L19: Open Questions in NLP
Week 10 · Tue Mar 10 2026 08:00:00 GMT+0800 (中国标准时间)
进度: 0/22 (0%)
L19: Open Questions in NLP
- 授课: Yejin Choi (Stanford & NVIDIA)
- 日期: Mar 10, 2026 (Week 10)
Slides
- EN
- ZH / BILINGUAL: 见
outputs/cs224n_translations/
核心知识点
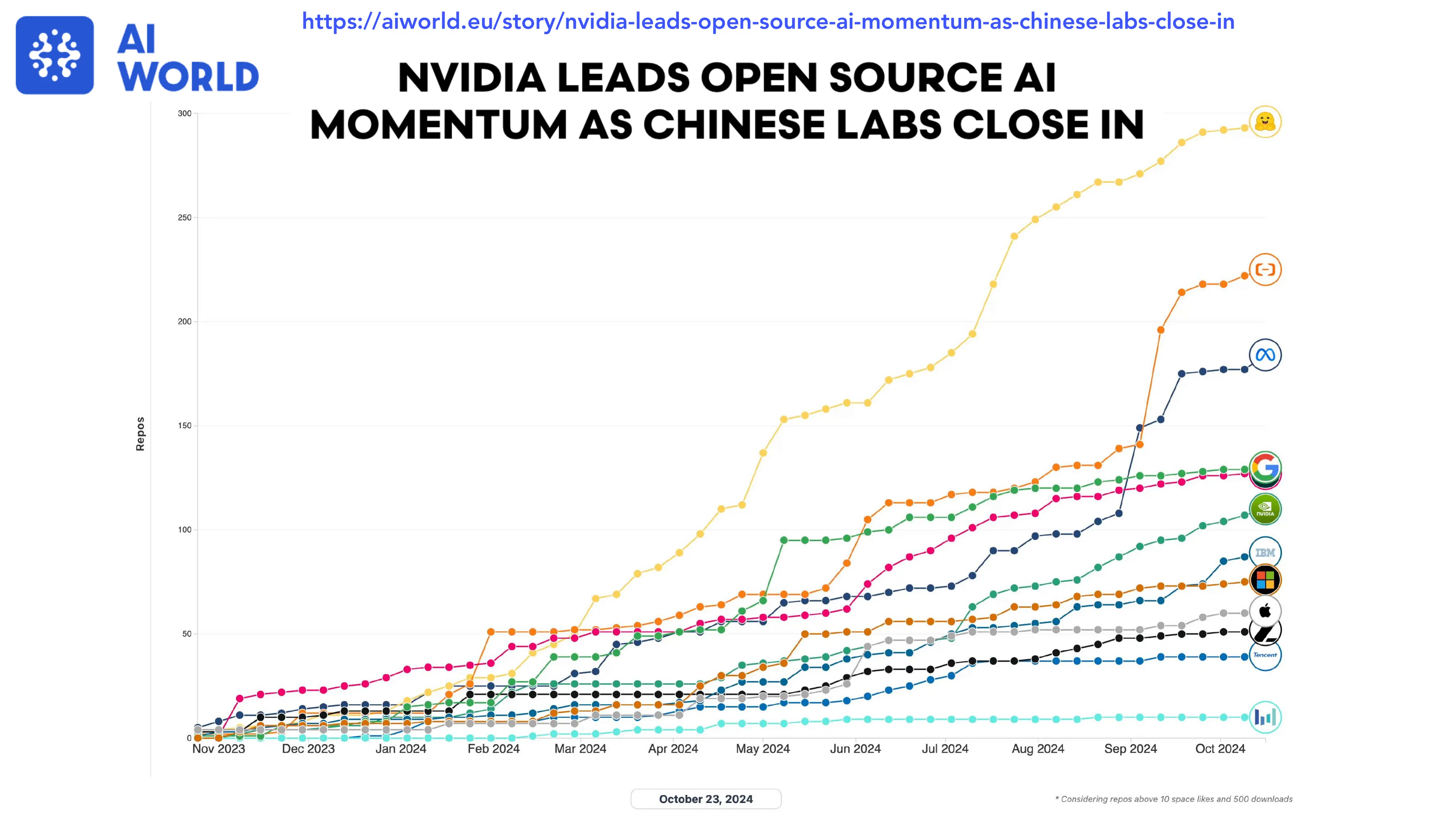
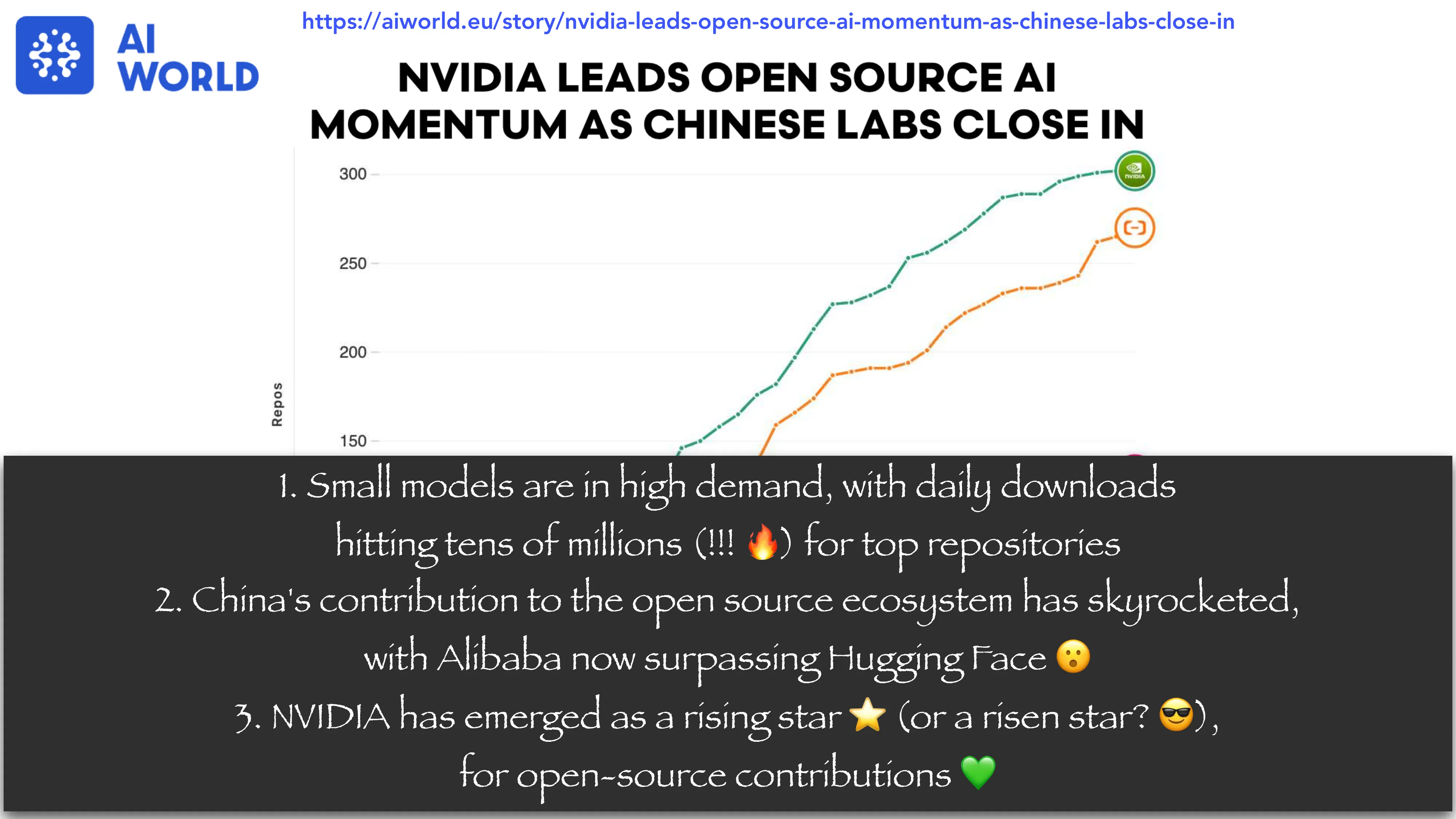
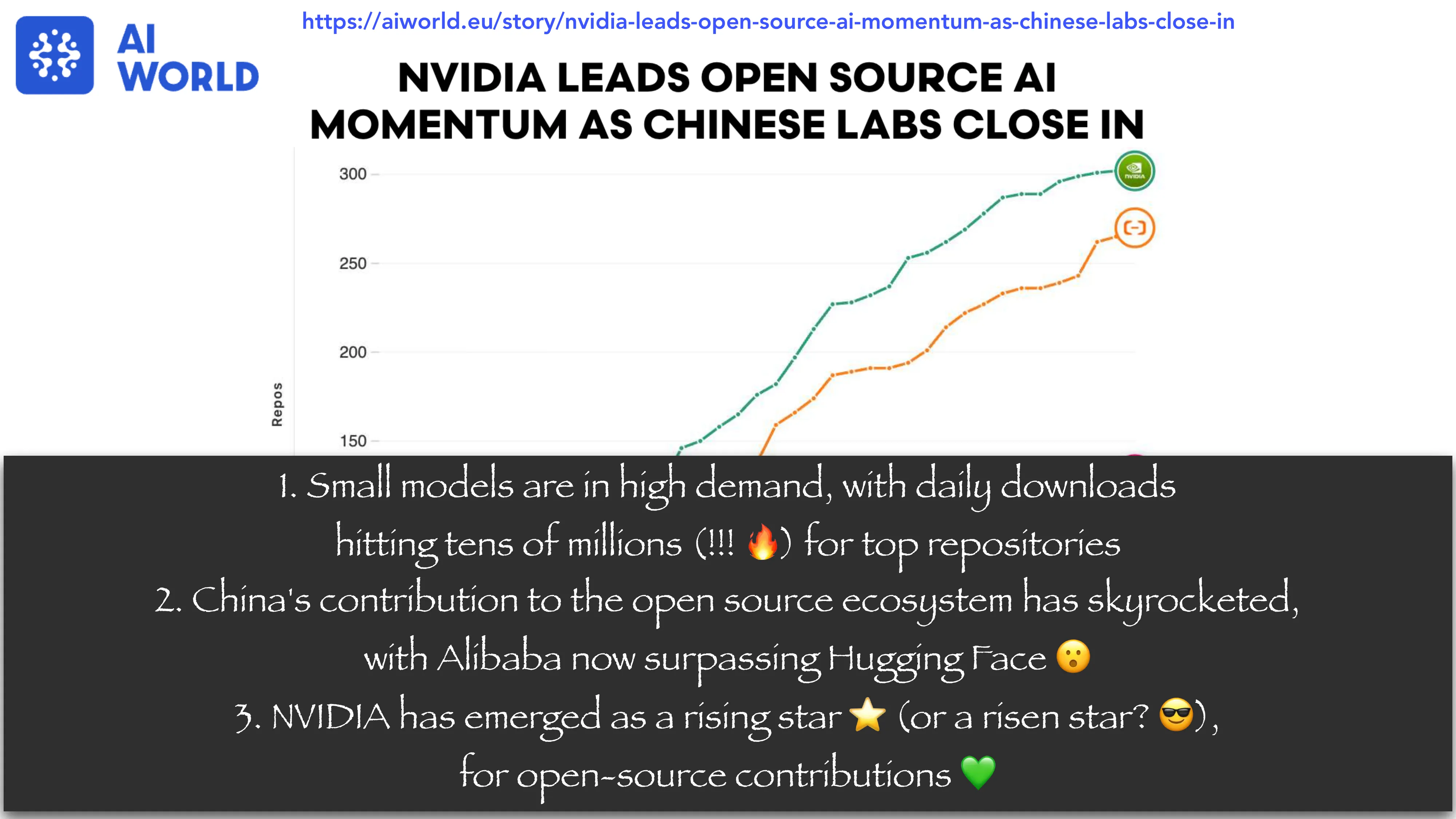
The Era of Brute-Force Scaling is Over









- Ilya Sutskever (NeurIPS 2024): “Pre-training as we know it will end” — 数据是 AI 的化石燃料
- 计算在增长(更好的硬件、算法、更大集群),但数据不在增长(只有一个互联网)
- GPT-5 的进步缓慢: New Yorker & New Scientist 质疑 AI 进步是否停滞
- 三条出路应对数据饱和: 1. 有限数据下学得更好更快(替代架构、替代训练策略) 2. 合成新数据(生成互联网数据的”外层空间”) 3. 超越数据进行推理(test-time reasoning/training)
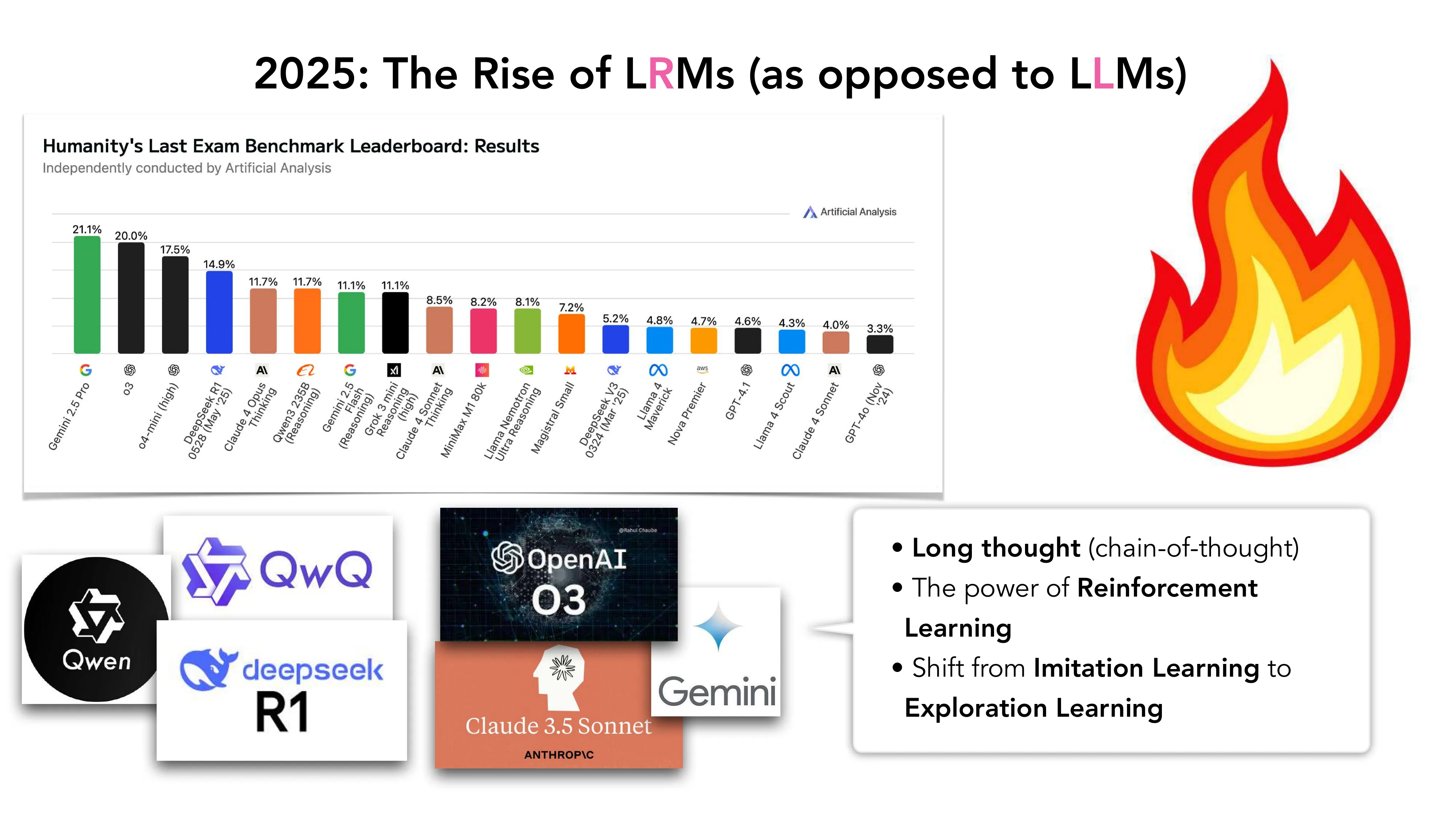
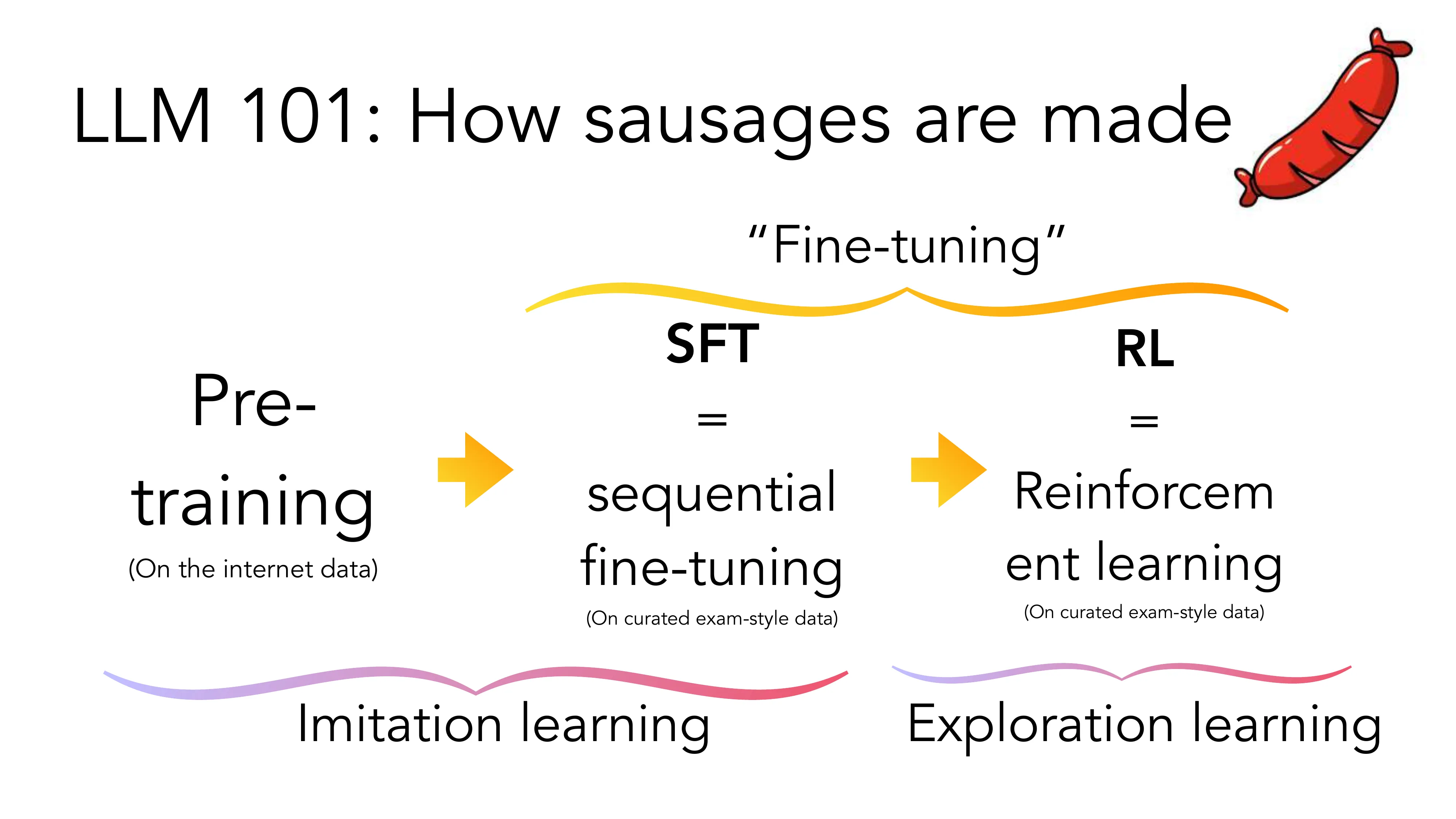
2025: The Rise of LRMs (Large Reasoning Models)
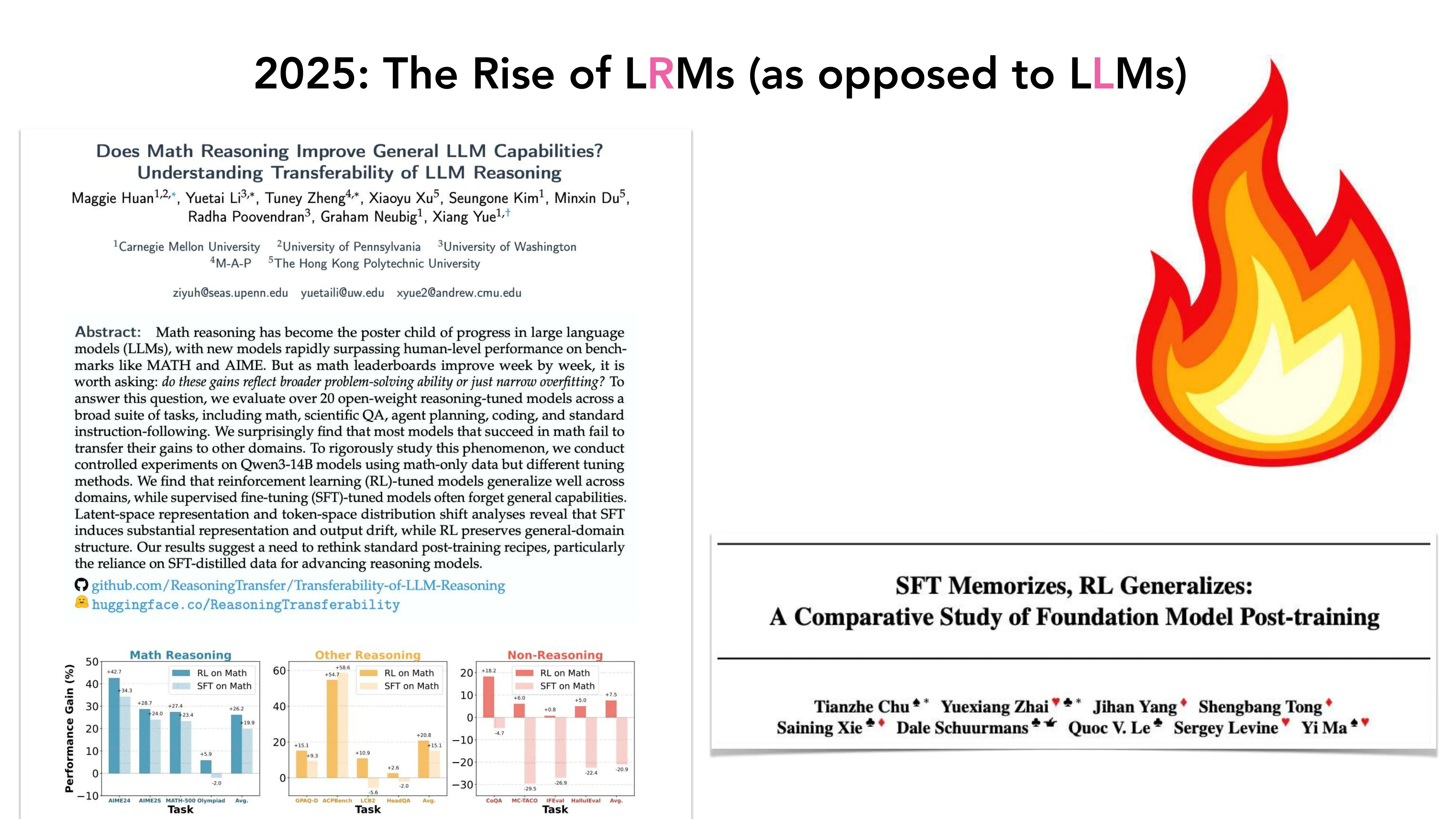
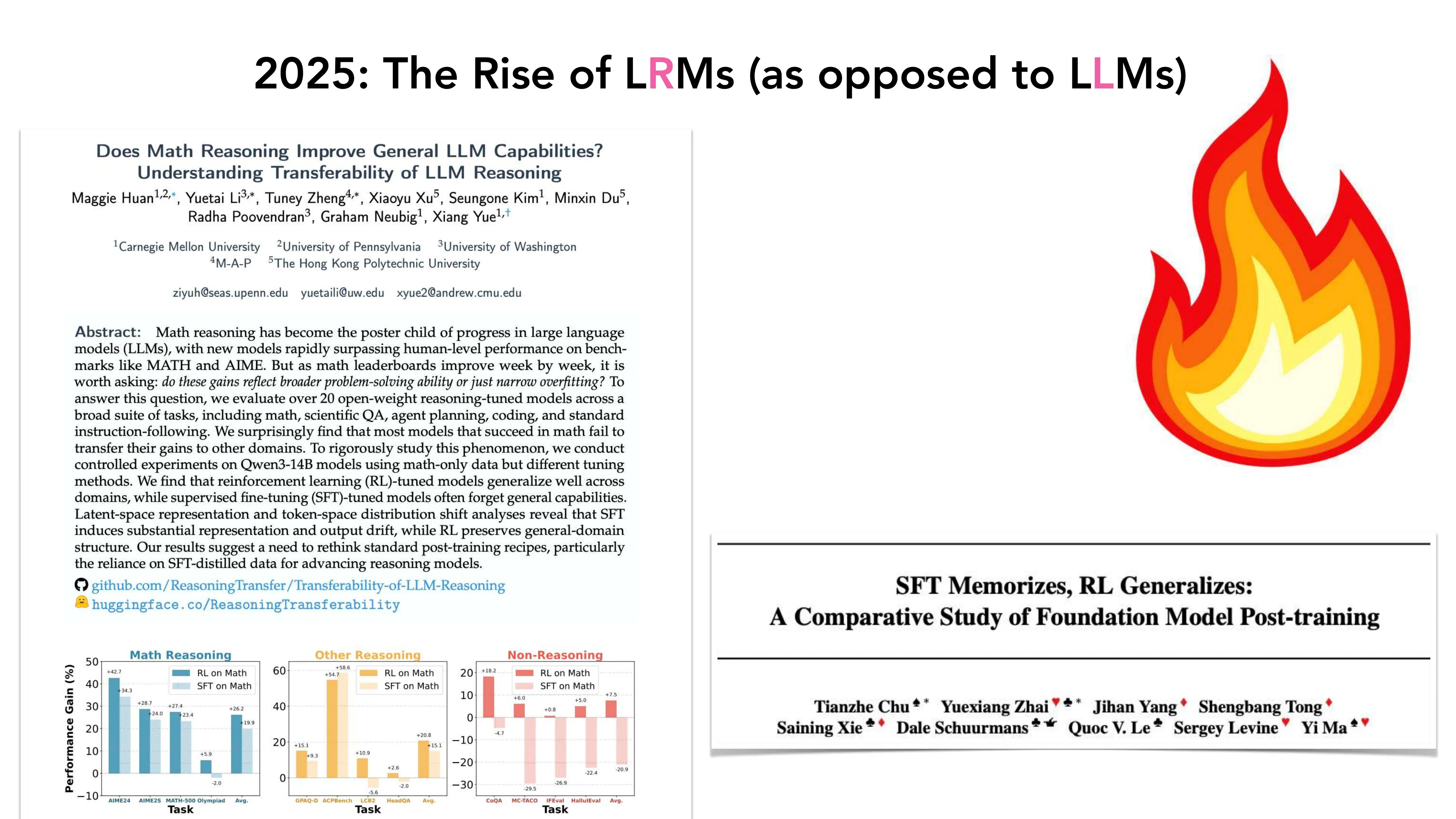
- DeepSeek-R1, QwQ, o3, Claude 3.5 Sonnet, Gemini — 长思考 + RL + 探索学习
- 从 Imitation Learning 到 Exploration Learning 的范式转移
- “SFT Memorizes, RL Generalizes” (Chu et al.): SFT 在数学上训练但难以泛化到其他领域,RL 可以
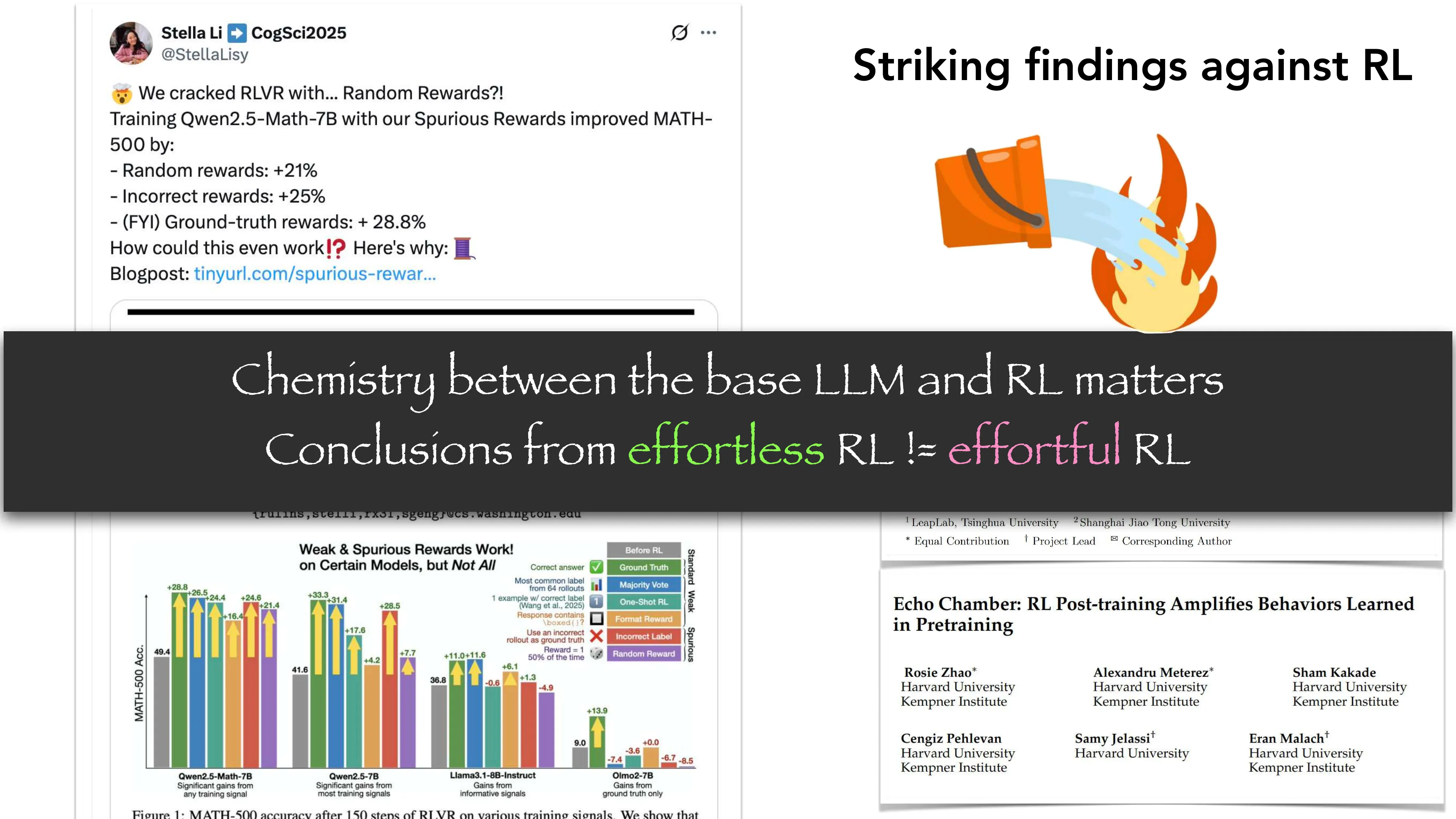
Striking Findings Against RL


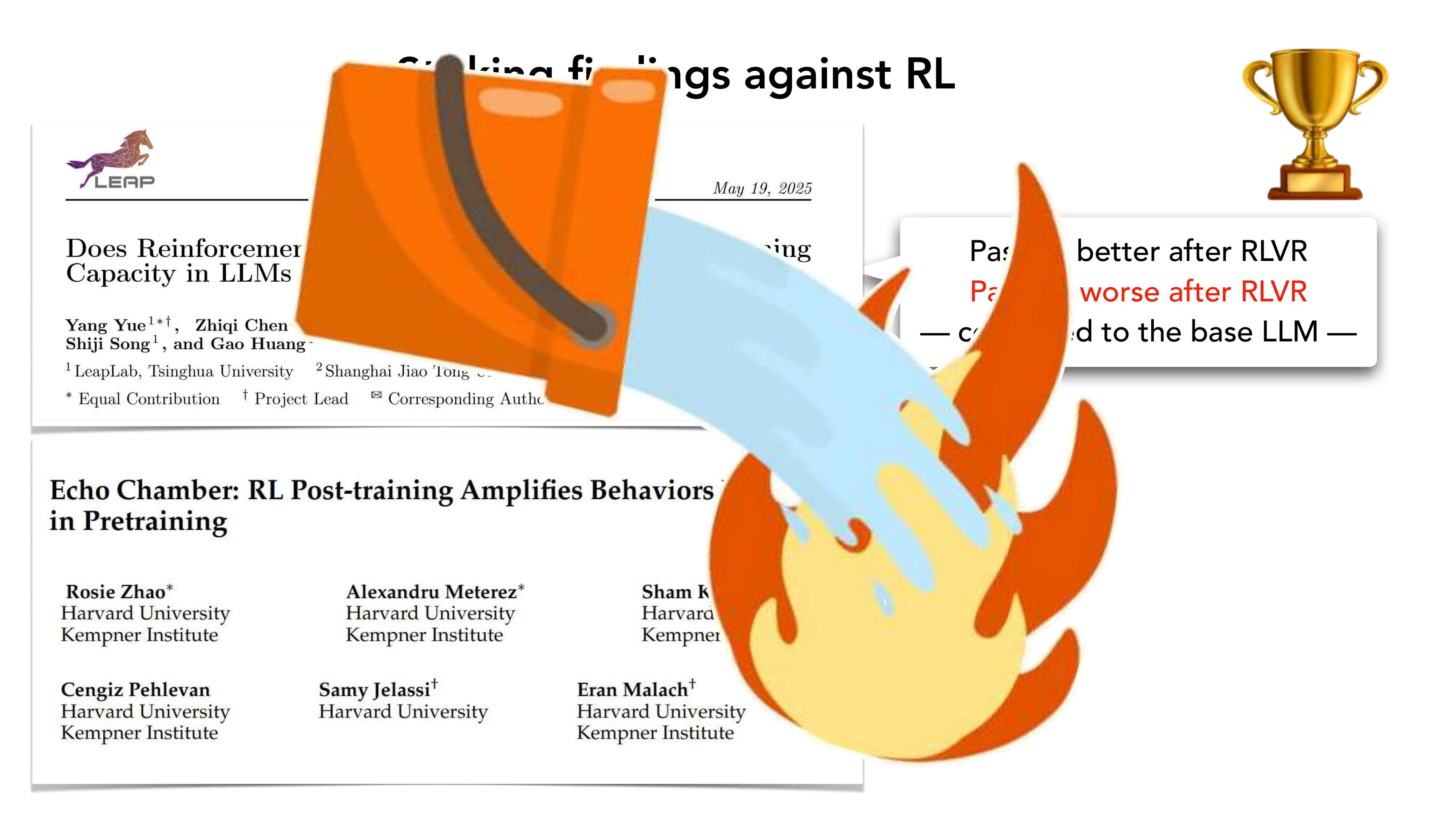
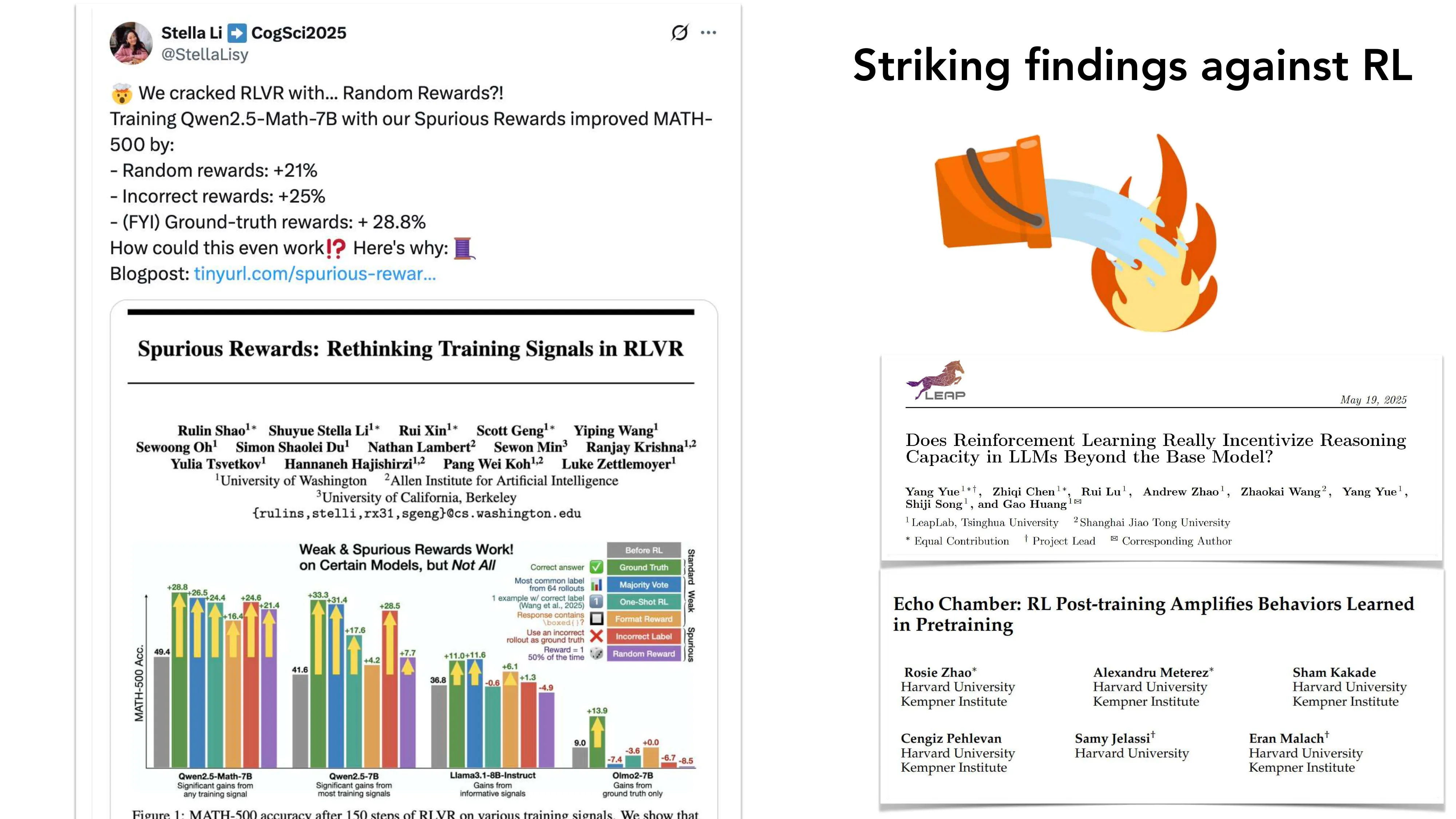
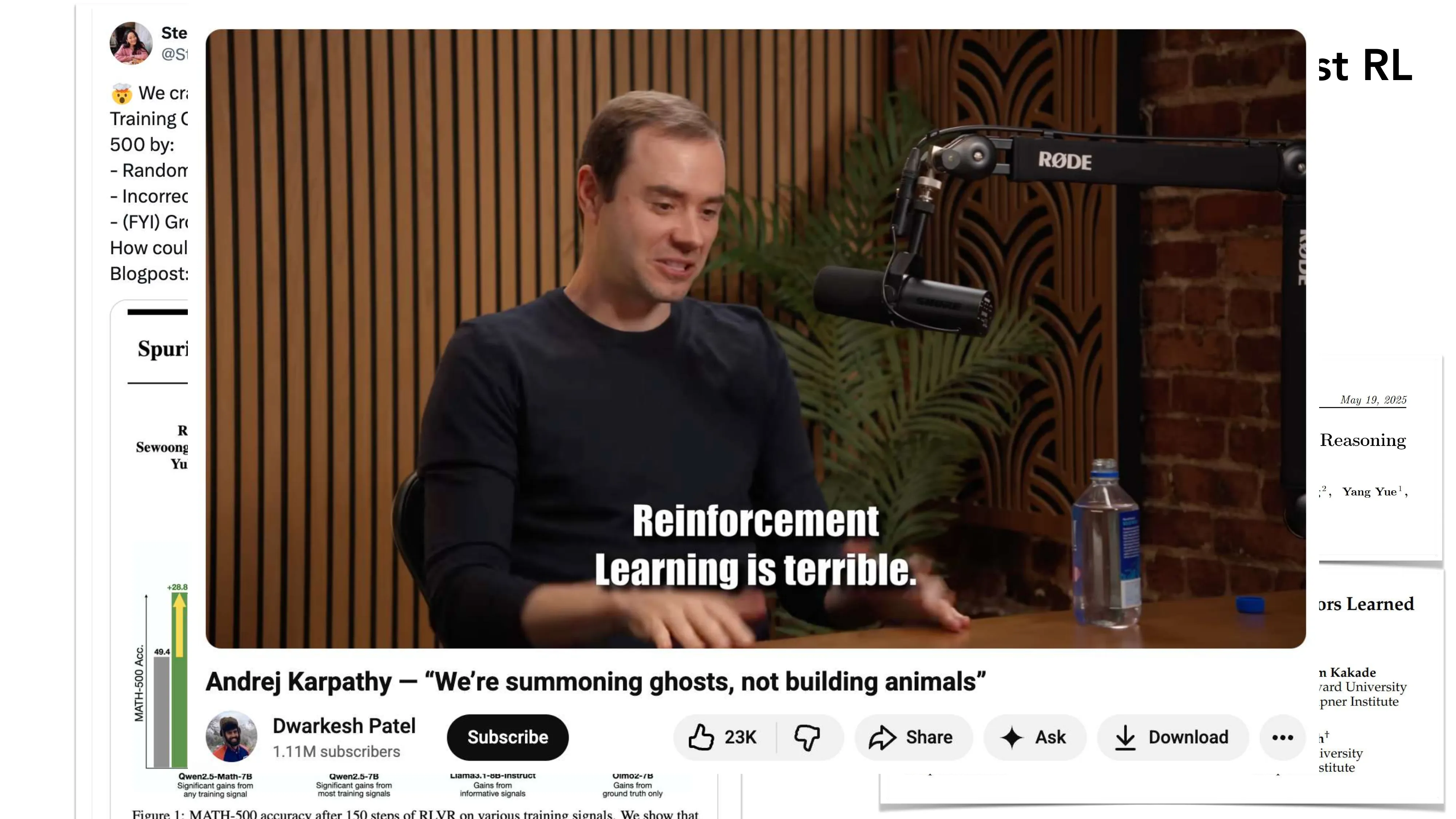

- “Does RL Really Incentivize Reasoning?” (Yue et al. 2025): Pass@1 提升但 Pass@K 下降 → RL 可能只是收敛而非拓展能力边界
- “Echo Chamber” (Zhao et al. Harvard): RL post-training 放大预训练中已有的行为
- “Spurious Rewards” (Shao et al. UW): 随机奖励 +21%, 错误奖励 +25%, 正确奖励 +28.8% — RLVR 的信号可能并非关键
- Andrej Karpathy: “Reinforcement Learning is terrible”
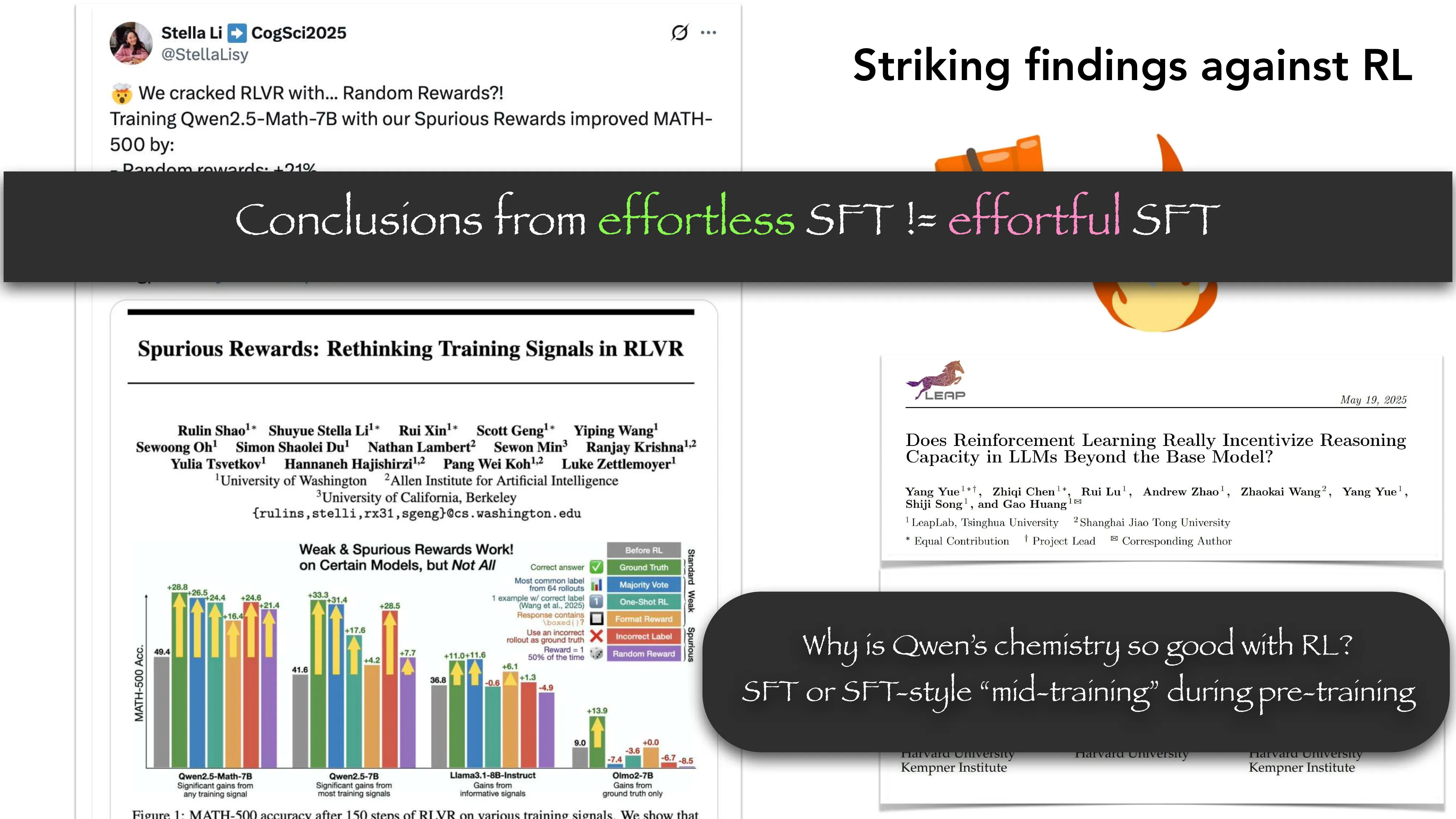
- 关键洞察: effortless RL 的结论 != effortful RL 的结论; base LLM 与 RL 的”化学反应”很重要
📐 GRPO 目标函数与 Pass@K 的关系
GRPO(Group Relative Policy Optimization)目标:
其中 是重要性权重, 是组内归一化优势。
Pass@K 与 Pass@1 的关系:
其中 是采样次数, 是正确回答数。
“Does RL Really Incentivize Reasoning?” 的关键发现(Yue et al. 2025):
RL 训练后 Pass@1 上升(从 30% → 45%),但 Pass@100 下降(从 85% → 78%)。
这意味着 RL 减少了解空间的多样性,把概率质量集中到少数路径——是收敛而非扩展。
📚 已收录至 拓展阅读知识库
⚠️ 常见误区
-
误区:RL 训练使模型获得了新的推理能力 → 正确:Echo Chamber 效应表明,RL 主要是放大了预训练中已有的行为,而非产生真正新颖的推理路径。Pass@K 的下降是明证。
-
误区:随机奖励(spurious rewards)会损害性能 → 正确:Shao et al. 2025 发现随机奖励也能带来 +21% 的性能提升(虽然低于正确奖励的 +28.8%),说明 RLVR 的部分收益来自训练动态而非奖励信号本身的语义内容。
ProRL: Prolonged Reinforcement Learning (NeurIPS 2025, NVIDIA)









- 在 1.5B 小模型上进行长时间 RL 训练(“Rome wasn’t built in a day”)
- 基于 DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization),GRPO 的变体
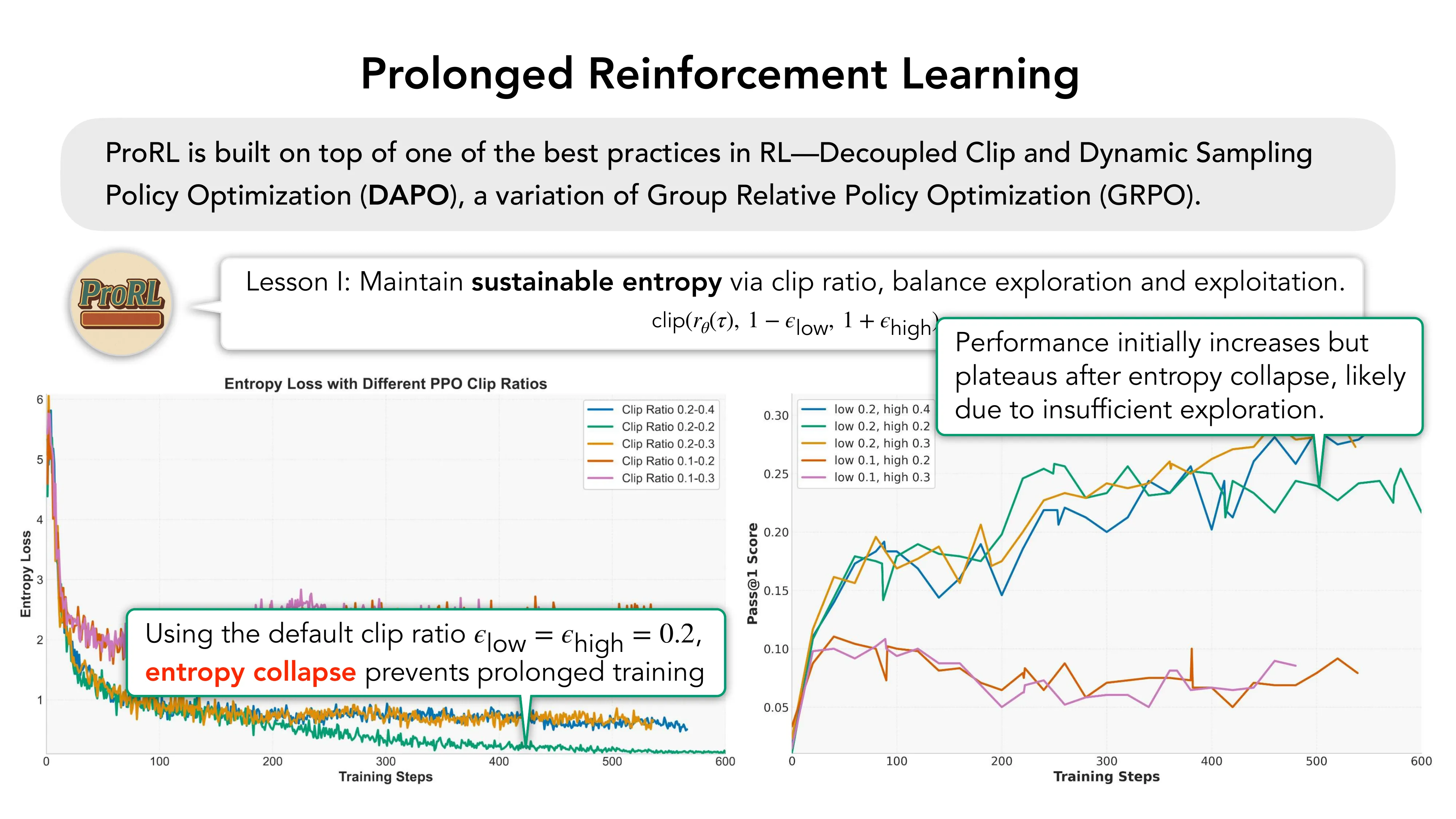
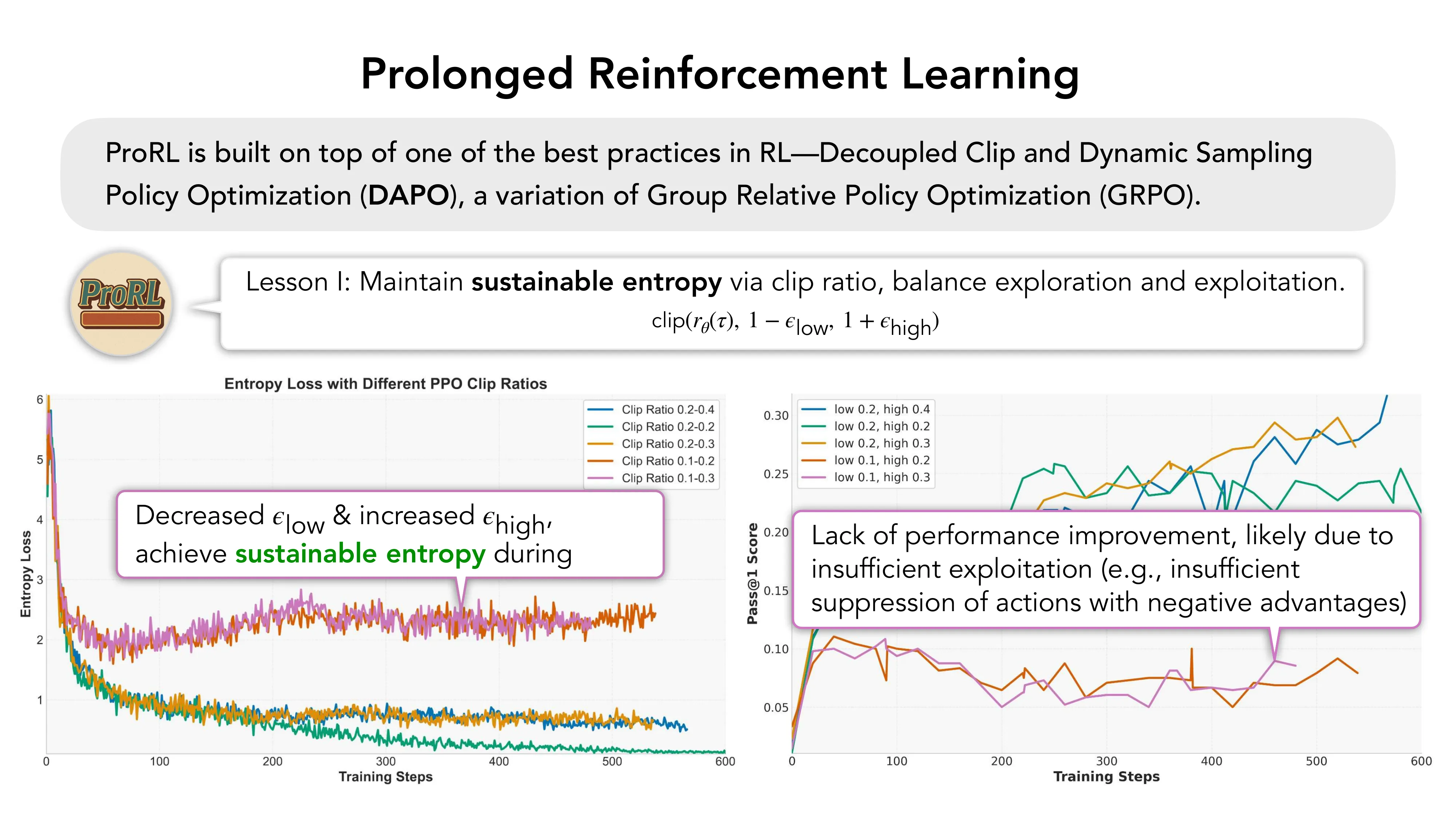
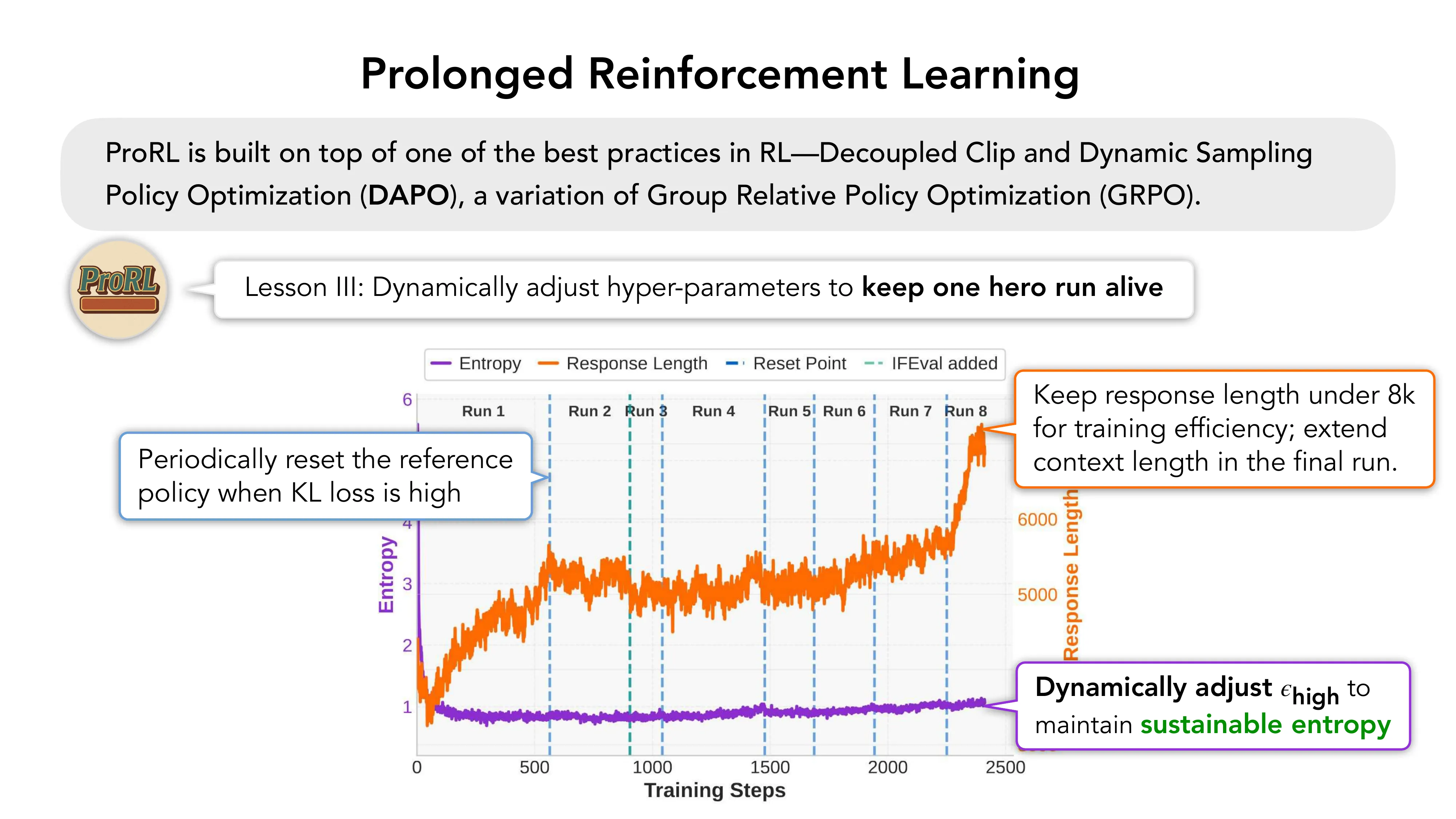
- Lesson I: Sustainable entropy — 通过非对称 clip ratio 平衡探索与利用
- 默认 epsilon_low = epsilon_high = 0.2 → entropy collapse → 训练停滞
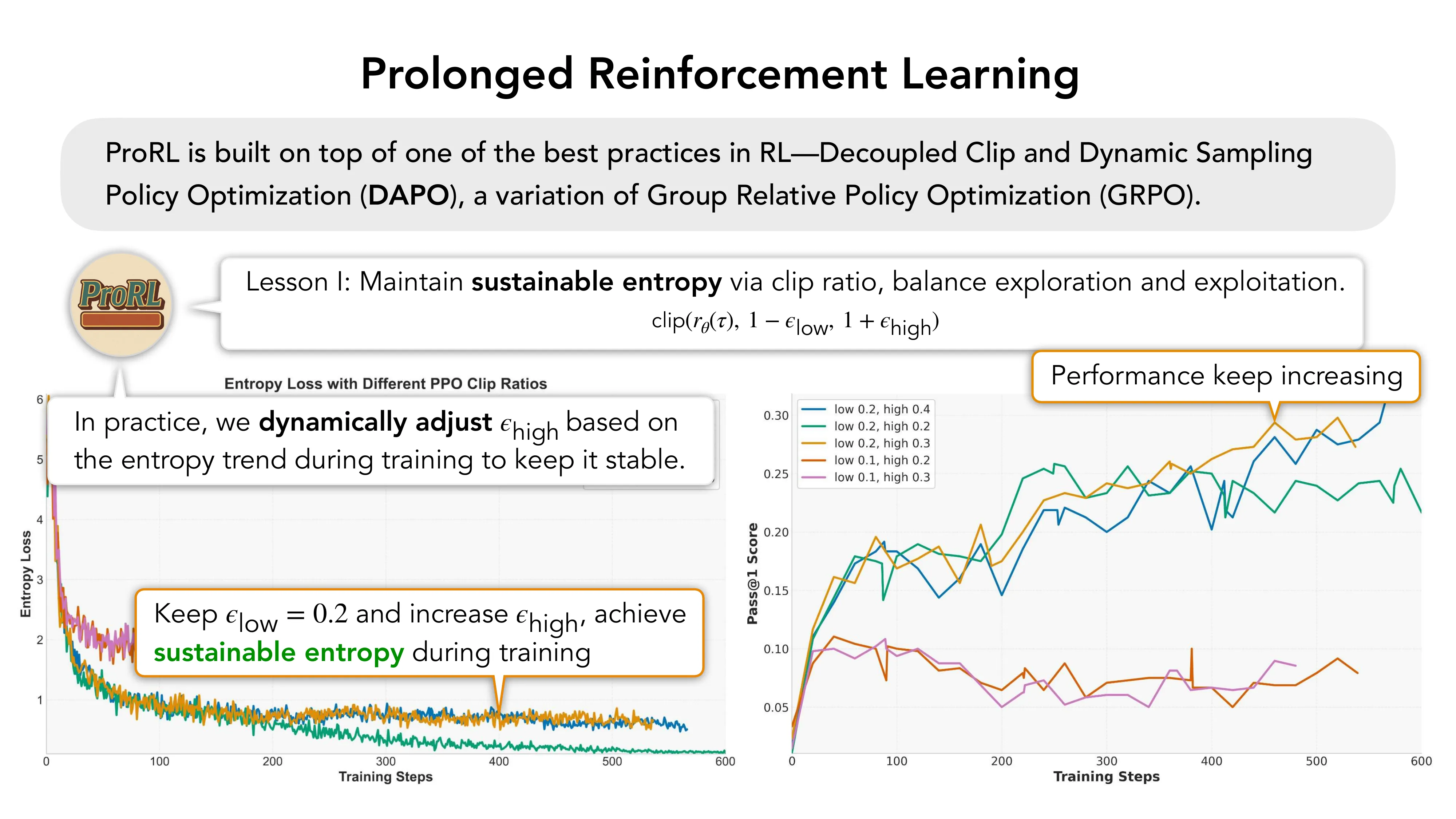
- 保持 epsilon_low = 0.2,增大 epsilon_high → 可持续熵
- Lesson II: 动态调节 epsilon_high 维持熵稳定
- Lesson III: 周期性重置参考策略(当 KL 过高时),控制 response length < 8k
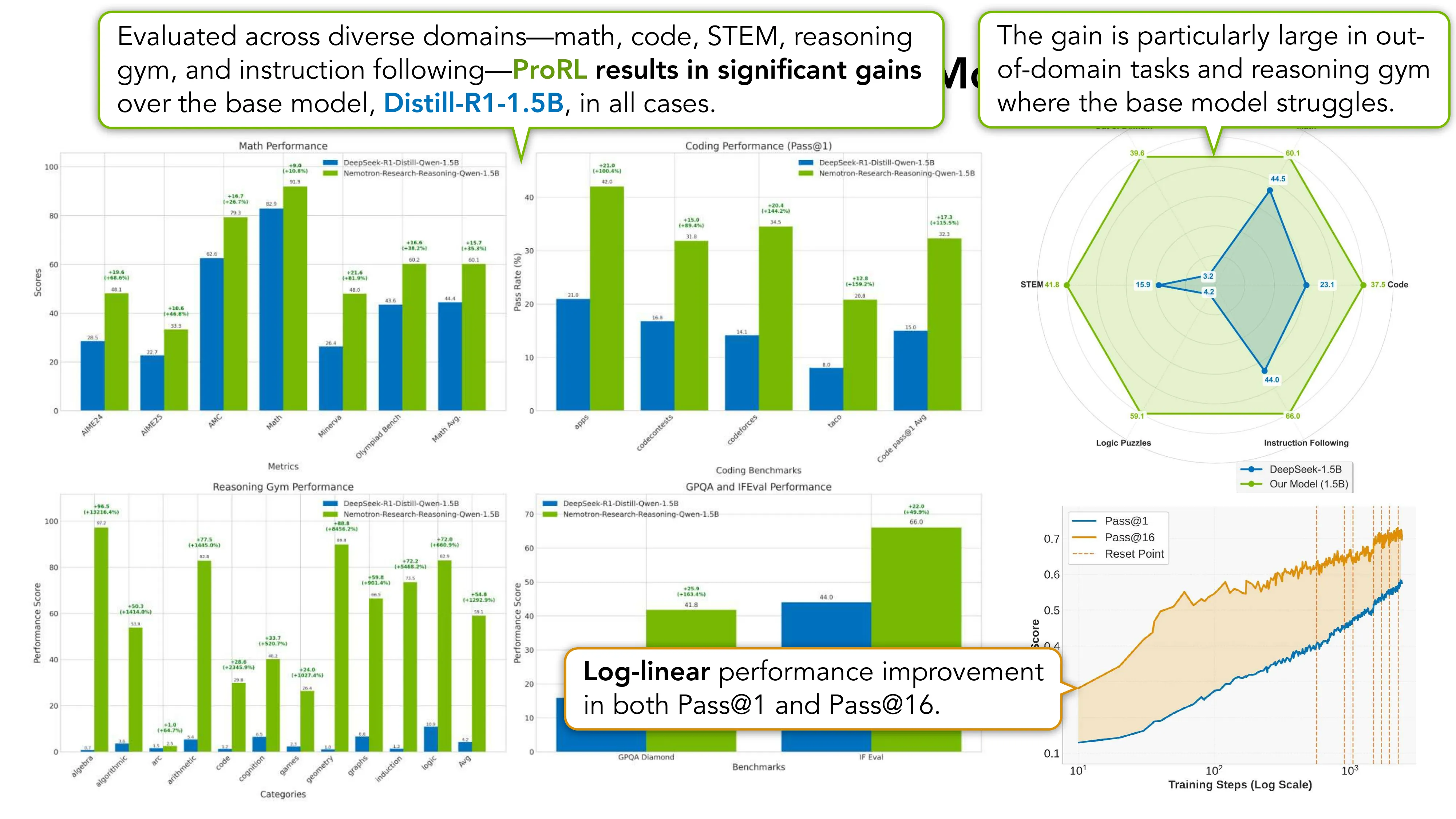
- 结果: Nemotron-Reasoning-1.5B 可匹敌 4.5x 大的 DeepSeek-R1-7B
- Log-linear performance improvement in both Pass@1 and Pass@16
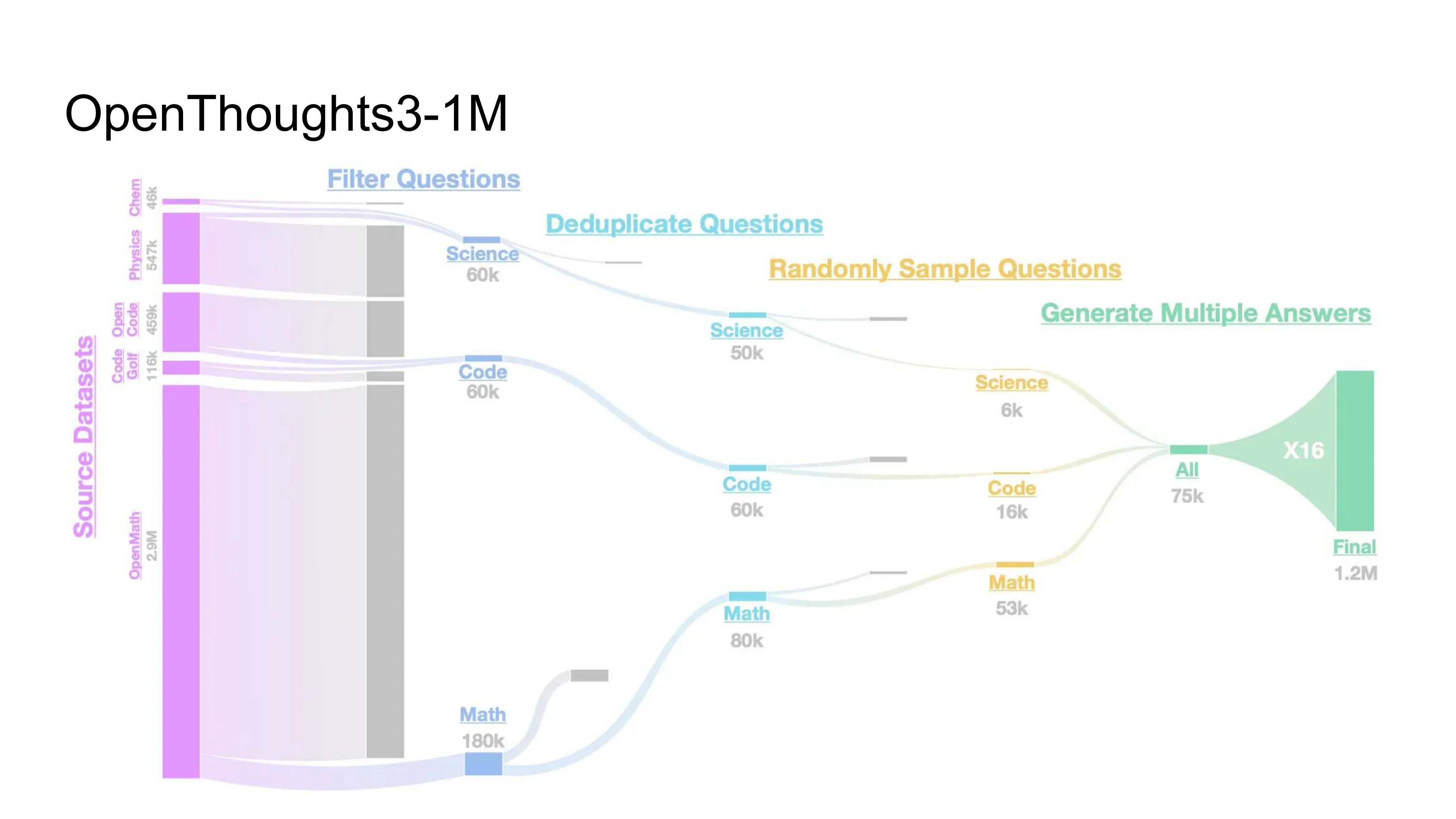
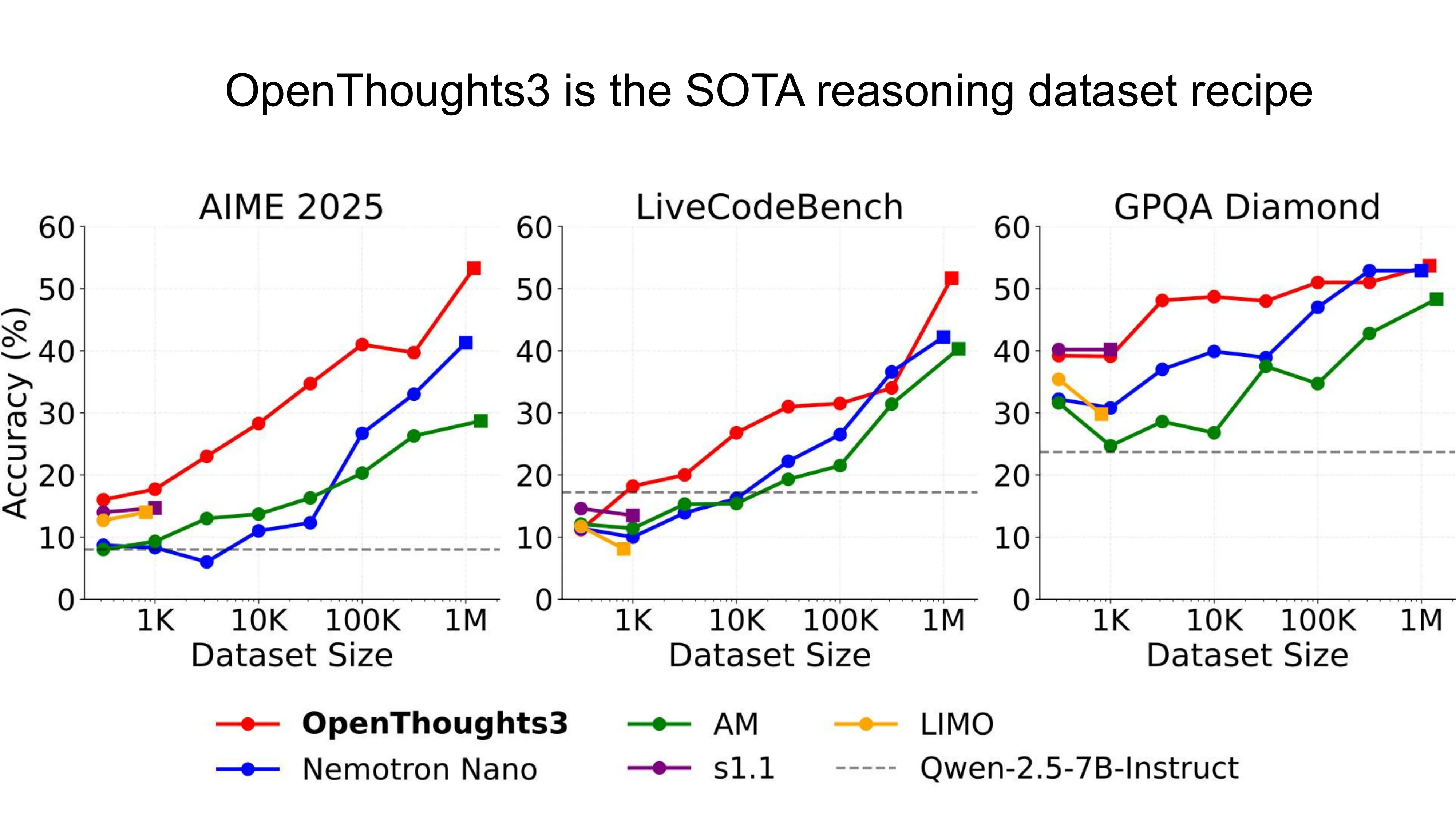
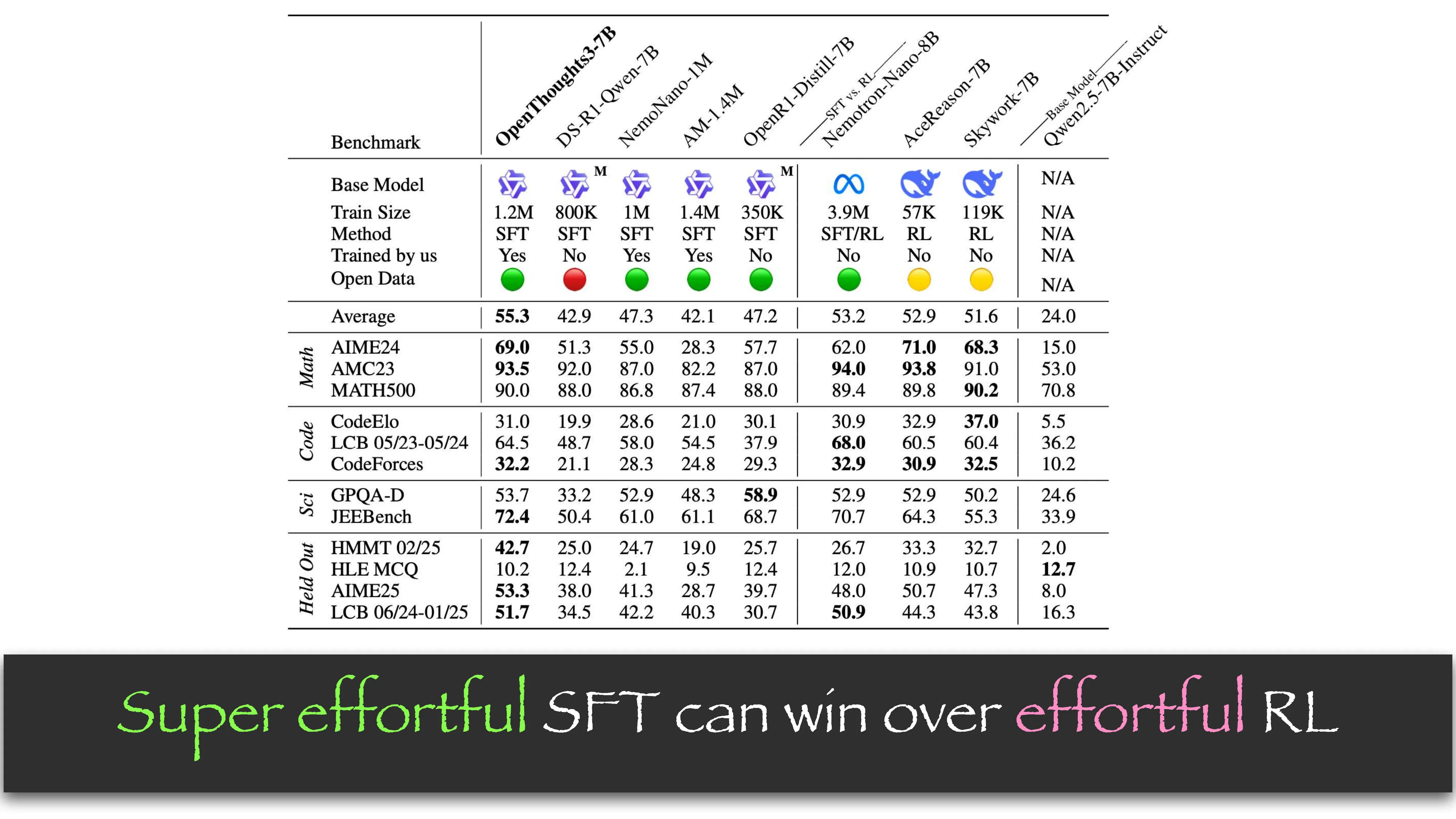
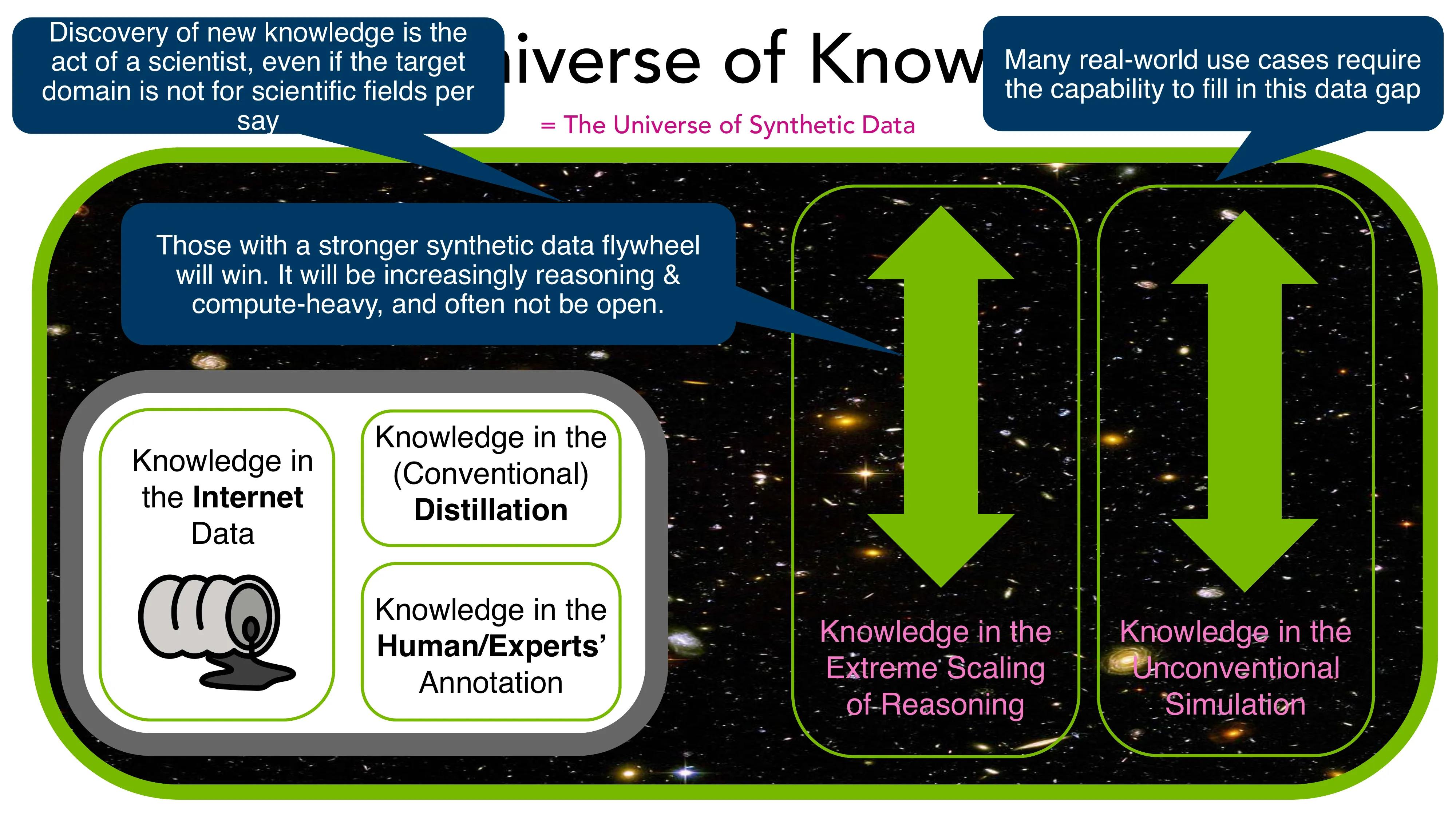
Prismatic Synthesis: Gradient-based Data Diversification (NeurIPS 2025, NVIDIA)




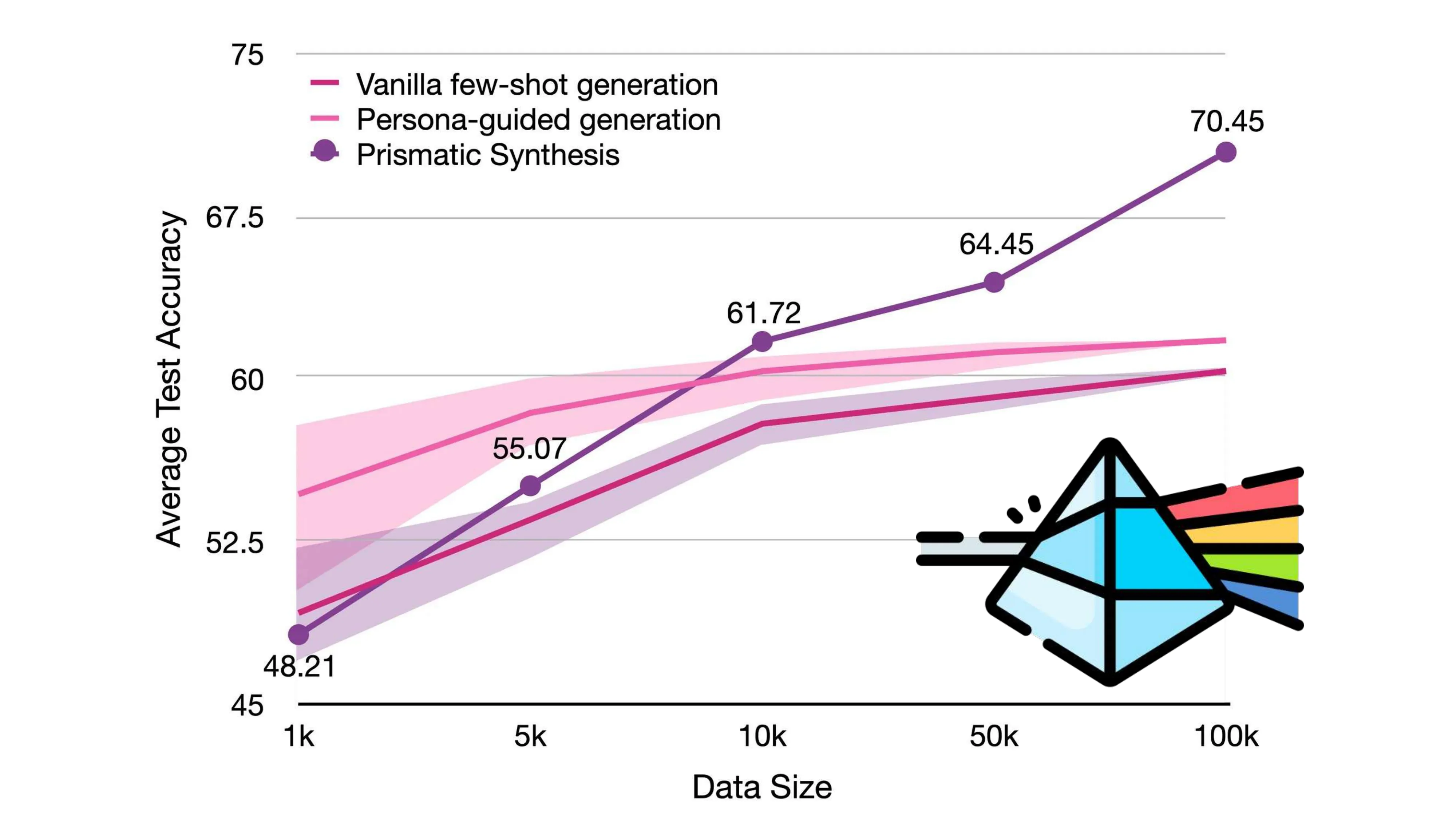
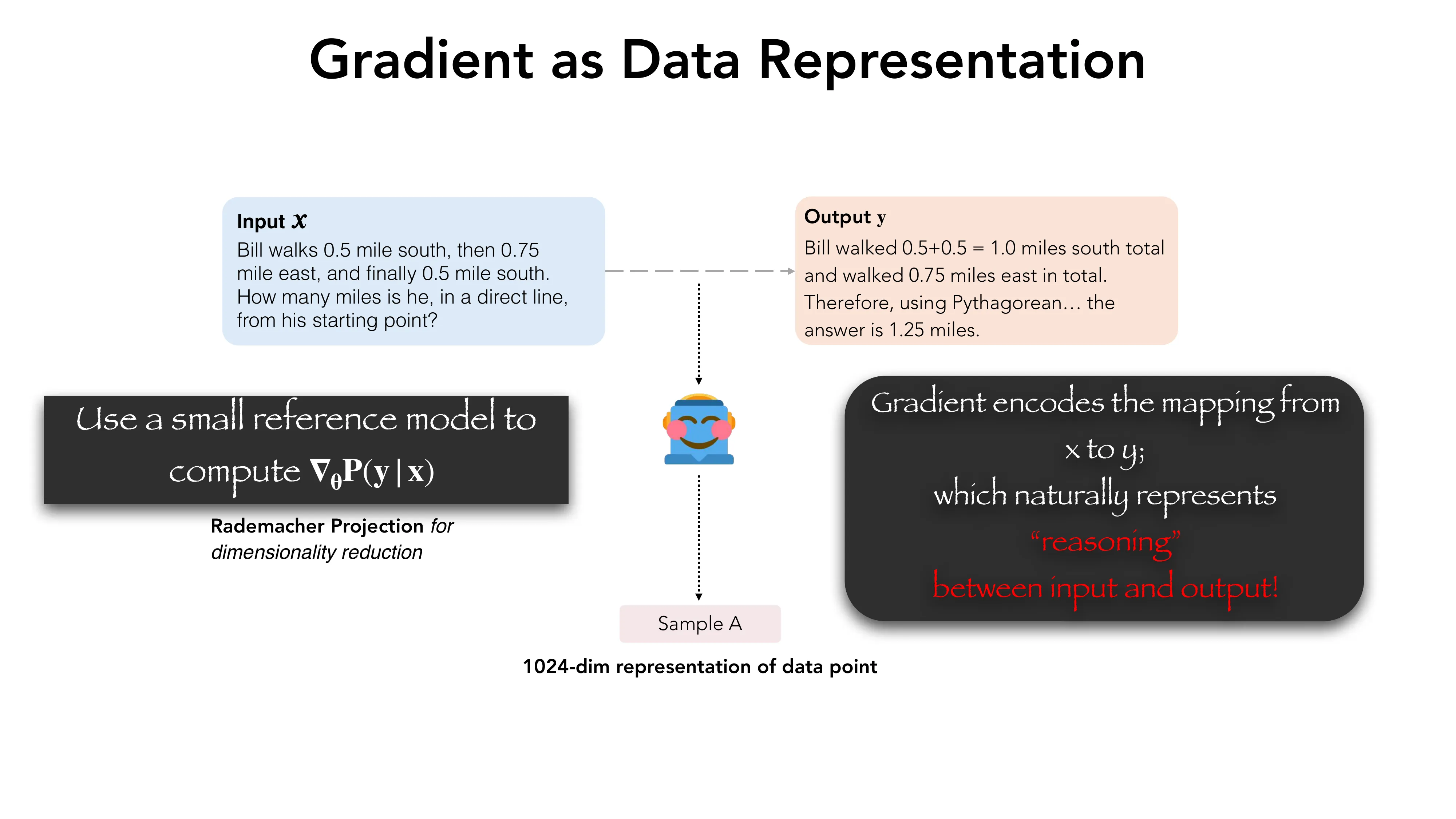
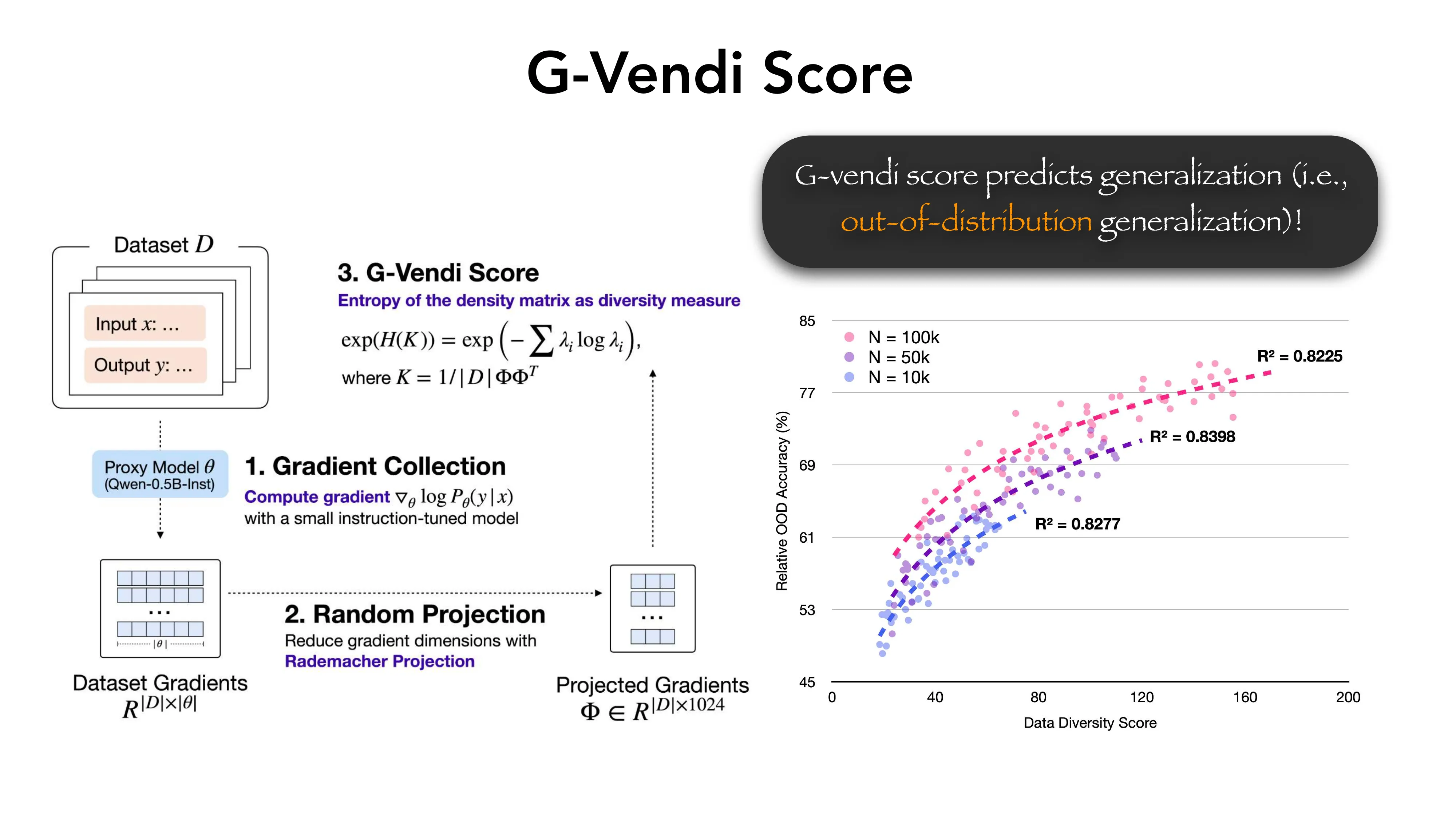
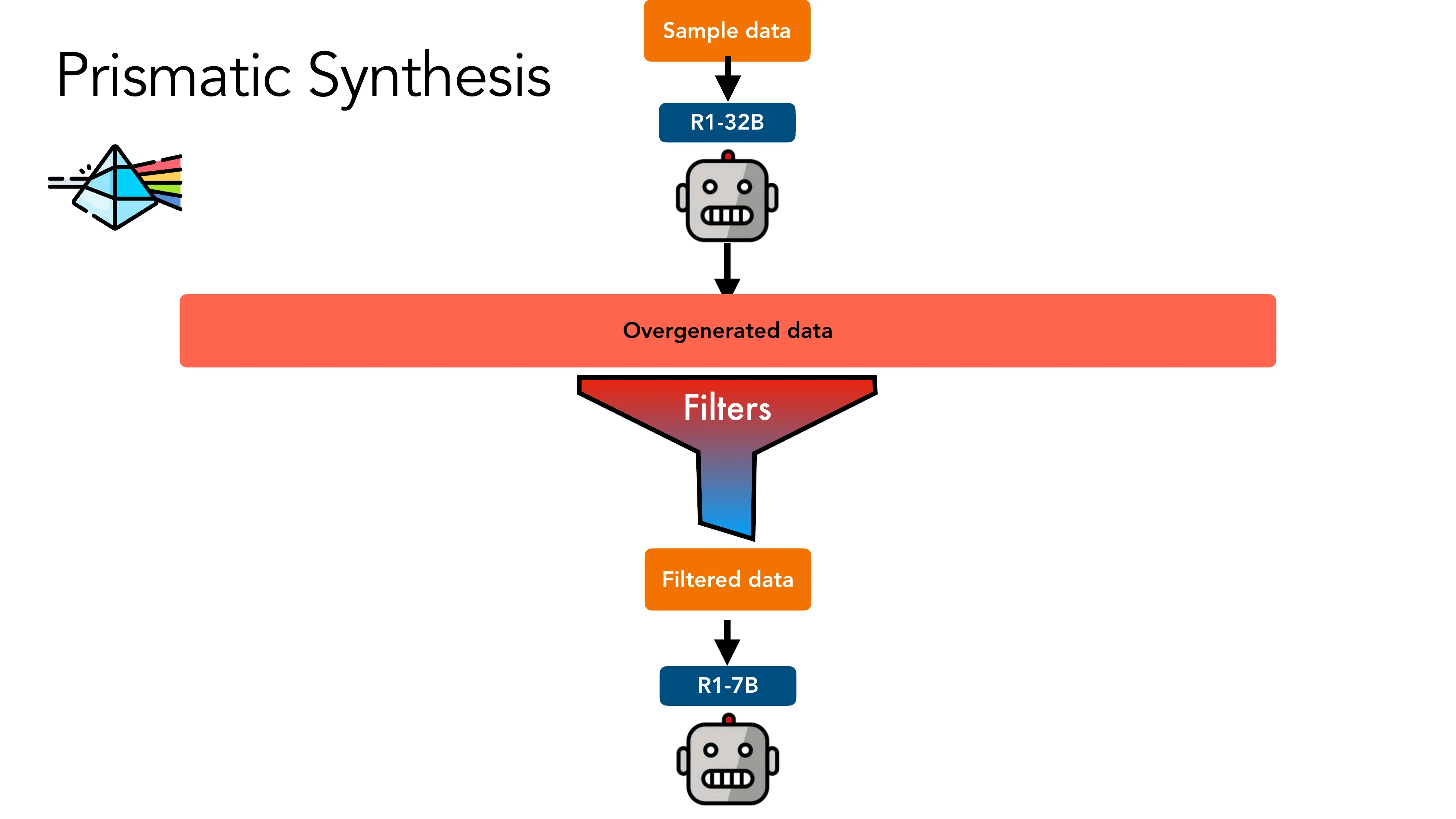
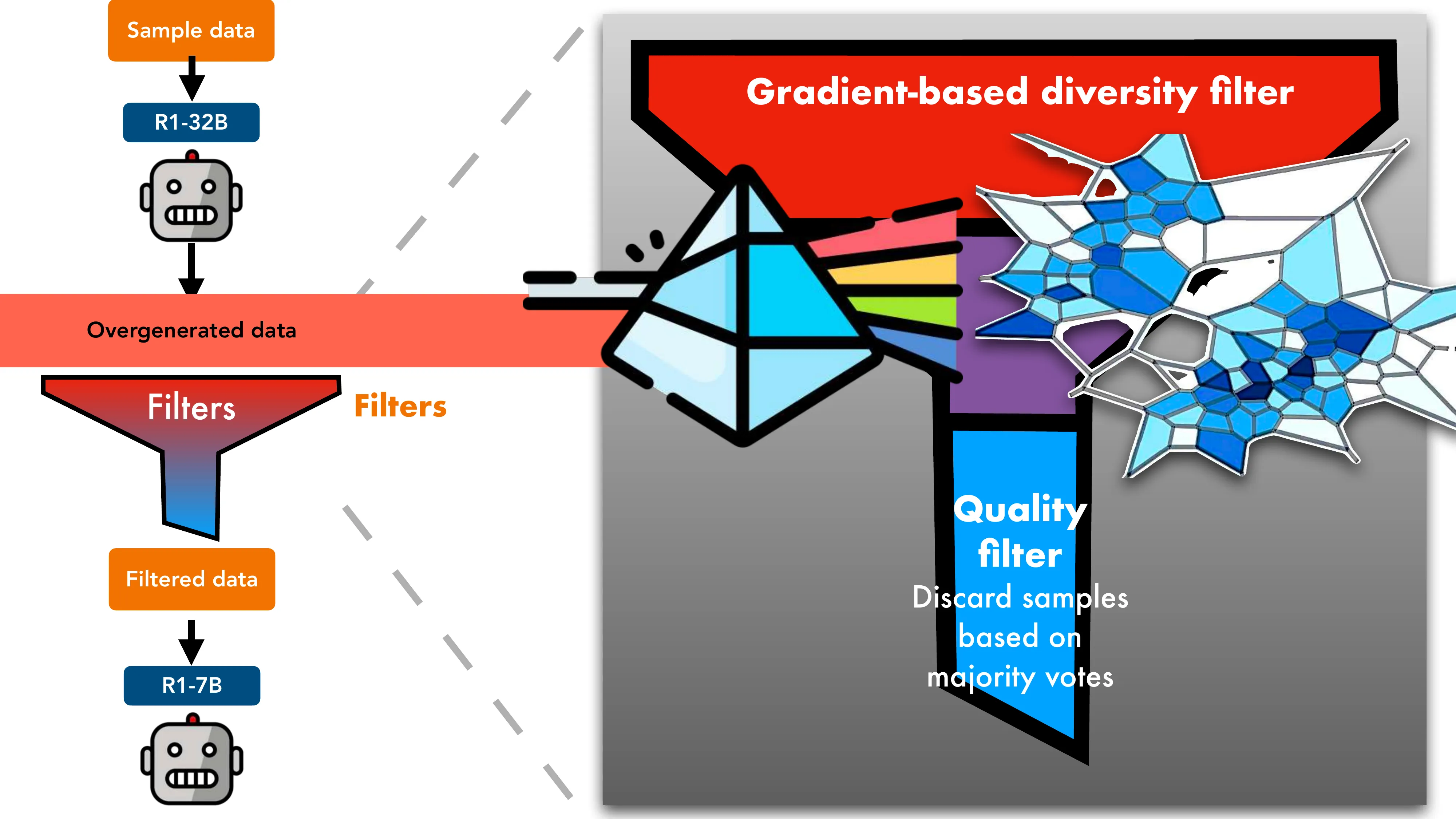
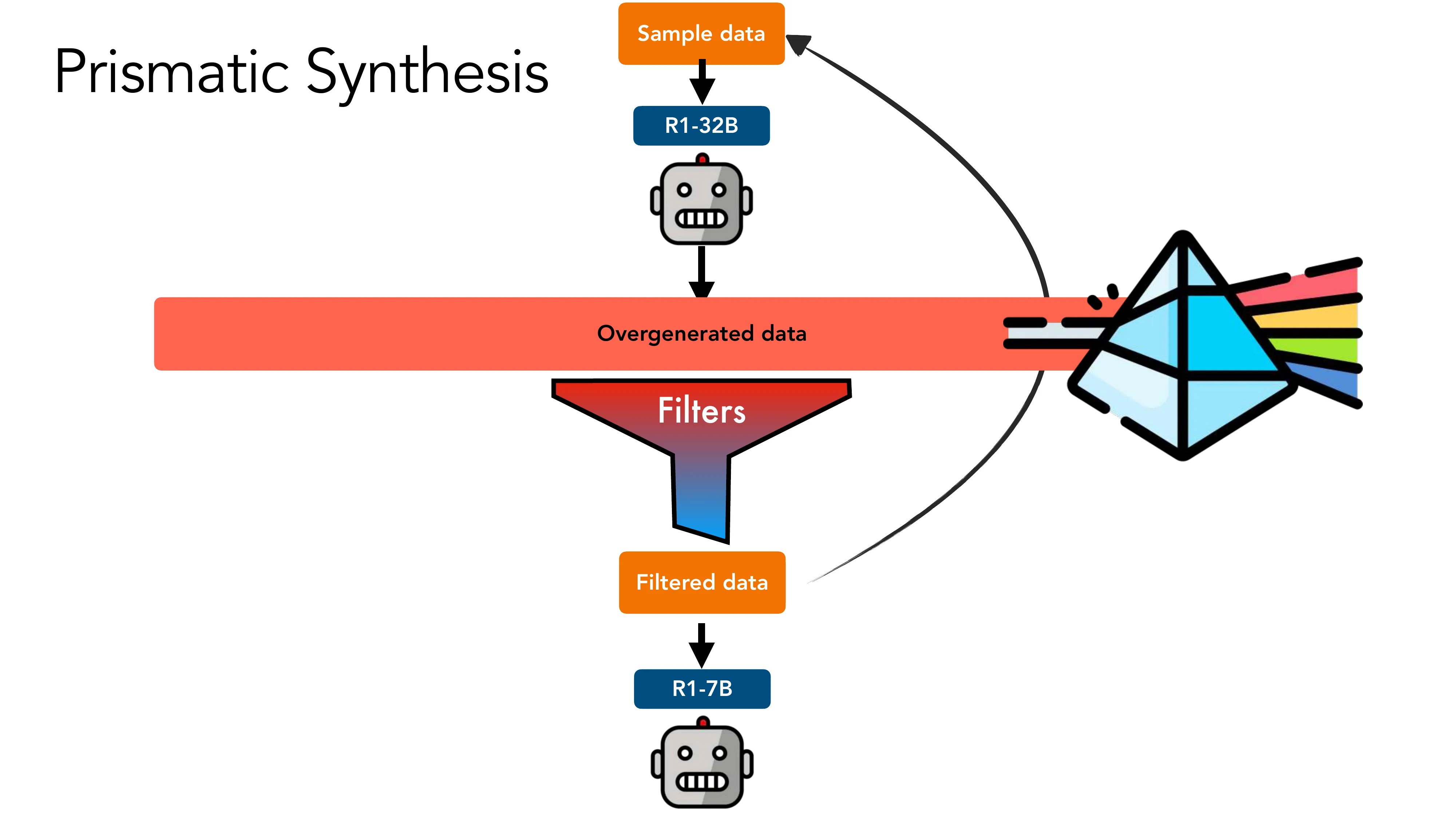


- 核心问题: 合成数据的 mode collapse — effortless synthetic data 的结论 != effortful 的
- Gradient as Data Representation: 用小参考模型计算梯度 nabla_theta P(y|x),Rademacher 投影降维到 1024 维
- G-Vendi Score: 密度矩阵的熵作为多样性度量 → 强预测 OOD 泛化能力 (R^2 > 0.82)
- Pipeline: 样本数据 → R1-32B 过生成 → Quality filter (majority vote) + Gradient-based diversity filter → R1-7B SFT
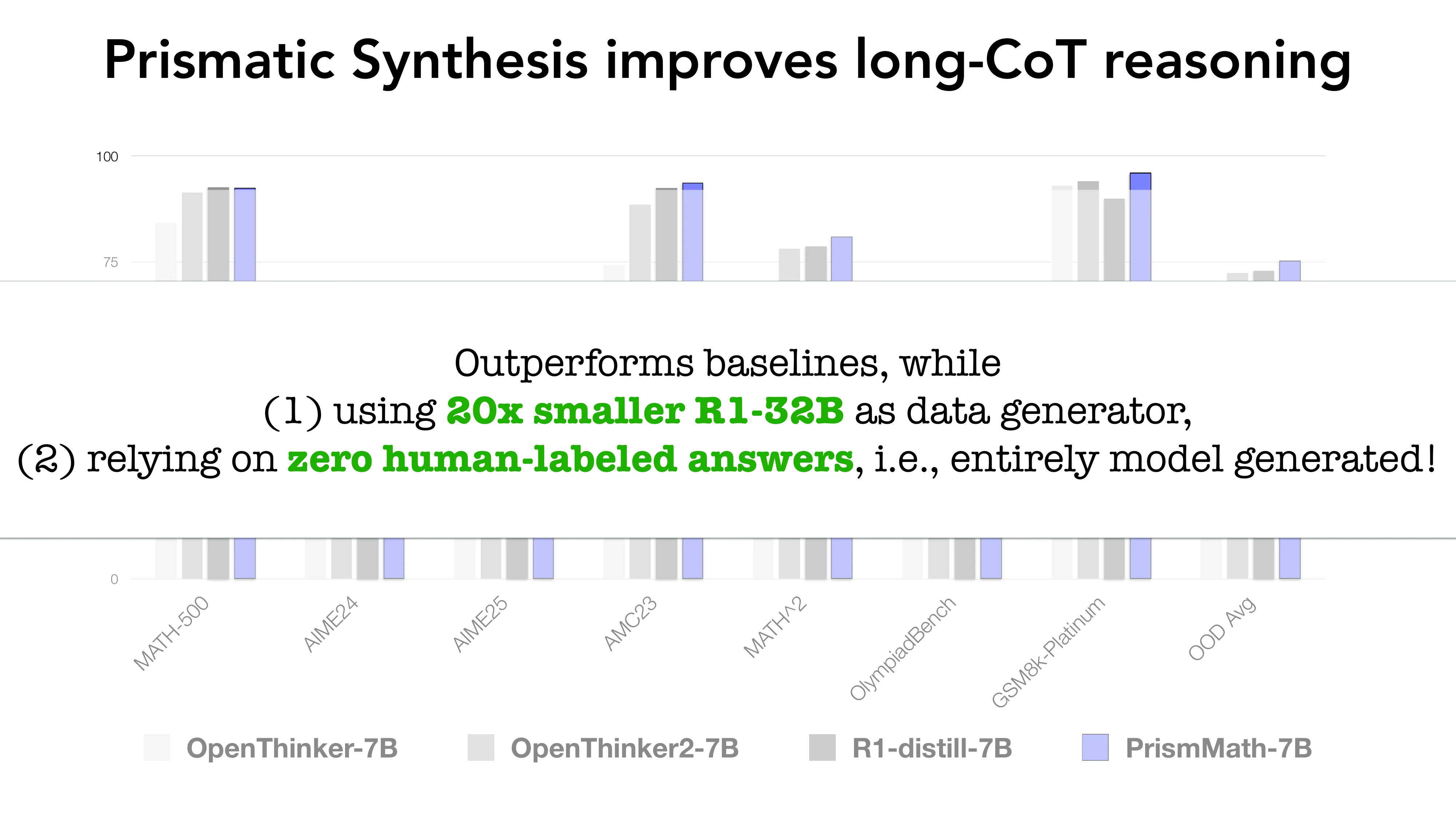
- 结果: 用 20x 小的 teacher + 零人类标注,PrismMath-7B 超越 OpenThinker/R1-distill-7B
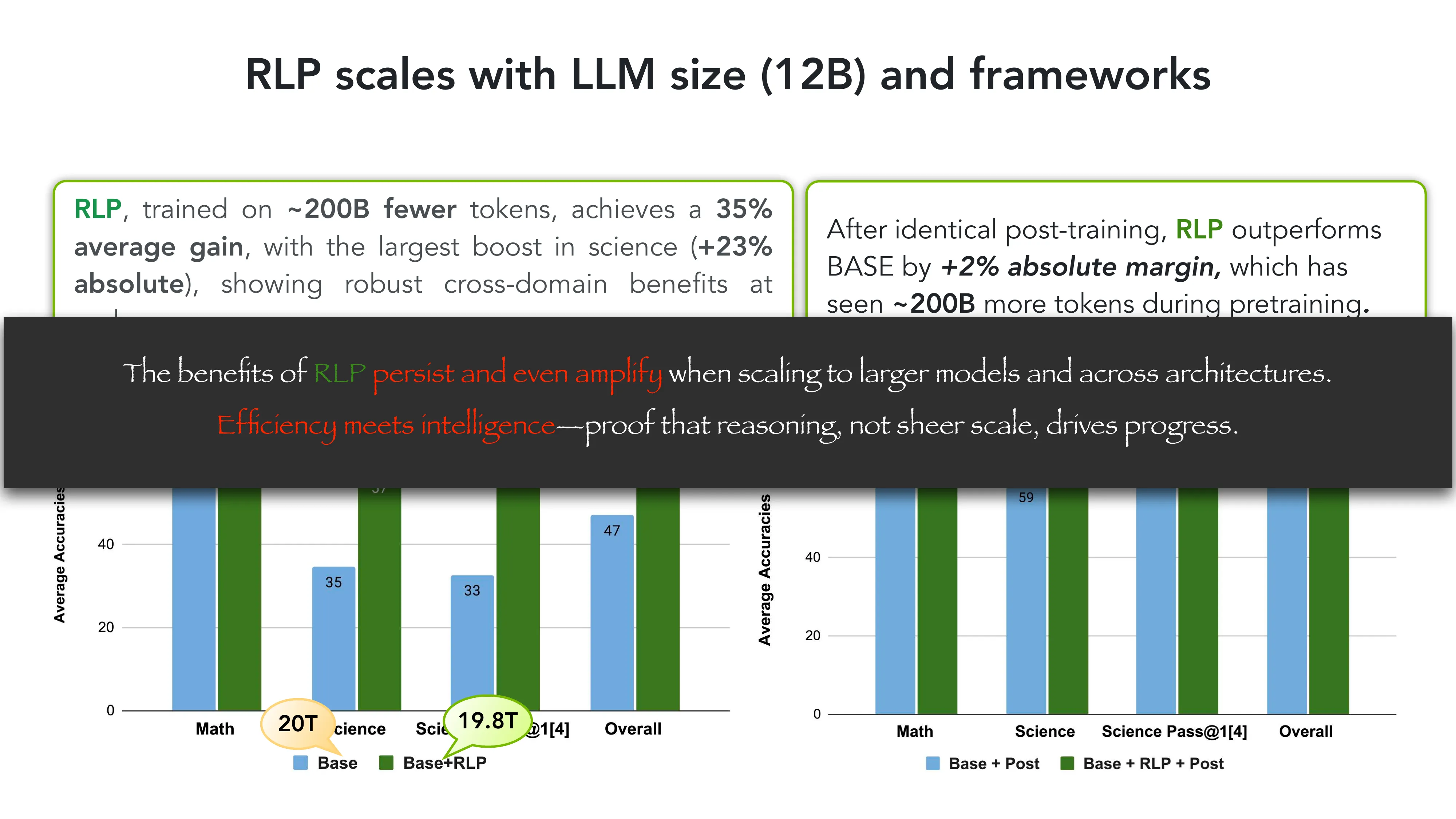
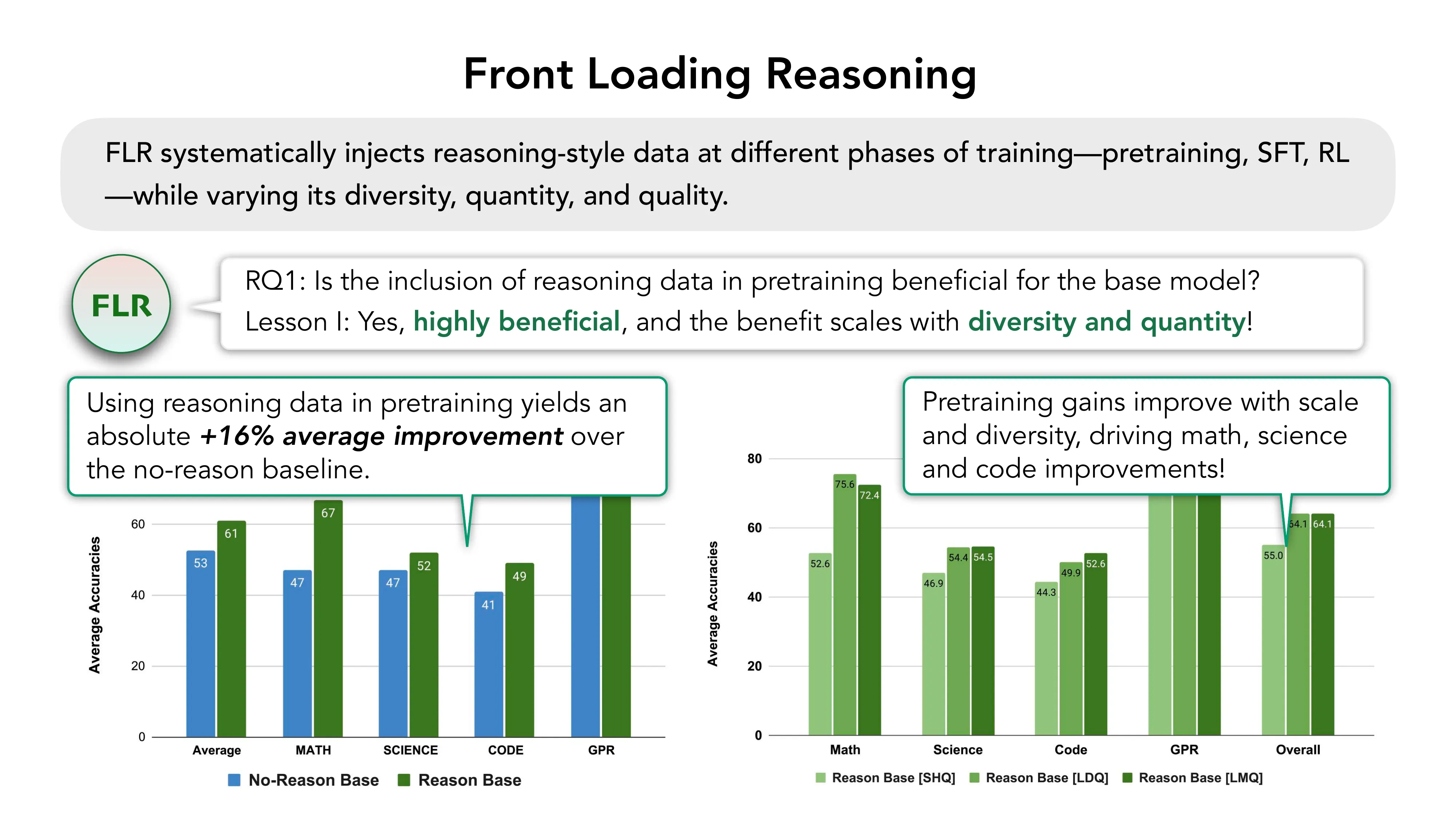
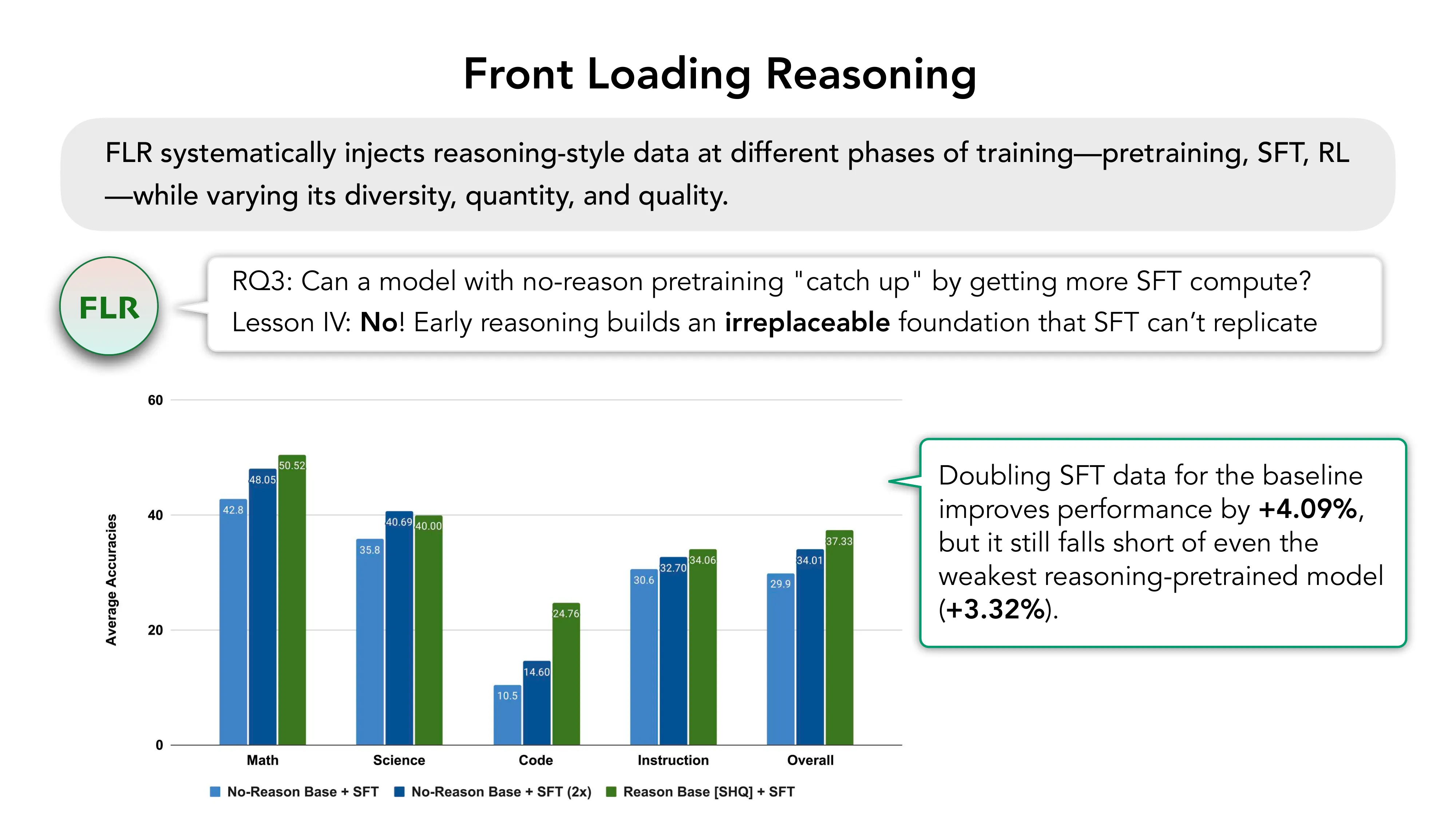
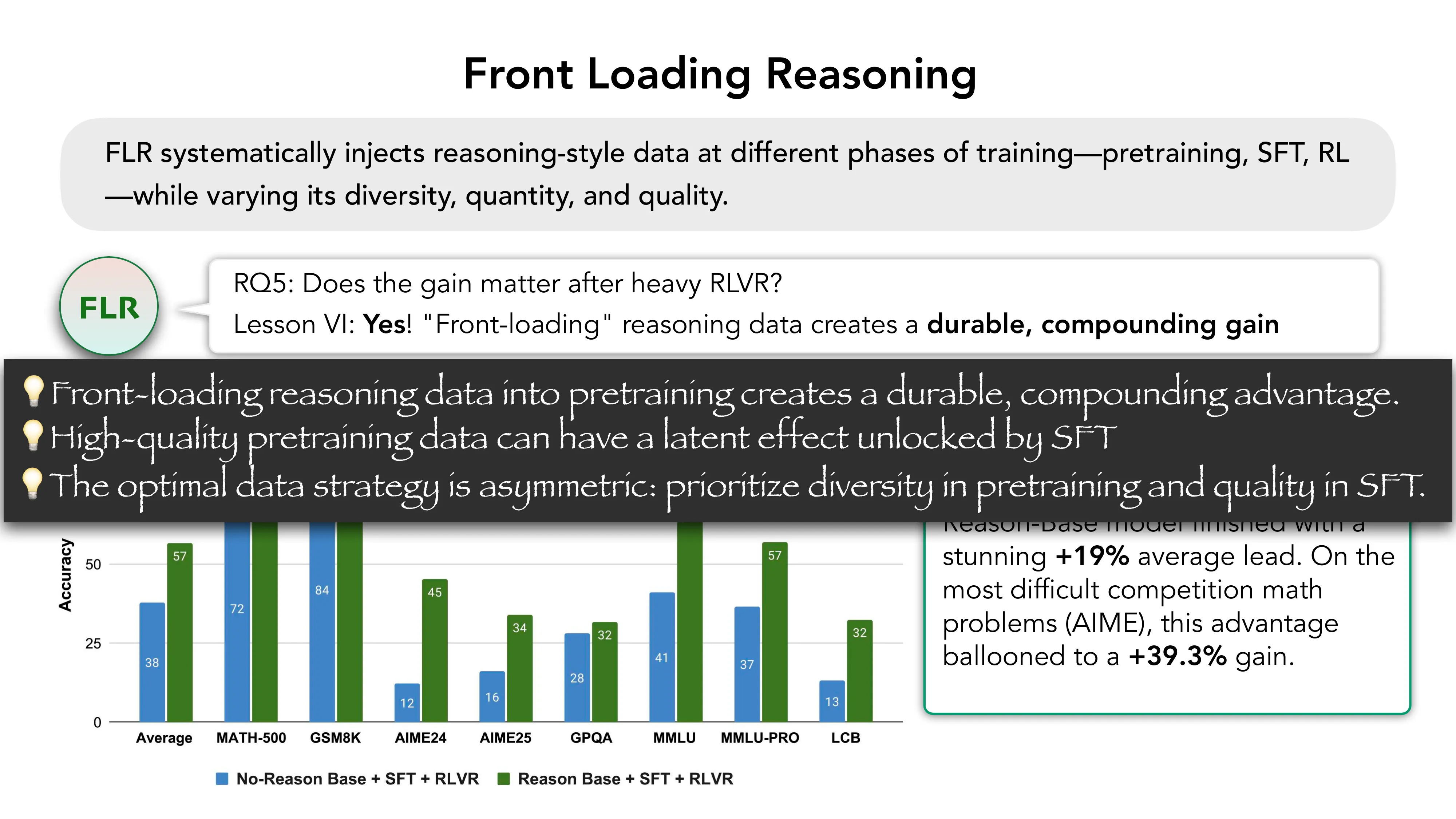
RLP: Reinforcement as a Pretraining Objective (ICLR 2026, NVIDIA)


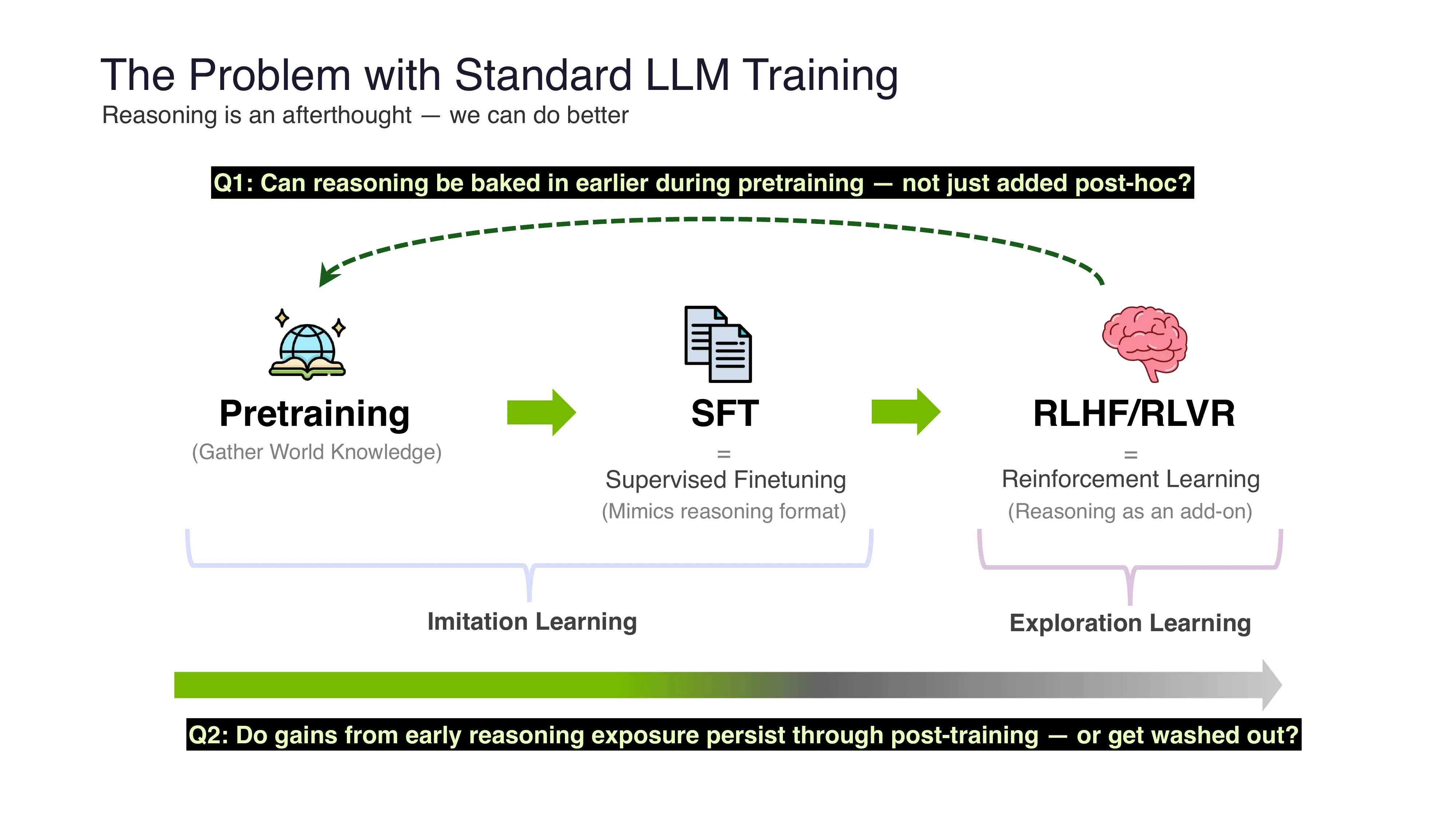
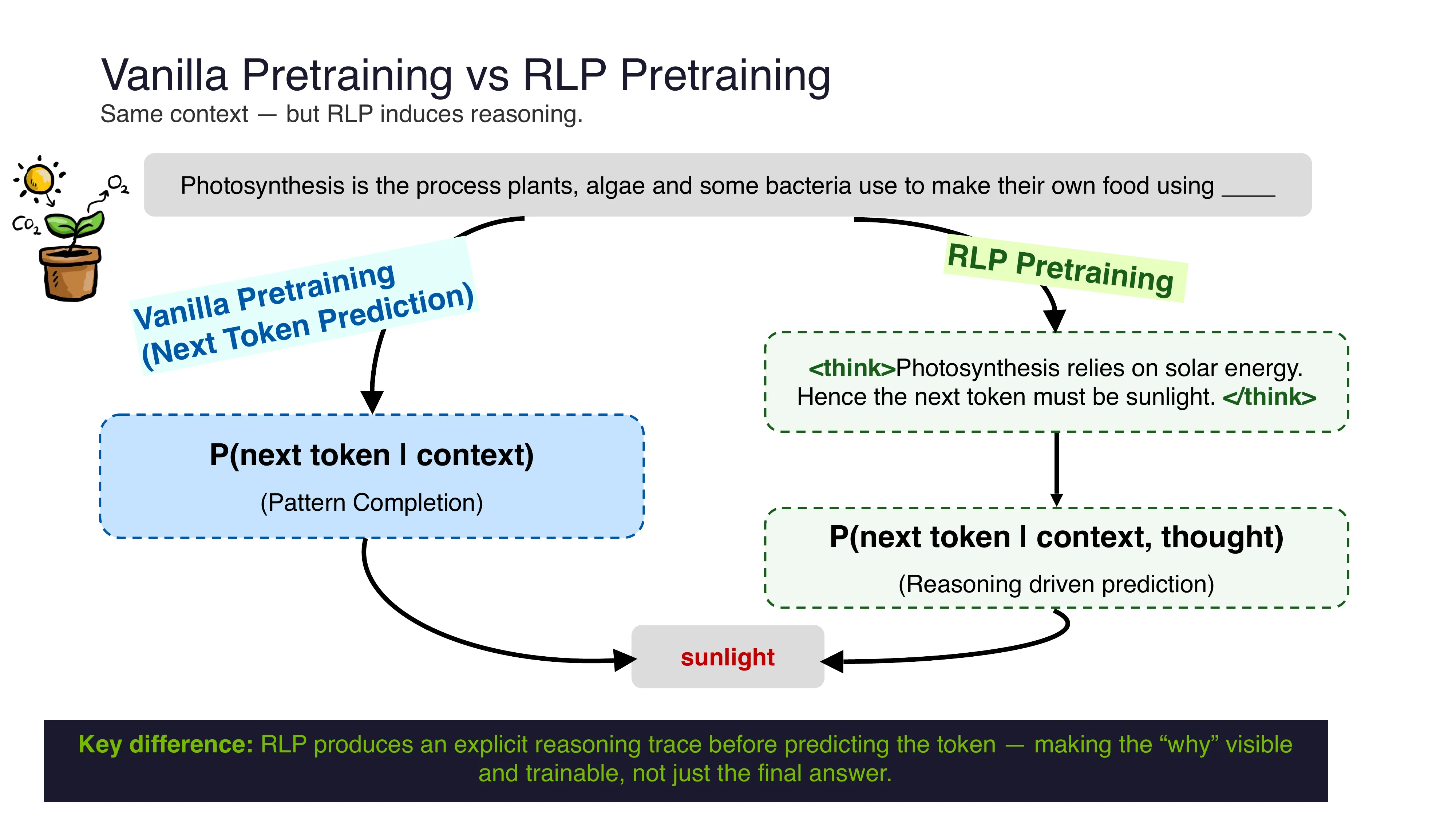

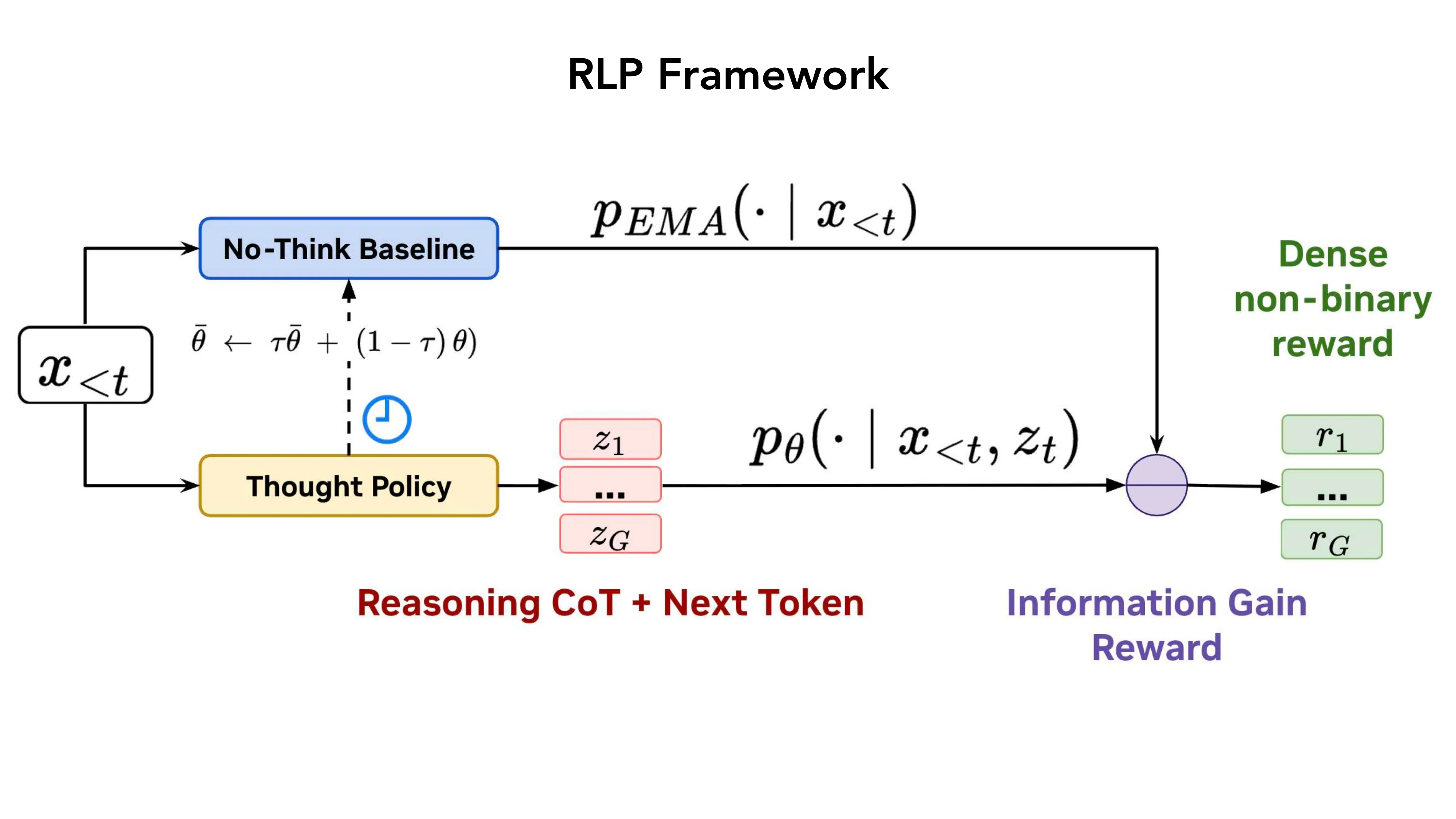


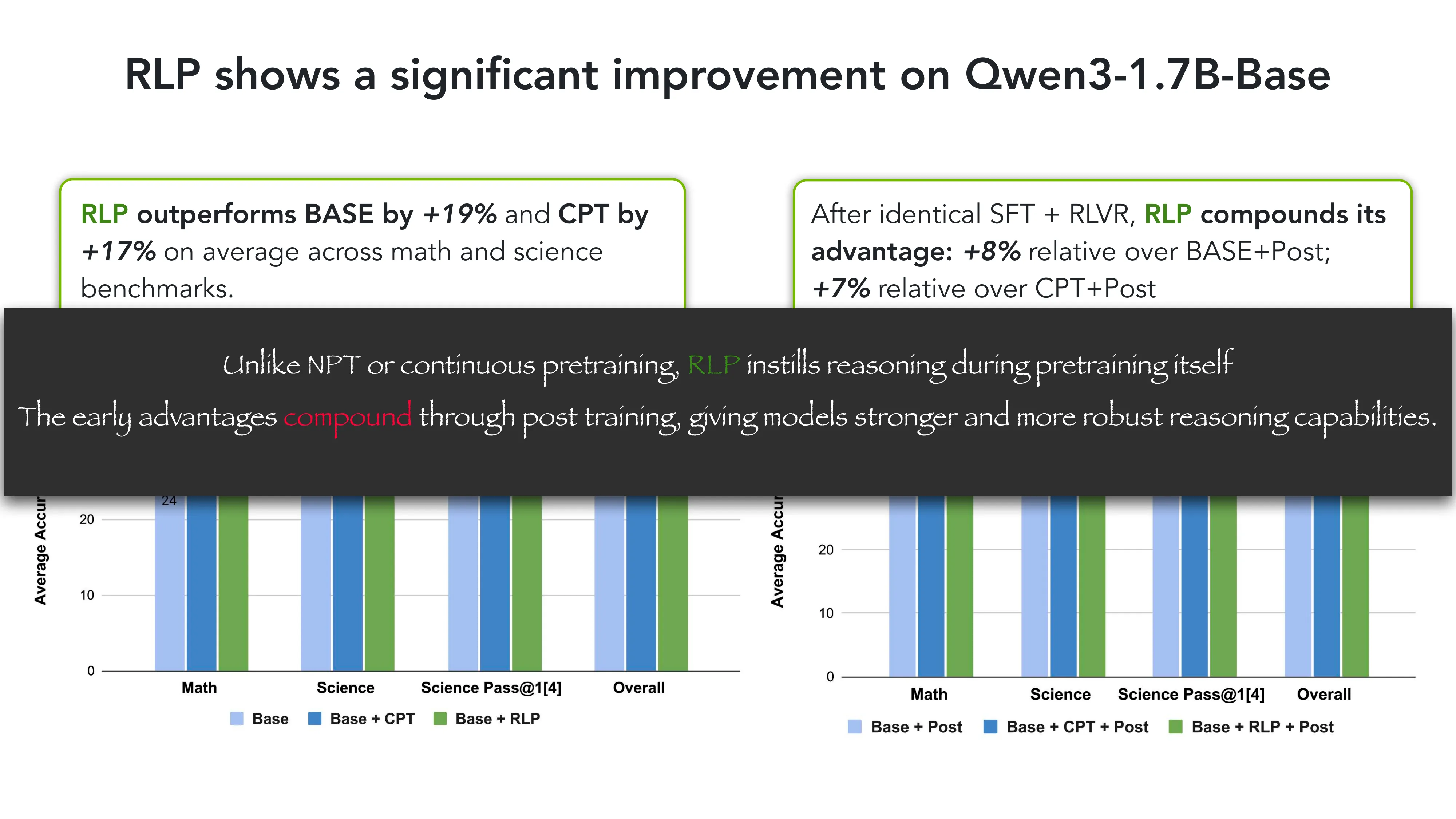
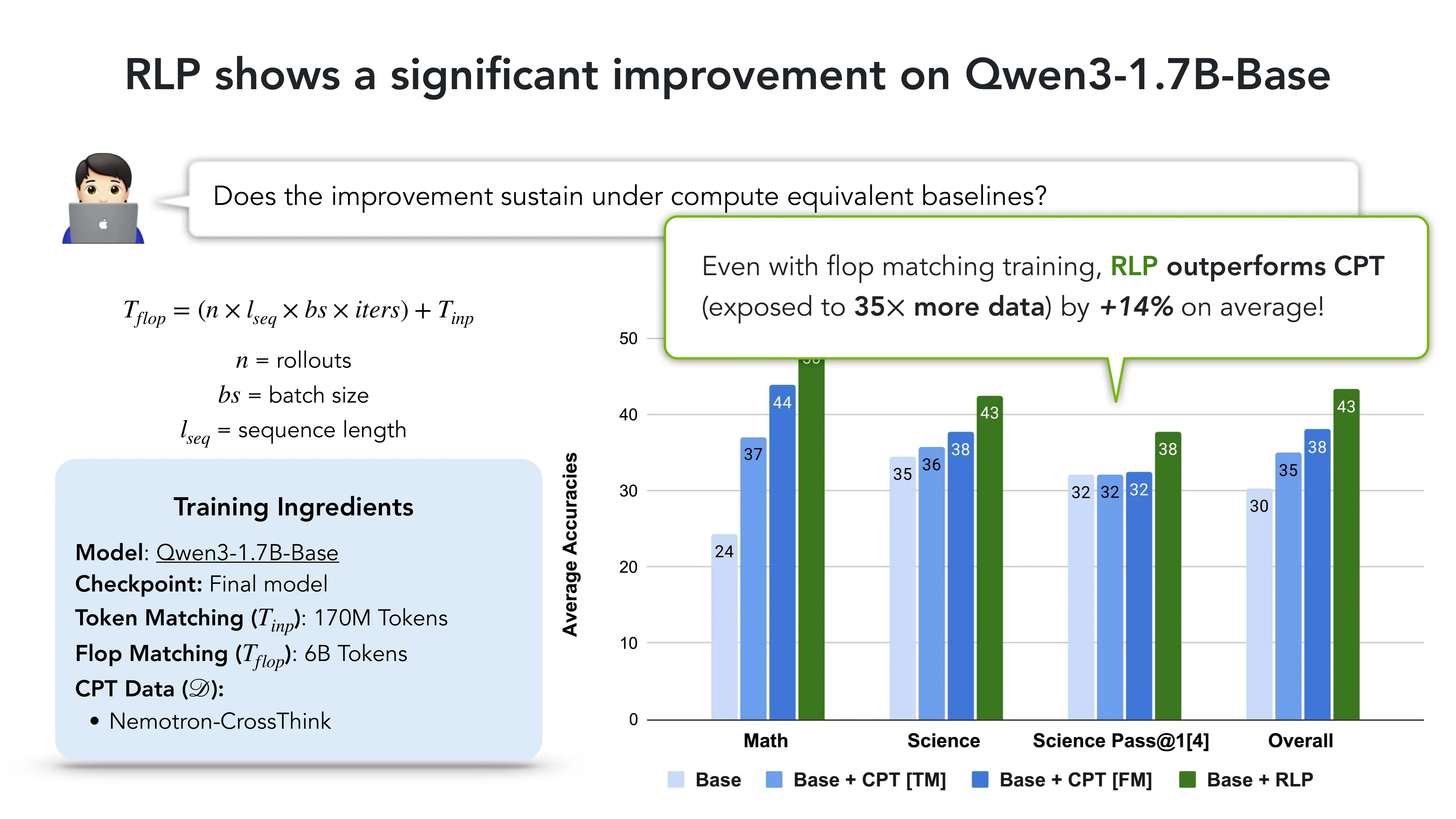








- 核心问题: 标准 LLM 训练中推理是事后补丁 — 能否在预训练阶段就注入?
- RLP vs. Vanilla Pretraining: 预测前先生成
<think>推理链,然后预测 token - Information Gain Reward: r(c_t) = log p_theta(x_t | x_{<t}, c_t) - log p_EMA(x_t | x_{<t})
- No-Think baseline 用 EMA 慢更新 (tau = 0.999)
- GRPO-style clipped surrogate,仅更新 thought tokens
- Q1 结果: RLP 在 Qwen3-1.7B-Base 上 outperforms BASE +19%, CPT +17%
- Q2 结果: RLP 的优势在 SFT+RLVR 后复合增长 (+8% vs BASE+Post, +7% vs CPT+Post)
- Compute efficiency: RLP 用 200B 更少的 token,仍优于 CPT(后者看了 35x 更多数据)+14%
🔗 三篇论文的统一视角(David vs. Goliath)
| 维度 | ProRL | Prismatic Synthesis | RLP |
|---|---|---|---|
| 创新点 | 算法(持续 RL) | 数据(梯度多样性) | 训练范式(RL 预训练) |
| 核心洞察 | 不是 RL 没用,是练得不够久 | 不是合成数据差,是选得不够好 | 不是预训练不能推理,是目标函数没要求 |
| 小模型 vs 大模型 | 1.5B ≈ 7B | 32B teacher > 671B teacher | 200B tokens > 7T tokens |
| 关键技术 | DAPO 非对称裁剪 | G-Vendi Score | Information Gain Reward |
统一主题:Effortless 的结论 ≠ Effortful 的结论。在数据、算法、训练范式三个维度上,“精心设计”可以击败”暴力堆砌”。
David vs. Goliath — 三大创新要素











- Unconventional data: Prismatic Synthesis — 梯度驱动多样化
- Unconventional algorithms: ProRL — 持续 RL + 熵控制; RLP — RL 作为预训练目标
- Unconventional collaboration: 开源生态(NVIDIA 领跑,中国实验室紧随)
推荐阅读
- ProRL (Liu et al. NeurIPS 2025) — Prolonged RL Expands Reasoning Boundaries in LLMs
- Prismatic Synthesis (Jung et al. NeurIPS 2025) — Gradient-based Data Diversification Boosts Generalization in LLM Reasoning
- RLP (Hatamizadeh et al. ICLR 2026) — Reinforcement as a Pretraining Objective
- BroRL — Scaling RL via Broadened Exploration
- Does Math Reasoning Improve General LLM Capabilities? (Huan et al.)
- SFT Memorizes, RL Generalizes (Chu et al.)
- Does RL Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? (Yue et al.)
- Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining (Zhao et al.)
- Spurious Rewards: Rethinking Training Signals in RLVR (Shao et al.)
关联概念
- Scaling Laws, GRPO, DAPO, Entropy Collapse
- Synthetic Data, Reinforcement Learning
- Test-Time Compute, Chain-of-Thought
- L16 Social Impact
- L12 Reasoning Part 1, L13 Reasoning Part 2
个人笔记
- Yejin Choi 的”Smaller but Better” & “Algorithms for the Win” 主题与 AdaGrow 的核心理念完美契合
- ProRL 的 sustainable entropy 机制(动态 clip ratio)可以借鉴到 AdaGrow 的训练调度中
-
G-Vendi Score 用梯度表示数据多样性的思路非常新颖,值得深入研究