L13: Reasoning 2/2
Week 7 · Tue Feb 17 2026 08:00:00 GMT+0800 (中国标准时间)
L13: Reasoning 2/2
- Lecturer: Yejin Choi
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
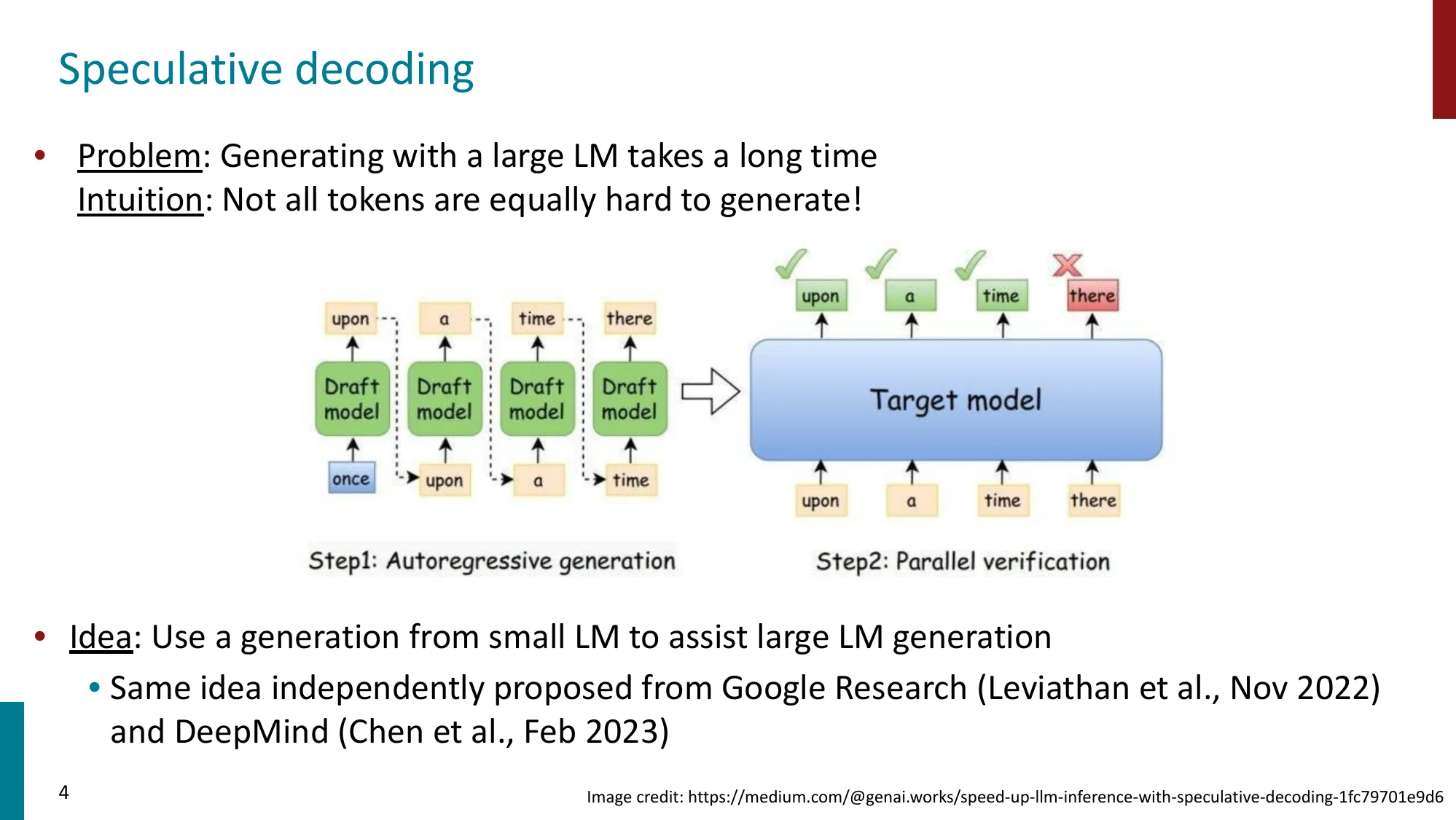
1. Speculative Decoding(推测解码)
- 问题:大型 LM 生成速度慢(memory-bound,逐 token 自回归)
- 核心直觉:不是所有 token 都同样难生成
标准 Speculative Decoding


- Step 1:小模型 自回归生成 K 个 draft token
- Step 2:大模型 单次前向传播验证所有 K 个 token
- 接受规则:
- Case 1: -> 直接接受
- Case 2: -> 以概率 接受
- Case 3: 拒绝 -> 从 重新采样
- 数学保证:输出分布等价于直接从大模型采样(rejection sampling)
- 实际加速:T5-small (60M) + T5-XXL (11B) 达到 2-3x 加速
Dynamic Speculative Decoding

- 自适应调整 lookahead 大小(候选 token 数量)
Universal Speculative Decoding



- 允许 draft 和 target 模型使用不同 tokenizer(通过 re-encoding 和 alignment)
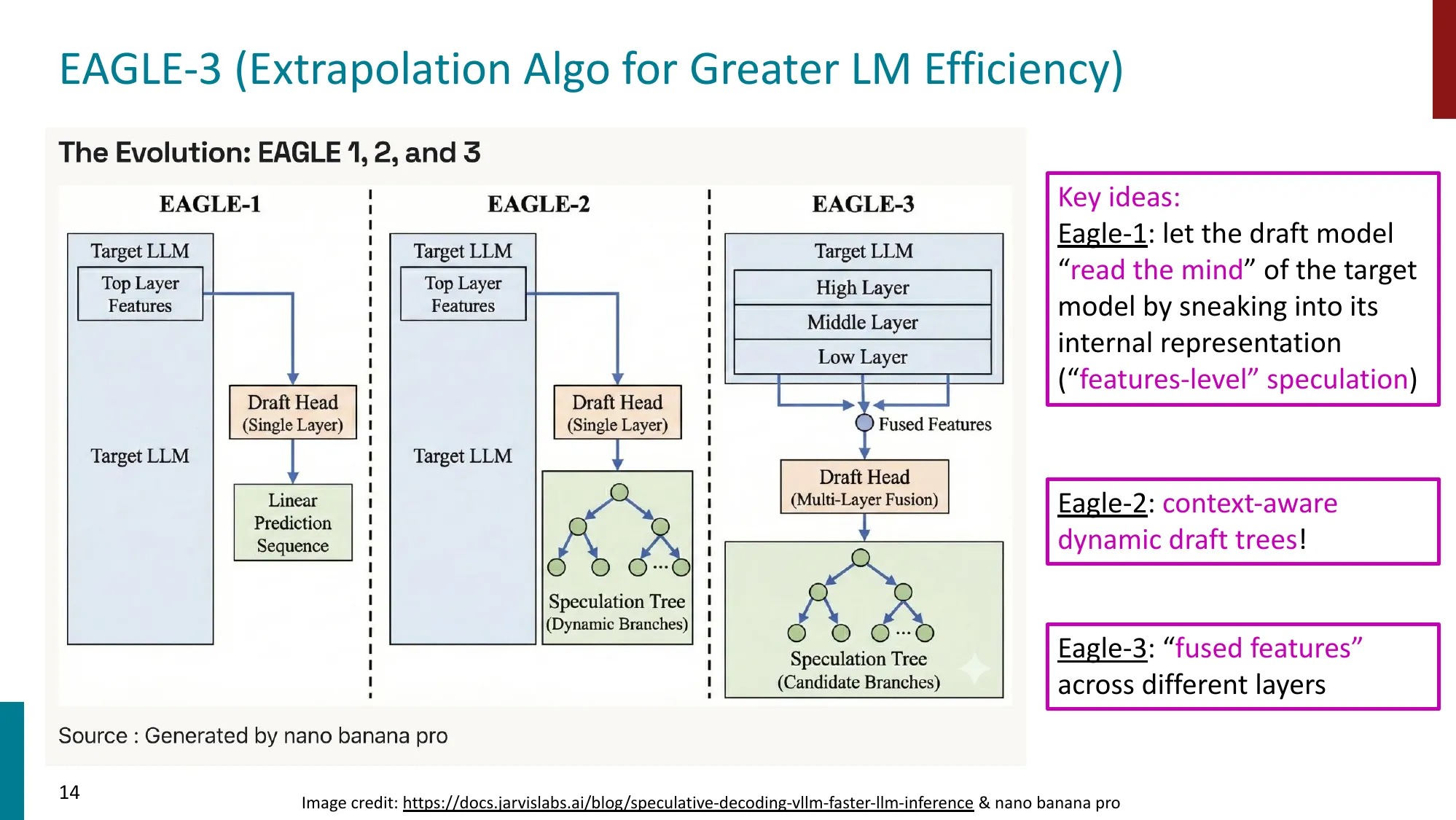
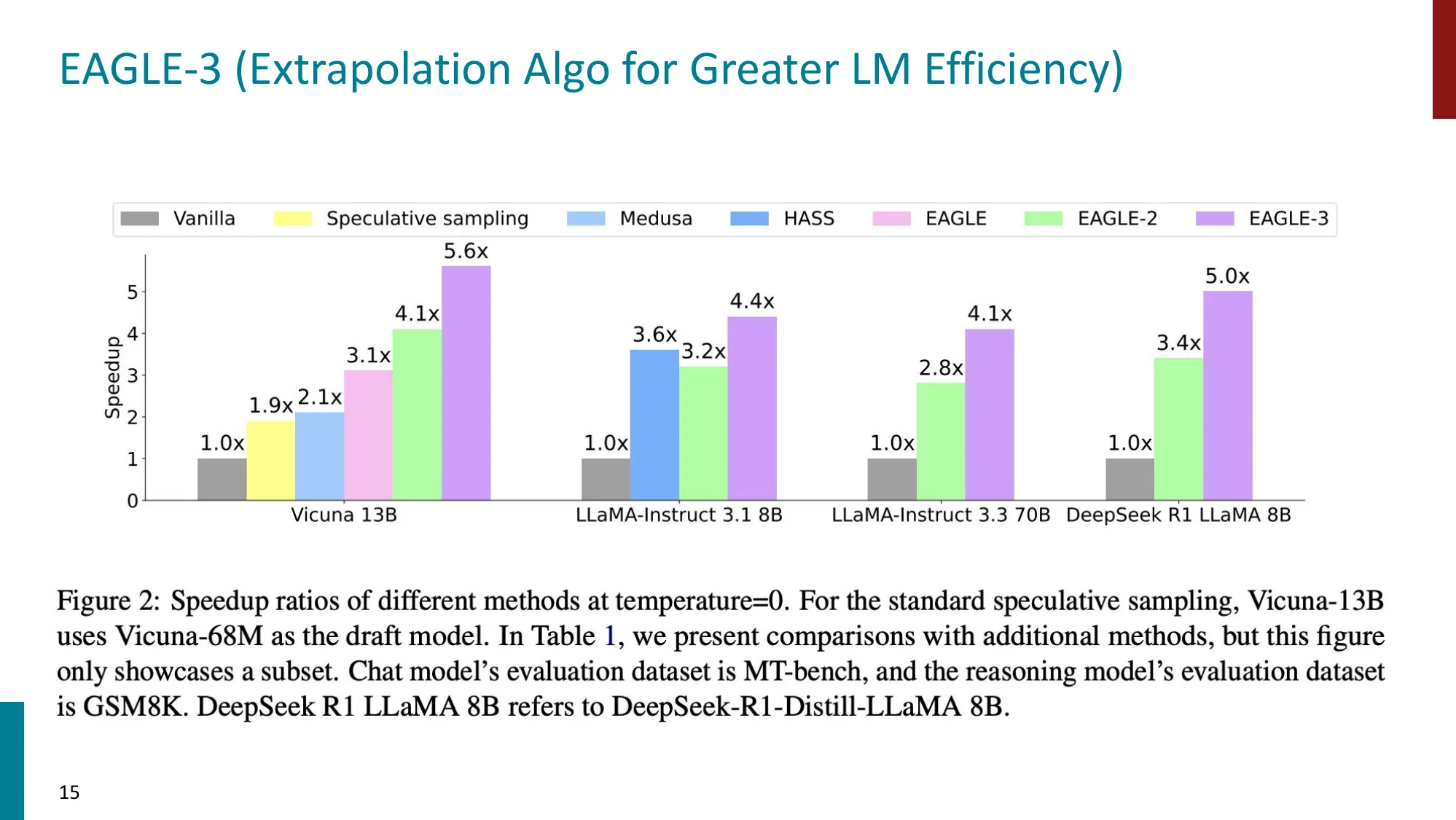
EAGLE 系列(1/2/3)


- EAGLE-1:draft head 读取 target model 的顶层特征(features-level speculation)
- EAGLE-2:上下文感知的动态 draft tree
- EAGLE-3:跨层 fused features,加速可达 5.6x
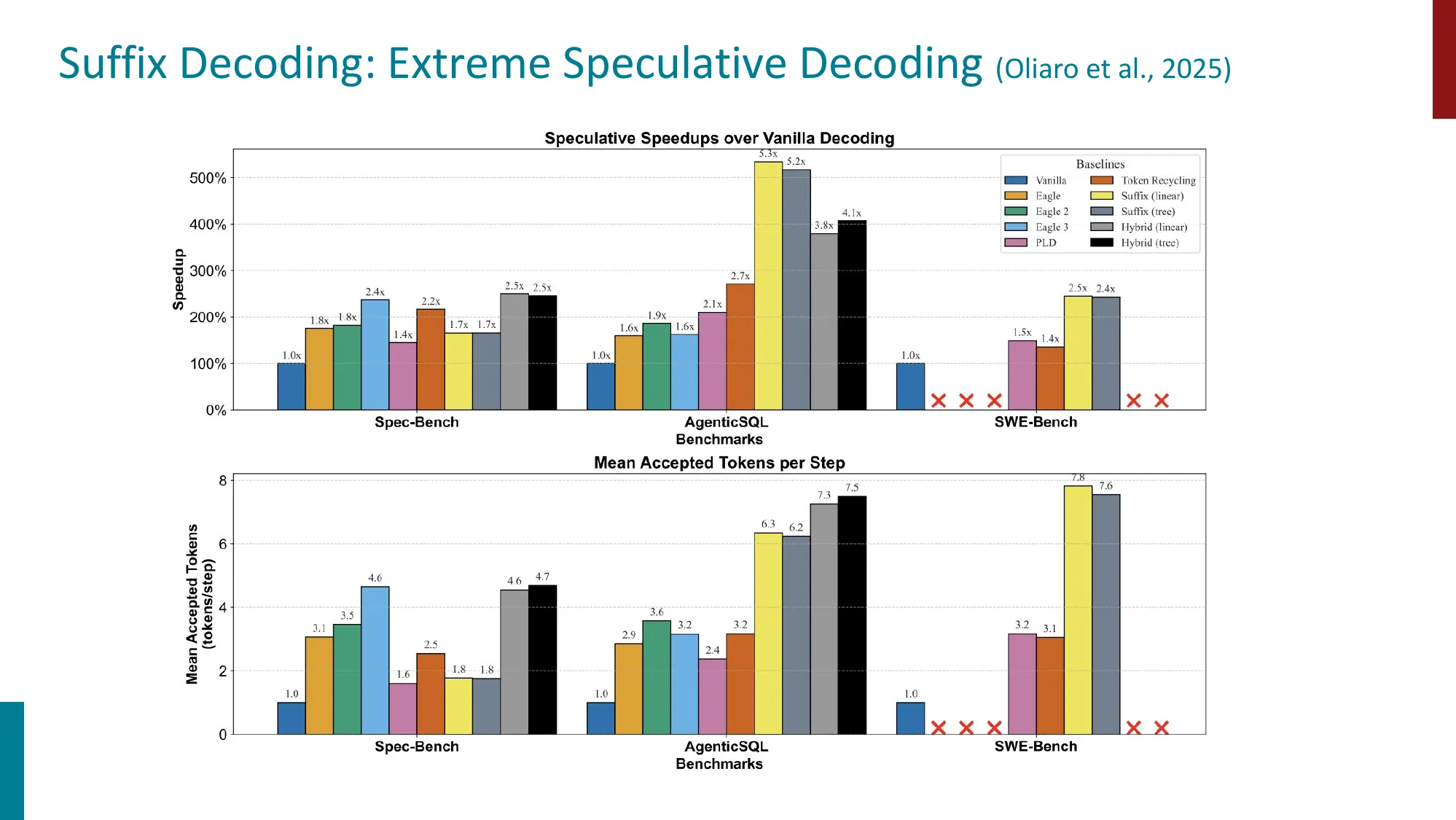
SuffixDecoding(Oliaro et al., 2025)



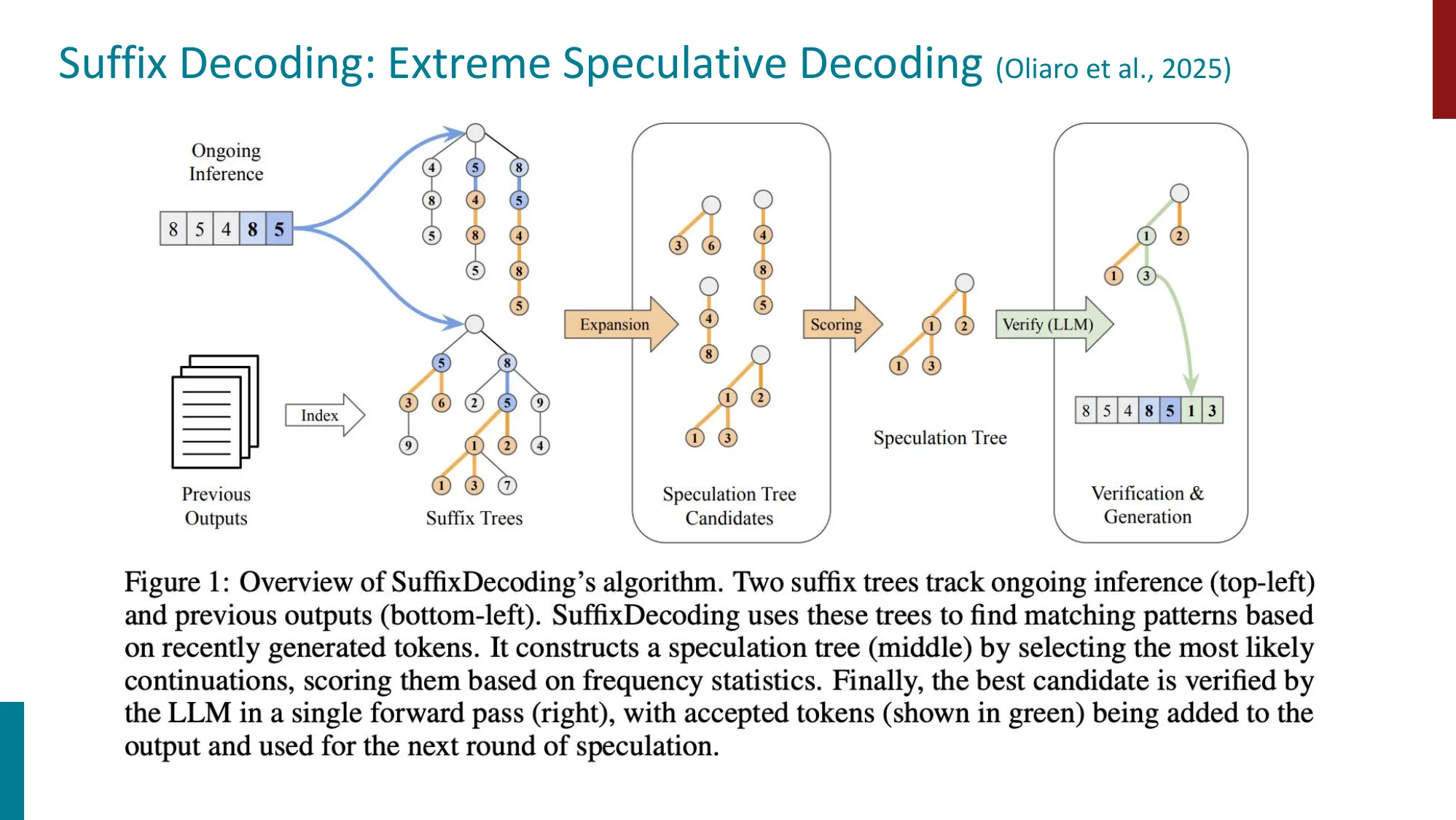
- Model-free:用 Suffix Tree 缓存和匹配重复序列模式
- CPU-bound(GPU 空闲时 CPU 做推测),零训练开销
- 最适合高重复任务(代码、Agent 循环、RAG、SQL)
- 在 AgenticSQL 上达到 5.3x 加速
SuffixDecoding vs EAGLE-3 对比
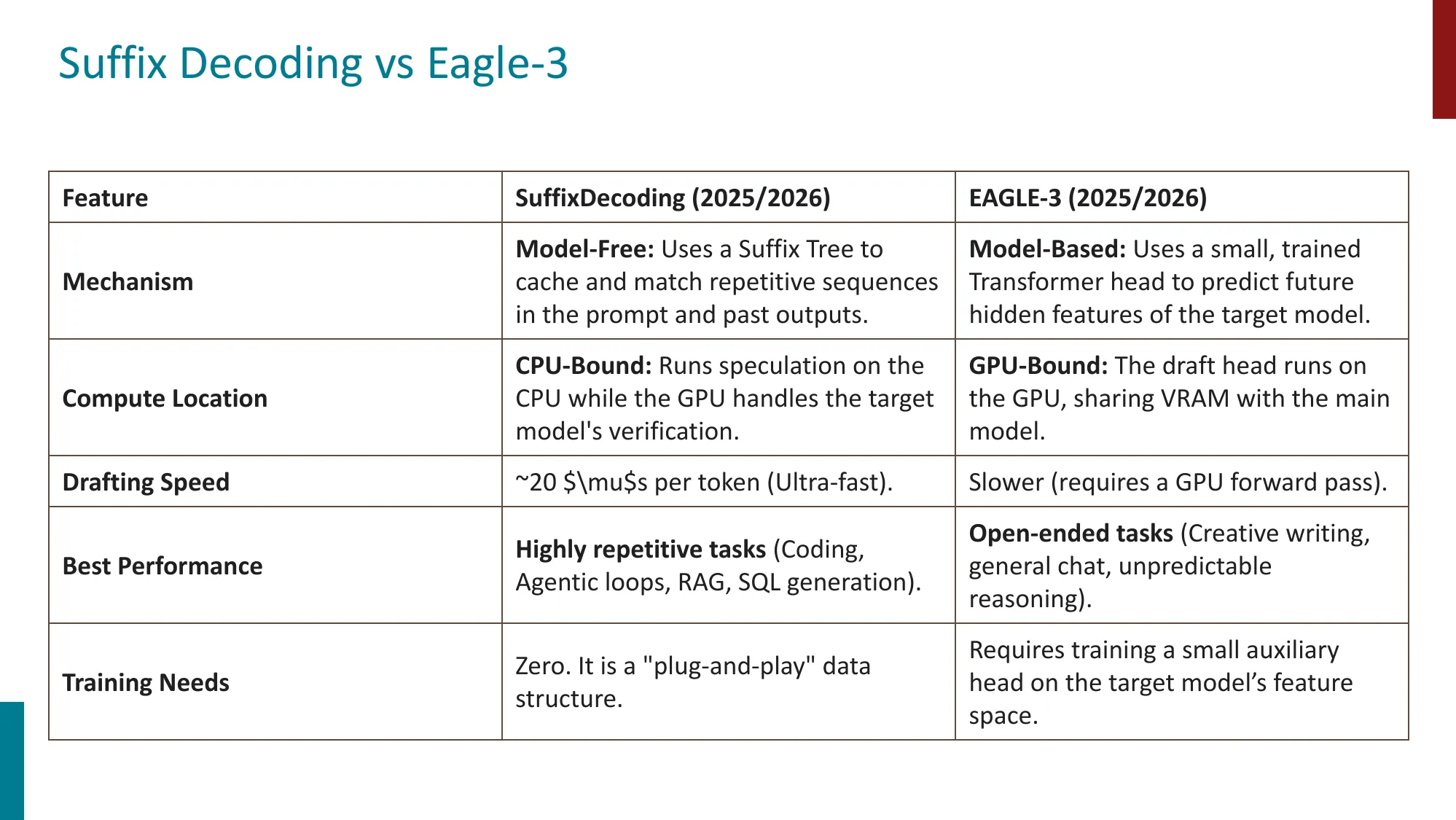

- SuffixDecoding:Model-free,CPU-bound,~20us/token,适合重复任务
- EAGLE-3:Model-based,GPU-bound,需要训练 draft head,适合开放任务
🔢 数值计算示例
(草稿模型先生成 4 个 token)
草稿模型生成:[“The”, “cat”, “sat”, “on”]
目标模型评估概率比:
- “The”: → ,直接接受
- “cat”: → ,直接接受
- “sat”: → 以 60% 概率接受,假设接受
- “on”: → 以 50% 概率接受,假设拒绝
结果:接受了 “The cat sat”(3 个 token),然后从修正分布重采样”on”的替代词。一次大模型调用 = 3+ 个有效 token;若直接用大模型,1次调用 = 1 个 token。本轮实际加速约 3x。
💡 为什么这样做?
草稿模型是”提案者”,大模型是”审核员”。草稿模型便宜快速,大模型昂贵但准确。大模型每次前向传播本来就能并行处理一整个序列——所以让它一口气批量审核草稿生成的多个 token,平均一次大模型调用批准多个 token,显著提速。本质是把自回归的串行瓶颈转化为批量并行审核。
⚠️ 常见误区
- 误区:Speculative Decoding 牺牲了输出质量换速度 → 正确:数学上已证明输出分布与直接用目标模型采样完全等价,不损失任何质量。
- 误区:草稿模型越小越好(节省时间)→ 正确:加速比依赖草稿和目标模型分布相似度——草稿模型和目标模型差距太大时接受率低,反而不如直接用目标模型。最佳选择是同家族小-大模型(如 Llama-7B 草稿 + Llama-70B 目标)。
2. Off-policy Drift & On-policy Distillation



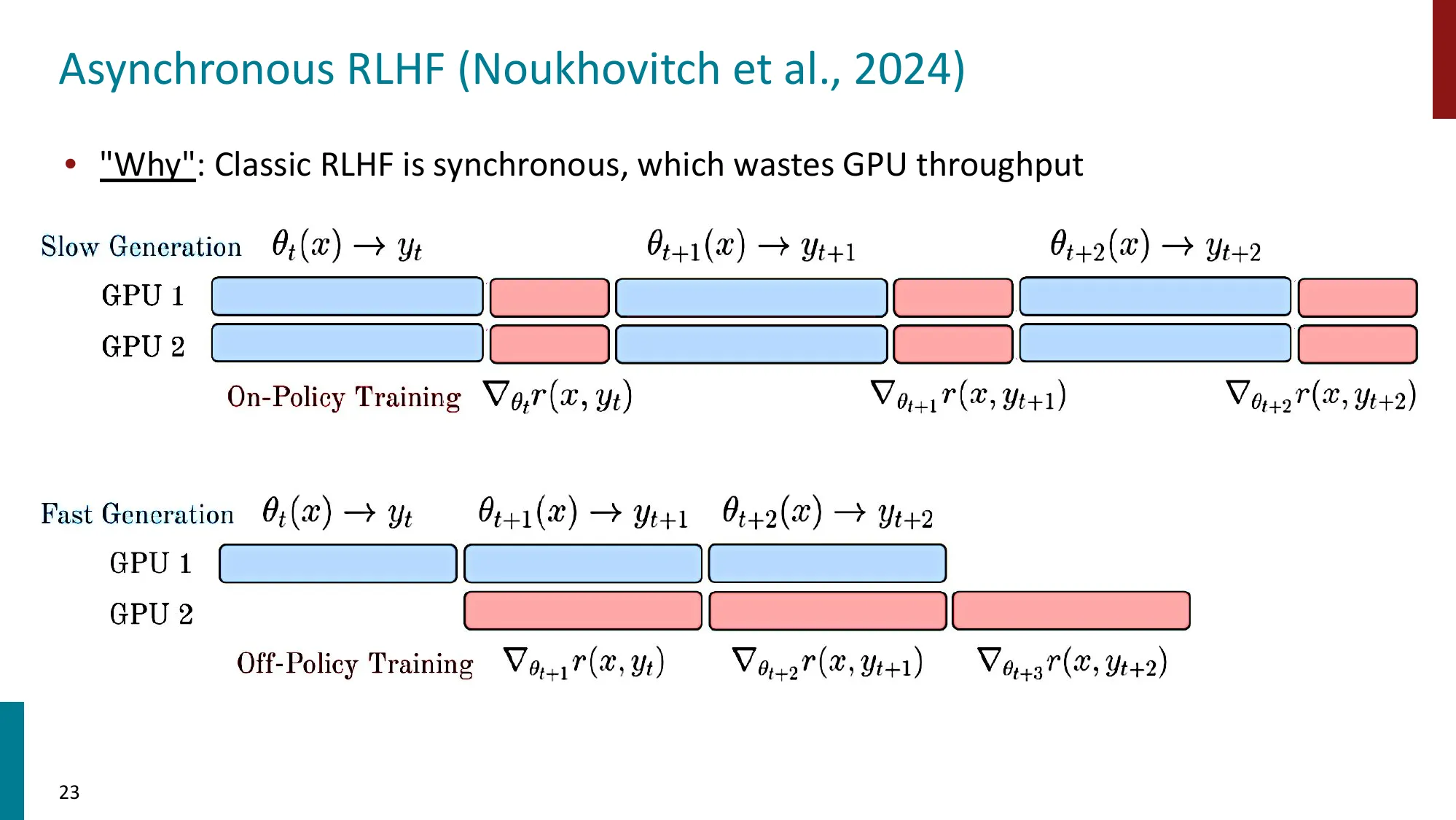




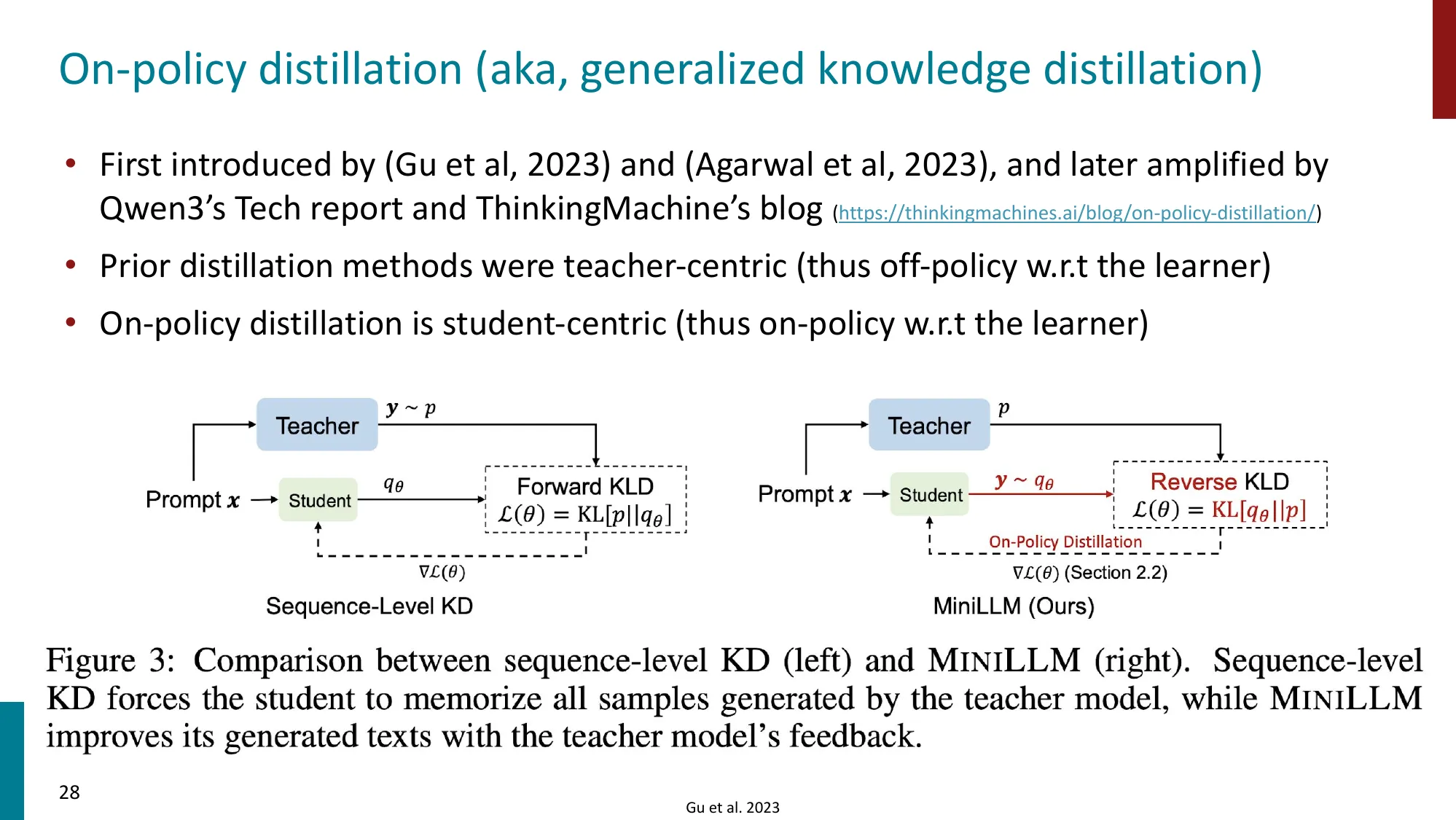


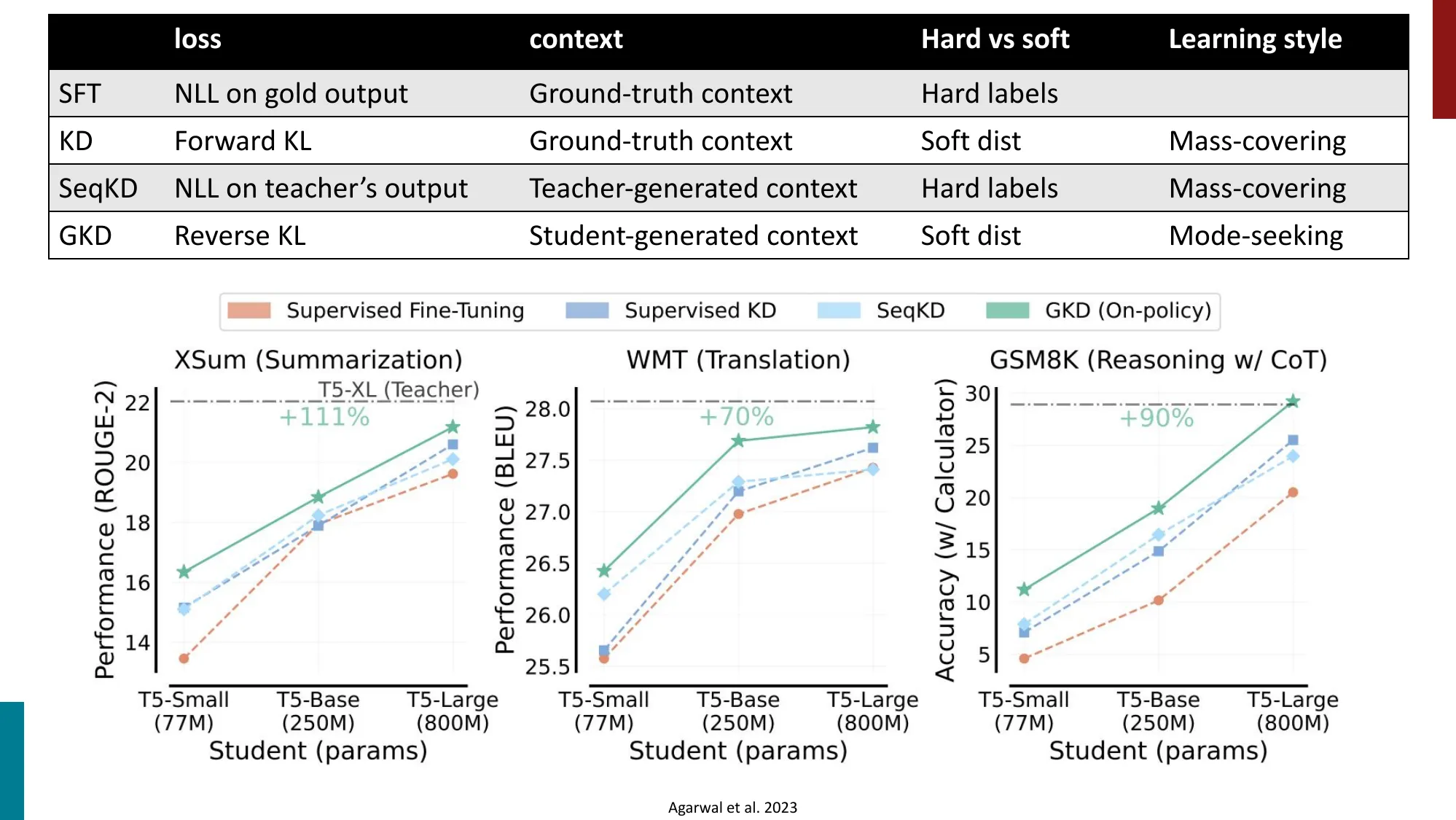

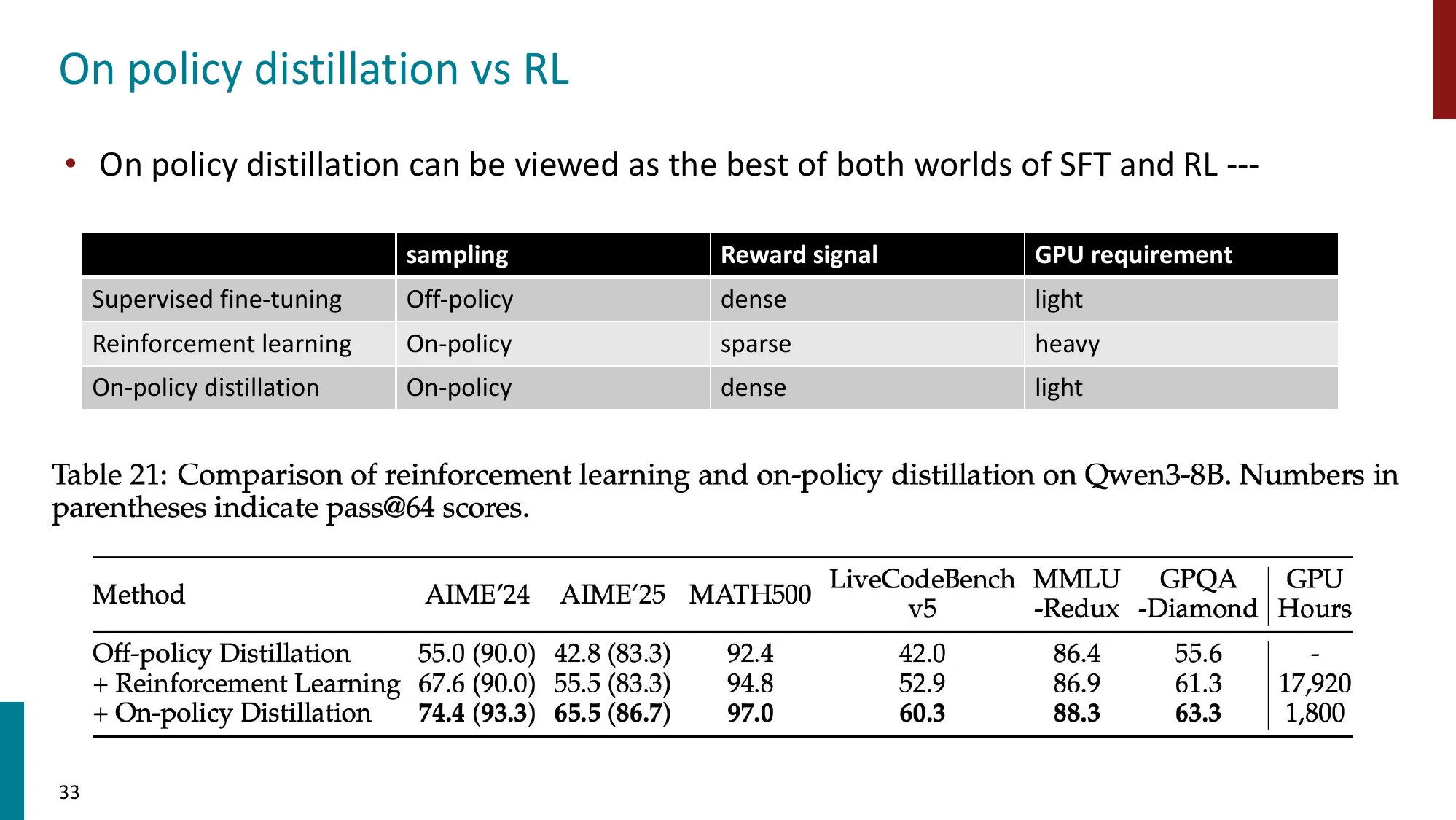

- On-policy vs Off-policy RL
- On-policy:用当前 policy 采样数据训练(新鲜但低效)
- Off-policy:用旧 policy/其他 policy 的数据训练(高效但有偏差)
- RL 基础设施与 Off-policy Drift
- 大规模 RL 训练中 actor 和 learner 不同步导致的分布漂移
- 漂移越大,训练越不稳定
- On-policy Distillation
- 用 teacher 模型的 on-policy 输出蒸馏到 student
🔢 数值计算示例
Off-policy drift 的危害数值示例:
假设某 token 在 下概率 0.01,在 (训练后)下概率 0.1:
IS ratio = 10(高方差,数值不稳定)。未截断时梯度 = ,若 advantage = 2,梯度放大到 20,可能导致梯度爆炸。
PPO clip():,有效梯度 = ,训练稳定。
⚠️ 常见误区
- 误区:off-policy 数据可以无限复用,多用旧数据提高样本效率 → 正确:IS ratio 方差随策略偏移指数增长,复用超过几个 epoch 就会训练不稳定甚至崩溃。实践中通常限制 off-policy 程度(PPO 每批数据只迭代 3-4 次)。
- 误区:On-policy Distillation 和普通 KD(知识蒸馏)一样 → 正确:关键区别在于训练数据是当前学生策略采样的,而非教师生成的固定数据集,这消除了 off-policy drift,但代价是每步推理开销大。
3. Long Context Extension(长上下文扩展)



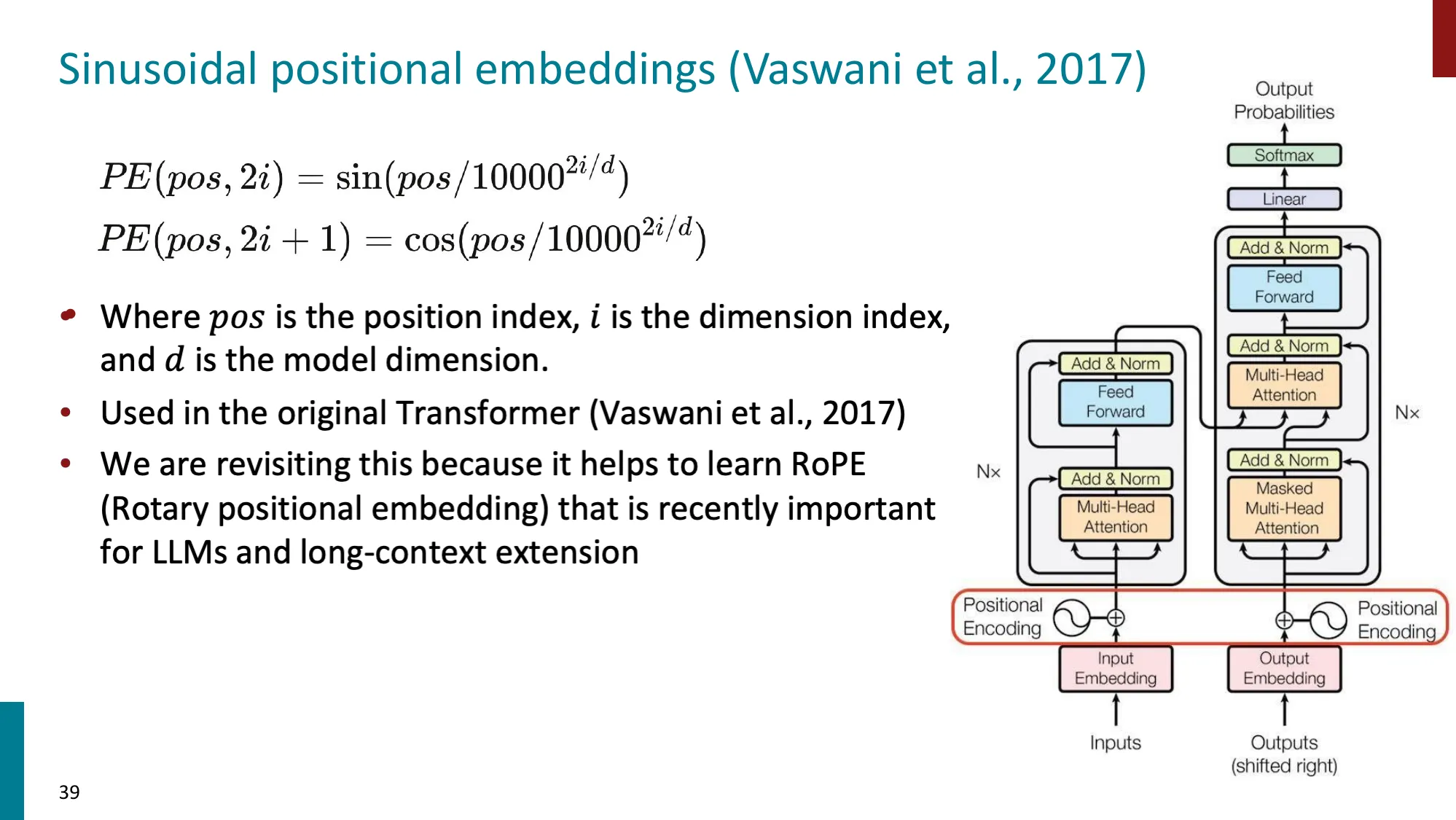
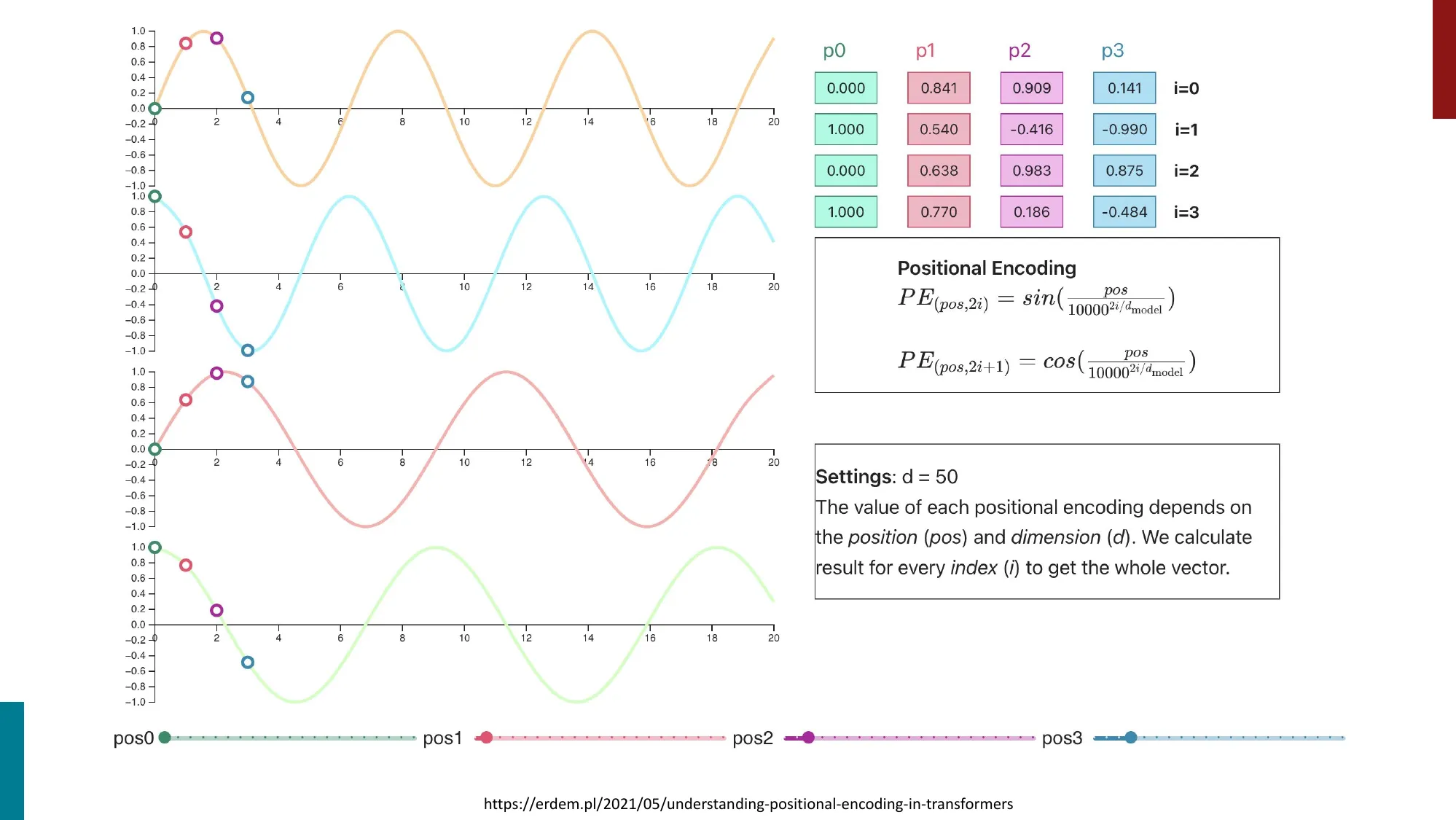


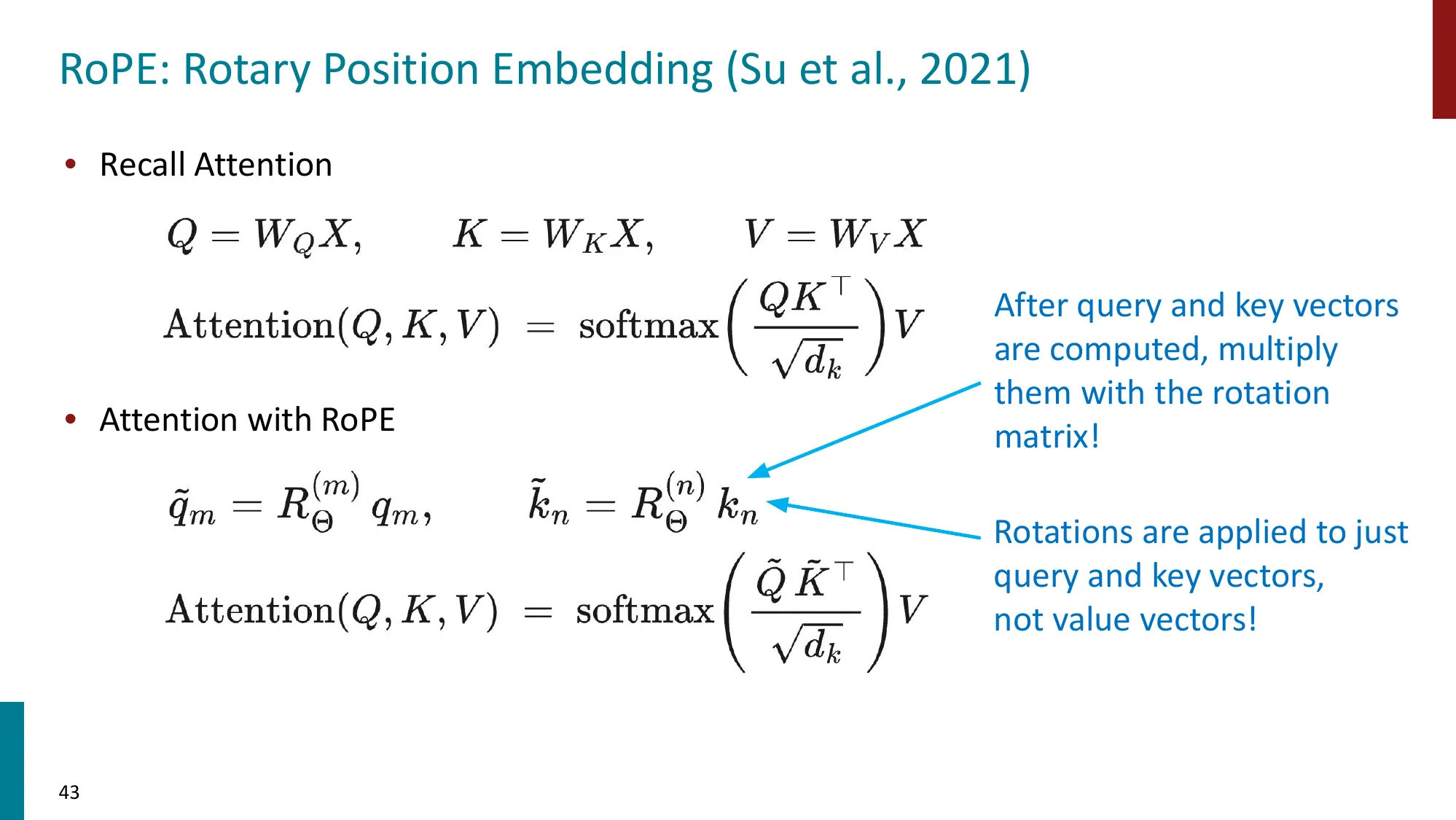
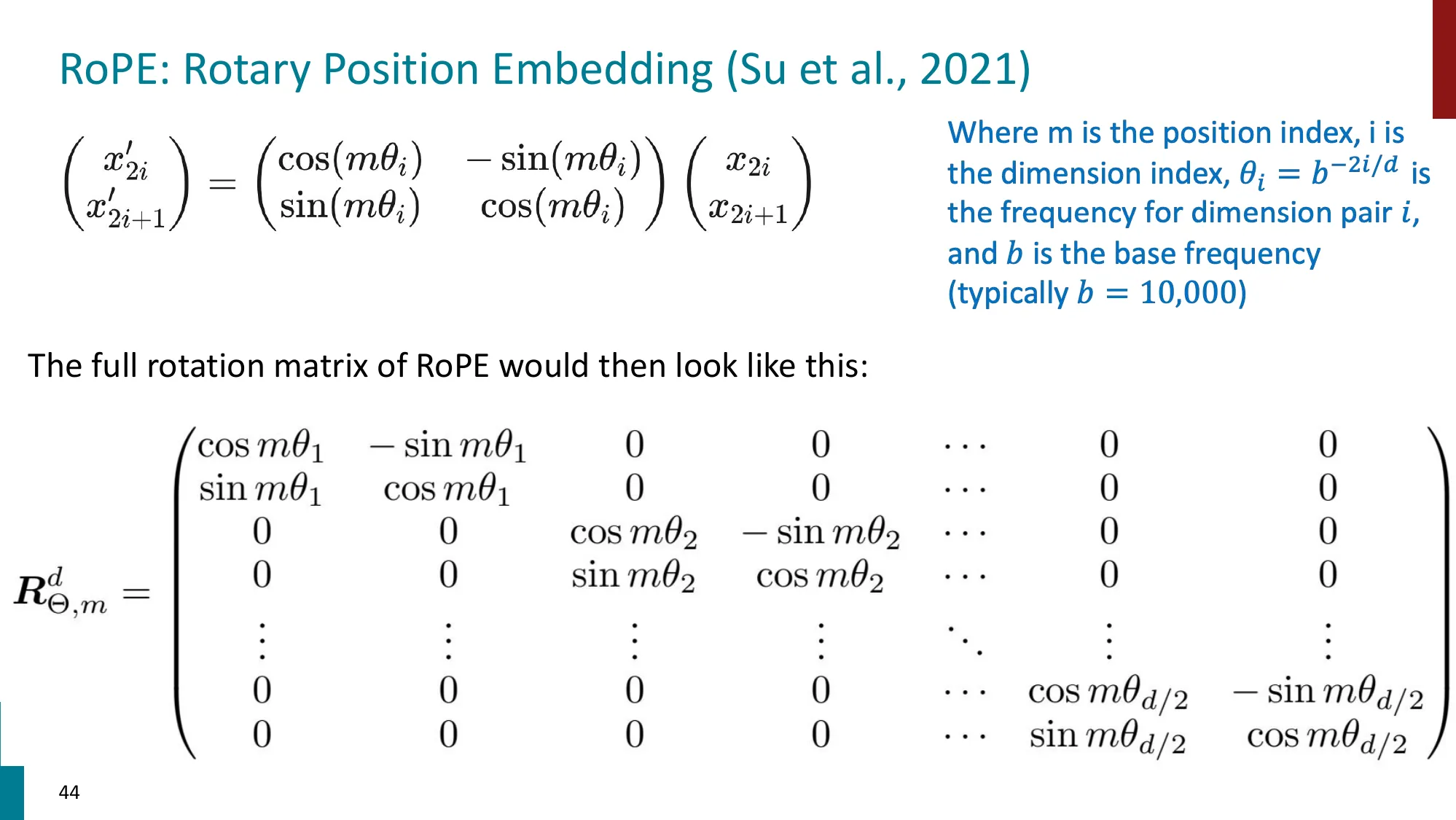
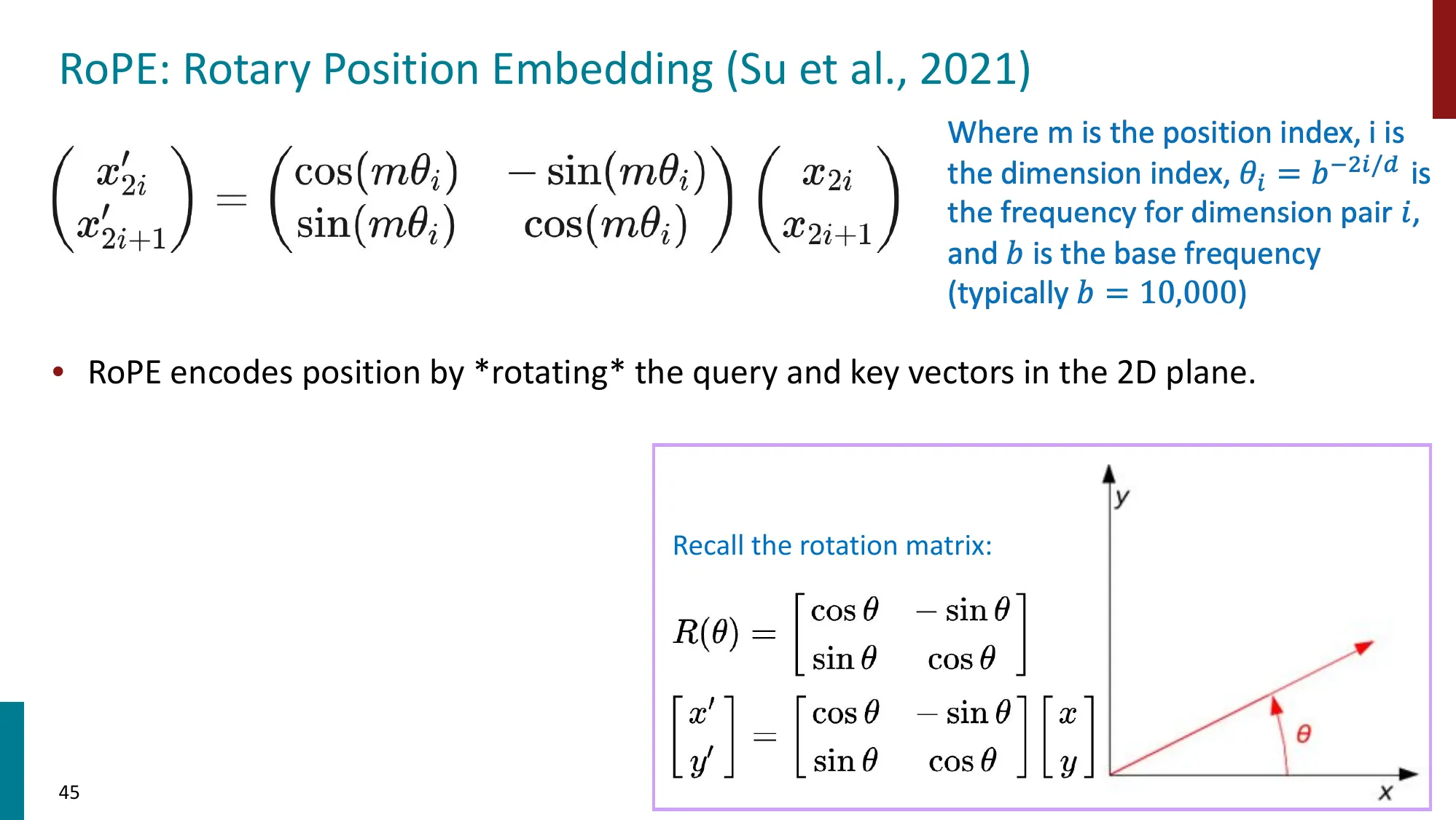

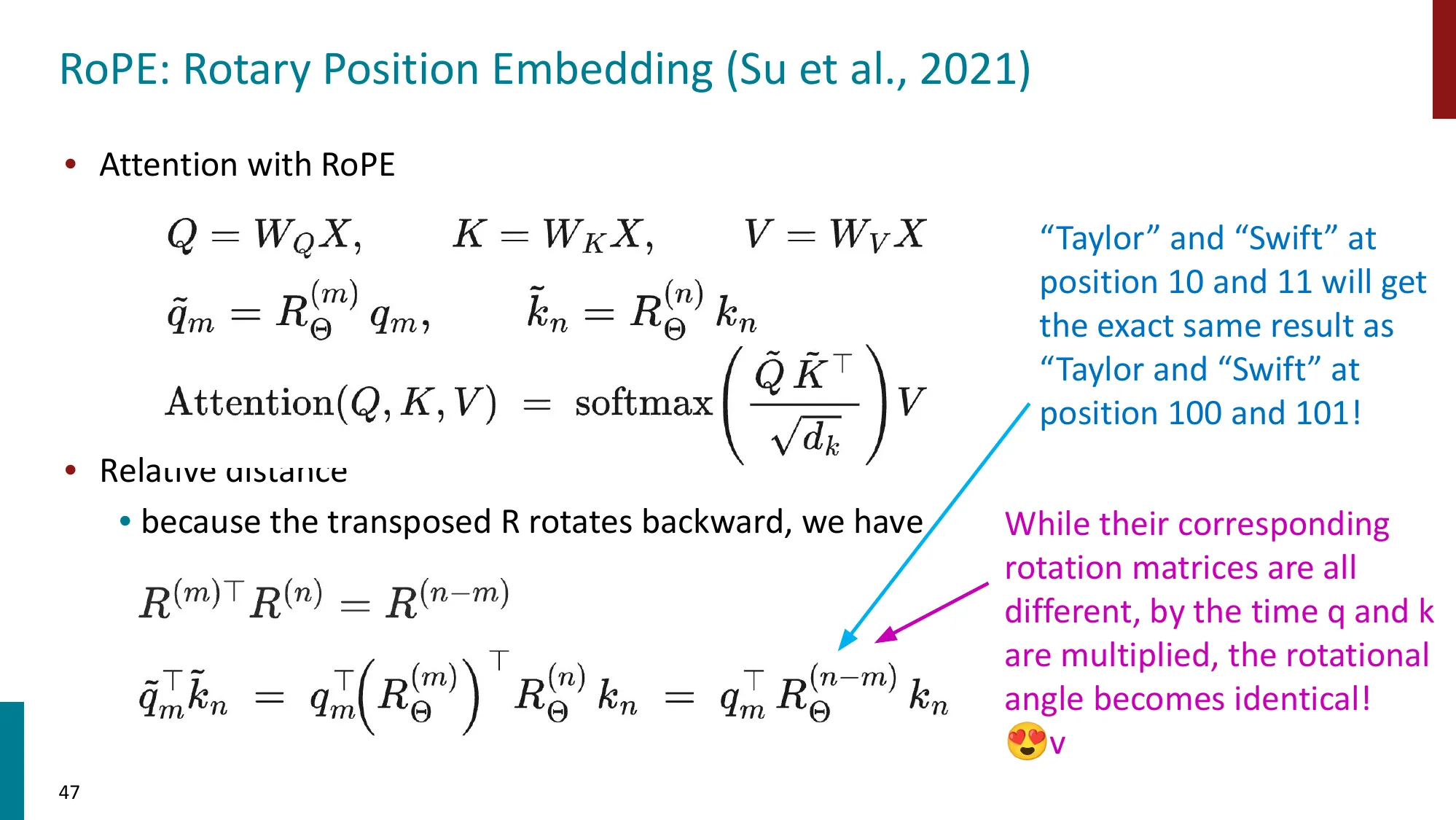





- 扩展 LLM 上下文窗口的技术
- 位置编码外推:RoPE 扩展、ALiBi
- 训练策略:渐进式扩展上下文长度
🔢 数值计算示例
位置插值数值示例:模型训练上下文 ,想扩展到 (4倍)。
PI 缩放因子:
- 原始位置 (超出训练分布)→ 插值后 (在训练范围内 ✓)
- 原始位置 (超出训练分布)→ 插值后 (在训练范围内 ✓)
代价:相邻位置 和 的间隔压缩为 和 (间距缩小4倍),模型需要通过 fine-tune 重新学习精细位置区分。
💡 为什么这样做?
RoPE 用旋转角度编码相对位置,注意力分数只取决于两个 token 的相对角差。训练时模型见过角差范围 ;如果推理时出现更大角差,模型行为未知。Position Interpolation 把所有位置等比压缩,保证任意两点的角差都在训练范围内,用”位置精度略降”换”长度外推稳定”。
⚠️ 常见误区
- 误区:扩展 context window = 获得长文档理解能力 → 正确:长上下文能力 ≠ 长上下文理解能力。Lost in the Middle(Liu et al., 2023)实验表明:即使窗口够大,模型对文档中间部分的注意力显著弱于开头和结尾。窗口够大只是必要条件,不是充分条件。
- 误区:RoPE 外推不需要任何 fine-tune → 正确:直接外推(不做任何修正)在超出训练长度时通常性能骤降;PI 和 YaRN 都需要少量 fine-tune(通常几百步即可)才能稳定。
4. Inference-time Scaling(推理时缩放)


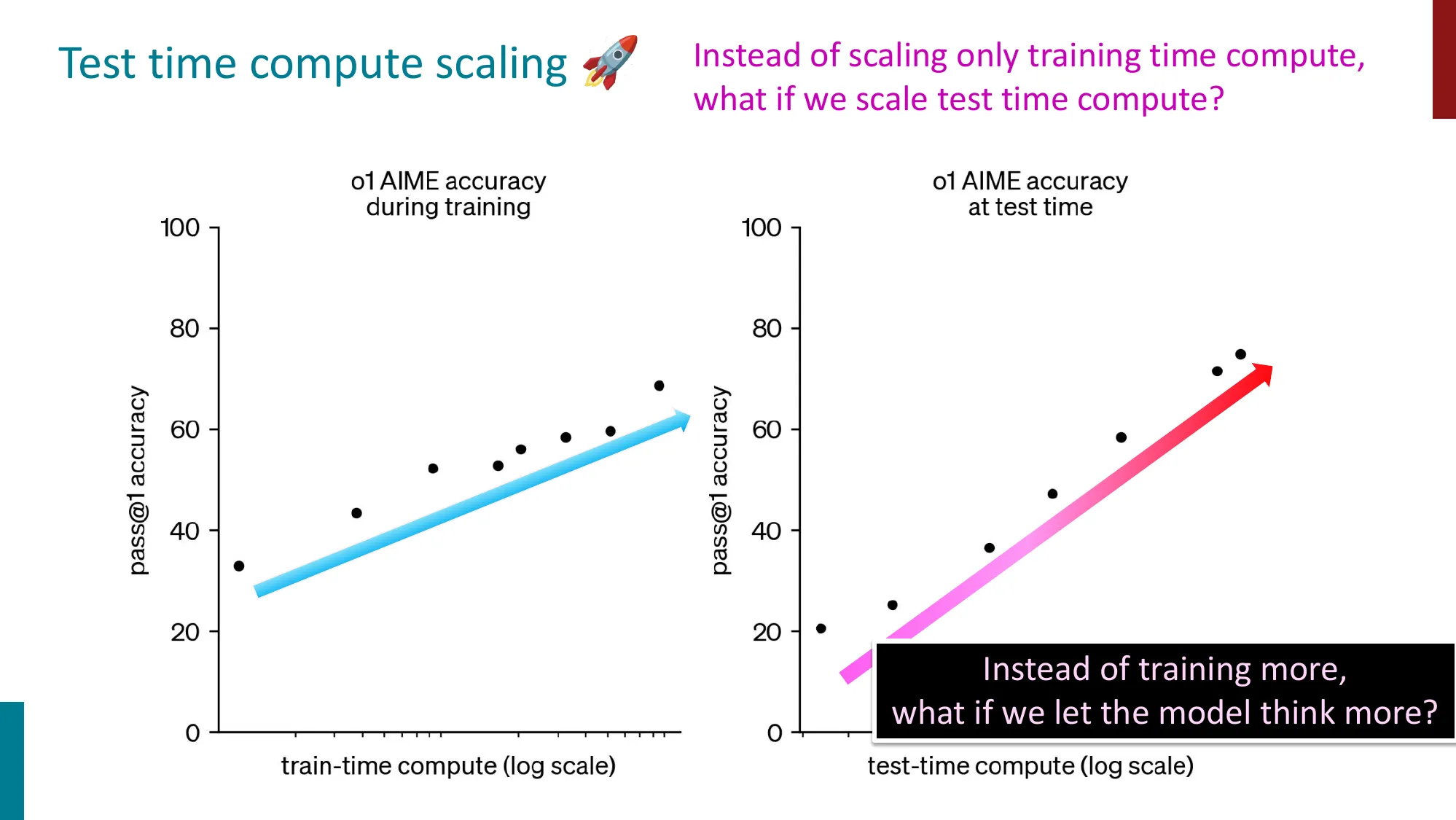


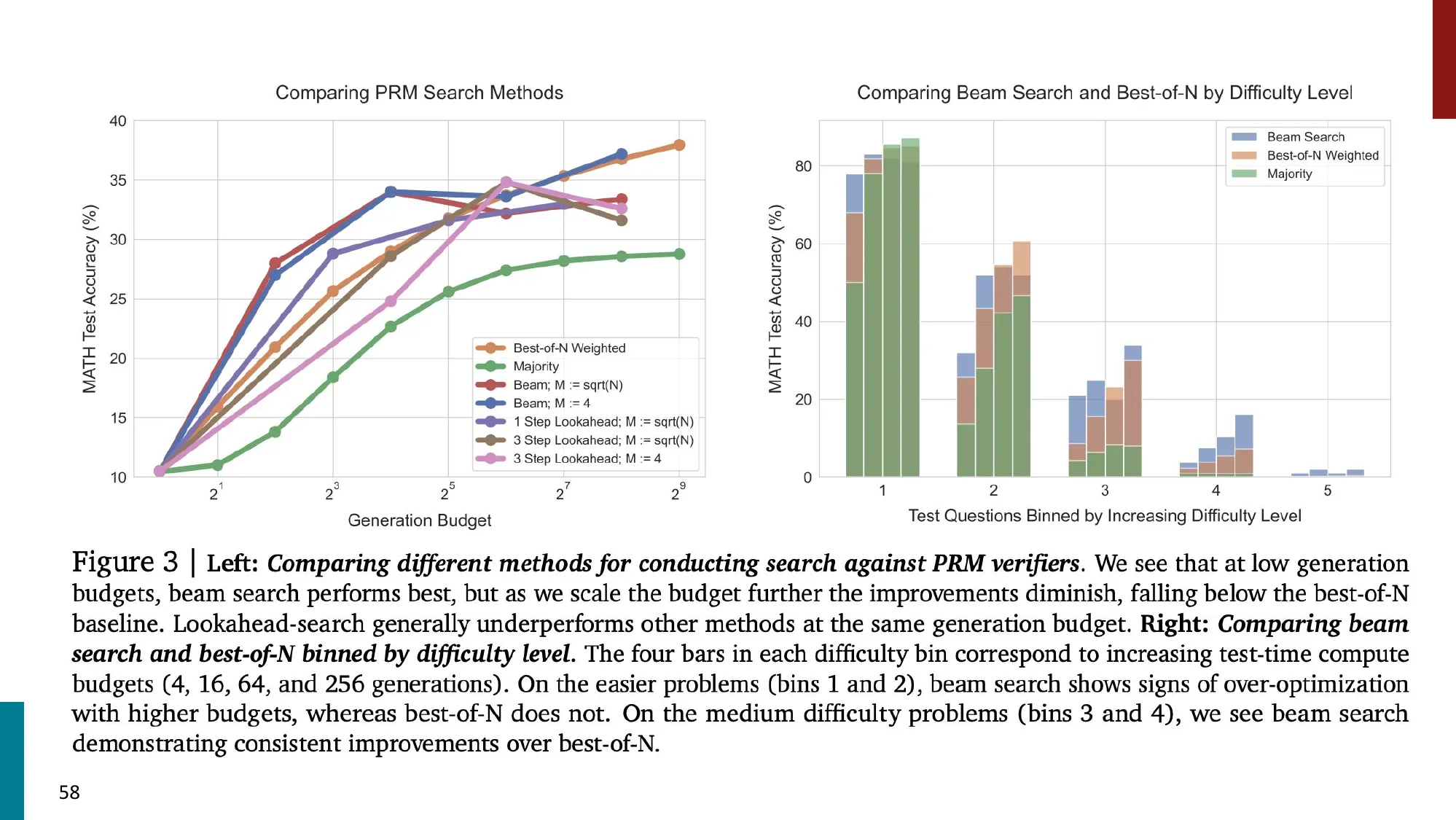

- 核心思想:在推理时投入更多计算以提升性能
- Best-of-N sampling + reward model
- 多次采样 + 投票(Self-Consistency)
- 推理时计算与训练时计算的权衡
- Test-Time-Compute-Scaling
🔢 数值计算示例
OpenAI o1/o3 的推理时缩放数据(近似):
- AIME 2024 数学竞赛题:o1 单次采样 ,Best-of-N()可达
- 这说明推理能力的瓶颈部分在于”试够多次”,而非”单次能力上限”
- 换个角度:把推理预算(compute budget)全押在”更大模型”不如”更多尝试 + 验证”
💡 为什么这样做?
推理时 scaling 是在”用计算换准确率”——把推理预算(compute budget)用于”多尝试”而非”更大模型”。对于有明确正误判断的任务(数学、代码),可以自动判断哪个答案”最好”,Best-of-N 效果显著。这也是 o1/o3 类模型的核心思路:在推理时做更多”思考”(longer chain-of-thought + 多次采样),而非单纯靠更大模型。
⚠️ 常见误区
- 误区:推理时 scaling 普遍有效,对所有任务都适用 → 正确:在有明确验证函数的任务(数学、代码)效果很好;对开放式生成(创意写作、对话)难以定义”最好”,奖励模型评分不可靠,不要把数学上的成功推广到所有任务。
- 误区:推理时 scaling 和训练时 scaling 是竞争关系 → 正确:二者互补。训练好的基础模型是推理时 scaling 的前提;同等算力下,小模型 + 大量推理搜索有时能超越大模型单次采样,但不能替代大模型的知识和能力上限。
推荐阅读
- Lets-Verify-Step-by-Step — Lightman et al., 2023
- Speculative-Decoding-Paper — Chen et al., 2023; Leviathan et al., 2022
- Test-Time-Compute-Scaling — Snell et al., 2024