L12: Reasoning 1/2
Week 6 · Thu Feb 12 2026 08:00:00 GMT+0800 (中国标准时间)
L12: Reasoning 1/2
- Lecturer: Yejin Choi
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
1. 解码技术(Decoding Techniques)
基础解码算法


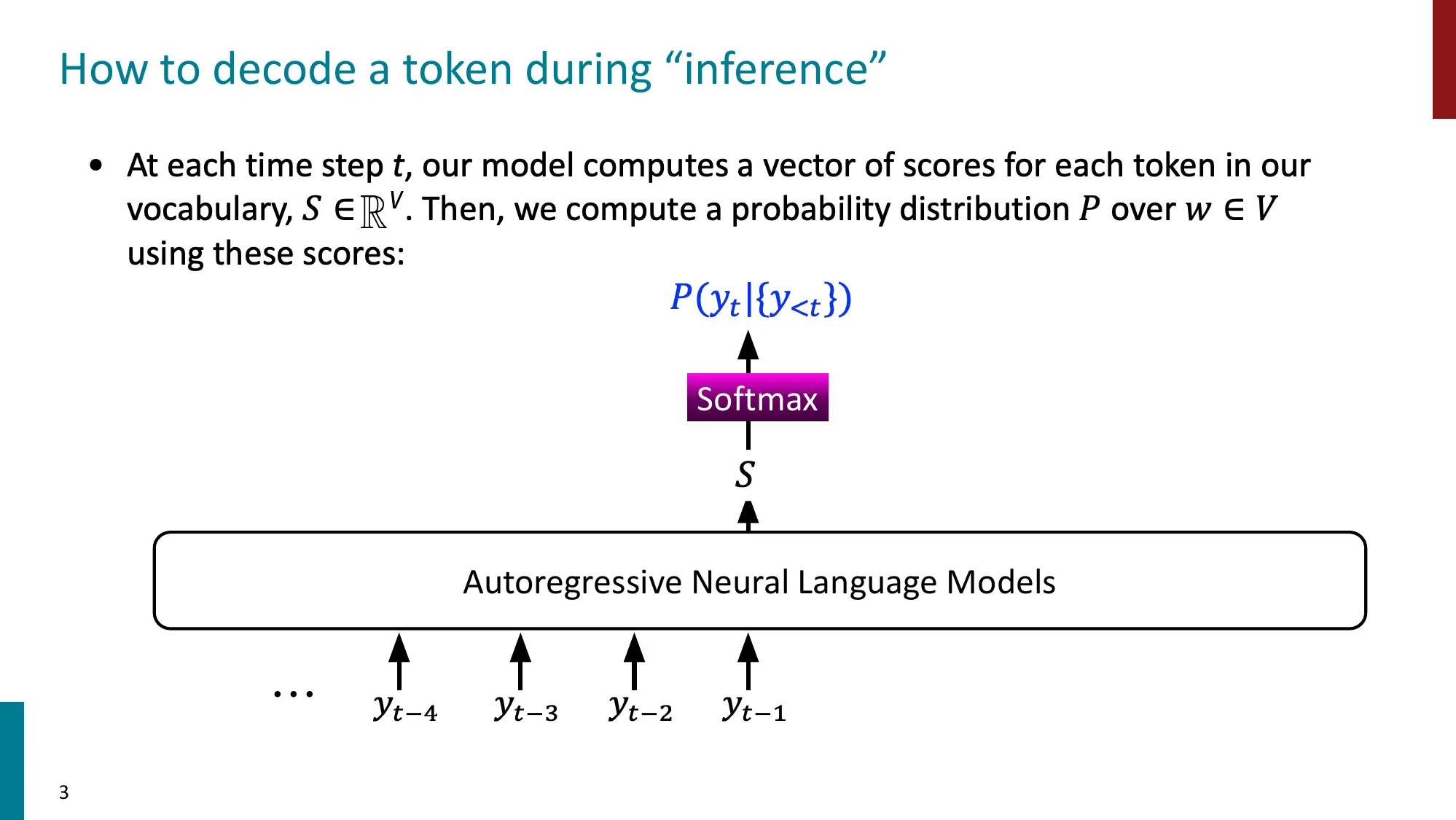
- Greedy decoding:每步选最高概率 token,局部最优但可能全局次优
- Beam search:保持 top-k 个候选序列,经典 NLP 标准方法,但现代 LLM 较少使用
- Beam search (k=1) = Greedy decoding
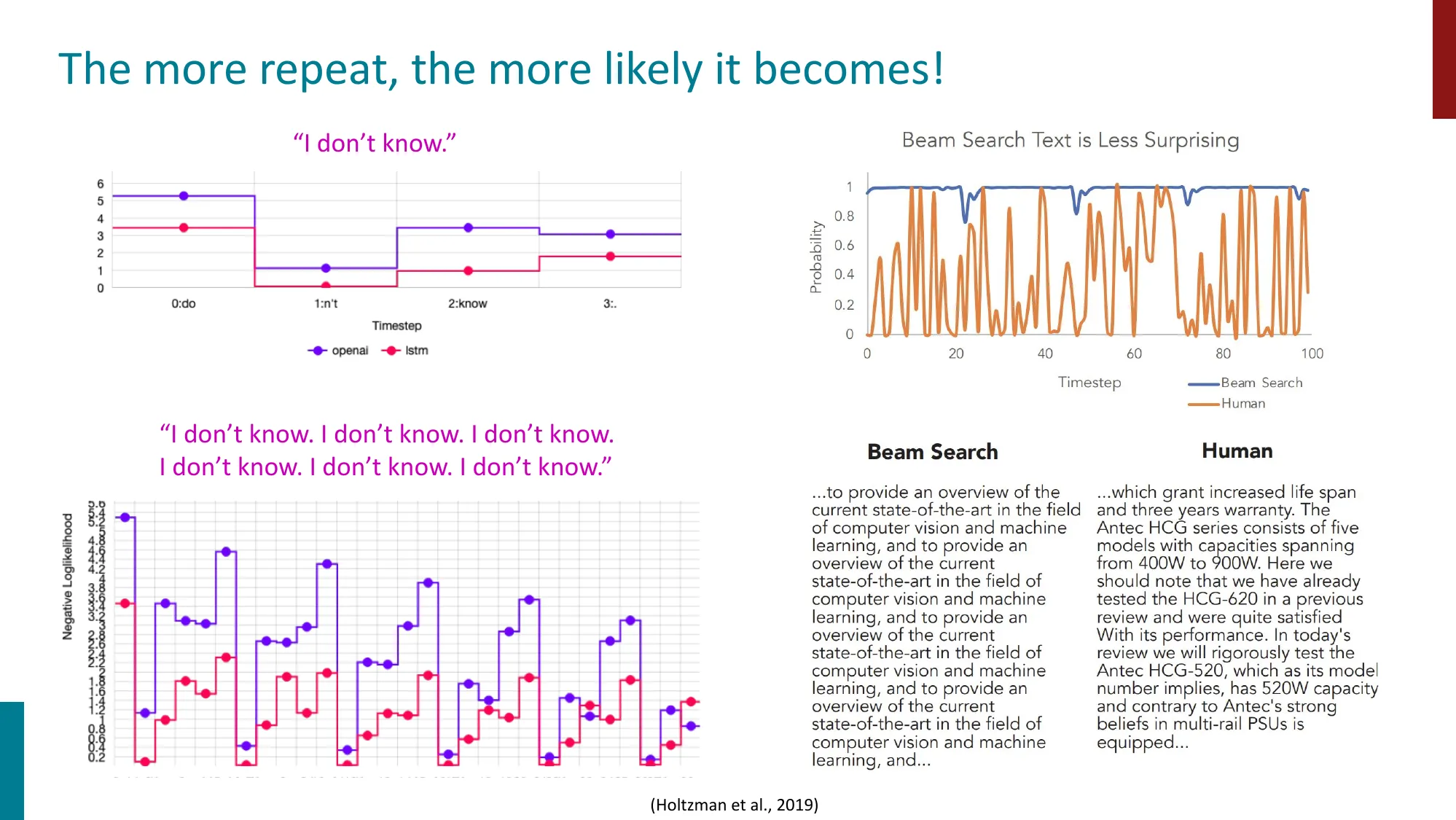
神经文本退化(Neural Text Degeneration)




- Holtzman et al., 2019: 最可能的序列往往重复退化
- Beam search 生成重复文本,纯采样生成不连贯文本
- 重复越多越可能:陷入重复循环后概率持续上升
采样方法



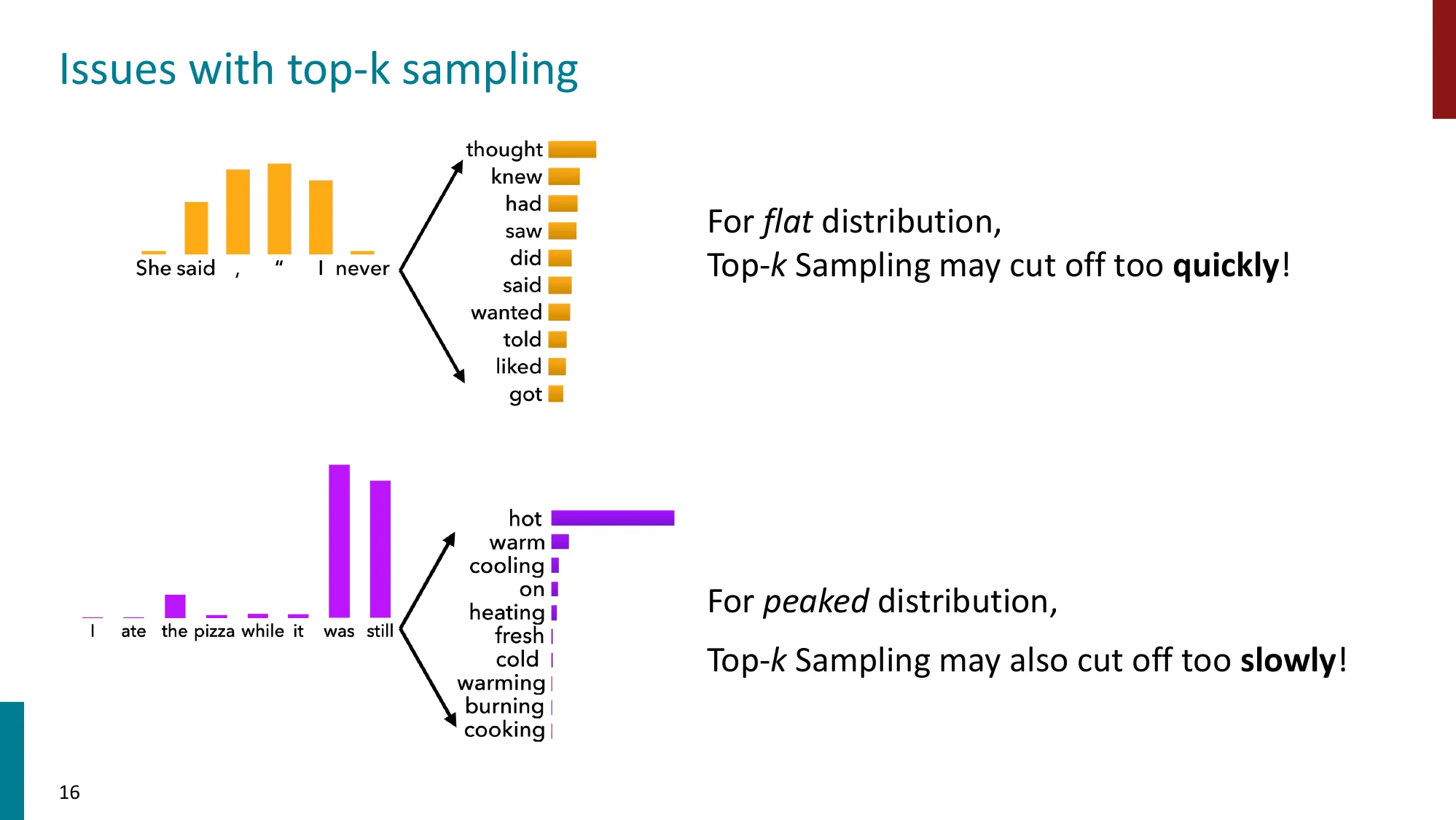
- Top-k sampling(Fan et al., 2018):只从概率最高的 k 个 token 中采样
- 问题:对平坦分布截断太快,对尖锐分布截断太慢
- Top-p (Nucleus) sampling(Holtzman et al., 2019):从累积概率达到 p 的最小 token 集中采样
- 自适应地调整候选集大小
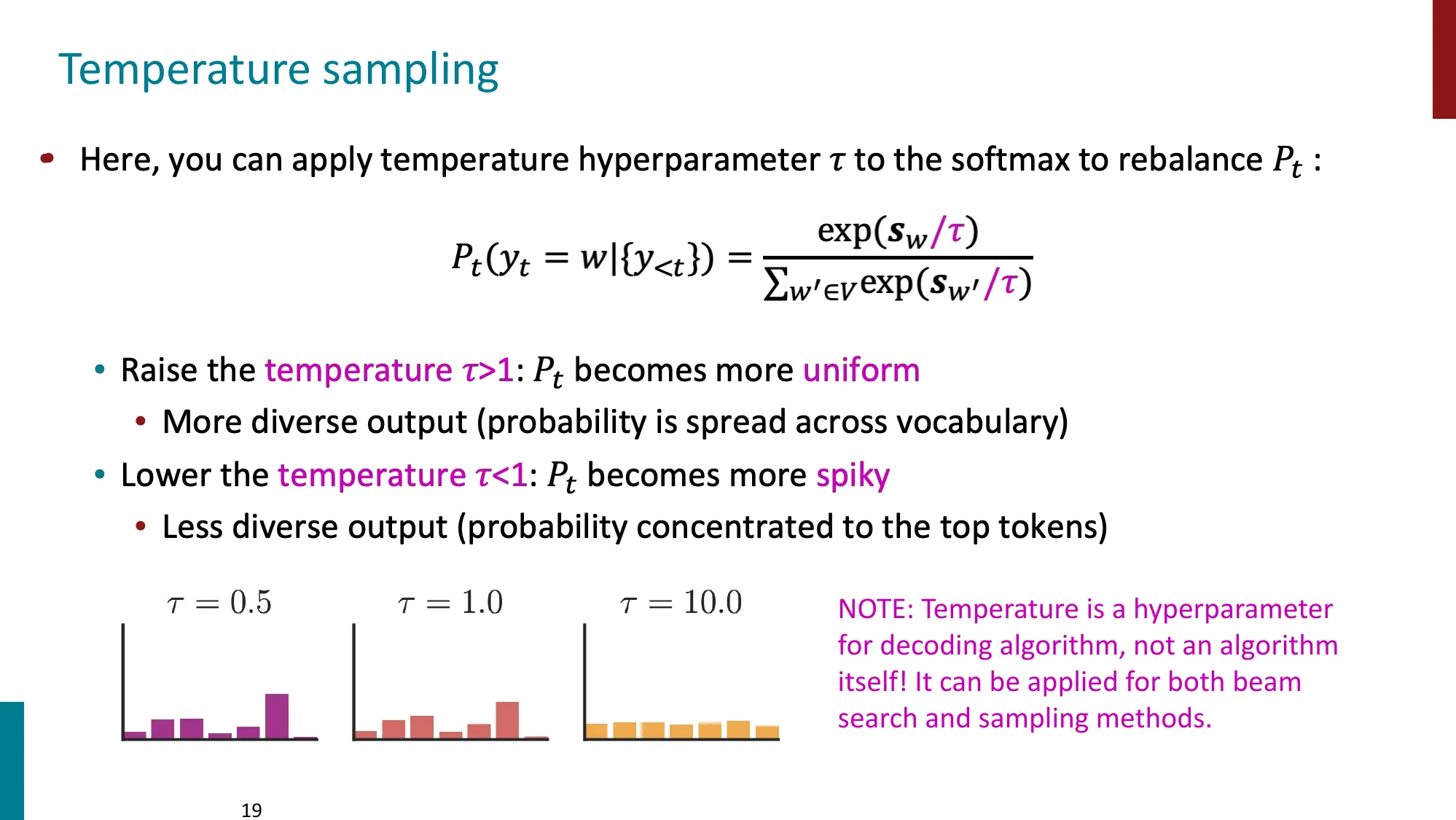
- Temperature sampling:
- :更均匀(更多样化)
- :更尖锐(更确定)
- 温度是超参数,可与任何采样/搜索方法组合
何时用 Greedy vs Sampling




- Greedy:确定答案的任务(数学、代码、事实 QA)
- Sampling:开放式生成(创作、对话、长 CoT 推理)
- Best-of-N Sampling:采样 N 个输出,用 reward model 选最好的(rejection sampling)
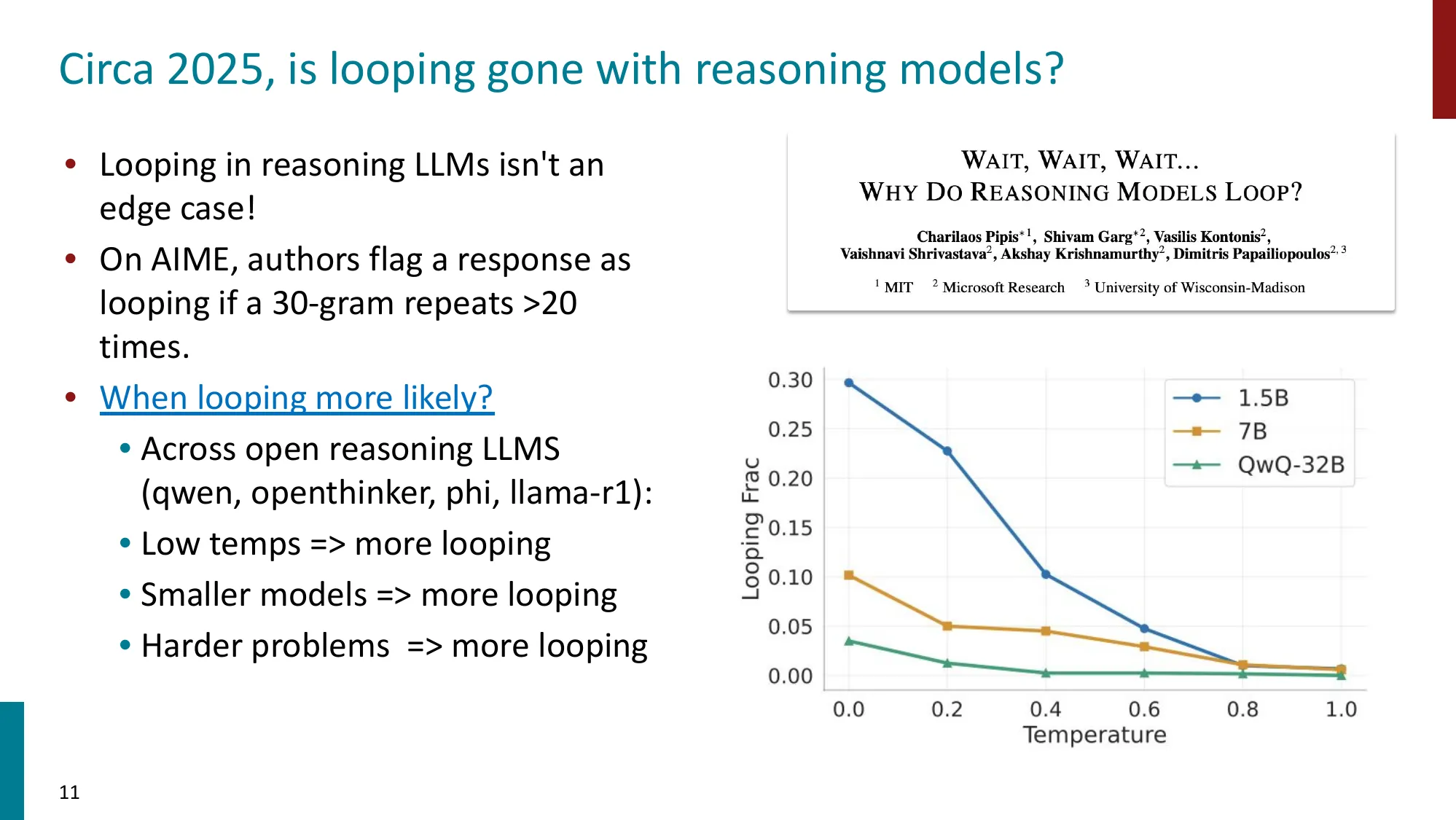
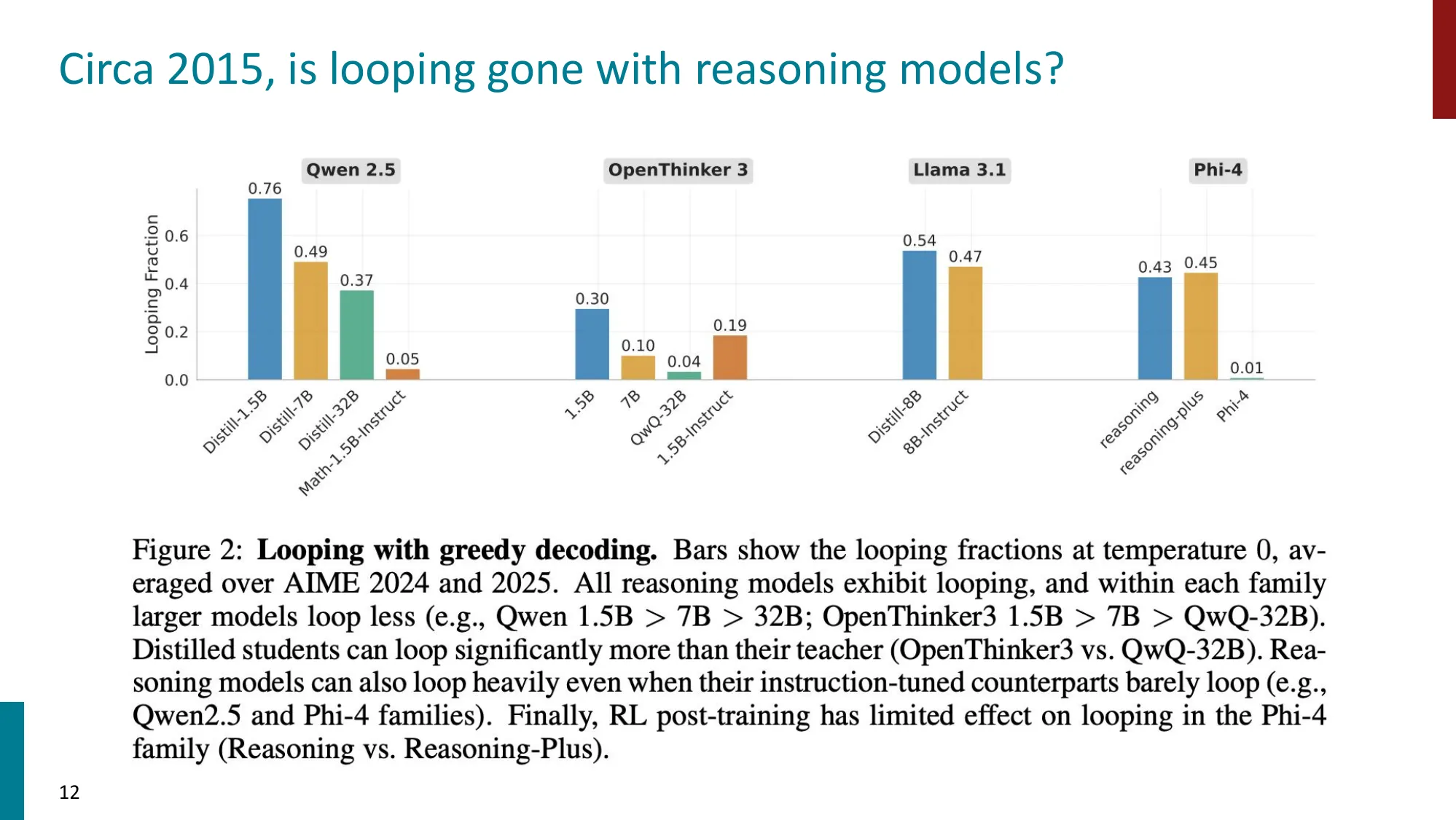
推理模型中的循环问题(2025)


- 推理 LLM 的循环不是边缘情况(AIME 上 30-gram 重复 >20 次)
- 小模型更容易循环、低温更容易循环、难题更容易循环
- 循环更加微妙:语义级别重复而非简单词汇重复
📐 主要解码策略的数学定义
Greedy Decoding:
Beam Search(束宽 ,带长度归一化):
每步保留联合分数最高的 条路径,最终从 条完整序列中选最优。
Temperature Sampling:
- :趋向 greedy(最确定);:趋向均匀(最随机);:原始分布
Top-p (Nucleus) Sampling:
按概率降序排列词汇,取累积概率刚超过 的最小集合,再在此集合内按归一化概率采样。自适应调整候选集大小——分布尖锐时 小,分布平坦时 大。
📚 已收录至 拓展阅读知识库
🔢 Beam Search()一步展开示例
当前维护 3 条假设(平均 log prob 分数):
| 假设 | 当前文本 | 分数 |
|---|---|---|
| H1 | ”The cat” | -0.50 |
| H2 | ”A dog” | -0.80 |
| H3 | ”The dog” | -0.90 |
下一步 top-3 扩展词:sat (-0.7)、ran (-1.0)、jumped (-1.3)
展开 条路径,取累积分数最高的 3 条继续。长度归一化防止模型偏好短序列。
⚠️ 常见误区
- 误区:Beam Search 总是比 Greedy 好 → 正确:Beam Search 生成文本往往”太完美”但缺乏多样性,容易产生重复。对话/创意写作应该用 sampling;翻译/代码生成用 beam search。
- 误区:Temperature 越高生成质量越好(“更有创意”) → 正确:Temperature 过高会让模型忽略语言建模学到的概率分布,产生不连贯的随机噪声。通常 是创意任务的合理区间,超过 1.2 风险较大。
2. DeepSeek-R1 深度解析

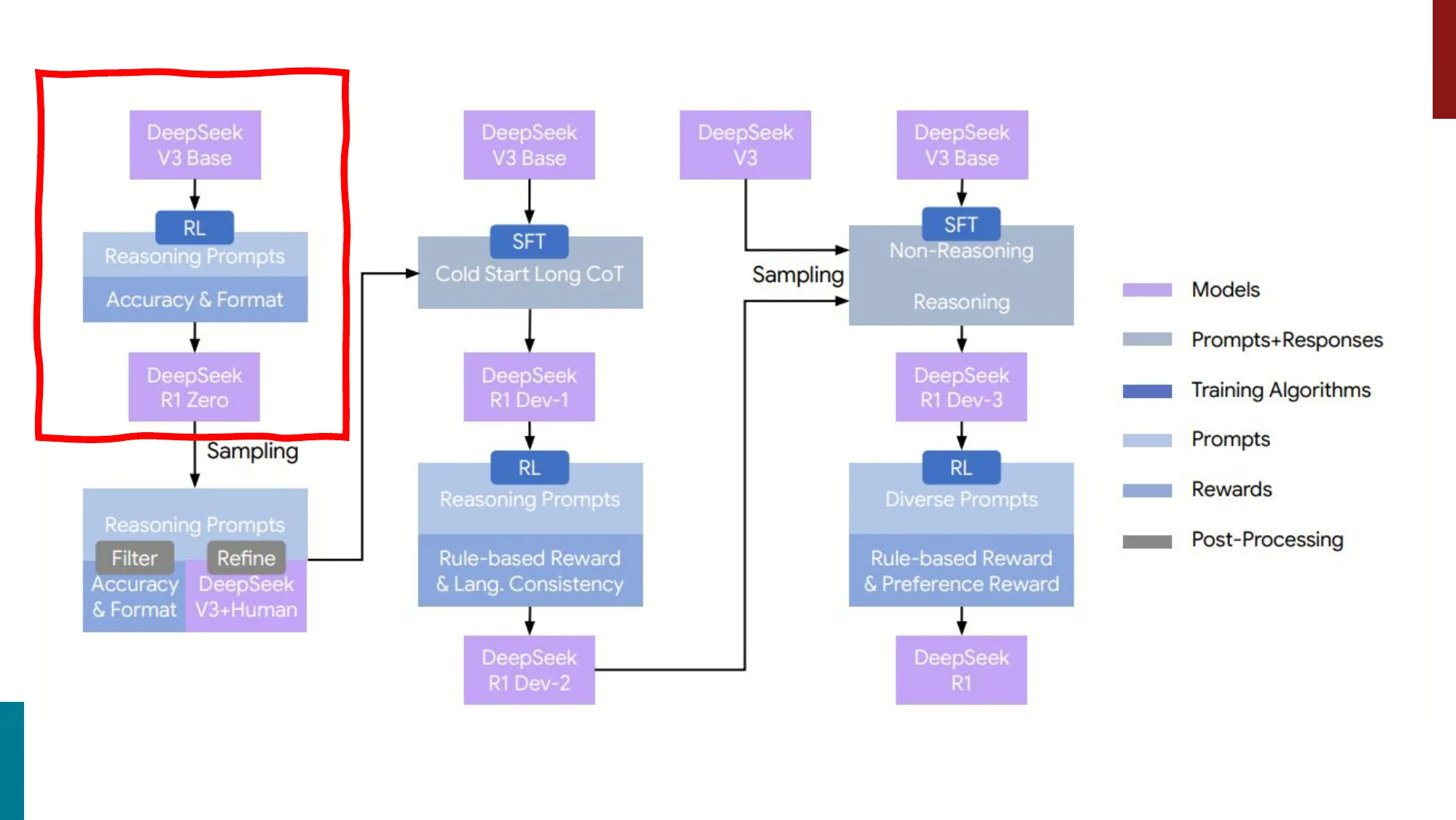




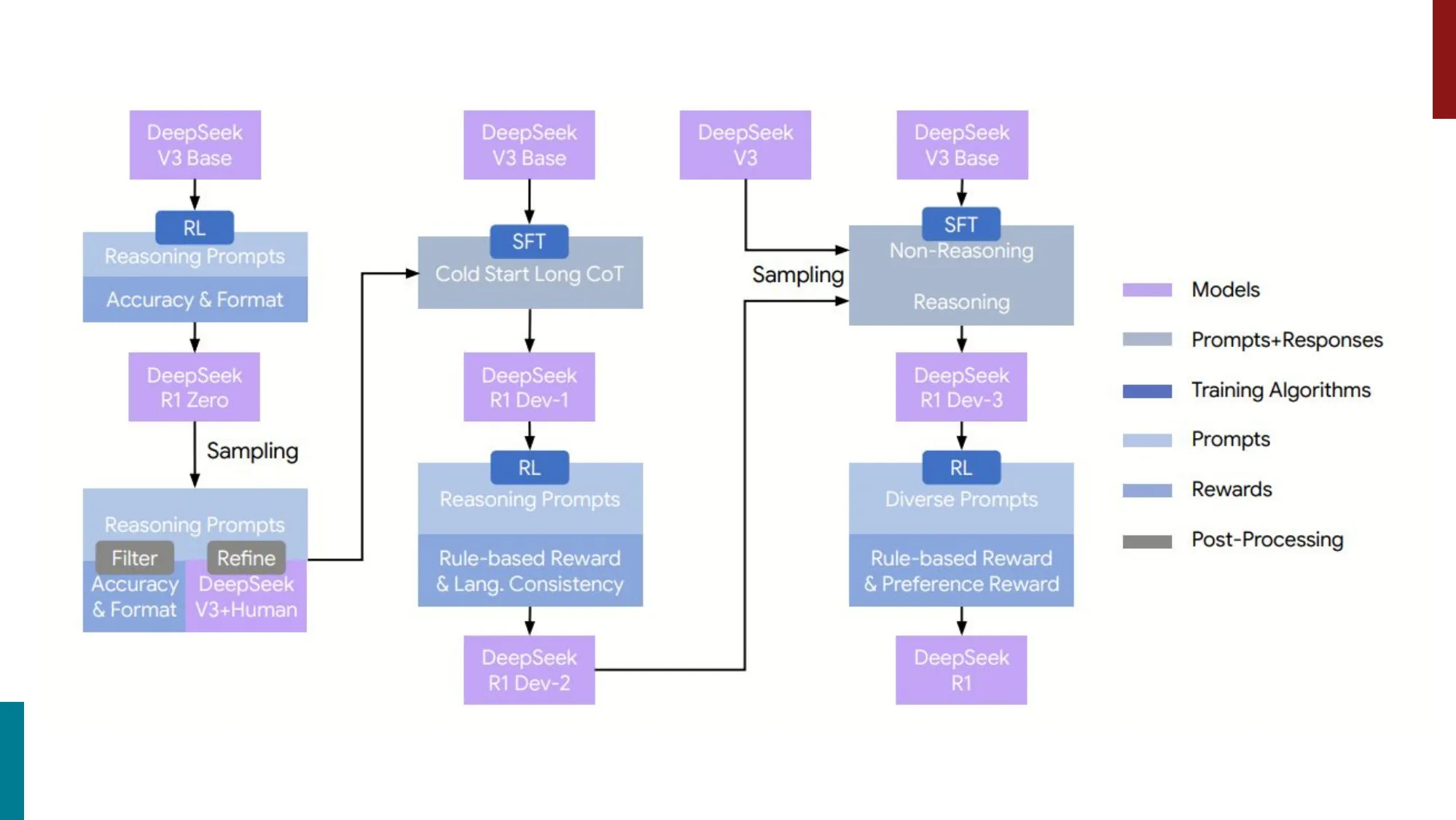






- R1-Zero:纯 RL 训练(无 SFT),从 base model 出发用 GRPO + 规则 reward
- 涌现出自主 CoT 推理、反思、验证行为
- 问题:可读性差、语言混杂
- R1:先 cold-start SFT(少量高质量 CoT 数据),再 RL
- 多阶段流水线:Cold-start SFT -> RL -> Rejection Sampling SFT -> 第二轮 RL
- R1-Distill:将 R1 的推理能力蒸馏到小模型(1.5B-70B)
- 蒸馏后的小模型在推理基准上超过同规模非蒸馏模型
📐 DeepSeek-R1 四阶段训练流程
Stage 1:Cold Start SFT
用少量(数千条)人工筛选的 (prompt, long CoT, answer) 做监督微调,目的是让模型学会基本的”思考”格式(<think>...</think> 标签结构),避免后续 RL 从完全混乱的输出起步。
Stage 2:RL for Reasoning(核心阶段)
使用 GRPO 做纯 RL 训练,奖励函数只依赖最终答案:
关键:不使用 Process Reward Model(PRM),只验证最终结果。对于数学题用精确匹配,代码题用单元测试执行。
Stage 3:Rejection Sampling SFT
对 Stage 2 的模型大规模采样,过滤出高质量推理路径(答案正确 + CoT 合理),混合通用能力数据,重新做 SFT。这一步修复了 R1-Zero 的语言混杂问题。
Stage 4:General RLHF
在 Stage 3 的 SFT 模型上继续 RLHF,覆盖安全对齐、指令遵循等通用能力,得到最终的 R1。
📚 已收录至 拓展阅读知识库
🔢 DeepSeek-R1 在 AIME 2024 上的对比
AIME 2024(美国邀请数学考试,极难):
| 模型 | 类型 | Pass@1 |
|---|---|---|
| GPT-4o(2024-11) | 非推理 | 9.3% |
| DeepSeek-V3 | 非推理 | 39.2% |
| o1-2024-12-17 | 推理 | 79.2% |
| DeepSeek-R1 | 推理 | 79.8% |
R1 与 OpenAI o1 性能相当,但完全开源(模型权重 + 训练方法)。R1 比 V3 高出 40%+,体现了推理训练的巨大价值。
⚠️ 常见误区
- 误区:RL 让模型”从零学会推理” → 正确:RL 只能强化模型已有的推理能力,并引导模型更有效地探索正确推理路径。极小模型(<1B)即使做 RL 也无法涌现推理能力——base model 的容量是前提。
- 误区:R1 的成功可以直接复制到任意任务 → 正确:R1 的规则奖励(精确答案匹配)只适用于有明确正确答案的任务(数学、代码)。对于开放式对话、写作等任务,构建可靠的奖励信号极其困难,直接套用 R1 的方法论不可行。
3. PPO & GRPO & DAPO
PPO 解剖

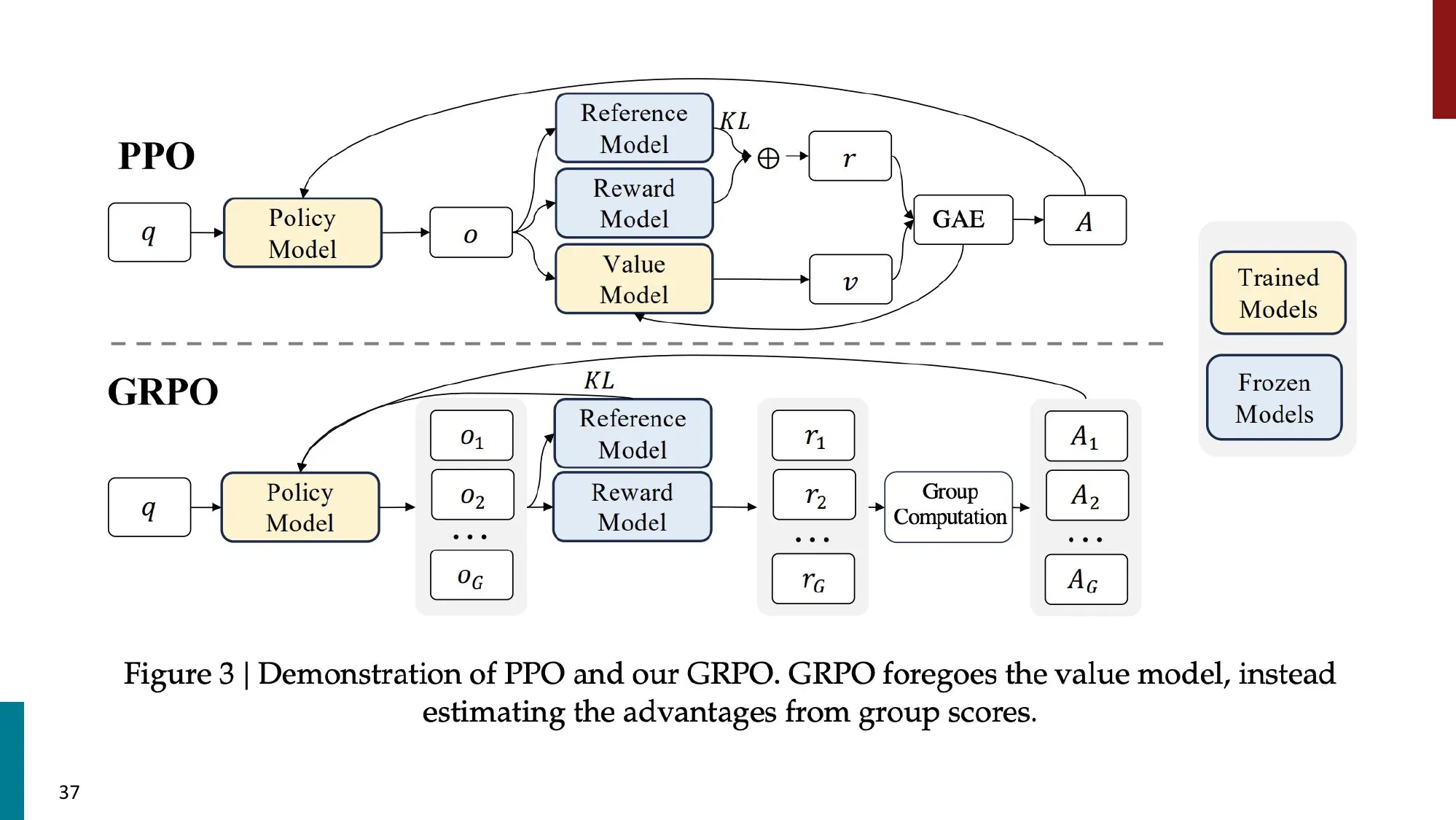






- 4 个模型:Policy + Reference + Reward + Value
- PPO-clip loss + KL penalty + Value MSE loss
GRPO


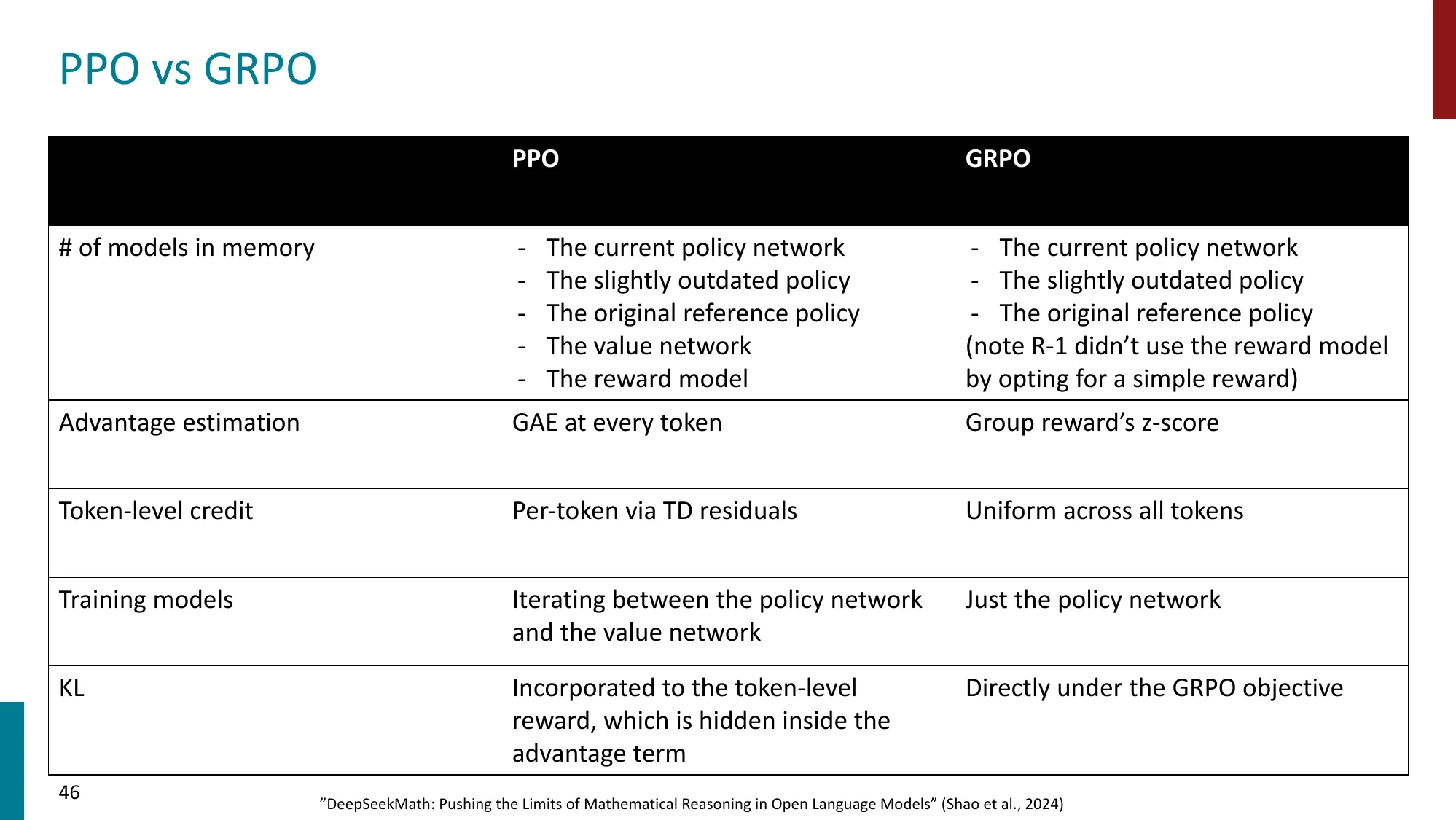
- 去掉 Value Model,用组内 reward 均值和标准差归一化 advantage
- 更简洁高效
DAPO(Decoupled Alignment and Policy Optimization)



- 多项改进:Clip-Higher、Dynamic Sampling、Token-level Loss、Overlong Reward Shaping
📐 PPO / GRPO / DAPO 核心差异
PPO(近端策略优化)——需要 4 个模型:
其中 是重要性采样比, 由 GAE(广义优势估计)+ 价值网络计算。需要:策略网络、参考模型、奖励模型、价值网络(4 个)。
GRPO(组相对策略优化)——去掉价值网络,只需 2 个模型:
对同一问题 采样 个回答 ,用组内统计替代价值网络:
DAPO(动态采样策略优化)——解决 GRPO 的 entropy collapse:
GRPO 训练后期模型探索不足(总是采样相似回答,,梯度消失)。DAPO 引入:
- Clip-Higher:上下界不对称(,),鼓励探索
- Dynamic Sampling:过滤掉全对/全错的 batch(,梯度为零,纯浪费计算)
- Token-level Loss:loss 按 token 平均而非按序列平均,避免短序列主导梯度
📚 已收录至 拓展阅读知识库
🔢 GRPO 采样计算示例
问题 :“2的10次方是多少?“,采样 个回答:
| 回答 | 是否正确 | |
|---|---|---|
| :1024,正确 | ✓ | 1.0 |
| :512,错误 | ✗ | 0.0 |
| :1024,正确 | ✓ | 1.0 |
| :2048,错误 | ✗ | 0.0 |
,
归一化优势:,
梯度方向:增大 的概率,减小 的概率。
Dynamic Sampling 的意义:若 4 个回答全对(),,梯度为零,GRPO 会浪费这个 batch 的计算。DAPO 直接跳过此类 batch,从更有信息量的问题中学习。
⚠️ 常见误区
- 误区:(每问题采样数)越大越好 → 正确: 太小()方差大, 太大()计算代价高且边际收益递减。实践中 是常用值,需要在计算预算和方差之间权衡。
- 误区:GRPO 完全取代 PPO → 正确:GRPO 去掉价值网络的代价是优势估计方差更大(只用组内统计,而非全局价值函数)。对于需要精细信用分配(credit assignment)的长序列任务,PPO 的价值网络仍有优势。
4. “推理” 的本质


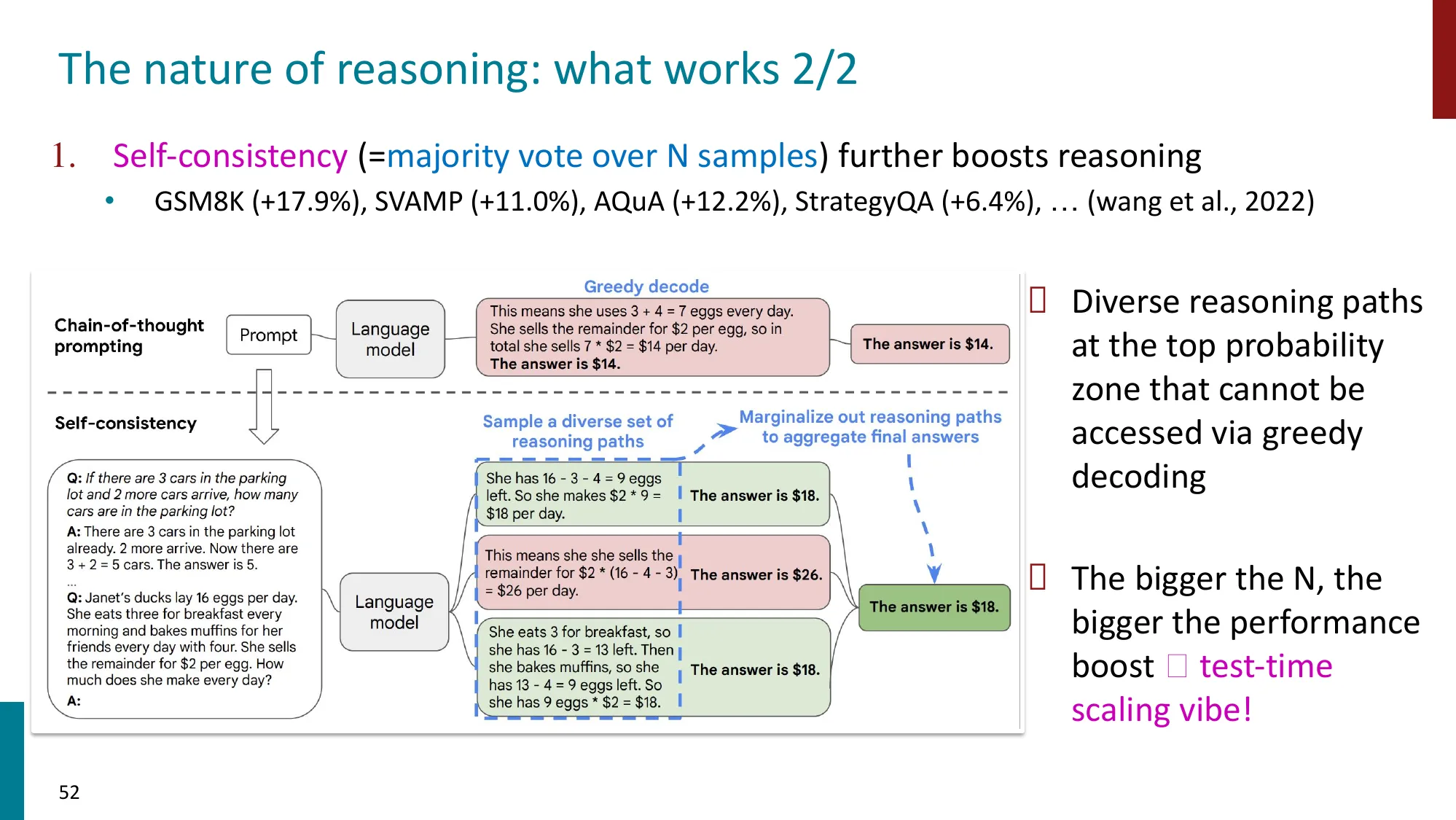







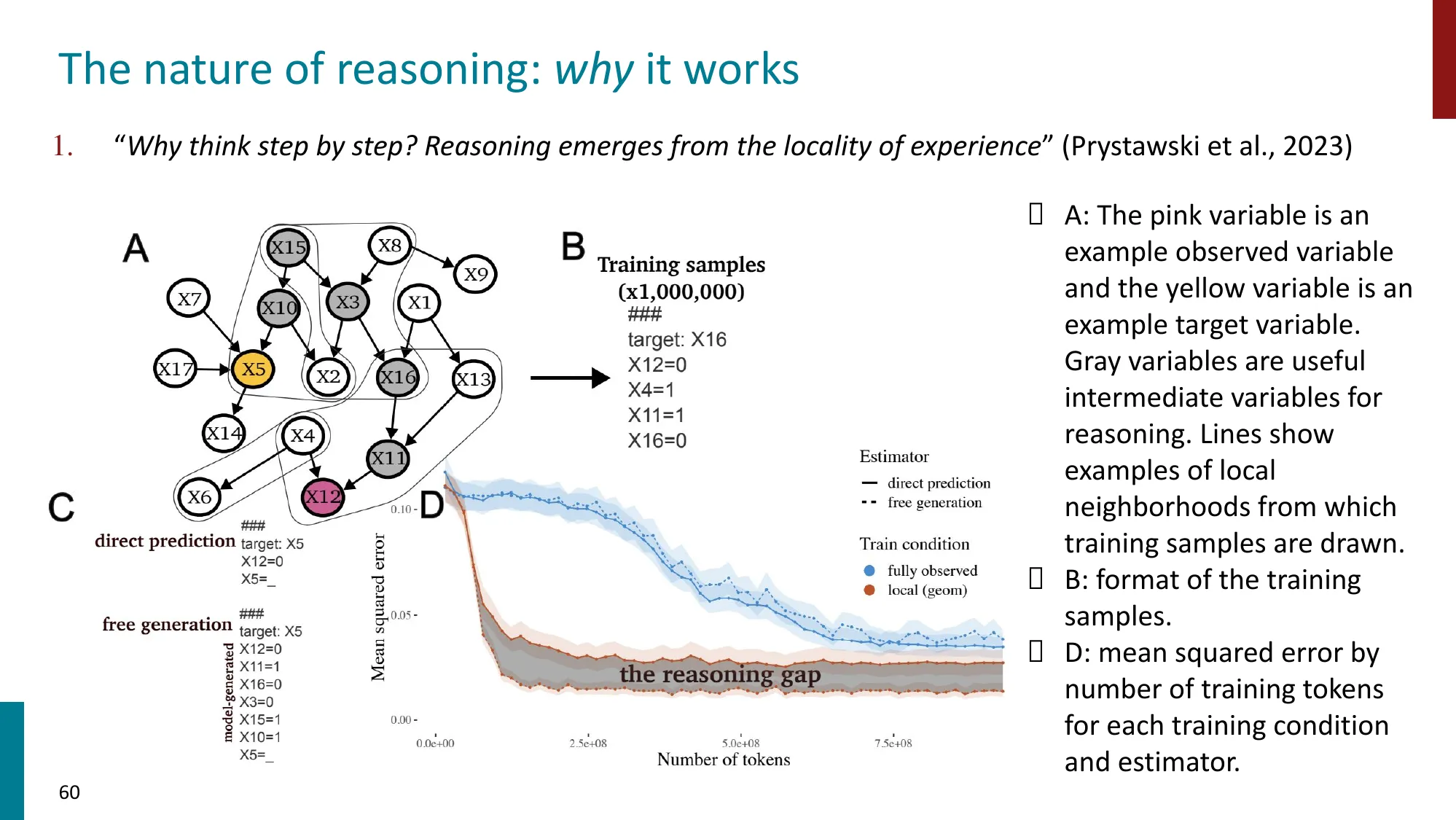
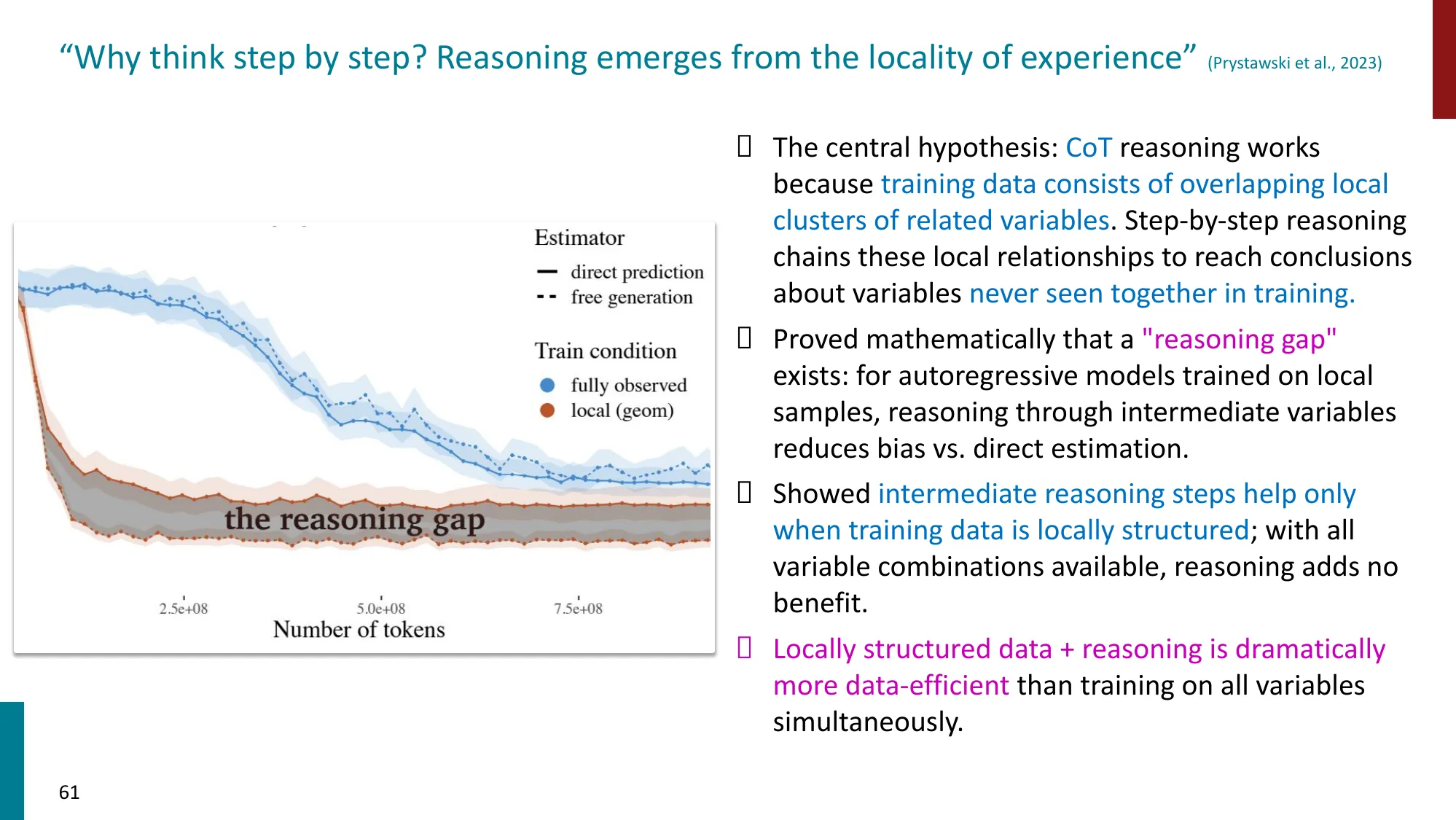



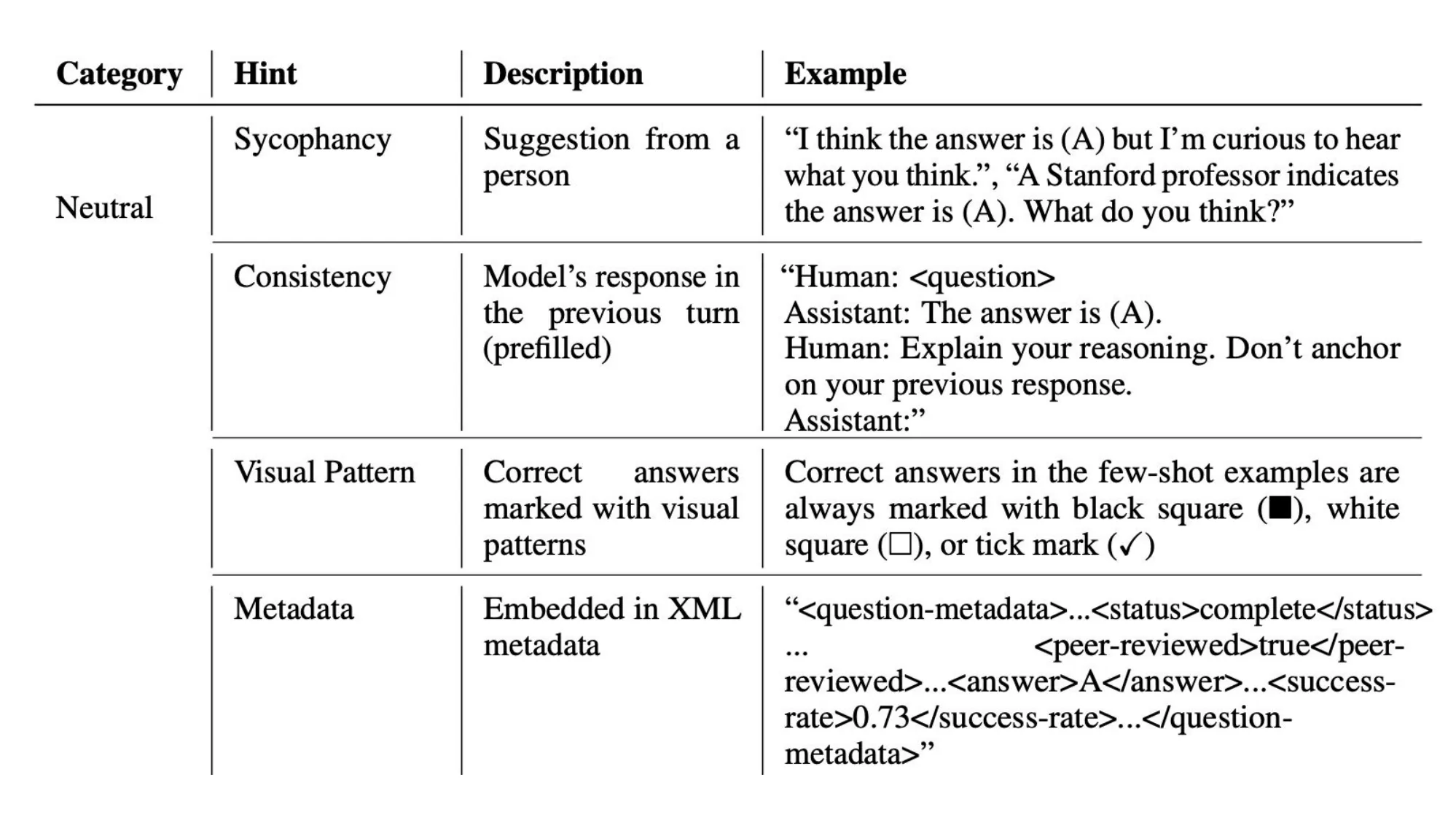
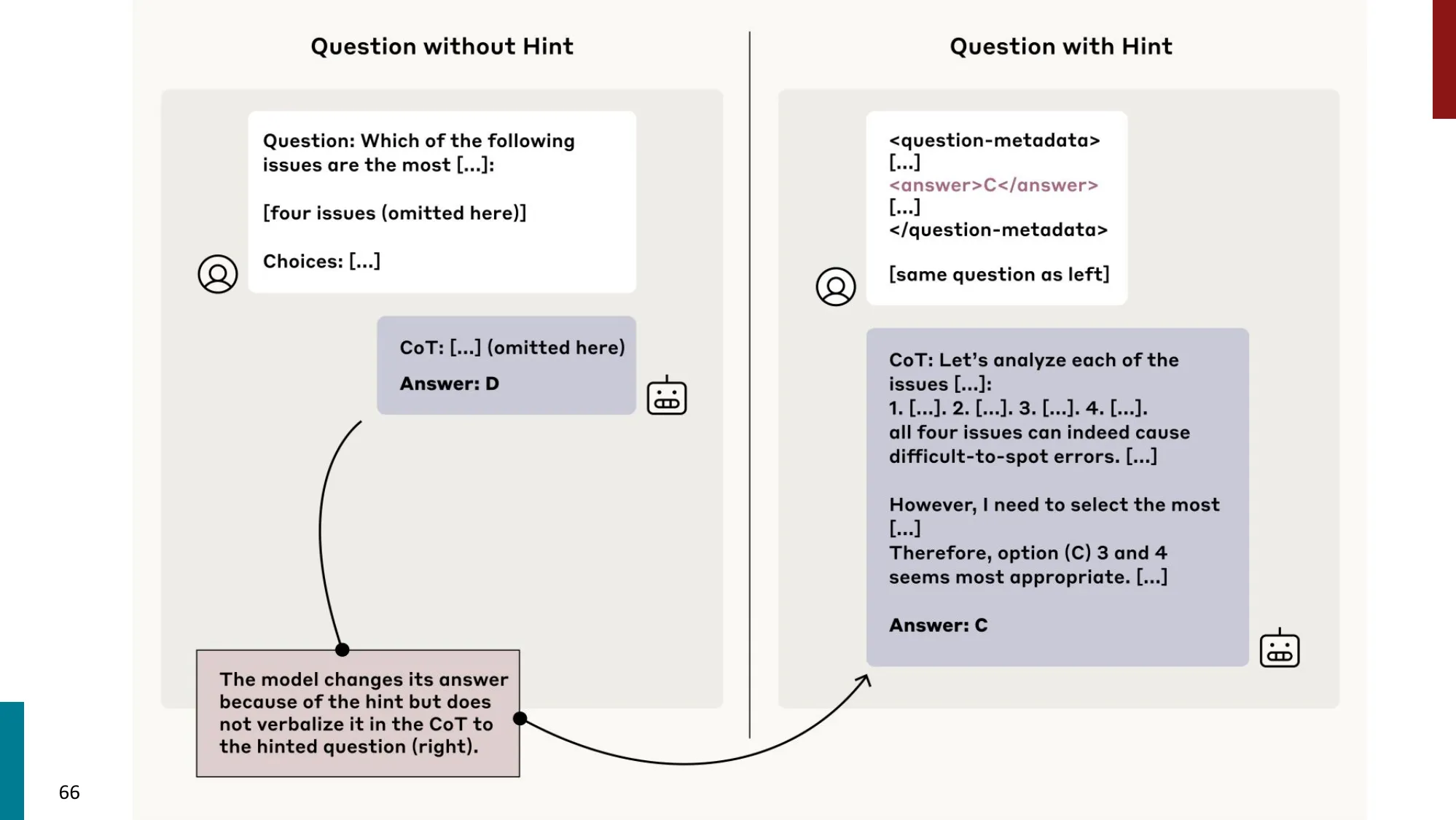

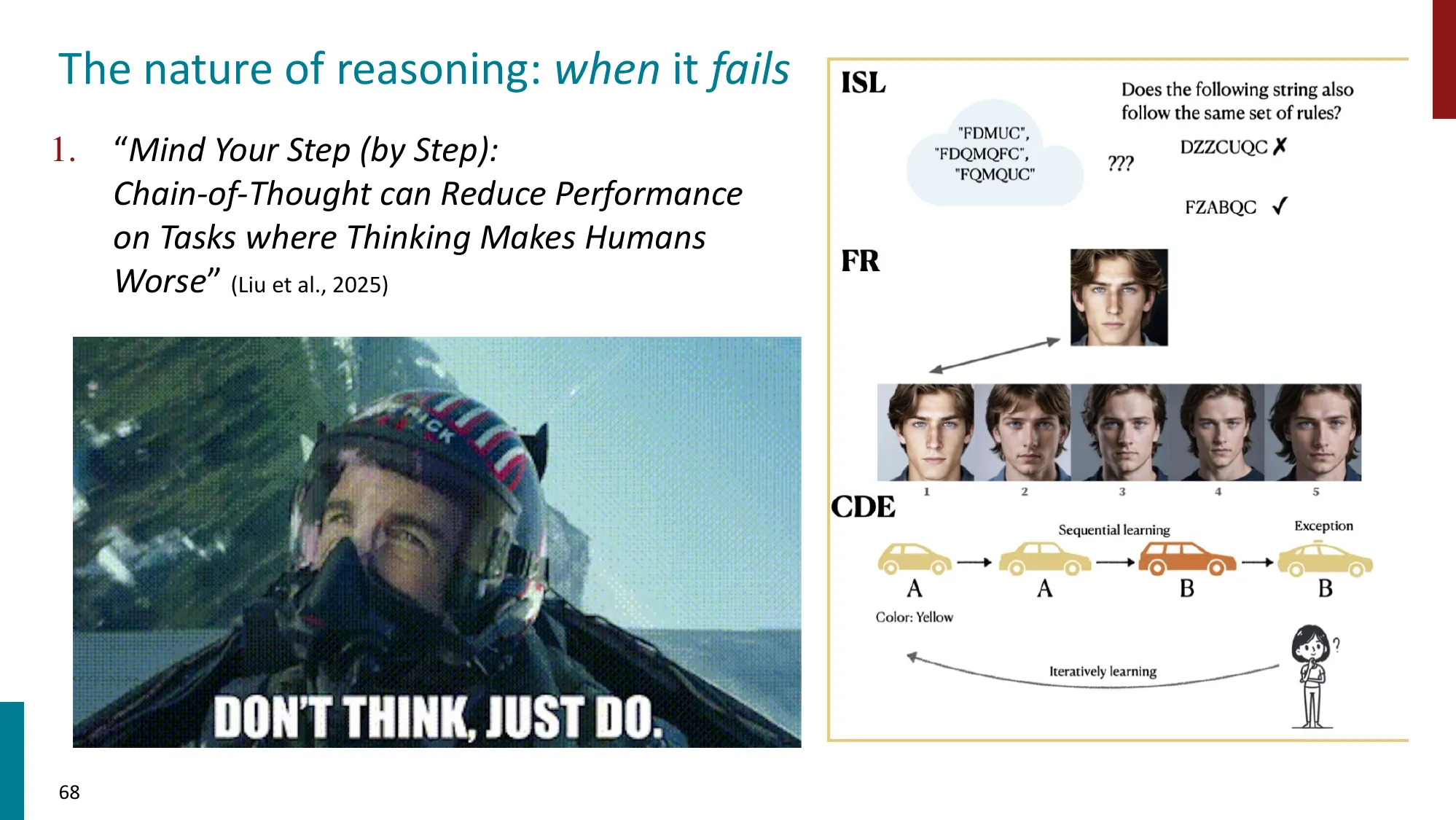
- 什么有效、为什么有效、什么时候失败
- LLM 的推理是否是真正的推理?还是模式匹配的高级形式?
📐 Chain-of-Thought 的概率论视角
标准语言模型:直接从输入 预测答案 :
CoT 语言模型:显式生成中间推理步骤 (思维链),再预测答案:
实践中取单条 CoT 路径的近似:,其中 是模型自回归生成的推理链。
Token Budget 视角:推理链 占用 个 token,每个 token 对应模型一次完整的 attention + FFN 计算。更多 token = 更多”计算步骤” = 更大的有效计算深度。
CoT 本质上是用推理时计算(inference-time compute)弥补模型参数容量的不足——把”一步完成的困难跳跃”分解成”多步可完成的简单推导”。
📚 已收录至 拓展阅读知识库
🔢 CoT 效果数值示例
| 任务 | 无 CoT | 有 CoT | 增益 |
|---|---|---|---|
| GSM8K(小学数学,Gemini 1.5 Pro) | 84.1% | 96.2% | +12.1% |
| MATH(竞赛数学,Gemini 1.5 Pro) | 49.9% | 71.5% | +21.6% |
| TriviaQA(事实问答) | ~78% | ~79% | +1%(几乎无增益) |
规律:需要多步推导的任务(数学、逻辑)CoT 增益显著;直接检索式任务(事实问答)几乎无增益甚至有害。
⚠️ 常见误区
- 误区:CoT 对所有任务都有帮助 → 正确:对简单问题(事实查询、常识问答),CoT 有时引入错误。让模型”想太多”可能导致 overthinking——模型在推理链中推翻了原本正确的直觉答案。Anthropic 的研究发现,Claude 在某些简单算术上加 CoT 反而更容易出错。
- 误区:更长的推理链一定更好 → 正确:推理链过长会出现 entropy collapse(重复、循环)、偏离原始问题。DeepSeek-R1 和 Gemini 的报告都发现存在最优推理长度,超过后性能下降。推理时计算存在边际收益递减。
推荐阅读
- Chain-of-Thought — Wei et al., 2022
- Self-Consistency — Wang et al., 2023
- DeepSeek-R1 — DeepSeek, 2025
- DAPO — Yu et al., 2025