Word2Vec Skip-gram 目标函数与梯度推导 分类: 词向量与表示学习 · 难度: 中级 · 关联讲座: L02
Word2Vec Skip-gram 目标函数与梯度推导
本文整理 Word2Vec Skip-gram 模型从分布假说到目标函数、再到完整梯度推导的全过程。内容涵盖分布假说的数学形式化、Softmax 预测函数的构造,以及对中心词向量 v c v_c v c u o u_o u o
1. 分布假说的数学表达
📐 分布假说的数学表达
核心思想 :“一个词的含义由其上下文决定”——这如何转化为可计算的目标?
步骤 1 :定义”上下文”为以目标词为中心、半径 m m m context ( w t ) = { w t − m , … , w t − 1 , w t + 1 , … , w t + m } \text{context}(w_t) = \{w_{t-m}, \ldots, w_{t-1}, w_{t+1}, \ldots, w_{t+m}\} context ( w t ) = { w t − m , … , w t − 1 , w t + 1 , … , w t + m }
步骤 2 :如果词向量能够预测上下文词,说明向量已经编码了”上下文分布”(即词的含义):
好的词向量 ⇔ 给定中心词,能准确预测上下文词 \text{好的词向量} \Leftrightarrow \text{给定中心词,能准确预测上下文词} 好的词向量 ⇔ 给定中心词,能准确预测上下文词
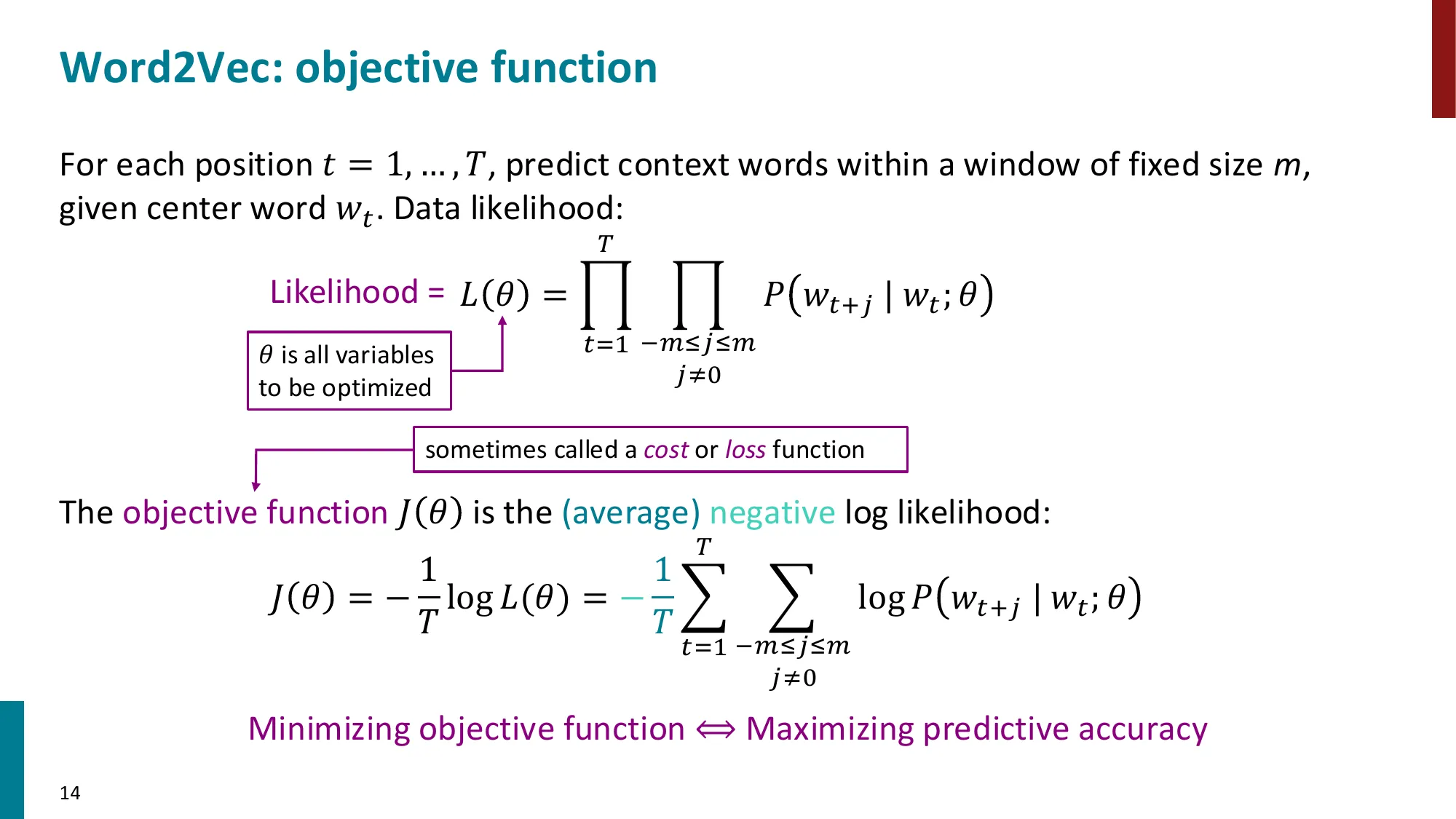
步骤 3 :将”预测能力”定义为目标函数——最大化在所有位置 t t t maximize ∏ t = 1 T ∏ − m ≤ j ≤ m j ≠ 0 P ( w t + j ∣ w t ; θ ) \text{maximize} \quad \prod_{t=1}^{T} \prod_{\substack{-m \le j \le m \\ j \neq 0}} P(w_{t+j} | w_t; \theta) maximize ∏ t = 1 T ∏ − m ≤ j ≤ m j = 0 P ( w t + j ∣ w t ; θ )
取负对数(最小化形式):
minimize J ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m j ≠ 0 log P ( w t + j ∣ w t ; θ ) \text{minimize} \quad J(\theta) = -\frac{1}{T} \sum_{t=1}^{T} \sum_{\substack{-m \le j \le m \\ j \neq 0}} \log P(w_{t+j} | w_t; \theta) minimize J ( θ ) = − T 1 ∑ t = 1 T ∑ − m ≤ j ≤ m j = 0 log P ( w t + j ∣ w t ; θ )
这就是 Word2Vec 的目标函数!分布假说 → 可微分的损失函数,一步完成。
🔢 点积相似度的计算
设定 :两个 3 维词向量:
v cat = [ 0.8 , 0.3 , − 0.1 ] v_{\text{cat}} = [0.8, 0.3, -0.1] v cat = [ 0.8 , 0.3 , − 0.1 ] v dog = [ 0.7 , 0.4 , − 0.2 ] v_{\text{dog}} = [0.7, 0.4, -0.2] v dog = [ 0.7 , 0.4 , − 0.2 ] v car = [ − 0.2 , 0.1 , 0.9 ] v_{\text{car}} = [-0.2, 0.1, 0.9] v car = [ − 0.2 , 0.1 , 0.9 ]
余弦相似度 (归一化点积):
cos ( cat , dog ) = v cat T v dog ∥ v cat ∥ ⋅ ∥ v dog ∥ \cos(\text{cat}, \text{dog}) = \frac{v_{\text{cat}}^T v_{\text{dog}}}{\|v_{\text{cat}}\| \cdot \|v_{\text{dog}}\|} cos ( cat , dog ) = ∥ v cat ∥ ⋅ ∥ v dog ∥ v cat T v dog
计算:
v cat T v dog = 0.8 × 0.7 + 0.3 × 0.4 + ( − 0.1 ) × ( − 0.2 ) = 0.56 + 0.12 + 0.02 = 0.70 v_{\text{cat}}^T v_{\text{dog}} = 0.8 \times 0.7 + 0.3 \times 0.4 + (-0.1) \times (-0.2) = 0.56 + 0.12 + 0.02 = 0.70 v cat T v dog = 0.8 × 0.7 + 0.3 × 0.4 + ( − 0.1 ) × ( − 0.2 ) = 0.56 + 0.12 + 0.02 = 0.70 ∥ v cat ∥ = 0.64 + 0.09 + 0.01 = 0.74 ≈ 0.860 \|v_{\text{cat}}\| = \sqrt{0.64 + 0.09 + 0.01} = \sqrt{0.74} \approx 0.860 ∥ v cat ∥ = 0.64 + 0.09 + 0.01 = 0.74 ≈ 0.860 ∥ v dog ∥ = 0.49 + 0.16 + 0.04 = 0.69 ≈ 0.831 \|v_{\text{dog}}\| = \sqrt{0.49 + 0.16 + 0.04} = \sqrt{0.69} \approx 0.831 ∥ v dog ∥ = 0.49 + 0.16 + 0.04 = 0.69 ≈ 0.831 cos ( cat , dog ) = 0.70 / ( 0.860 × 0.831 ) ≈ 0.977 \cos(\text{cat}, \text{dog}) = 0.70 / (0.860 \times 0.831) \approx \mathbf{0.977} cos ( cat , dog ) = 0.70/ ( 0.860 × 0.831 ) ≈ 0.977
cos ( cat , car ) = ( − 0.16 + 0.03 − 0.09 ) / ( … ) ≈ − 0.26 \cos(\text{cat}, \text{car}) = (-0.16 + 0.03 - 0.09) / (\ldots) \approx \mathbf{-0.26} cos ( cat , car ) = ( − 0.16 + 0.03 − 0.09 ) / ( … ) ≈ − 0.26
结论 :cat 和 dog 向量相近,cat 和 car 向量方向相反。
2. Softmax 预测函数的由来
📐 Softmax 预测函数的由来
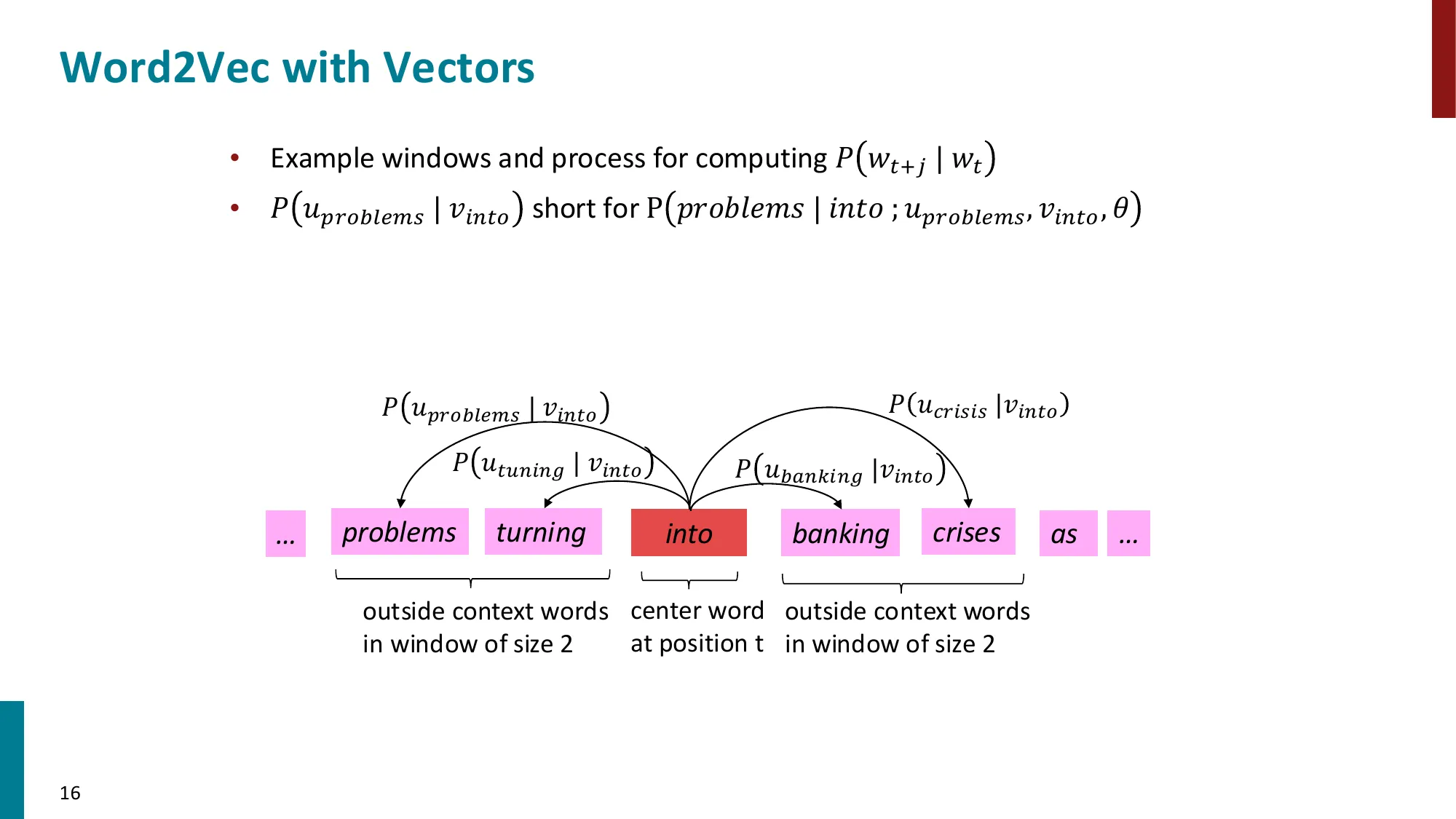
目标 :给定中心词 c c c o o o P ( o ∣ c ) P(o|c) P ( o ∣ c ) 第 1 步:相似度度量
用点积衡量中心词向量 v c v_c v c u o u_o u o score ( o , c ) = u o T v c = ∑ i = 1 d u o , i ⋅ v c , i \text{score}(o, c) = u_o^T v_c = \sum_{i=1}^{d} u_{o,i} \cdot v_{c,i} score ( o , c ) = u o T v c = ∑ i = 1 d u o , i ⋅ v c , i
第 2 步:指数化(使所有分数为正)
原始点积可以是负数,不能直接当概率。用指数函数 exp ( ⋅ ) \exp(\cdot) exp ( ⋅ )
exp ( u o T v c ) > 0 ∀ u o , v c \exp(u_o^T v_c) > 0 \quad \forall\, u_o, v_c exp ( u o T v c ) > 0 ∀ u o , v c
这保证了大的相似度 → 大的正数,小的(负的)相似度 → 接近 0 的正数。
第 3 步:归一化(使概率和为 1)
Slide 14
除以所有词的指数和,得到合法的概率分布:
P ( o ∣ c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w T v c ) P(o|c) = \frac{\exp(u_o^T v_c)}{\sum_{w \in V} \exp(u_w^T v_c)} P ( o ∣ c ) = ∑ w ∈ V e x p ( u w T v c ) e x p ( u o T v c ) 为什么用指数而不是其他函数?
指数函数有特殊性质:exp ( a + b ) = exp ( a ) exp ( b ) \exp(a+b) = \exp(a)\exp(b) exp ( a + b ) = exp ( a ) exp ( b )
🔢 数值计算:3 个词的 Skip-gram
设定 :词表 V = { cat , dog , fish } V = \{\text{cat}, \text{dog}, \text{fish}\} V = { cat , dog , fish } d = 2 d = 2 d = 2
词 中心词向量 v v v 上下文向量 u u u cat [ 0.5 , 0.3 ] [0.5, 0.3] [ 0.5 , 0.3 ] [ 0.2 , 0.8 ] [0.2, 0.8] [ 0.2 , 0.8 ] dog [ 0.4 , 0.6 ] [0.4, 0.6] [ 0.4 , 0.6 ] [ 0.7 , 0.1 ] [0.7, 0.1] [ 0.7 , 0.1 ] fish [ 0.1 , 0.9 ] [0.1, 0.9] [ 0.1 , 0.9 ] [ 0.3 , 0.5 ] [0.3, 0.5] [ 0.3 , 0.5 ]
任务 :计算 P ( dog ∣ cat ) P(\text{dog} \mid \text{cat}) P ( dog ∣ cat )
Step 1 :计算点积 u w T v cat u_w^T v_\text{cat} u w T v cat
u cat T v cat = 0.2 × 0.5 + 0.8 × 0.3 = 0.34 u_\text{cat}^T v_\text{cat} = 0.2 \times 0.5 + 0.8 \times 0.3 = 0.34 u cat T v cat = 0.2 × 0.5 + 0.8 × 0.3 = 0.34
Slide 16
u dog T v cat = 0.7 × 0.5 + 0.1 × 0.3 = 0.38 u_\text{dog}^T v_\text{cat} = 0.7 \times 0.5 + 0.1 \times 0.3 = 0.38 u dog T v cat = 0.7 × 0.5 + 0.1 × 0.3 = 0.38
Slide 17
u fish T v cat = 0.3 × 0.5 + 0.5 × 0.3 = 0.30 u_\text{fish}^T v_\text{cat} = 0.3 \times 0.5 + 0.5 \times 0.3 = 0.30 u fish T v cat = 0.3 × 0.5 + 0.5 × 0.3 = 0.30 Step 2 :指数化:
exp ( 0.34 ) = 1.405 , exp ( 0.38 ) = 1.462 , exp ( 0.30 ) = 1.350 \exp(0.34) = 1.405, \quad \exp(0.38) = 1.462, \quad \exp(0.30) = 1.350 exp ( 0.34 ) = 1.405 , exp ( 0.38 ) = 1.462 , exp ( 0.30 ) = 1.350 Step 3 :归一化:
sum = 1.405 + 1.462 + 1.350 = 4.217 \text{sum} = 1.405 + 1.462 + 1.350 = 4.217 sum = 1.405 + 1.462 + 1.350 = 4.217 P ( dog ∣ cat ) = 1.462 4.217 = 0.347 P(\text{dog}|\text{cat}) = \frac{1.462}{4.217} = 0.347 P ( dog ∣ cat ) = 4.217 1.462 = 0.347 验证 :P ( cat ∣ cat ) + P ( dog ∣ cat ) + P ( fish ∣ cat ) = 0.333 + 0.347 + 0.320 = 1.000 P(\text{cat}|\text{cat}) + P(\text{dog}|\text{cat}) + P(\text{fish}|\text{cat}) = 0.333 + 0.347 + 0.320 = 1.000 P ( cat ∣ cat ) + P ( dog ∣ cat ) + P ( fish ∣ cat ) = 0.333 + 0.347 + 0.320 = 1.000 观察 :dog 的概率最高(0.347),因为 u dog u_\text{dog} u dog v cat v_\text{cat} v cat
💡 Skip-gram 为什么能学到词义?
Slide 18
把 Skip-gram 的训练想象成一个预测游戏 :
给你一个中心词 “bank”
你要猜它周围会出现什么词
如果 “bank” 经常和 “money”, “deposit”, “account” 一起出现
模型就会让 v bank v_\text{bank} v bank u money u_\text{money} u money u deposit u_\text{deposit} u deposit 关键洞察 :如果 “bank” 和 “financial” 周围出现的词很相似(都跟钱有关),那么它们的 v v v 因为它们需要对相同的上下文词产生高概率 。
这就是 “You shall know a word by the company it keeps” 的数学实现。
3. 对 v c v_c v c
📐 对 v c v_c v c
目标 :计算 ∂ ∂ v c log P ( o ∣ c ) \frac{\partial}{\partial v_c} \log P(o|c) ∂ v c ∂ log P ( o ∣ c )
第 1 步:展开对数
log P ( o ∣ c ) = u o T v c − log ∑ w ∈ V exp ( u w T v c ) \log P(o|c) = u_o^T v_c - \log \sum_{w \in V} \exp(u_w^T v_c) log P ( o ∣ c ) = u o T v c − log ∑ w ∈ V exp ( u w T v c )
第 2 步:分别求导
第一项的导数(直接):
∂ ∂ v c ( u o T v c ) = u o \frac{\partial}{\partial v_c}(u_o^T v_c) = u_o ∂ v c ∂ ( u o T v c ) = u o
第二项使用链式法则 ——令 S = ∑ w ∈ V exp ( u w T v c ) S = \sum_{w \in V} \exp(u_w^T v_c) S = ∑ w ∈ V exp ( u w T v c )
∂ ∂ v c log S = 1 S ⋅ ∂ S ∂ v c = 1 S ∑ x ∈ V exp ( u x T v c ) ⋅ u x \frac{\partial}{\partial v_c} \log S = \frac{1}{S} \cdot \frac{\partial S}{\partial v_c} = \frac{1}{S} \sum_{x \in V} \exp(u_x^T v_c) \cdot u_x ∂ v c ∂ log S = S 1 ⋅ ∂ v c ∂ S = S 1 ∑ x ∈ V exp ( u x T v c ) ⋅ u x
第 3 步:化简
Slide 15
= ∑ x ∈ V exp ( u x T v c ) S ⋅ u x = ∑ x ∈ V P ( x ∣ c ) ⋅ u x = \sum_{x \in V} \frac{\exp(u_x^T v_c)}{S} \cdot u_x = \sum_{x \in V} P(x|c) \cdot u_x = ∑ x ∈ V S e x p ( u x T v c ) ⋅ u x = ∑ x ∈ V P ( x ∣ c ) ⋅ u x 第 4 步:合并结果
∂ ∂ v c log P ( o ∣ c ) = u o − ∑ x ∈ V P ( x ∣ c ) u x \frac{\partial}{\partial v_c} \log P(o|c) = u_o - \sum_{x \in V} P(x|c) u_x ∂ v c ∂ log P ( o ∣ c ) = u o − ∑ x ∈ V P ( x ∣ c ) u x 直觉 :梯度 = 观察到的 上下文向量 u o u_o u o 期望的 上下文向量 E [ u x ] \mathbb{E}[u_x] E [ u x ] v c v_c v c
4. 对 u o u_o u o
📐 对 u o u_o u o
目标 :计算 ∂ ∂ u o log P ( o ∣ c ) \frac{\partial}{\partial u_o} \log P(o|c) ∂ u o ∂ log P ( o ∣ c ) 第 1 步:展开对数
log P ( o ∣ c ) = u o T v c − log ∑ w ∈ V exp ( u w T v c ) \log P(o|c) = u_o^T v_c - \log \sum_{w \in V} \exp(u_w^T v_c) log P ( o ∣ c ) = u o T v c − log ∑ w ∈ V exp ( u w T v c ) 第 2 步:对 u o u_o u o
第一项:∂ ∂ u o ( u o T v c ) = v c \frac{\partial}{\partial u_o}(u_o^T v_c) = v_c ∂ u o ∂ ( u o T v c ) = v c
第二项:在求和 ∑ w ∈ V exp ( u w T v c ) \sum_{w \in V} \exp(u_w^T v_c) ∑ w ∈ V exp ( u w T v c ) w = o w = o w = o u o u_o u o
Slide 20
∂ ∂ u o log ∑ w ∈ V exp ( u w T v c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w T v c ) ⋅ v c = P ( o ∣ c ) ⋅ v c \frac{\partial}{\partial u_o} \log \sum_{w \in V} \exp(u_w^T v_c) = \frac{\exp(u_o^T v_c)}{\sum_{w \in V} \exp(u_w^T v_c)} \cdot v_c = P(o|c) \cdot v_c ∂ u o ∂ log ∑ w ∈ V exp ( u w T v c ) = ∑ w ∈ V e x p ( u w T v c ) e x p ( u o T v c ) ⋅ v c = P ( o ∣ c ) ⋅ v c 第 3 步:合并
∂ ∂ u o log P ( o ∣ c ) = v c − P ( o ∣ c ) ⋅ v c = ( 1 − P ( o ∣ c ) ) ⋅ v c \frac{\partial}{\partial u_o} \log P(o|c) = v_c - P(o|c) \cdot v_c = (1 - P(o|c)) \cdot v_c ∂ u o ∂ log P ( o ∣ c ) = v c − P ( o ∣ c ) ⋅ v c = ( 1 − P ( o ∣ c )) ⋅ v c 直觉 :如果模型已经给 o o o P ( o ∣ c ) ≈ 1 P(o|c) \approx 1 P ( o ∣ c ) ≈ 1 v c v_c v c u o u_o u o v c v_c v c
5. 常见误区
⚠️ 常见误区
Slide 19
误区:每个词只有一个向量 → 正确 :每个词有两个 向量——v w v_w v w u w u_w u w θ ∈ R 2 d V \theta \in \mathbb{R}^{2dV} θ ∈ R 2 d V R d V \mathbb{R}^{dV} R d V 误区:Softmax 的分母只是 normalization trick → 正确 :分母 ∑ w exp ( u w T v c ) \sum_w \exp(u_w^T v_c) ∑ w exp ( u w T v c ) Z Z Z V V V ∣ V ∣ |V| ∣ V ∣ 误区:梯度 u o − ∑ P ( x ∣ c ) u x u_o - \sum P(x|c)u_x u o − ∑ P ( x ∣ c ) u x v c v_c v c → 正确 :还需要计算对 u o u_o u o
⚠️ 常见误区
误区 :窗口越大越好 → 正确 :大窗口捕捉主题相似性(bank + money),小窗口捕捉句法相似性(run + running)。不同任务最优窗口大小不同。误区 :点积 = 余弦相似度 → 正确 :余弦相似度是归一化的 点积。如果词向量的模长不一样,直接比较点积是不公平的。Word2Vec 通常用点积(不归一化),评估时才用余弦相似度。