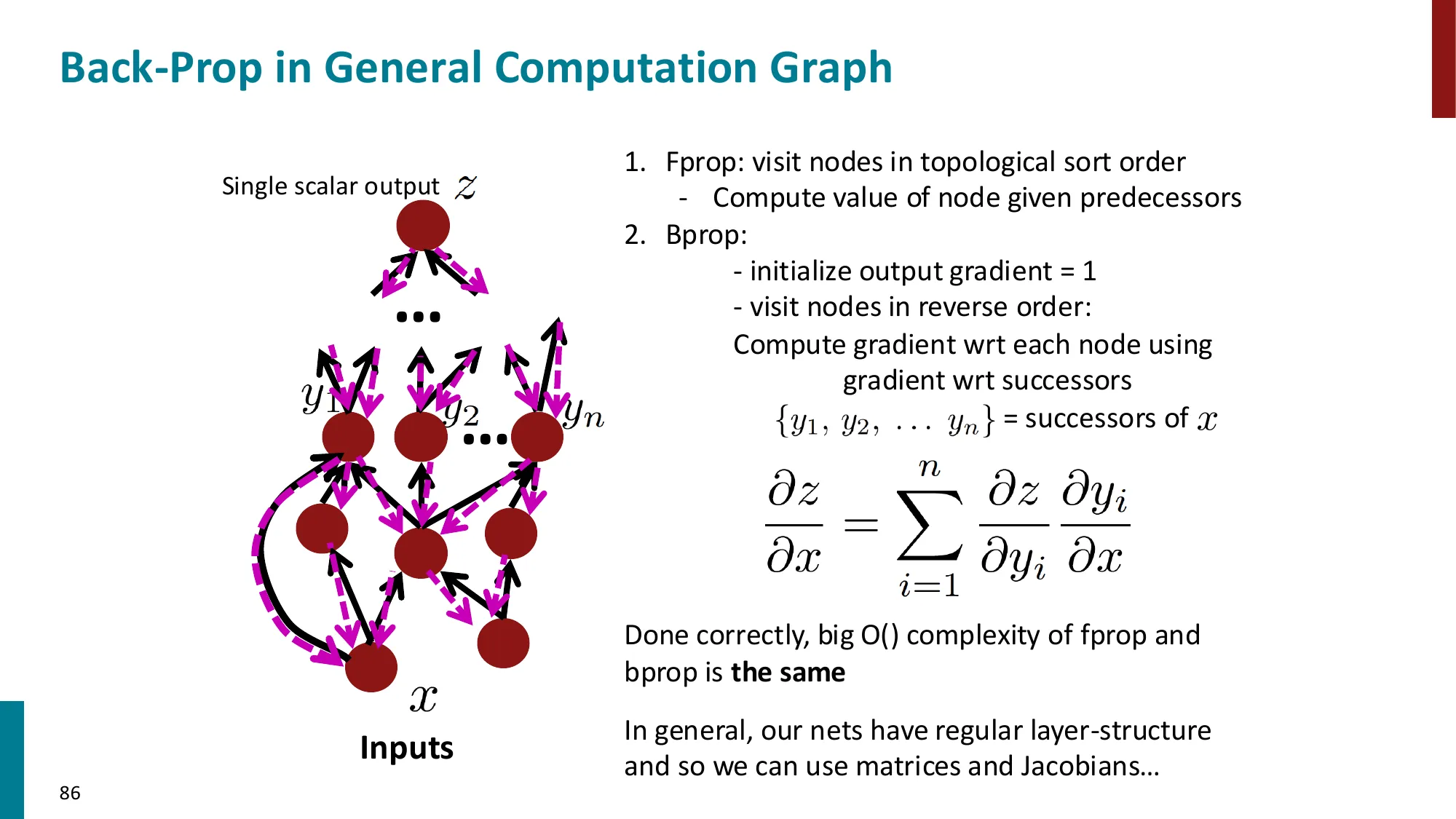
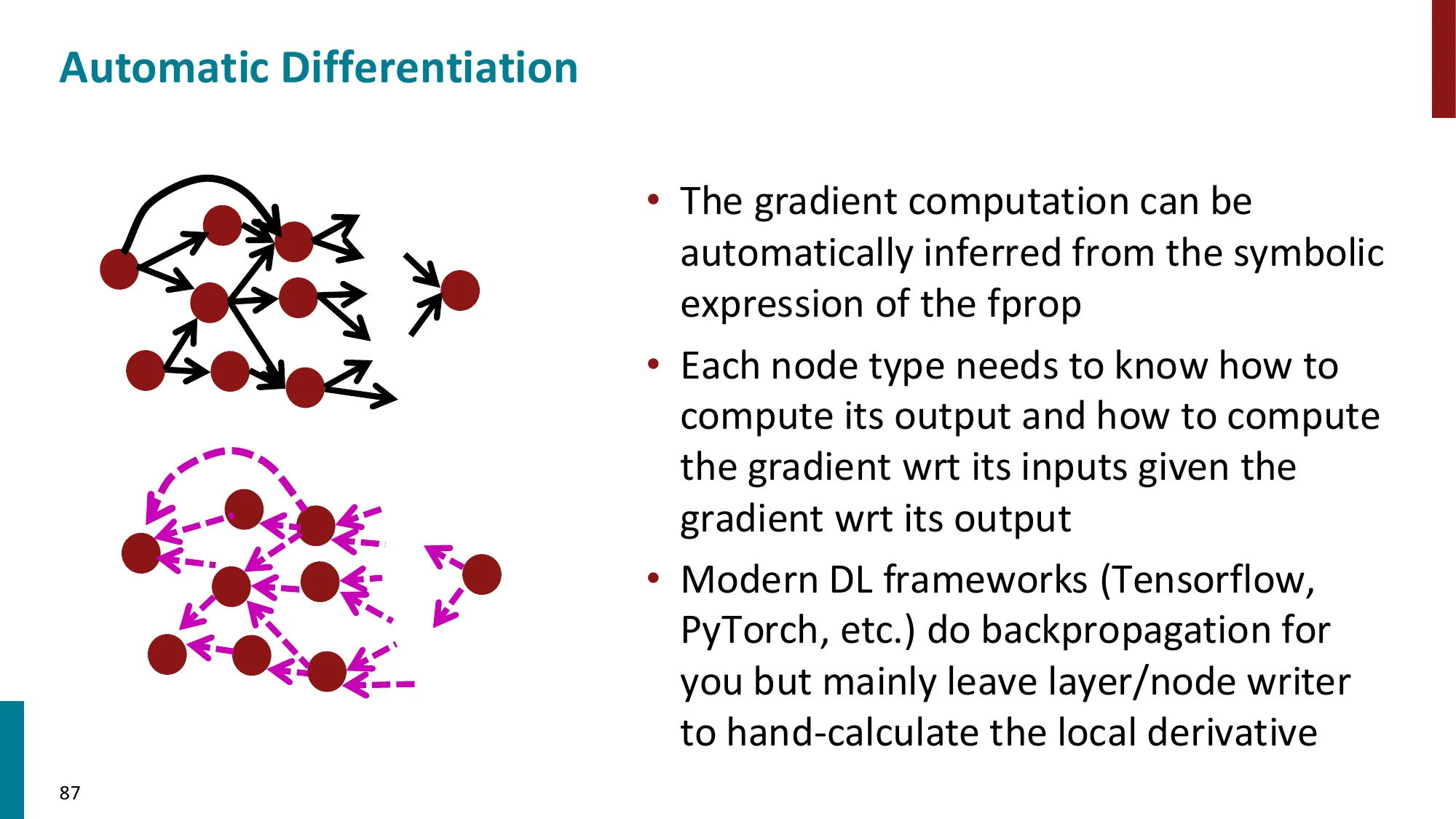
7. 反向传播算法(Backpropagation)
- 核心思想:利用计算图(computation graph)的链式法则从输出到输入逐层传播梯度
- 前向传播:计算各节点的值
- 反向传播:从损失出发,逆序传播梯度
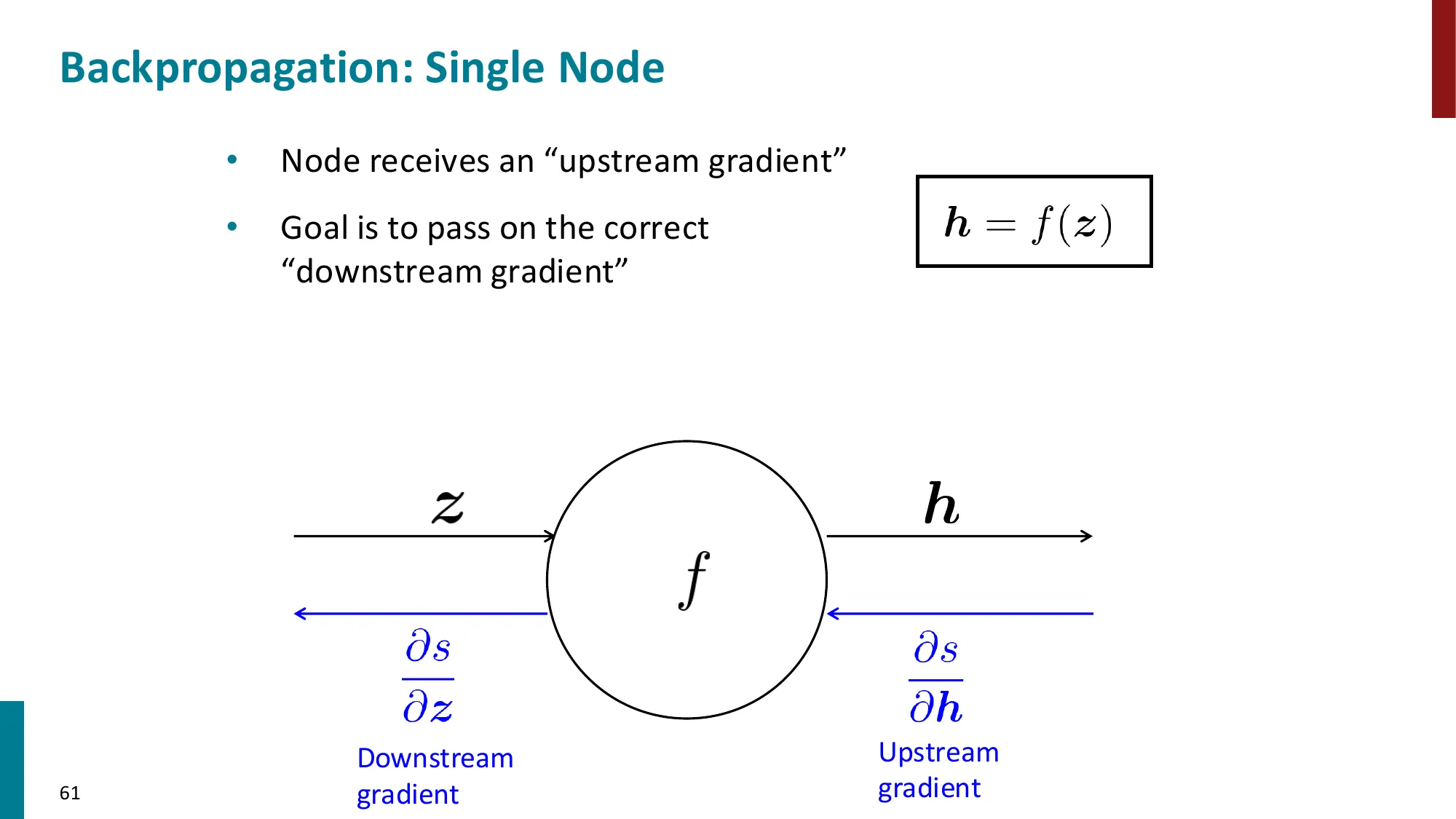
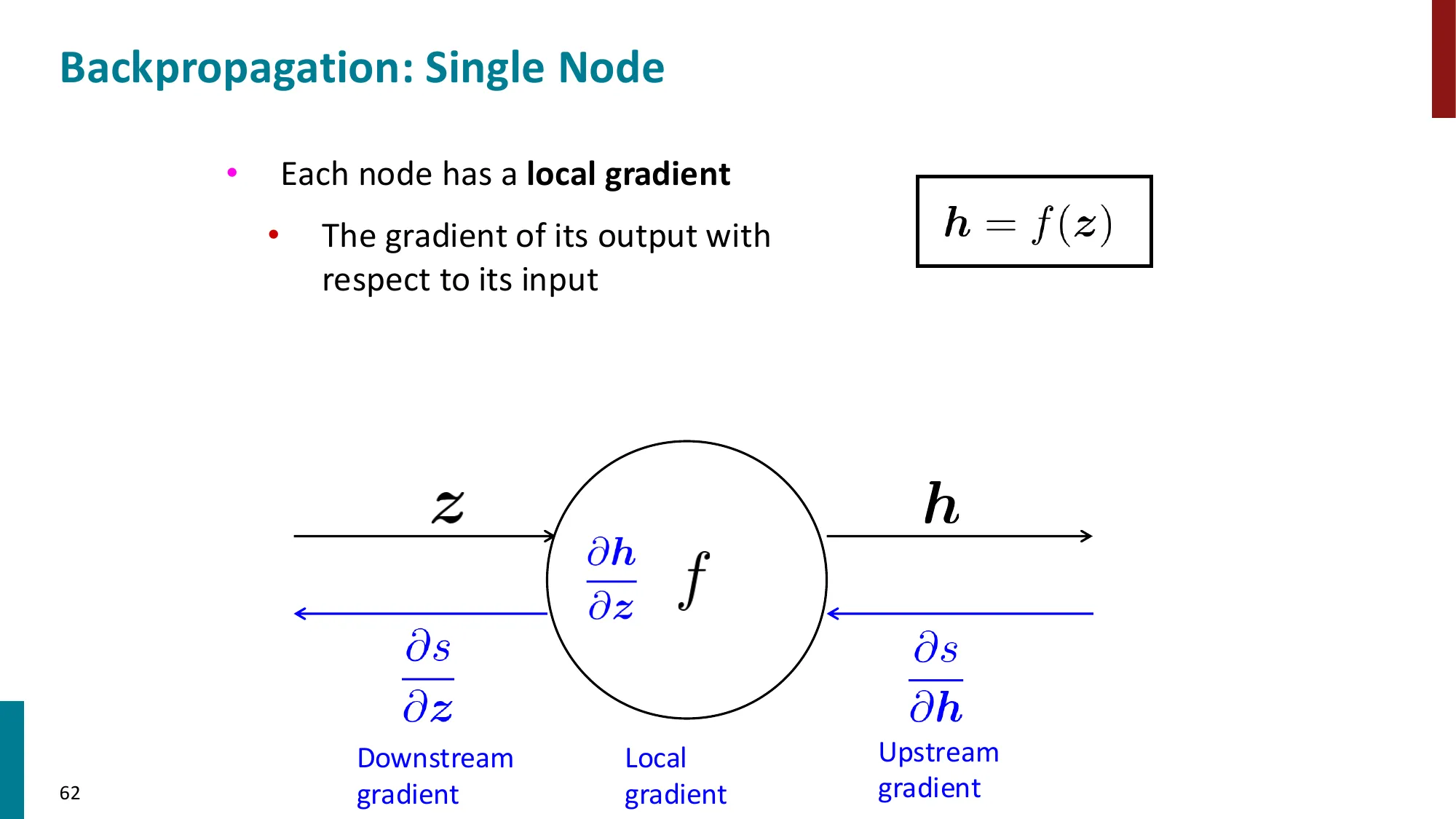
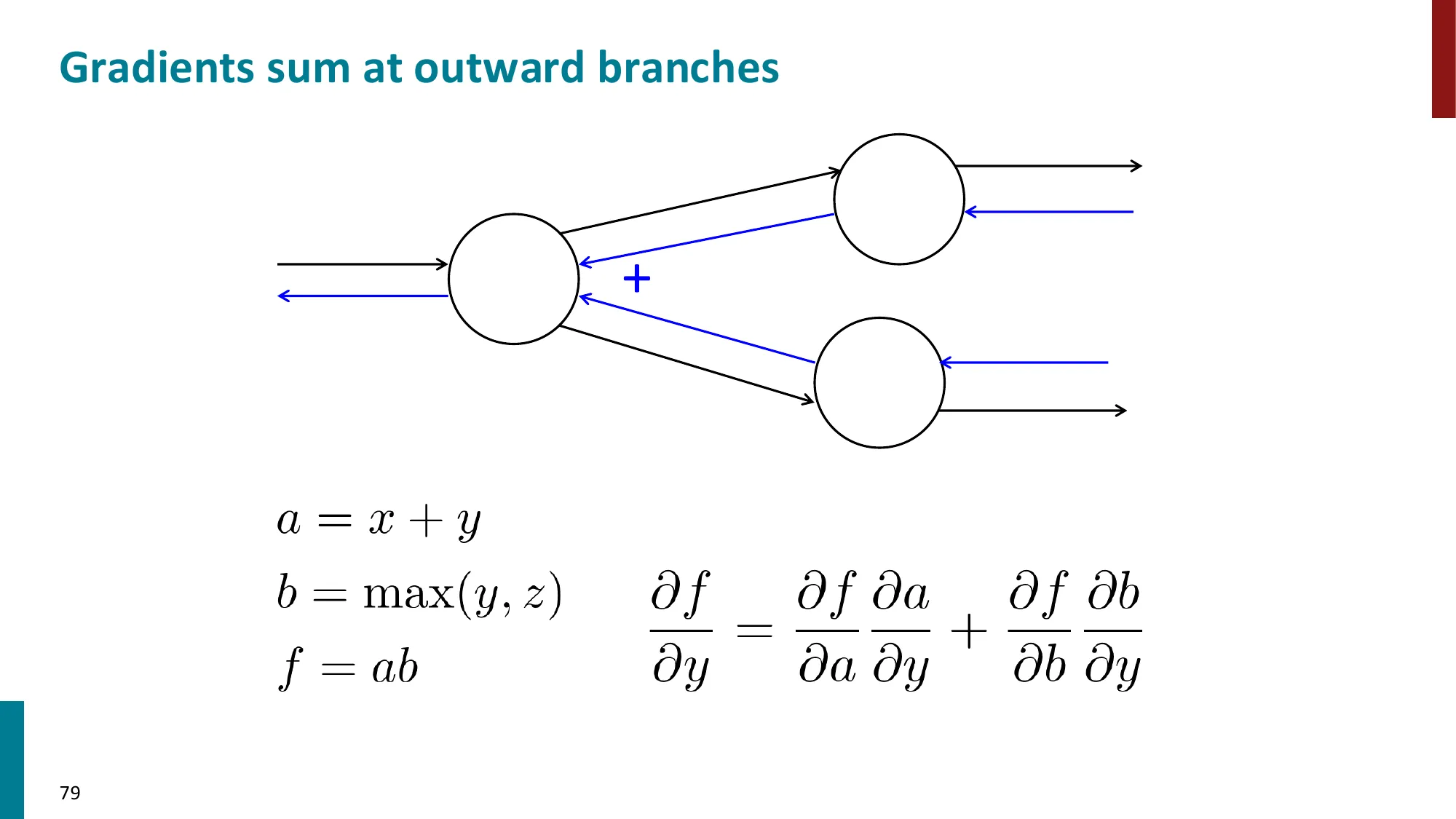
- 每个节点只需知道:局部偏导 × 上游梯度
- 上游梯度 = ∂z∂L(从后面传来的)
- 局部梯度 = ∂x∂z(本节点的偏导)
- 下游梯度 = 上游梯度 × 局部梯度
- 效率:每条边只遍历一次,时间复杂度 O(n)(n 为计算图中的节点数)
- 实现:PyTorch 的
autograd 自动完成
📐 反向传播完整推导:NER 二分类网络
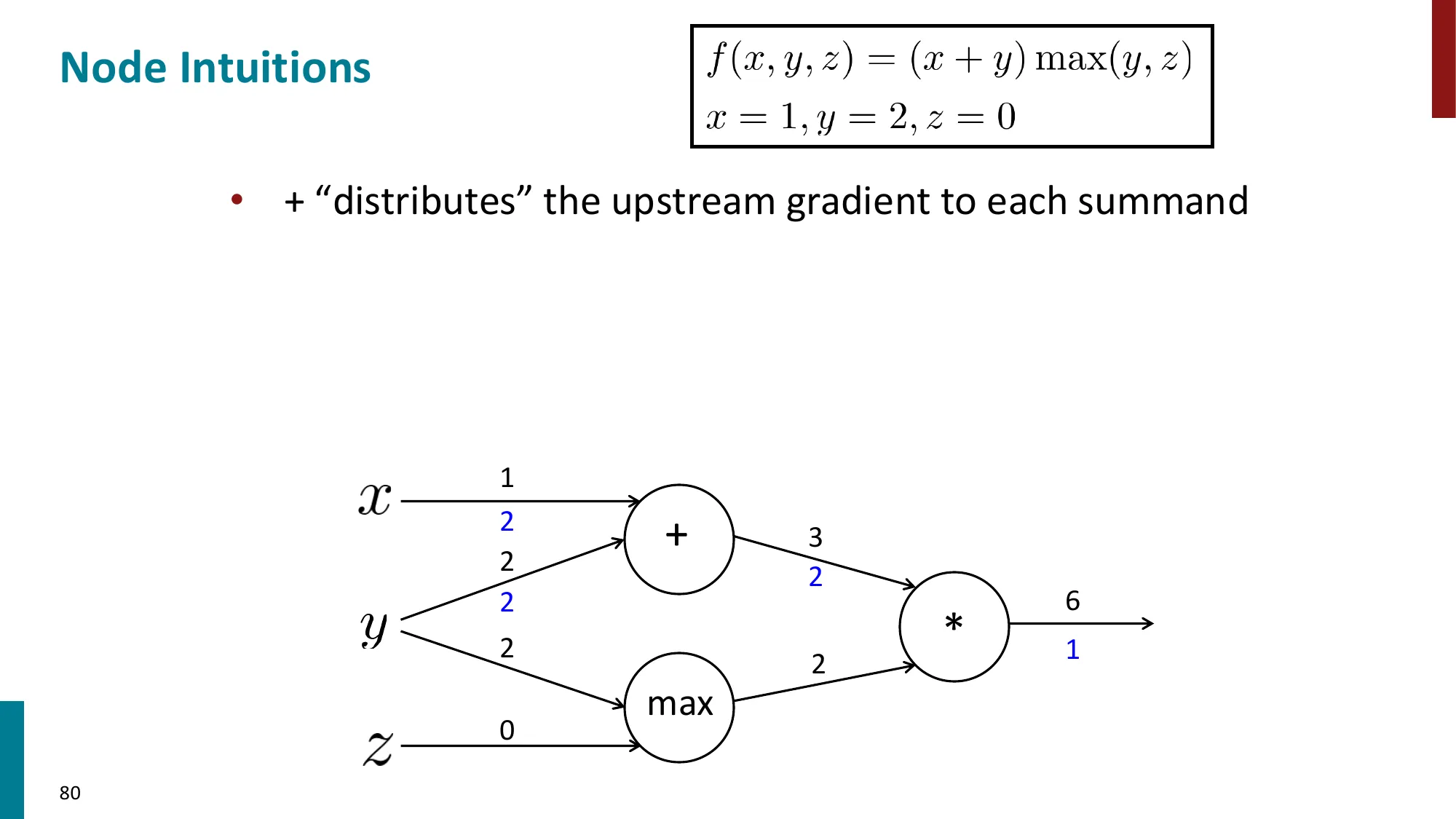
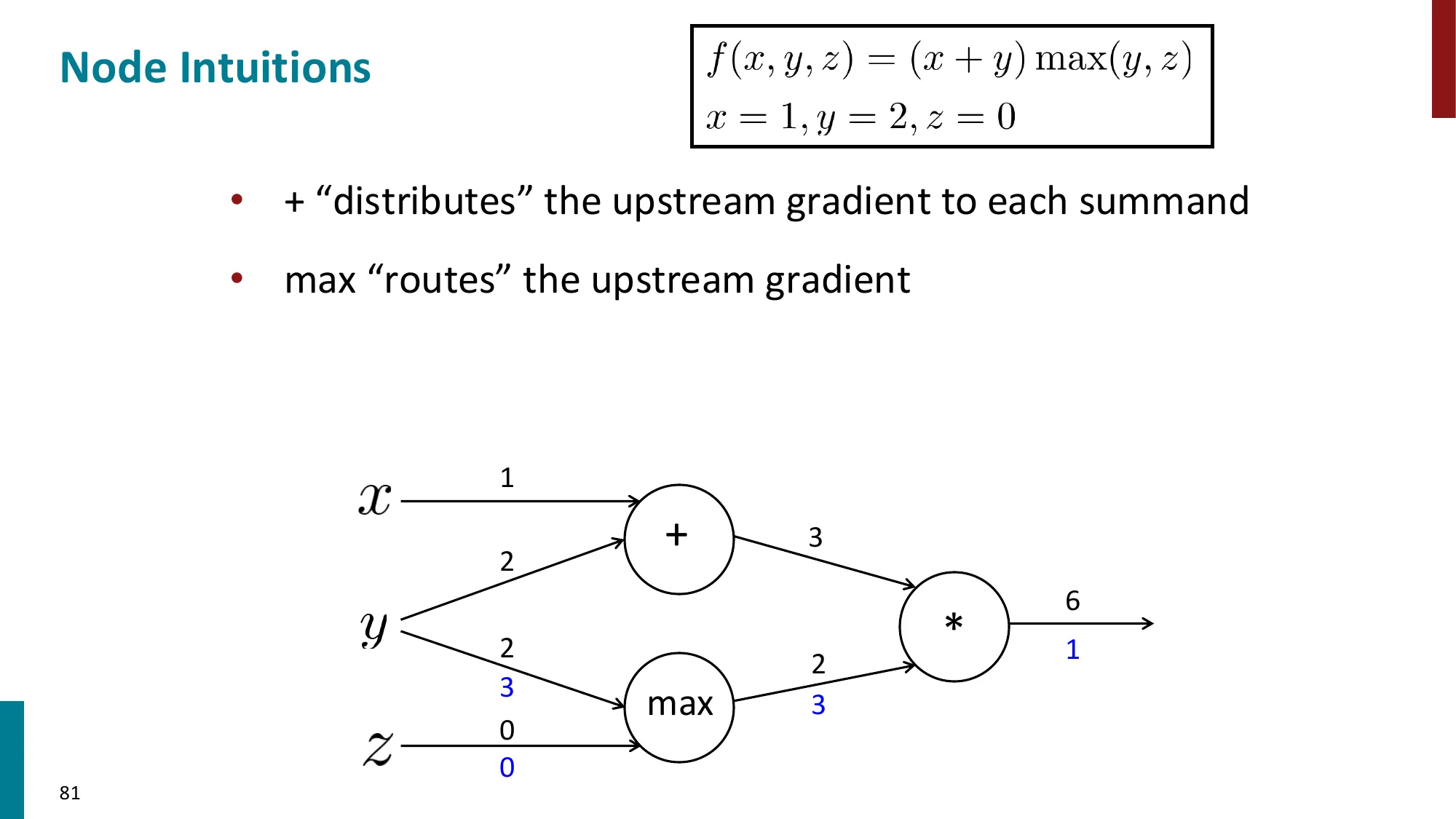
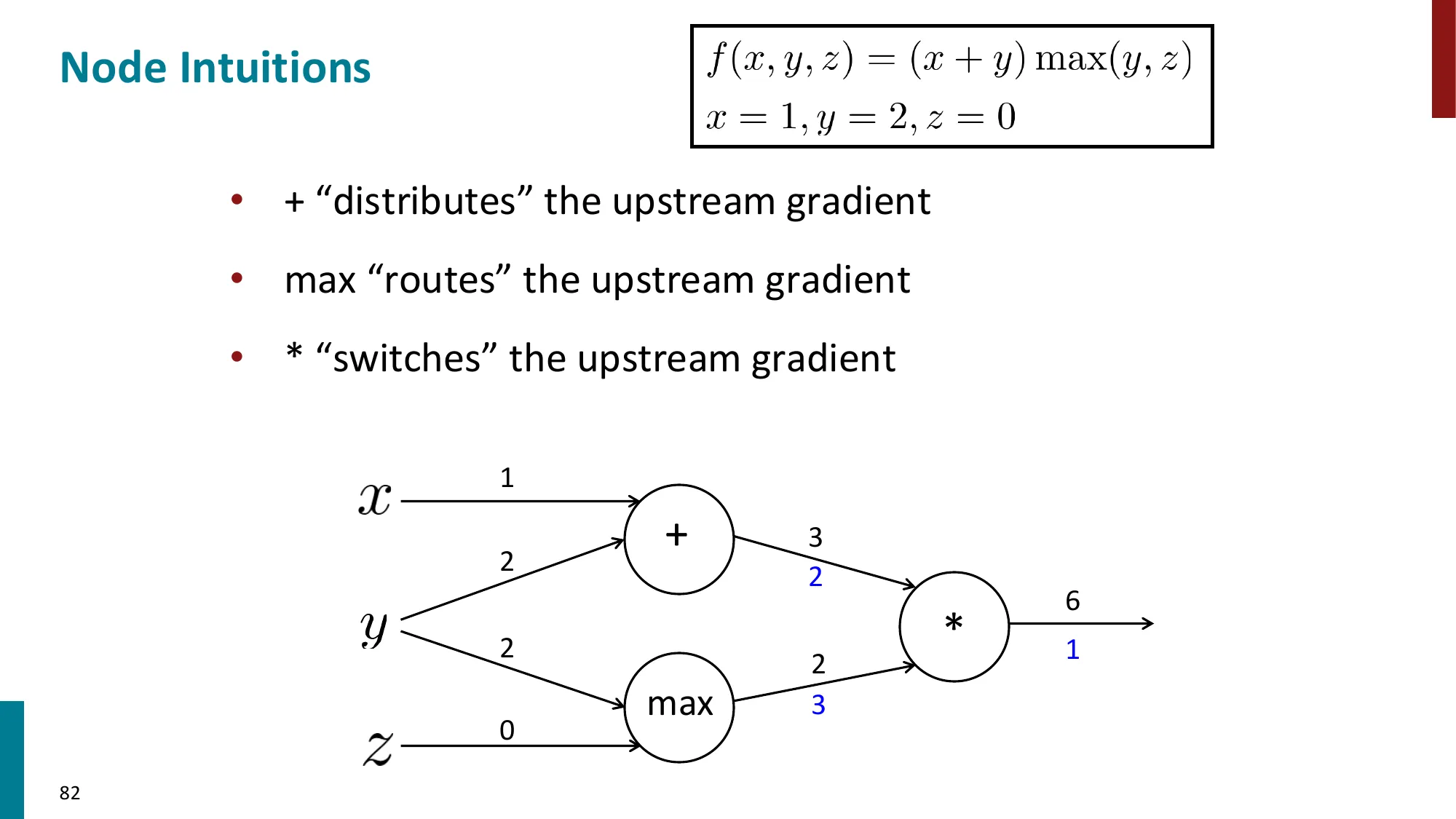
网络定义:
z(1)=Wx+b,h=tanh(z(1)),s=uTh,J=−logσ(s)(y=1 的二元交叉熵)
参数:θ={W,b,u,x}(此处也对输入 x 求梯度,以便更新词向量)
第 1 步:∂s∂J(损失对评分的梯度)
J=−logσ(s),σ(s)=1+e−s1
∂s∂J=−σ(s)1⋅σ′(s)=−σ(s)1⋅σ(s)(1−σ(s))=σ(s)−1
直觉:σ(s)∈(0,1),所以 ∂s∂J=σ(s)−1∈(−1,0)——评分越高,梯度越小(越接近 0),因为已经预测得很好了。
第 2 步:∂u∂J(损失对输出权重 u 的梯度)
s=uTh,故 ∂u∂s=h(列向量),链式法则:
∂u∂J=∂s∂J⋅∂u∂s=(σ(s)−1)⋅h∈Rm
第 3 步:∂z(1)∂J(误差信号 δ,关键中间量)
∂h∂s=uT,∂z(1)∂h=diag(1−h2)(tanh 导数)
设上游梯度(从损失到 h)为:
∂h∂J=∂s∂J⋅∂h∂s=(σ(s)−1)⋅uT∈R1×m
传过 tanh(逐元素乘,⊙ 表示 Hadamard 积):
δ≡∂z(1)∂J=(σ(s)−1)⋅u⊙(1−h2)∈Rm
(将行向量转为列向量后与 1−h2 逐元素相乘)
第 4 步:各参数梯度
利用 z(1)=Wx+b 及 §6 的规则:
∂W∂J=δ⋅xT∈Rm×n(外积,形状与 W 相同)
∂b∂J=δ∈Rm(形状与 b 相同)
∂x∂J=WTδ∈Rn(传给词向量,用于联合训练)
计算图(ASCII 示意):
x ──→ [z=Wx+b] ──→ [h=tanh(z)] ──→ [s=uᵀh] ──→ [J=-log σ(s)]
↑W,b ↑ ↑u
前向:→→→→→→→→→→→→→→→→→→→→→→→→→→→→→
反向:←←←←←←←←←←←←←←←←←←←←←←←←←←←
∂J/∂W=δxᵀ ∂J/∂z=δ ∂J/∂s=σ(s)-1
每个节点只需记录自己的局部导数,不需要知道网络其他部分的结构。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例(完整前向 + 反向)
设定:d=2,m=2,W=I2(单位矩阵),b=[0,0]T,u=[1,1]T,x=[0.6,−0.4]T,标签 y=1
前向传播:
| 步骤 | 计算 | 结果 |
|---|
| z(1)=Wx+b | =[0.6,−0.4]T | [0.6, −0.4]T |
| h=tanh(z(1)) | [tanh(0.6), tanh(−0.4)] | [0.537, −0.380]T |
| s=uTh | 1(0.537)+1(−0.380) | 0.157 |
| σ(s) | σ(0.157) | 0.539 |
| J=−logσ(s) | −log(0.539) | 0.618 |
反向传播:
| 步骤 | 计算 | 结果 |
|---|
| ∂s∂J=σ(s)−1 | 0.539−1 | −0.461 |
| ∂u∂J=(σ(s)−1)h | −0.461×[0.537,−0.380]T | [−0.248, 0.175]T |
| 1−h2 | [1−0.5372, 1−0.3802] | [0.712, 0.856]T |
| δ=(σ(s)−1)u⊙(1−h2) | −0.461×[1,1]T⊙[0.712,0.856]T | [−0.328, −0.395]T |
| ∂W∂J=δxT | [−0.328,−0.395]T⋅[0.6,−0.4] | [−0.197−0.2370.1310.158] |
| ∂b∂J=δ | — | [−0.328, −0.395]T |
| ∂x∂J=WTδ | I⋅[−0.328,−0.395]T | [−0.328, −0.395]T |
验证:∂W∂J 形状 2×2= W 的形状 ✓,∂x∂J 形状 2= x 的形状 ✓
💡 反向传播的本质是什么?
反向传播的天才之处在于重用中间计算结果。如果你手动展开损失对每个参数的偏导数(拆掉所有复合函数),会得到大量重复子表达式。反向传播通过计算图把这些子表达式只计算一次,存起来复用。
类比:计算 f(x)=((x+1)2+(x+1)3)×5,先算 u=x+1,再算 u2、u3,比展开后各自对 x 求导快得多。
时间复杂度是 O(n)(n 为参数数量)——每个参数的梯度计算量与前向传播等量级。这是深度学习可扩展到数十亿参数的根本原因。
⚠️ 常见误区
- 误区:反向传播 = 梯度下降 → 正确:反向传播只负责计算梯度(∇θJ),梯度下降(或 Adam 等优化器)才负责用梯度更新参数(θ←θ−η∇J)。两者是完全不同的操作。
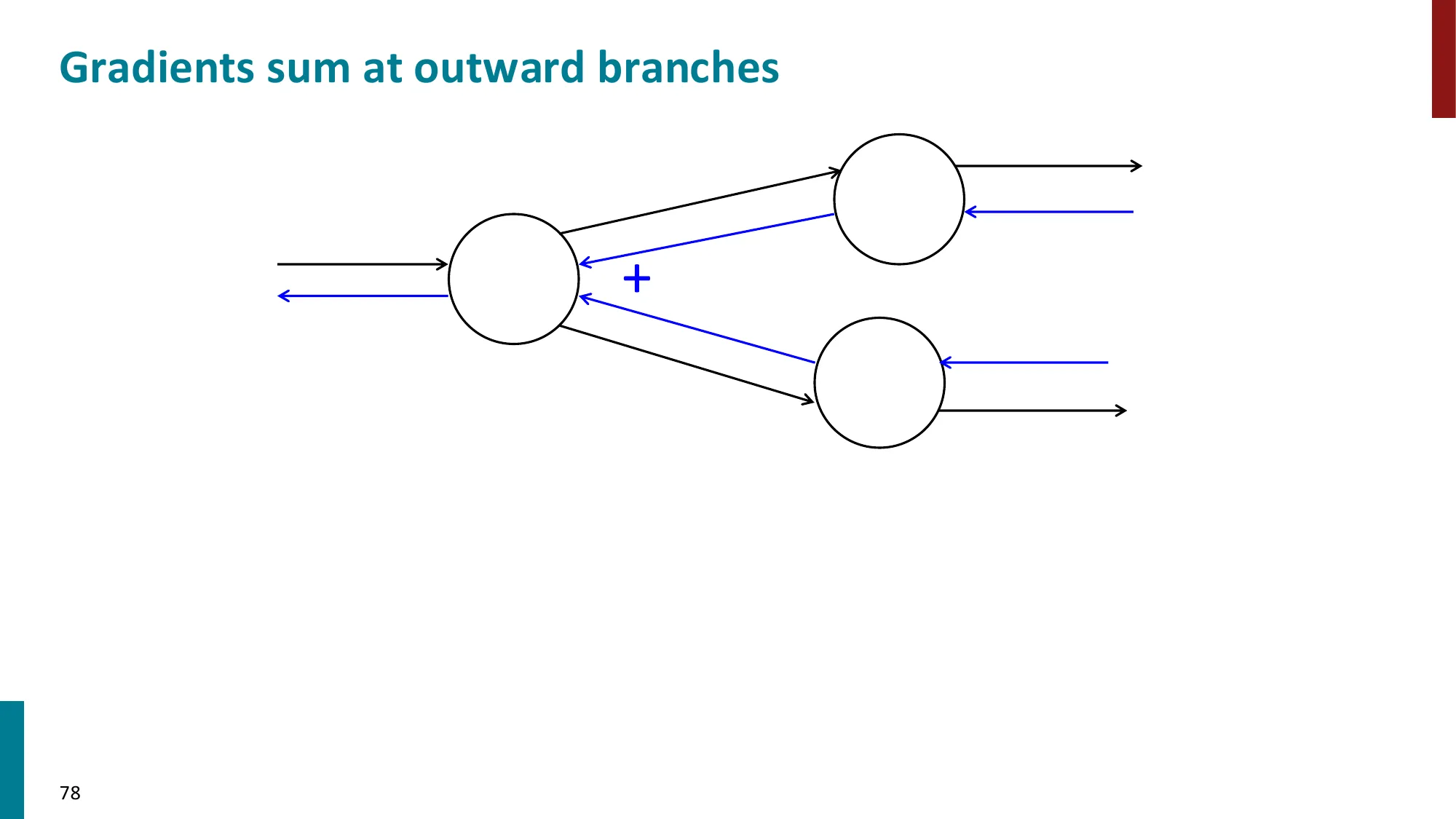
- 梯度累加陷阱:若某节点(如词向量)被多个地方引用(同一个词在窗口中出现多次),其梯度必须累加所有路径传来的梯度,而不是取平均或覆盖。PyTorch 的
.grad 属性在多次 backward 时会自动累加(这也是为什么要 optimizer.zero_grad())。
- tanh 导数记忆:tanh′(z)=1−tanh2(z),不要写成 1/cosh2(z)(虽然等价,但前者可直接用前向已算出的 h=tanh(z),后者还需重新算 cosh)。
- 误区:只有参数需要梯度 → 正确:NLP 中词向量也是参数,∂x∂J 非零,用于联合训练(fine-tuning embedding)。若想固定词向量,需要显式
requires_grad=False。
推荐阅读
关联概念
作业提醒
- A2 发布(神经网络基础 + 张量求导 + 依赖解析)
- A1 截止
个人笔记