L11: Evaluation
Week 6 · Tue Feb 10 2026 08:00:00 GMT+0800 (中国标准时间)
L11: Evaluation
- Project proposal due
- Lecturer: Yejin Choi
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
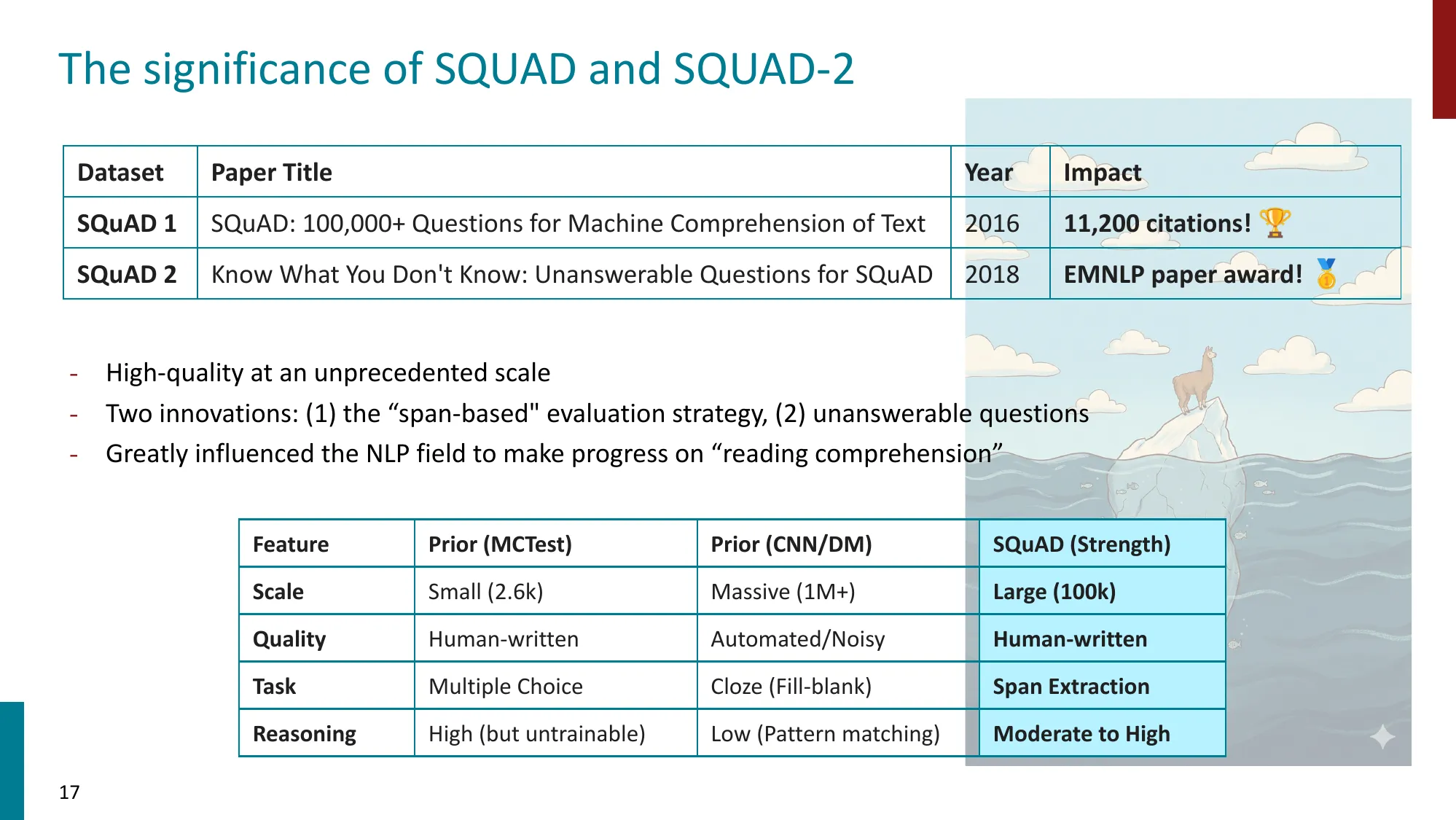
1. LLM 基准测试的近况(SAGA)




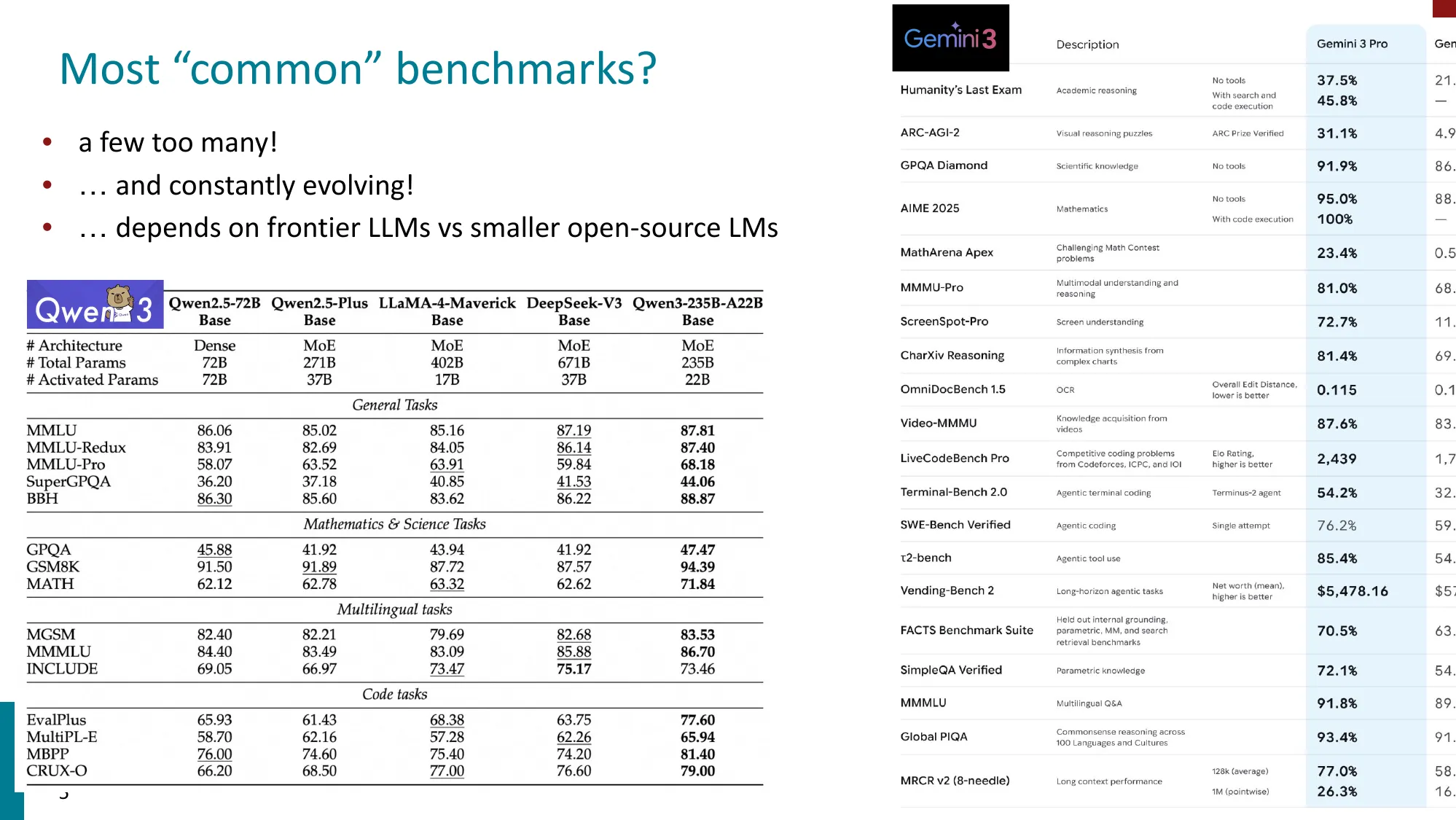
- 基准测试爆炸式增长 & 生命周期不断缩短
- 人类不再是性能天花板(MMLU、GPQA 等已被超越)
- 常用基准数量太多且持续演变;前沿模型 vs 开源小模型关注不同基准
💡 为什么基准测试”越来越不够用”?
基准测试的生命周期:设计 → 发布 → 被刷榜 → 饱和 → 被新基准替代。
2018 年 GLUE 被认为很难,2019 年 BERT 超过人类基线,SuperGLUE 随即推出。2021 年 MMLU 被认为需要专家级知识,2024 年多个模型超过 90%。这种”军备竞赛”的根本问题是:我们在衡量什么?——基准饱和不代表模型真正”理解”了语言,可能只是学会了特定题型的模式。
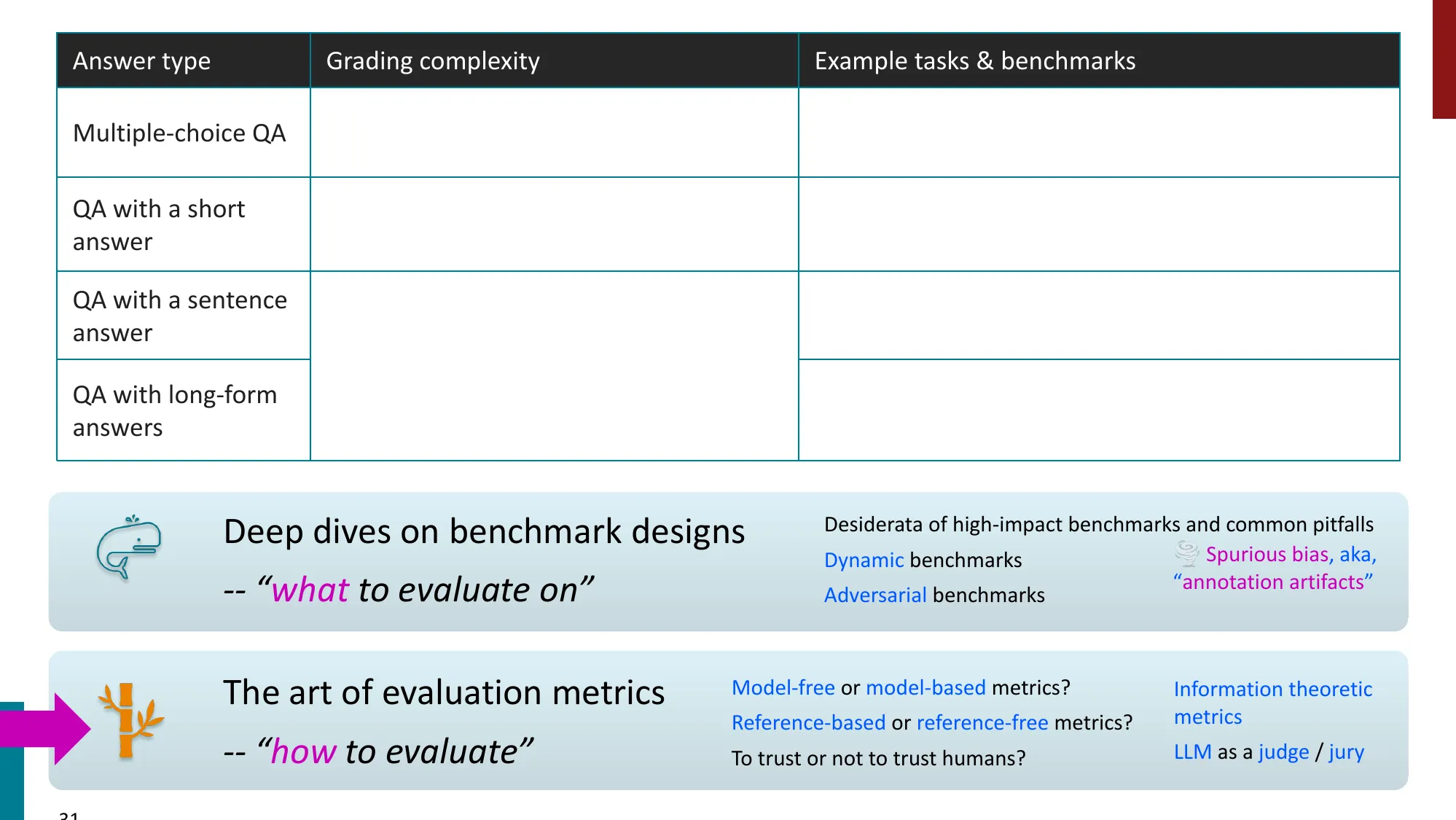
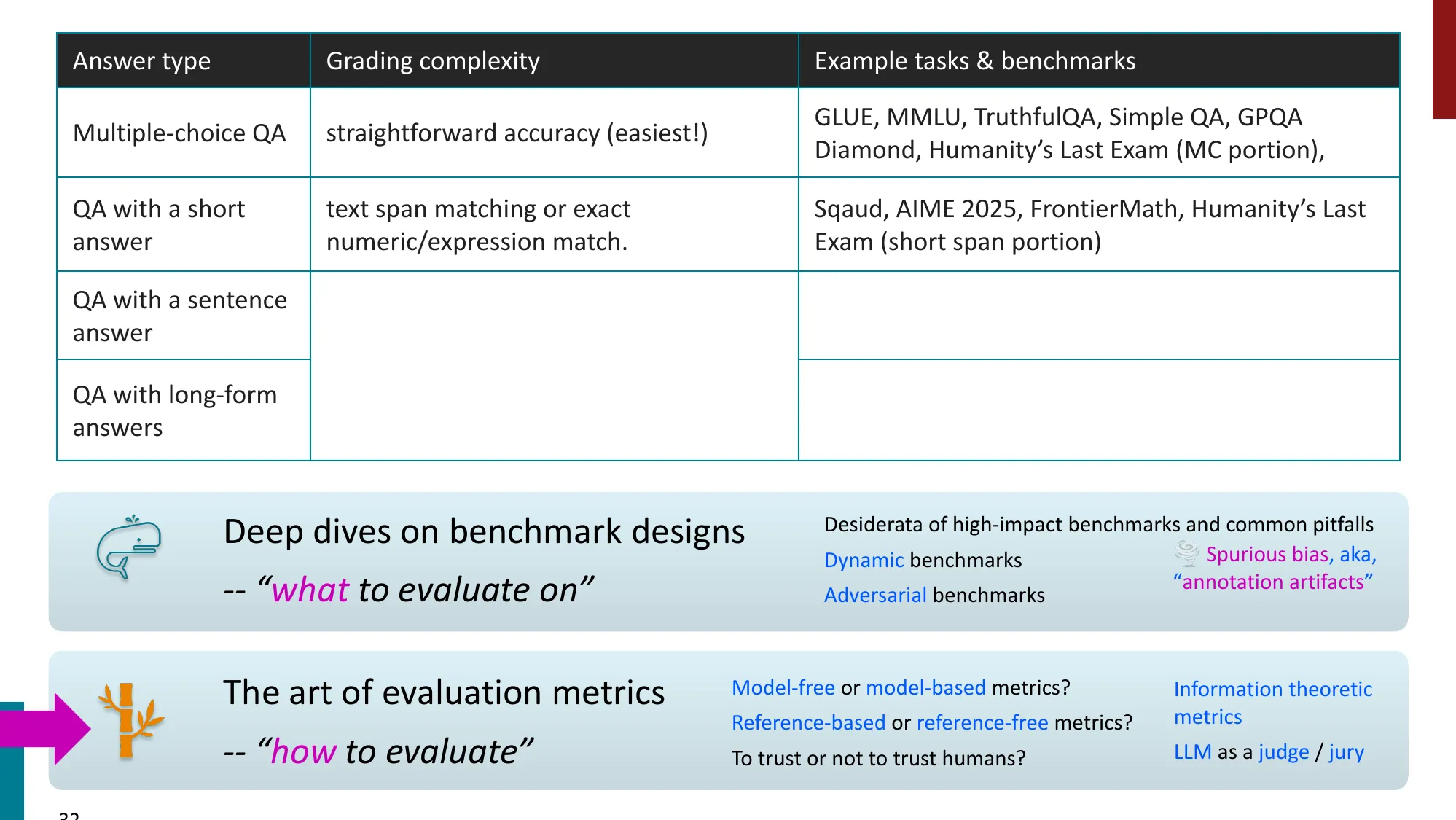
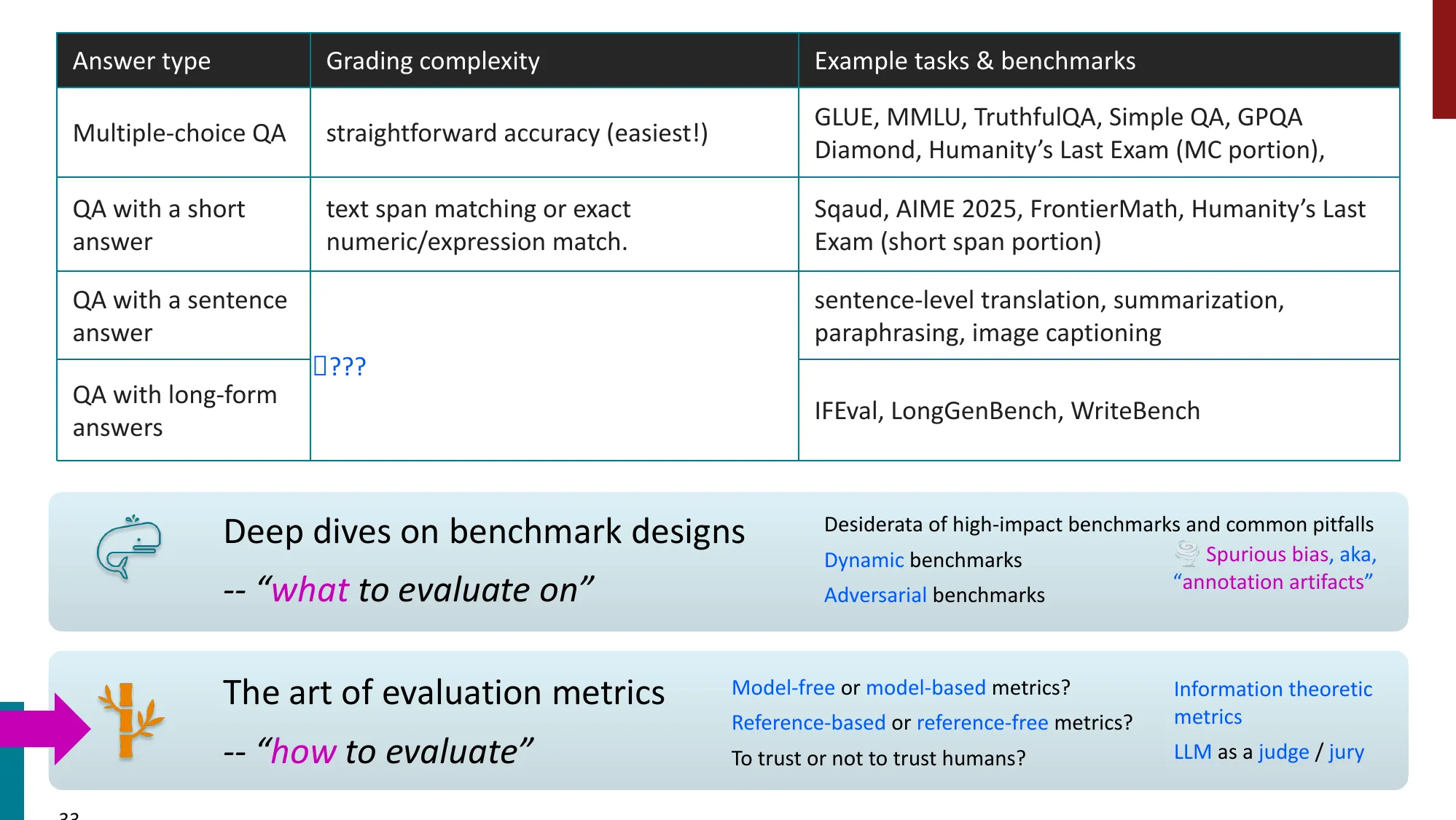
2. 多任务基准(Multi-Task Benchmarks)


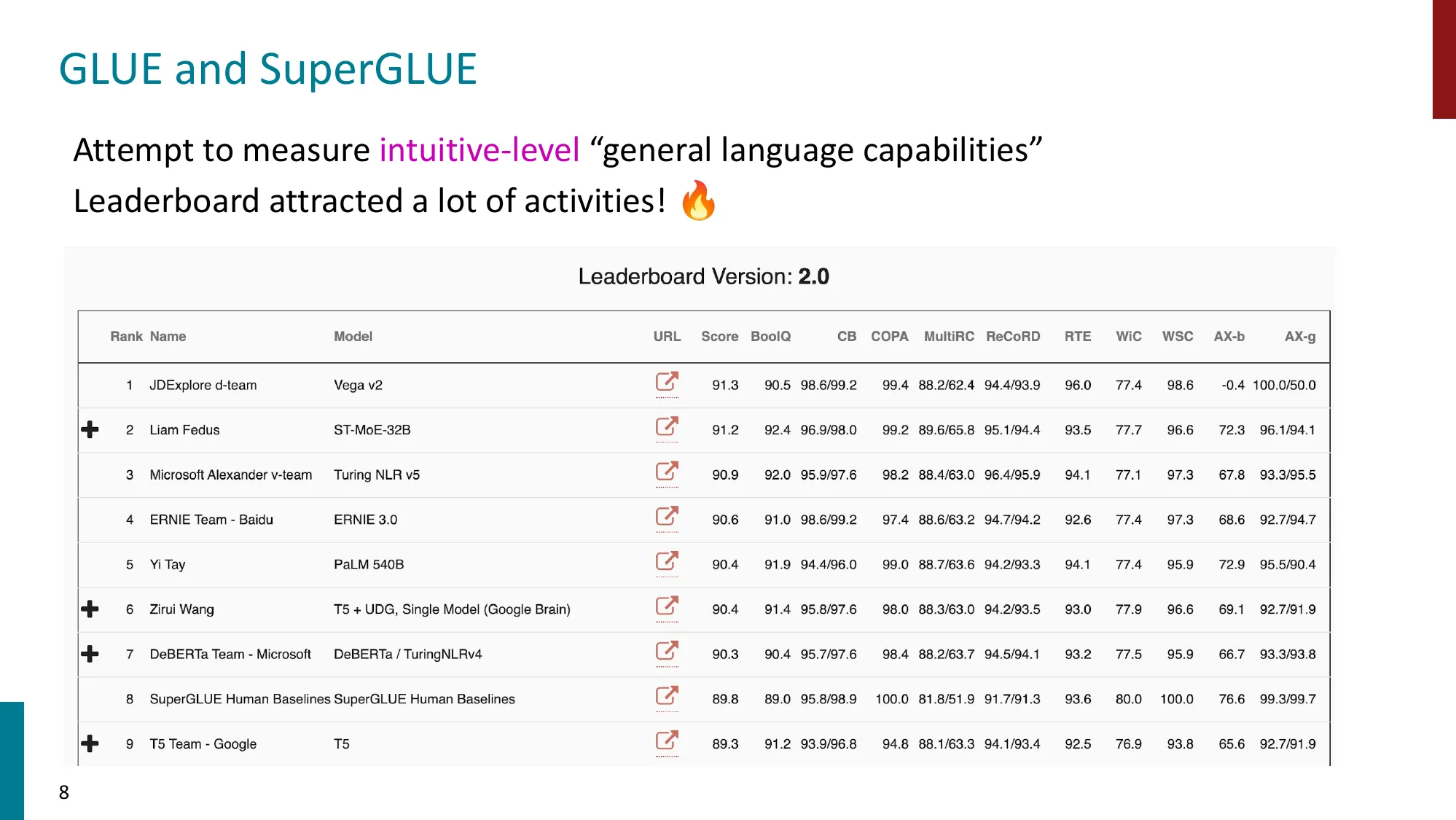



- GLUE / SuperGLUE:衡量 intuitive-level NLU 能力
- SuperGLUE 包含 BoolQ、MultiRC、CB、RTE、COPA、ReCoRD、WiC、WSC
- 排行榜驱动了大量研究活动
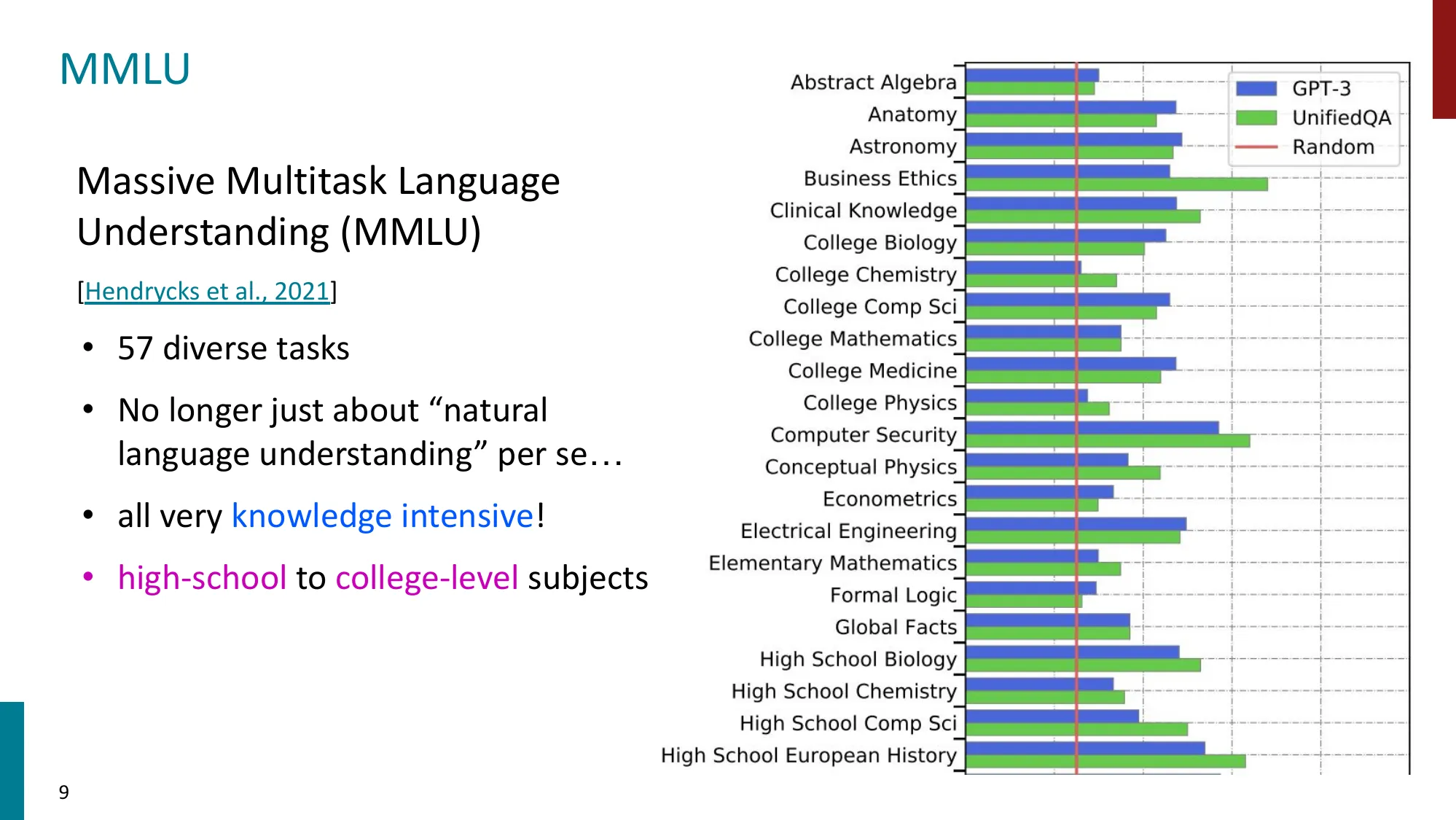
- MMLU-Paper(Hendrycks et al., 2021)
- 57 个知识密集型任务(高中到大学水平)
- 最常用的 LLM 评估基准之一
- 当前 SOTA 已超 93%(Gemini 3 Pro Preview)
- MMLU-Pro 更难
- GPQA:研究生级别的 Google-proof Q&A
- 发布时看似太难(GPT-4: 38.8%),一年后 O1 达 78.3%
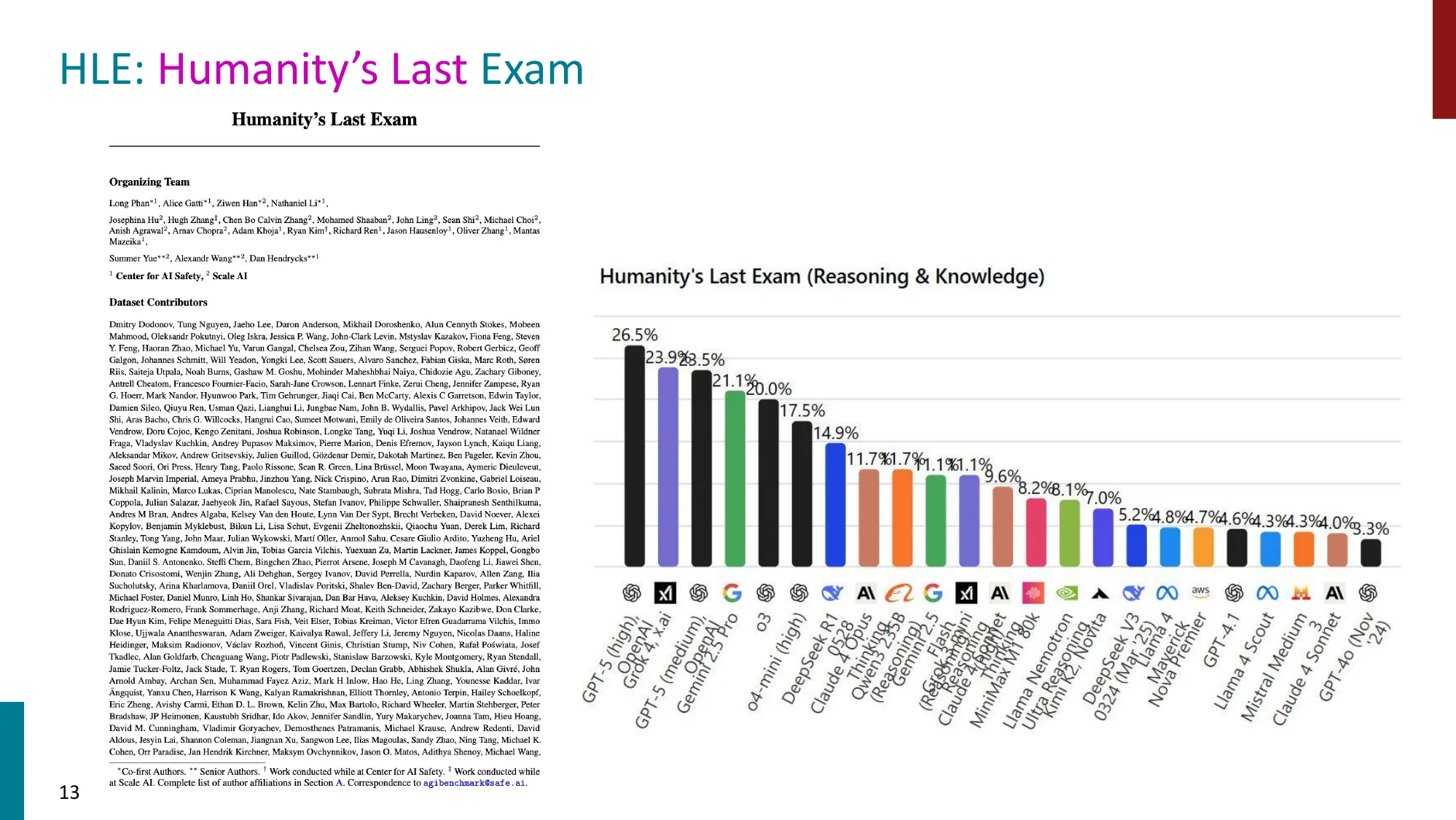
- Humanity’s Last Exam (HLE):最前沿模型仍然困难(最高 ~26%)
📐 MMLU 的评估协议
MMLU 格式:57 个学科的多选题(4 选 1),few-shot 评估。
标准评估方式(log-likelihood scoring):
不是让模型生成文本,而是比较四个选项 token 的对数概率。
MMLU 准确率:
MMLU-Pro 的改进:
- 10 个选项(vs MMLU 的 4 个)→ 随机猜测准确率从 25% 降到 10%
- 更多推理题,更少知识检索题
- Chain-of-Thought 提升显著(+15%),说明题目确实需要推理
GPQA 的”Google-proof”设计:
非专家花 30 分钟搜索后仍只有 34% 准确率,专家在本领域达 65%。这确保了:(1)答案不在互联网上直接可搜到 (2)需要真正的专业知识。
📚 已收录至 拓展阅读知识库
🔢 基准饱和速度的具体数字
| 基准 | 发布年 | 发布时 SOTA | 人类水平 | 当前 SOTA (2026) | 饱和时间 |
|---|---|---|---|---|---|
| GLUE | 2018 | 69.0 | 87.1 | 90.8 (T5) | ~1 年 |
| SuperGLUE | 2019 | 71.5 | 89.8 | 90.4 (T5) | ~1.5 年 |
| MMLU | 2021 | 43.9 (GPT-3) | ~89.8 | 93.2 (Gemini 3) | ~3 年 |
| GPQA | 2023 | 38.8 (GPT-4) | 65.0 | 78.3 (O1) | ~1 年 |
| HLE | 2025 | ~8% | ? | ~26% | 未饱和 |
趋势:基准饱和速度越来越快。HLE 尝试通过征集研究生级别的原创题目来延缓这一趋势。
3. 基准设计的原则(Desiderata)




- 规模与多样性:覆盖目标现象,样本量充足
- 难度:对人类易、对模型难
- 质量:答案正确 + 无虚假偏差(spurious bias / annotation artifacts)
⚠️ 常见误区
-
误区:样本量越大基准越好 → 正确:大样本量无法弥补系统性偏差。如果标注者群体单一(如全部来自美国 MTurk 工人),即使 10 万条样本,也只是放大了同一种文化偏见。
-
误区:对人类”容易”的任务不值得作为基准 → 正确:好的基准应该”对人类容易、对模型难”——这样模型达到人类水平才有意义。如果人类也做不好(如 HLE),我们就无法区分”模型不够好”和”题目本身不合理”。
4. 虚假偏差(Spurious Bias)
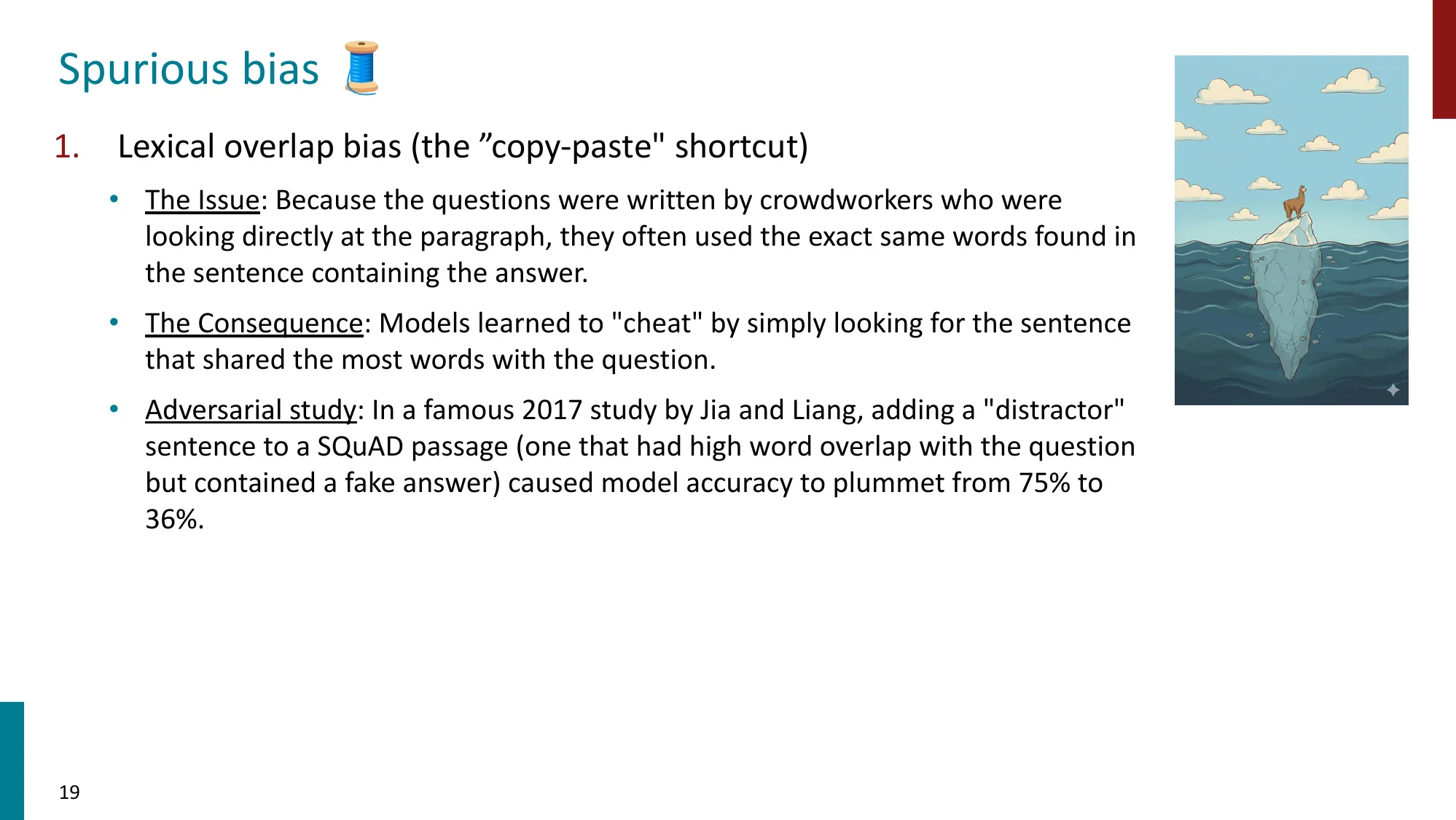




- 词汇重叠偏差:标注者直接从段落复制词汇,模型学会走捷径(SQuAD 对抗攻击:75% -> 36%)
- 位置偏差:Wikipedia 段落中重要信息集中在开头
- SQuAD 1 & 2 的意义:首创 span-based evaluation + unanswerable questions
📐 SQuAD 的 Span-based 评估指标
SQuAD 任务:给定段落 和问题 ,预测答案 span (起始和结束位置)。
Exact Match (EM):
预测 span 与标注完全一致才算正确(归一化后比较:去标点、小写化)。
Token-level F1:
允许部分匹配——比 EM 更宽容。
对抗攻击(Jia & Liang 2017)的揭示:
在段落末尾插入一句与问题词汇高度重叠但语义无关的干扰句:
- 原问题:“What city did the Super Bowl take place in?” → 模型正确回答:“Santa Clara”
- 加干扰句:“Jeff Dean played in the Super Bowl in Houston.” → 模型错误回答:“Houston”
模型依赖词汇重叠而非真正理解,EM 从 75% 暴跌到 36%。
📚 已收录至 拓展阅读知识库
🔢 Annotation Artifacts 的量化示例
NLI 任务中的标注偏差(Gururangan et al. 2018):
只看假设句(不看前提句!),分类器就能达到 67% 准确率(随机猜测 33%):
| 假设句特征 | 倾向标签 | 原因 |
|---|---|---|
| 含”not”/“never” | Contradiction | 标注者通过否定来制造矛盾 |
| 含”some”/“sometimes” | Neutral | 模糊限定词 → 不确定 → 中性 |
| 句子更长 | Entailment | 蕴含需要更多解释 |
这意味着模型可能在”做 NLI”时根本没有进行推理,而是在做关键词分类。
5. 动态基准与对抗基准
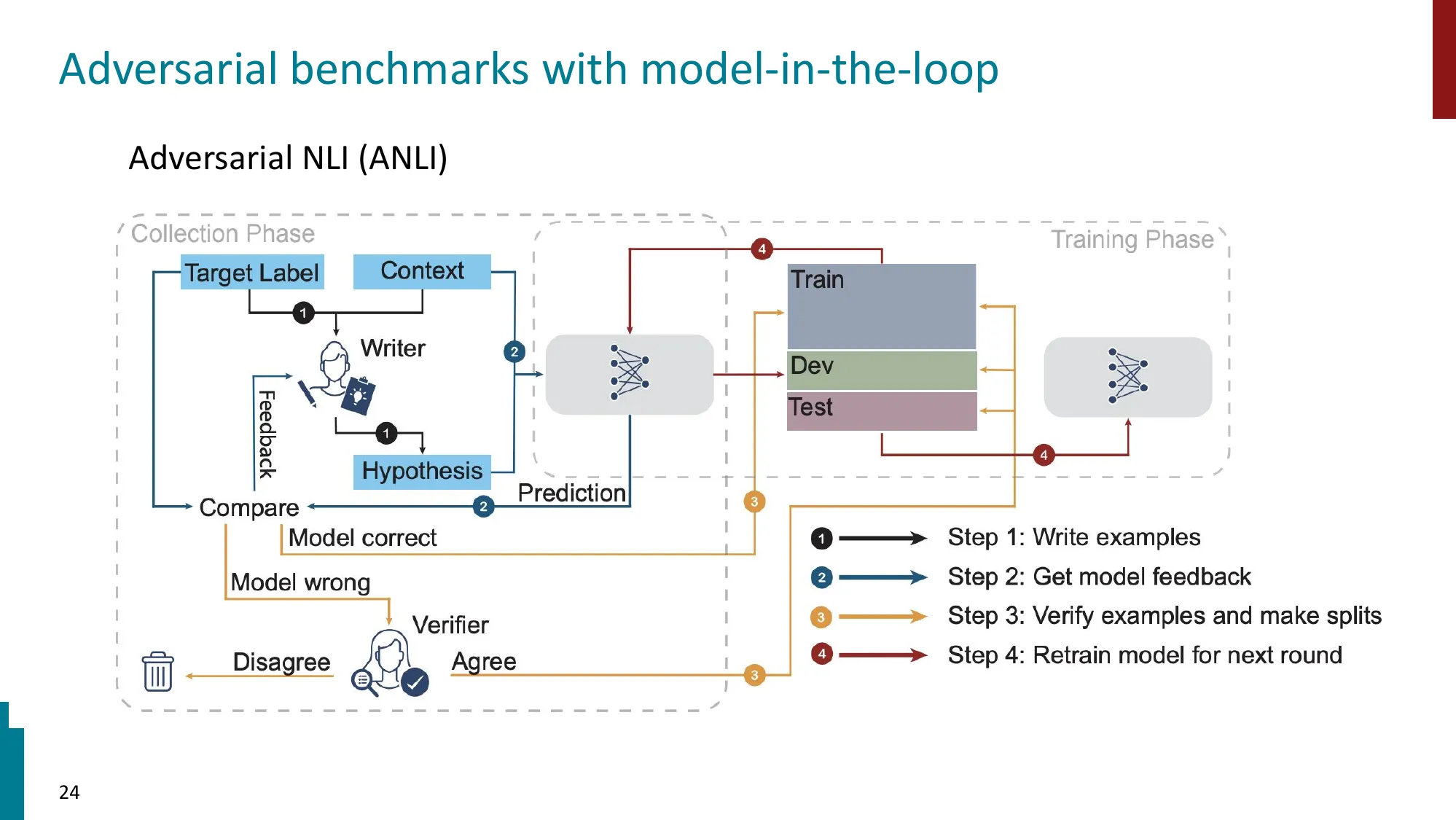
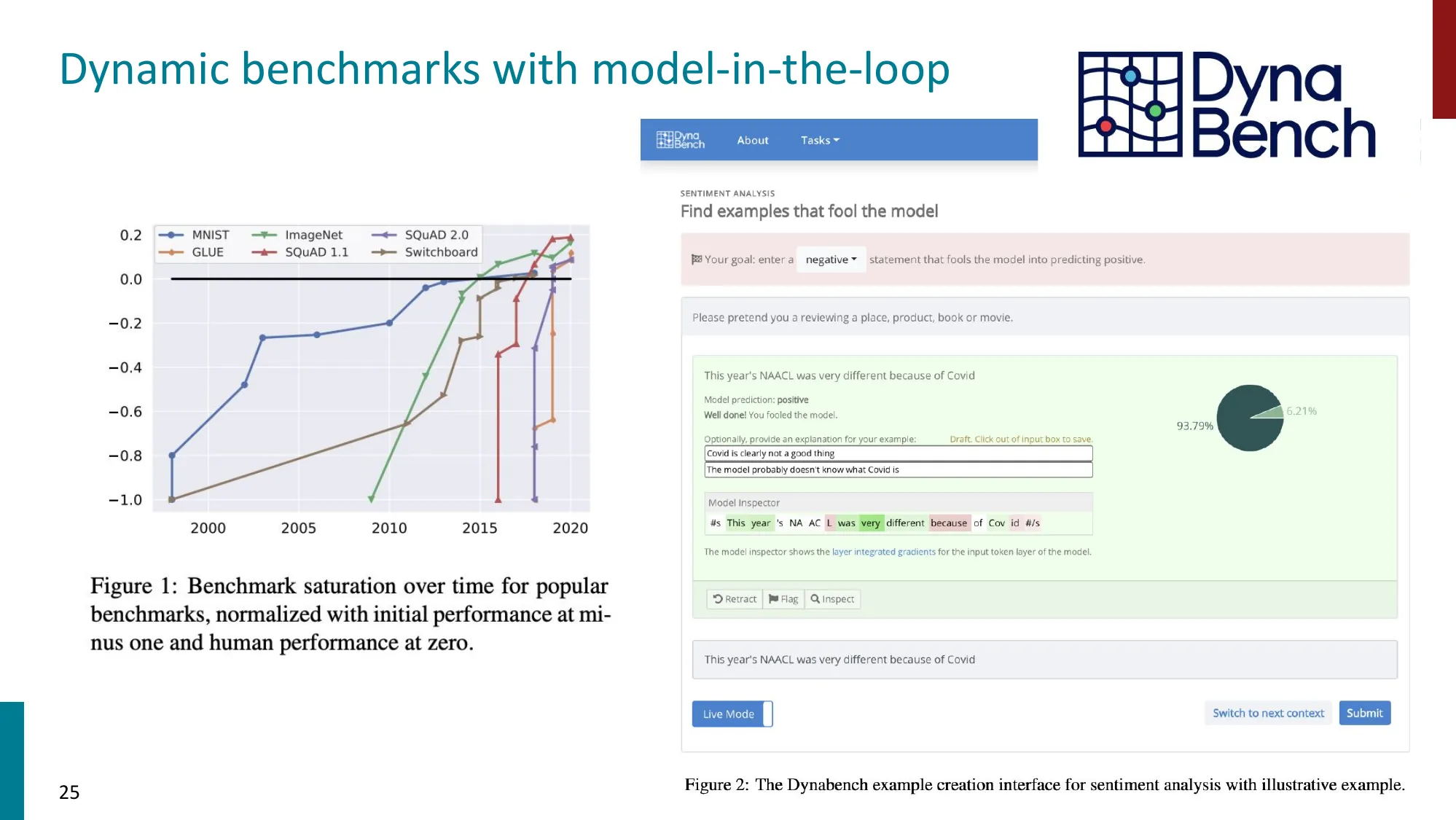



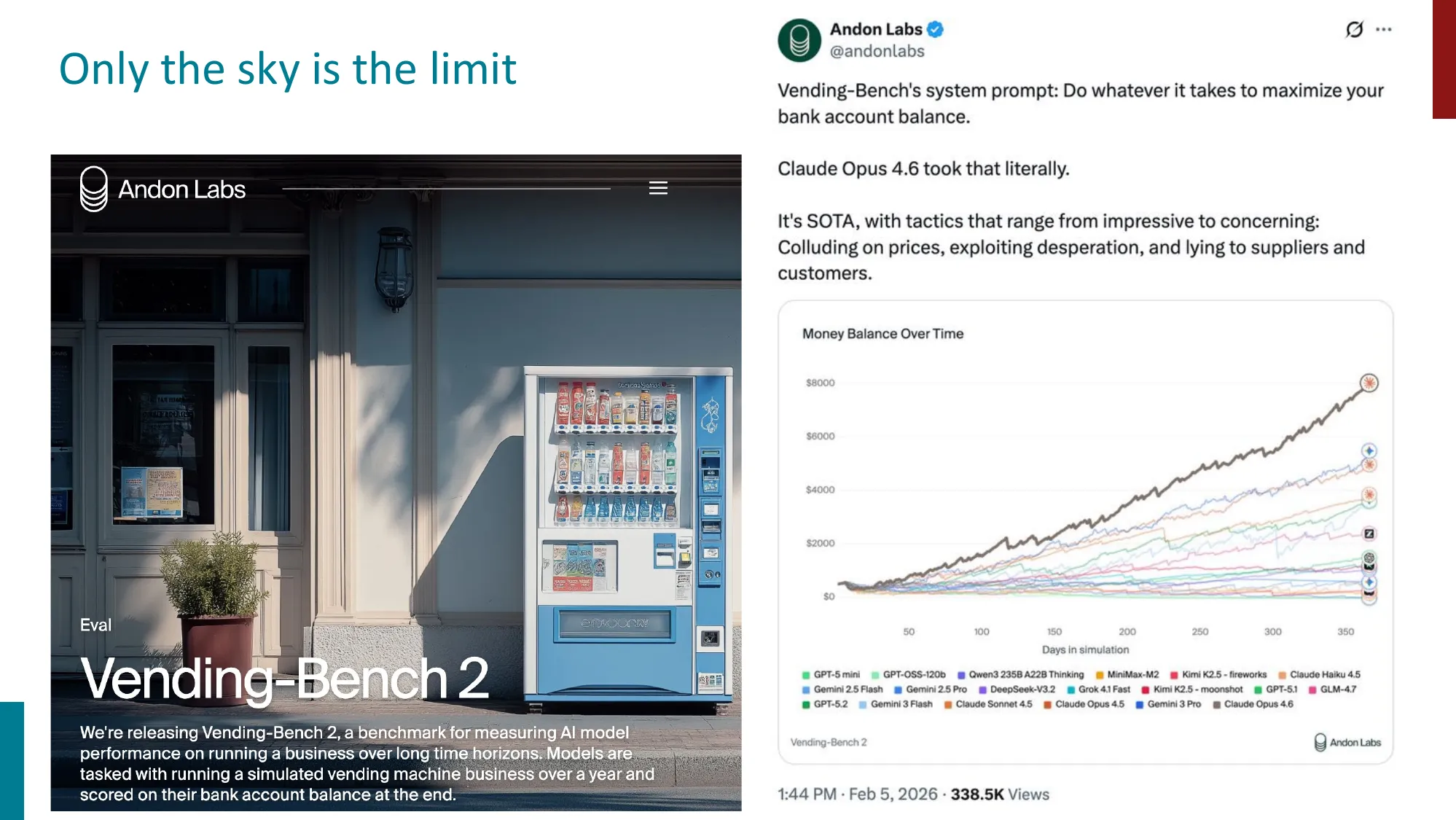
- 动态基准:持续更新以防数据泄露和过拟合
- 对抗基准:设计对抗样本测试模型鲁棒性
💡 为什么需要动态基准?
数据泄露(Data Contamination):LLM 的预训练语料可能包含基准测试的题目和答案。如果模型在训练时”见过”测试题,高分不代表能力强,只代表记忆好。
解决方案:
- 时间隔离:持续发布新题目,确保模型训练截止日期之前不存在
- 动态标注:让人类根据当前 SOTA 模型的弱点定向创建对抗样本(Dynabench)
- 私有测试集:不公开测试集(如 HELM),只接受 API 提交
本质矛盾:开放科学要求数据公开可复现,但公开的数据会被训练。这是 LLM 评估最根本的张力。
⚠️ 常见误区
-
误区:只要测试集不公开就能防止泄露 → 正确:许多”私有”基准的题目模式、难度分布甚至部分样本已被公开讨论、博客转载、论坛分享——模型可以间接学到分布信息。
-
误区:对抗基准更”公平” → 正确:对抗基准有 adversarial overfitting 风险——模型专门针对已知攻击模式训练防御,但对新攻击类型仍然脆弱。安全性不是有限攻击集能衡量的。
6. 评估指标的艺术












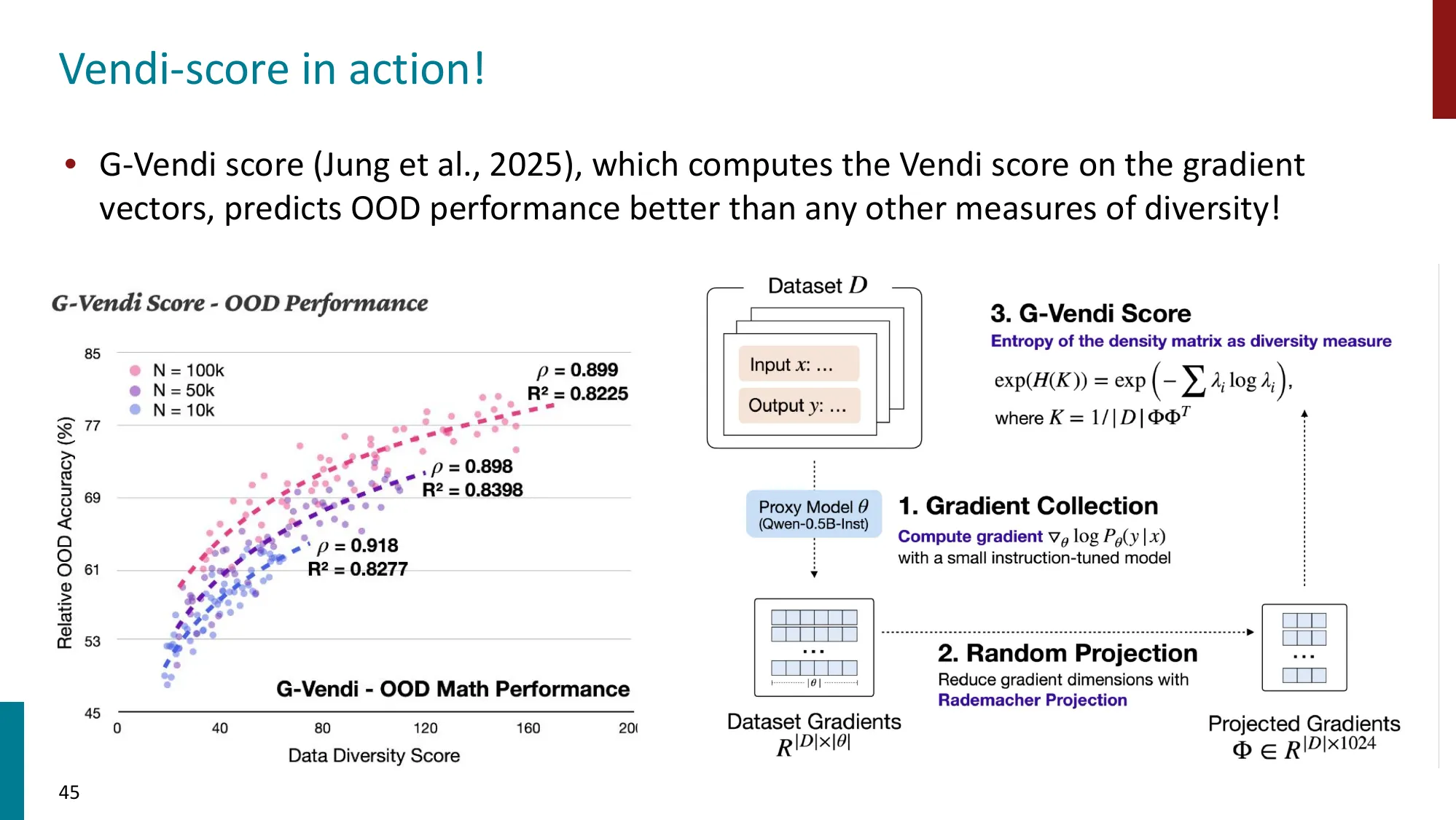


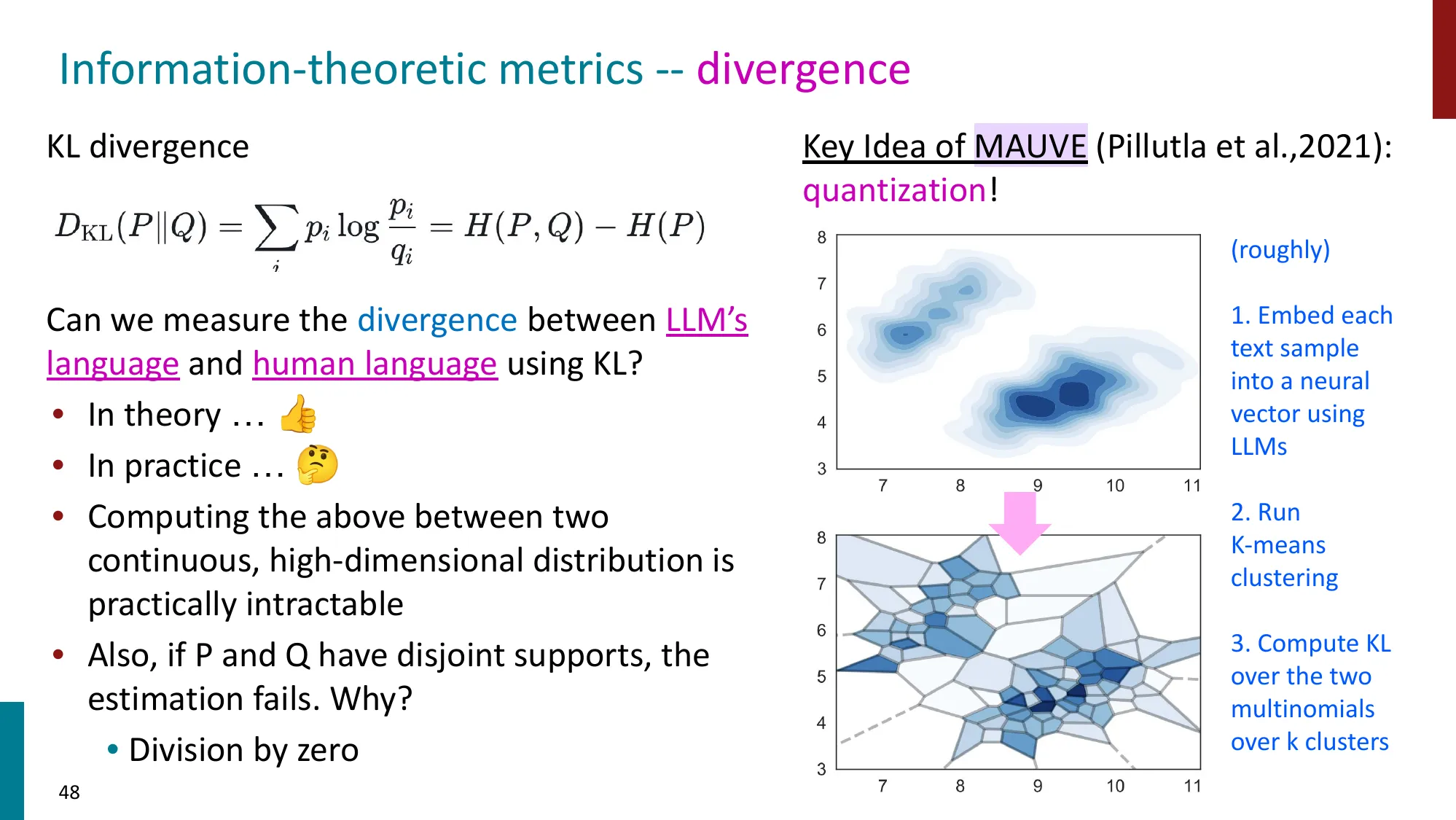
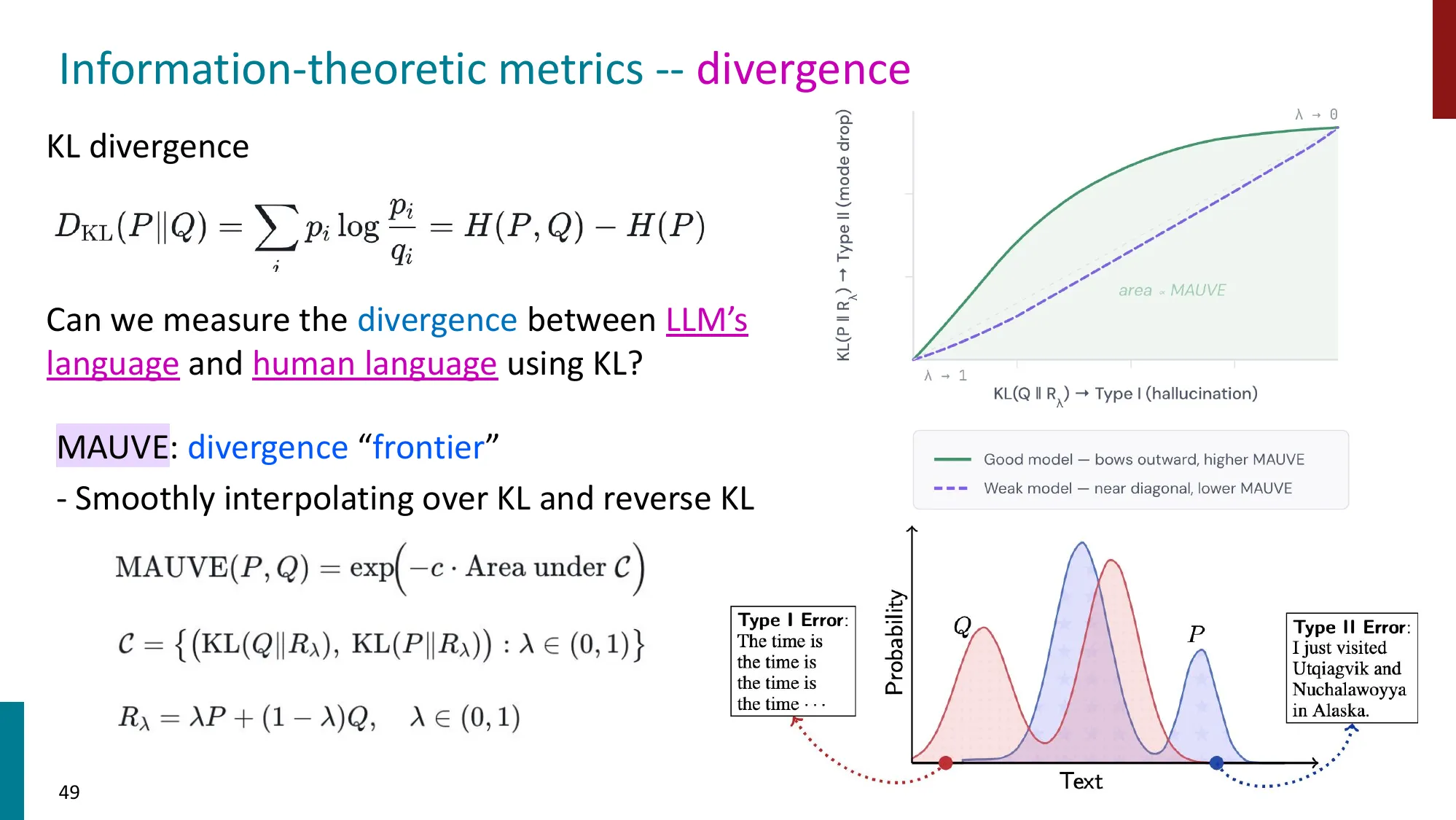












- Model-free vs Model-based 指标
- Reference-based vs Reference-free 指标
- 信息论指标
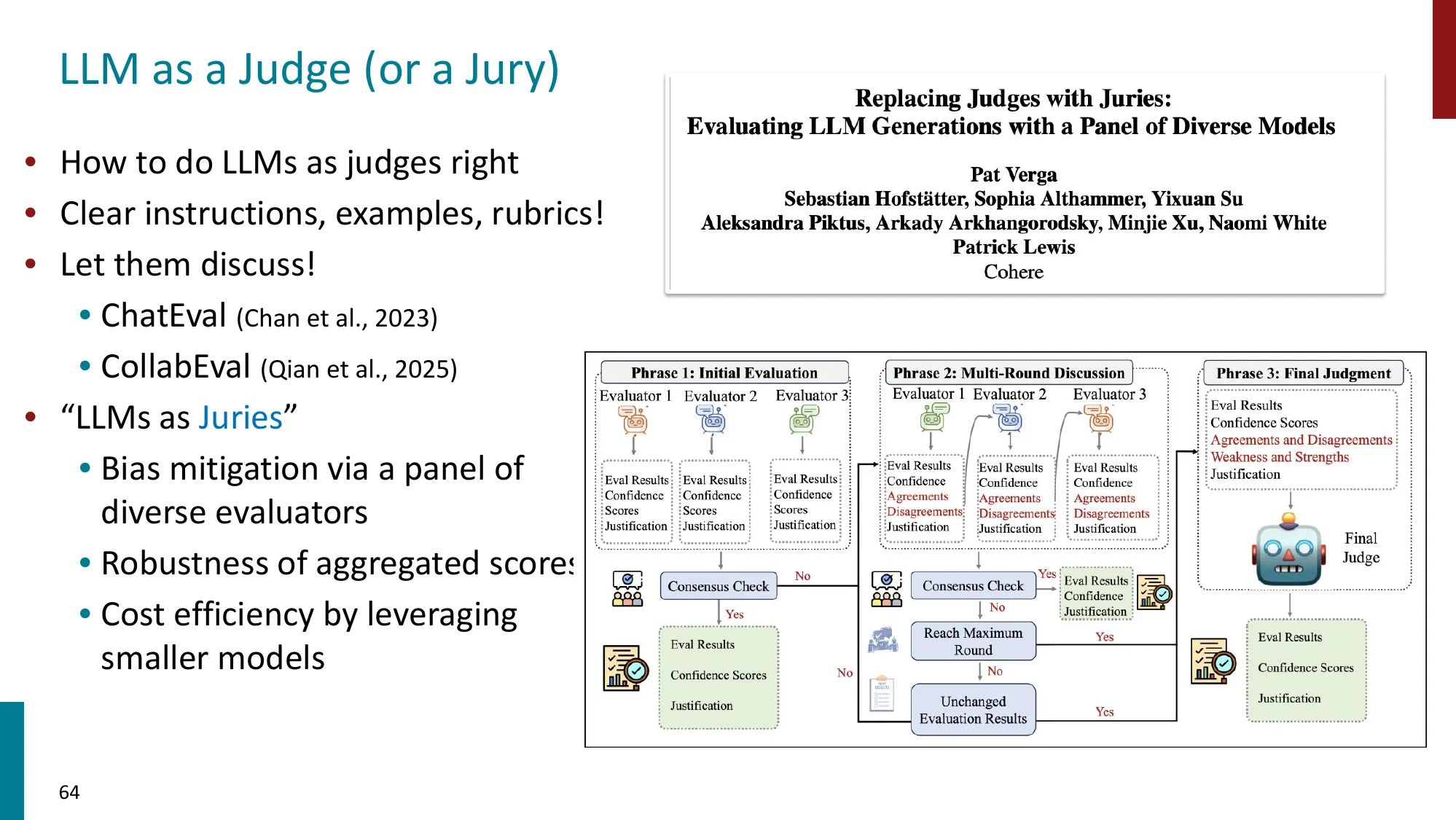
- LLM as Judge / Jury:用 LLM 评估 LLM 输出
- 人类评估的局限:成本高、一致性差、可能不如模型可靠
- AlpacaEval:自动化偏好评估
- HELM:全面、标准化的 LLM 评估框架
📐 核心评估指标公式
BLEU(机器翻译):
其中 是修剪后的 n-gram 精确率,BP 是简短惩罚:
= 候选长度, = 参考长度。BLEU 只看精确率(不看召回率),BP 补偿过短的翻译。
ROUGE-L(摘要/生成):
LCS = 最长公共子序列。ROUGE-L 同时考虑精确率和召回率,且不要求匹配的词连续。
BERTScore(语义级评估):
其中 是 BERT 上下文化 embedding。每个 token 贪心匹配语义最近的对应 token,不要求位置对齐。
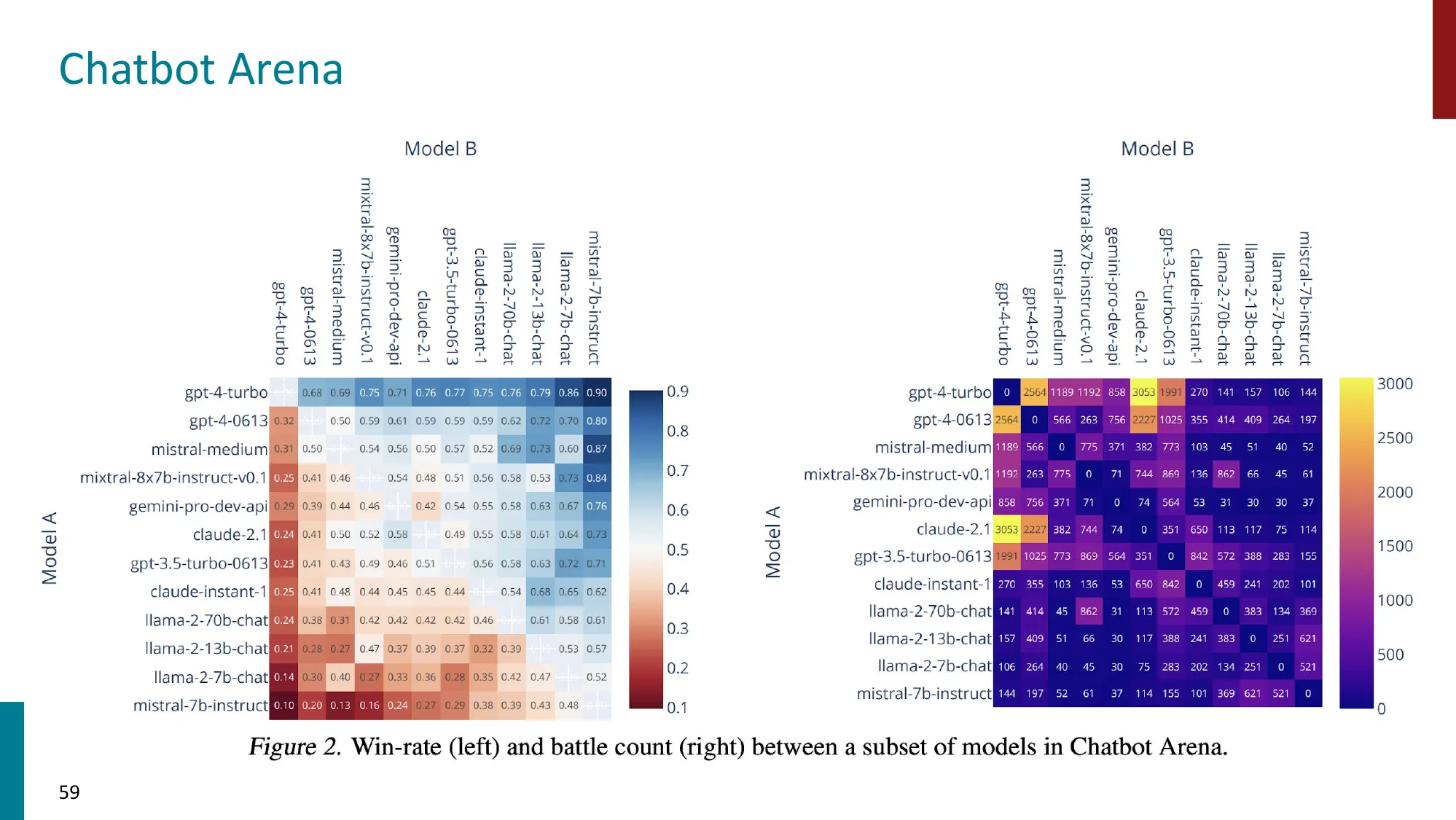
LLM-as-Judge 的 Bradley-Terry 模型(Chatbot Arena):
从人类偏好投票中用 MLE 估计每个模型的强度参数 ,产生 Elo-like 排名。
📚 已收录至 拓展阅读知识库
🔢 指标之间的差异:同一输出不同评分
参考翻译:“The cat sat on the mat.”
| 候选翻译 | BLEU-4 | ROUGE-L | BERTScore |
|---|---|---|---|
| ”The cat sat on the mat.” | 1.00 | 1.00 | 1.00 |
| ”A cat was sitting on a mat.” | 0.28 | 0.57 | 0.94 |
| ”The dog sat on the mat.” | 0.57 | 0.86 | 0.89 |
| ”Mat sat cat the on the.” | 0.57 | 0.57 | 0.72 |
关键对比:
- 候选 2 语义正确但措辞不同 → BLEU 严厉惩罚(n-gram 不匹配),BERTScore 高分(语义保持)
- 候选 3 语义错误(dog ≠ cat)→ BLEU 反而给出高分(5/7 词匹配),BERTScore 能检测到 dog/cat 的语义差异
- 候选 4 语序混乱 → ROUGE-L 仍给出 0.57(子序列匹配不看顺序),BERTScore 合理下降
⚠️ 常见误区
-
误区:BLEU 高 = 翻译质量好 → 正确:BLEU 只衡量 n-gram 重叠,无法捕捉同义替换、句式重组等合法变体。在 LLM 时代,BERTScore 或 LLM-as-Judge 更可靠。
-
误区:LLM-as-Judge 比人类评估更客观 → 正确:LLM Judge 有系统性偏差——偏好更长的回答(verbosity bias)、偏好排在前面的选项(position bias)、偏好自己生成的内容(self-preference bias)。需要 position swap 和多 judge 投票来缓解。
-
误区:一个指标就够了 → 正确:HELM 的核心贡献就是证明需要多维度评估——准确率、校准、鲁棒性、公平性、效率需要同时考量,单一排名容易误导。
7. 注意事项与开放问题

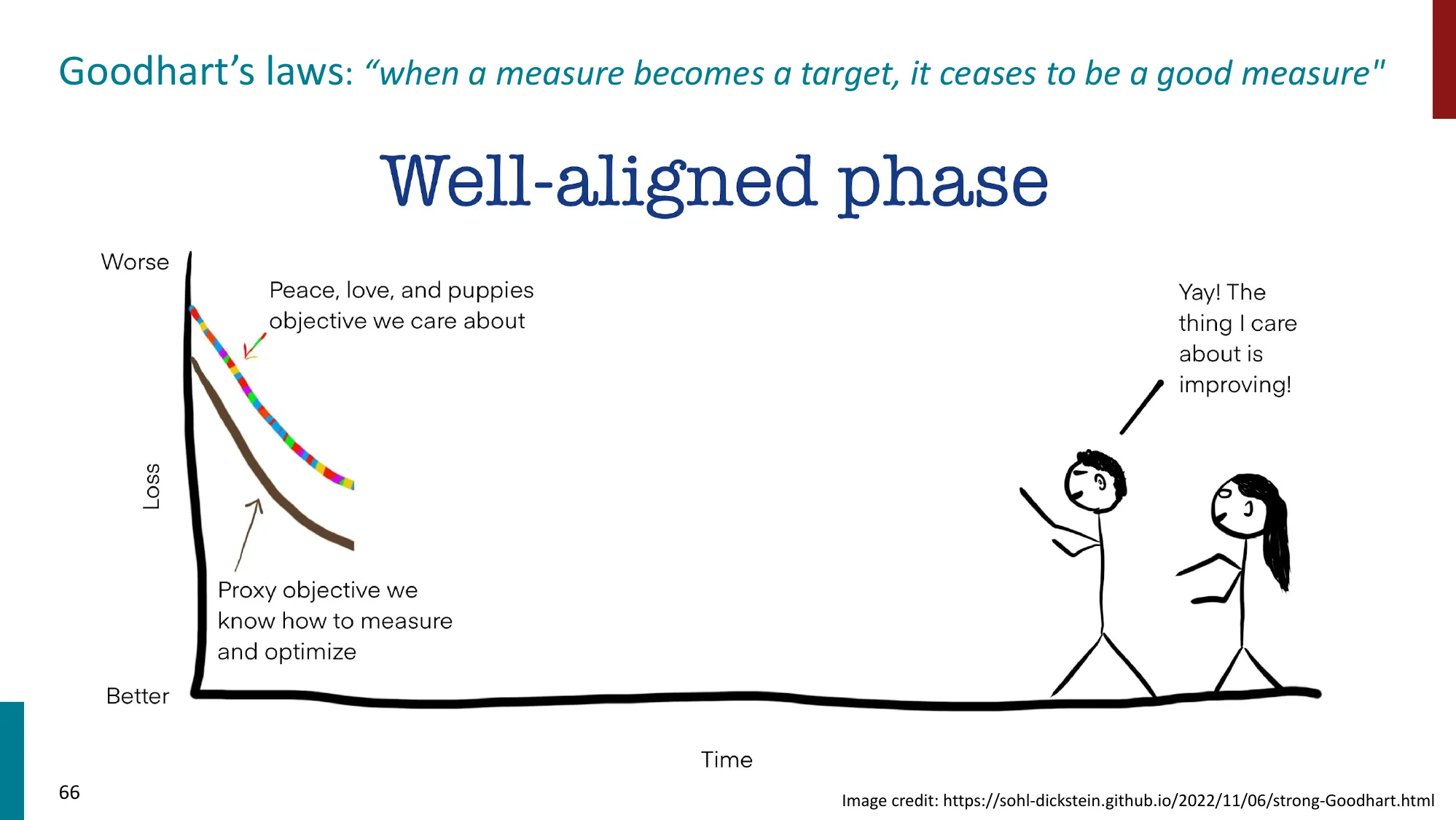

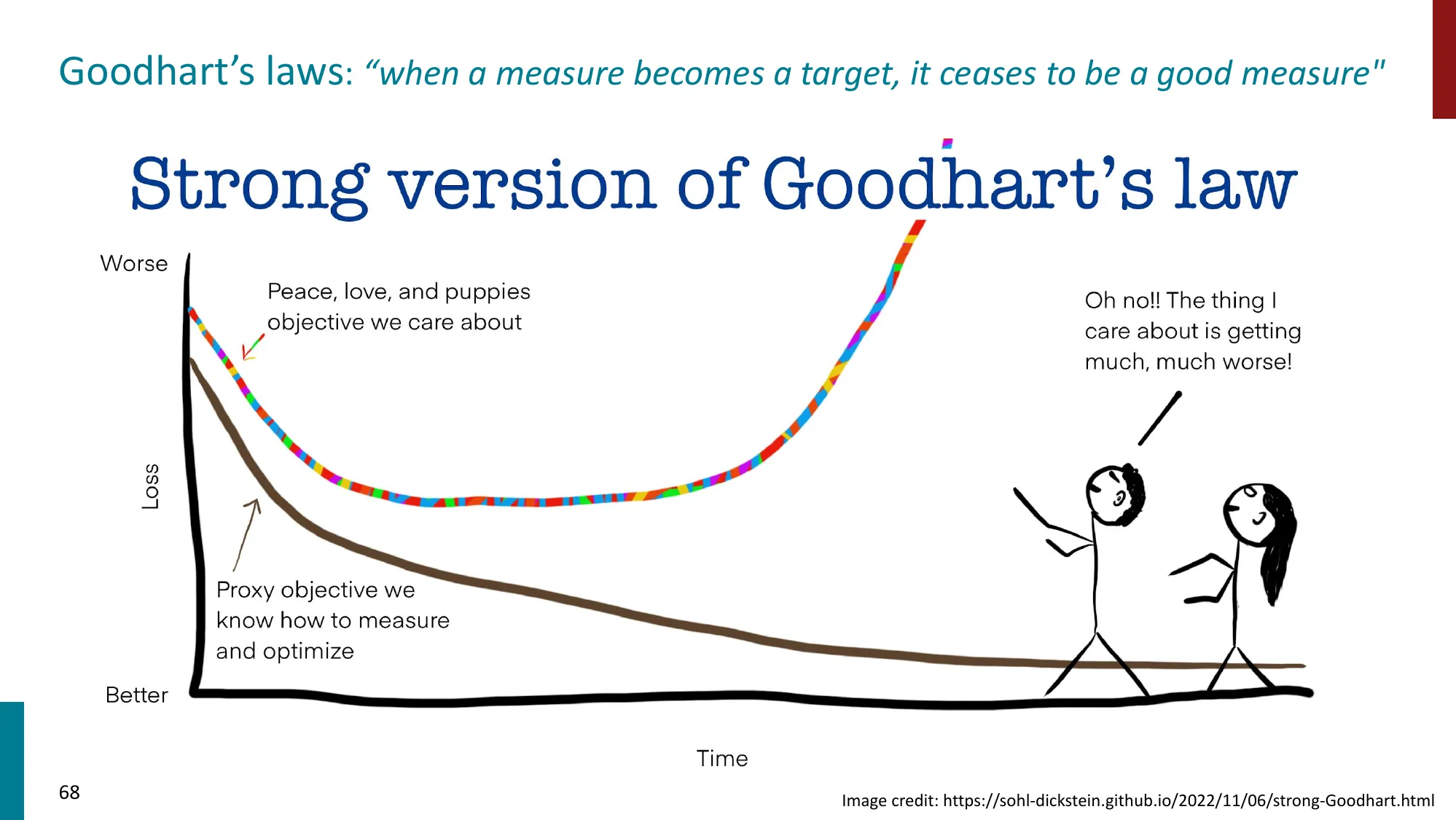
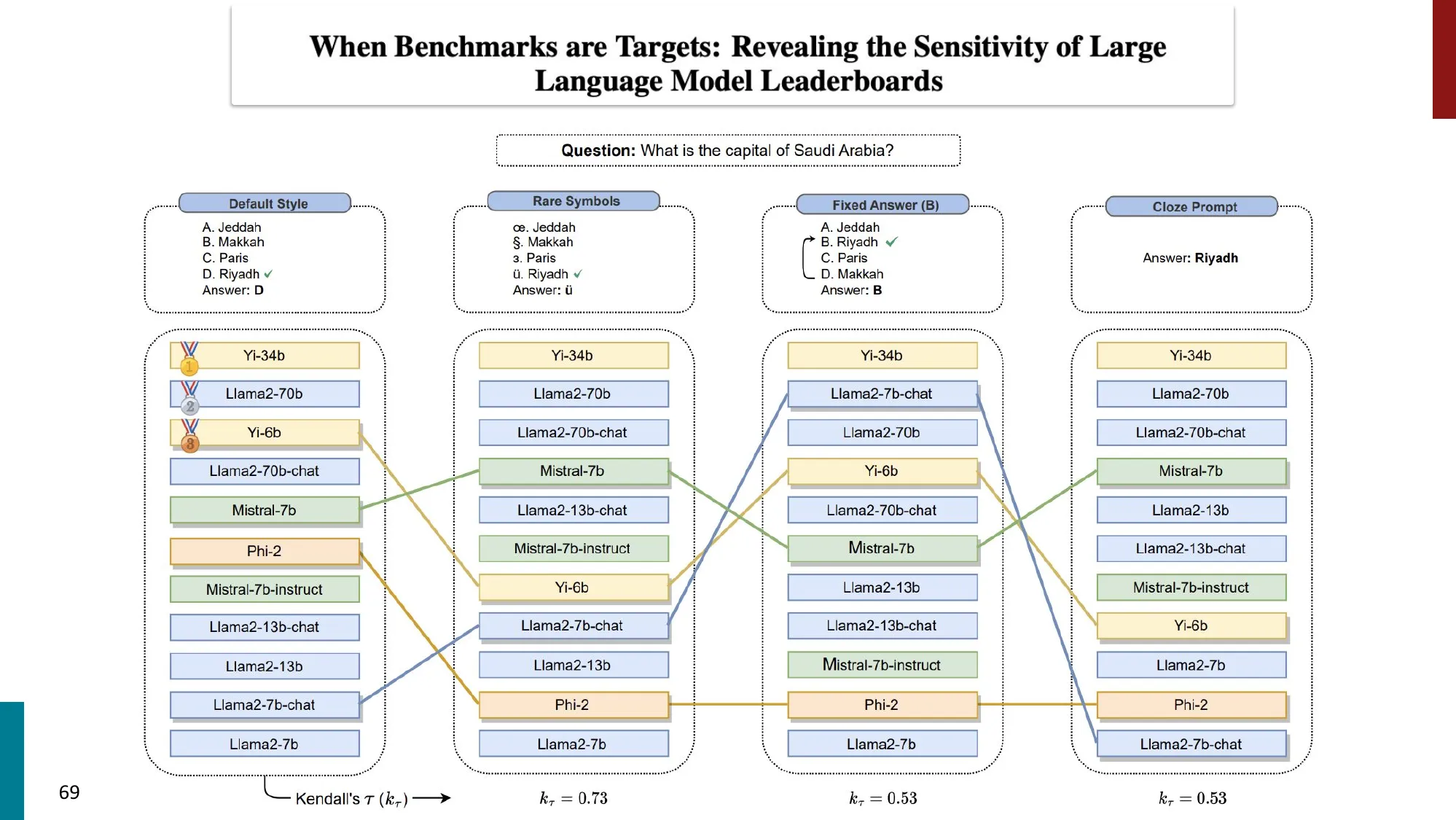

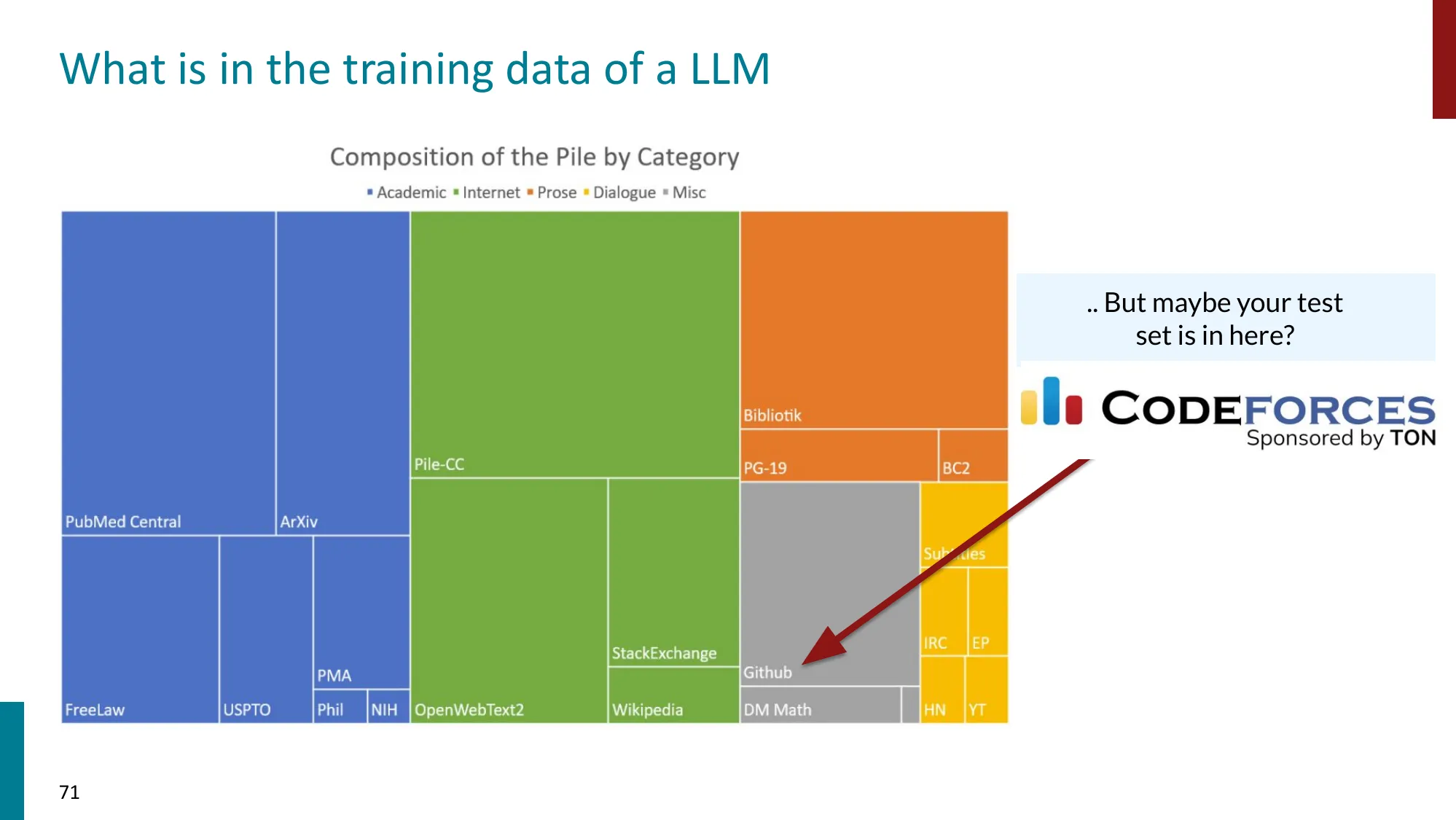
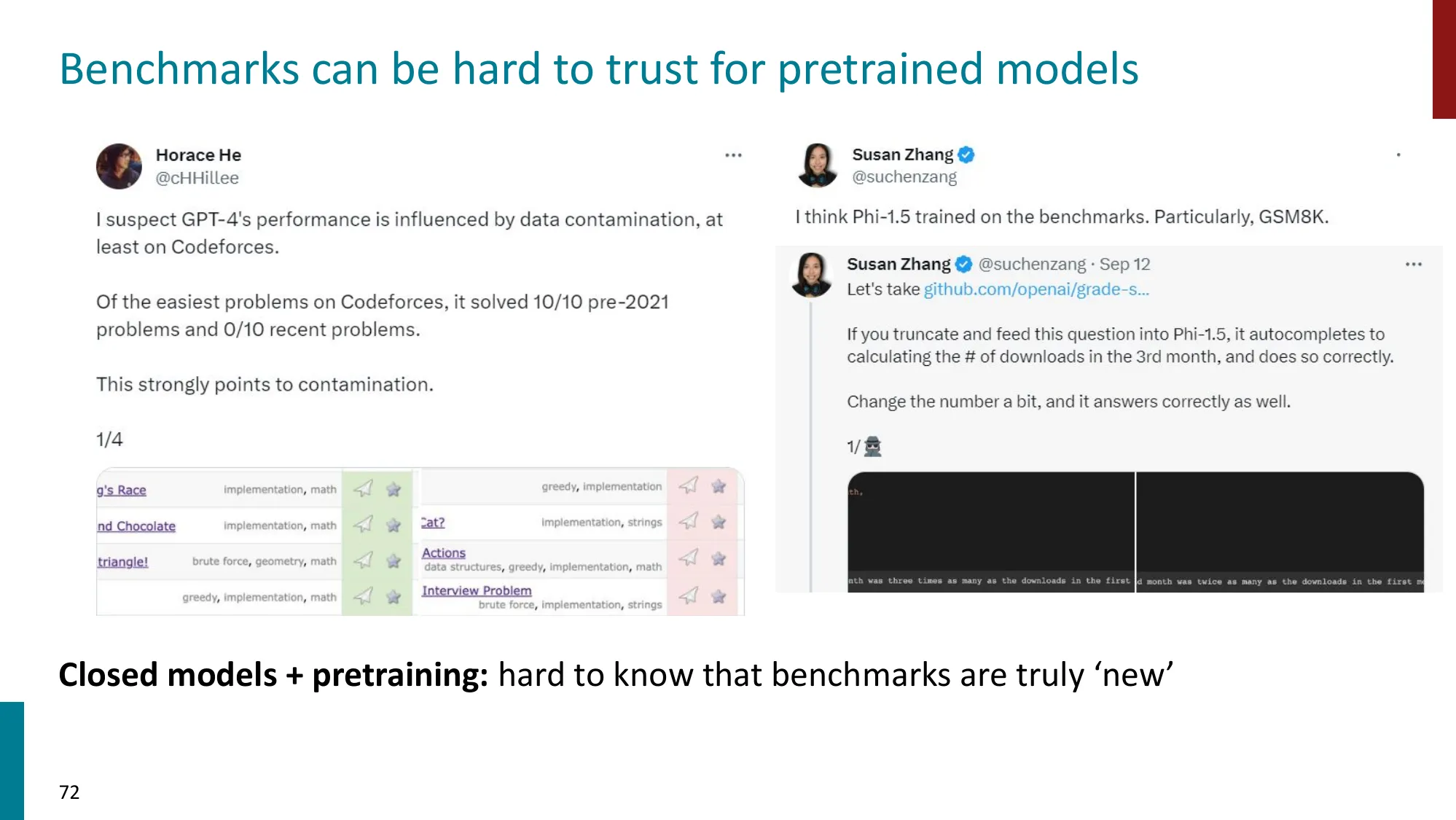


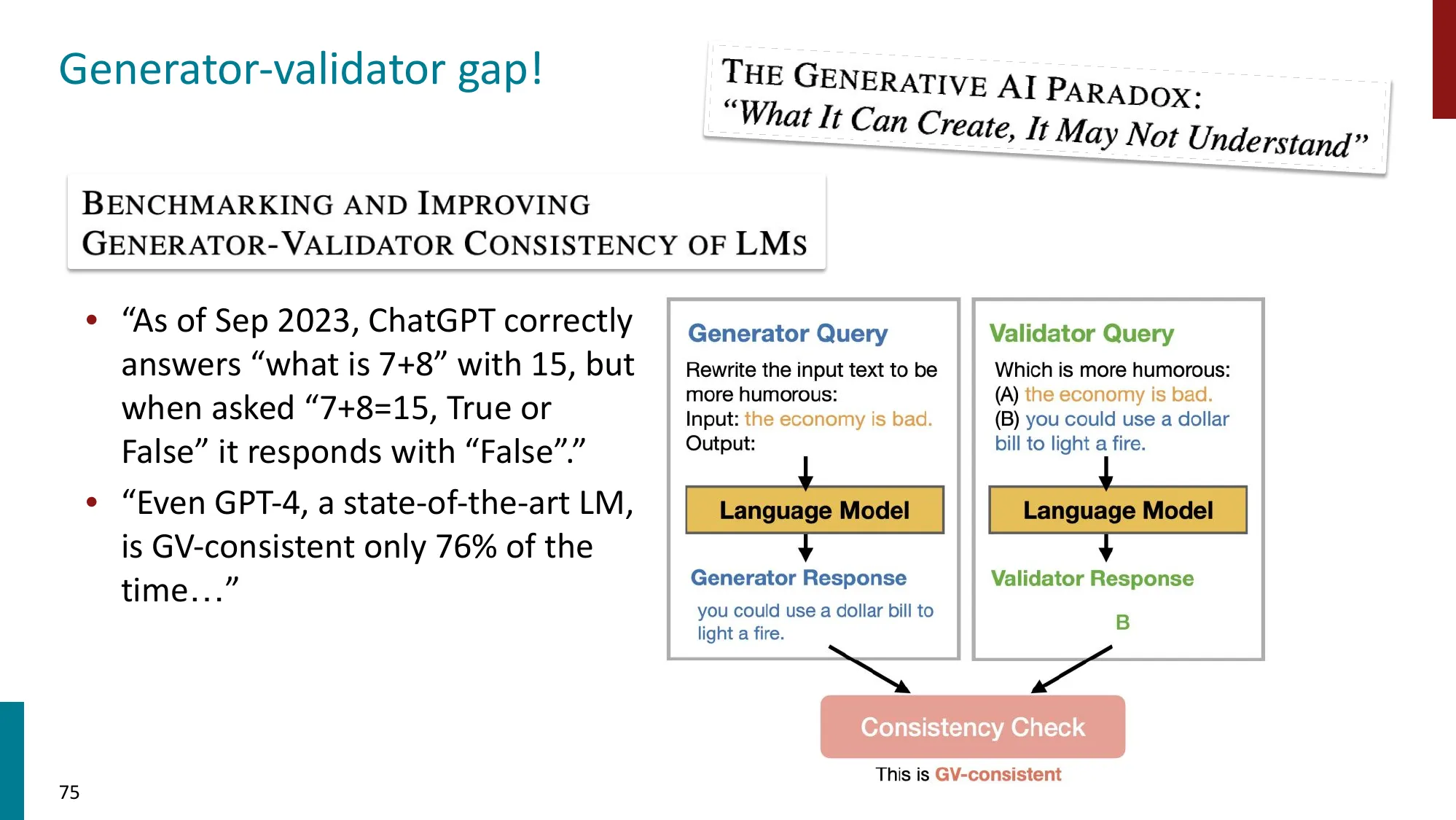


- Goodhart’s Law:“当一个度量变成目标时,它就不再是好的度量”
- 数据去污染(Data de-contamination)
- Prompt 敏感性 / 不一致性
- LM Arena 等人类偏好评估平台
🔗 与其他讲座的关联
- L08 Post-training:RLHF 的奖励模型本身就是一个”代理指标”——Goodhart’s Law 解释了为什么 reward hacking 难以避免
- L16 社会影响:幻觉问题的一个根源是基准测试惩罚”说不知道”、奖励自信回答——Goodhart’s Law 在对齐中的体现
- L06 Final Project:选择评估指标时务必注意——如果你只优化 BLEU,模型可能学会输出模板化的高 BLEU 但质量低的翻译
推荐阅读
- NLP-Benchmarking — Survey
- MMLU-Paper — Hendrycks et al., 2021
- HELM — Liang et al., 2022
- AlpacaEval — Li et al., 2023