L05: Attention and Transformers
Week 3 · Tue Jan 20 2026 08:00:00 GMT+0800 (中国标准时间)
Slides
中英交替版(推荐)
L05 双语 (PDF)
英文原版
L05 EN (PDF)
中文翻译版
L05 ZH (PDF)
核心知识点
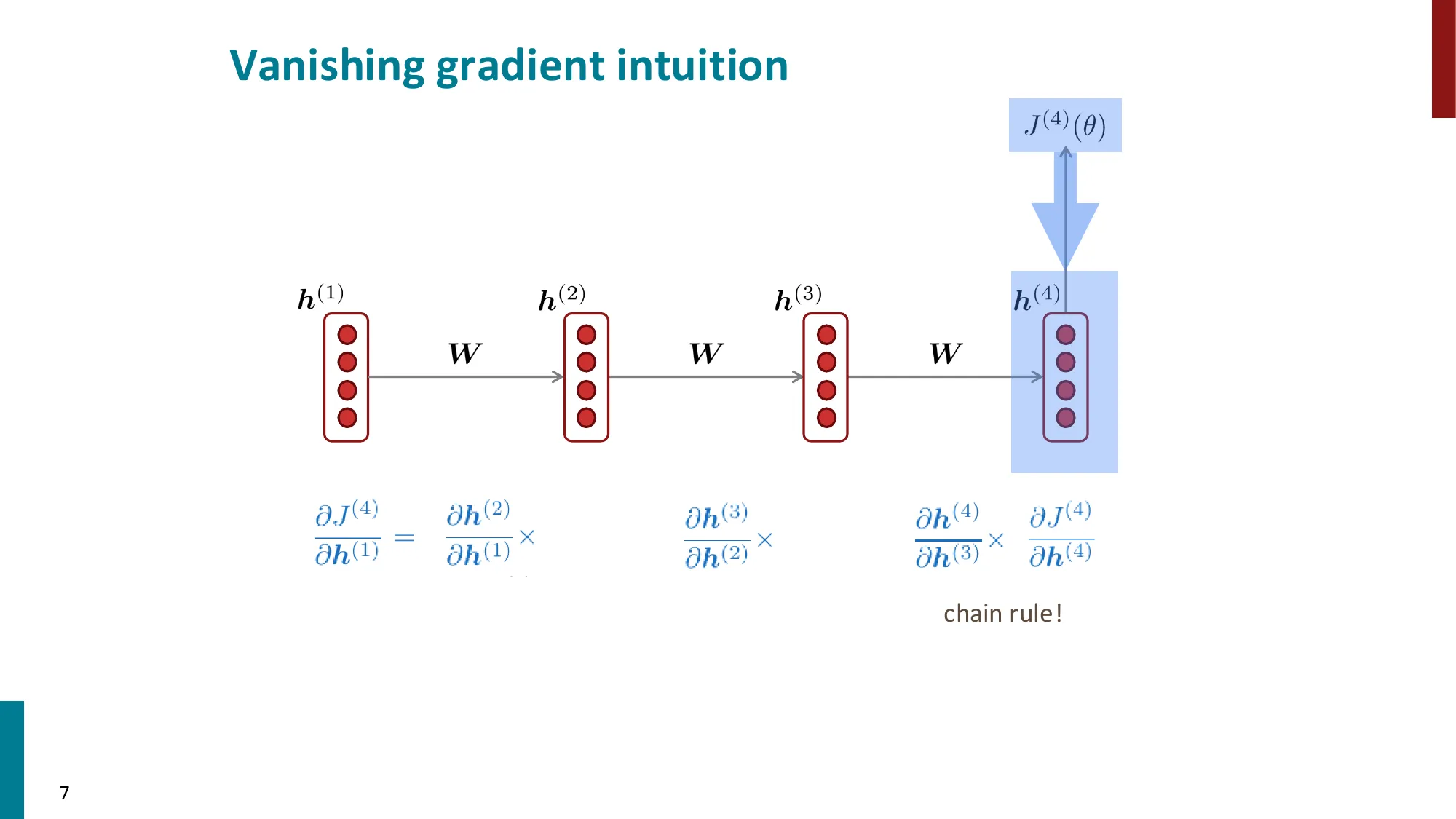
1. RNN 的梯度消失/爆炸问题回顾
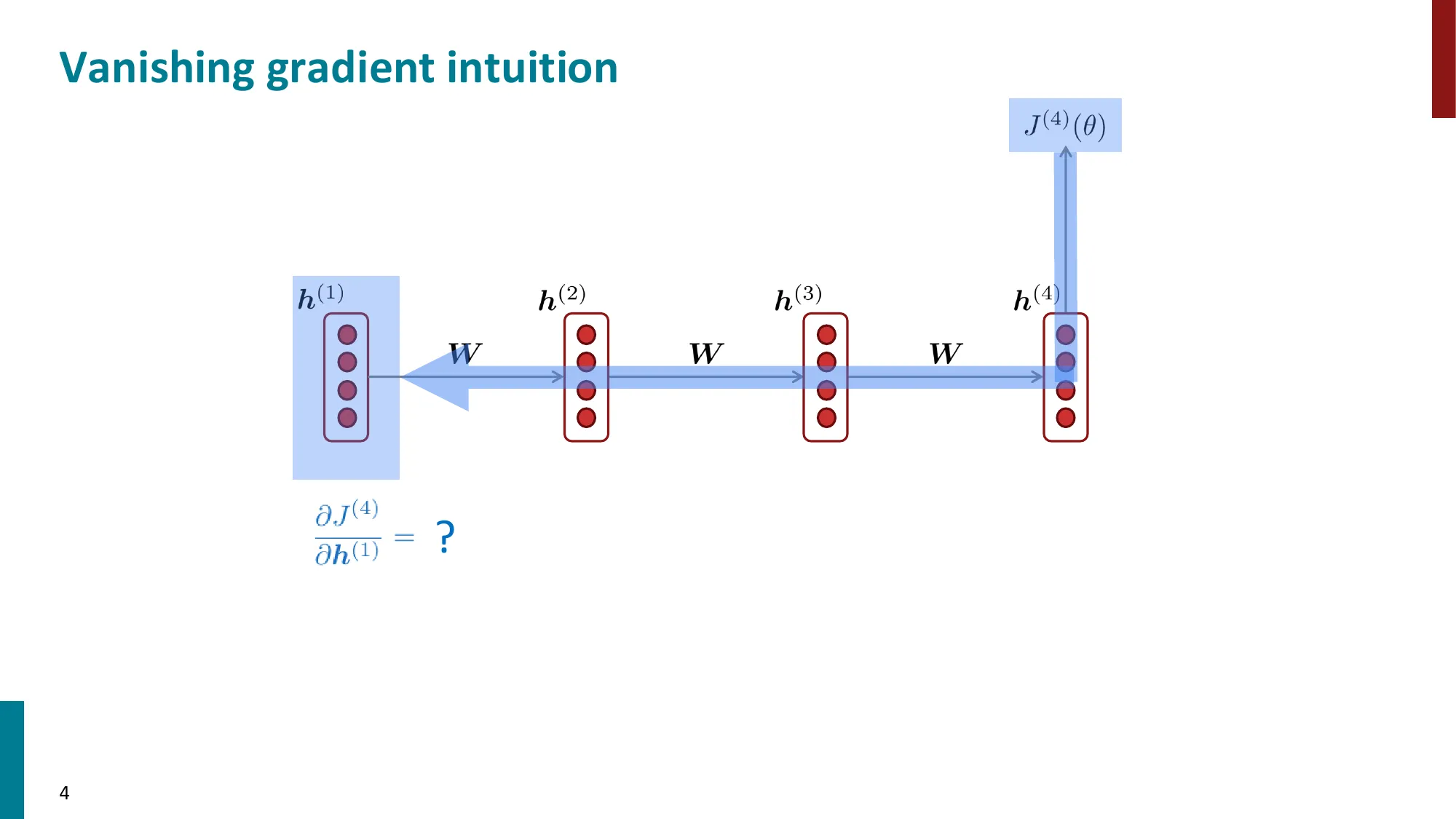
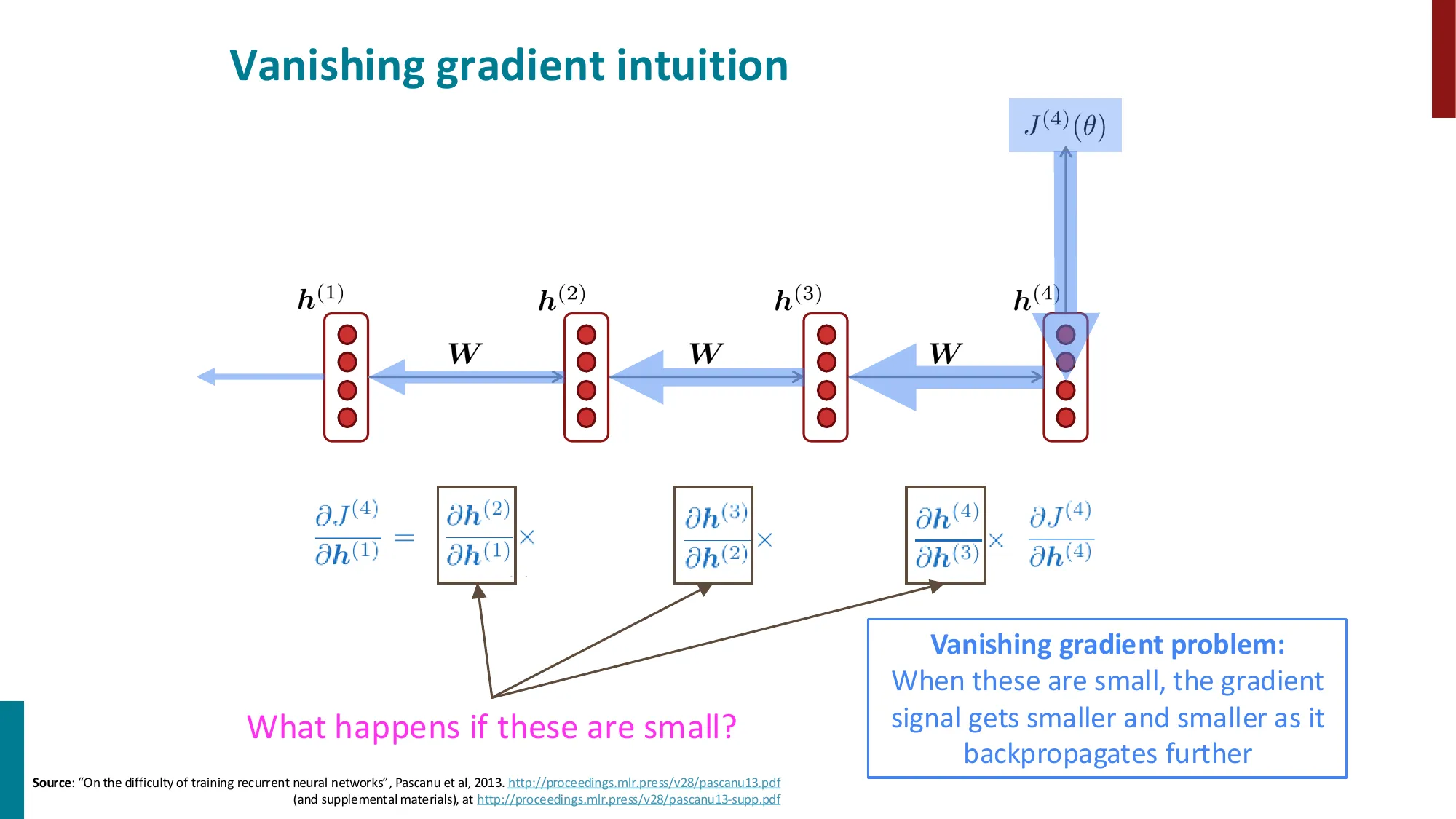
- 梯度消失:∂h(1)∂J(t) 涉及多次矩阵连乘,小特征值导致梯度趋零
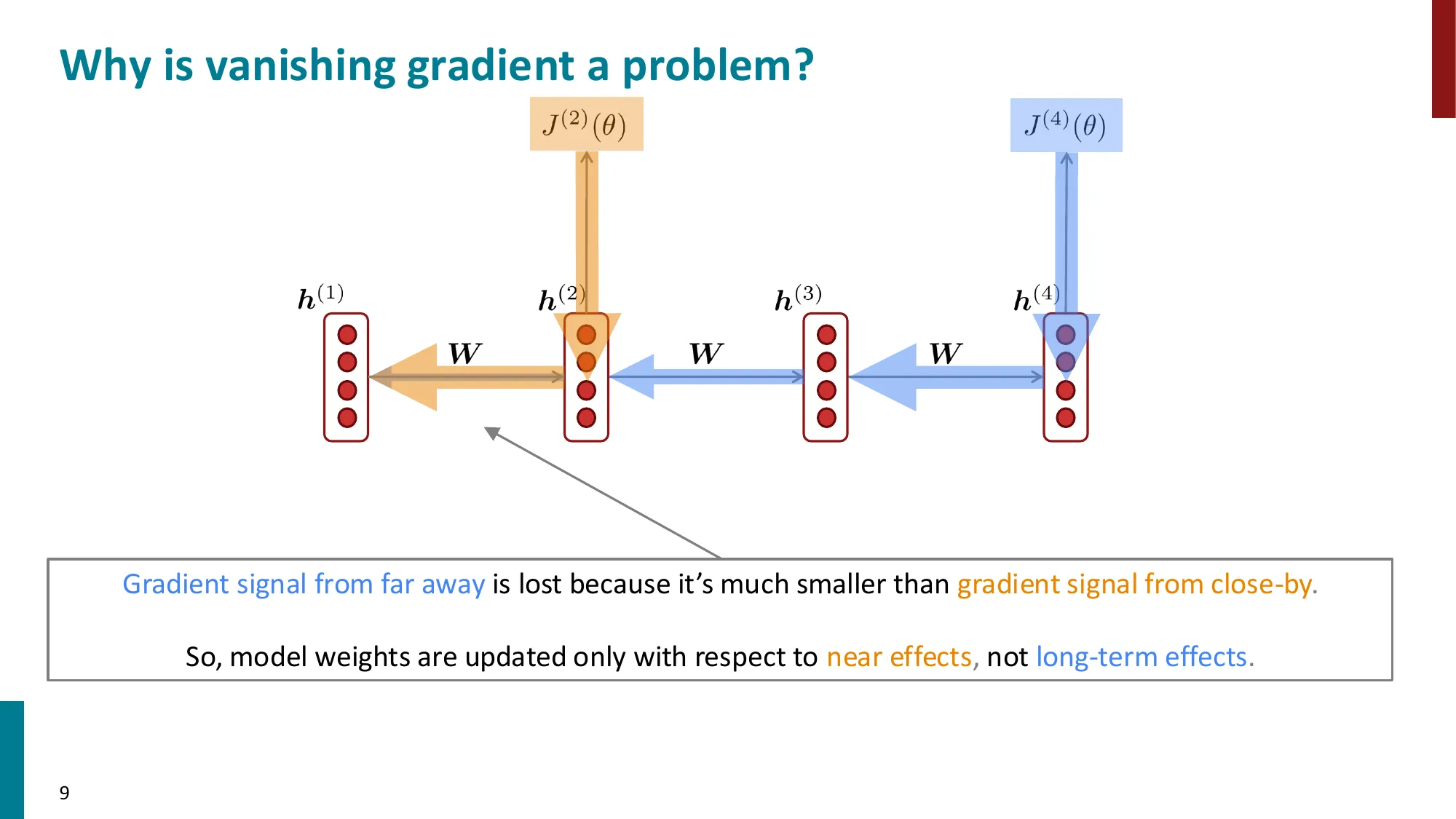
- 后果:远距离依赖的梯度信号丢失,模型只能学到近距离关系
- 梯度爆炸:特征值 > 1 时梯度指数增长
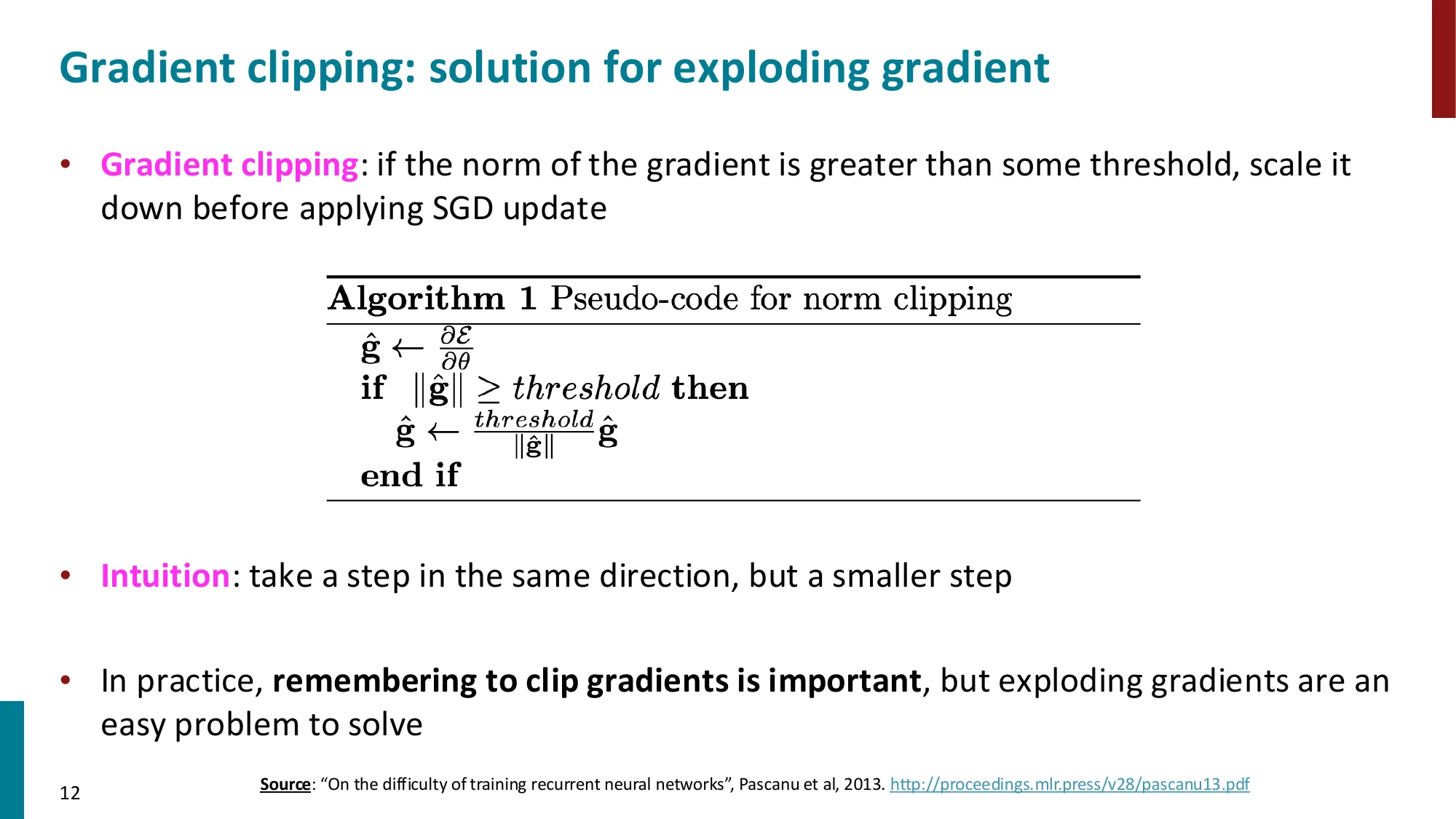
- 解决方案:Gradient Clipping(g^←∥g^∥thresholdg^)
- 根本问题:RNN 很难跨多个时间步保留信息
- 解决思路:LSTM(记忆单元 + 门控),更根本的是注意力机制和残差连接
📐 梯度连乘:完整推导
变量定义:
- h(t) = 时间步 t 的隐状态
- Wh = 隐状态到隐状态的权重矩阵
- σ = 激活函数(如 tanh)
- z(j)=Whh(j−1)+Wxx(j) = 前激活值
推导过程:
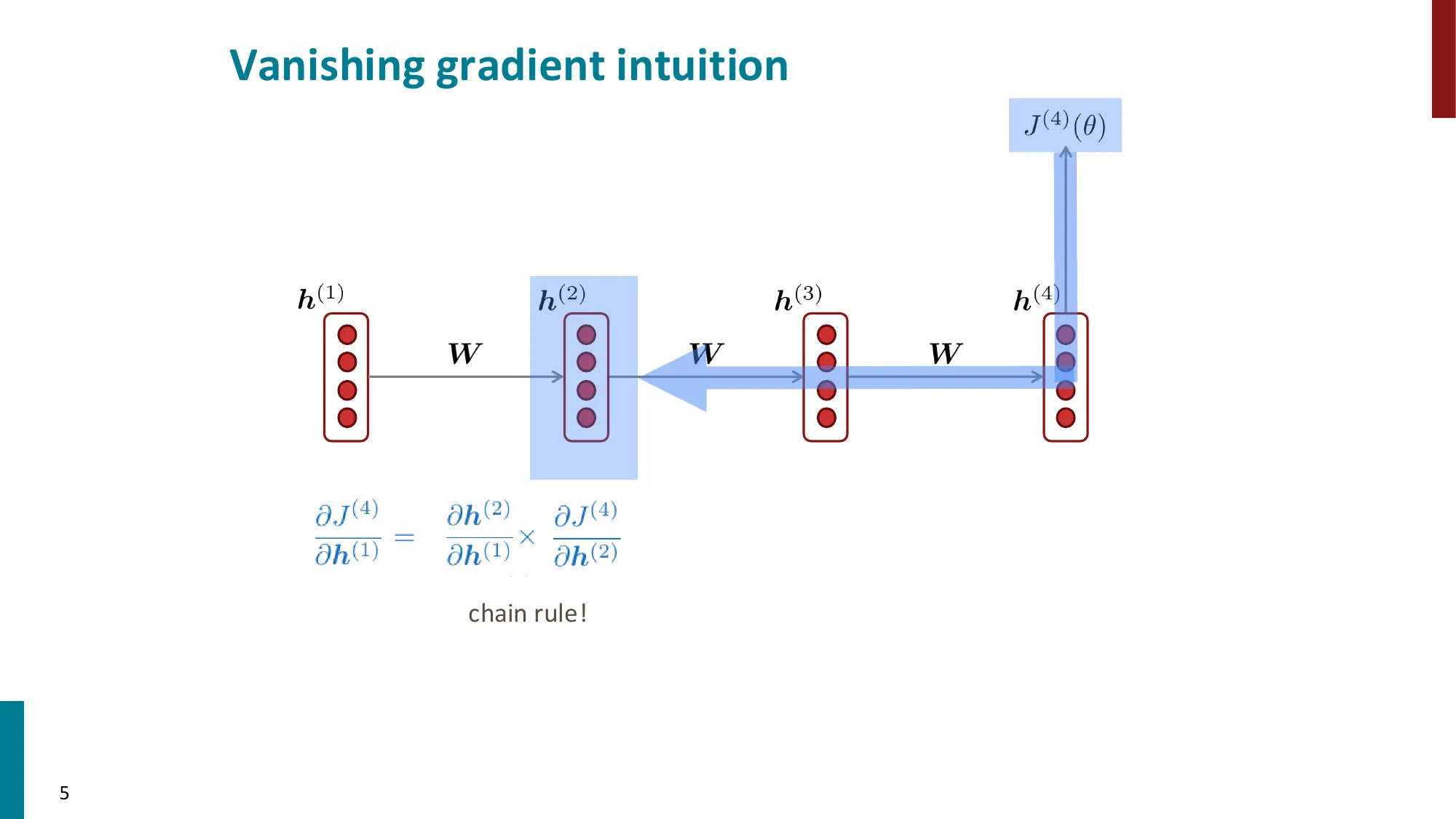
第 1 步:从损失 J(t) 到 h(k) 的梯度,需要经过链式法则逐步回传:
∂h(k)∂J(t)=∂h(t)∂J(t)⋅∂h(k)∂h(t)
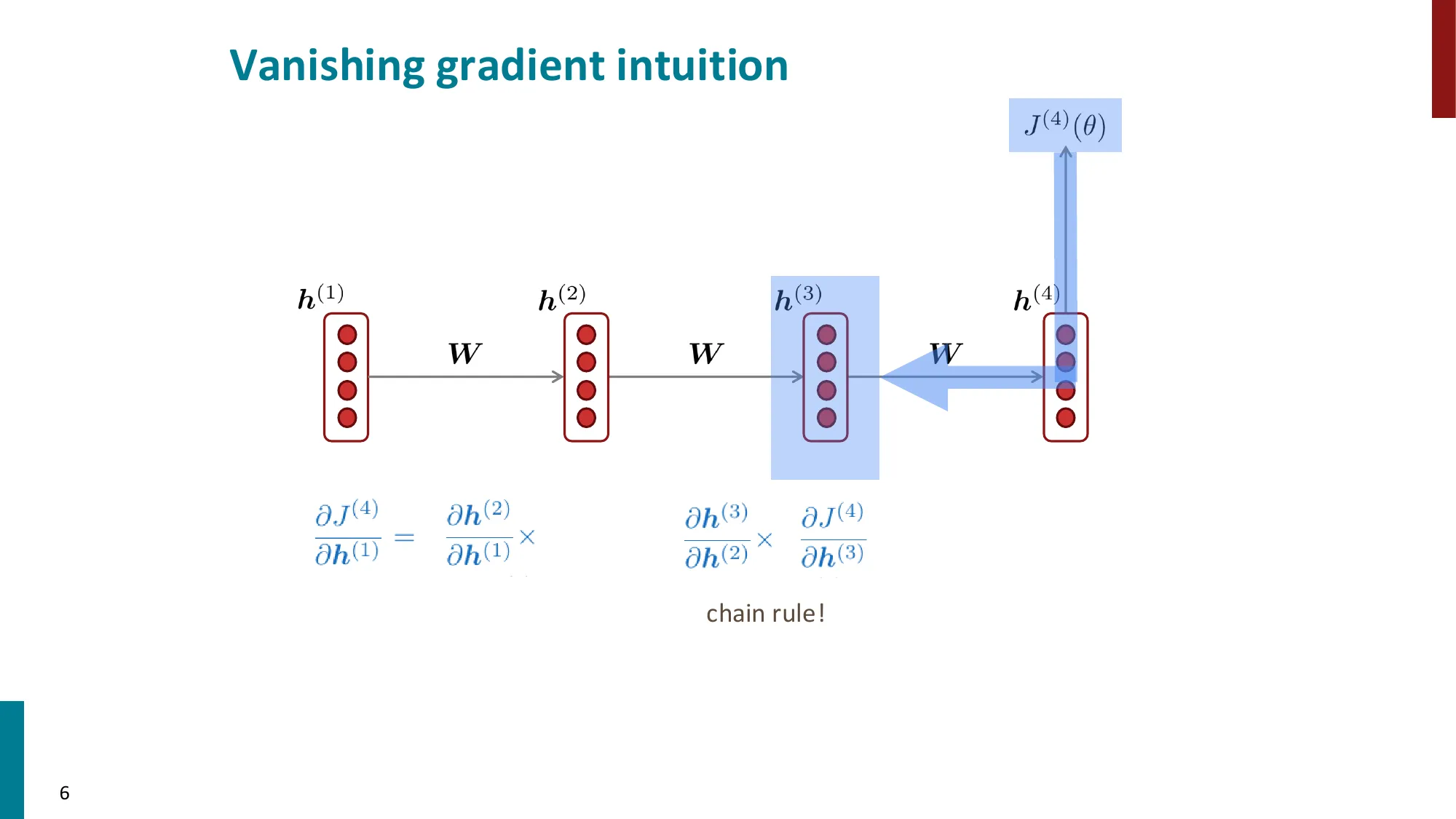
第 2 步:将 ∂h(k)∂h(t) 展开为连乘积(每一步用链式法则):
∂h(k)∂h(t)=∏j=k+1t∂h(j−1)∂h(j)
第 3 步:计算单步 Jacobian,由 h(j)=σ(Whh(j−1)+Wxx(j)) 得:
∂h(j−1)∂h(j)=WhT⋅diag(σ′(z(j)))
第 4 步:代入连乘积,得完整梯度公式:
∂h(k)∂h(t)=∏j=k+1tWhT⋅diag(σ′(z(j)))
第 5 步:奇异值分析,设 Wh 的最大奇异值为 λ1,σ′ 在 [0,1] 有界:
Gradient Clipping 算法:
g^←⎩⎨⎧∥g^∥thresholdg^g^若 ∥g^∥>threshold否则
直觉:将梯度向量缩放到固定长度以内,保持方向不变,只压缩幅度。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:标量情形,Wh 为标量,σ′=1(线性激活),t=10,k=0
| 场景 | Wh | 梯度幅度 =Wh10 |
|---|
| 梯度消失 | 0.5 | 0.510≈0.001 |
| 正常传播 | 1.0 | 1.010=1.000 |
| 梯度爆炸 | 2.0 | 210=1024 |
计算(消失示例):
- 每步 × 0.5:1→0.5→0.25→⋯
- 10 步后:0.510=2−10≈0.00098
- 若学习率为 0.01,实际更新量 ≈9.8×10−6,几乎为零
Clipping 示例:若 g^=[3,4](∥g^∥=5),threshold = 1:
g^clipped=51[3,4]=[0.6,0.8]
💡 为什么这样做?
想象一根绳子传递力——每次传递都衰减一半,10 步之后力气几乎为零(梯度消失)。反过来,每次加倍,10 步后力气大到绳子断掉(梯度爆炸)。
Gradient Clipping 就像给绳子加一个限力器:无论力有多大,传出去的力不超过设定值。它只解决爆炸,不解决消失。
RNN 梯度问题的根本解法:
- LSTM/GRU:加法路径(cell state)让梯度可以”直通”多步
- Residual connections:加法路径同理
- Attention:彻底绕过顺序传递,直接建立任意两步的连接
⚠️ 常见误区
- 误区:Gradient Clipping 能防止梯度消失 → 正确:Clipping 只防止爆炸(缩小幅度),对消失问题无效;消失需要 LSTM 或注意力机制
- 误区:LSTM 完全解决了梯度消失 → 正确:LSTM 缓解但不消除,超长距离(>1000 步)依然困难
- 误区:梯度消失只影响最远的时间步 → 正确:每一步都会受到影响,只是距离越远越严重
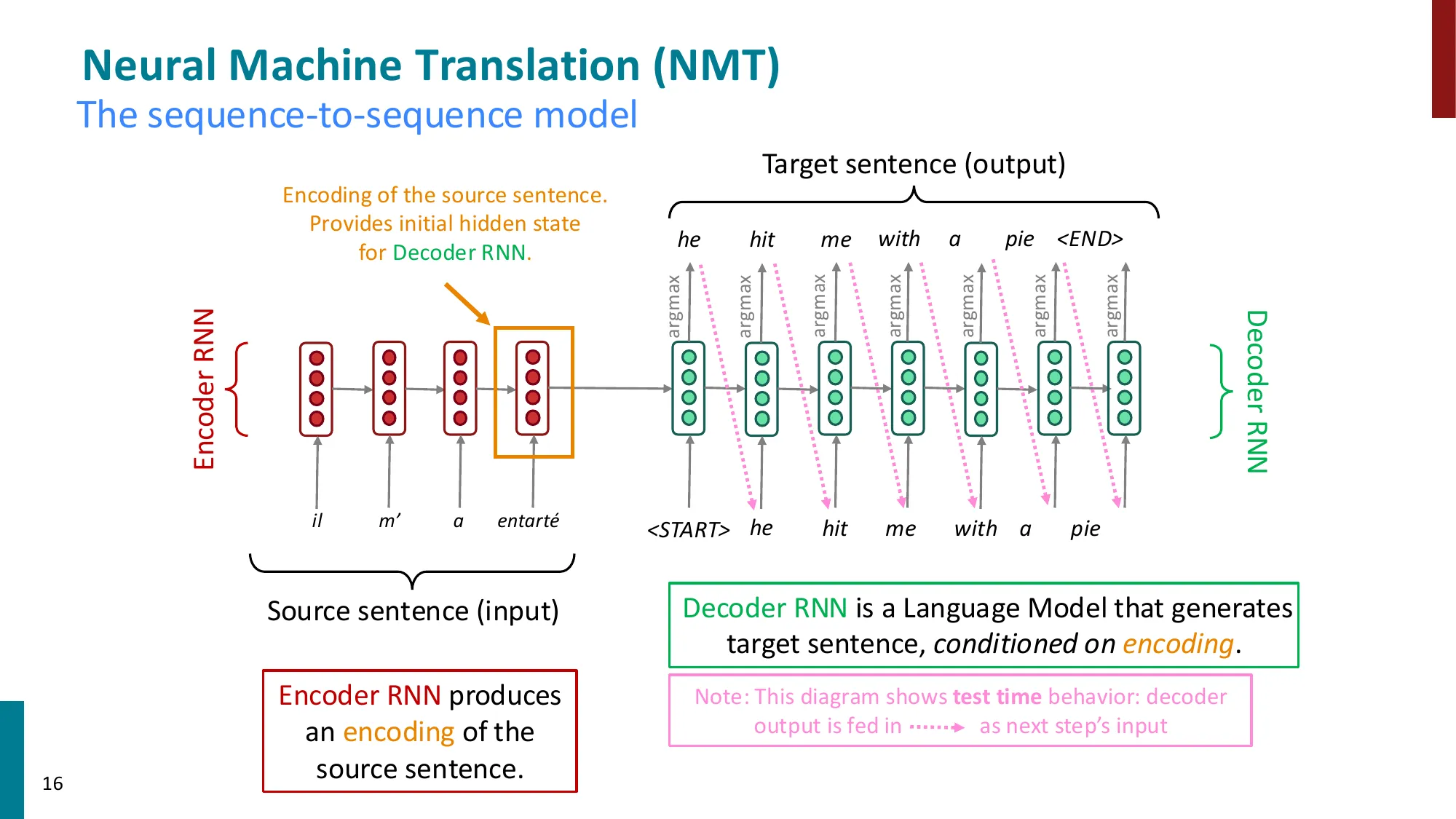
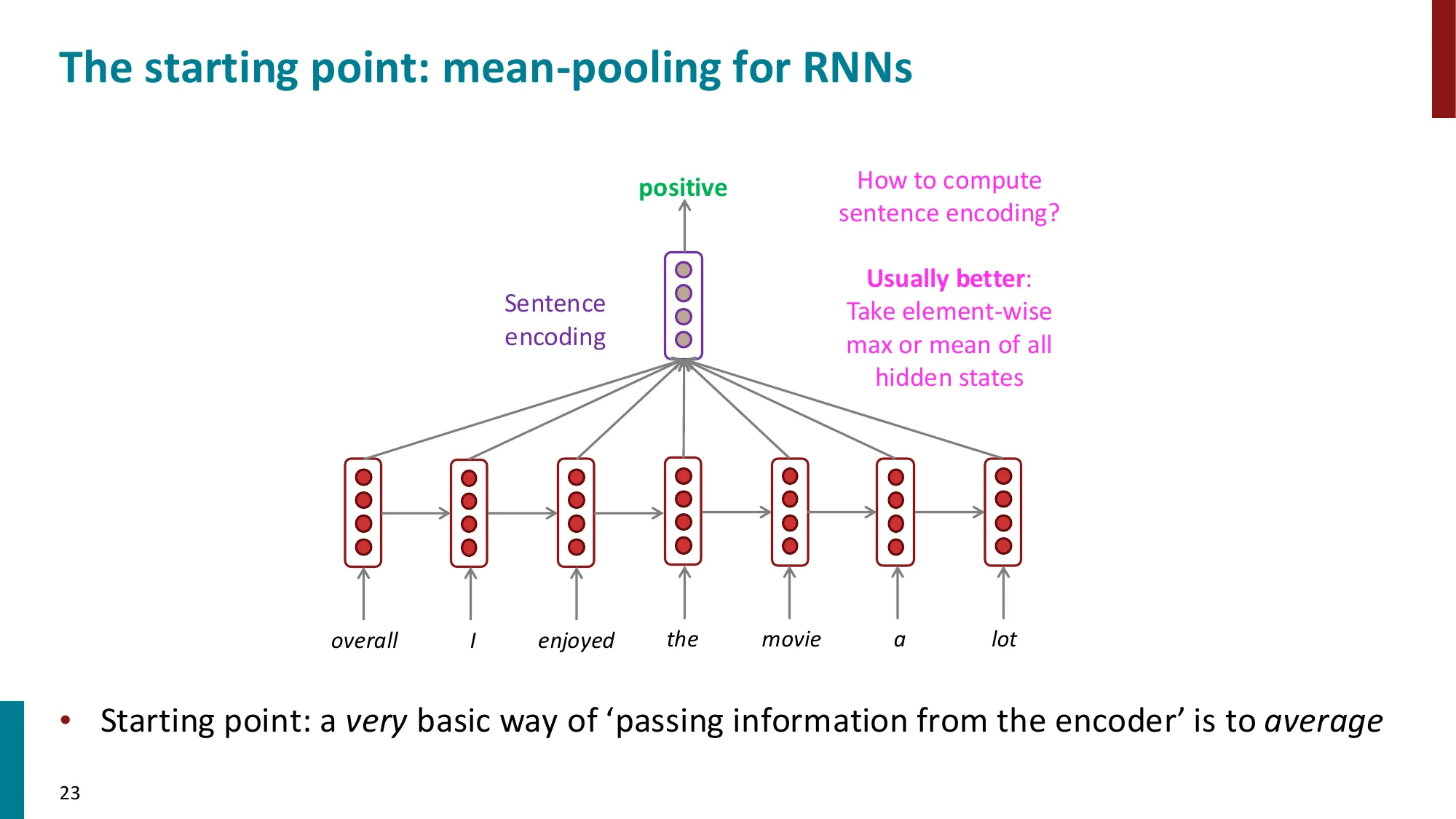
2. 机器翻译与 Seq2Seq
- NMT 的突破:2014 年首篇 seq2seq 论文 → 2016 年 Google Translate 全面转向 NMT
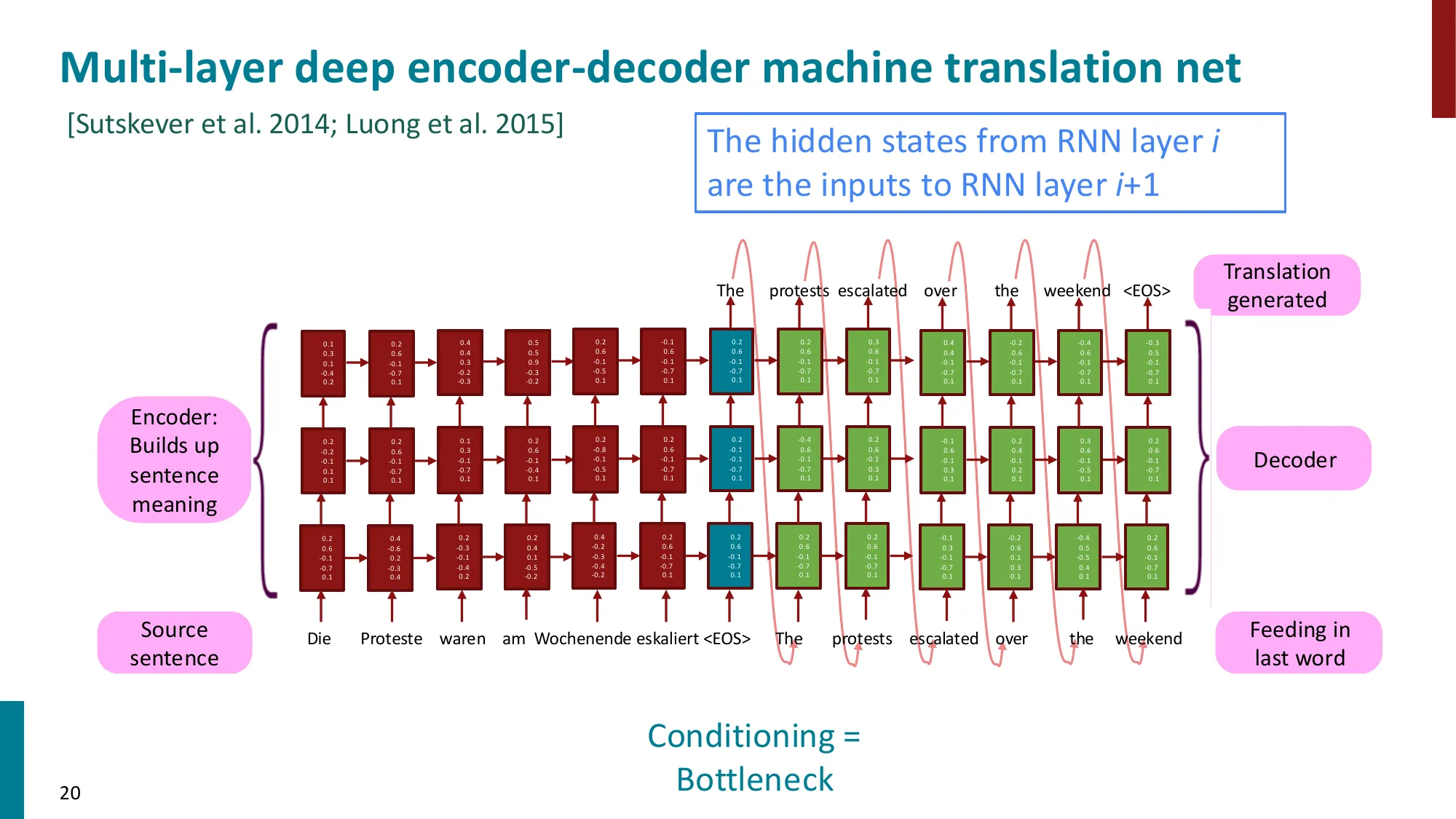
- Encoder-Decoder 模型:
- Encoder RNN:编码源句子为一个上下文向量
- Decoder RNN:条件语言模型,生成目标句子
- 条件语言模型:P(y∣x)=∏tP(yt∣y1,…,yt−1,x)
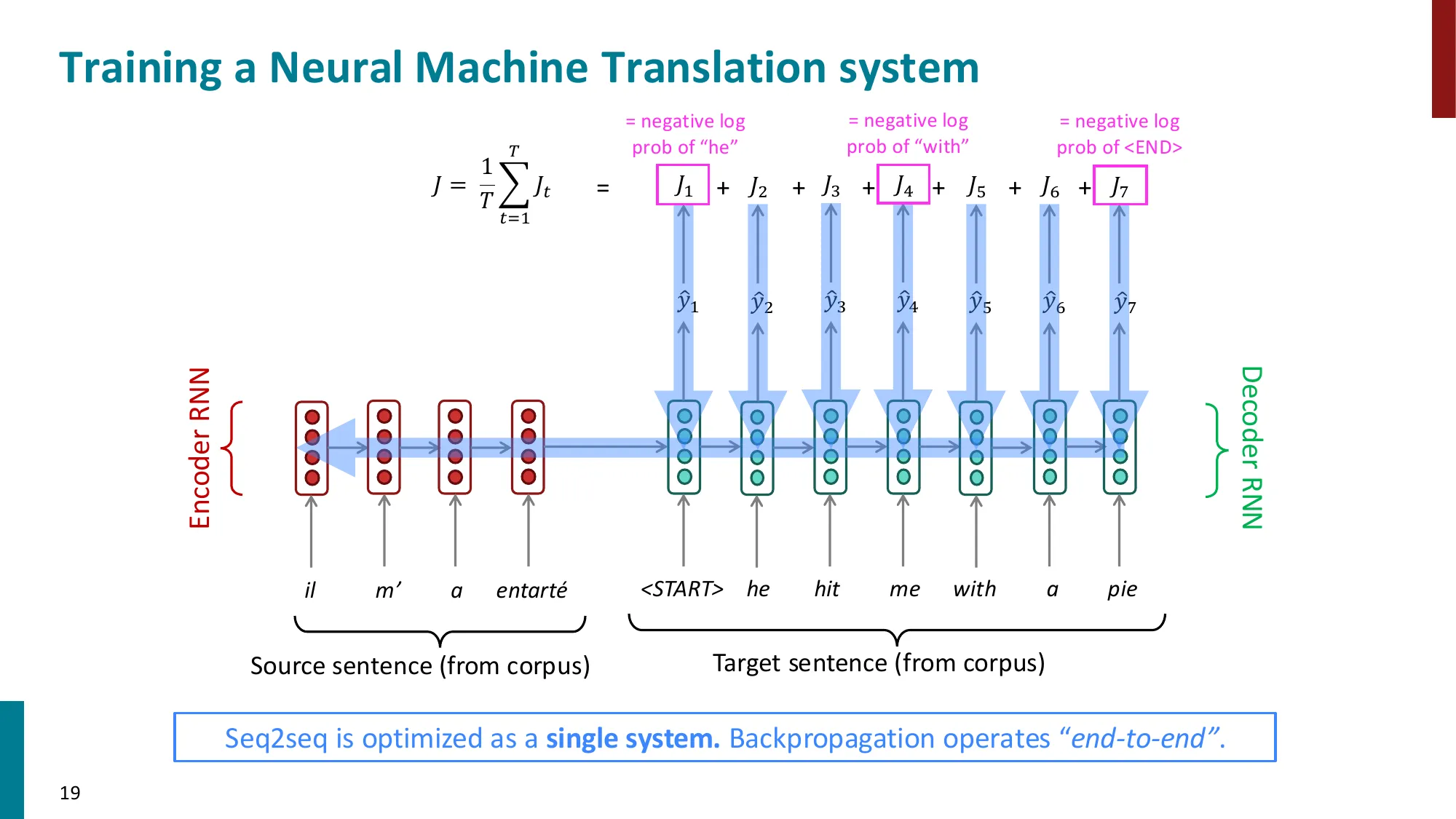
- 端到端训练:Encoder + Decoder 作为整体系统,反向传播一步到位
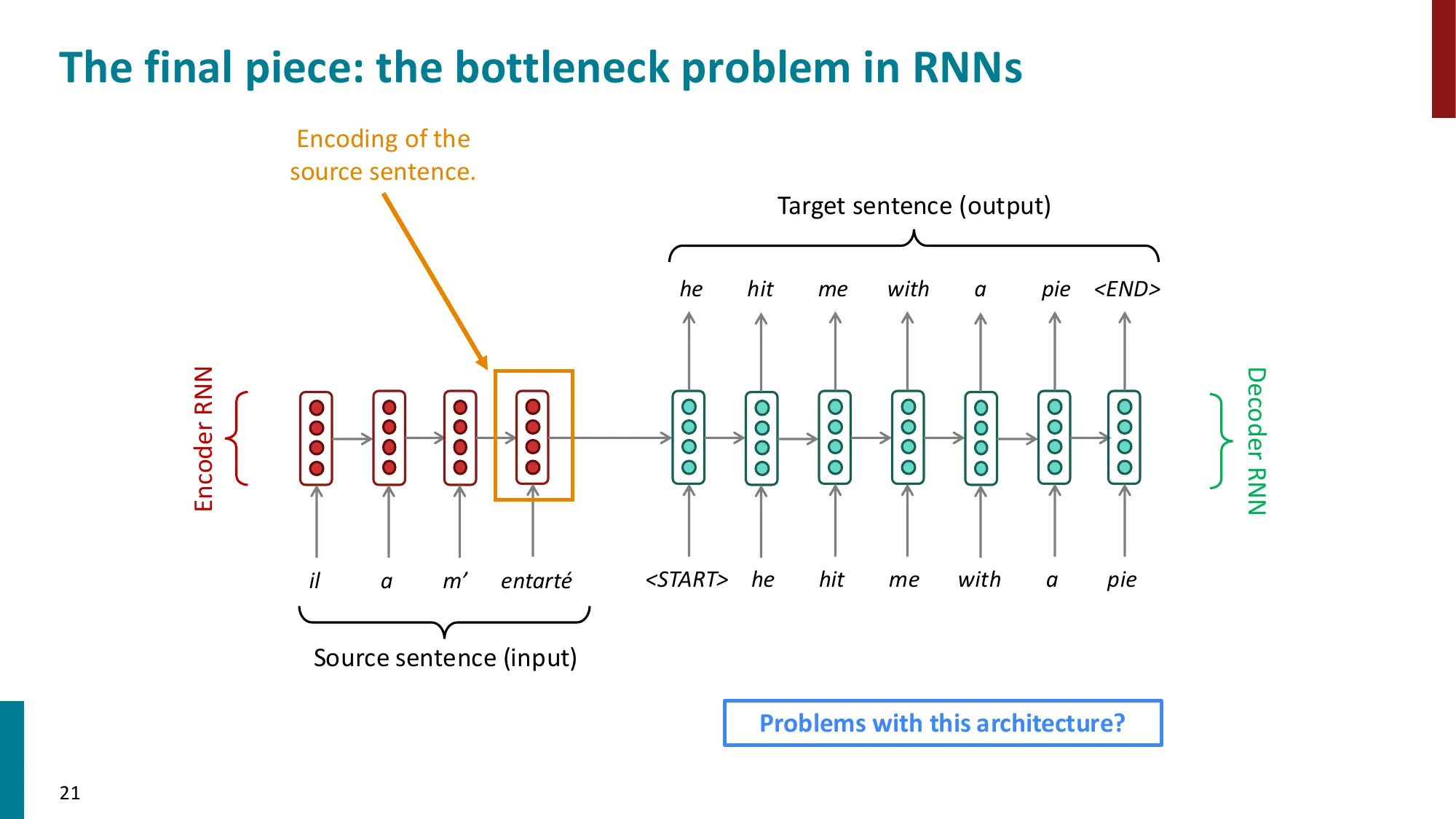
- 瓶颈问题:整个源句信息被压缩到单一上下文向量
📐 条件语言模型:完整推导
变量定义:
- x=(x1,…,xm) = 源句子(长度 m)
- y=(y1,…,yT) = 目标句子(长度 T)
- c = 上下文向量(encoder 最终隐状态)
- s(t) = decoder 在时间步 t 的隐状态
推导过程:
第 1 步:目标是对 P(y∣x) 建模,用概率链式法则分解联合概率:
P(y∣x)=P(y1,y2,…,yT∣x)=∏t=1TP(yt∣y1,…,yt−1,x)
第 2 步:Encoder 将 x 压缩为固定向量 c(Encoder RNN 最后一步隐状态):
c=henc(m)=fenc(x1,…,xm)
第 3 步:Decoder 在每一步利用 c 和之前生成的词:
s(t)=fdec(s(t−1),yt−1,c)
P(yt∣y<t,x)=softmax(Wos(t))[yt-index]
第 4 步:训练目标——最大化对数似然(对训练集上每个 (x,y) 对求和):
L=∑(x,y)∈DlogP(y∣x)=∑(x,y)∈D∑t=1TlogP(yt∣y<t,x)
第 5 步:推断时用贪心解码或 Beam Search 寻找最高概率序列:
y^=argmaxyP(y∣x)
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:源句 “Ich liebe NLP”(3 词),目标句 “I love NLP”(3 词),词表大小 V=5
联合概率分解:
P("I love NLP"∣"Ich liebe NLP")=P(I∣<start>,x)⋅P(love∣I,x)⋅P(NLP∣I love,x)
假设各步概率:
| 时间步 | 生成词 | 条件概率 |
|---|
| t=1 | ”I" | P(y1=I∥<start>,x)=0.7 |
| t=2 | "love" | P(y2=love∥I,x)=0.6 |
| t=3 | "NLP” | P(y3=NLP∥I love,x)=0.8 |
联合概率:
P(y∣x)=0.7×0.6×0.8=0.336
对数似然:
logP(y∣x)=log0.7+log0.6+log0.8≈−0.357+(−0.511)+(−0.223)=−1.091
💡 为什么这样做?
Seq2Seq 本质上是”条件版语言模型”——普通语言模型问的是”这句话自然不自然”,Seq2Seq 问的是”给定源句子,什么是最好的翻译”。
Encoder 相当于一个”理解员”,把源句子的所有信息提炼成一份摘要(上下文向量 c)。Decoder 相当于”写作员”,拿着这份摘要一个词一个词地翻译出来。
瓶颈在哪:摘要只有固定大小(比如 512 维向量),但源句子可以有 100 个词甚至 1000 个词。就像让你用一句话概括整本书——越长的书,信息损失越多。这就是注意力机制要解决的问题。
⚠️ 常见误区
- 误区:Seq2Seq 的 encoder 和 decoder 必须是同一种 RNN → 正确:可以是不同架构(甚至不同维度),只要上下文向量维度匹配即可
- 误区:条件概率链式分解是 Seq2Seq 特有的 → 正确:这是所有自回归模型的通用分解,GPT 也用同样公式(只是没有条件 x)
- 误区:瓶颈问题可以用更大的上下文向量解决 → 正确:固定大小的向量无法随序列长度线性扩展,根本解法是注意力(直接访问所有 encoder 隐状态)
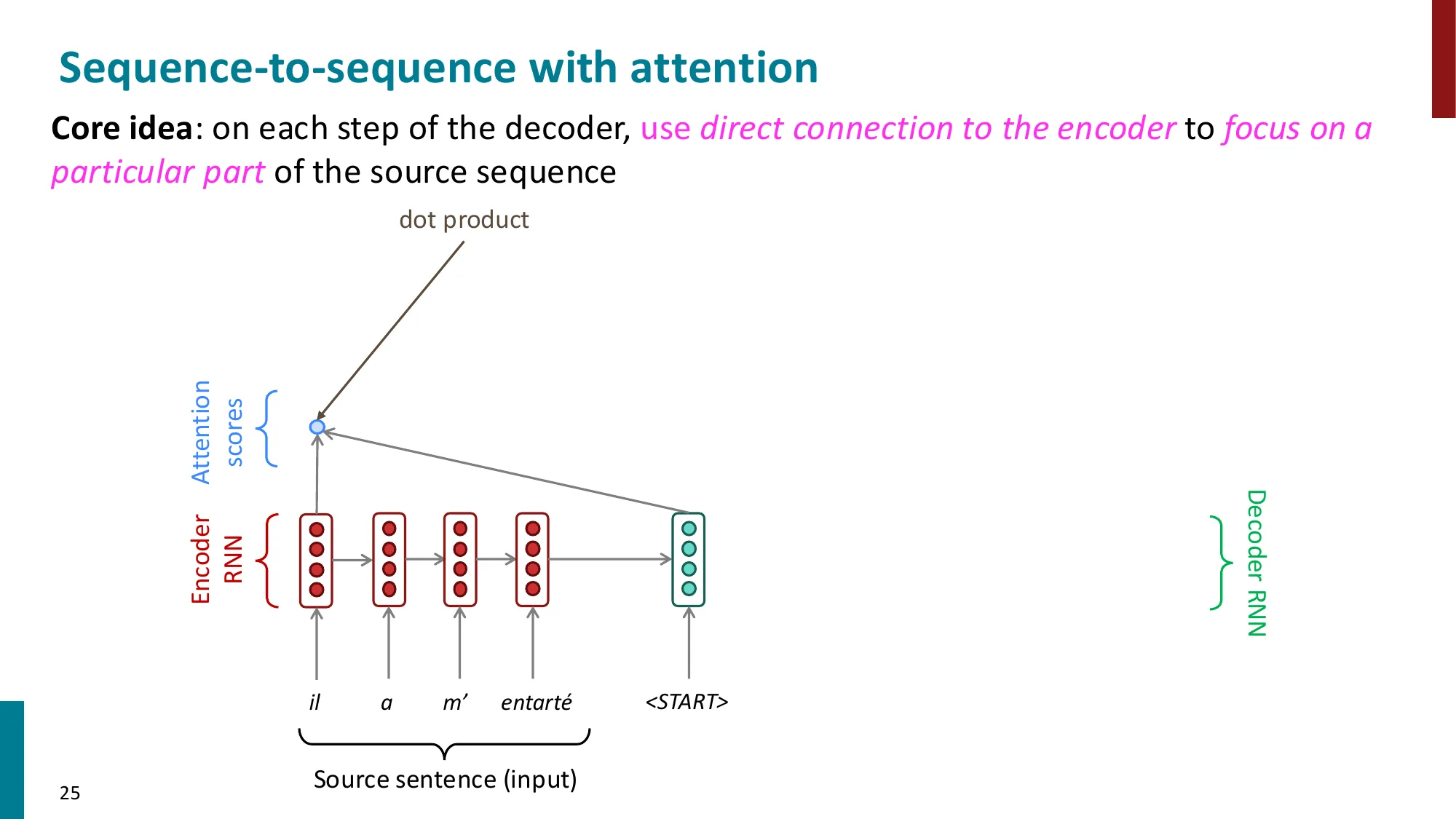
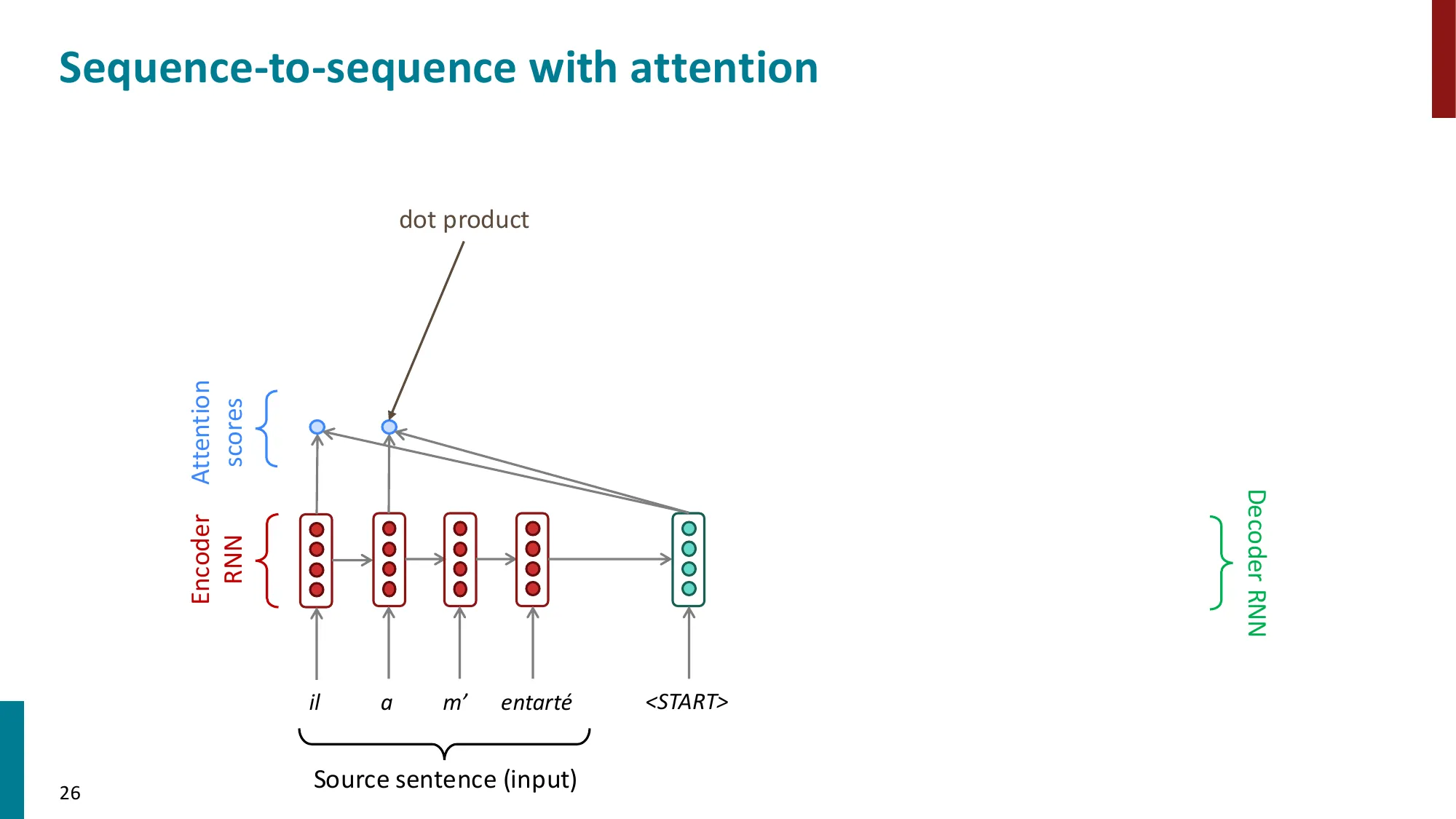
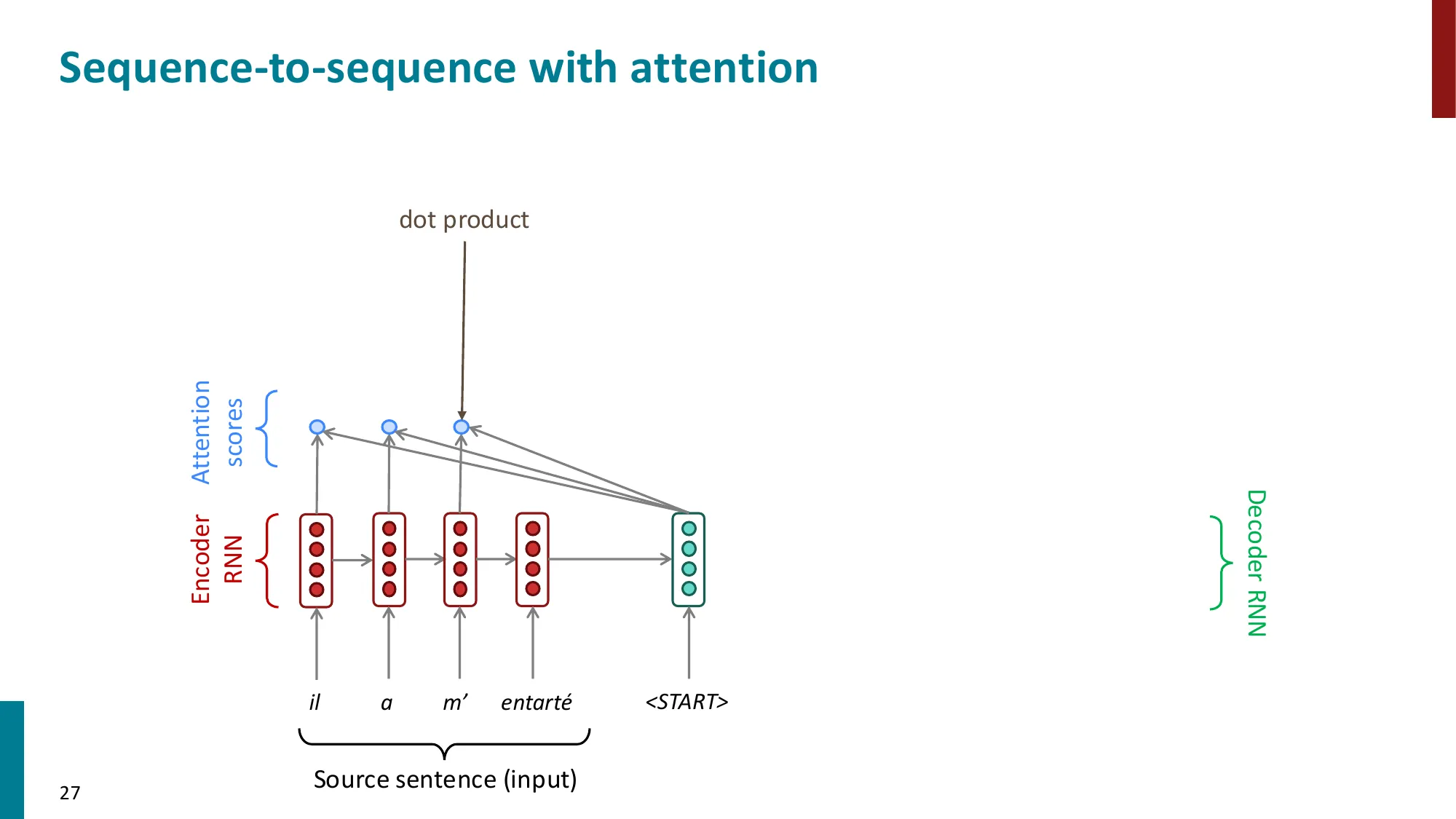
3. 从 RNN 到注意力(Attention)
- 注意力机制的动机:解决 seq2seq 的信息瓶颈
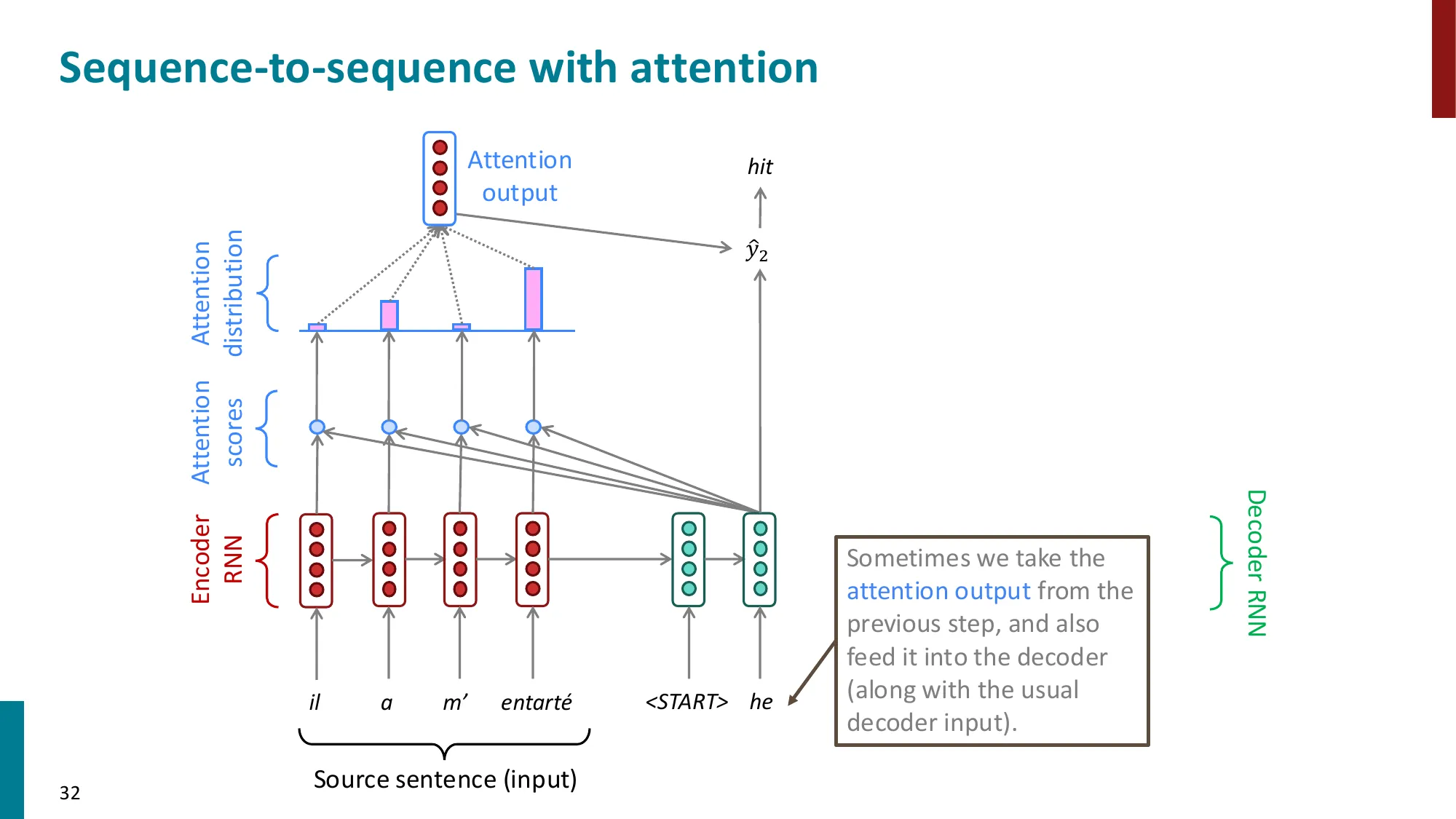
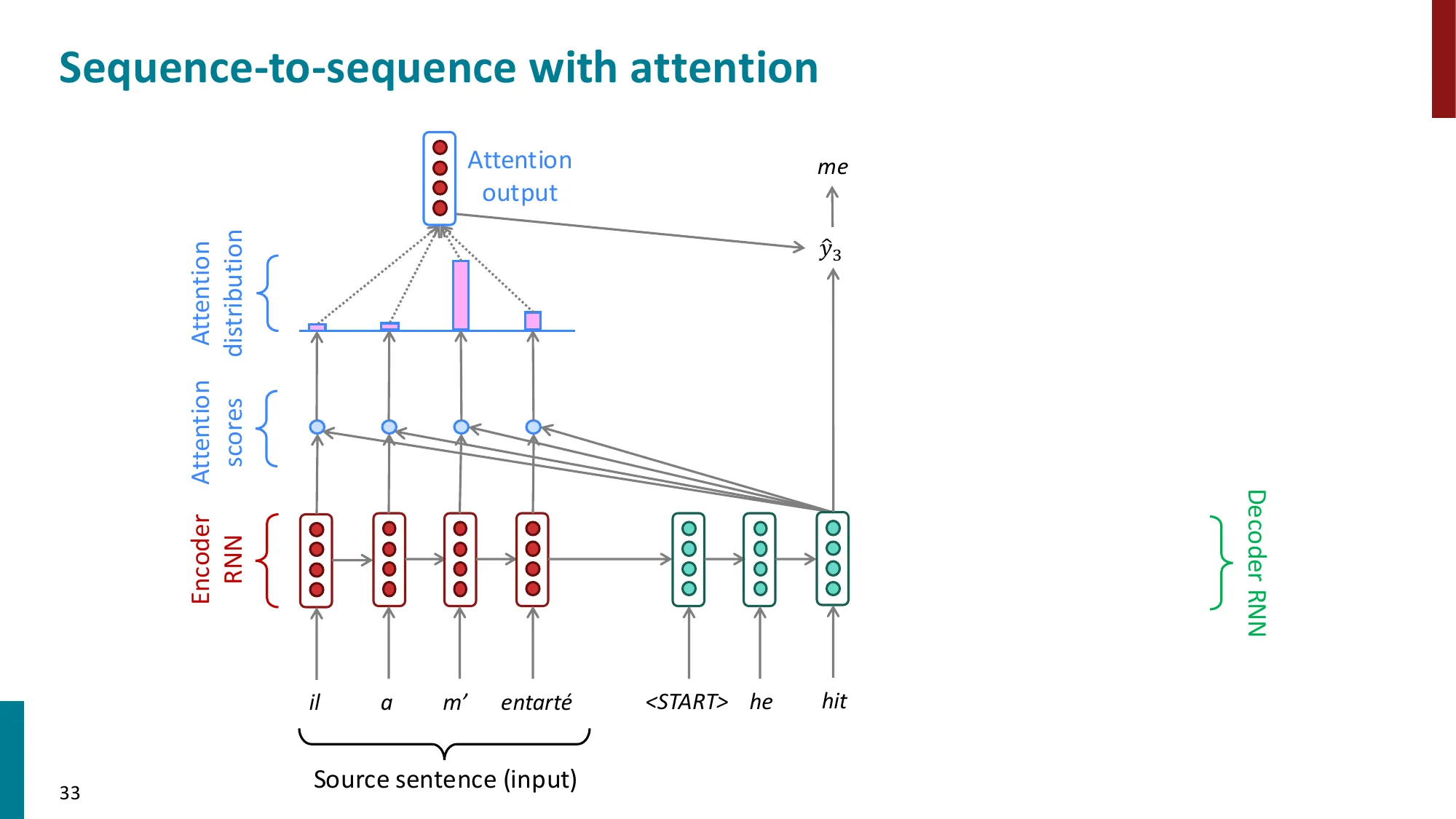
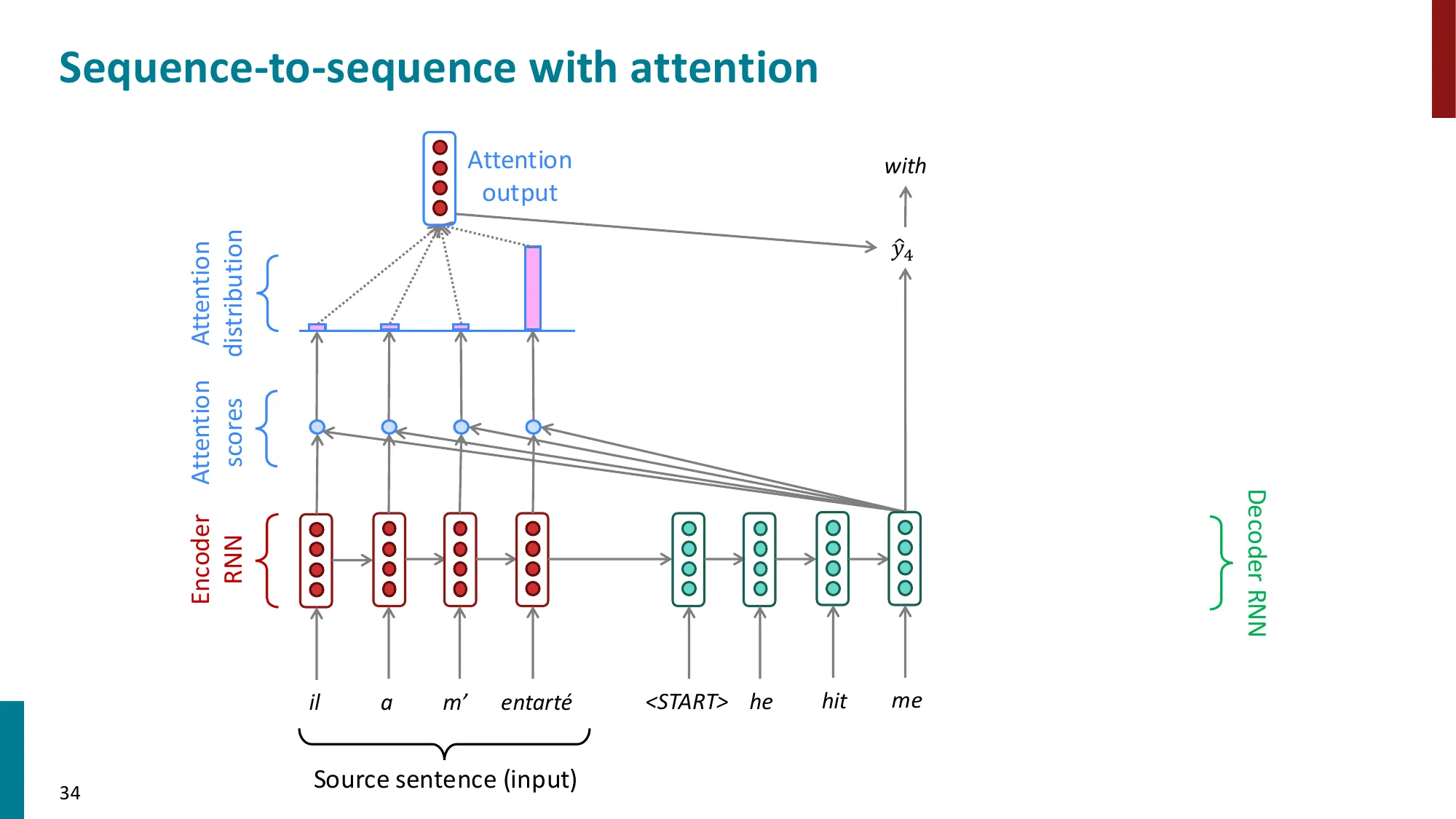
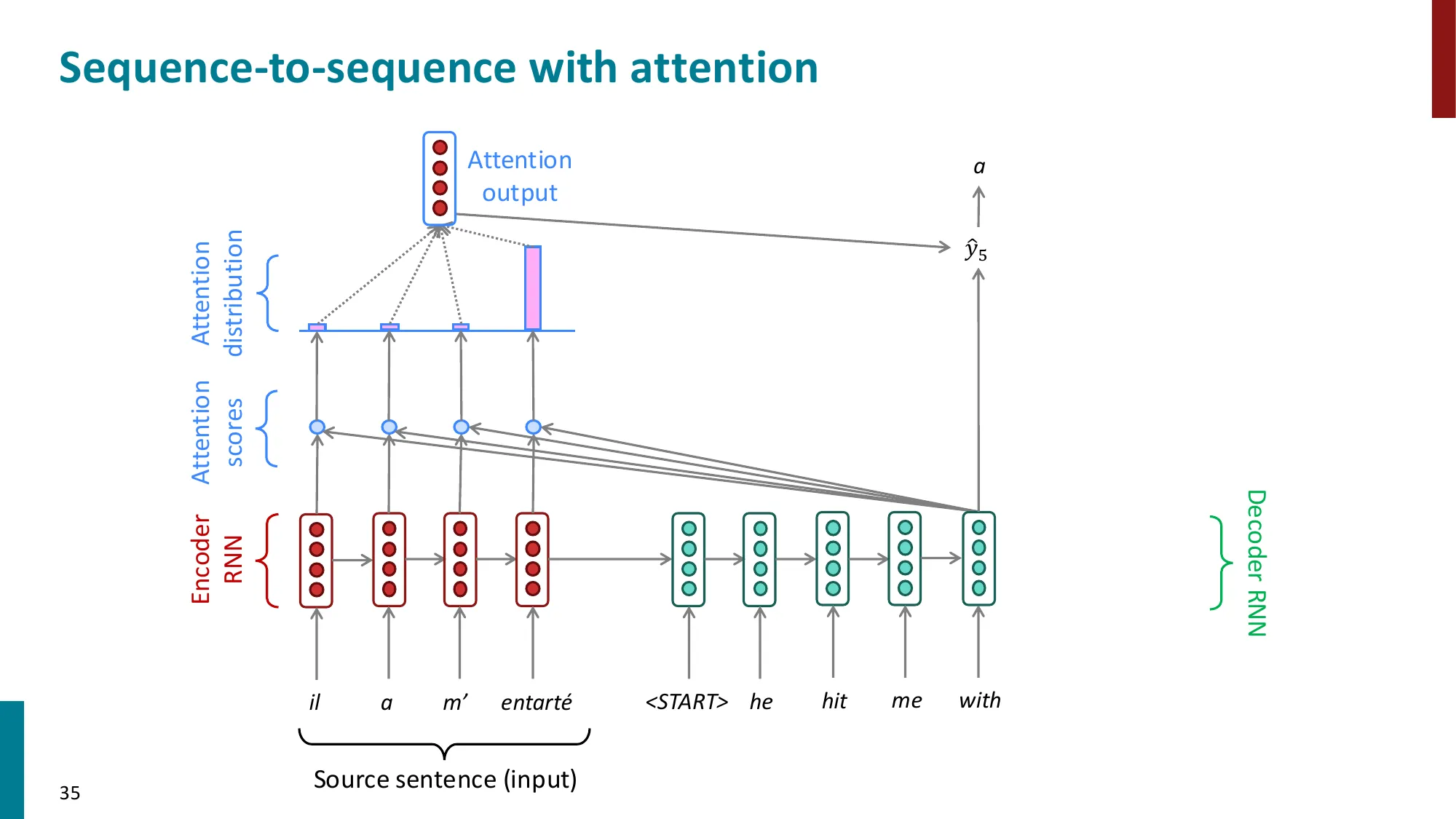
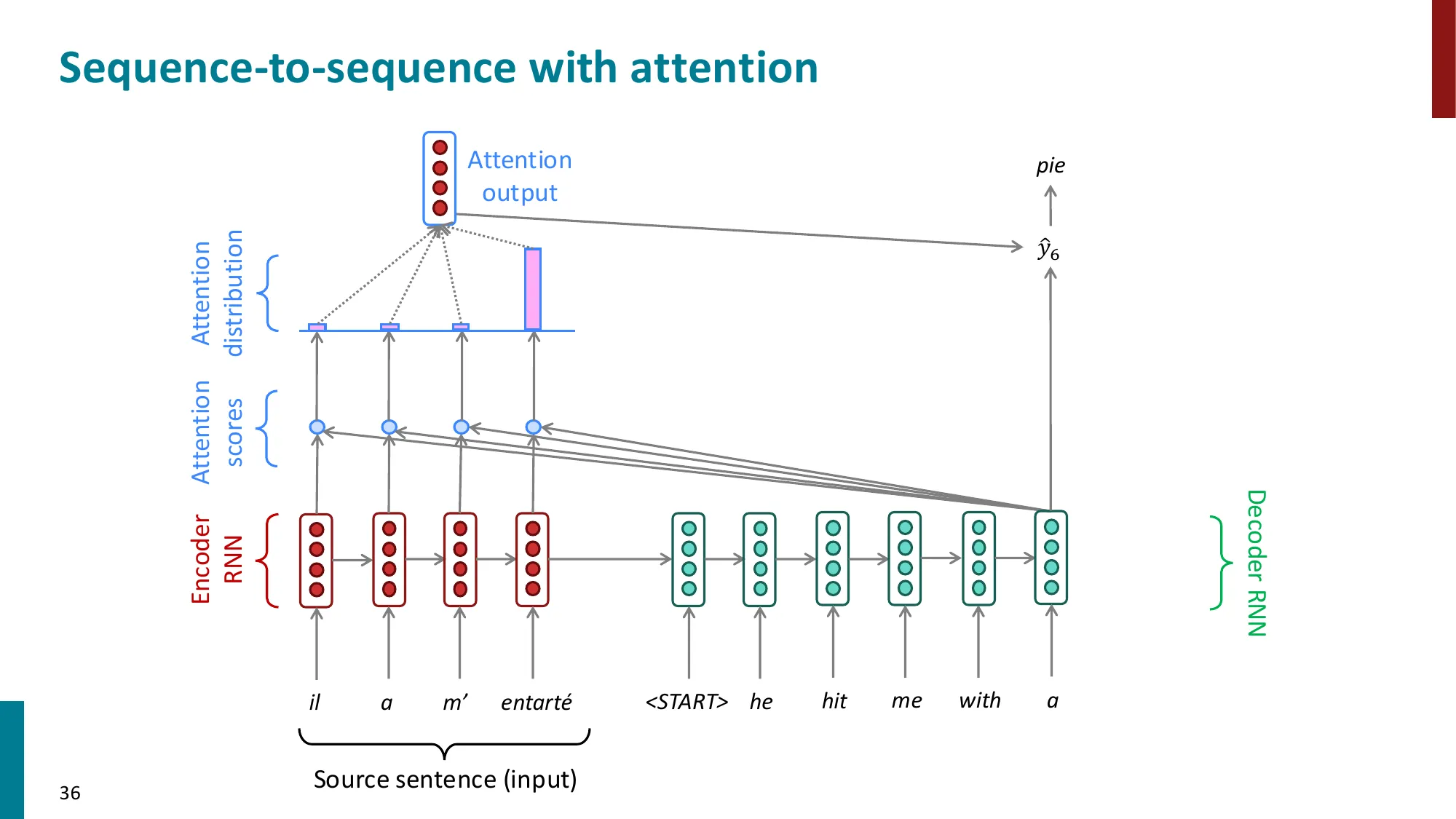
- 核心思想:在每个解码步,允许 decoder 直接”看到”所有 encoder 隐状态
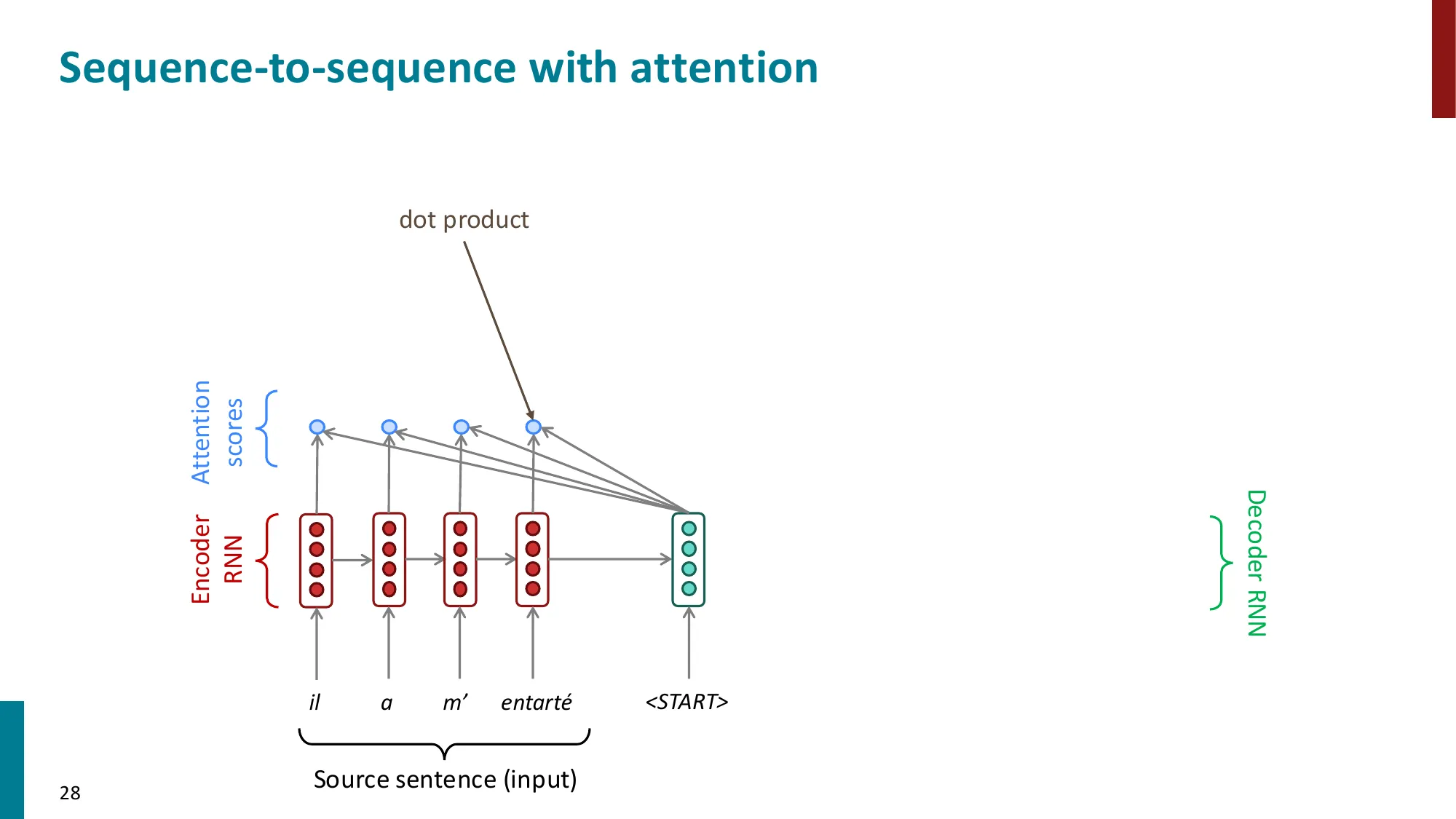
- 注意力计算步骤:
- (1) 计算注意力分数:ei=sThi(decoder 隐状态 s 与 encoder 隐状态 hi 的点积)
- (2) 归一化:α=softmax(e)∈Rn(注意力权重/分布)
- (3) 加权求和:a=∑iαihi(注意力输出/上下文向量)
- 注意力变体:
- 点积注意力:ei=sThi
- 缩放点积注意力:ei=dksThi
- 加性注意力:ei=vTtanh(W1hi+W2s)
📐 三步注意力计算:完整推导
变量定义:
- st∈Rd = decoder 在时间步 t 的隐状态(Query)
- hi∈Rd = encoder 第 i 个位置的隐状态(Key/Value)
- H=[h1,…,hn]∈Rd×n = 所有 encoder 隐状态
- ei∈R = 第 i 个位置的注意力分数(标量)
- α∈Rn = 注意力权重向量(概率分布)
- at∈Rd = 注意力输出(加权上下文向量)
推导过程:
第 1 步:计算注意力分数(三种等价变体)
点积注意力(Luong et al., 2015):
ei=stThi
缩放点积注意力(Vaswani et al., 2017):
ei=dstThi
缩放原因:stThi 的期望方差为 d(若 st,hi 各分量 i.i.d. 均值0方差1),d 缩放将方差归一化为1。
加性注意力(Bahdanau et al., 2015):
ei=vTtanh(W1hi+W2st),v∈Rda,W1,W2∈Rda×d
参数 v,W1,W2 通过反向传播学习,表达能力更强但参数更多。
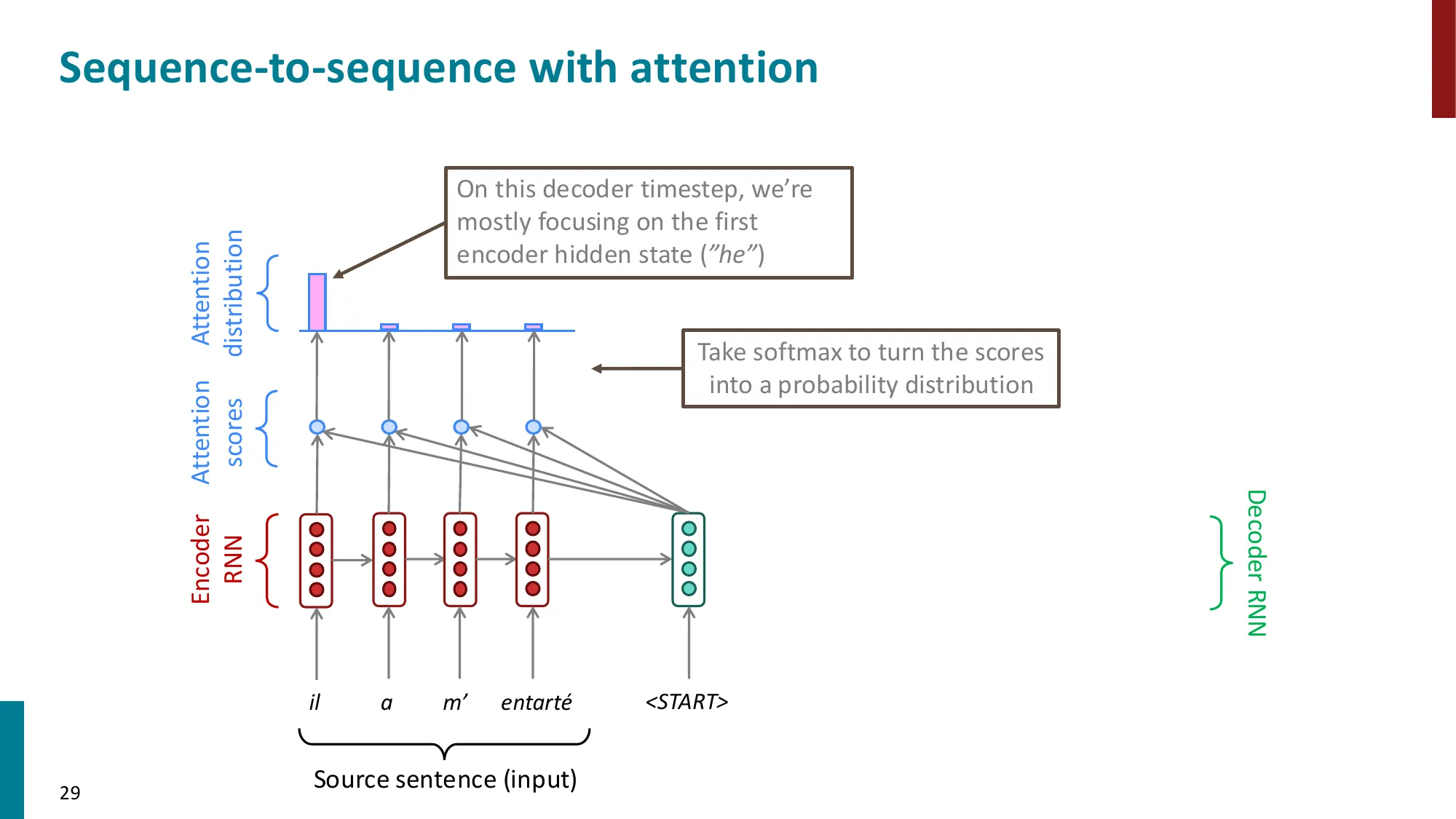
第 2 步:Softmax 归一化
将 n 个原始分数归一化为概率分布:
αi=∑j=1nexp(ej)exp(ei),α∈Rn,∑i=1nαi=1,αi≥0
矩阵形式:α=softmax(e)
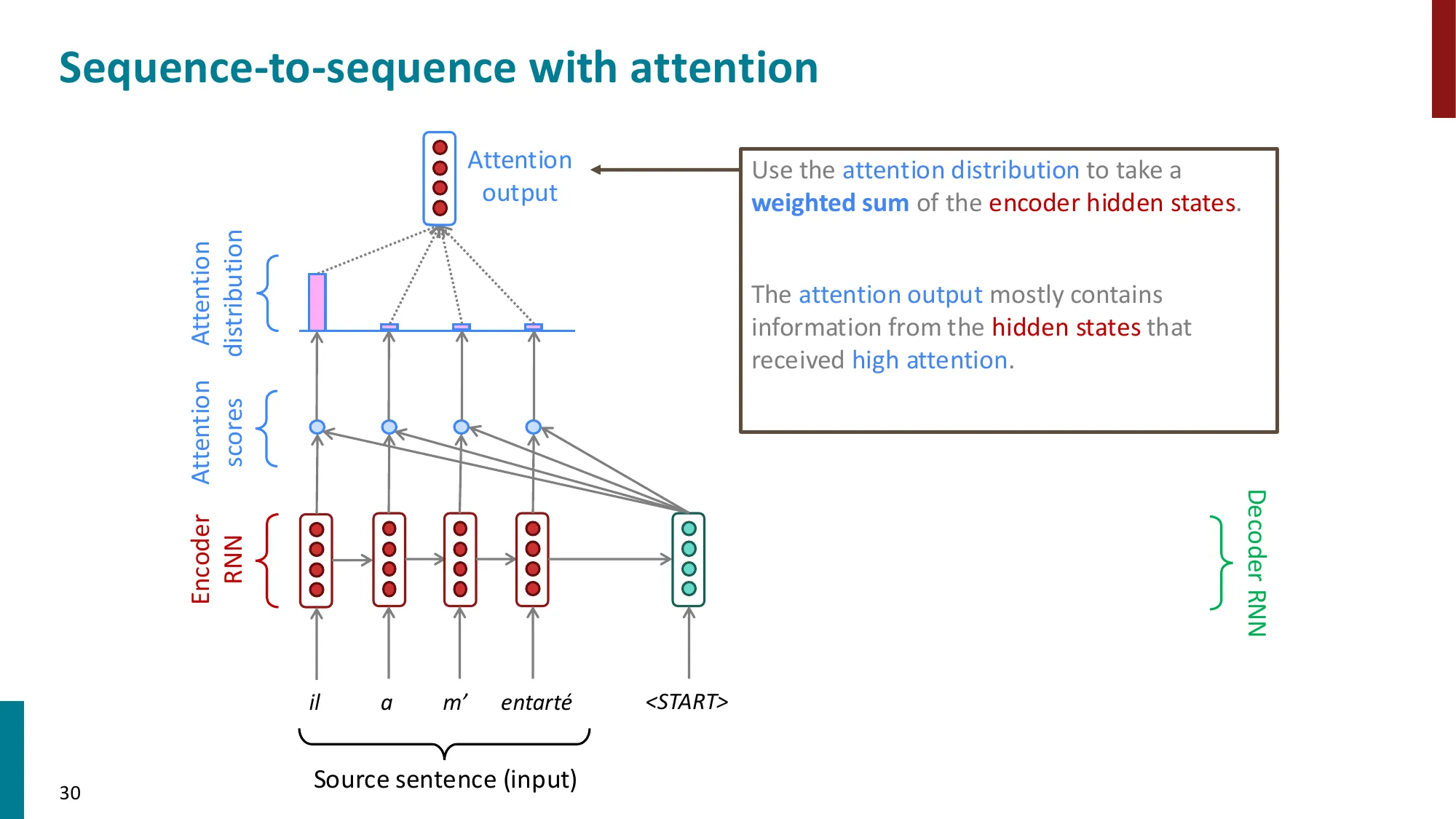
第 3 步:加权求和得上下文向量
at=∑i=1nαihi=Hα∈Rd
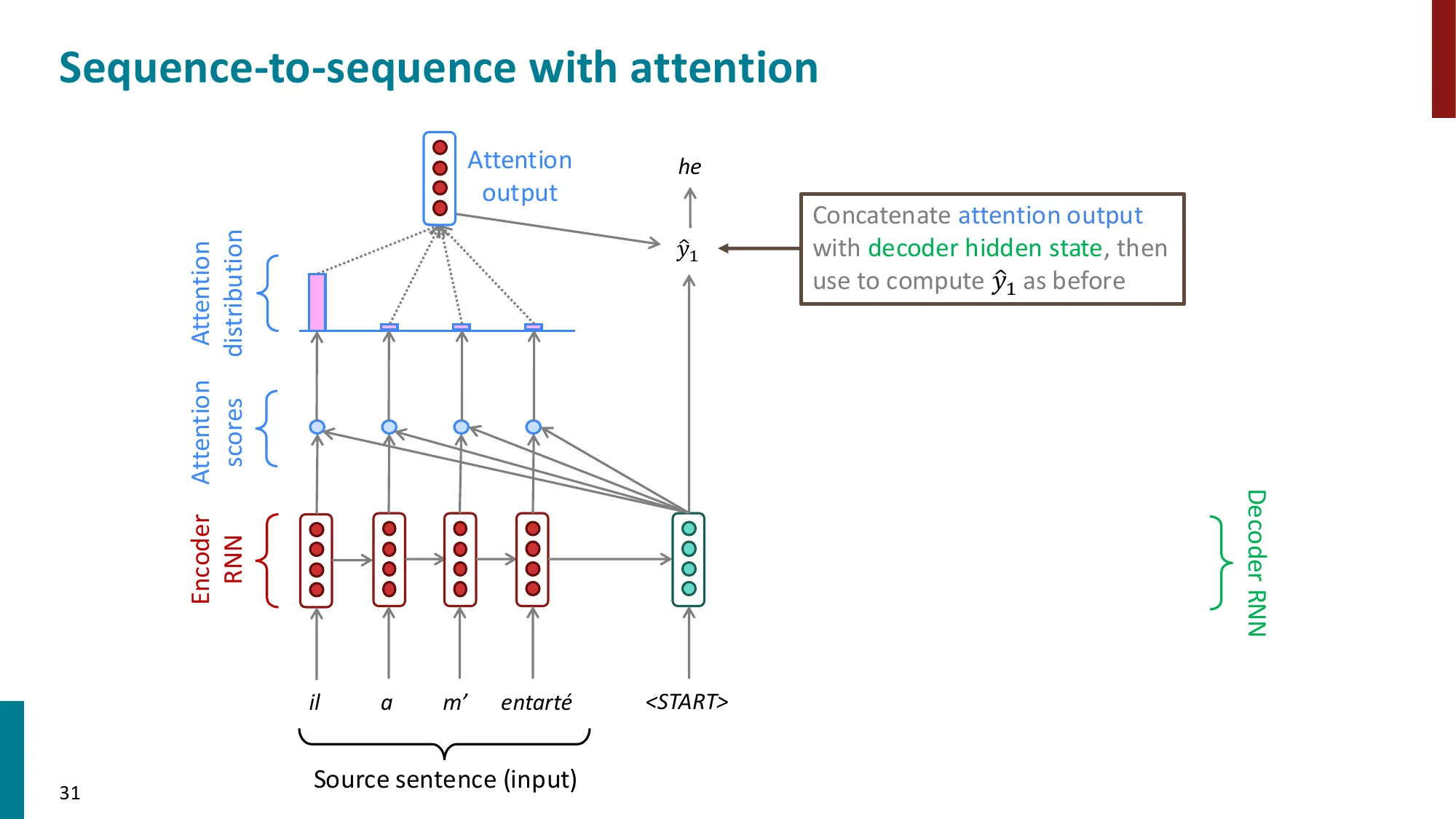
最终将 at 与 st 拼接,送入输出层:s~t=tanh(Wc[at;st]),用于预测 yt。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:d=2,encoder 3 个位置,decoder 当前隐状态 s=[0.8,0.2]
| 变量 | 值 |
|---|
| h1 | [1.0,0.0] |
| h2 | [0.0,1.0] |
| h3 | [0.5,0.5] |
| s | [0.8,0.2] |
计算(点积注意力):
-
注意力分数:
- e1=sTh1=0.8×1.0+0.2×0.0=0.8
- e2=sTh2=0.8×0.0+0.2×1.0=0.2
- e3=sTh3=0.8×0.5+0.2×0.5=0.5
-
Softmax(e=[0.8,0.2,0.5]):
- exp(e)=[2.226,1.221,1.649],∑=5.096
- α=[0.437,0.239,0.324]
-
加权求和:
a=0.437×[1,0]+0.239×[0,1]+0.324×[0.5,0.5]=[0.599,0.401]
结论:decoder 最关注 h1(43.7%),因为 s 在第一维较大,与 h1 对齐。
💡 为什么这样做?
注意力 = 软搜索(soft search)。
传统信息检索是硬搜索:输入查询词,精确匹配,返回结果。注意力是软版本:给每个 encoder 位置分配”相关性权重”,用加权平均把所有位置的信息混合起来。
为什么用加权平均而不是”找最相关的那个”?因为翻译一个词往往对应源句多个词的组合,权重让模型学会”分配注意力”而不是强制选一个。
三种分数变体的权衡:
- 点积:最简单,无额外参数
- 缩放点积:高维时更稳定(防止 softmax 饱和)
- 加性:最灵活,有额外参数捕捉更复杂的对应关系
⚠️ 常见误区
- 误区:注意力权重 α 是独热(one-hot)的,每次只关注一个位置 → 正确:α 是连续概率分布,多个位置可以同时被关注(这正是”软”的含义)
- 误区:只有一种注意力分数计算方式 → 正确:点积/缩放点积/加性等都是合法选项,没有绝对的”最好”;Transformer 用缩放点积,BERT 之前的 NMT 常用加性
- 误区:注意力向量 at 直接就是输出 → 正确:at 通常需要与 st 拼接后再经过线性层才能预测 yt
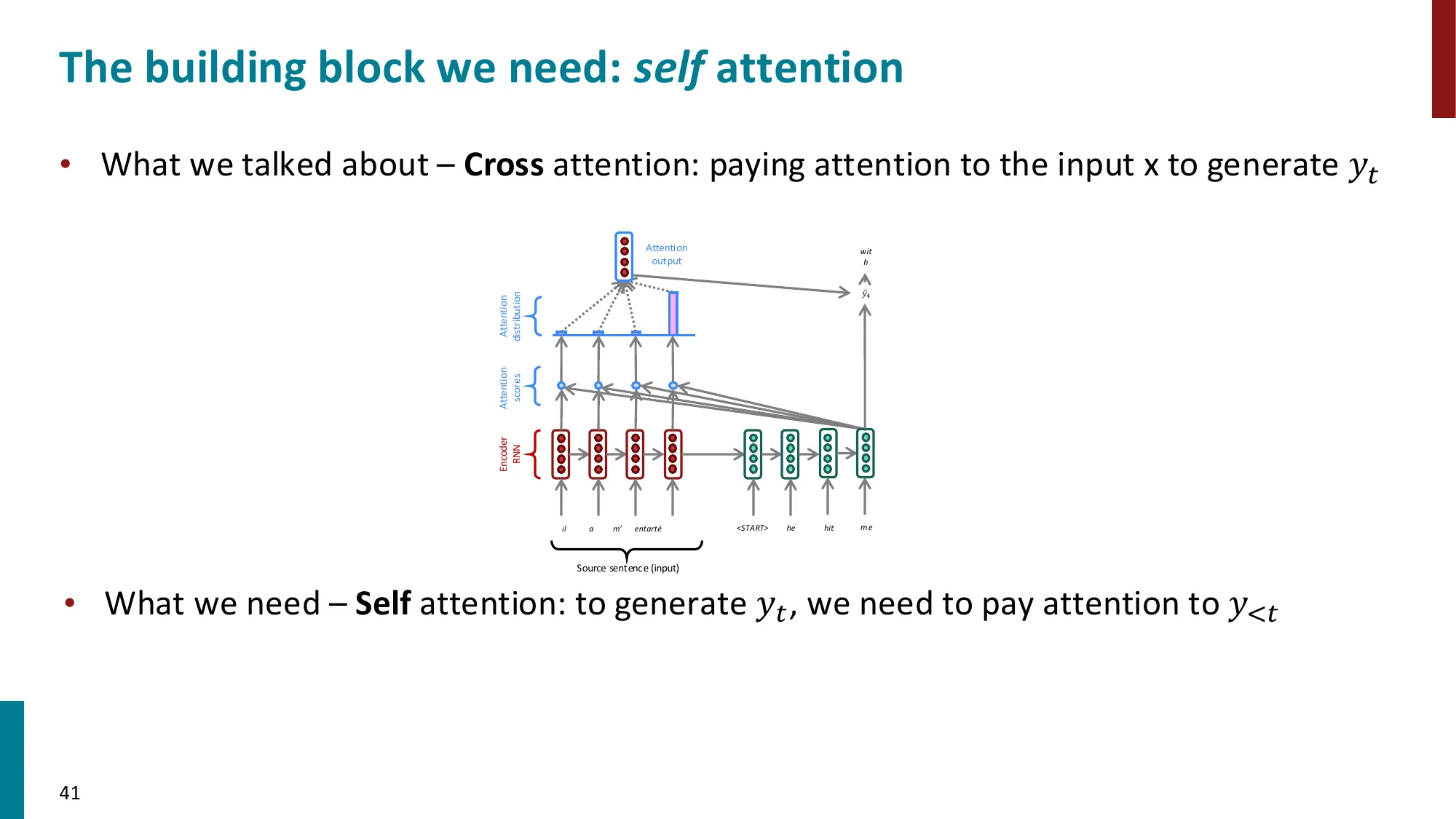
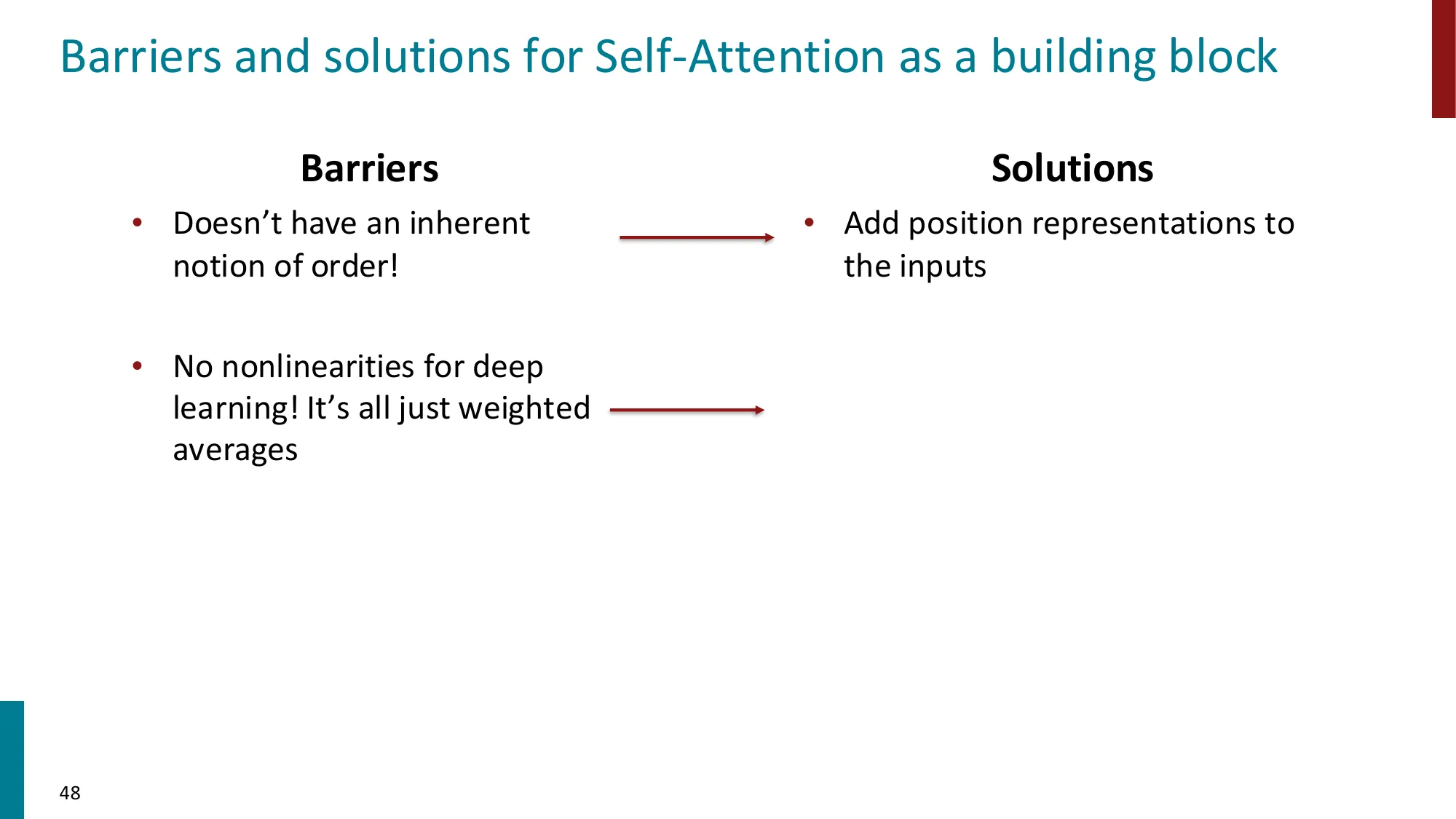
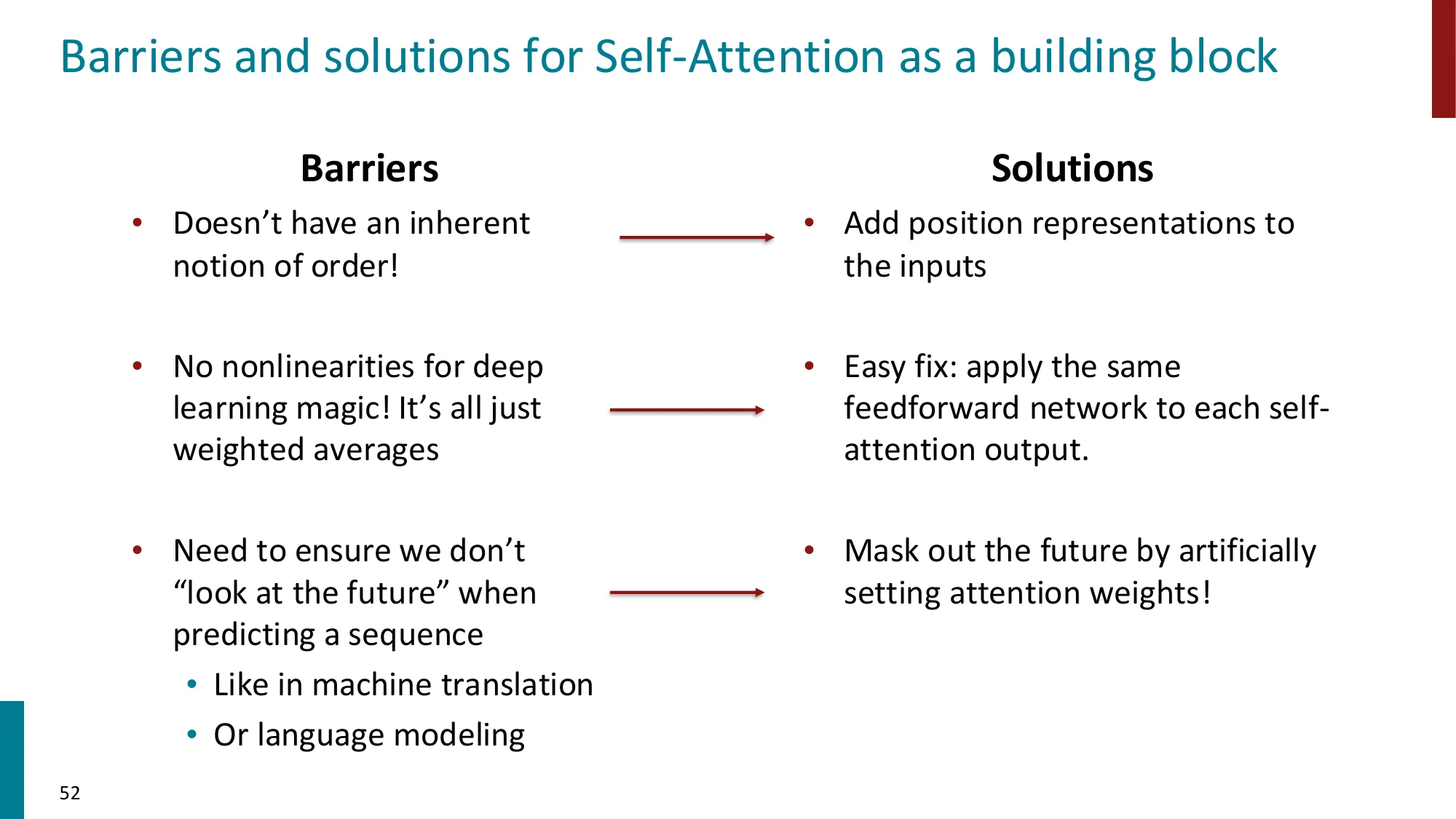
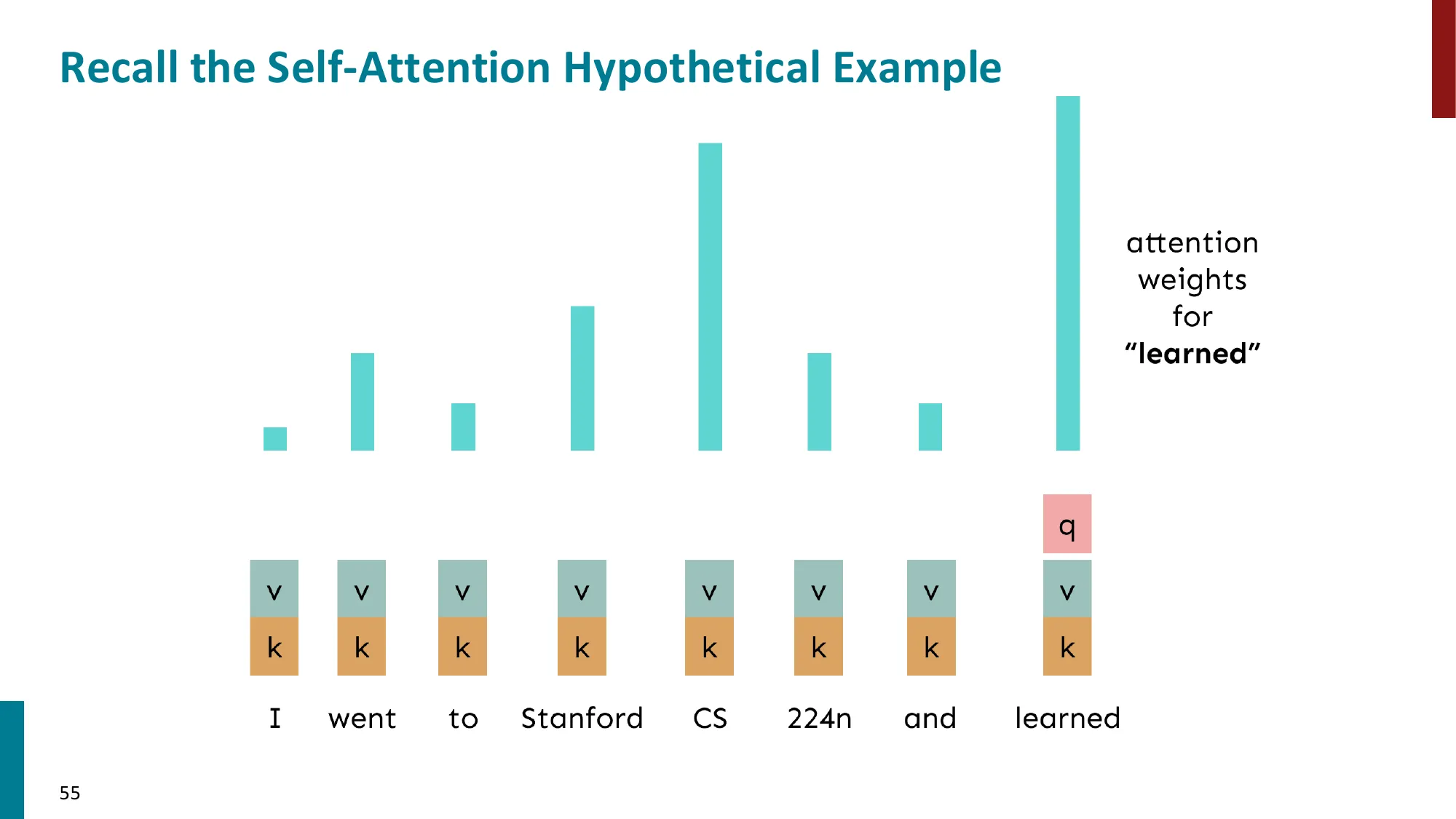
4. 自注意力(Self-Attention)
- 关键创新:注意力不仅用于 encoder-decoder 之间,序列内部也可以互相注意
- Query-Key-Value 框架:
- 每个位置 i 生成三个向量:qi=WQxi,ki=WKxi,vi=WVxi
- 注意力分数:eij=qiTkj
- 输出:outputi=∑jαijvj
- 矩阵形式:
- Attention(Q,K,V)=softmax(dkQKT)V
- 缩放因子 dk 的作用:防止点积值过大导致 softmax 梯度过小
- 优点:
- 每个位置可以直接关注任何其他位置(O(1) 的路径长度 vs RNN 的 O(n))
- 全部位置可以并行计算(vs RNN 的顺序计算)
- 缺点:计算复杂度 O(n2d),对长序列代价高
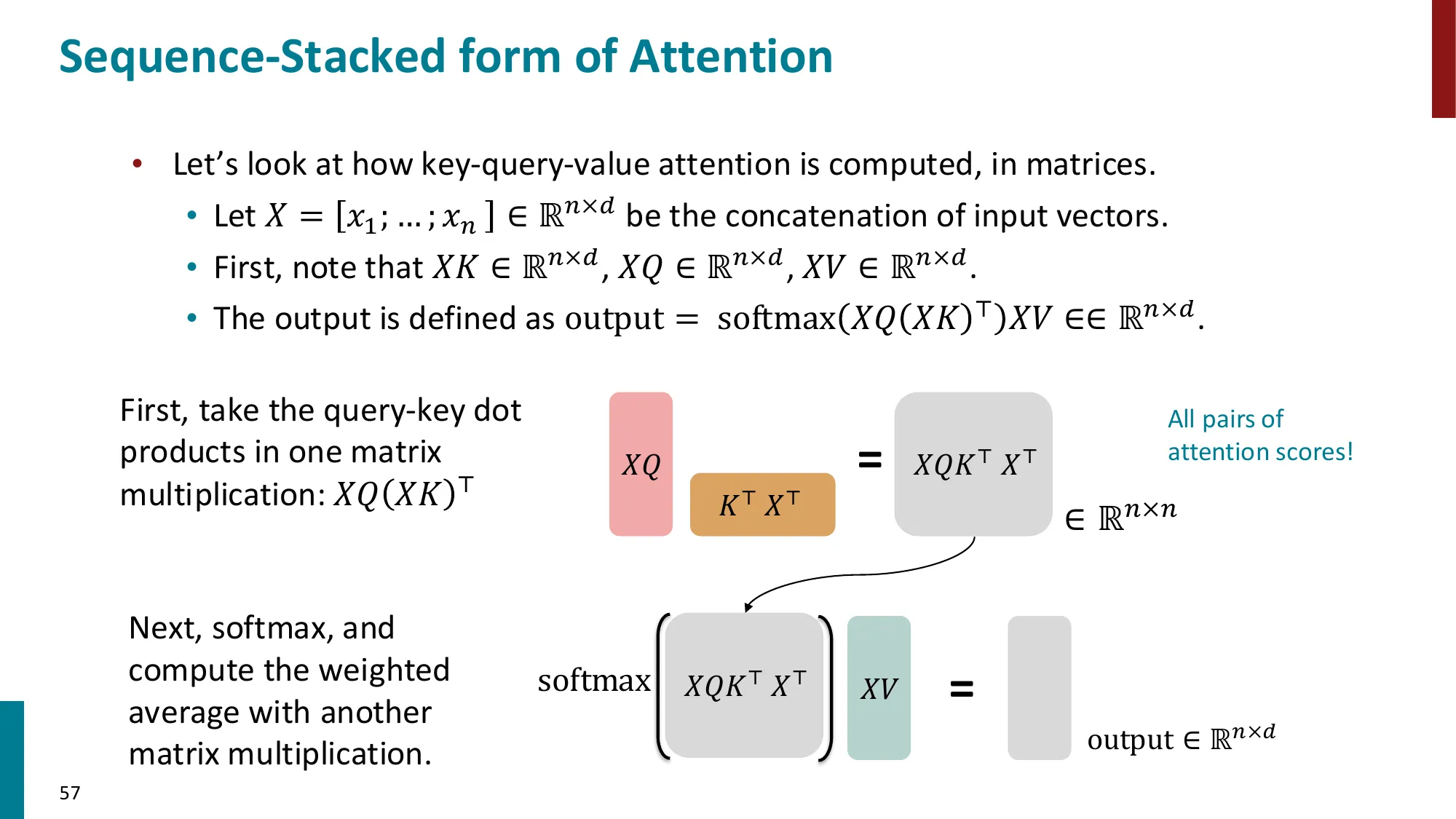
📐 Attention(Q, K, V):完整推导
变量定义:
- X∈Rn×dmodel = 输入矩阵(序列长度 n,每个位置 dmodel 维)
- WQ∈Rdmodel×dk = Query 投影矩阵
- WK∈Rdmodel×dk = Key 投影矩阵
- WV∈Rdmodel×dv = Value 投影矩阵
- Q=XWQ∈Rn×dk,K=XWK∈Rn×dk,V=XWV∈Rn×dv
推导过程:
第 1 步:线性投影
每个输入向量 xi∈Rdmodel 通过三个独立线性变换得到 Q/K/V:
qi=xiWQ,ki=xiWK,vi=xiWV
矩阵形式同时处理所有位置:Q=XWQ,K=XWK,V=XWV
第 2 步:计算相似度矩阵
计算所有 Query 与所有 Key 的点积,得到 n×n 注意力分数矩阵:
E=QKT∈Rn×n,Eij=qiTkj
Eij 表示位置 i 对位置 j 的原始注意力分数。
第 3 步:缩放(关键步骤)
为什么需要除以 dk?
设 qi,kj 的各分量 i.i.d.,均值 0,方差 1,则:
Var(qiTkj)=Var(∑l=1dkqilkjl)=∑l=1dkVar(qil)⋅Var(kjl)=dk
所以 qiTkj 的标准差为 dk。不缩放时,dk 较大(如 64)的分数会使 softmax 饱和在接近独热分布的区域,梯度近乎为零。缩放后方差归一化为 1:
E~=dkQKT
第 4 步:Softmax 按行归一化
A=softmax(dkQKT)∈Rn×n
按行归一化:Aij=∑l=1nexp(E~il)exp(E~ij),每行之和为 1。
Aij 是位置 i 分配给位置 j 的注意力权重。
第 5 步:加权求和 Value 得输出
O=AV∈Rn×dv,Oi=∑j=1nAijvj
位置 i 的输出是所有位置 Value 向量按注意力权重的加权平均。
完整公式:
Attention(Q,K,V)=softmax(dkQKT)V
形状追踪(务必熟练):
| 矩阵 | 形状 | 说明 |
|---|
| Q | (n×dk) | |
| KT | (dk×n) | |
| QKT | (n×n) | 注意力矩阵,与序列长度平方成正比 |
| A=softmax(⋅) | (n×n) | 行归一化概率矩阵 |
| V | (n×dv) | |
| O=AV | (n×dv) | 最终输出 |
计算复杂度:
- QKT:(n×dk)⋅(dk×n)⇒O(n2dk)
- AV:(n×n)⋅(n×dv)⇒O(n2dv)
- 总:O(n2d)(n2 是瓶颈)
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:n=3,dmodel=4,dk=dv=2
输入矩阵 X:
X=101011100010
投影矩阵(为简化取前两维):
WQ=WK=WV=10000100
第 1 步:计算 Q,K,V=XW(取输入前两维):
Q=K=V=101011
第 2 步:计算 E=QKT:
E=101011[100111]=101011112
第 3 步:缩放 E~=E/2≈E/1.414:
E~≈0.70700.70700.7070.7070.7070.7071.414
第 4 步:按行 softmax(取第 3 行为例,[0.707,0.707,1.414]):
- exp([0.707,0.707,1.414])=[2.028,2.028,4.113],∑=8.169
- A3≈[0.248,0.248,0.503](第 3 个词最关注自身)
第 5 步:O=AV(第 3 行输出):
O3=0.248×[1,0]+0.248×[0,1]+0.503×[1,1]≈[0.751,0.751]
结论:词 3(“1,1” 特征)主要关注自身(50.3%),并均等关注词 1 和词 2。
💡 为什么这样做?
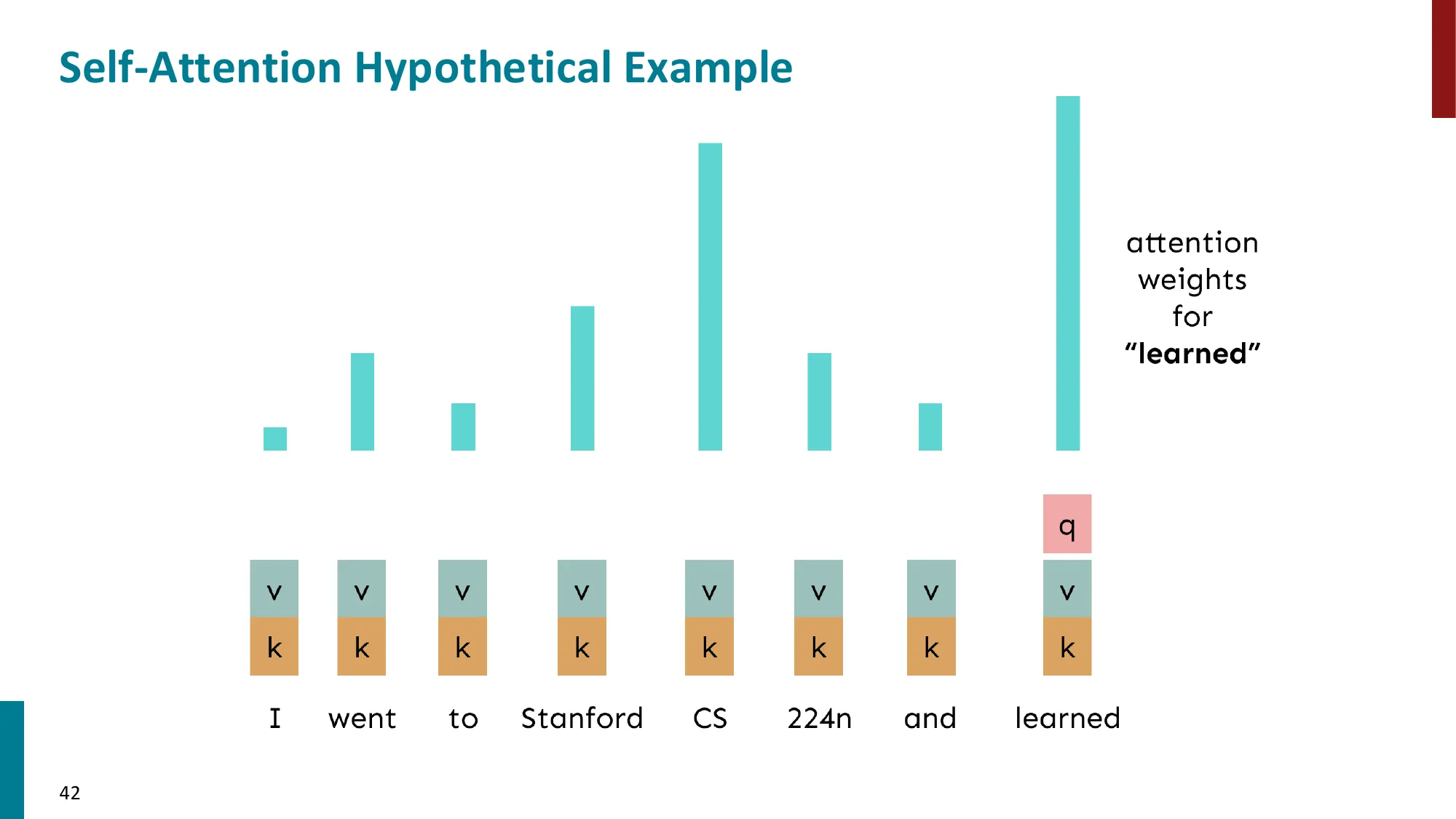
自注意力 = “让序列中每个词问问自己与其他所有词的关系”。
- Query(qi):“我在找什么类型的信息?”
- Key(kj):“我能提供什么类型的信息?”
- Value(vj):“我实际携带的内容是什么?”
qiTkj 衡量”位置 i 的信息需求”与”位置 j 的信息供给”的匹配程度。匹配越高,注意力越大,从 vj 取的信息越多。
类比搜索引擎:Query 是搜索词,Key 是页面关键词,Value 是页面内容。注意力分数决定哪些页面排前,输出是加权后的搜索结果。
与 encoder-decoder 注意力的区别:自注意力的 Q、K、V 都来自同一序列(“自”的含义),而 encoder-decoder 注意力的 Q 来自 decoder,K/V 来自 encoder。
⚠️ 常见误区
-
误区:自注意力天然知道位置信息 → 正确:自注意力完全没有位置概念——“I love you” 和 “you love I” 的自注意力输出完全相同(排列不变性)。这就是为什么需要额外注入位置编码。
-
误区:1/dk 可以省略 → 正确:dk 越大,qTk 的方差越大,softmax 越接近独热,梯度越接近零。Vaswani et al. 实验表明:去掉缩放后 dk=64 时模型性能显著下降。
-
误区:QKT 的形状是 (dk×dk) → 正确:QKT 的形状是 (n×n)(序列长度的平方),不是 (dk×dk)。这是长序列计算代价高的根本原因。
-
误区:WQ,WK,WV 是方阵(dmodel×dmodel)→ 正确:它们的输出维度 dk 可以与 dmodel 不同(多头注意力中通常 dk=dmodel/h)。
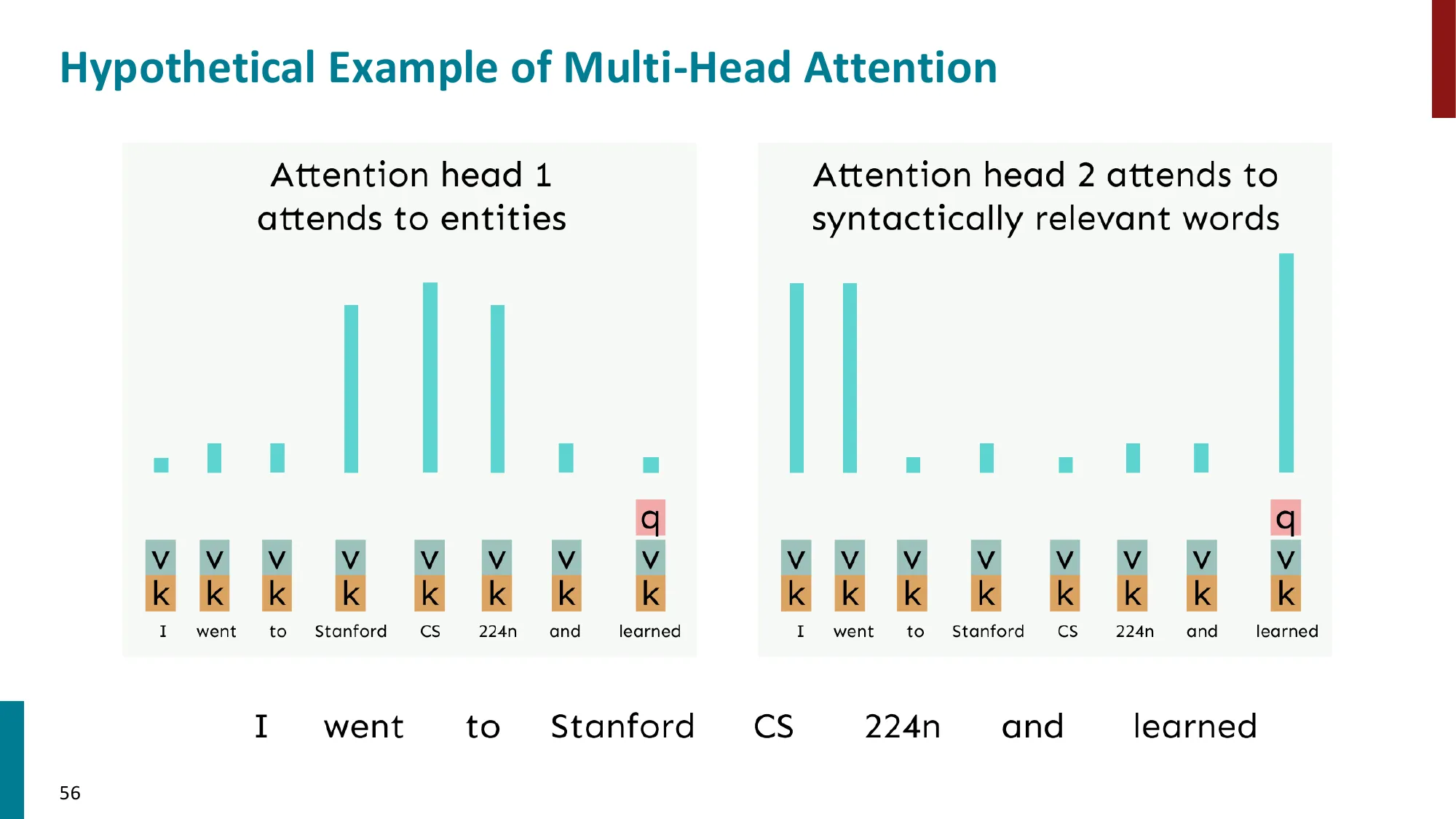
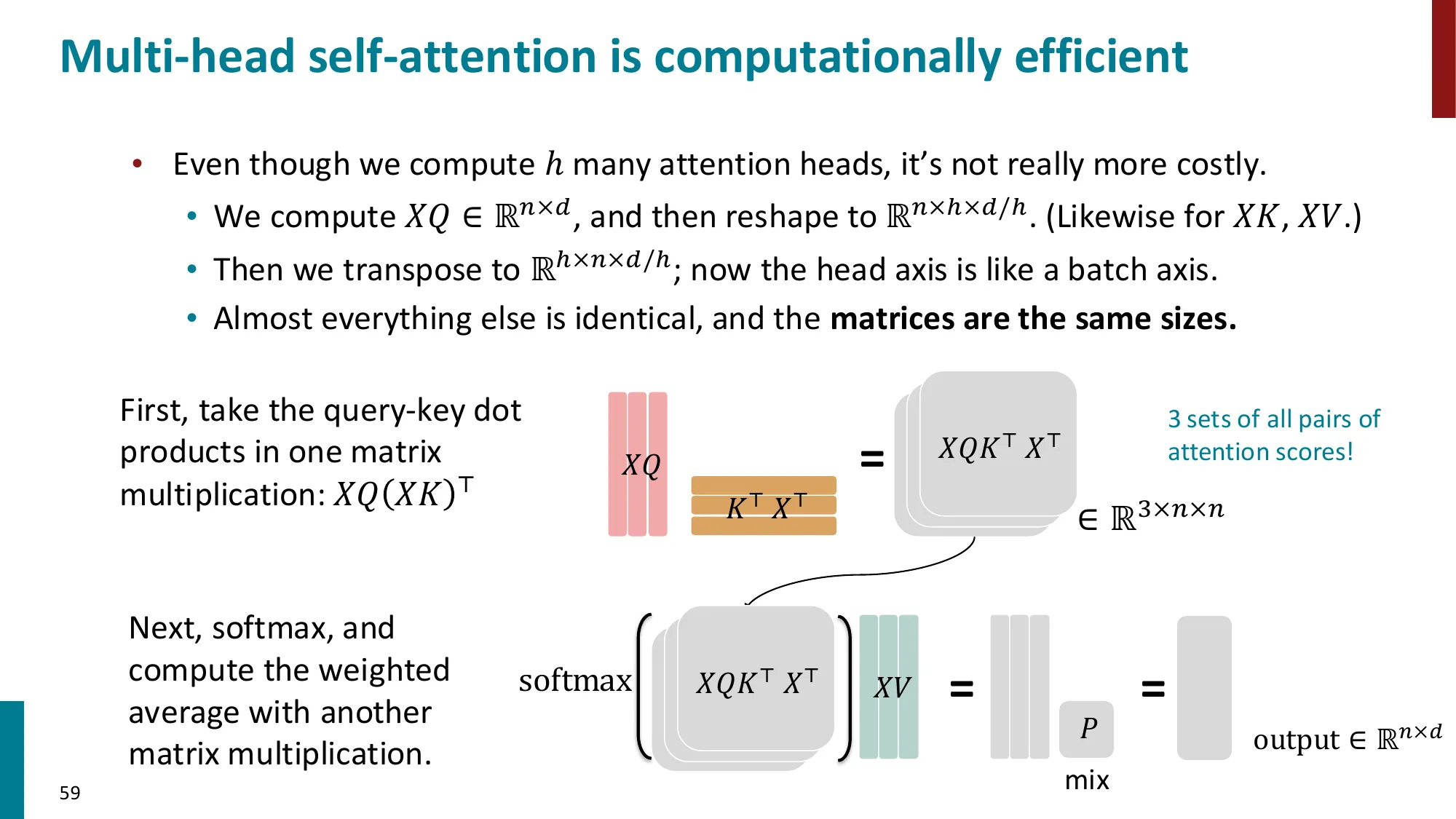
5. 多头注意力(Multi-Head Attention)
- 动机:不同的”头”可以关注不同类型的信息(句法、语义、位置等)
- MultiHead(Q,K,V)=Concat(head1,…,headh)WO
- headi=Attention(QWiQ,KWiK,VWiV)
- 每个头的维度 dk=dmodel/h,总计算量与单头相近
📐 Multi-Head Attention:完整推导
变量定义:
- h = 注意力头数(Transformer base 中 h=8)
- dmodel = 模型维度(Transformer base 中 dmodel=512)
- dk=dv=dmodel/h = 每个头的维度(base 中 dk=64)
- WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv = 第 i 个头的投影矩阵
- WO∈Rhdv×dmodel = 输出投影矩阵
推导过程:
第 1 步:每个头独立计算注意力
第 i 个头将输入投影到低维子空间后计算注意力:
headi=Attention(QWiQ,KWiK,VWiV)∈Rn×dv
每个头有自己独立的 WiQ,WiK,WiV——这是关键,让每个头可以”专注”不同方面。
第 2 步:拼接所有头的输出
沿最后维度拼接 h 个头的输出:
Concat(head1,…,headh)∈Rn×(h⋅dv)=Rn×dmodel
(因为 h⋅dv=h⋅(dmodel/h)=dmodel)
第 3 步:输出投影
用 WO 将拼接结果投影回 dmodel 维,融合来自不同头的信息:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO∈Rn×dmodel
参数量分析(每个 MultiHead 层):
- h 个头的 WiQ:h×dmodel×dk=dmodel2(因为 h⋅dk=dmodel)
- 同理 WiK,WiV:各 dmodel2
- WO:hdv×dmodel=dmodel2
- 总参数量:4dmodel2(与单头完全相同!)
计算量分析:h 个头,每个头维度 dk=dmodel/h,计算量 ≈h×O(n2dk)=O(n2dmodel)(与单头相同量级)。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
设定:dmodel=8,h=2,n=3,dk=dv=4
| 参数 | 值 |
|---|
| dmodel | 8 |
| h(头数) | 2 |
| dk=dv | 8/2=4 |
| 每个 WiQ 形状 | (8×4) |
| WO 形状 | (8×8) |
Head 1 投影到前 4 维方向 → 假设捕捉句法关系(如主谓一致):
- QW1Q:形状 (3×4),注意力输出 head1:(3×4)
Head 2 投影到后 4 维方向 → 假设捕捉语义关系(如共指):
- QW2Q:形状 (3×4),注意力输出 head2:(3×4)
拼接:Concat(head1,head2):(3×8)
输出投影:乘以 WO(8×8),最终输出 (3×8)
参数量验证:
- 2个头的 WQ:2×8×4=64=82 ✓
- 同理 WK,WV:各 64
- WO:8×8=64
- 总:64×4=256=4×82 ✓(与单头参数量相同)
💡 为什么这样做?
多头注意力 = 多个视角同时观察。
单头注意力只能学到一种”什么和什么相关”的模式。多头允许模型同时问不同的问题:
- Head 1:“这个词的主语是谁?“(句法依存)
- Head 2:“这个代词指代什么?“(共指消解)
- Head 3:“这个动词的宾语是什么?“(论元结构)
- …
每个头在 dk 维的子空间内独立运算,互不干扰。最后用 WO 把所有头的发现”融合”成一个综合判断。
为什么不用 h 个独立的全维度注意力?计算量会变成 h 倍,而多头通过降维保持总计算量不变,兼顾效率和表达力。
⚠️ 常见误区
-
误区:多头注意力的计算量是单头的 h 倍 → 正确:每个头维度是 dmodel/h,总计算量 ≈h×O(n2⋅dmodel/h)=O(n2dmodel),与单头相同量级
-
误区:最后的 WO 只是”接口变换”,可以省略 → 正确:WO 是关键的信息融合矩阵,它让模型学习如何组合来自不同头的信息;省略后不同头的信息只是简单拼接,无法有效交互
-
误区:每个头一定学到了不同的语言学特征 → 正确:这是直觉上的解释,实践中头的分工不总是那么清晰;某些头可能学到相似的模式,也有研究显示许多头可以被剪枝
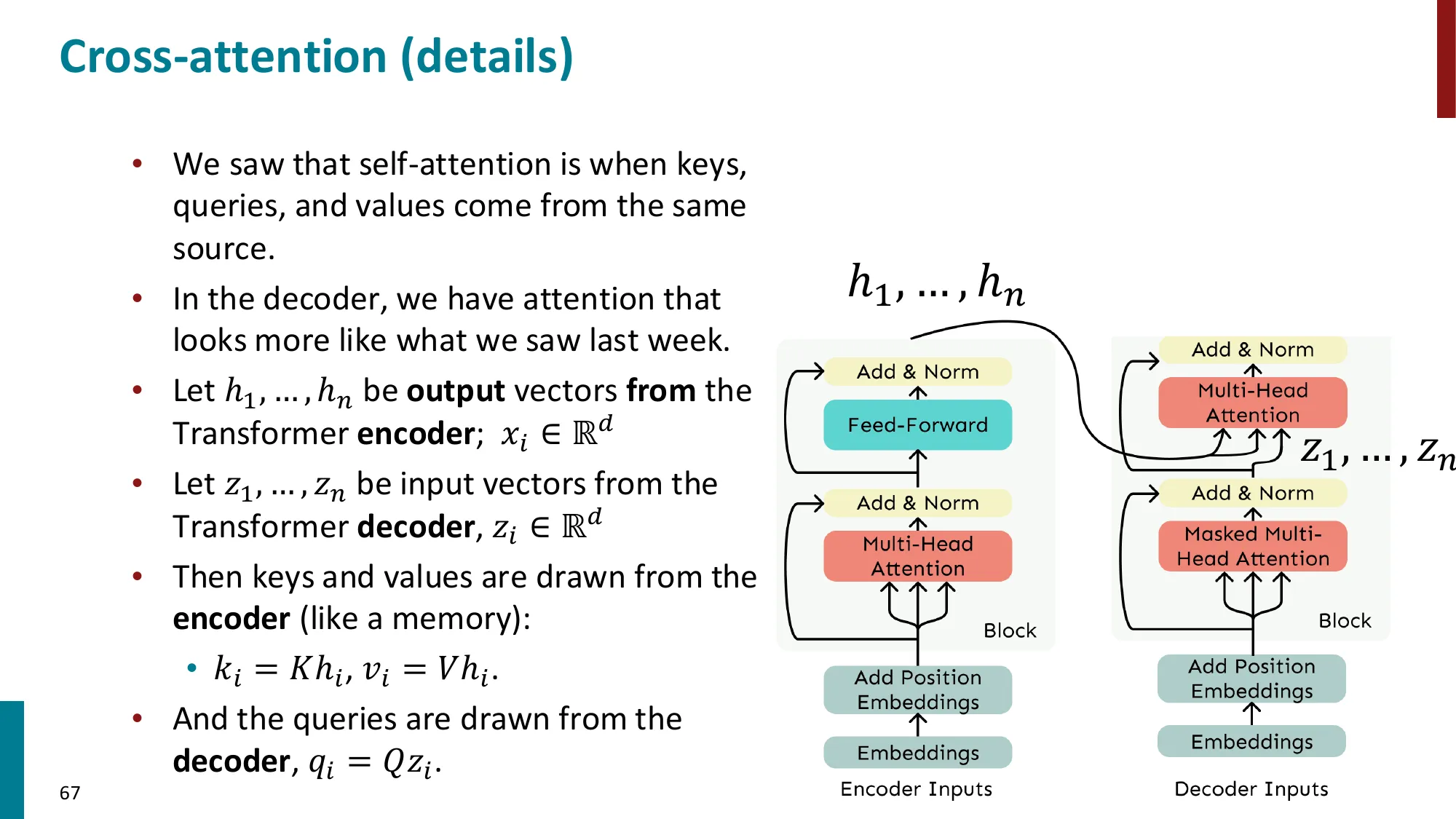
- “Attention Is All You Need” — 完全去除 RNN,只用注意力
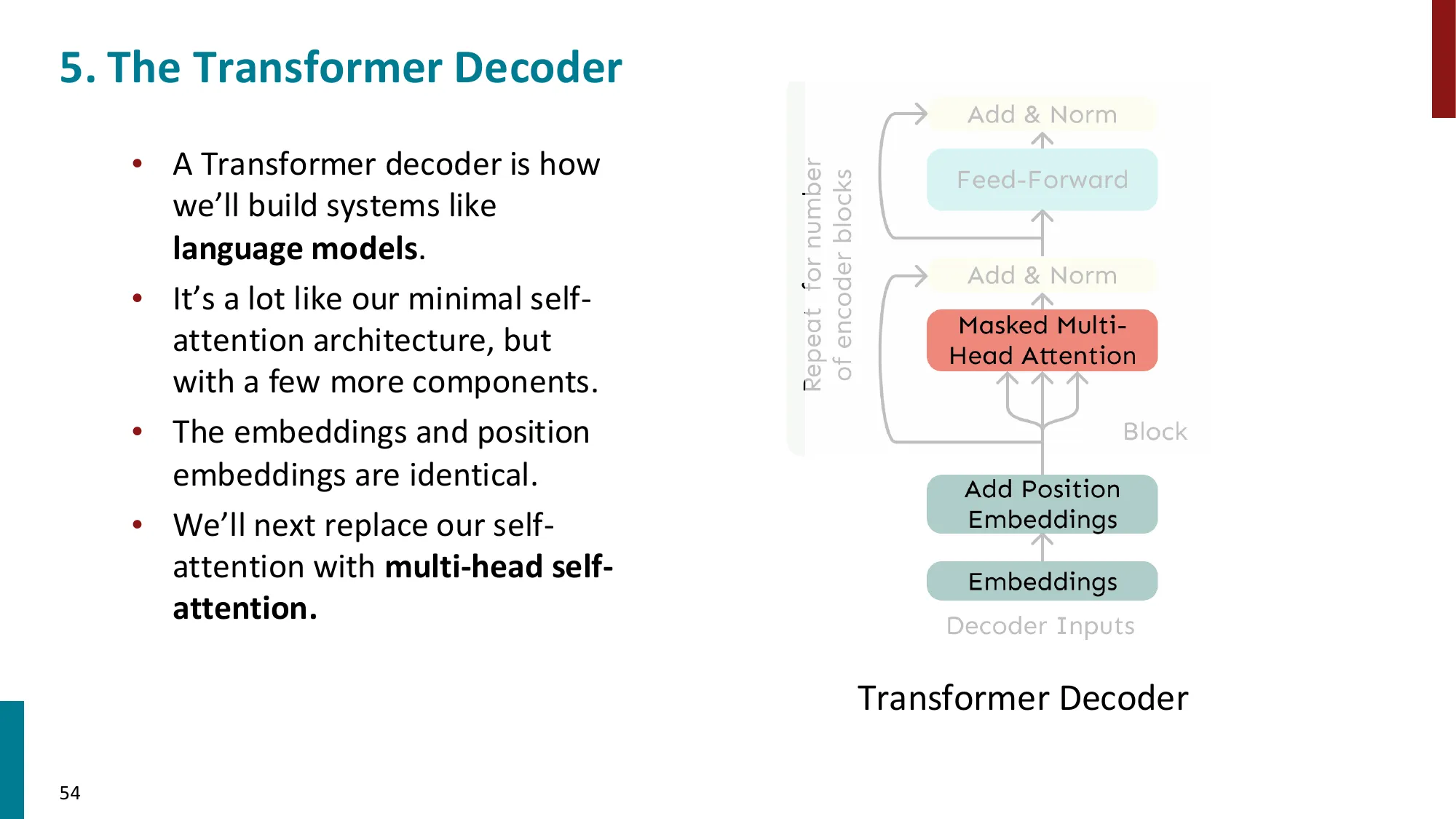
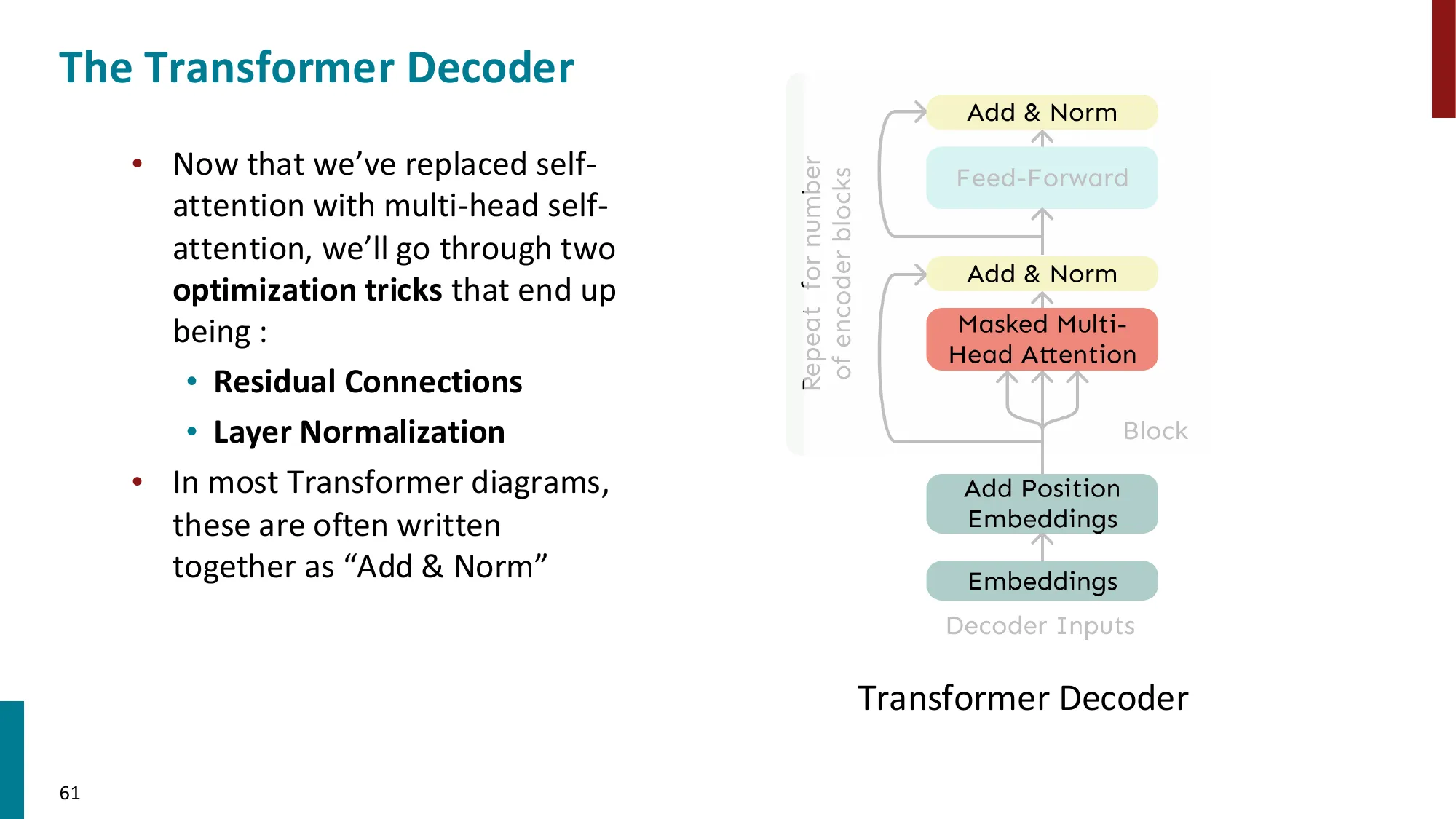
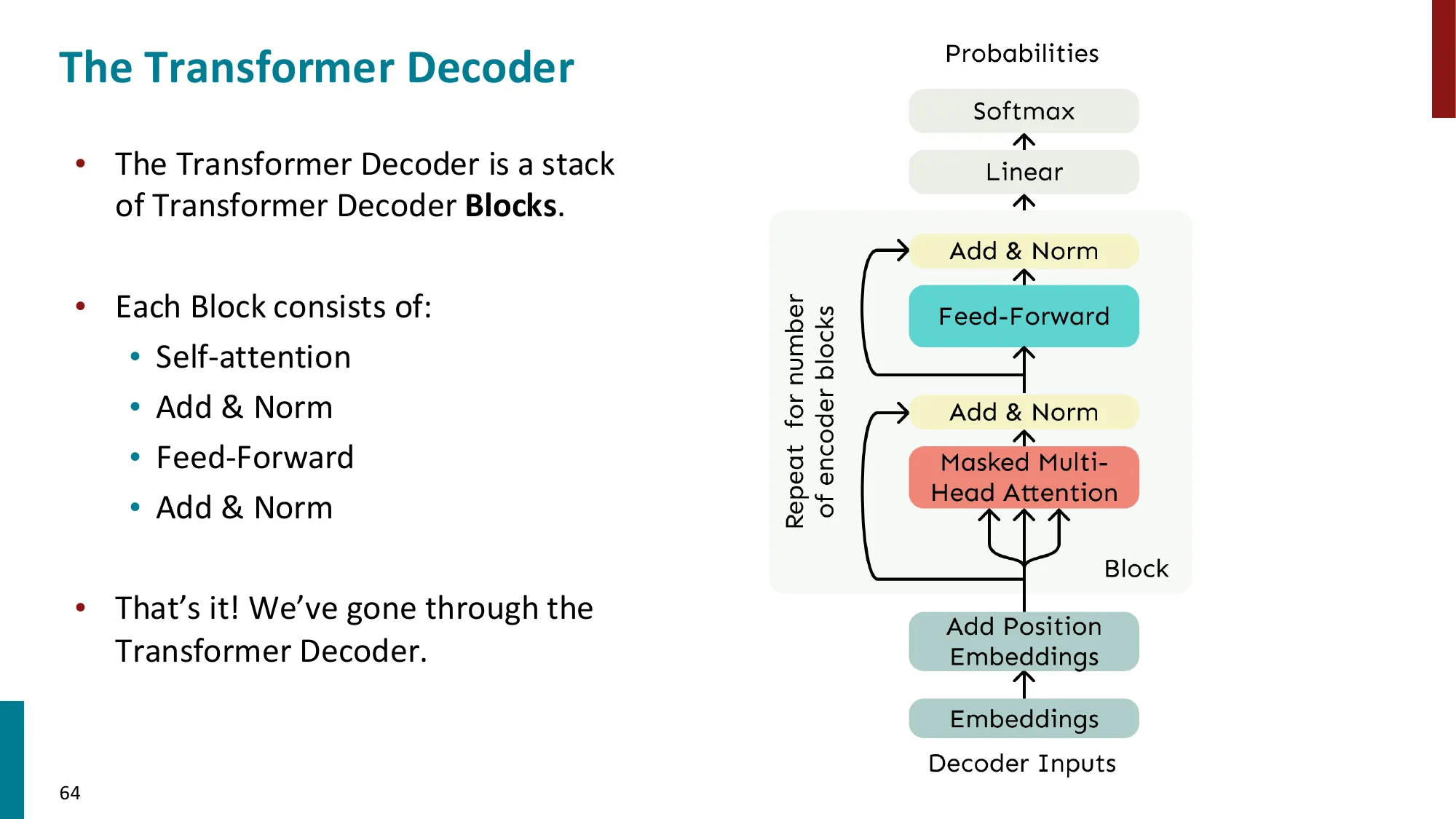
- Transformer Decoder(GPT 类):
- 每个 Block:Masked Multi-Head Self-Attention → Add & Norm → FFN → Add & Norm
- Masked:防止位置 i 看到未来位置 j>i(因果掩码)
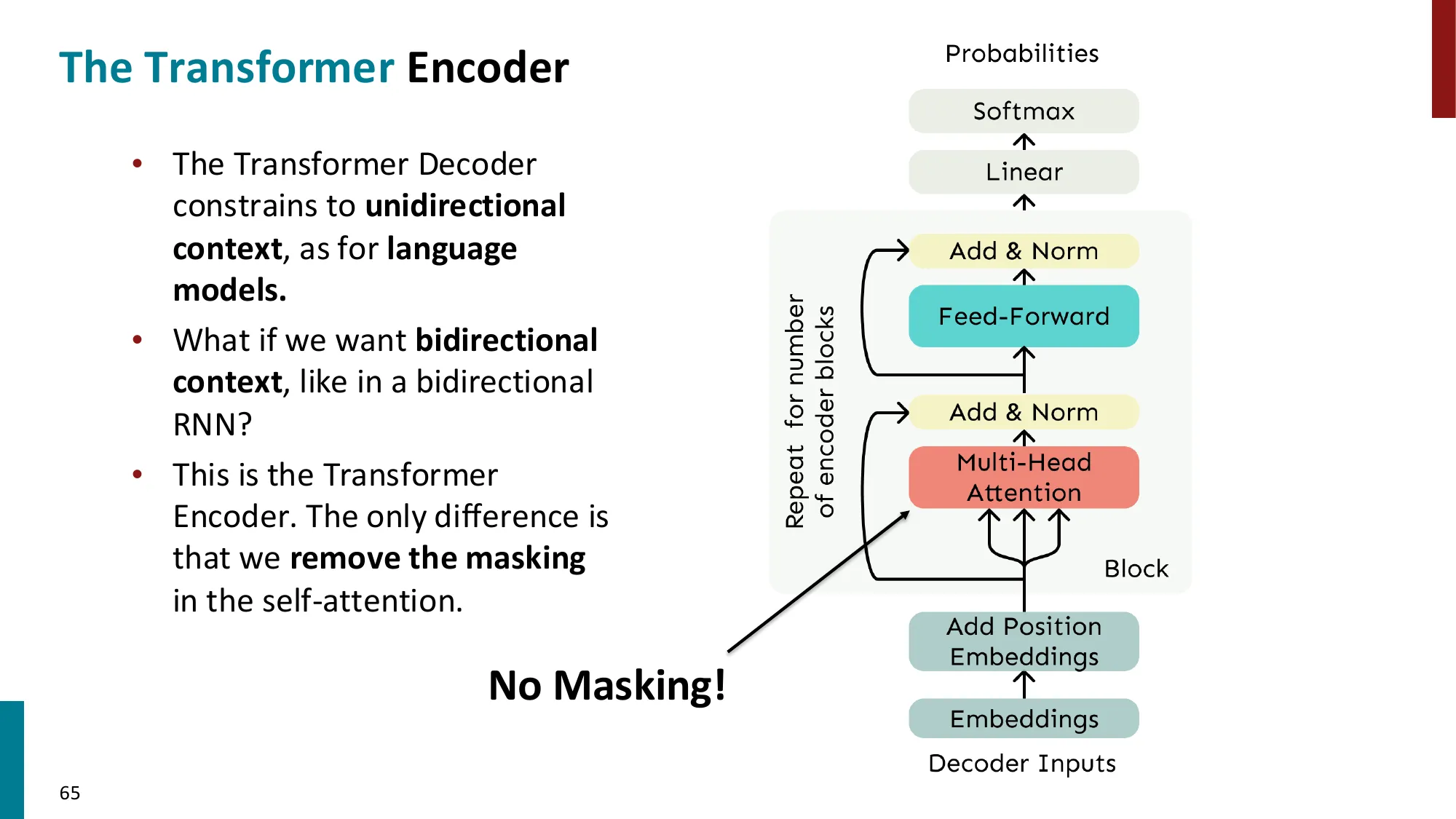
- Transformer Encoder(BERT 类):
- 与 Decoder 相同结构,但去掉 masking(双向上下文)
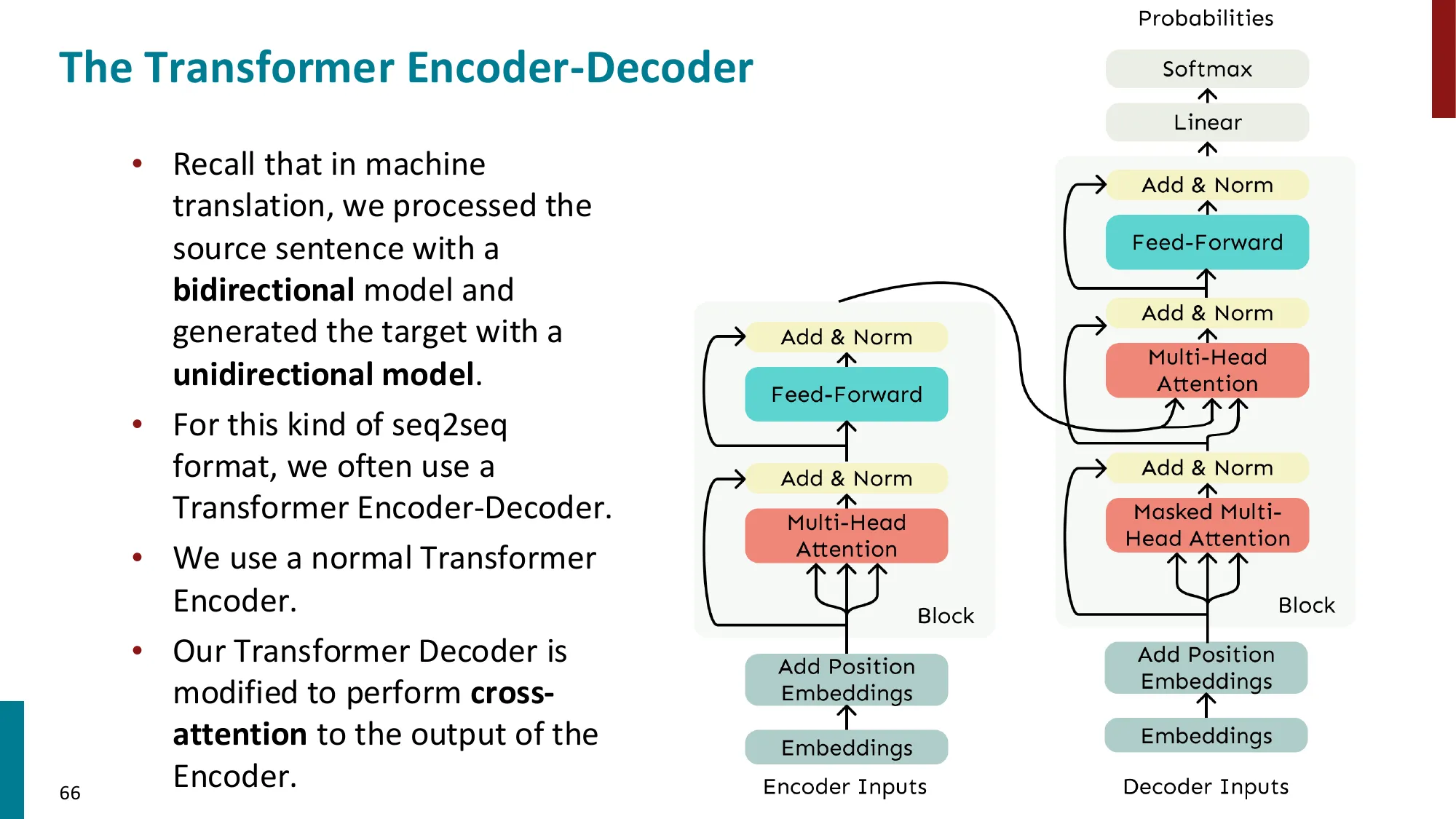
- Transformer Encoder-Decoder(T5 类):
- Encoder:双向注意力处理源序列
- Decoder:因果掩码自注意力 + 交叉注意力(Cross-Attention)
- Keys/Values 来自 Encoder 输出,Queries 来自 Decoder
- 关键组件:
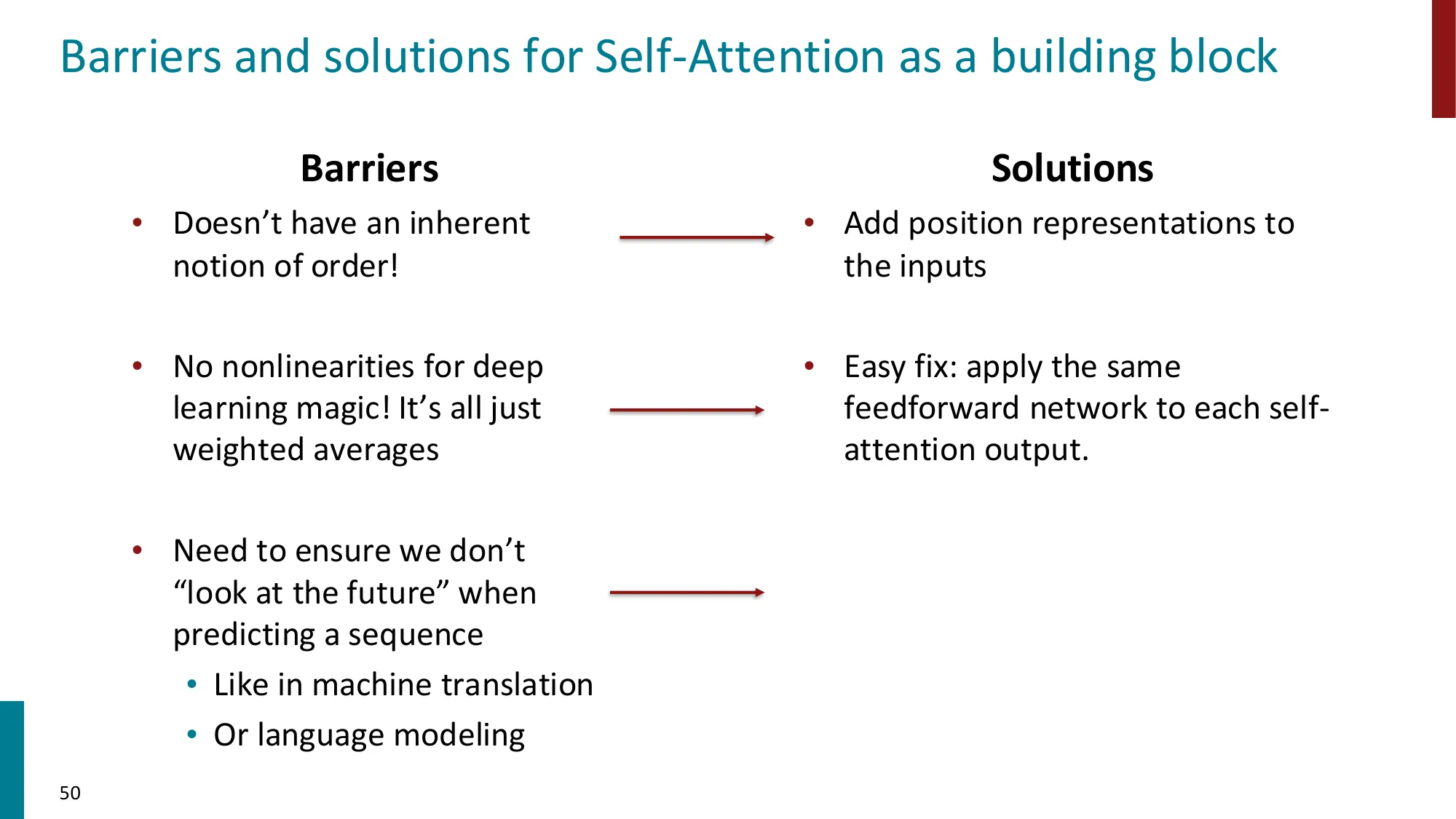
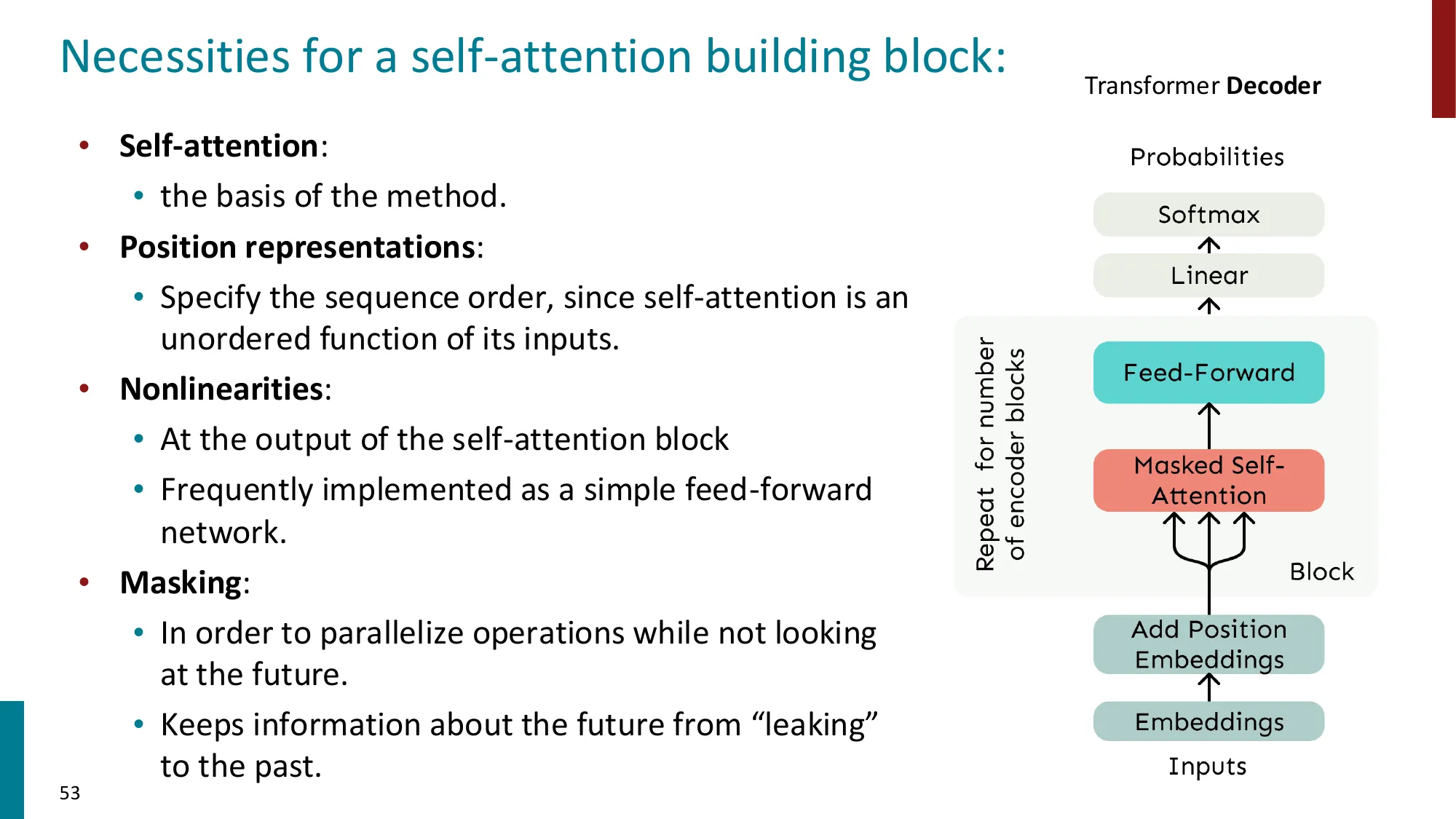
- 位置编码(Positional Encoding):自注意力本身没有位置概念,需要显式注入
- 正弦位置编码:PE(pos,2i)=sin(pos/100002i/d)
- 可学习位置嵌入(learned positional embeddings)
- RoPE(Rotary Position Embedding,Su et al., 2021)
- DeRoPE(Xiong et al., 2026)
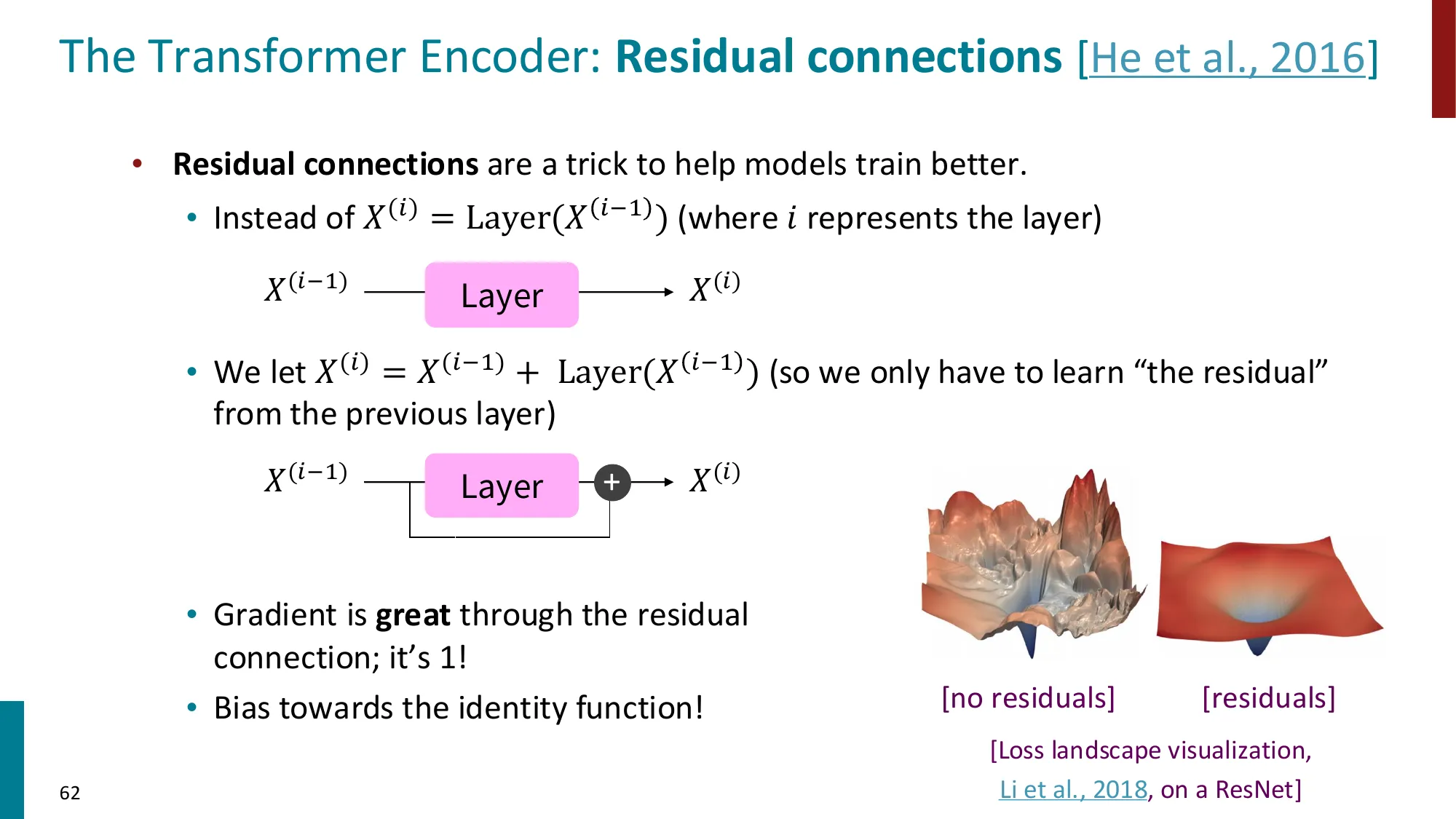
- 残差连接(Residual Connections):output=x+SubLayer(x)
- 层归一化(Layer Normalization)
- 前馈网络(FFN):FFN(x)=W2⋅ReLU(W1x+b1)+b2
一、正弦位置编码
变量定义:
- pos = 序列中位置(0,1,…,n−1)
- i = 编码向量的维度索引(0,1,…,dmodel/2−1)
- dmodel = 模型维度
公式:
PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos)
为什么用正弦/余弦?三个关键性质:
性质 1:每个位置有唯一编码——不同 pos 的编码向量两两不同。
性质 2:可以用线性变换表示相对位置偏移。用三角恒等式展开:
sin(A+B)=sinAcosB+cosAsinB
cos(A+B)=cosAcosB−sinAsinB
设 ωi=1/100002i/dmodel,则 PEpos+k 可由 PEpos 线性表示:
[PE(pos+k,2i)PE(pos+k,2i+1)]=[cos(kωi)−sin(kωi)sin(kωi)cos(kωi)][PE(pos,2i)PE(pos,2i+1)]
旋转矩阵只依赖偏移 k,不依赖绝对位置 pos——这意味着模型可以学习”相对偏移为 k 的词之间的关系”,而不受绝对位置影响。
性质 3:低频分量(大 i,小 ωi)变化慢,捕捉长距离结构;高频分量(小 i,大 ωi)变化快,捕捉局部精细位置。
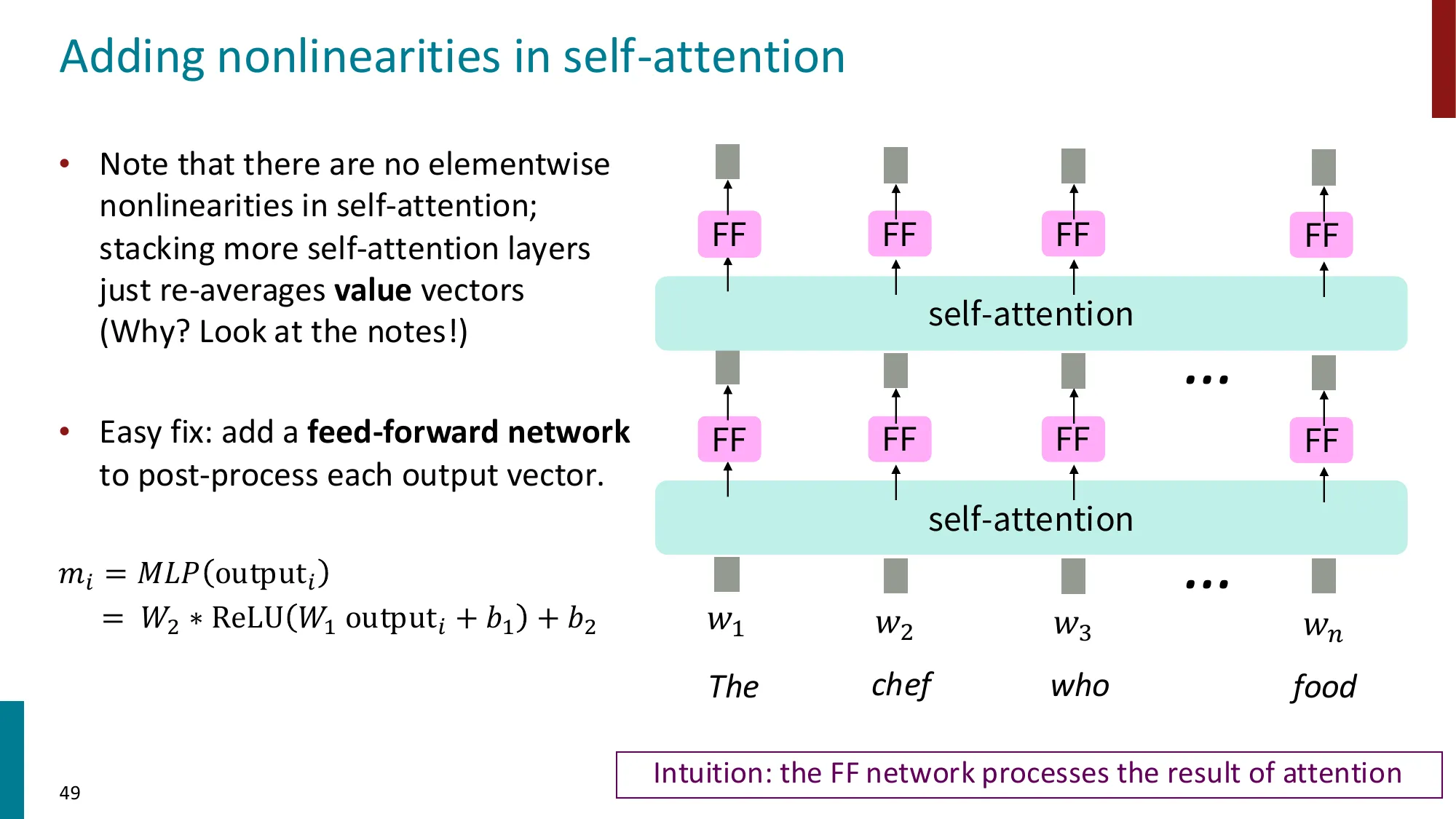
二、前馈网络(FFN)
FFN(x)=W2⋅ReLU(W1x+b1)+b2
- W1∈Rdff×dmodel,W2∈Rdmodel×dff,dff=4dmodel(先扩展 4 倍再压缩)
- 作用:在注意力聚合信息后,对每个位置独立做非线性变换
- 参数量:2×dmodel×dff=8dmodel2(约占 Transformer 总参数 2/3)
三、残差连接 + Layer Normalization(Post-LN)
output=LayerNorm(x+SubLayer(x))
残差连接的梯度传播:设 y=x+f(x),则:
∂x∂L=∂y∂L⋅∂x∂y=∂y∂L(1+∂x∂f)
梯度中有 “+1” 项,即使 ∂f/∂x 很小(子层几乎不学习),梯度仍然能通过 “+1” 路径直接传到更早的层,避免梯度消失。
Layer Normalization:
LayerNorm(x)=σ+ϵx−μ⋅γ+β
其中 μ,σ 是在特征维度上计算的(不同于 BatchNorm 在 batch 维度上计算)。
Pre-LN vs Post-LN:
- Post-LN(原始 Transformer):LayerNorm(x+SubLayer(x))
- Pre-LN(现代 LLM 标准):x+SubLayer(LayerNorm(x))
- Pre-LN 训练更稳定(梯度直接通过残差路径流动,不经过 LayerNorm),现代 LLM(GPT-2 之后)几乎全部采用 Pre-LN。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
位置编码计算:dmodel=4,计算位置 pos=0 和 pos=1 的编码向量
ωi=1/100002i/4:
- i=0:ω0=1/100000=1.000
- i=1:ω1=1/100000.5=0.01
| pos | PE(pos,0)=sin(pos⋅ω0) | PE(pos,1)=cos(pos⋅ω0) | PE(pos,2)=sin(pos⋅ω1) | PE(pos,3)=cos(pos⋅ω1) |
|---|
| 0 | sin(0)=0 | cos(0)=1 | sin(0)=0 | cos(0)=1 |
| 1 | sin(1)≈0.841 | cos(1)≈0.540 | sin(0.01)≈0.01 | cos(0.01)≈1.000 |
| 2 | sin(2)≈0.909 | cos(2)≈−0.416 | sin(0.02)≈0.02 | cos(0.02)≈1.000 |
观察:
- 高频维度(i=0):相邻位置差异大(0→0.841),分辨局部位置
- 低频维度(i=1):pos=1 和 pos=2 几乎相同(0.01≈0.02),变化极慢
FFN 数值示例:dmodel=4,dff=16,输入 x=[1,0,0,0]
- h=W1x+b1:形状 (16,),经 ReLU 后大多数为 0(稀疏激活)
- output=W2ReLU(h)+b2:形状 (4,),恢复为 dmodel 维
💡 为什么这样做?
位置编码:自注意力对输入排列不变——打乱词序后输出只是对应打乱,不改变内容。正弦编码像给每个词贴上”座位号”,让模型感知”我在第 3 位,你在第 7 位,我们相差 4 步”。
残差连接:想象学习”恒等变换”有多难——网络要学会让输出等于输入。有了残差连接,子层只需要学习”要修改的增量”(残差),默认行为是”什么都不改”(直接传递 x)。这大大降低了训练难度。
FFN 的角色:注意力负责”收集信息”(从其他位置聚合),FFN 负责”处理信息”(对收集到的信息做非线性变换)。研究表明 FFN 像”知识存储”——很多事实性知识(如”法国的首都是巴黎”)存储在 FFN 的权重中。
LayerNorm 的角色:稳定训练,防止层间激活值的均值和方差飘移。BatchNorm 对 batch 归一化在序列模型中不适用(序列长度不固定),LayerNorm 对特征维度归一化更自然。
⚠️ 常见误区
-
误区:位置编码是拼接到词嵌入上的 → 正确:是加法(input=embedding+PE),维度不变
-
误区:Pre-LN 和 Post-LN 性能相同 → 正确:Post-LN 原始论文用,但需要精细学习率调度;Pre-LN 更稳定,现代 LLM(GPT-2, LLaMA 等)全部用 Pre-LN;深层网络 Pre-LN 明显优于 Post-LN
-
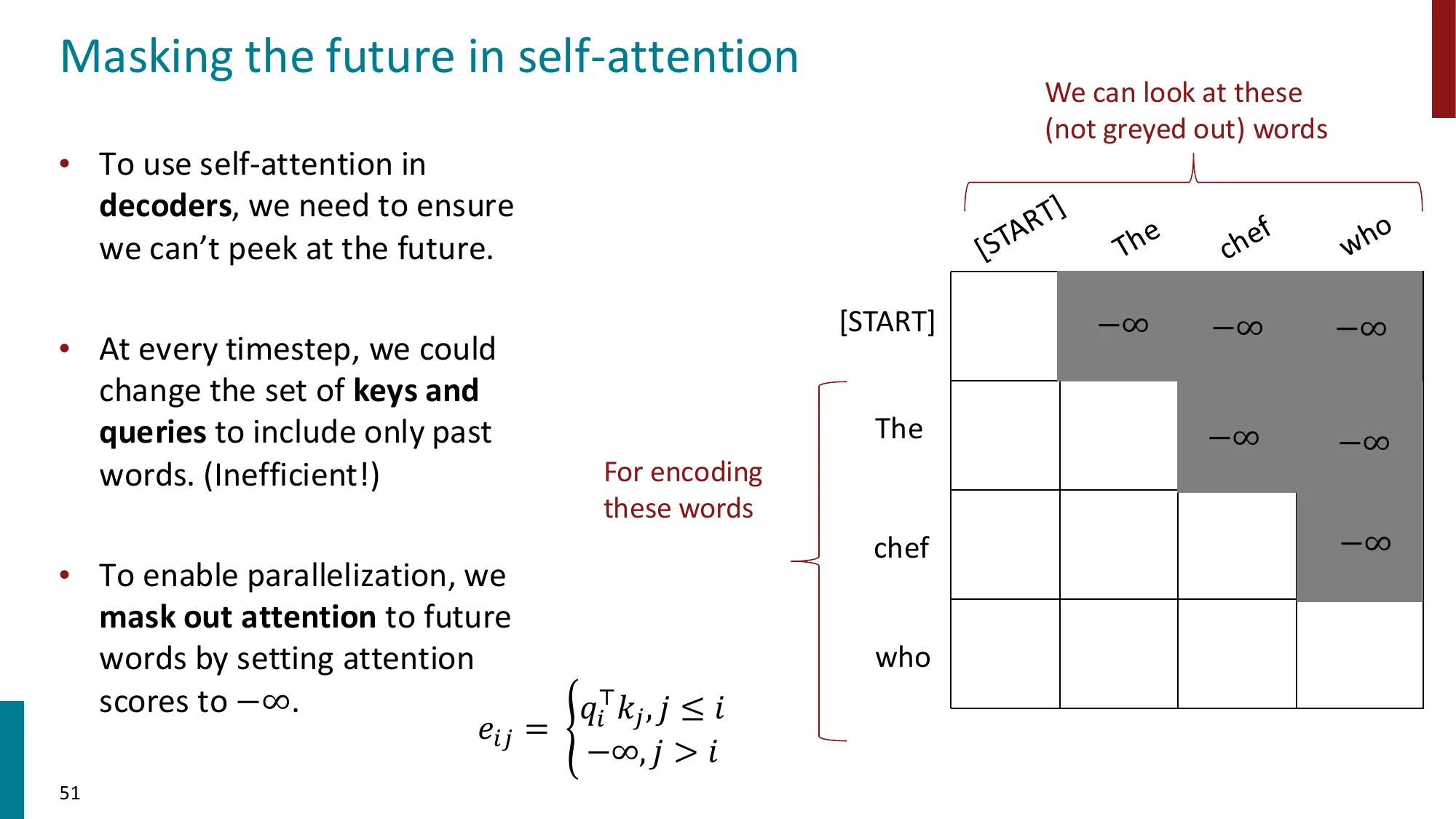
误区:Decoder 的掩码是随机 dropout → 正确:Decoder 的 Masked Self-Attention 用因果掩码(causal mask),即严格的下三角矩阵:位置 i 只能看到 j≤i 的位置,保证自回归生成时不看到”未来”
-
误区:FFN 的 dff 必须是 4dmodel → 正确:4× 是 Vaswani et al. 的选择,后来的模型有不同比例(如 LLaMA 3 用 8/3⋅dmodel,结合 SwiGLU 激活)
一、为什么会演化出三种架构?
原始 Transformer(Vaswani et al., 2017)是 Encoder-Decoder 结构,为机器翻译设计。后续研究发现,不同任务对信息流向的需求不同,于是拆分出三种变体:
| 架构 | 注意力方向 | 信息流 | 核心任务 | 代表模型 |
|---|
| Encoder-only | 双向(Bidirectional) | 每个 token 看到所有 token | 理解、分类、匹配 | BERT, RoBERTa |
| Decoder-only | 单向(Causal) | 每个 token 只看到左侧 token | 生成、续写 | GPT, LLaMA |
| Encoder-Decoder | Enc 双向 + Dec 单向 + 交叉 | 理解→生成的桥接 | 翻译、摘要、问答 | T5, BART |
二、Encoder-only(BERT 类)详解
结构:L 层堆叠,每层 = Self-Attention + FFN + 残差 + LayerNorm
注意力矩阵:无掩码,n×n 的完整矩阵
Aij=dk(xiWQ)(xjWK)T,∀i,j∈{1,…,n}
关键特性:位置 i 的表示融合了整个序列的信息,包括”未来”位置。
为什么适合理解任务? 考虑情感分析句子 “The movie was not bad at all”:
- 理解 “not bad” 需要同时看到 “not” 和 “bad”
- 双向注意力让 “bad” 能关注左边的 “not”,也能关注右边的 “at all”
- 最终
[CLS] token 聚合了全局信息,用于分类
局限:无法直接用于生成——因为训练时每个位置都能看到答案,推理时生成位置 t+1 时无法提供位置 t+1 及之后的真实 token。
三、Decoder-only(GPT 类)详解
结构:L 层堆叠,每层 = Masked Self-Attention + FFN + 残差 + LayerNorm
注意力矩阵:下三角因果掩码
Aij={dk(xiWQ)(xjWK)T−∞if j≤iif j>i
−∞ 经过 softmax 后变为 0,确保位置 i 只能关注 {1,2,…,i}。
为什么需要因果掩码? 自回归生成的核心约束:
P(x1,x2,…,xn)=∏t=1nP(xt∣x1,…,xt−1)
如果位置 t 能看到 xt+1,那模型在训练时直接”抄答案”,推理时(没有答案可抄)就完全失效。因果掩码在训练时模拟推理时的信息约束。
KV Cache 优化:推理时生成 token t,位置 1 到 t−1 的 Key/Value 已经计算过且不会改变(因为因果掩码保证它们不依赖未来 token),因此可以缓存复用,将每步复杂度从 O(t⋅d) 降为 O(d)。
四、Encoder-Decoder(T5 类)详解——两种架构如何协同
这是三种架构中最复杂也最精巧的设计。核心问题:为什么需要同时拥有 Encoder 和 Decoder?
4.1 设计动机:理解与生成是两个不同的计算过程
以机器翻译为例——将 “我爱自然语言处理” 翻译为 “I love NLP”:
-
理解阶段(Encoder 的任务):充分理解源句的每个词和整体语义。“我” 指代谁?“爱” 的对象是什么?“自然语言处理” 是一个专有名词还是三个独立词?这需要双向注意力——“处理” 要知道前面是 “自然语言”,“自然” 要知道后面是 “语言处理”。
-
生成阶段(Decoder 的任务):逐词生成目标语言。生成 “I” 后才能生成 “love”,生成 “love” 后才能生成 “NLP”。这需要因果掩码——保证自回归生成的正确性。
-
桥接阶段(Cross-Attention 的任务):生成每个目标词时,需要”回头看”源句。生成 “NLP” 时要知道它对应的是源句中的 “自然语言处理” 而不是 “我” 或 “爱”。这需要 Cross-Attention。
4.2 数据流的完整路径
设源序列 X=(x1,…,xn),目标序列 Y=(y1,…,ym)。
第 1 步:Encoder 处理源序列
H(0)=Embed(X)+PE∈Rn×d
经过 Lenc 层 Encoder Block:
H(l)=EncoderBlock(l)(H(l−1)),l=1,…,Lenc
每层内部:
H~=LayerNorm(H(l−1)+SelfAttn(H(l−1)))
H(l)=LayerNorm(H~+FFN(H~))
最终输出 H(Lenc)∈Rn×d——源序列的上下文感知表示。
第 2 步:Decoder 逐层处理目标序列
Z(0)=Embed(Y)+PE∈Rm×d
经过 Ldec 层 Decoder Block,每层包含三个子层:
子层 1:Masked Self-Attention(目标序列内部的因果注意力)
Z′=LayerNorm(Z(l−1)+MaskedSelfAttn(Z(l−1)))
子层 2:Cross-Attention(从 Encoder 输出获取源序列信息)
Z′′=LayerNorm(Z′+CrossAttn(Q=Z′,K=H(Lenc),V=H(Lenc)))
子层 3:FFN
Z(l)=LayerNorm(Z′′+FFN(Z′′))
4.3 Cross-Attention:连接理解与生成的桥梁
Cross-Attention 的数学形式:
CrossAttn(Z′,H)=softmax(dk(Z′WQcross)(HWKcross)T)(HWVcross)
关键区别:
- Self-Attention:Q, K, V 全部来自同一个序列
- Cross-Attention:Q 来自 Decoder(“我想找什么”),K 和 V 来自 Encoder(“源序列有什么”)
注意力矩阵维度:m×n(目标长度 × 源长度),无掩码——生成每个目标 token 时可以关注源序列的任意位置。
直觉:Cross-Attention 就像一个可学习的对齐模型。当 Decoder 在生成 “NLP” 时:
- Query 编码了 “在当前生成上下文中,我需要什么样的源信息”
- Key 编码了 “源序列每个位置提供什么样的信息”
- 注意力权重 αij 告诉我们:“NLP” 应该主要关注源句中的 “自然”、“语言”、“处理” 三个 token
- Value 加权求和后,Decoder 获得了精确的源端信息
4.4 为什么不能只用 Decoder?
GPT 类模型证明了 Decoder-only 也能做翻译(把源句和目标句拼接成一个序列)。但 Encoder-Decoder 有结构性优势:
-
信息利用效率:Encoder 用双向注意力理解源句,信息提取更充分。Decoder-only 模型中源句部分也受因果掩码约束,源句末尾的词看不到开头的词(除非加前缀注意力等技巧)
-
计算效率:Encoder 对源句的计算只做一次,生成每个目标 token 时复用。Decoder-only 模型在 KV Cache 下也能做到类似效果,但 Encoder 的双向注意力质量更高
-
对齐的显式建模:Cross-Attention 的 m×n 矩阵可以直接可视化为源→目标的对齐矩阵,具有很好的可解释性
🔢 Encoder-Decoder 数据流数值示例
设定:翻译 “猫 坐 了” → “cat sat”,dmodel=4
| 符号 | 含义 | 维度 |
|---|
| X | 源序列 “猫 坐 了” | (3,) |
| H | Encoder 输出 | (3,4) |
| Y | 目标序列 “cat sat” | (2,) |
| Z | Decoder 隐状态 | (2,4) |
Encoder 阶段(双向注意力,3×3 矩阵):
Self-Attention 矩阵(softmax 后):
| 猫 | 坐 | 了 |
|---|
| 猫 | 0.40 | 0.35 | 0.25 |
| 坐 | 0.30 | 0.45 | 0.25 |
| 了 | 0.20 | 0.30 | 0.50 |
每行之和 = 1。“坐” 对 “猫” 的注意力为 0.30(知道谁在坐),对 “了” 为 0.25(知道已完成)。
Decoder 阶段——生成 “sat” 时:
子层 1 — Masked Self-Attention(2×2,因果掩码):
| cat | sat |
|---|
| cat | 1.00 | 0 |
| sat | 0.45 | 0.55 |
“sat” 只能看到 “cat” 和自己,看不到更后面的 token。
子层 2 — Cross-Attention(2×3,无掩码):
| 猫 | 坐 | 了 |
|---|
| cat | 0.70 | 0.15 | 0.15 |
| sat | 0.10 | 0.65 | 0.25 |
观察:
- “cat” 强烈关注 “猫”(权重 0.70)——正确的词汇对齐
- “sat” 强烈关注 “坐”(权重 0.65),同时关注 “了”(0.25,因为 “了” 表示完成态,对应英语过去时 “sat”)
- Cross-Attention 自动学会了词汇对齐和语法特征对齐
💡 Encoder-Decoder 协同的三个类比
类比 1:同声传译
- Encoder = 听完整句话并充分理解(双向,因为已经听完了整句)
- Decoder = 一个词一个词地翻译出来(因果,因为翻译是顺序进行的)
- Cross-Attention = 翻译每个词时回忆原文的哪个部分(对齐/查询)
类比 2:开卷考试
- Encoder = 仔细阅读参考材料,标注重点(理解 + 编码)
- Decoder = 写答案(必须按顺序写,不能先写结论再补论据)
- Cross-Attention = 写每一句时翻阅参考材料的相关段落
类比 3:乐队指挥
- Encoder = 分析总谱(看到所有声部的关系)
- Decoder = 指挥演奏(按时间顺序,一拍一拍地进行)
- Cross-Attention = 每一拍看总谱对应的位置,决定哪些乐器该强调
⚠️ 三种架构的常见误区
-
误区:Encoder-Decoder 的 Decoder 和 Decoder-only 模型的 Decoder 完全一样 → 正确:Encoder-Decoder 的 Decoder 多了一个 Cross-Attention 子层。每层结构是 Masked Self-Attn → Cross-Attn → FFN(三个子层),而 Decoder-only 是 Masked Self-Attn → FFN(两个子层)
-
误区:Cross-Attention 也有因果掩码 → 正确:Cross-Attention 没有掩码。生成目标 token yt 时,可以关注源序列的所有位置 {x1,…,xn}。因果约束只在 Decoder 的 Self-Attention 中
-
误区:Encoder 和 Decoder 共享参数 → 正确:标准设计中 Encoder 和 Decoder 的参数是独立的(虽然 T5 的词嵌入层可以共享)。它们有不同的 WQ,WK,WV 矩阵
-
误区:现代 LLM 都用 Decoder-only,所以 Encoder-Decoder 过时了 → 正确:GPT-4、LLaMA 等确实是 Decoder-only,但 Encoder-Decoder 在特定任务(翻译、摘要、语音识别如 Whisper)上仍有优势。选择取决于任务性质,不是一概而论
-
误区:Encoder 的输出直接作为 Decoder 第一层的输入 → 正确:Encoder 的输出通过 Cross-Attention 的 K 和 V 注入到 Decoder 的每一层,不是作为 Decoder 的初始输入
🔗 知识关联
- 与 L06: 预训练模型 的关系:BERT(Encoder-only)、GPT(Decoder-only)、T5(Encoder-Decoder)分别代表三种预训练范式,L06 深入讨论它们的预训练目标和微调策略
- 与 Self-Attention 推导 的关系:三种架构的差异本质上是Self-Attention 矩阵的掩码策略不同
- 与 三种 Transformer 架构的注意力矩阵对比 的关系:该知识库条目从数学形式化角度对比注意力矩阵
- 历史脉络:Encoder-Decoder(2017)→ Encoder-only BERT(2018)→ Decoder-only GPT-2(2019)→ 统一框架 T5(2020)→ 大规模 Decoder-only LLM 浪潮(2022-至今)
📚 已收录至 拓展阅读知识库
📐 前馈网络(FFN)深度剖析:概念、机制与目的
一、FFN 是什么?——概念定义
FFN(Feed-Forward Network,前馈网络)是 Transformer 每一层中与 Self-Attention 并列的第二个核心子层。完整的 Transformer Block 结构为:
Block(x)=FFN(Attention(x))
FFN 是一个逐位置(position-wise) 的两层全连接网络——它对序列中的每个位置独立、平行地应用相同的变换,不同位置之间不交换信息。
变量定义:
- x∈Rdmodel = 单个位置的输入向量
- W1∈Rdff×dmodel = 第一层权重(“上投影”)
- W2∈Rdmodel×dff = 第二层权重(“下投影”)
- b1∈Rdff,b2∈Rdmodel = 偏置项
- dff = FFN 隐藏层维度(通常 dff=4⋅dmodel)
二、核心机制:升维→非线性→降维
标准 FFN(Vaswani et al., 2017):
FFN(x)=W2⋅σ(W1x+b1)+b2
其中 σ 是激活函数(原始论文用 ReLU)。展开为三步:
第 1 步:升维投影(Up-Projection)
h=W1x+b1∈Rdff
将 dmodel 维向量映射到 dff 维(dff=4dmodel),维度扩展 4 倍。
为什么要升维? 低维空间中线性不可分的特征,投影到高维后可能变得线性可分。这与核方法(kernel methods)的思想一致——通过升维获得更强的表达能力。
第 2 步:非线性激活
a=σ(h)
ReLU:σ(z)=max(0,z)。把负值归零,保留正值。
关键性质:ReLU 产生稀疏激活——实验表明,FFN 隐藏层中通常只有 ~10-30% 的神经元被激活(输出非零)。这意味着:
- 每个输入只”使用”了 FFN 容量的一小部分
- 不同输入激活不同的神经元子集 → FFN 像一个稀疏寻址的记忆库
第 3 步:降维投影(Down-Projection)
output=W2a+b2∈Rdmodel
从 dff 维压缩回 dmodel 维,恢复原始维度以传入下一层。
三、现代 FFN 变体
GLU 家族(Gated Linear Unit)——现代 LLM 的标准选择:
FFNGLU(x)=W2⋅[σ(Wgatex)⊙(Wupx)]
其中 ⊙ 是逐元素乘法(Hadamard 积),Wgate,Wup∈Rdff×dmodel。
GLU 的关键创新:引入门控机制——σ(Wgatex) 作为”门”,逐元素控制 Wupx 中哪些信息通过。
| 变体 | 激活函数 σ | 使用模型 |
|---|
| SwiGLU | SiLU(z)=z⋅sigmoid(z) | LLaMA, Mistral, Gemma |
| GeGLU | GELU(z)=z⋅Φ(z) | PaLM |
| ReGLU | ReLU(z)=max(0,z) | 部分实验模型 |
参数量对比:
- 标准 FFN:2×dmodel×dff 参数
- GLU FFN:3×dmodel×dff 参数(多了 Wgate)
- 为保持总参数量不变,LLaMA 将 dff 从 4dmodel 调整为 38dmodel≈2.67dmodel
四、FFN 的三个核心目的
目的 1:提供非线性变换能力
Self-Attention 本质上是加权平均——它是关于 Value 向量的线性组合(softmax 权重不依赖 Value 本身)。没有 FFN,堆叠再多层 Attention 仍然只是在做线性混合。
FFN 引入非线性,使得 Transformer 成为通用函数逼近器(universal approximator)。这是表达能力的根本保证。
目的 2:逐位置的信息处理(“思考”阶段)
Transformer 每层的计算可以理解为两个阶段:
- Attention = 收集:从序列中其他位置聚合相关信息(“社交”阶段)
- FFN = 处理:对聚合后的信息进行独立计算和变换(“思考”阶段)
类比:Attention 像开会讨论(收集各方意见),FFN 像会后各自回到工位做具体工作(独立处理)。
目的 3:知识存储(“事实记忆库”)
Geva et al. (2021) 的开创性研究 “Transformer Feed-Forward Layers Are Key-Value Memories” 证明:
FFN(x)=W2⋅ReLU(W1x+b1)=∑i=1dffai⋅vi
其中 ai=ReLU(kiTx+b1,i) 是第 i 个神经元的激活值,vi 是 W2 的第 i 列(输出向量)。
这可以重新解读为:
- W1 的第 i 行 ki = 键(key):定义”什么输入会激活这个神经元”
- W2 的第 i 列 vi = 值(value):定义”激活后输出什么信息”
- FFN 整体 = 键值记忆(key-value memory),激活模式决定检索哪些记忆
实验证据:
- 编辑 FFN 中特定神经元的权重可以修改模型的事实性知识(如把”埃菲尔铁塔在巴黎”改为”在伦敦”)
- 这是 知识编辑(knowledge editing) 和 模型可解释性 的理论基础
- Meng et al. (2022) 的 ROME 方法正是基于此原理定位和编辑 FFN 中的事实记忆
五、FFN 的参数量与计算量分析
对于 dmodel=4096(LLaMA-7B 量级):
| 指标 | 标准 FFN (dff=4d) | SwiGLU FFN (dff=38d) |
|---|
| dff | 16,384 | 10,923 |
| 参数量/层 | 2×4096×16384=134M | 3×4096×10923=134M |
| FLOPs/token/层 | 2×134M=268M | 2×134M=268M |
| 占 Block 参数比例 | ~67% | ~67% |
FFN 占 Transformer 总参数的约 2/3,Self-Attention 只占约 1/3。这反映了 FFN 作为”知识存储”的核心角色——大部分参数用于记忆知识,而不是计算注意力。
📚 已收录至 拓展阅读知识库
🔢 FFN 完整数值计算示例
设定:dmodel=3,dff=6(2 倍扩展,便于手算)
输入向量(某个位置经过 Self-Attention 后的表示):
x=0.5−0.30.8
权重矩阵(简化示意):
W1=1.0−0.50.00.5−1.00.00.01.0−0.50.50.01.0−0.50.01.00.51.0−1.0,b1=000000
第 1 步:升维投影 h=W1x
h=1.0(0.5)+0.0(−0.3)+(−0.5)(0.8)(−0.5)(0.5)+1.0(−0.3)+0.0(0.8)0.0(0.5)+(−0.5)(−0.3)+1.0(0.8)0.5(0.5)+0.5(−0.3)+0.5(0.8)(−1.0)(0.5)+0.0(−0.3)+1.0(0.8)0.0(0.5)+1.0(−0.3)+(−1.0)(0.8)=0.10−0.550.950.500.30−1.10
第 2 步:ReLU 激活 a=ReLU(h)
a=max(0,0.10)max(0,−0.55)max(0,0.95)max(0,0.50)max(0,0.30)max(0,−1.10)=0.1000.950.500.300
稀疏激活:6 个神经元中只有 4 个被激活(67%),神经元 2 和 6 被”关闭”。
第 3 步:降维投影 output=W2a(假设 W2 是 3×6 矩阵)
W2=0.5−0.10.200.30−0.30.60.10.2−0.20.50.40.1−0.3000
由于 a2=a6=0,对应列不参与计算(零乘以任何数为零):
output=0.10⋅0.5−0.10.2+0.95⋅−0.30.60.1+0.50⋅0.2−0.20.5+0.30⋅0.40.1−0.3
=0.05−0.285+0.10+0.12−0.01+0.57−0.10+0.030.02+0.095+0.25−0.09=−0.020.490.28
观察:
- 稀疏激活验证:W2 中第 2、6 列虽然存在,但因为对应神经元未激活而完全不参与——这就是”不同输入使用不同神经元子集”的直观体现
- Key-Value Memory 解读:W1 的第 3 行 [0,−0.5,1.0] 是”键”,它对 x 中第 3 维大(第 2 维小)的输入响应强烈(0.95);W2 的第 3 列 [−0.3,0.6,0.1]T 是对应的”值”,贡献了输出中最大的分量
- 维度变化:R3W1R6ReLUR6W2R3,升维→非线性→降维
💡 FFN 为什么不可或缺?
如果没有 FFN 会怎样?
假设 Transformer 只有 Self-Attention + 残差 + LayerNorm,没有 FFN:
yi=LayerNorm(xi+∑jαijVxj)
这本质上是输入向量的加权平均(加上残差和归一化)。无论堆叠多少层,每层做的都是”重新混合序列中各位置的信息”,但不改变信息本身的表示。
类比:一群人在会议室里反复讨论(Attention),但从来不回到工位做实际计算(FFN)。讨论再多轮,也不会产生新信息。
FFN 引入的两个关键能力:
-
非线性变换:ReLU/SwiGLU 让 Transformer 能学习复杂的非线性映射。没有非线性,多层 Transformer 等价于单层线性变换(线性变换的组合仍是线性变换)。
-
逐位置独立计算:每个 token 的表示经过相同但独立的 FFN 处理。这类似于:Attention 决定了”收集什么信息”,FFN 决定了”如何处理收集到的信息”。
FFN 是”知识”还是”计算”?
两者兼有,但层数不同侧重不同:
- 底层 FFN:更多承担通用的特征变换(语法、词形变化等模式)
- 高层 FFN:更多存储事实性知识(“巴黎是法国首都”)和任务相关的决策逻辑
这也解释了为什么知识编辑(如 ROME)主要针对中高层的 FFN——底层存储的是通用语言模式,不容易对应到单个事实。
⚠️ FFN 常见误区
-
误区:FFN 是”全连接层”,所以序列中所有位置会互相影响 → 正确:FFN 是 position-wise 的,每个位置完全独立地通过同一个 FFN。位置间的信息交换只在 Self-Attention 中发生。“全连接”指的是维度间全连接(dmodel→dff),不是位置间全连接
-
误区:FFN 只是简单的”投影层”,不重要 → 正确:FFN 占 Transformer 约 2/3 的参数,是模型容量的主要来源。删除 FFN 会导致性能灾难性下降。现代研究认为 FFN 是知识记忆的核心载体
-
误区:FFN 的 dff=4dmodel 是通过理论推导得出的 → 正确:这是 Vaswani et al. 的经验选择。后续研究尝试了不同比例:LLaMA 用 8/3(配合 SwiGLU),Mixture of Experts(MoE)模型可以用更大的 dff 但只稀疏激活一部分
-
误区:SwiGLU 和 ReLU 只是”换了个激活函数”,效果差不多 → 正确:SwiGLU 引入了门控机制(额外的 Wgate 矩阵),这不仅是激活函数的变化,更是架构的变化——多了 50% 的参数(需要调整 dff 补偿)。SwiGLU 在实际表现中一致优于 ReLU/GELU
-
误区:FFN 中每个神经元独立工作,互不关联 → 正确:虽然 ReLU 让激活是稀疏的,但 W2 的降维投影将所有激活神经元的输出混合。最终输出是所有活跃神经元”投票”的结果,不是单个神经元决定的
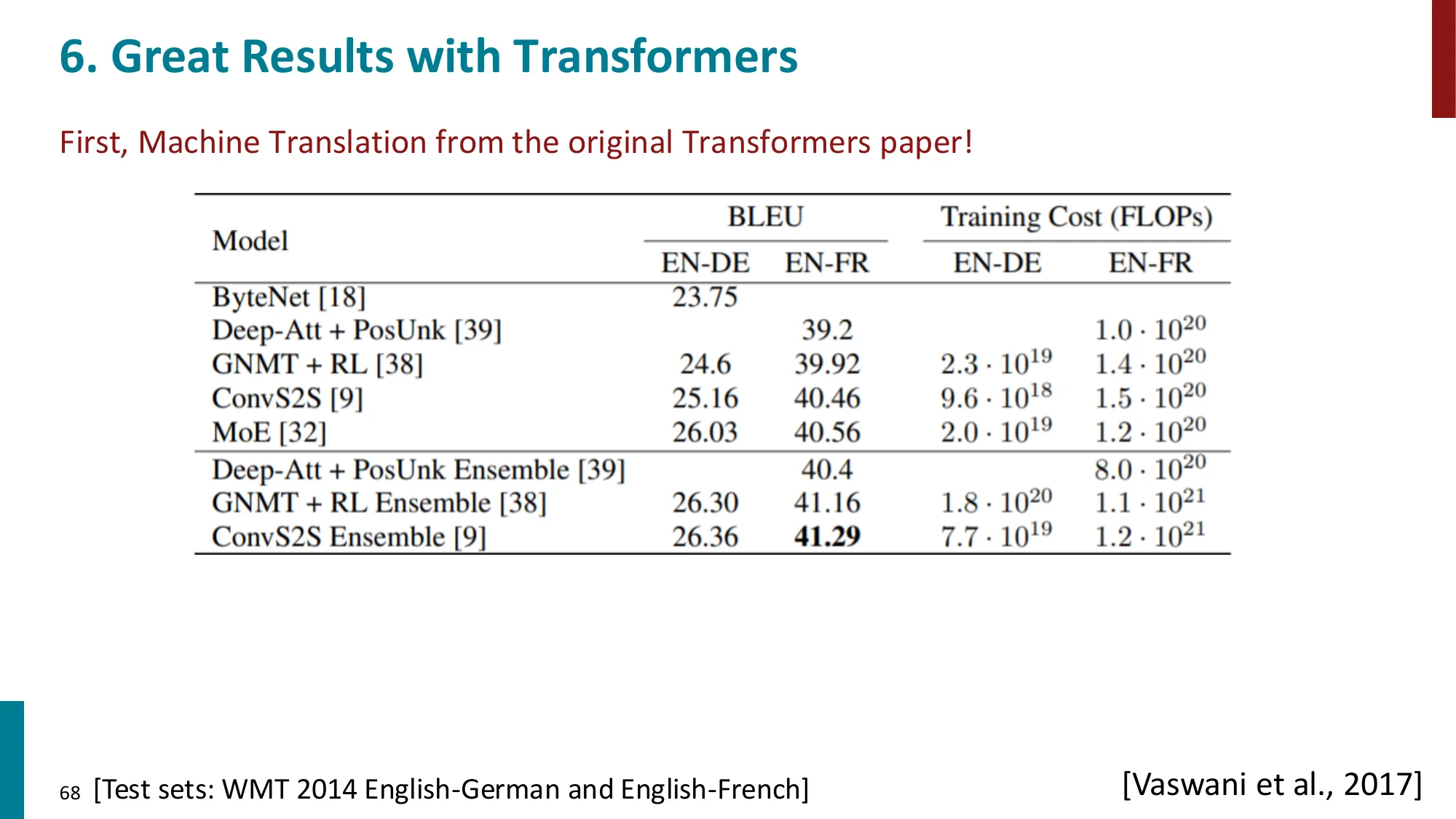
- 优势:MT 上 SOTA(WMT 2014 EN-DE 28.4 BLEU),文档生成也显著提升
- 待改进:
- 自注意力的二次计算复杂度 O(n2):长序列(n≥50000)仍是挑战
- 位置表示:绝对位置 vs 相对位置 vs 旋转位置嵌入
- 实践中,大型 Transformer LM 几乎都沿用标准二次注意力(更便宜的替代方案在规模化后效果不佳)
推荐阅读
关联概念
个人笔记