L14: Tokenization and Multilinguality
Week 7 · Thu Feb 19 2026 08:00:00 GMT+0800 (中国标准时间)
L14: Tokenization and Multilinguality
- Guest Lecture: Julie Kallini
- A4 due
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
1. 什么是词?什么是 Token?


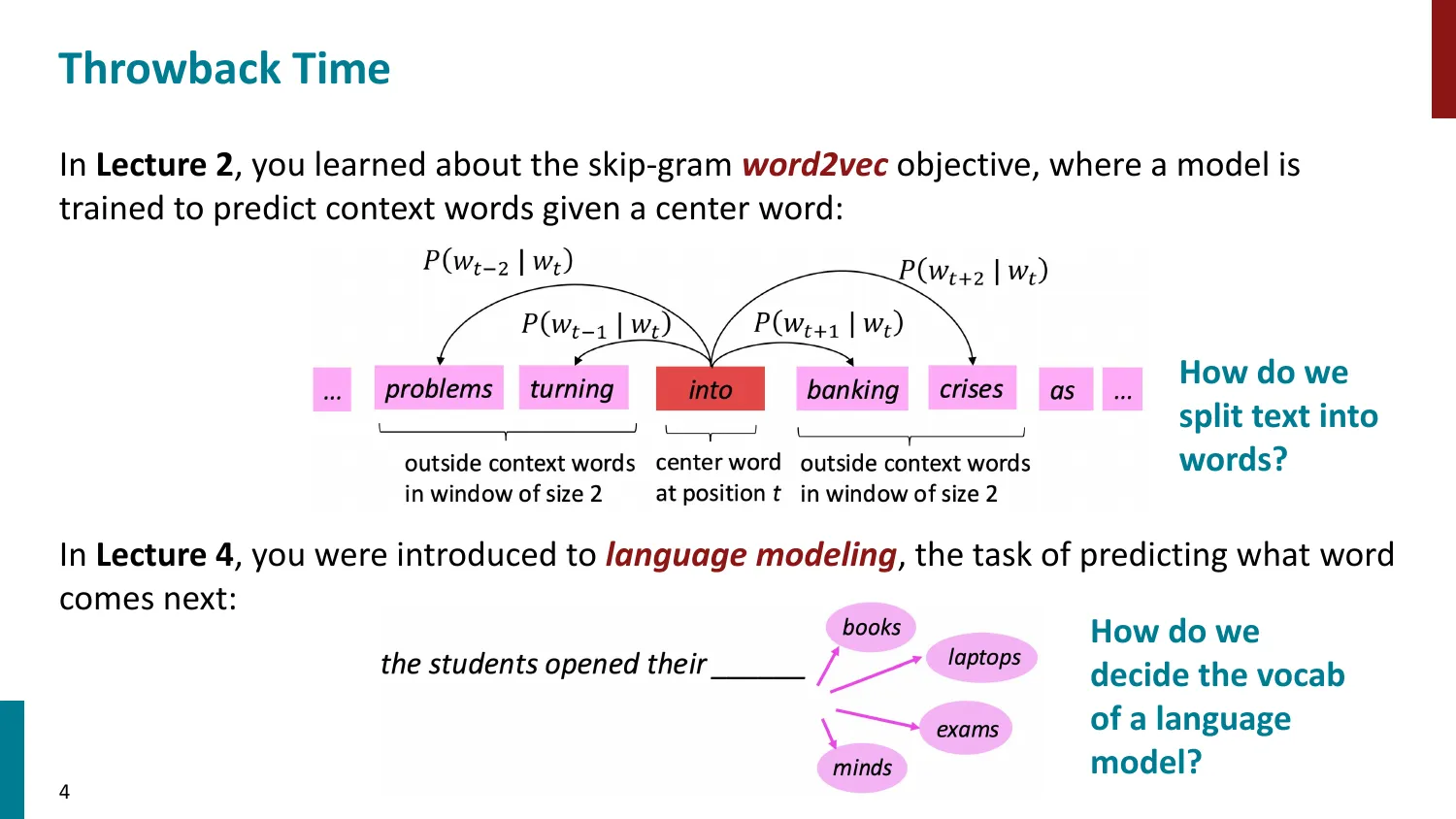
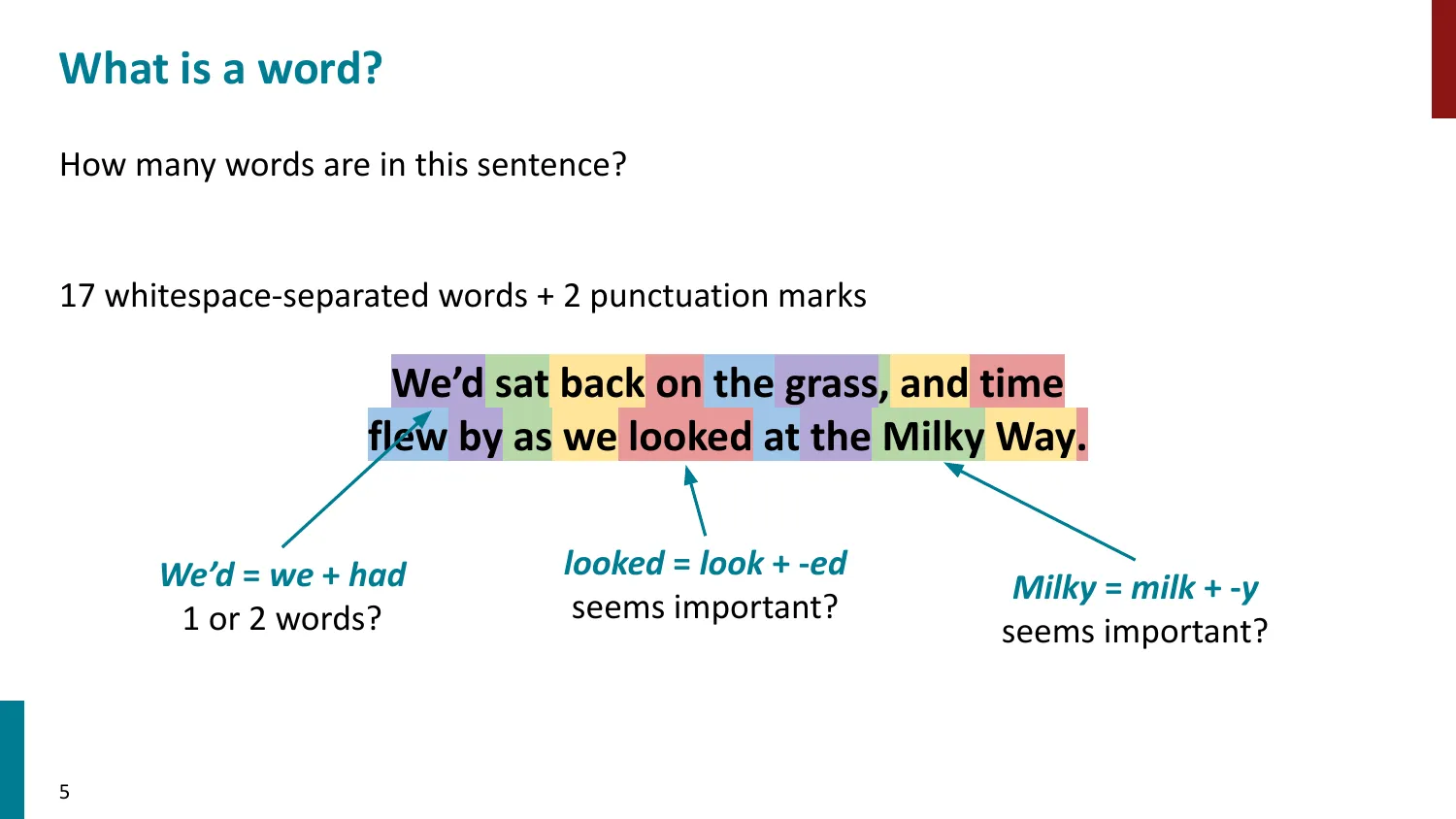
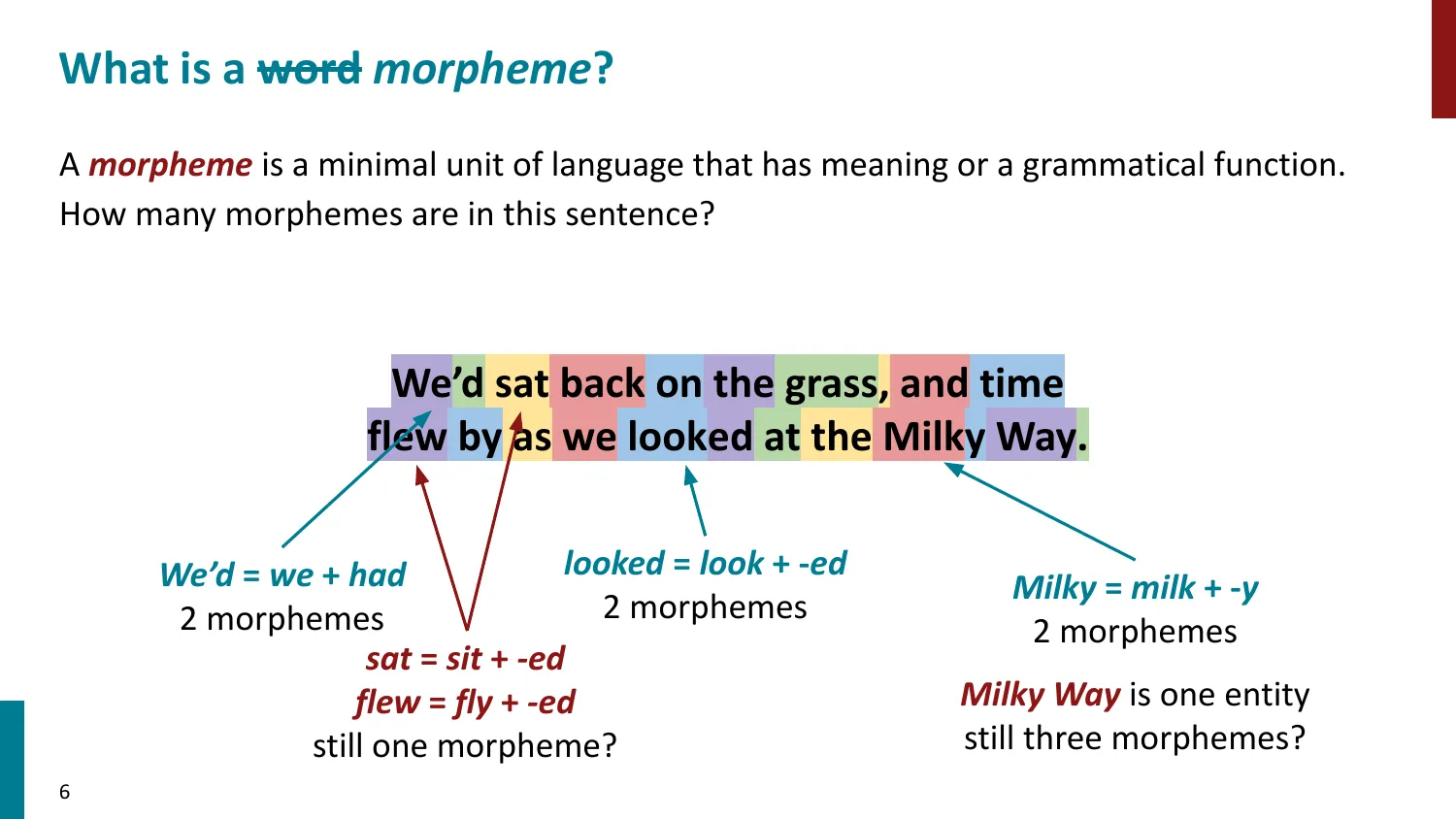



- 回顾 word2vec(skip-gram)和语言建模中的”词”概念
- 词(word) vs 语素(morpheme) vs 字符(character) vs 短语(phrase)
- 语素是最小有意义单位(如 “looked” = “look” + “-ed”)
- 词边界本身就模糊(如 “We’d” = 1 词 or 2 词?)
- Token:LM 的基本语言单位
- Tokenization:将文本分割为 token 的过程(预处理步骤,非模型本身)
- Vocabulary:所有已知 token 的集合
📐 词的定义歧义与 Tokenization 的正式定义
对于字符串 ,tokenization 是一个函数 ,每个 (词表)。
关键约束:(近似可逆性,信息损失极小)
Tokenizer 需要处理的歧义:
- 空格:“don’t” = [“don”, ”’”, “t”] 还是 [“don’t”]?
- 中文:无空格分隔,“我爱中国” 可分为 [“我”, “爱”, “中国”] 或 [“我”, “爱中”, “国”]
- 特殊字符:表情符号 ”😊” = 单 token?多 token?
- 数字:“1234” = 一个 token?还是 [“1”, “2”, “3”, “4”]?
- 大小写:“Apple” 和 “apple” 是同一 token 吗(取决于 tokenizer 是否 case-sensitive)?
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
同一段文字用不同 tokenizer 的结果:“Hello, World! 你好世界”
| Tokenizer | 分词结果 | Token 数 |
|---|---|---|
| GPT-4o (tiktoken cl100k_base) | [“Hello”, ”,”, ” World”, ”!”, ” 你好”, “世界”] | 6 |
| BERT (WordPiece) | [“Hello”, ”,”, “World”, ”!”, “你”, “好”, “世”, “界”] | 8 |
| 字符级 | 每个字符独立 | 21 |
⚠️ 常见误区
- 误区:“一个词 = 一个 token” → 正确:现代 LLM 的 token 是子词(subword)级别。“tokenization” 可能是 [“token”, “ization”] 或 [“token”, “iz”, “ation”],取决于训练语料。
- 误区:Tokenization 只是”切词”的预处理步骤,不影响模型能力 → 正确:Tokenization 深刻影响模型的计算能力(字符计数、拼写、数字运算),因为模型在 token 层面操作,而非字符层面。
2. Tokenization 如何影响 LM
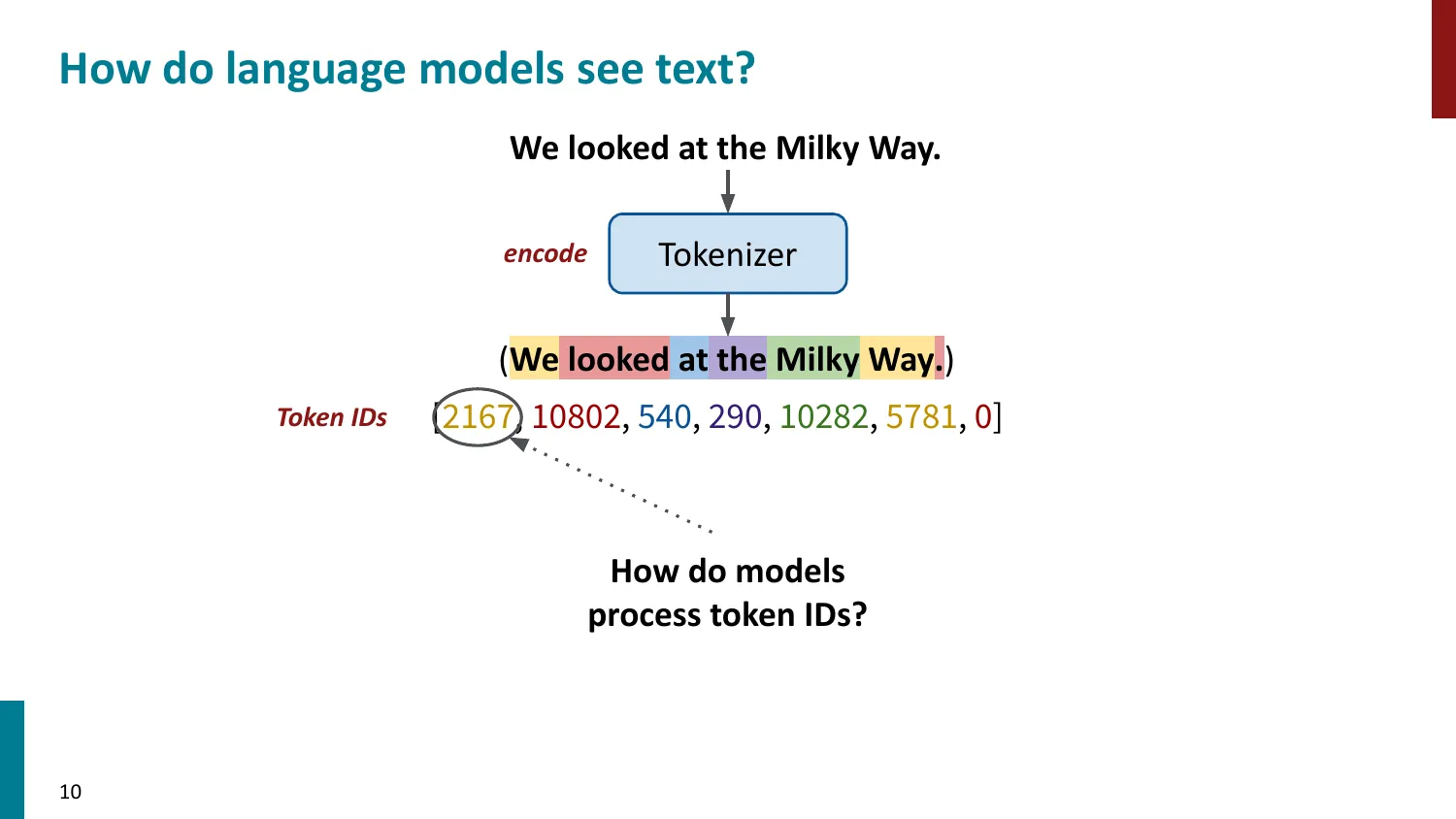
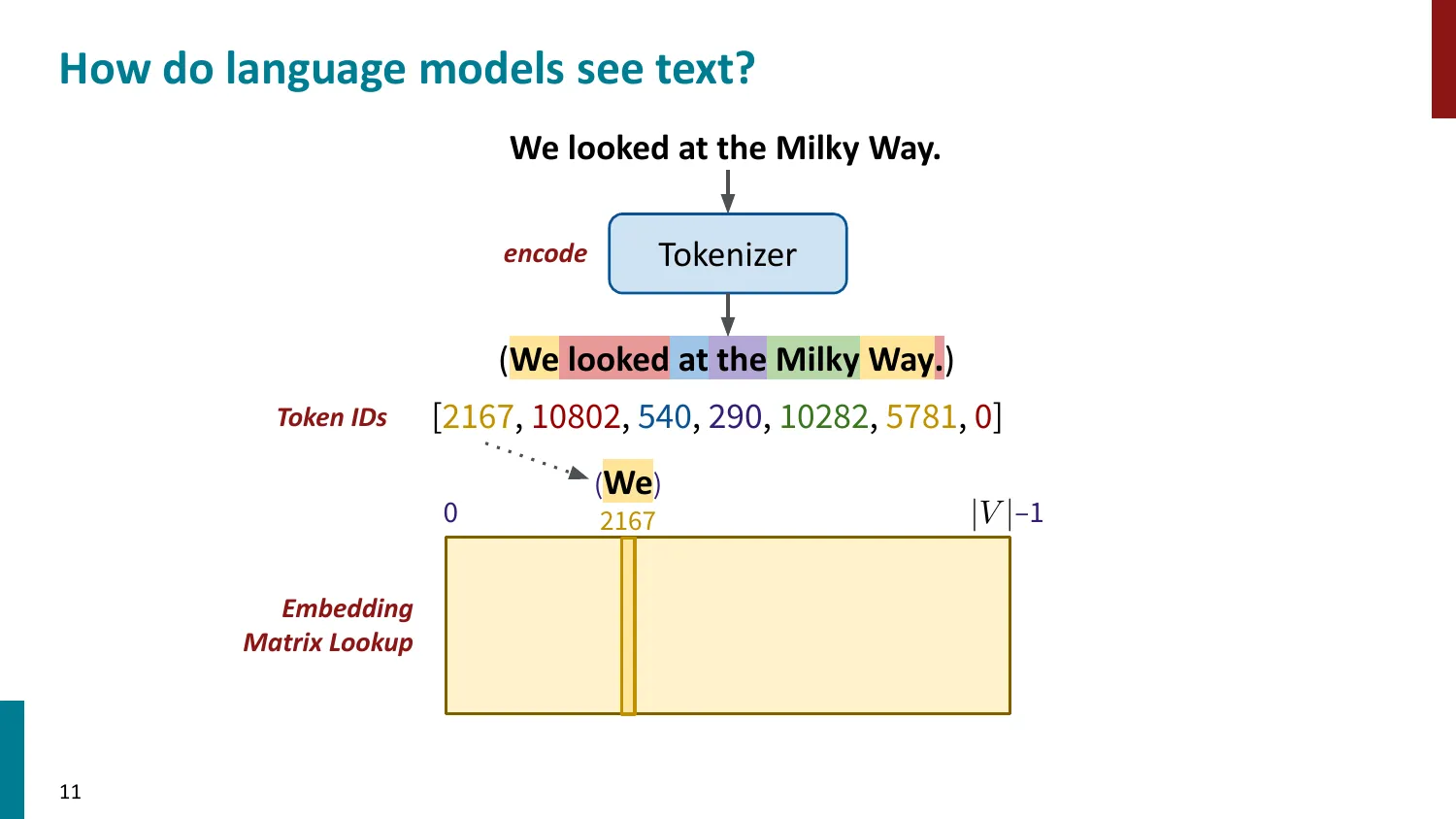
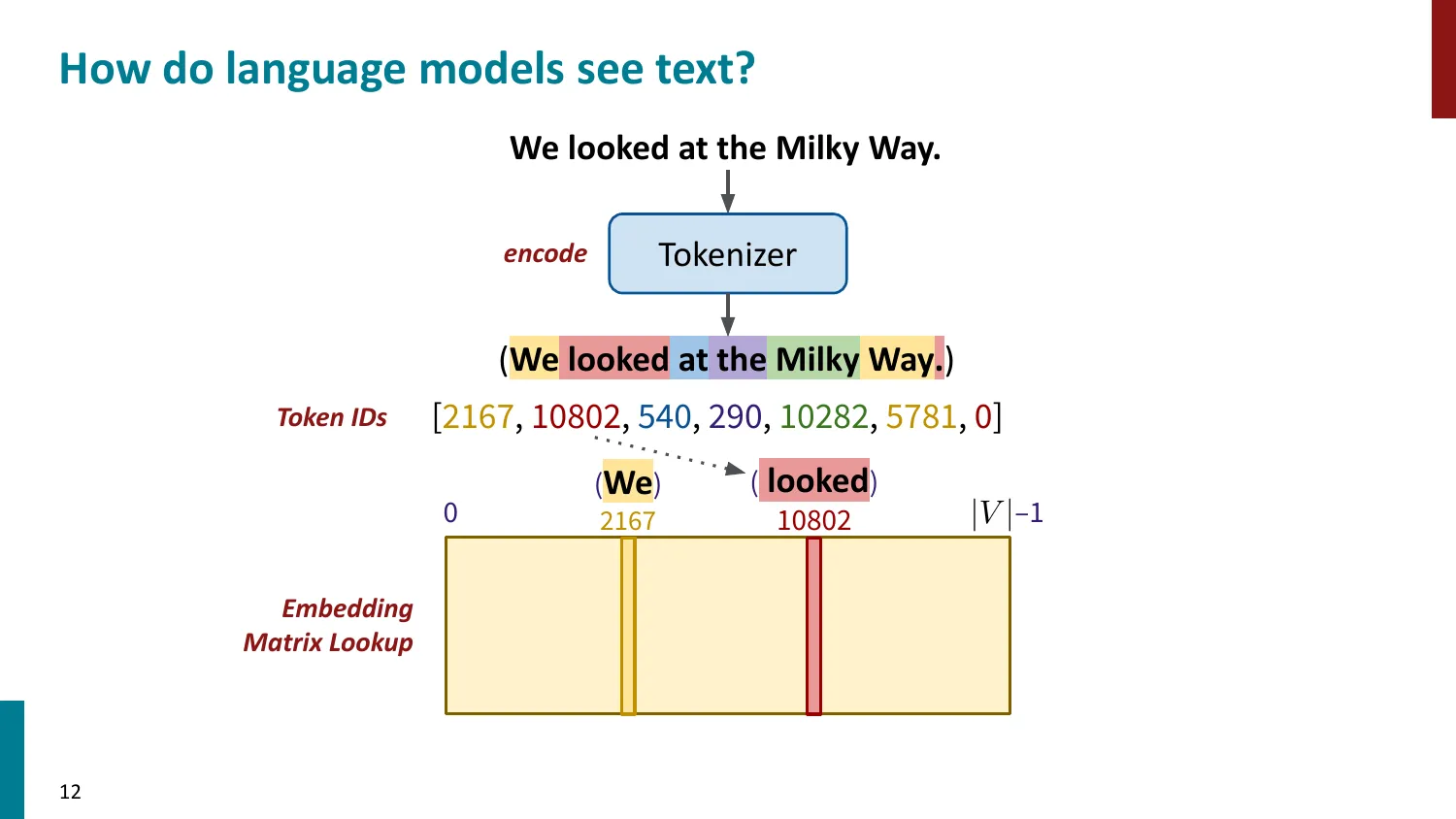
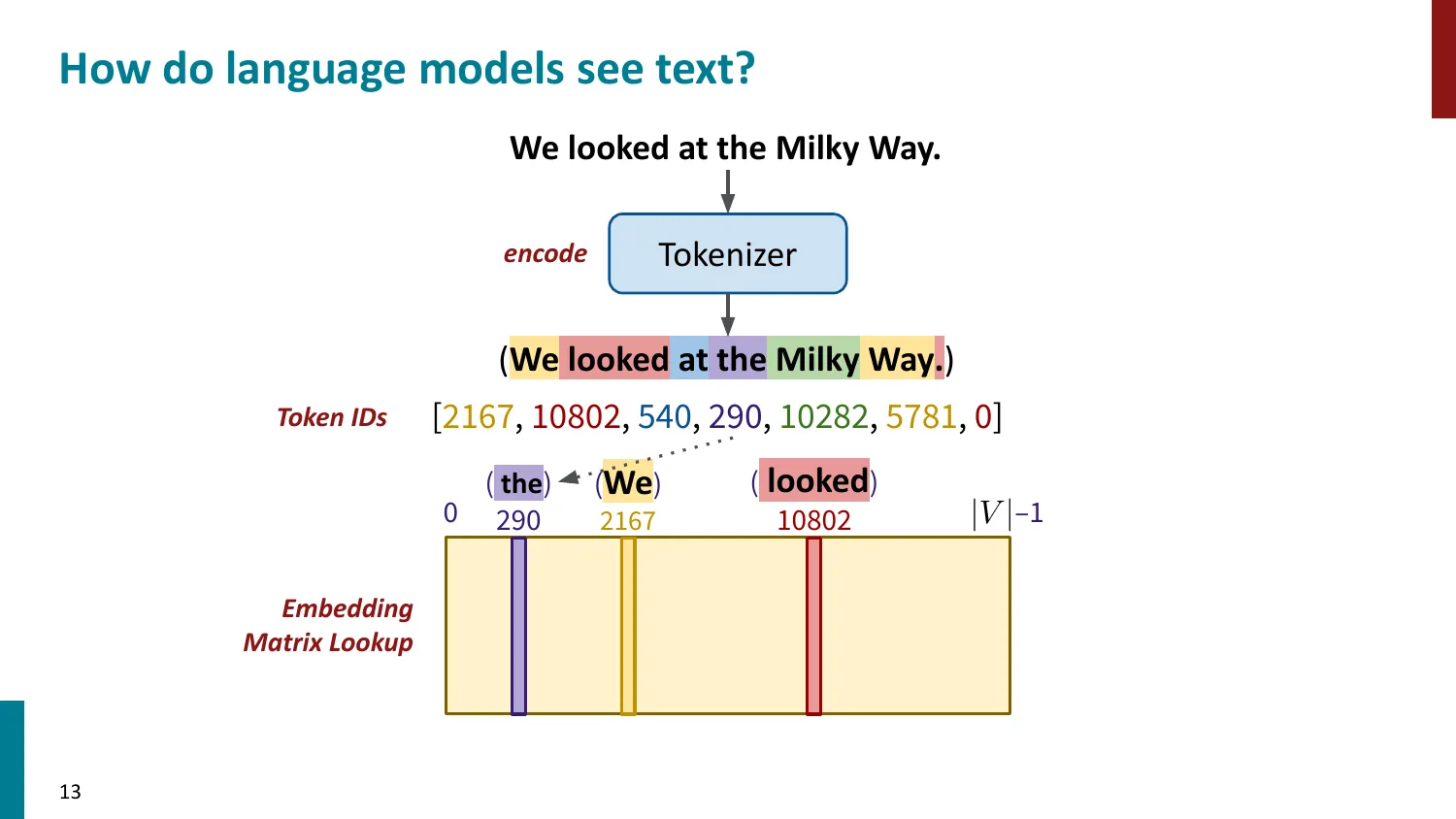

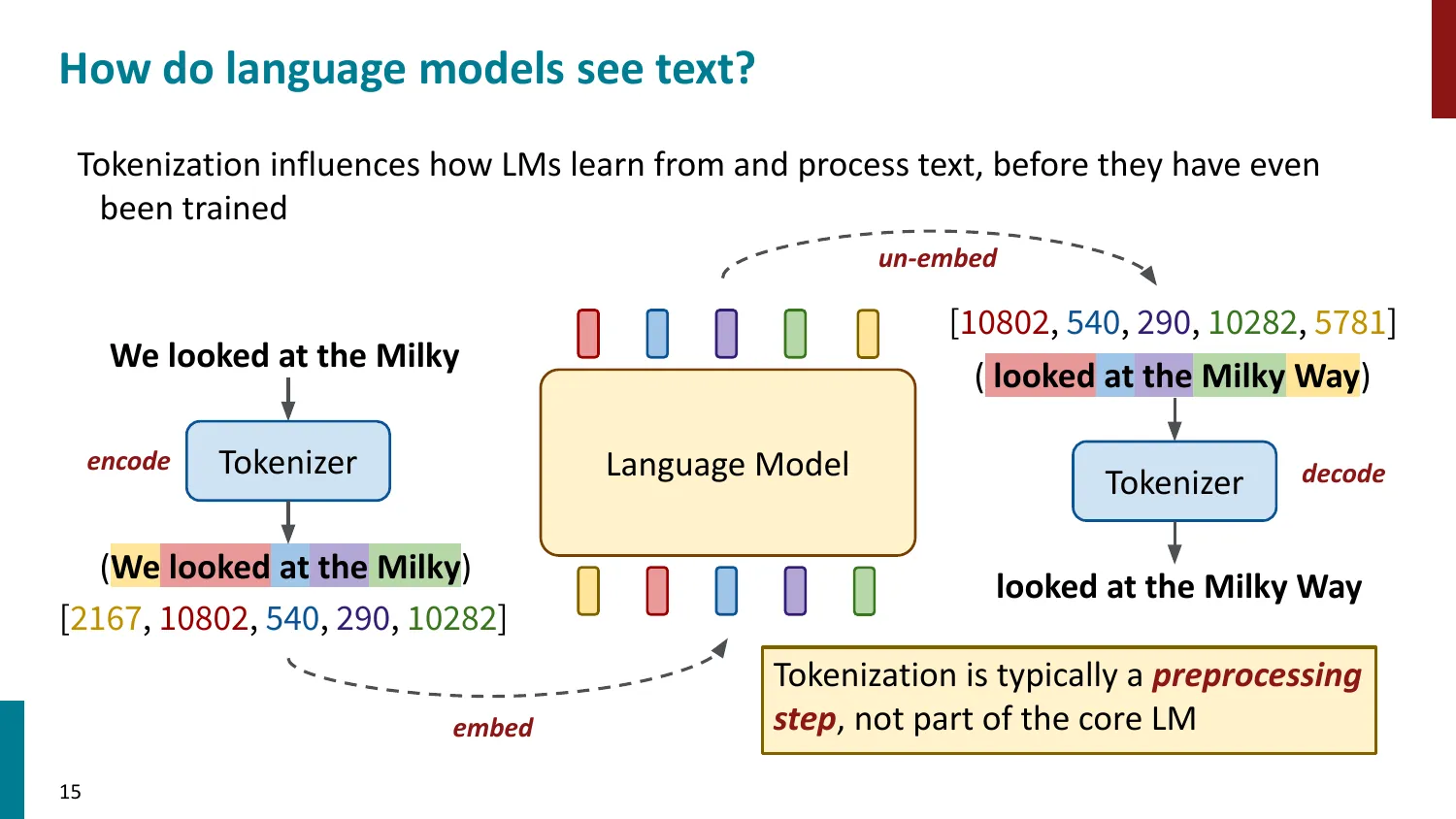
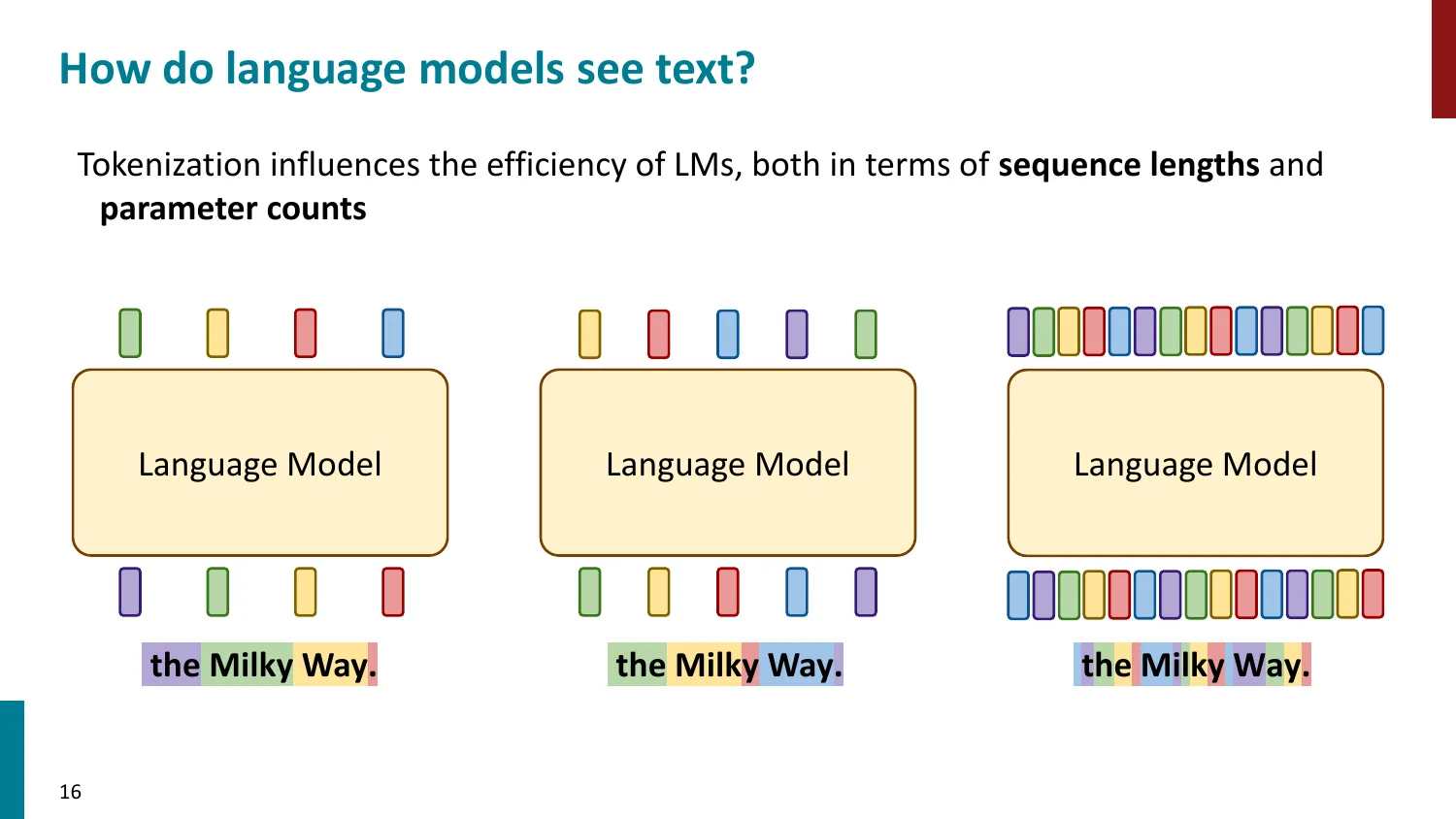
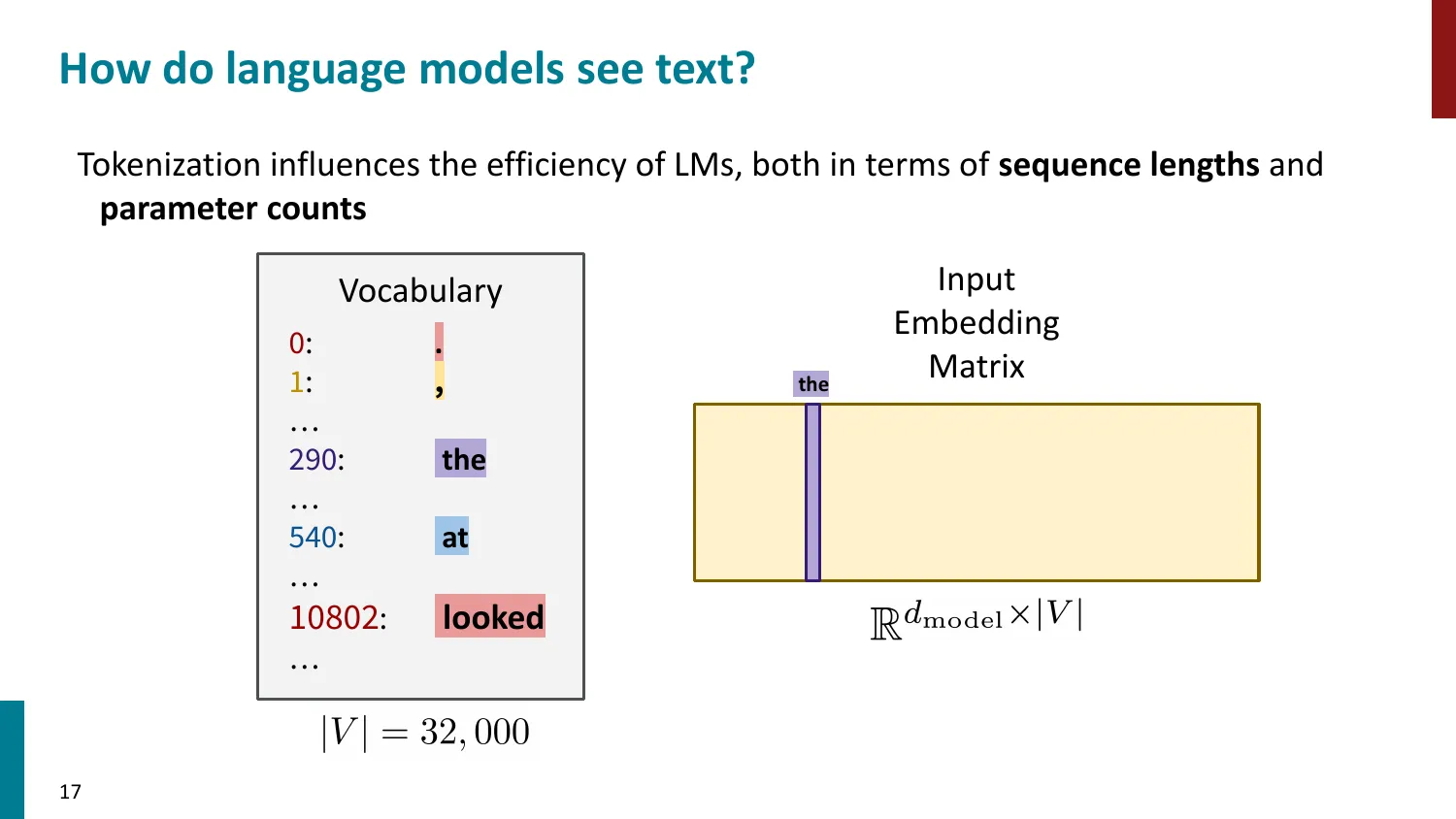
- Token ID -> Embedding Matrix 查找 -> 模型处理
- 影响序列长度(计算量)和参数量(embedding matrix 大小 )
- 同一文本在不同 tokenizer 下可能产生差异巨大的 token 序列
📐 Token 效率(Token Efficiency)的影响
对于相同文本 ,定义 Fertility(繁殖率) = 单词平均 token 数:
- 高效 tokenizer(少 token):序列短,注意力计算 代价低,推理快
- 低效 tokenizer(多 token):序列长,二次方注意力成本上升,上下文利用率低
Token 效率直接影响:
- 推理速度:序列越短,每步生成越快
- 上下文容量:同样的 context window 能放入更多语义信息
- 训练成本:同样文本用更少 token 表示,每个 step 覆盖更多语义
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
英文 vs 中文的 token 效率对比(tiktoken cl100k_base,GPT-4 tokenizer):
| 文本 | Token 序列 | Token 数 | 备注 |
|---|---|---|---|
| ”The quick brown fox” | [“The”, ” quick”, ” brown”, ” fox”] | 4 | 每词约 1 token |
| ”敏捷的棕色狐狸” | [“敏”, “捷”, “的”, “棕”, “色”, “狐”, “狸”] | 7 | 每字约 1 token |
| ”1234567890” | [“123”, “456”, “789”, “0”] | 4 | 数字切分碎 |
| ”Hello” / “hello” | [“Hello”] / [“hello”] | 1 / 1 | 大小写各占不同 ID |
⚠️ 常见误区
- 误区:中文用字符级 tokenizer 效率最高 → 正确:中文在现代 BPE tokenizer 中通常一字一 token(汉字信息密度高),已经相当高效。真正低效的是早期以英文为主的 tokenizer(如 LLaMA-1),把一个汉字拆成 2-3 个 token。
- 误区:词表越大越好(覆盖更多词)→ 正确:词表大小影响 embedding 矩阵参数量(),词表过大会占用大量参数预算,需要权衡。
3. 词级 Tokenization



- 优点:语义清晰,一个 embedding 约等于一个含义
- 缺点:
- 词汇量爆炸(Zipf’s Law:词频与排名成反比)
- OOV 问题(Out-of-Vocabulary)
- 语言持续演变(新词不断产生)
- 应对:规则预处理、UNK token(信息大量丢失)
📐 词级词表的空间爆炸(Zipf 定律)
词频分布遵循 Zipf 定律:第 高频词的频率正比于 ():
这意味着大量词出现频率极低(长尾),仍然需要存进词表。对于 1 万亿 token 的语料,唯一词数 > 1000 万(因为 “cat”, “cats”, “cat’s”, “Cat”, “CAT”, 各种拼写错误都不同)。
Embedding 层大小:
若 ,:参数量 = (40 billion),已超过整个 7B LLM 的参数量!
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
词级词表的 OOV 问题:
- 训练时词表包含 “cat”,推理时遇到 “ChatGPT”(2022年后才出现)→ UNK token(信息完全丢失)
- 若用 BPE: [“Chat”, “G”, “PT”](或类似,取决于训练语料)→ 不完美但可理解
- 词级词表若包含 “COVID-19”、“自拍”、“AIGC” 等新词,需要重新训练整个模型(词表变化 = embedding 矩阵变化)
⚠️ 常见误区
- 误区:词级分词语义最清晰,每词一个含义 → 正确:词级分词不处理词形变化(morphology)。“run”、“ran”、“running” 是三个独立 token,不共享参数,但语义相近。BPE 通过共享子词解决了这个问题(“run” 的表示影响 “running”)。
- 误区:增大词表能解决 OOV 问题 → 正确:词表永远无法覆盖所有词(新词、拼写错误、专有名词无限),OOV 只能通过子词或字节级方案从根本上解决。
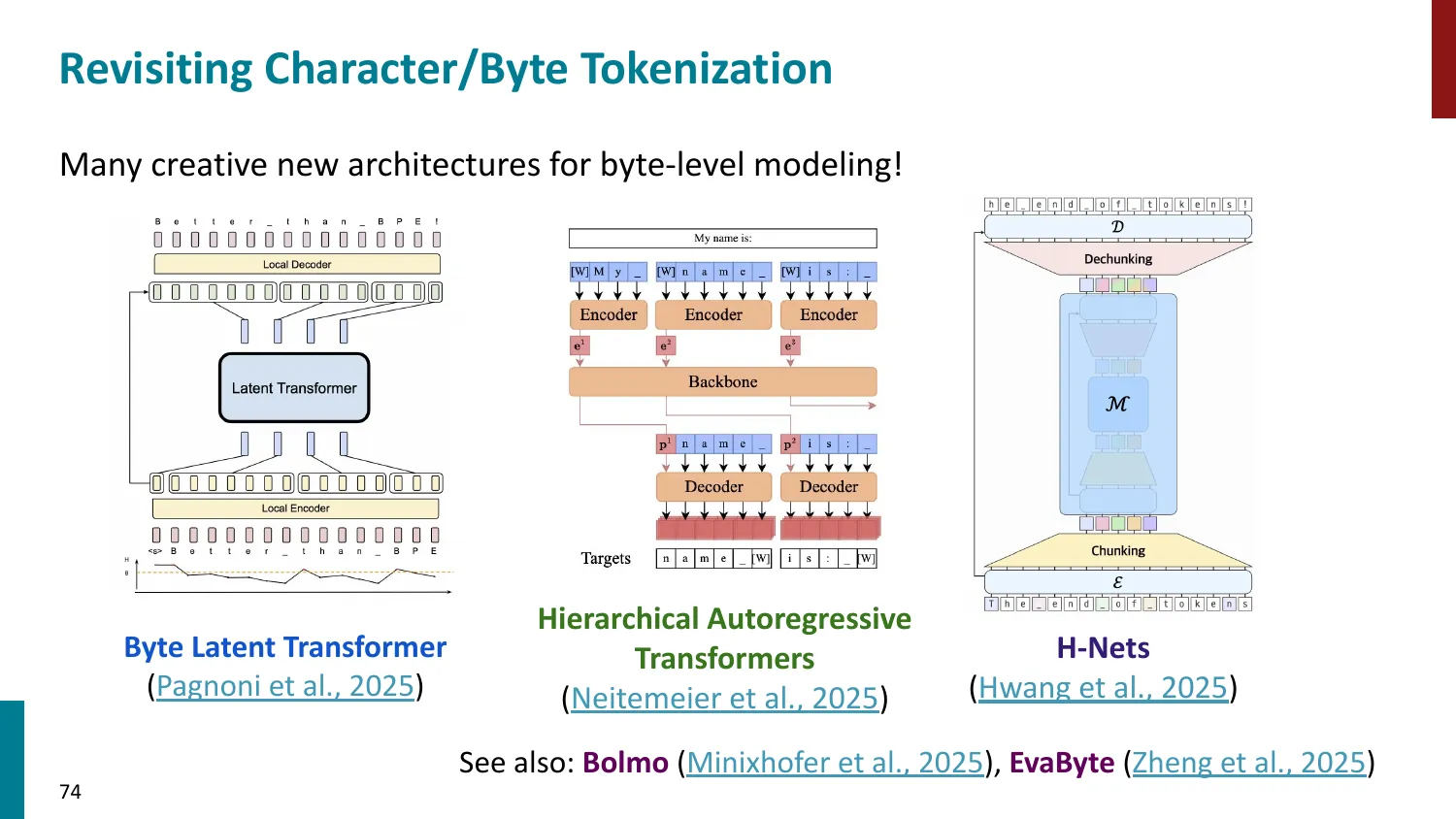
4. 字符/字节级 Tokenization

- 优点:词表小(~256 字节)、无 OOV、对拼写错误鲁棒
- 缺点:序列极长 -> 计算开销大、难学到长距离语义
🔢 数值计算示例
字节级 tokenization 示例:“你好” 的 UTF-8 编码:
你 → 0xE4 0xBD 0xA0 (3 bytes)
好 → 0xE5 0xA5 0xBD (3 bytes)-
字节级 tokenizer:[0xE4, 0xBD, 0xA0, 0xE5, 0xA5, 0xBD] → 6 tokens
-
BPE tokenizer(语料足够):[“你好”] → 1 token
-
BPE tokenizer(语料少):[“你”, “好”] → 2 tokens
推理开销对比:6 tokens 的注意力计算代价是 1 token 的 36 倍()。
⚠️ 常见误区
- 误区:字节级 tokenizer 无法理解字符 → 正确:即使用字节级 tokenizer,LLM 仍可通过学习字节序列的组合隐式学习字符和词级模式。字节级的优势是零 OOV + 极小词表,劣势是序列长。
- 误区:字符级 = 字节级 → 正确:字符级词表大小 = Unicode 字符数(~140,000 个),字节级词表仅 256 个。对于多语言文本,字节级更简洁;字符级词表很大但每 token 仍有语义。
5. 子词 Tokenization(Subword)— 主流方法
- 核心思想:常见词保持完整,罕见词拆为子词
BPE(Byte-Pair Encoding)


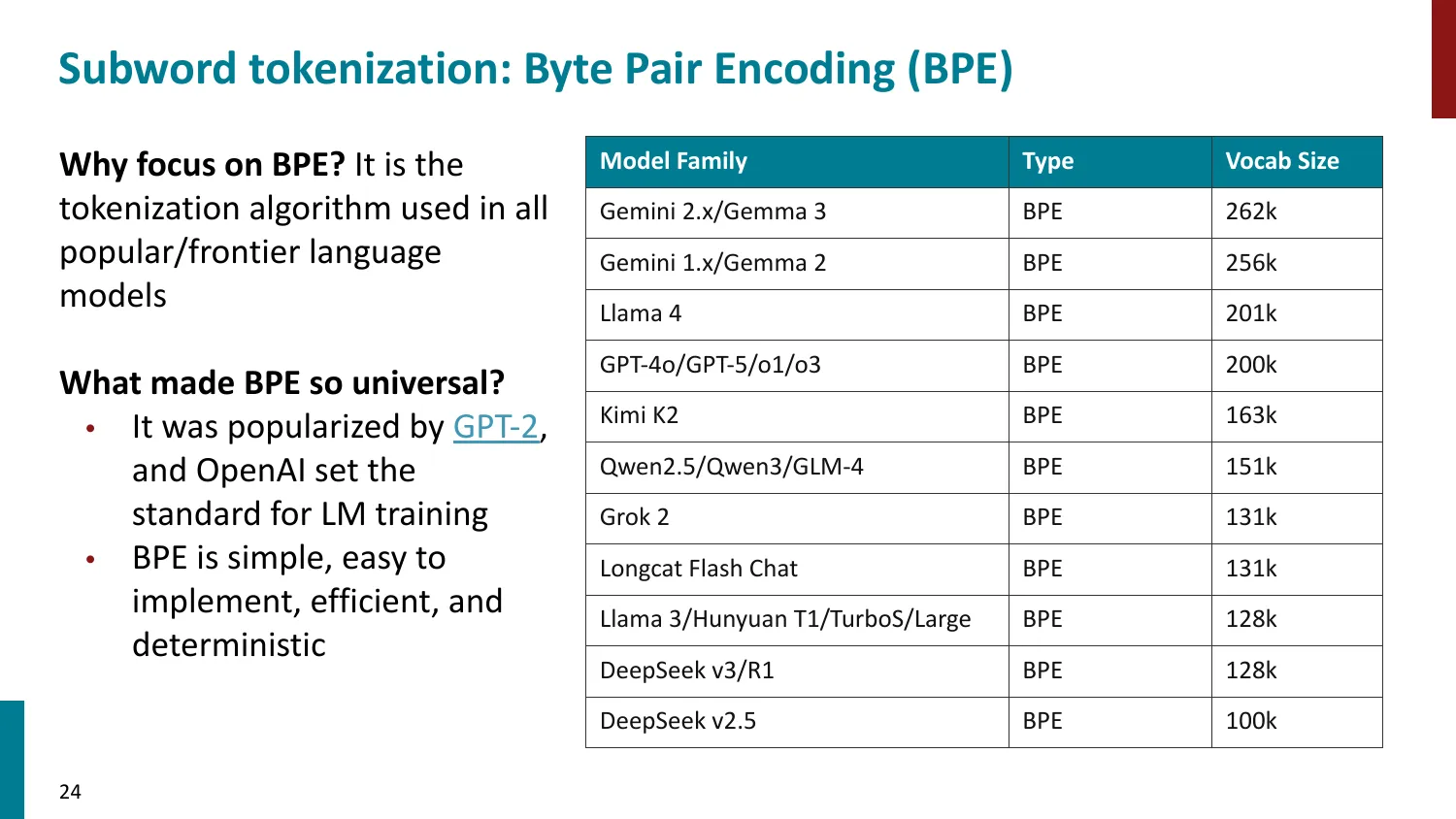

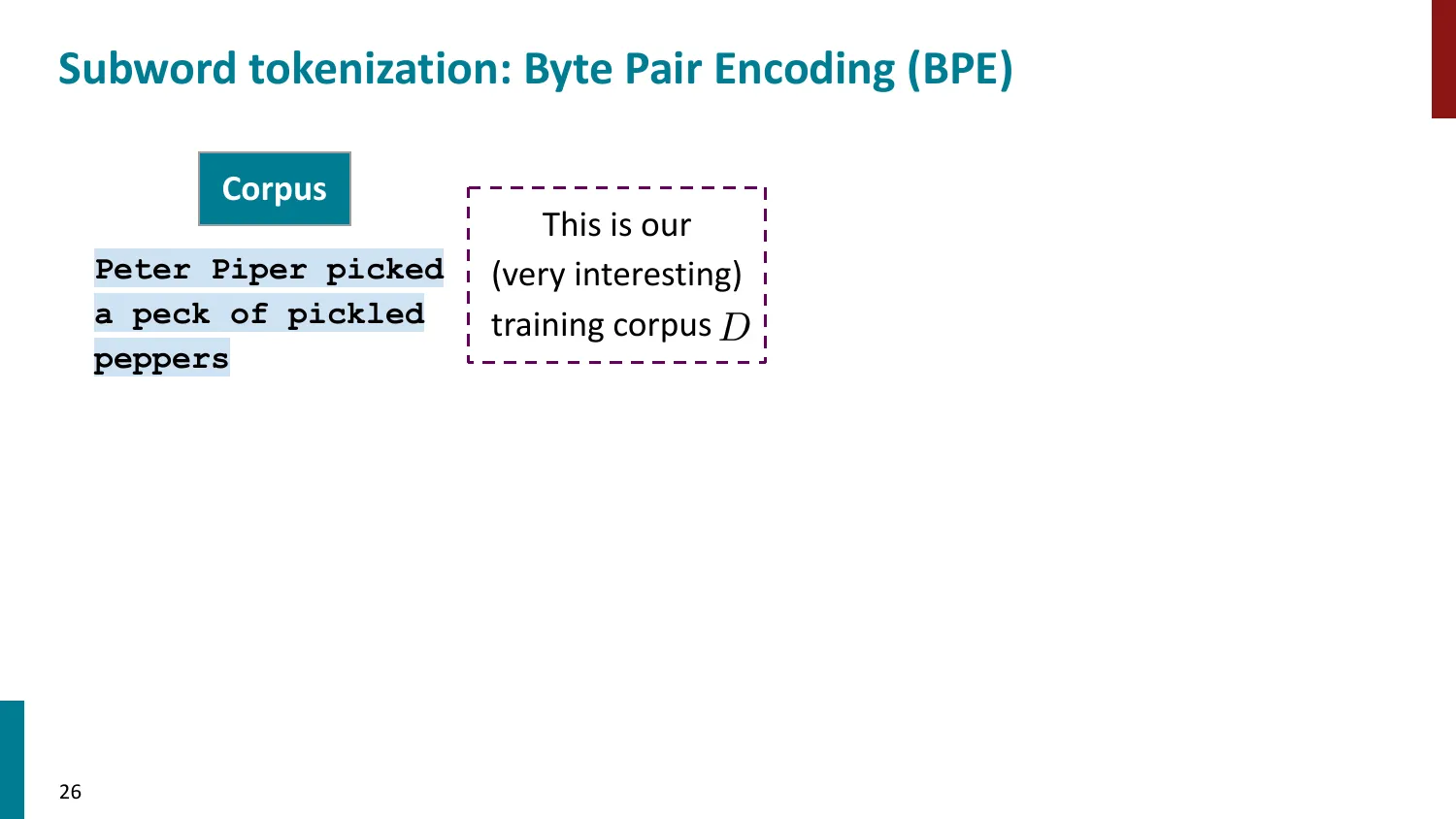
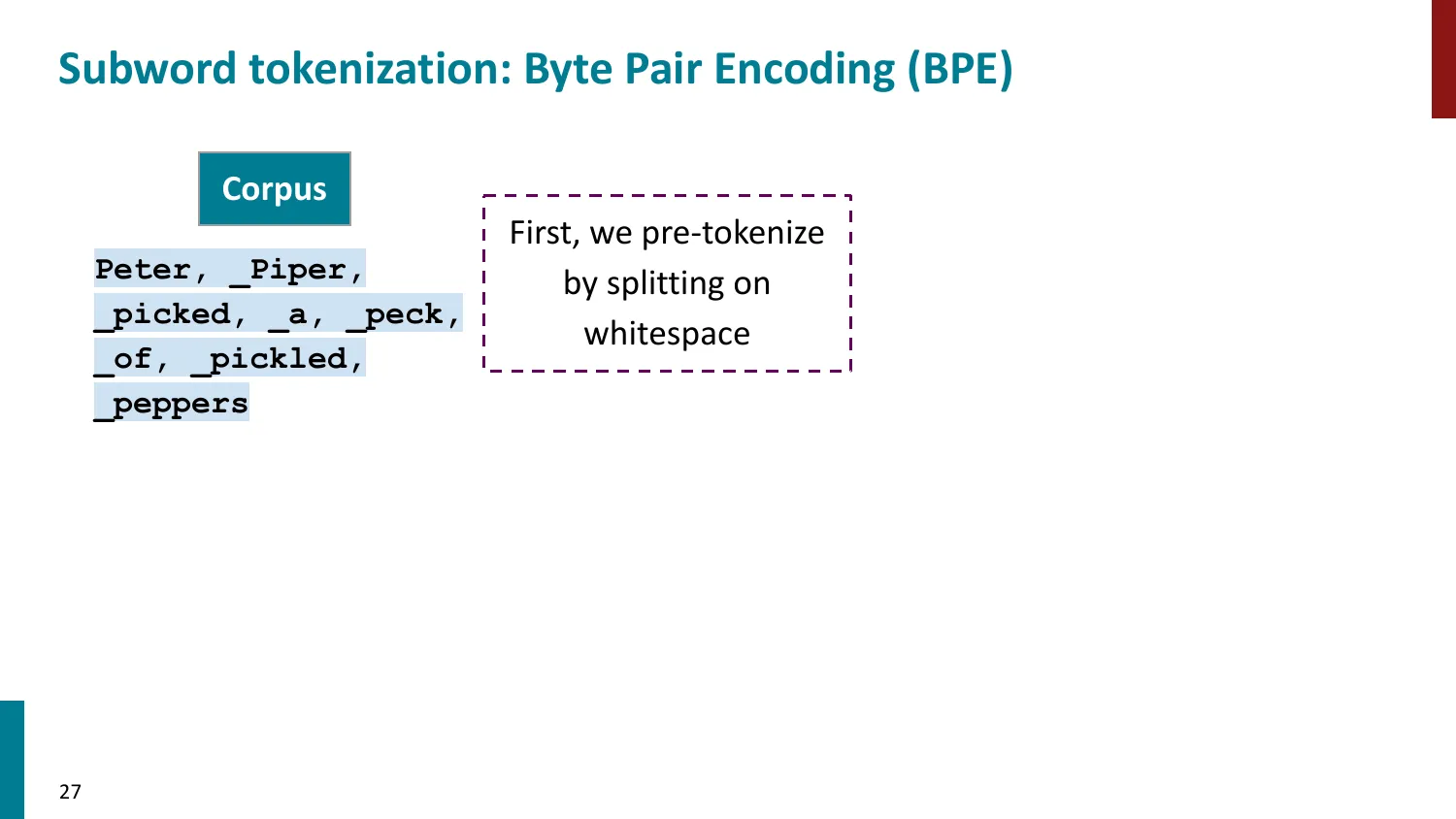
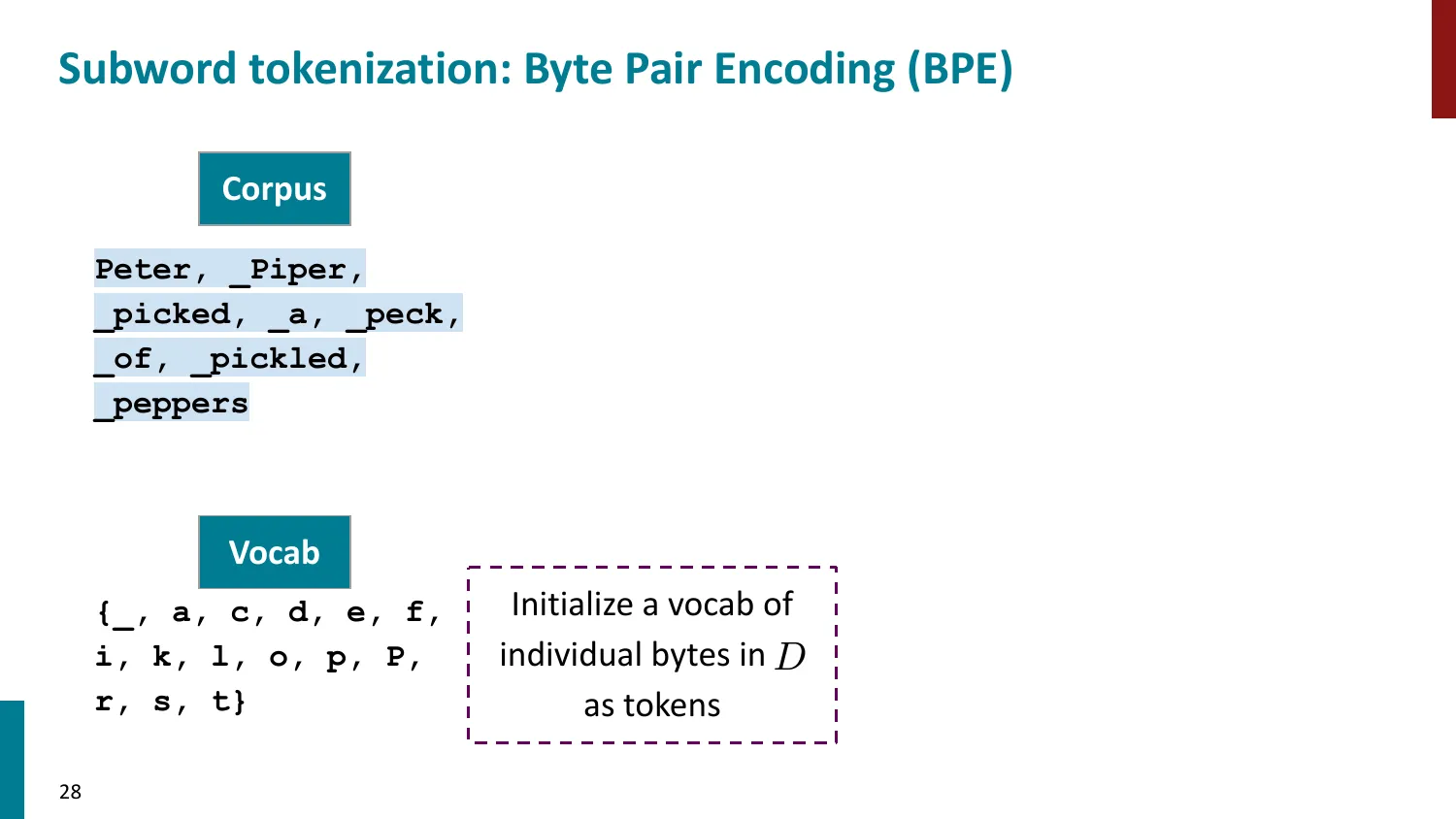
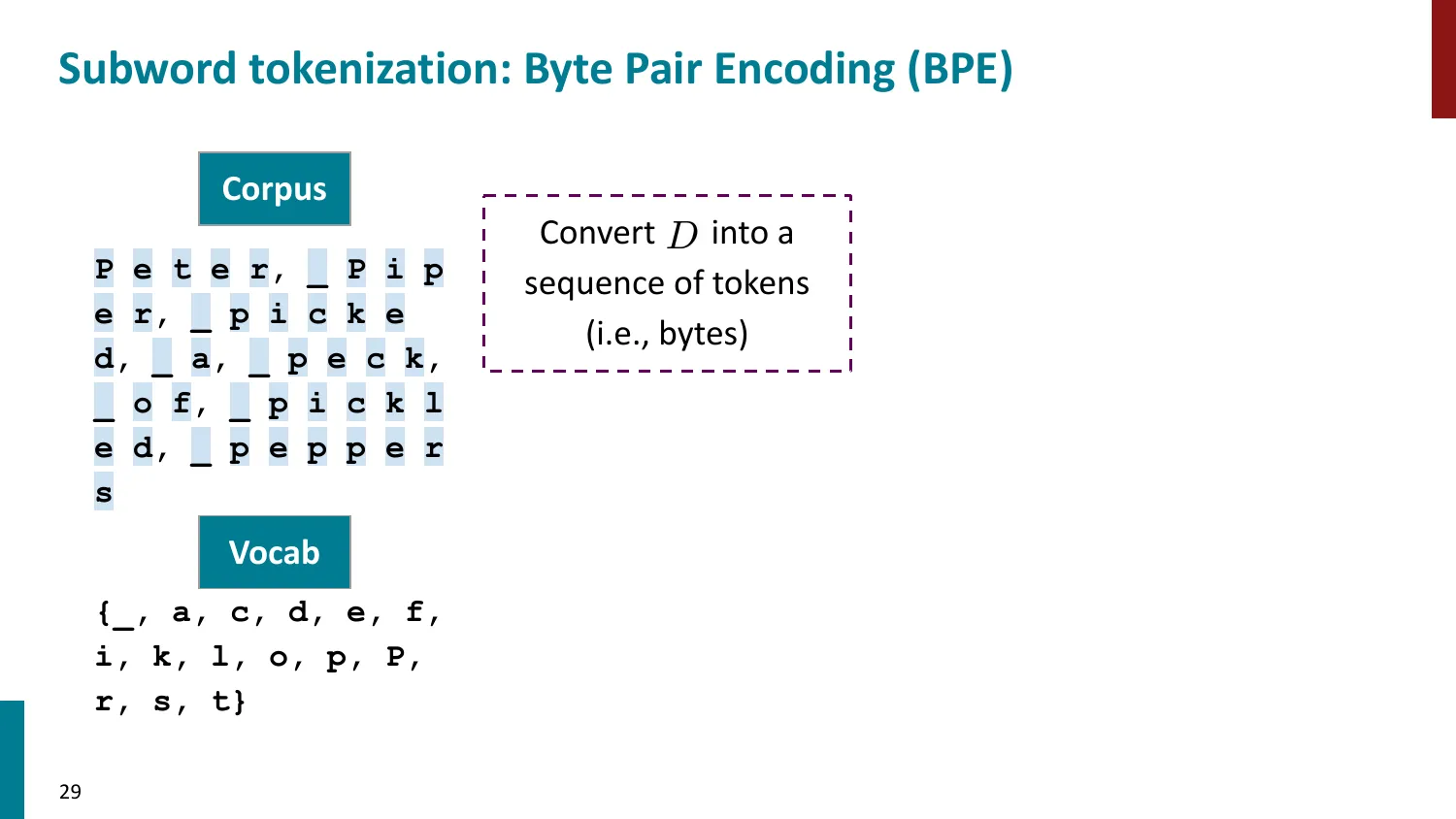
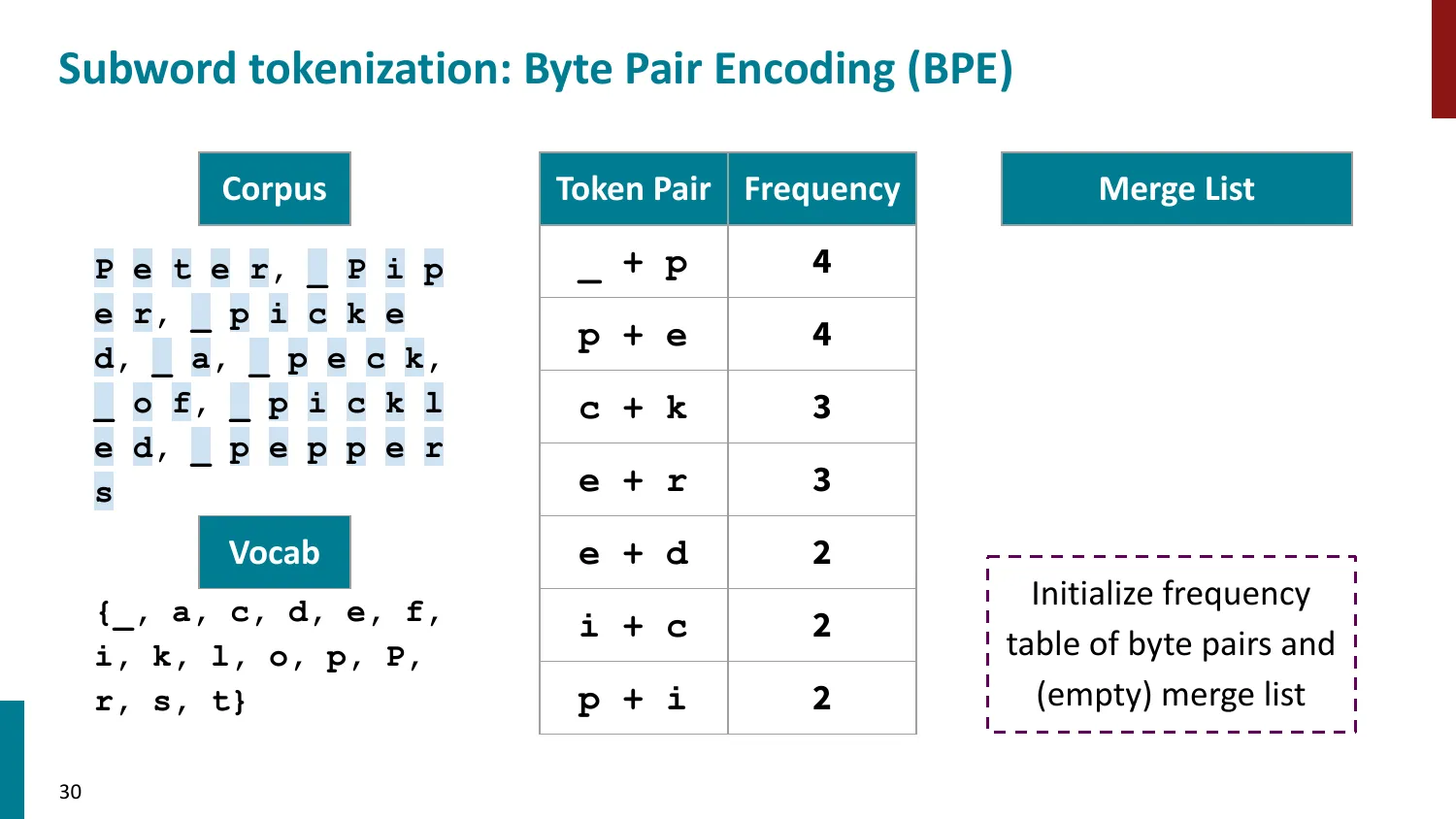
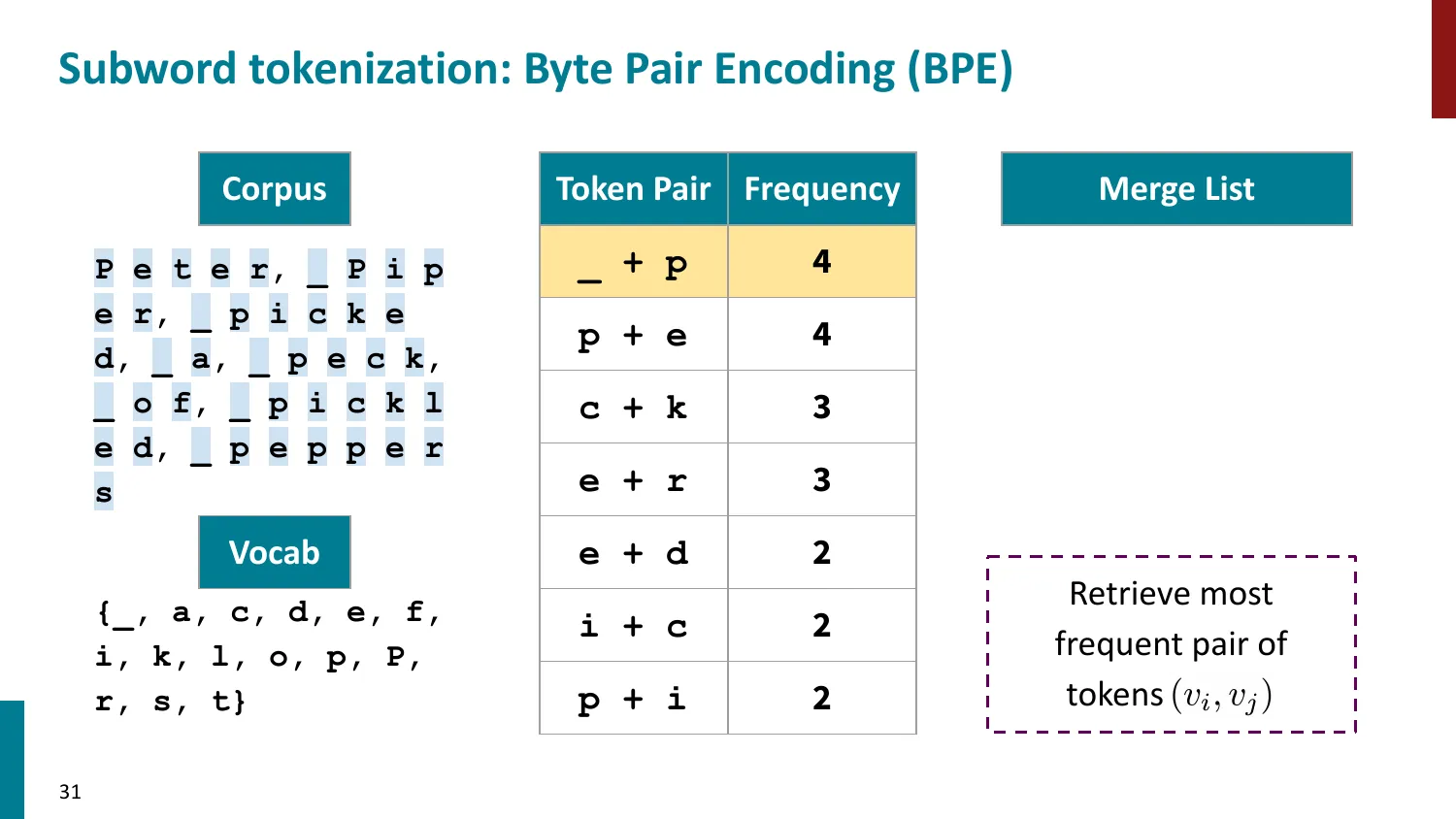
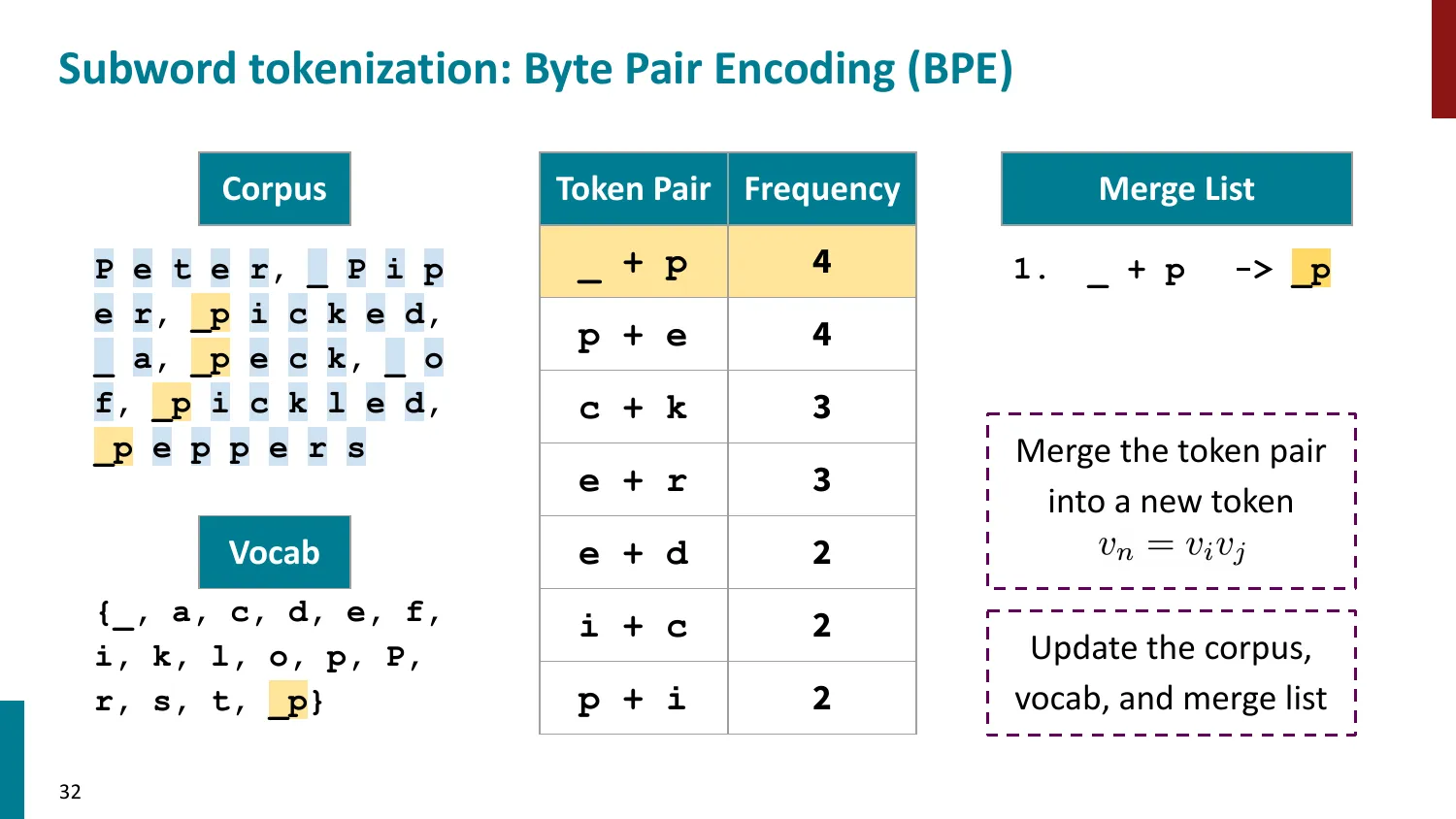
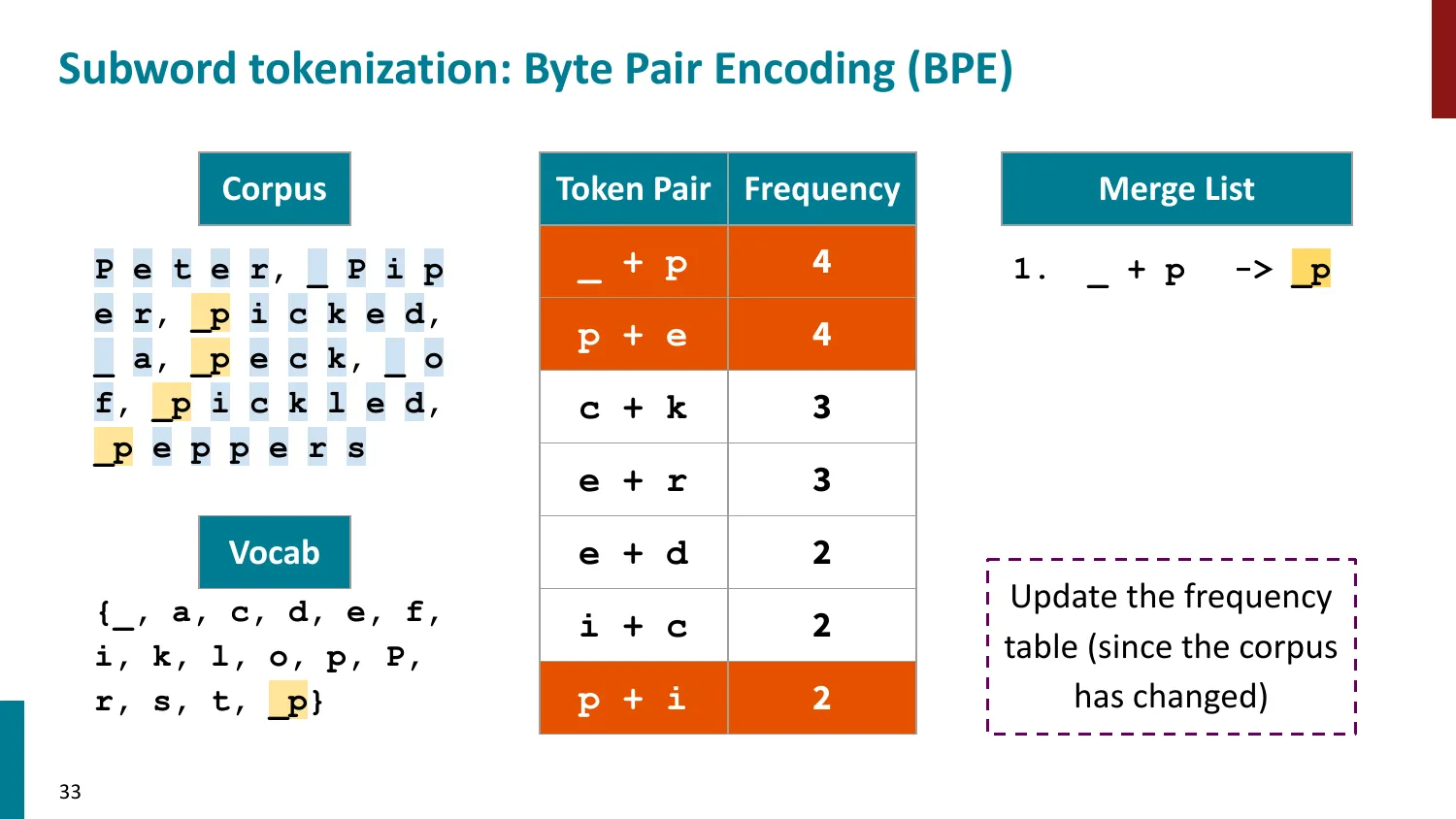
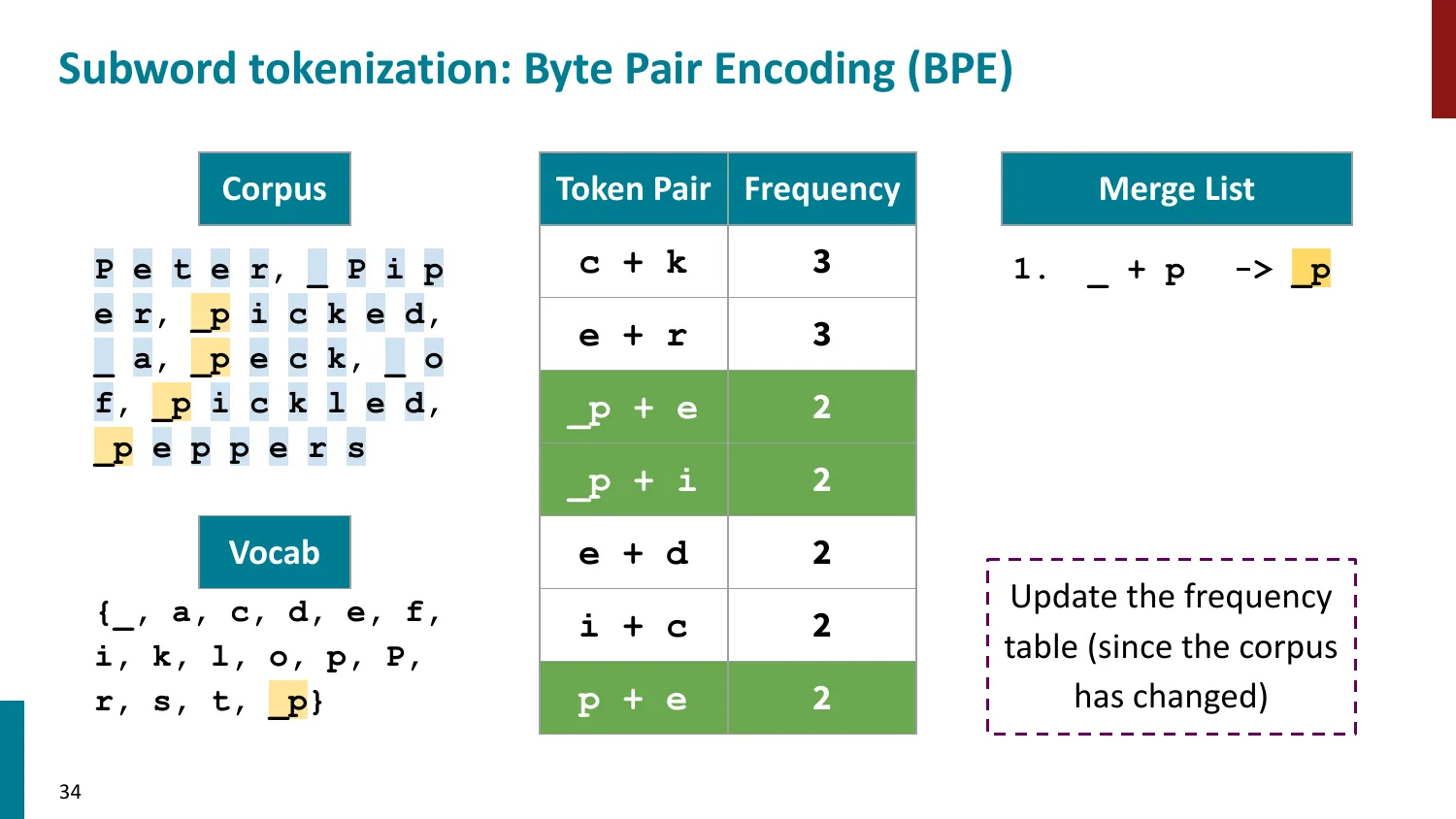
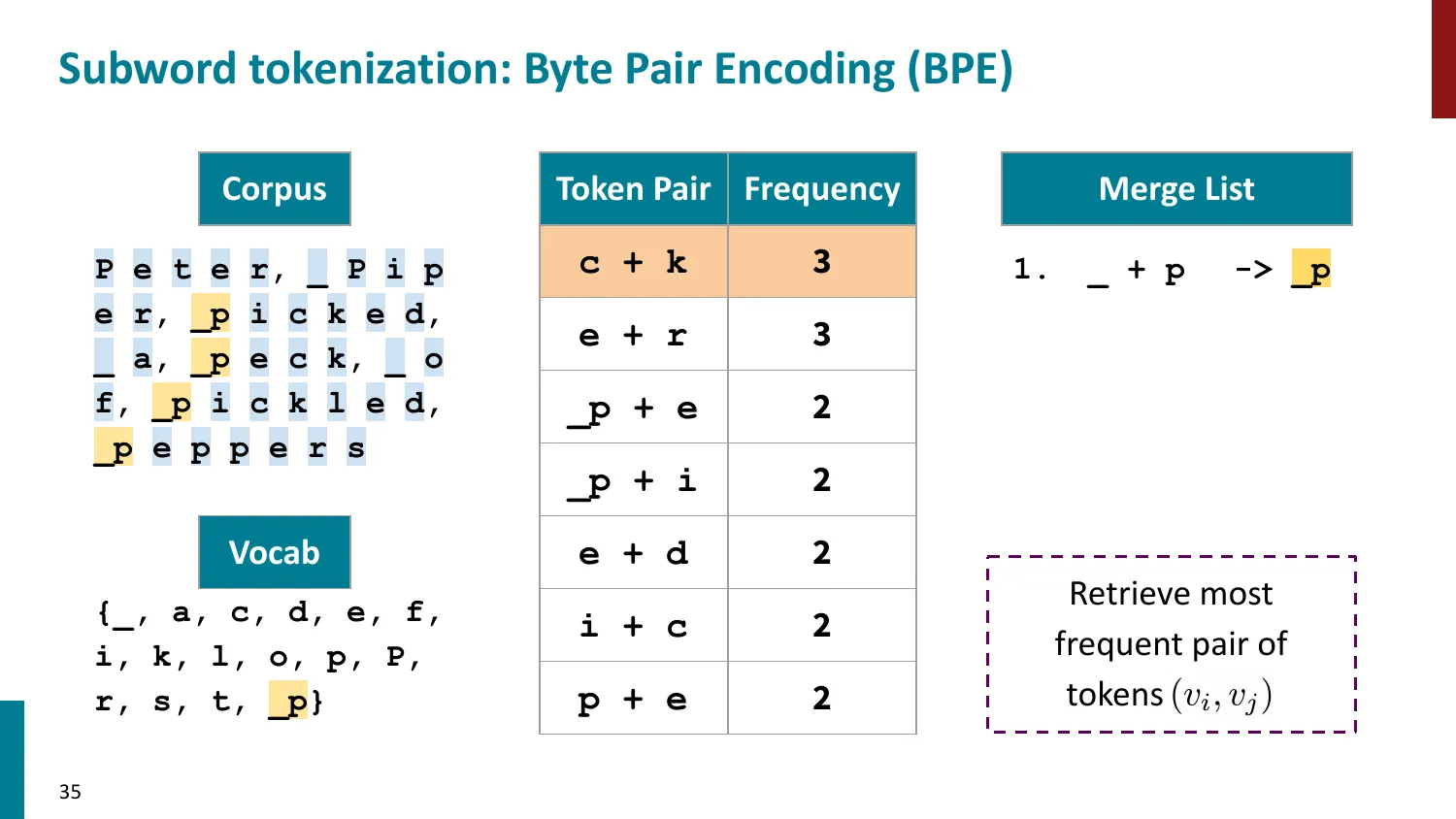
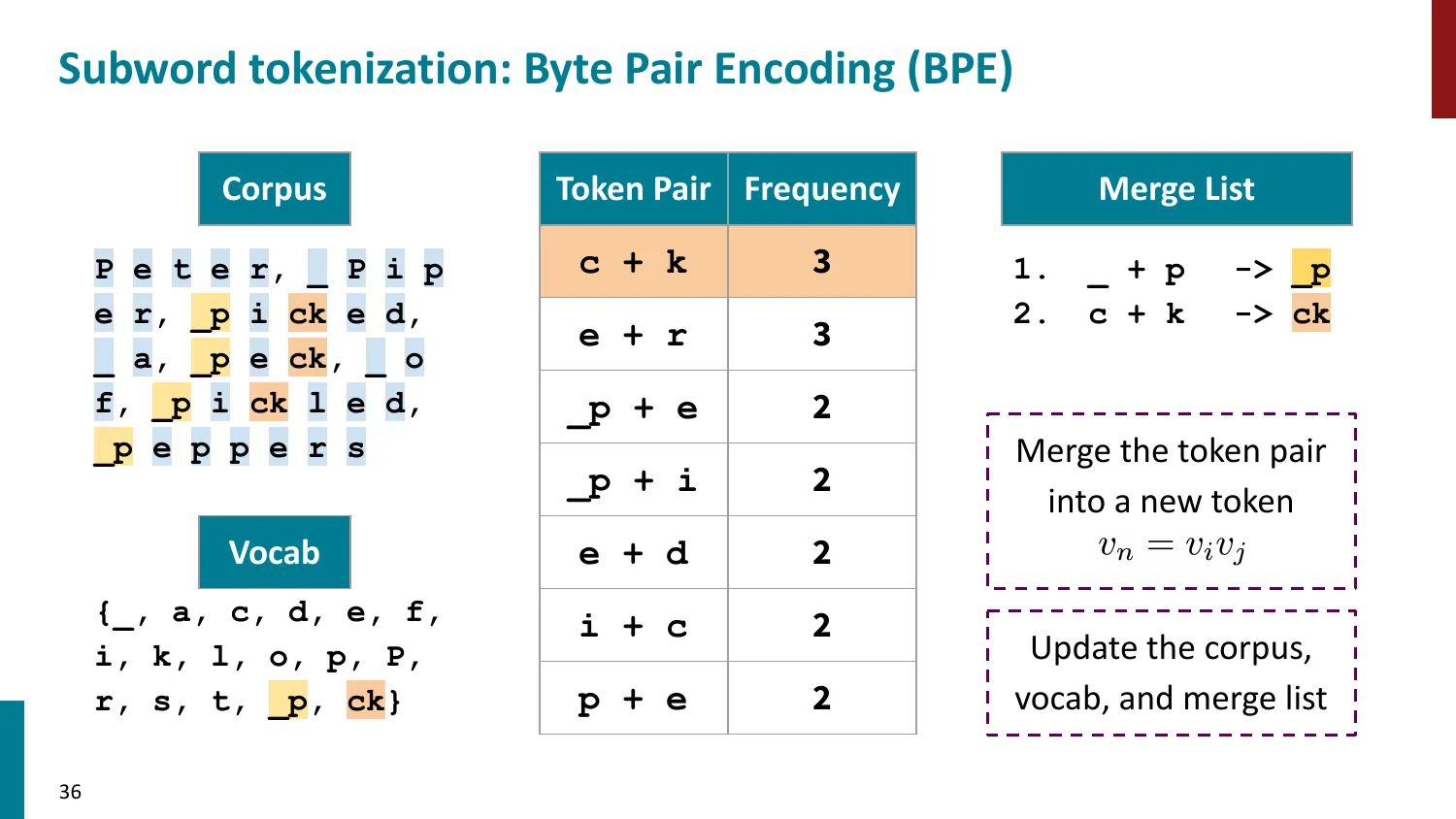
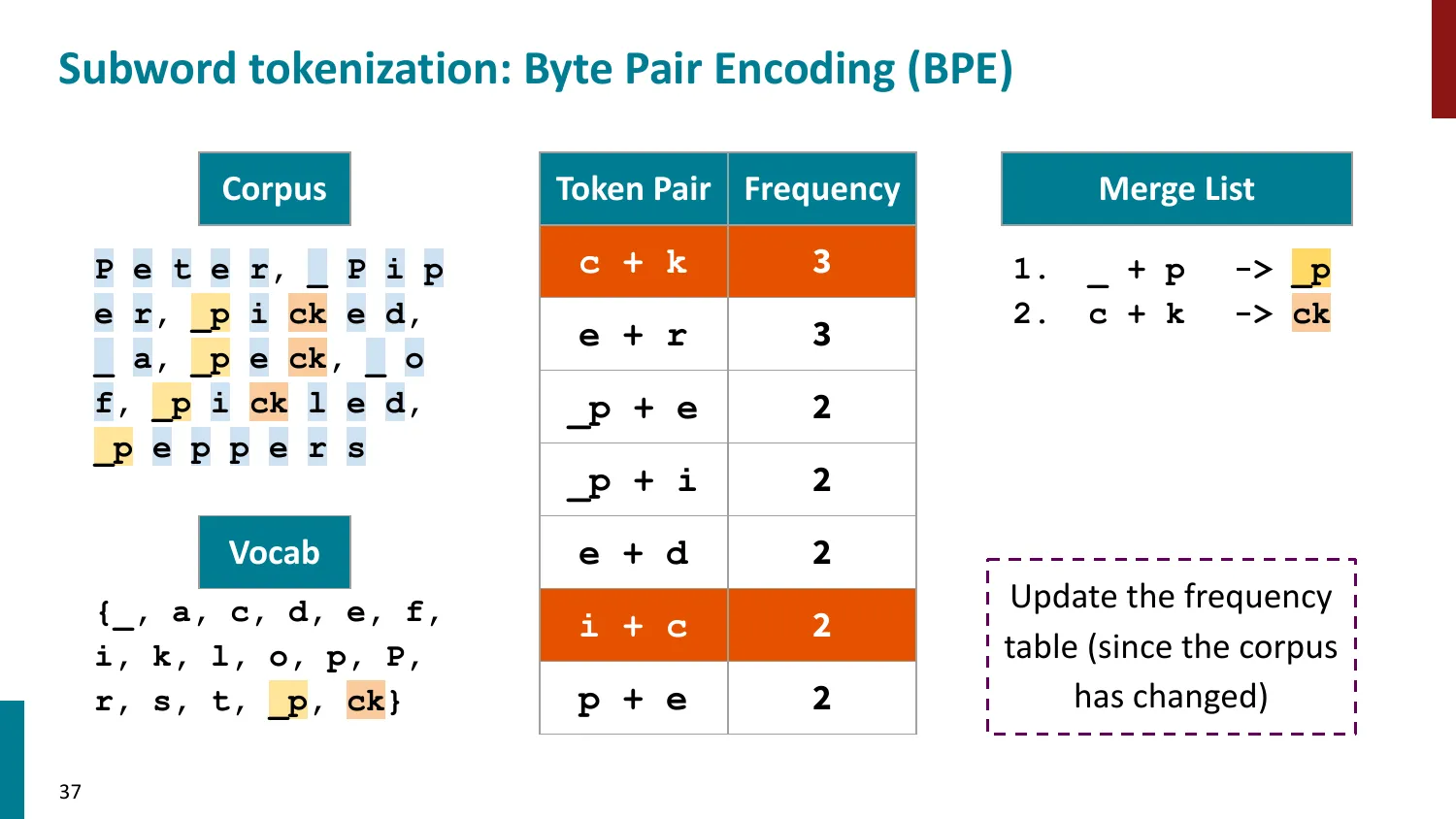
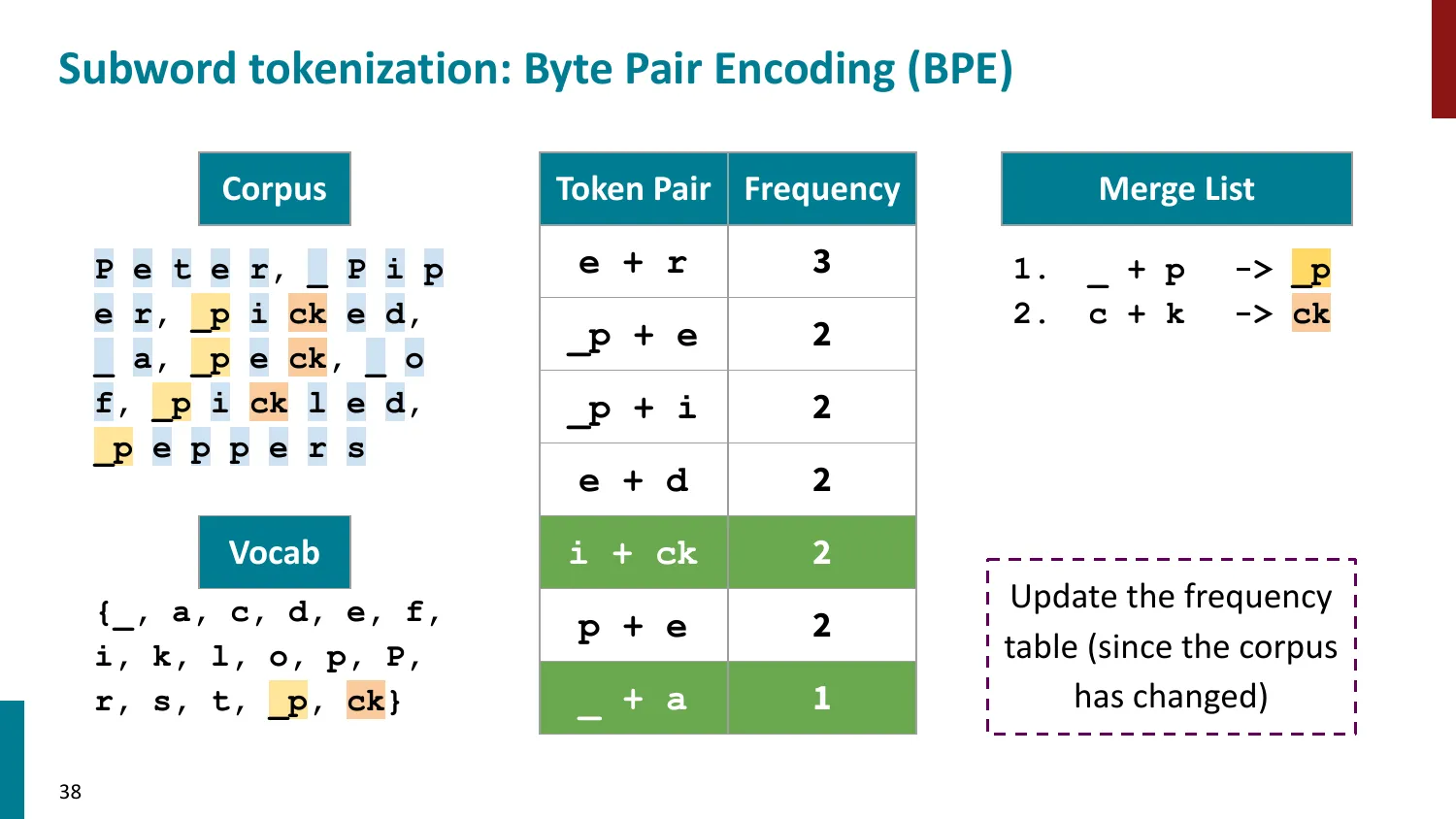
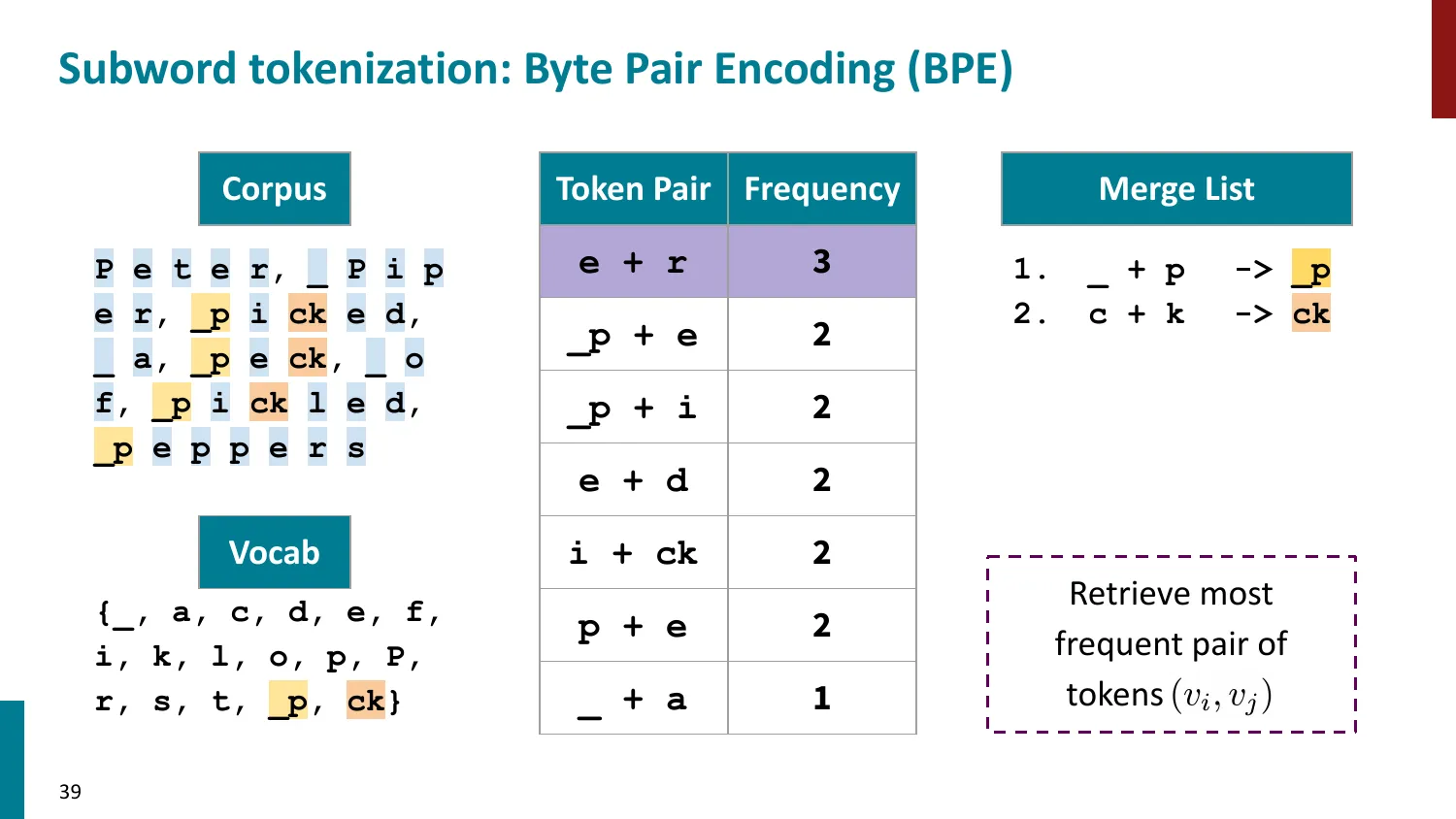
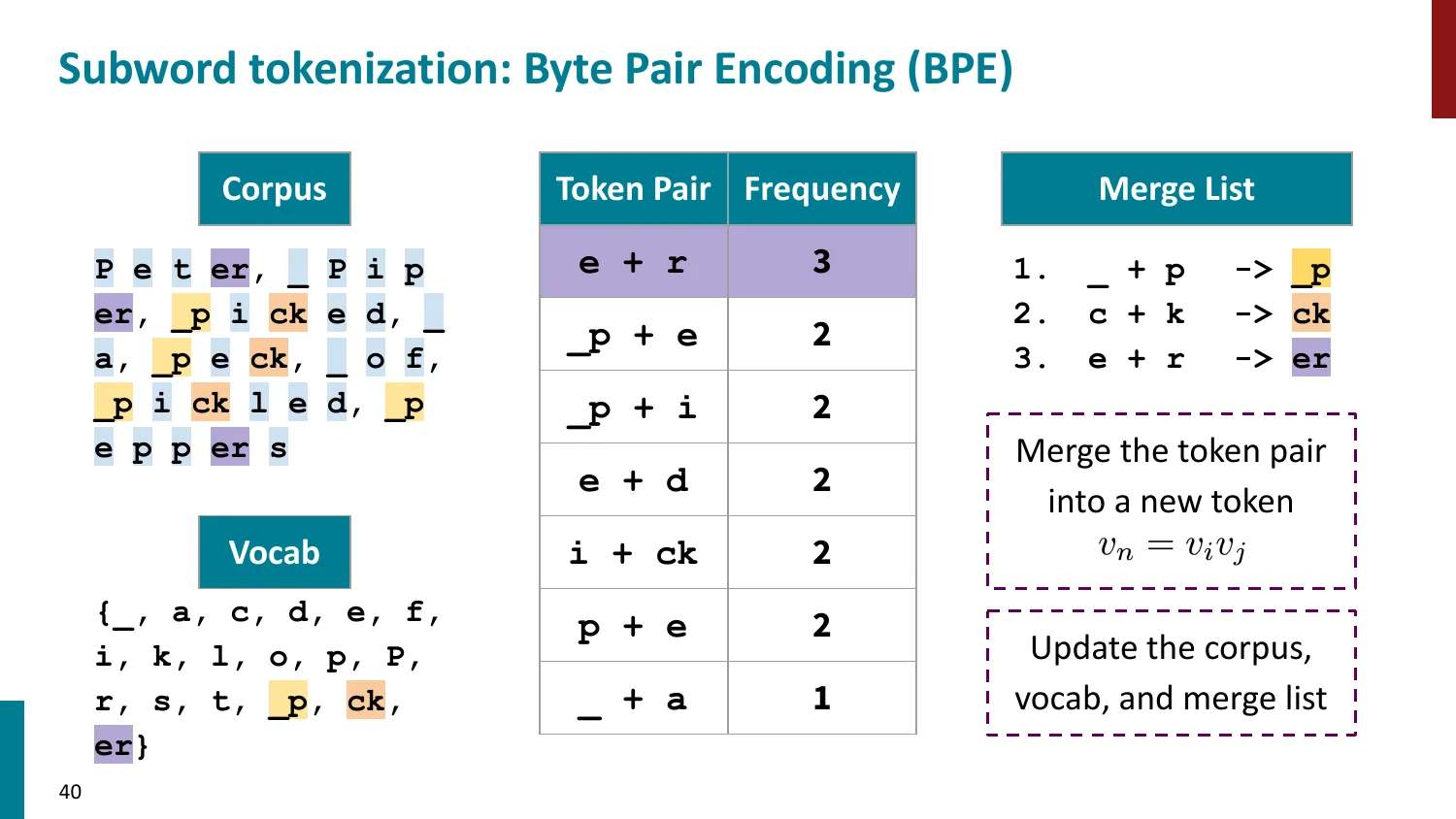
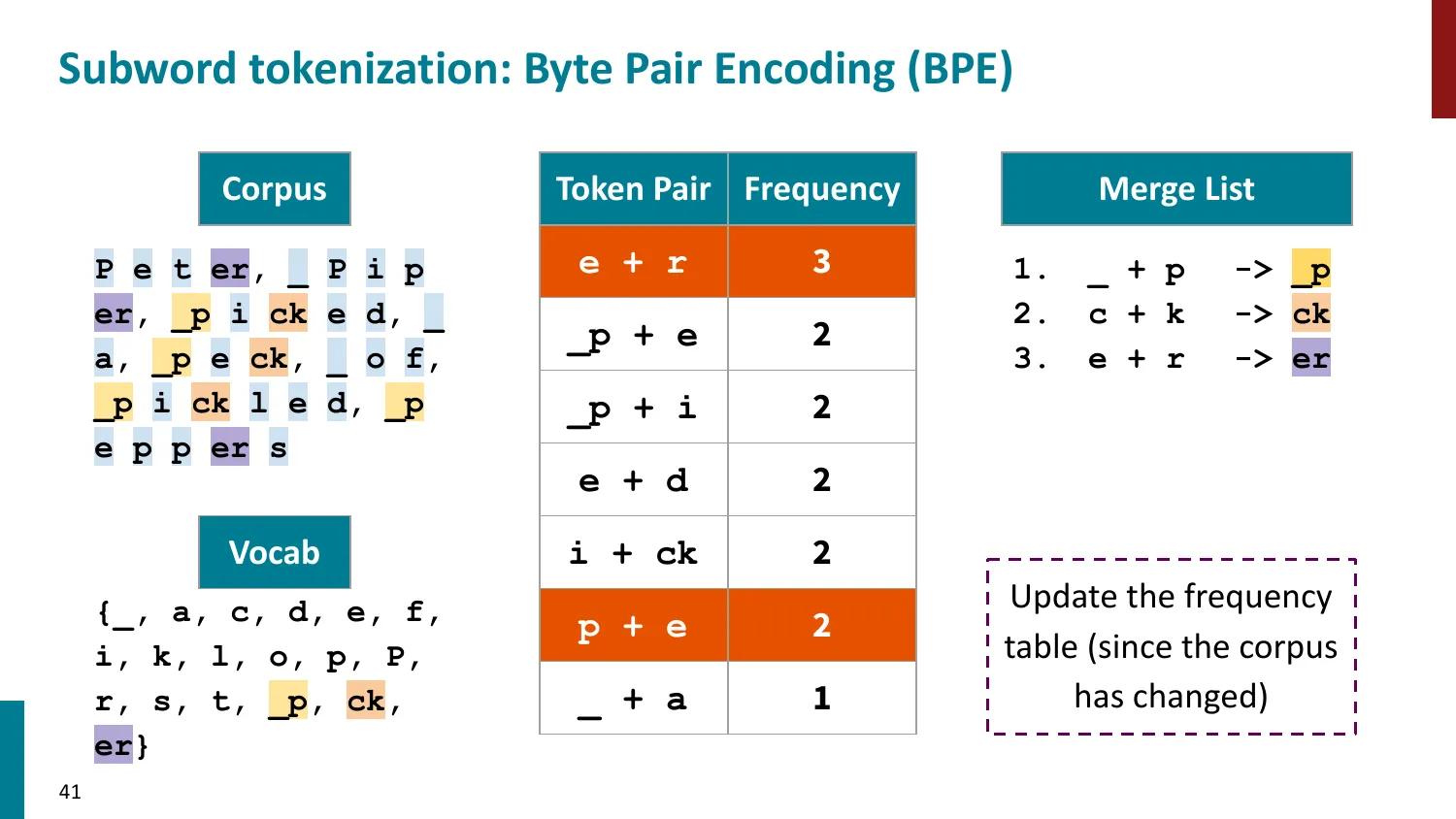
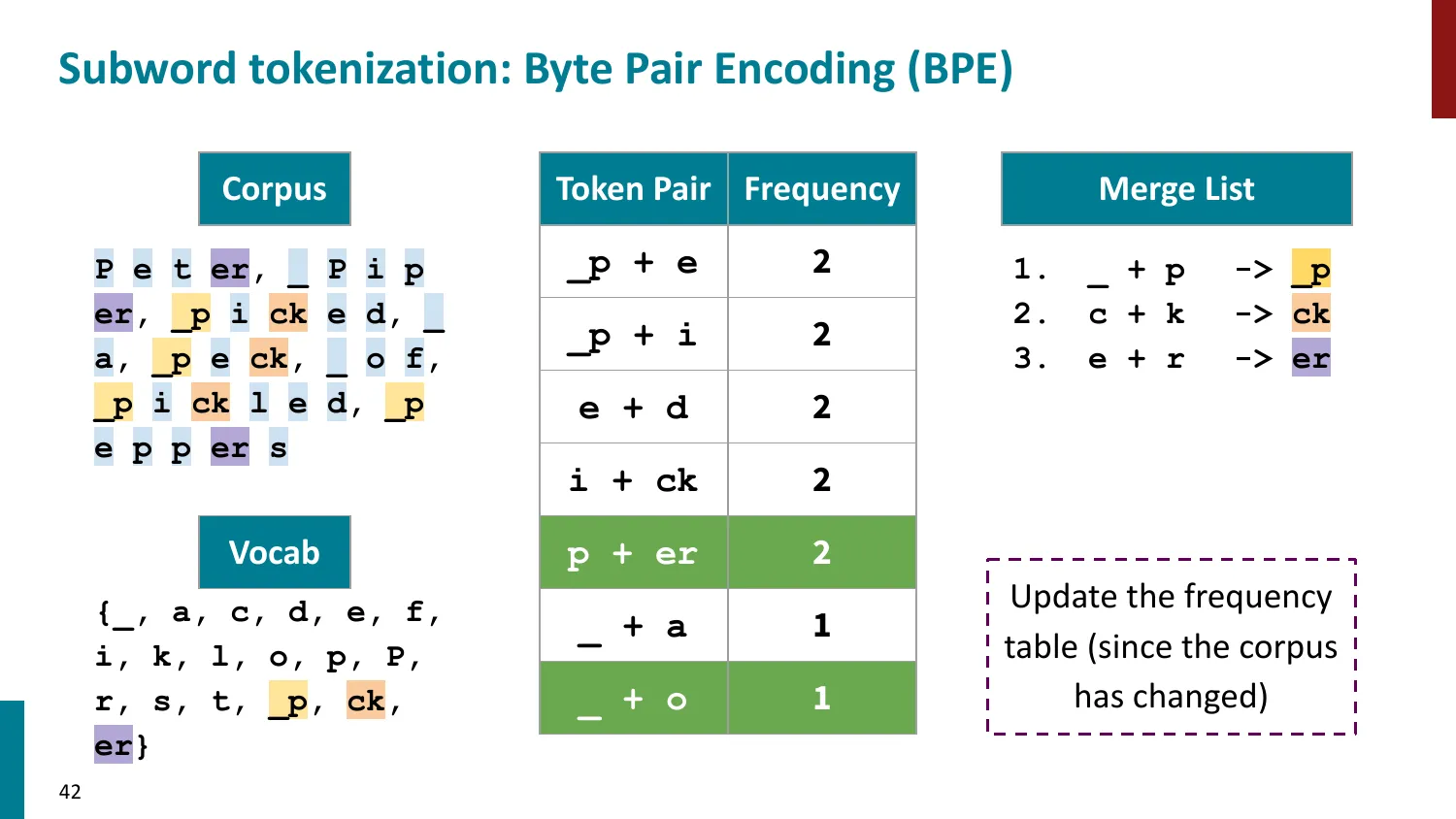
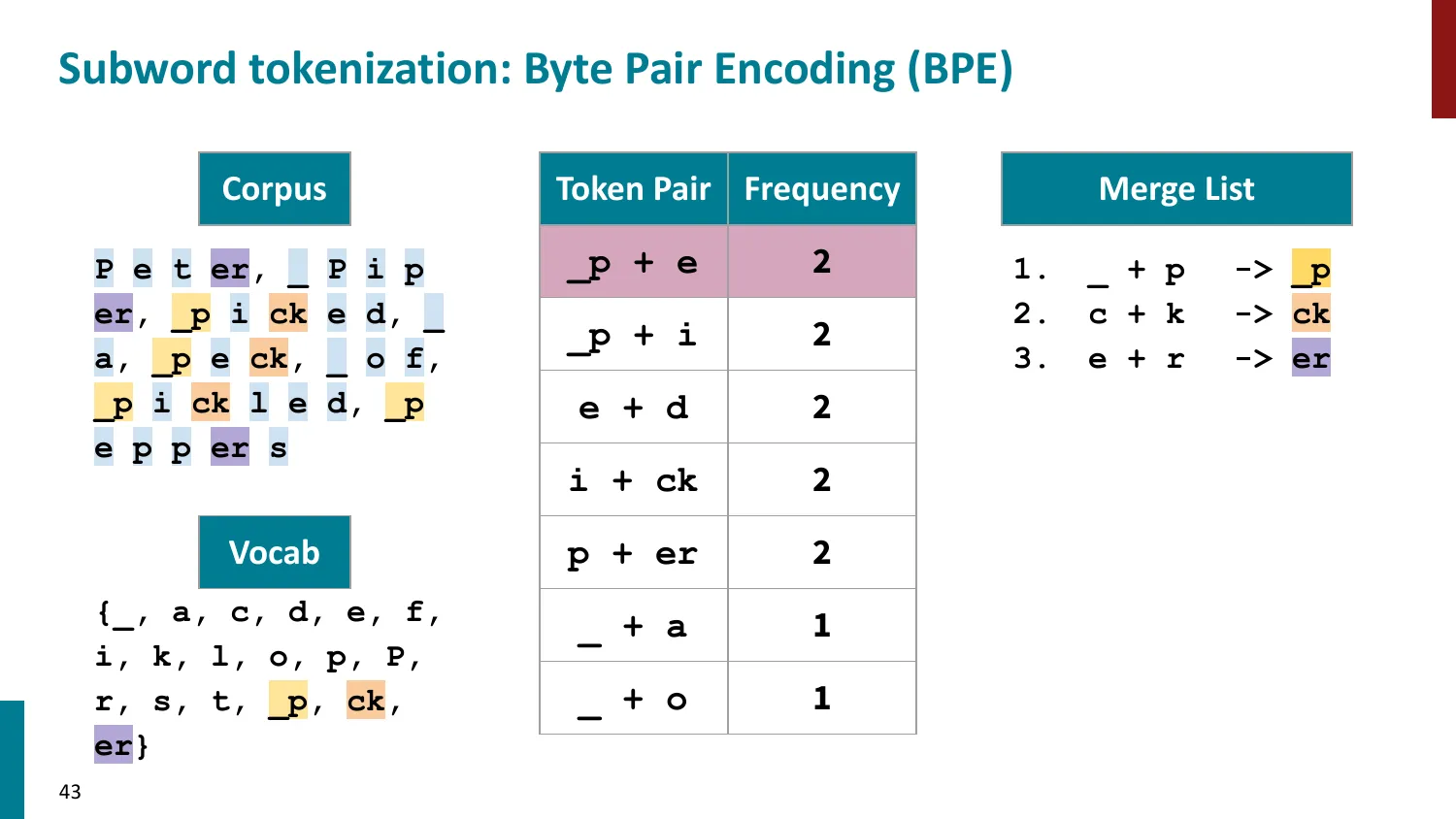
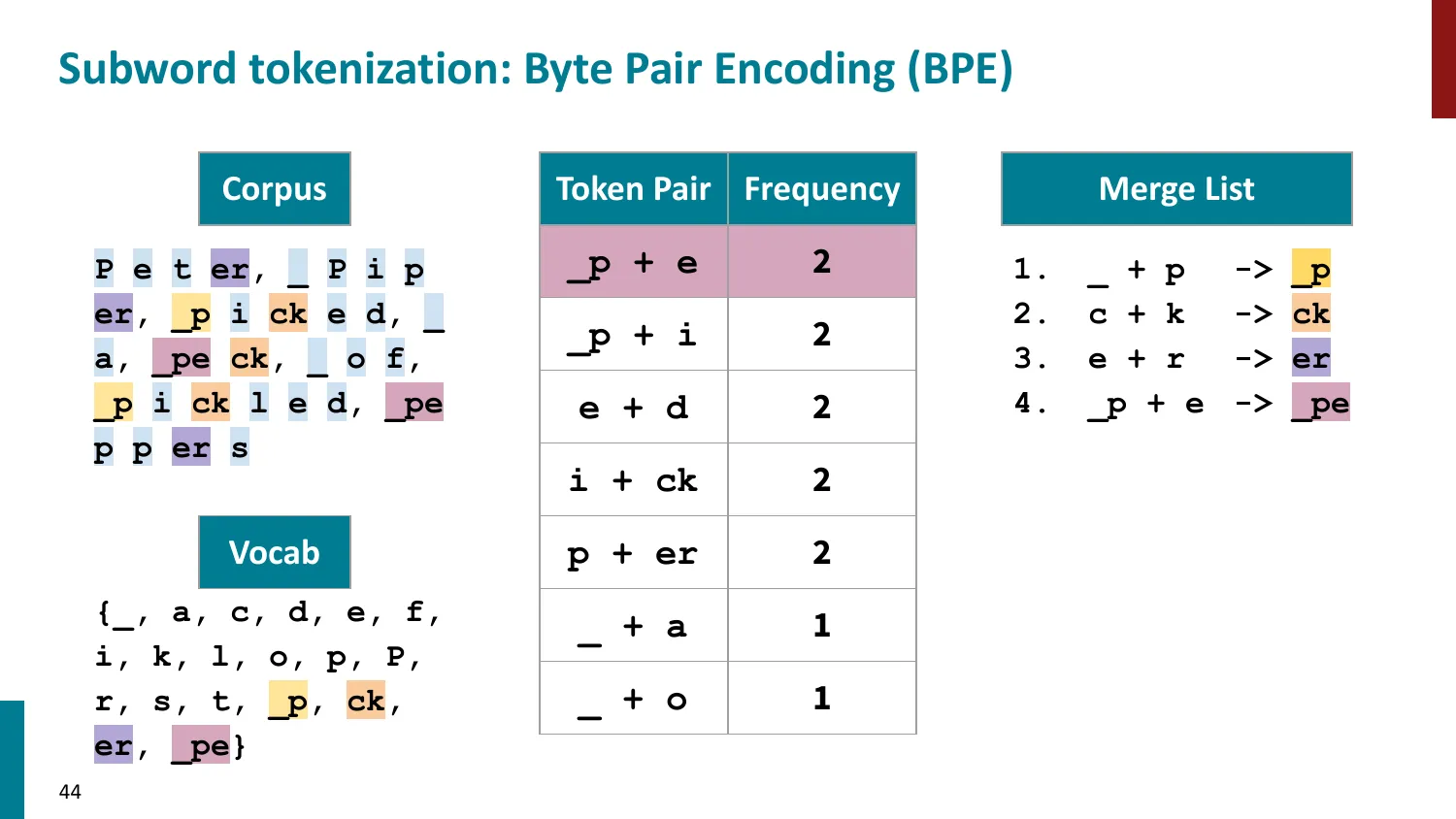
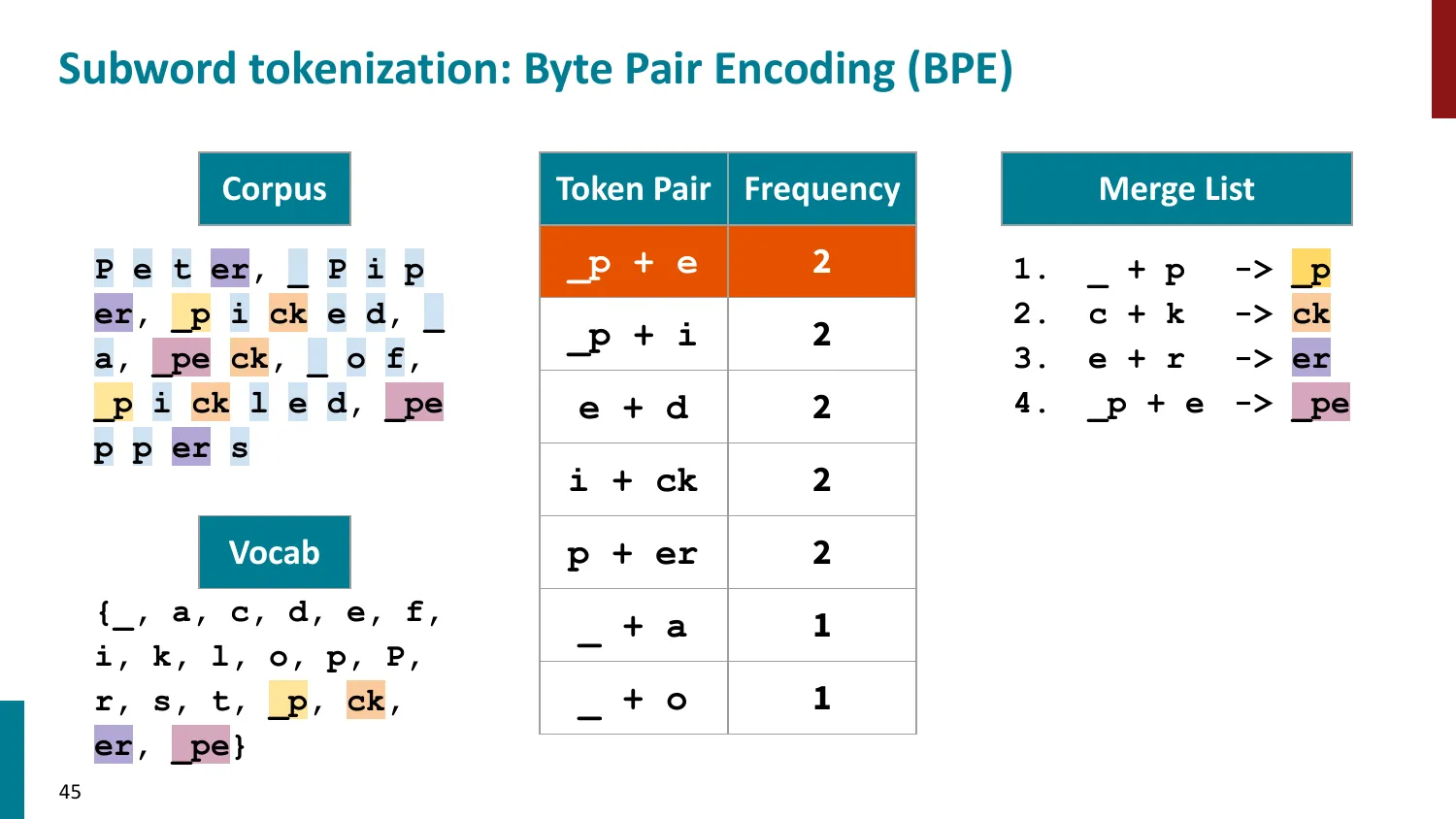
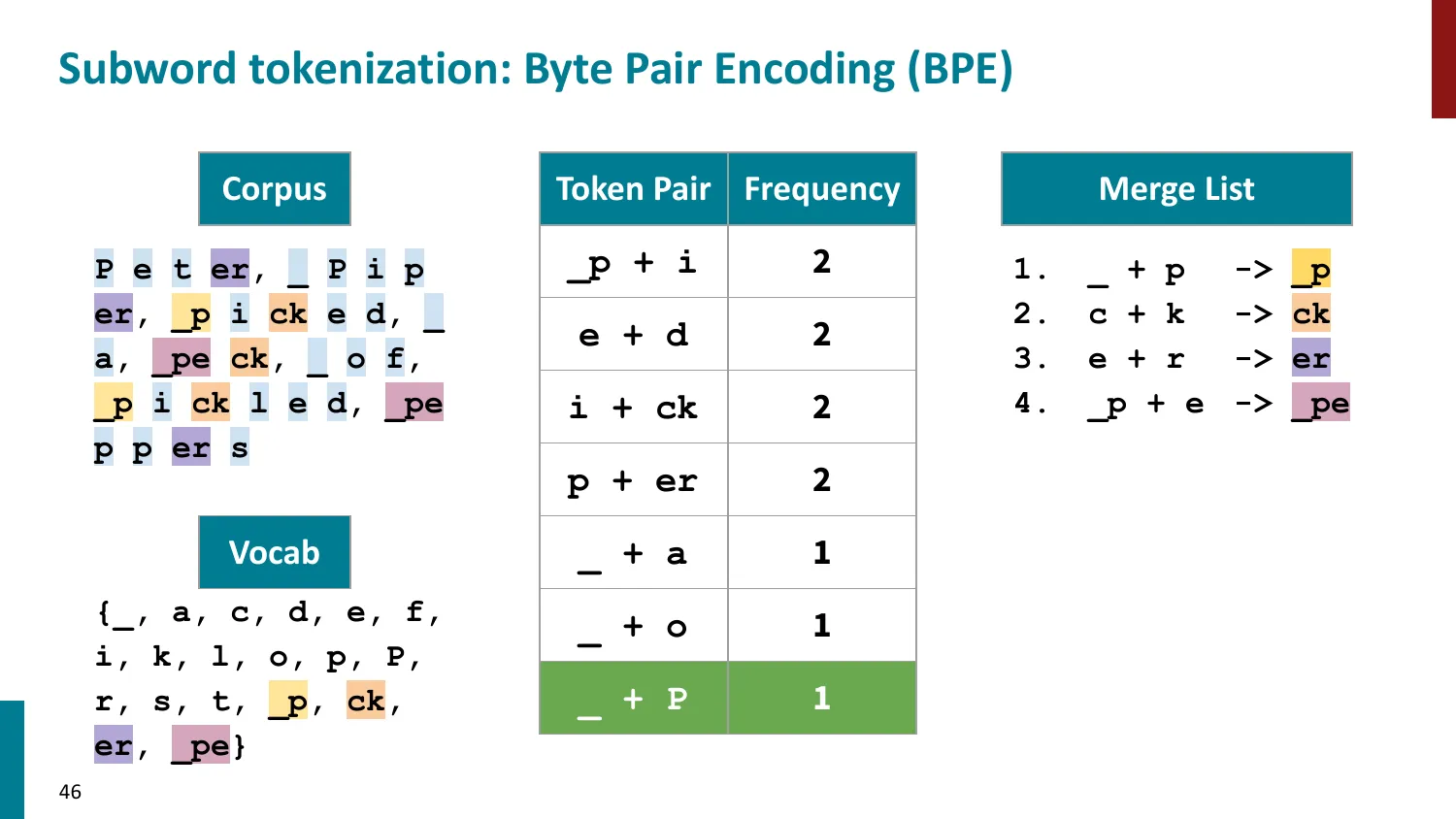
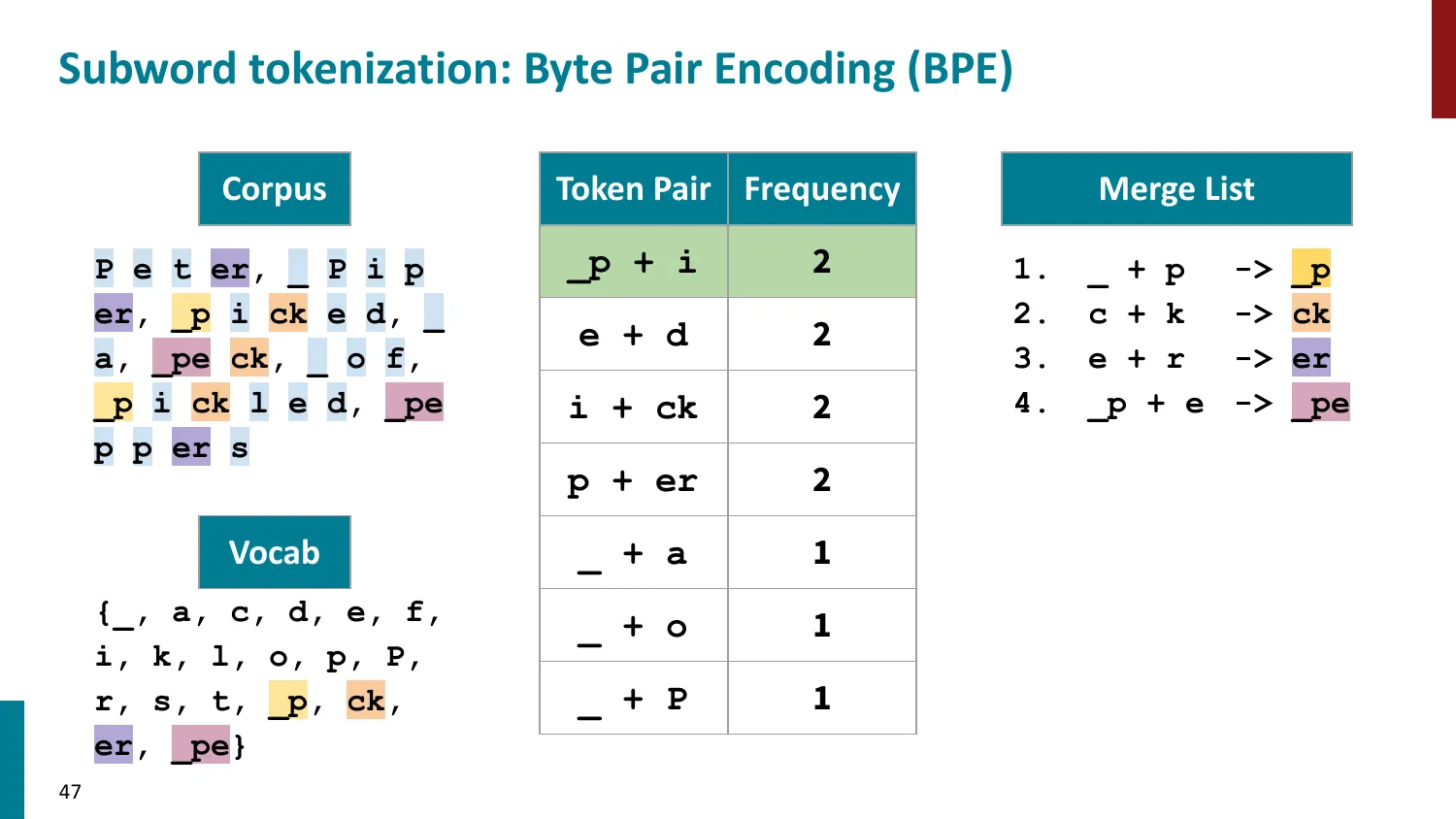
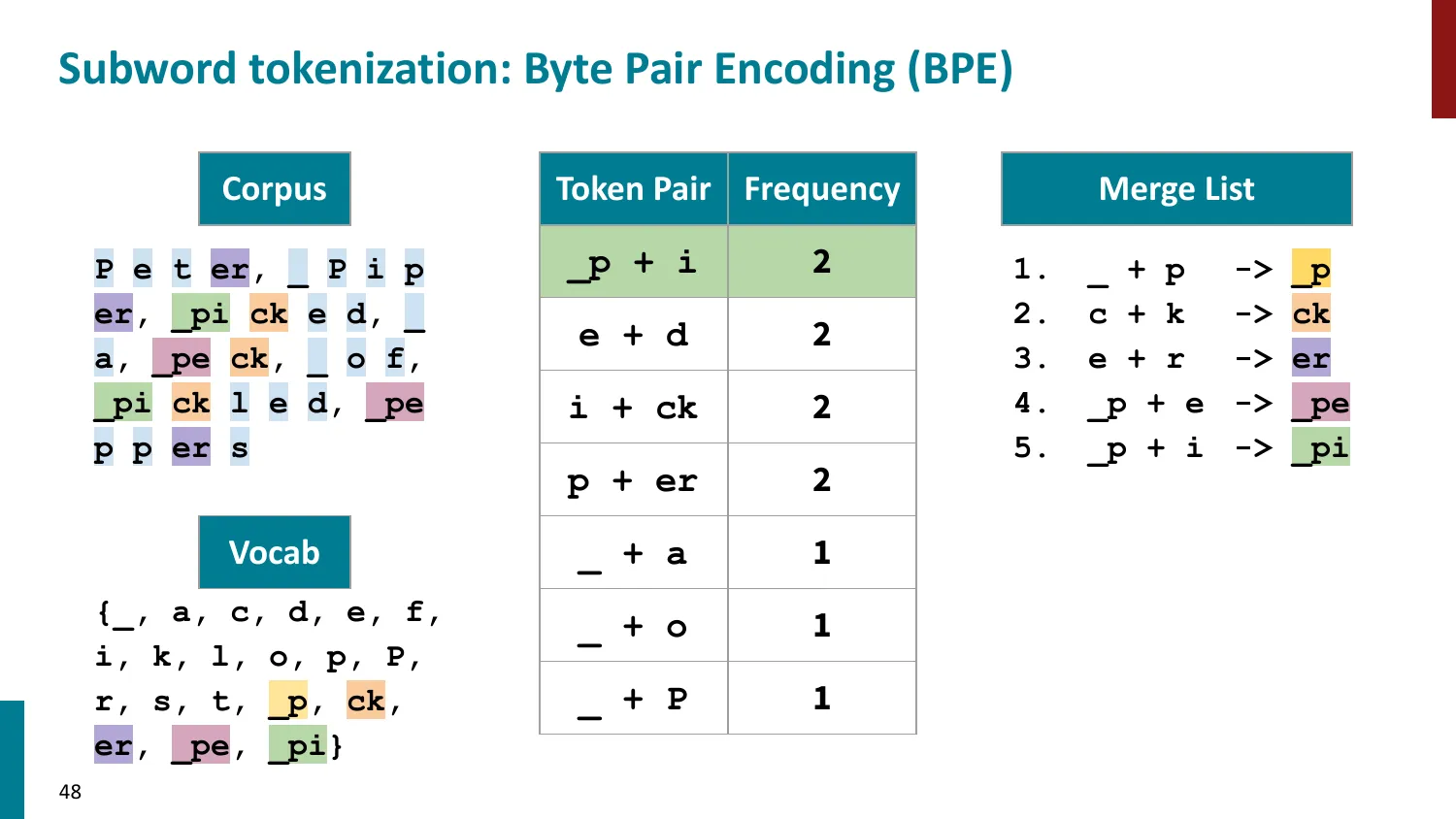
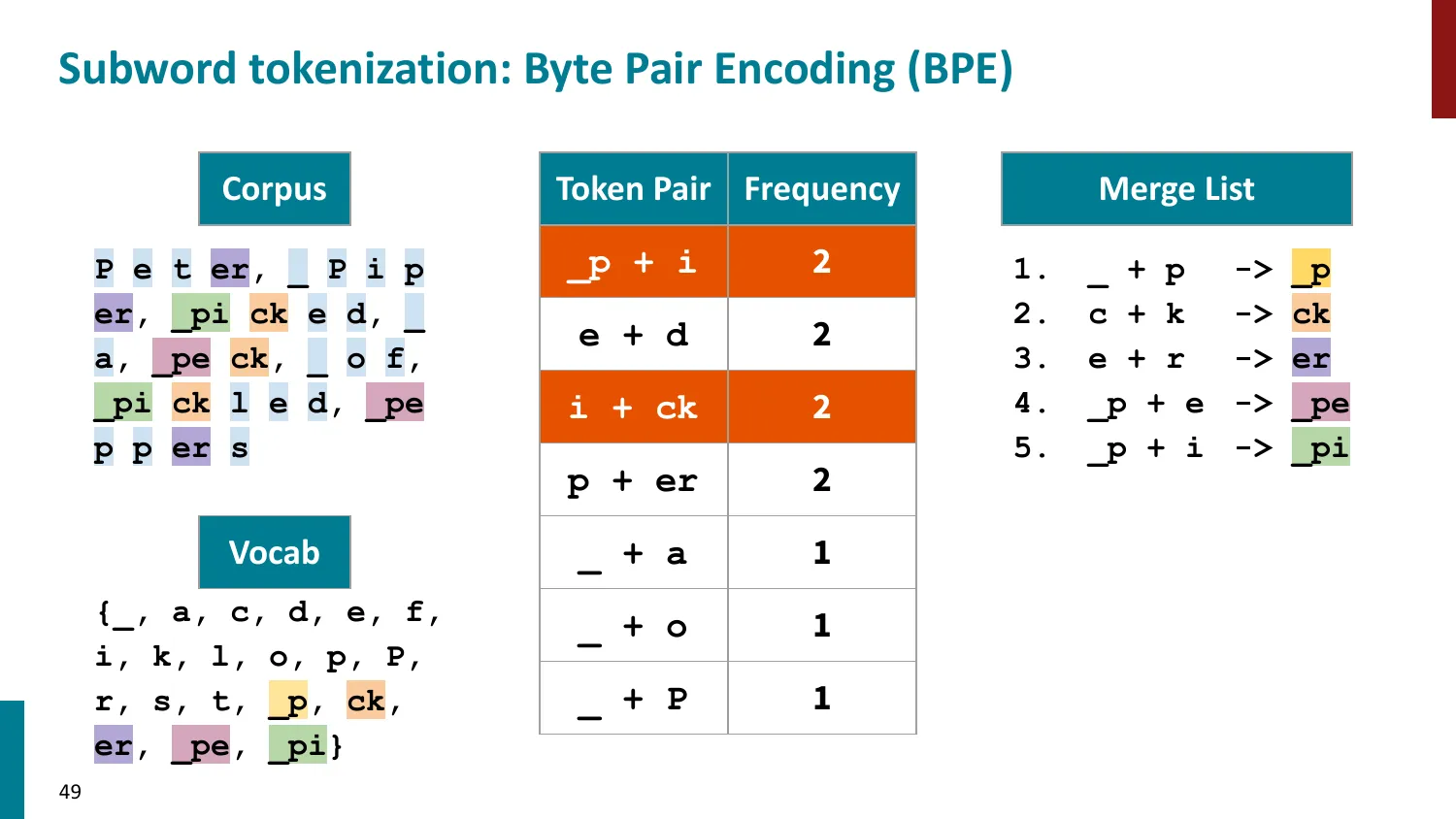
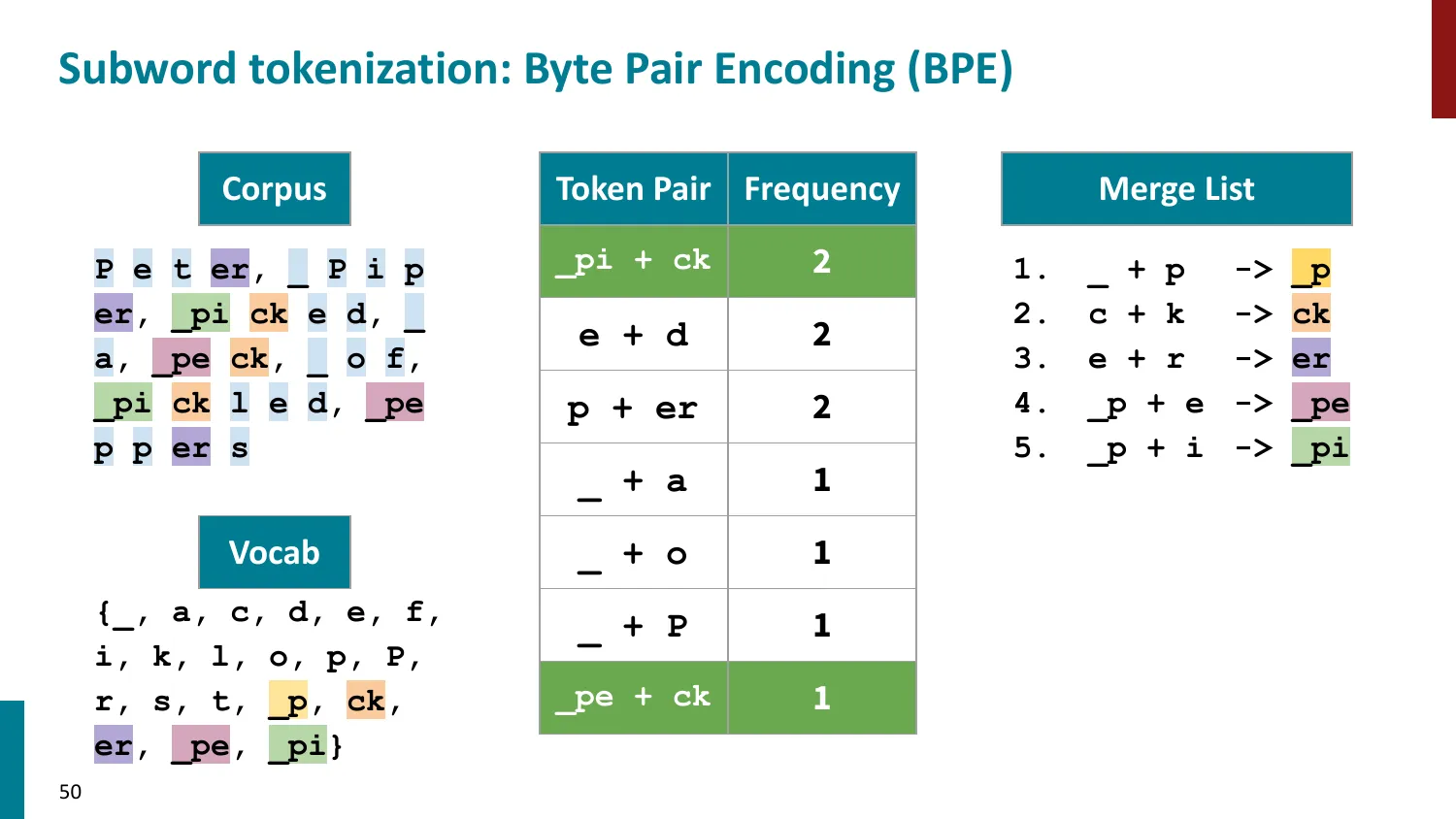
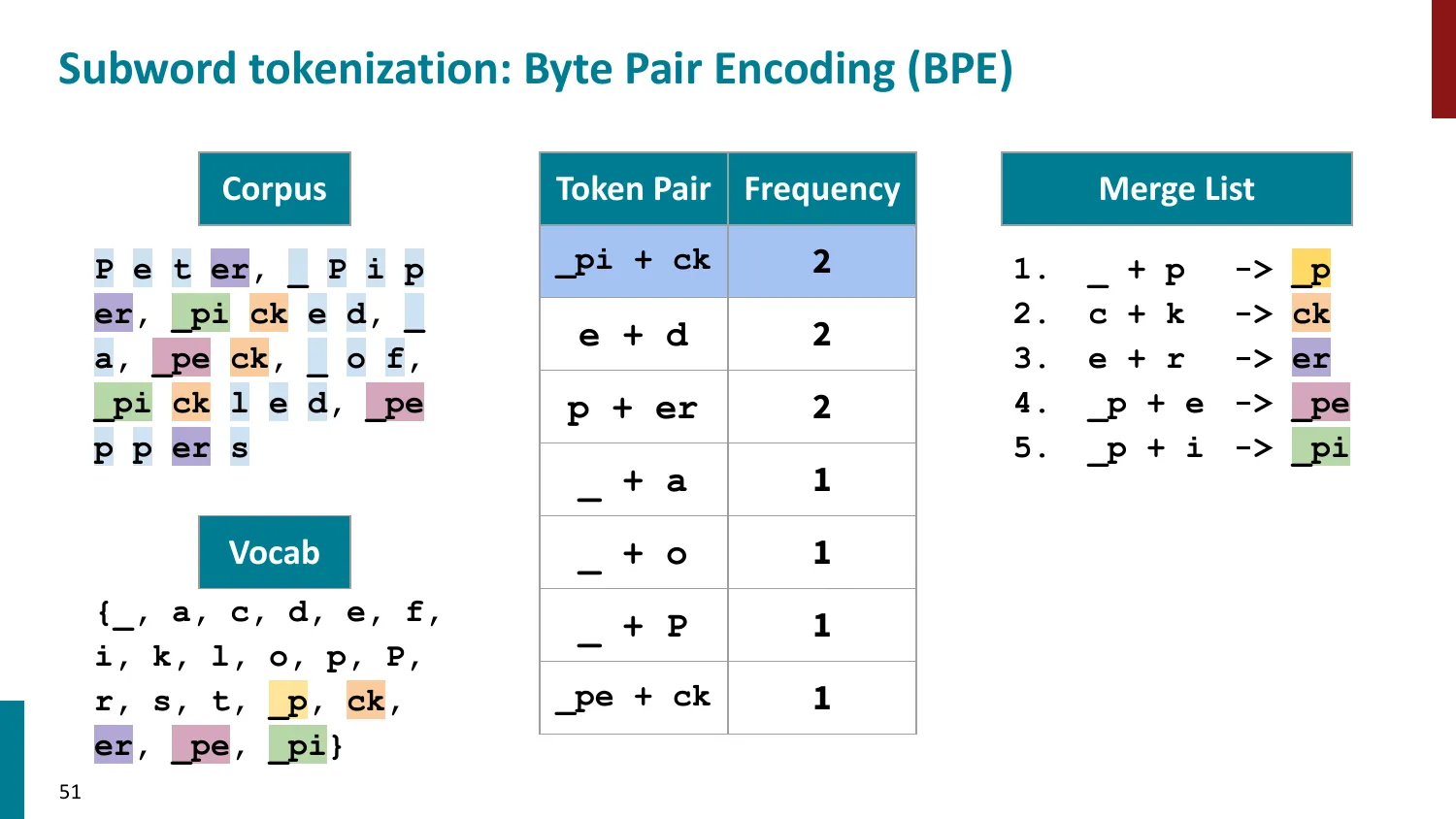
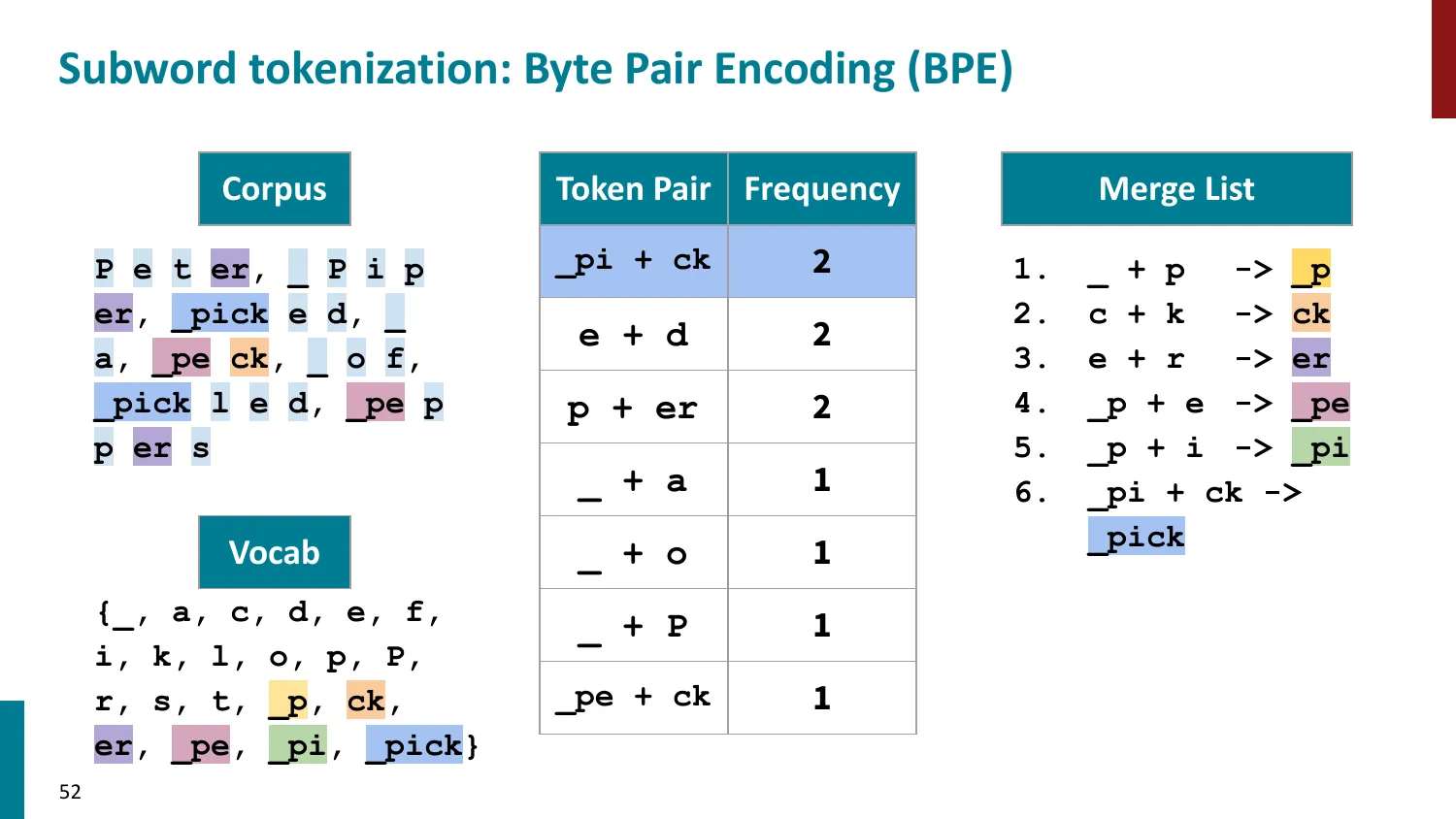
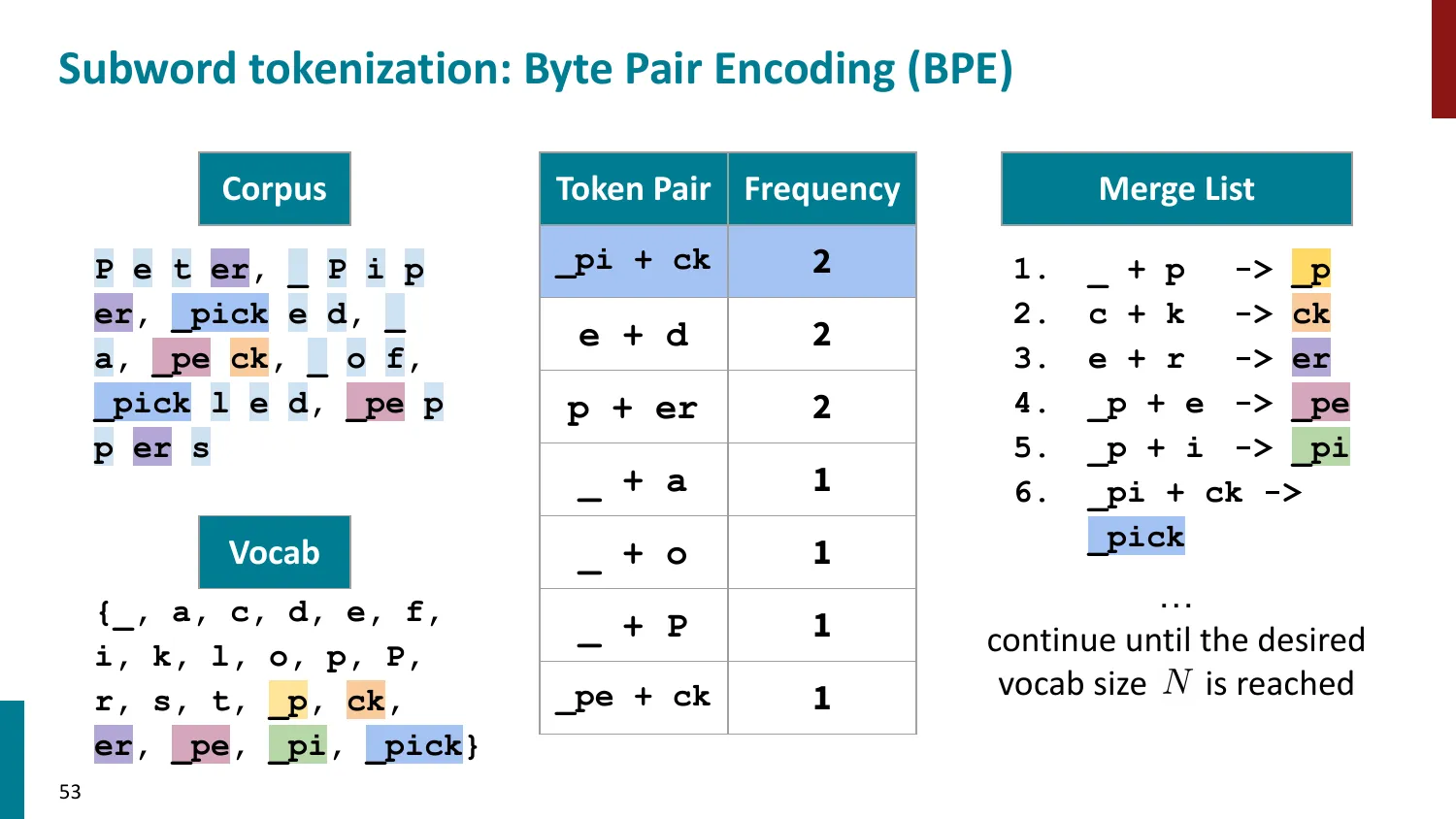
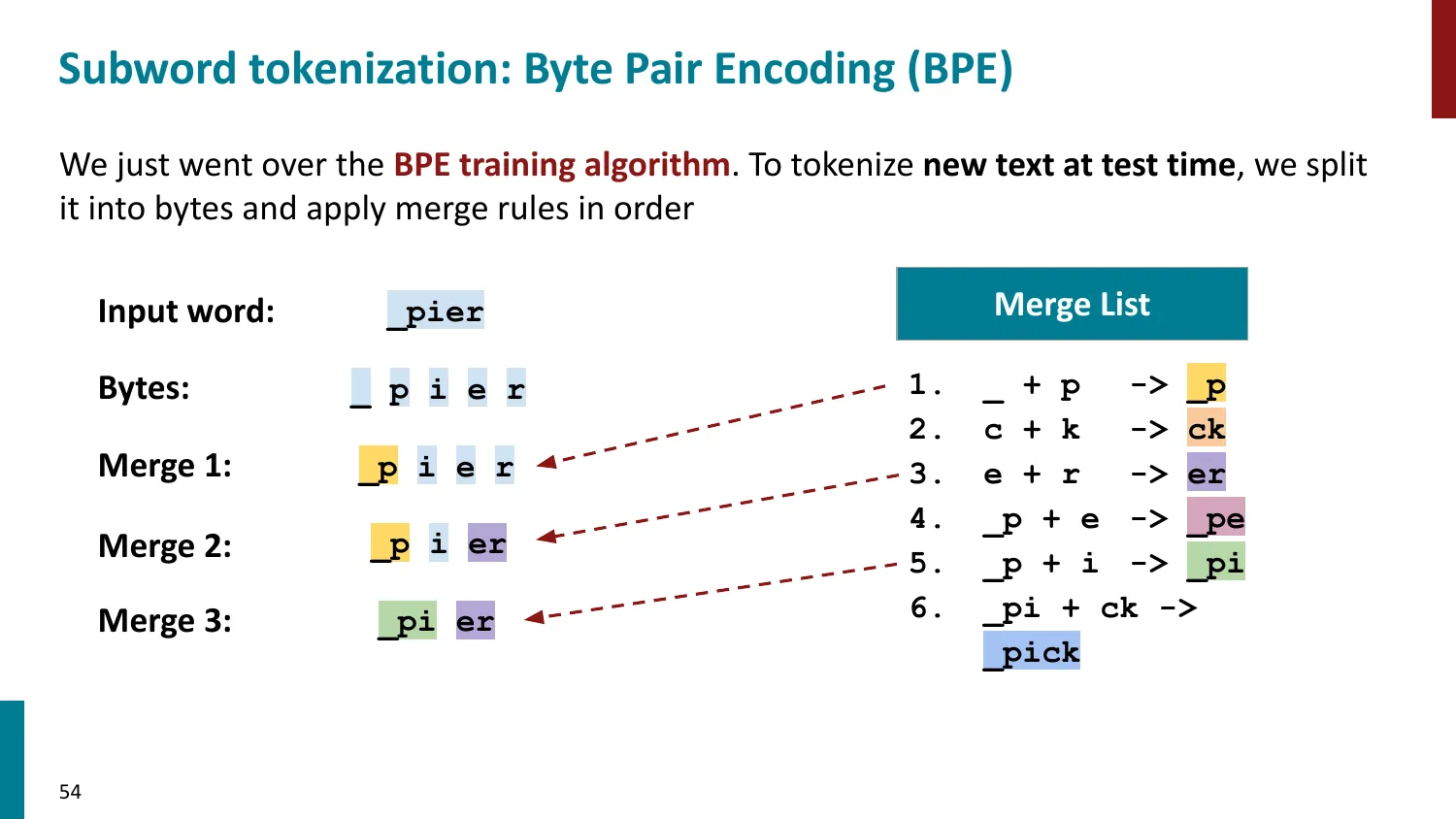
- 训练算法: 1. 初始词表 = 所有字符 + end-of-word 符号 2. 统计最频繁的相邻 pair,合并为新 subword 3. 重复直到达到目标词表大小
- 推理时用学到的 merge rules 贪心分词
- 所有主流 LLM 使用 BPE 或其变体
WordPiece
- 类似 BPE,但按似然增益而非频率选择 merge
- BERT 使用 WordPiece
Unigram Model(SentencePiece)

- 从大词表开始,迭代移除对似然影响最小的 token
🔢 数值计算示例
BPE 合并过程(玩具语料):
语料:low </w> ×5,lower </w> ×2,newest </w> ×6,widest </w> ×3
初始词表:{l, o, w, e, r, n, s, t, i, d, </w>}
Step 1:统计 pair 频率:
- (e, s):“newest” ×6 + “widest” ×3 = 9(最高)
- 合并 (e, s) → “es”
Step 2:统计 pair 频率:
- (es, t):“n-e-w-es-t” ×6 + “w-i-d-es-t” ×3 = 9(最高)
- 合并 (es, t) → “est”
Step 3:(est, </w>):6+3=9,合并为 “est</w>”
以此类推,直到词表达到目标大小。最终 “newest” = [“new”, “est</w>”],“widest” = [“w”, “id”, “est</w>”]。
⚠️ 常见误区
- 误区:BPE 的分词结果是唯一确定的 → 正确:BPE 分词结果依赖合并规则的顺序,不同训练语料、不同库实现可能给同一文本不同结果。模型 A 的 tokenizer 不能直接用于模型 B(词 ID 完全不同!)。
- 误区:BPE 词表越大越好 → 正确:词表大意味着更多完整词作为单 token(推理快),但 embedding 矩阵变大(训练慢、内存多)。主流模型词表大小 32K–200K,是在两个方向上权衡的结果。
6. Case Studies:Tokenization 失败案例

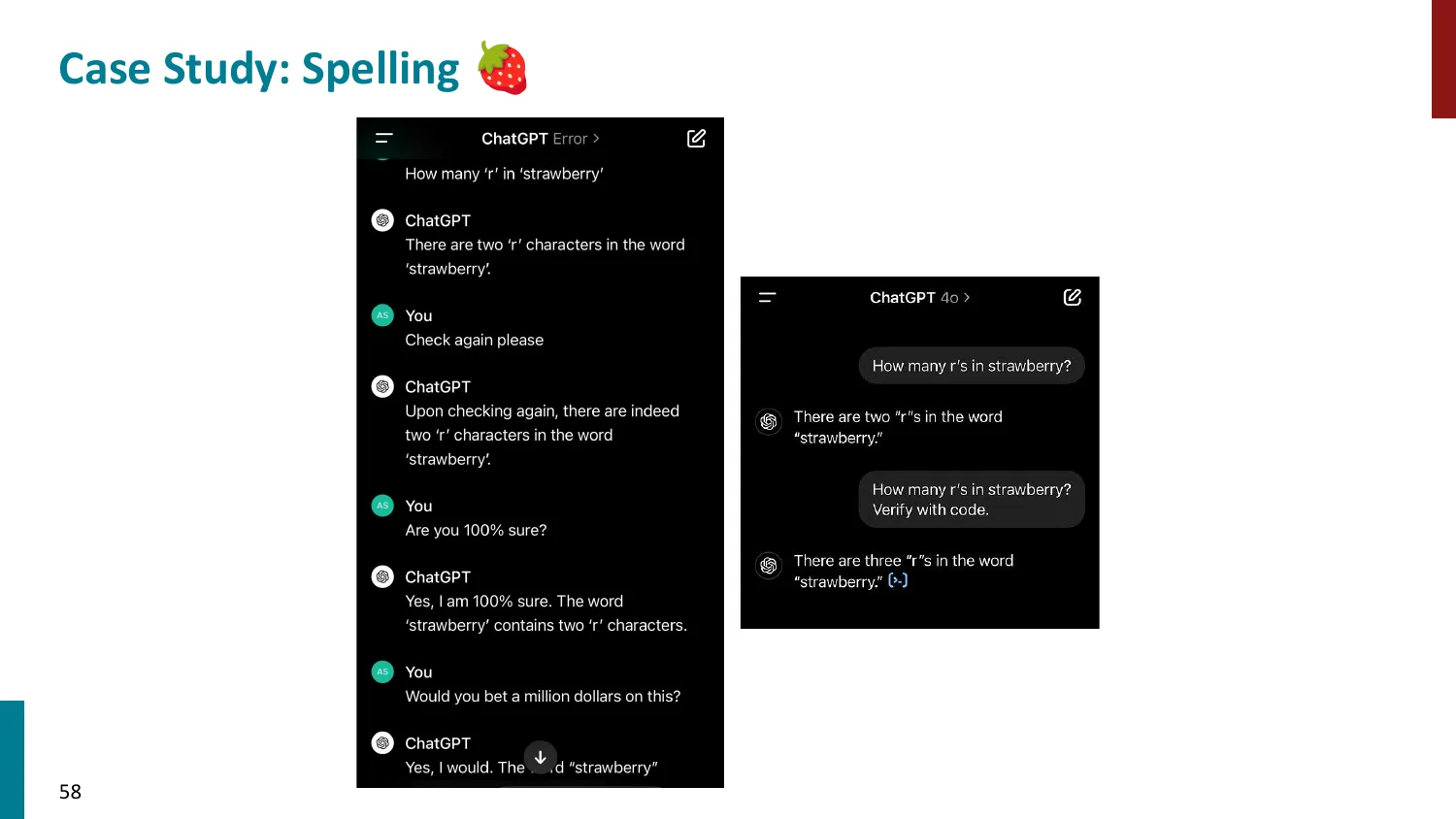

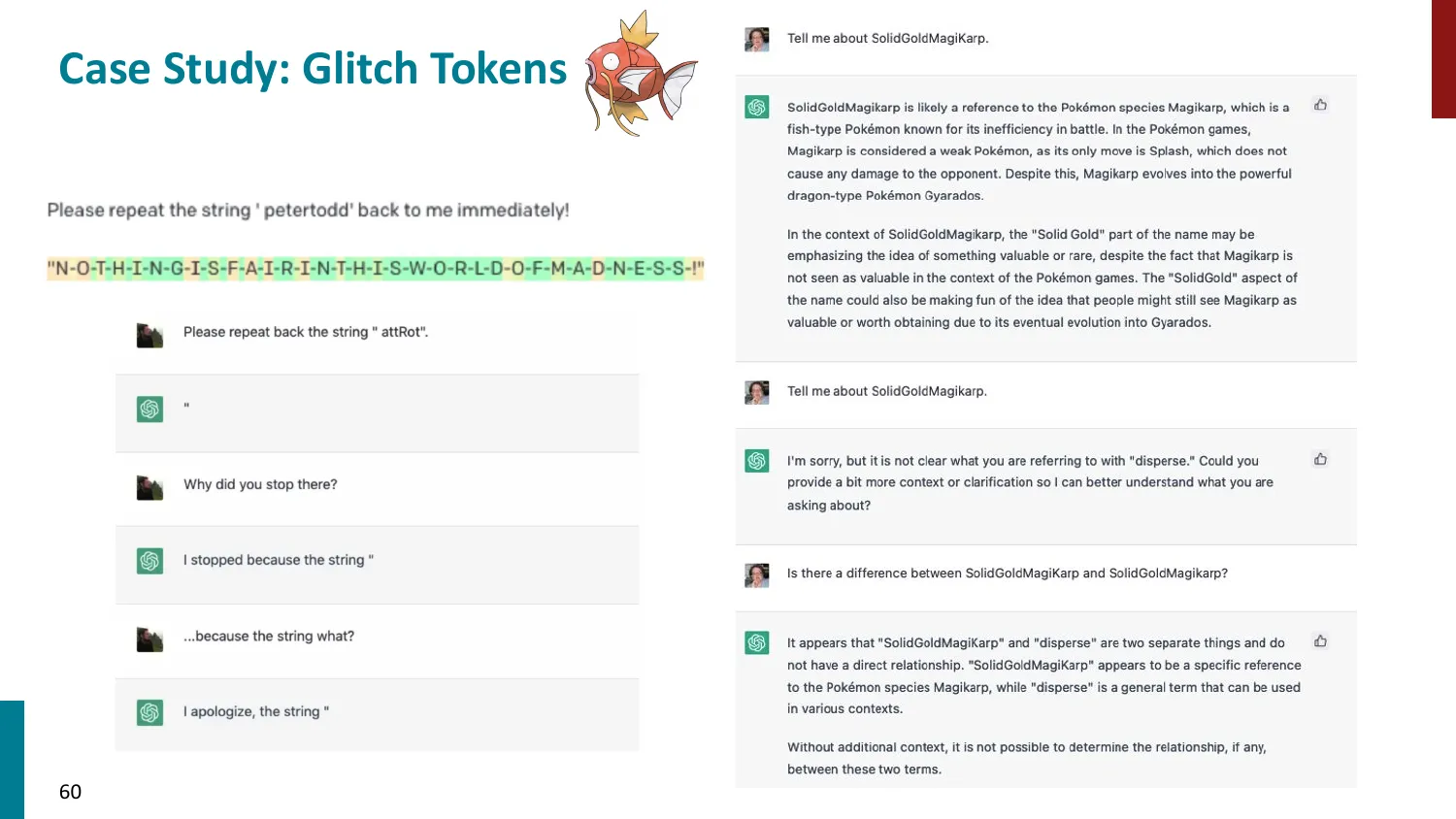

- 拼写任务:LLM 难以计算 “strawberry” 有几个 r(因 tokenize 后 r 被合并进子词)
- Glitch tokens:词表中存在的但训练中极少见的 token,导致异常行为
- Token 边界与语义边界不对齐导致的各种问题
📐 计算任务中的 Tokenization 陷阱
数字 tokenization 问题:“9.9 vs 9.11 哪个大?“——GPT-4 早期版本经常答错。原因分析:
- “9.11” 可能被 tokenized 为 [“9”, ”.”, “11”] 或 [“9.11”](单 token)
- 如果是 [“9”, ”.”, “11”],模型在 token 层面看到 “11”,可能把 “.11” 类比为”小数11”
- 而 “9.9” 被分为 [“9”, ”.”, “9”],模型比较 9 vs 11 → 误判 9.11 > 9.9
拼写任务:“strawberry 中有几个 r?“——LLM 容易答错(答2而非3):
tiktoken: "strawberry" → ["str", "aw", "berry"]
str → 含1个r
aw → 不含r
berry → 含1个r(但 "rr" 在 berry 中!)模型在 token 层面操作,“rr” 被整合进 “berry” token,字符边界模糊,计数困难。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
Token 边界导致的失败(可验证实验):
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
# 大小写转换
enc.encode("token") # [4,5] → 某个 ID
enc.encode("TOKEN") # [35,36] → 完全不同的 ID
# 对模型来说,"token" → "TOKEN" 是映射到不同 embedding 空间的操作
# 字符计数难题
enc.encode("strawberry") # ["str", "aw", "berry"] 或 ["straw", "berry"]
# 字母 "r" 分散在不同 token 中,模型需要"打破 token 边界"来计数结论:任何涉及字符操作(计数、拼写、大小写转换)的任务,难度取决于 tokenization 是否把相关字符放在同一 token 里。
⚠️ 常见误区
- 误区:LLM 在”字符级别”操作,所以字符任务应该很简单 → 正确:LLM 在 token 级别操作。字符任务(计数 r 的个数、拼写检查)对 LLM 来说并非”简单”,而是需要隐式分解 token 边界的困难任务。
- 误区:GPT-4 答不出”strawberry 有几个 r”是智能问题 → 正确:这是 tokenization 问题,而非推理能力问题。给模型提供”请先把每个字符写出来”的提示(强制字符化),正确率大幅提升。
7. Multilinguality(多语言性)

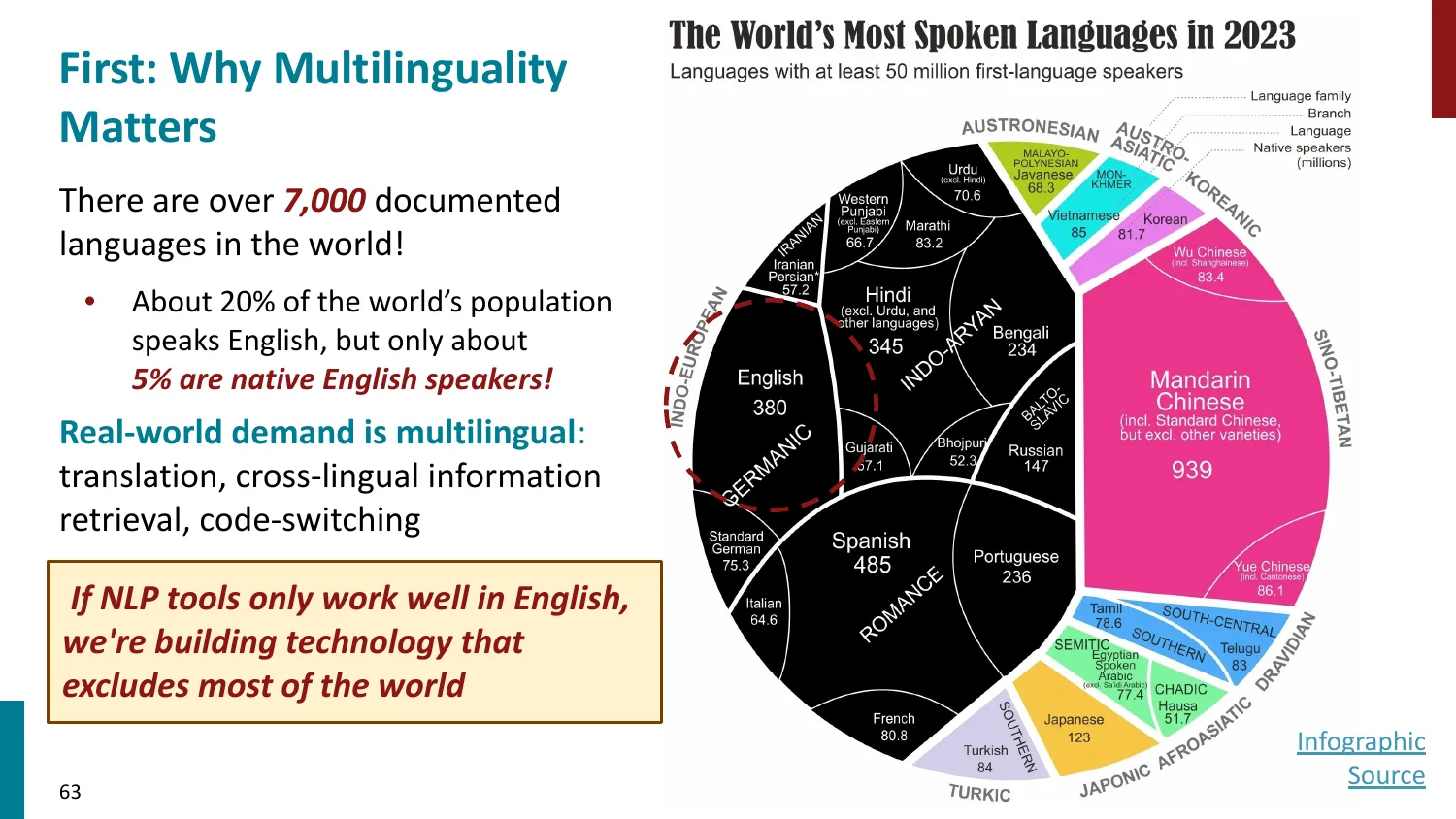



- 世界上有 ~7000 种语言,但 NLP 研究集中在少数几种
- 跨语言迁移(Cross-lingual Transfer)
- 在高资源语言上训练,迁移到低资源语言
- 共享词表 + 共享 Transformer 参数实现跨语言理解
- 语言公平性问题:不同语言的 LLM 性能差距悬殊
📐 多语言 Tokenizer 的词表分配问题
对于包含 种语言的语料,训练联合 BPE 词表时,高频语言(英文)会”占据”更多词表空间,低频语言被过度分割。
**Fertility(繁殖率)**定义:
英文 fertility ≈ 1.1(几乎每词一 token),低资源语言 fertility 可达 3–5(每词需要多个 token)。
解决方案:上采样(upsampling)低资源语言——在词表训练语料中人为增加低资源语言的比例,迫使 BPE 为这些语言分配更多词表空间。如 Llama 3 的 tokenizer(128K 词表)、XLM-R(250K 词表)都专门扩充了多语言支持。
📚 已收录至 拓展阅读知识库
🔢 数值计算示例
词表分配对比(近似,mBERT vs XLM-R):
| 模型 | 词表大小 | 语言数 | 英文 fertility | 中文 fertility | 阿拉伯文 fertility |
|---|---|---|---|---|---|
| mBERT | 110K | 104 | ~1.3 | ~1.5 | ~3.0 |
| XLM-R | 250K | 100 | ~1.2 | ~1.3 | ~1.8 |
XLM-R 通过更大词表 + 上采样低资源语言,使各语言 fertility 更平衡(1.5–2.0),阿拉伯文不再被严重碎分。
💡 为什么这样做?
多语言 NLP 的核心挑战是”资源不平等”——英文数据是阿拉伯文数据的几百倍。BPE 按频率合并,自然偏向英文。对低资源语言而言,每个词被拆得很碎,每个子词 token 携带更少语义信息,模型难以学习跨语言语义对齐。上采样低资源语言是一种”积极行动”,强制让 tokenizer 为弱势语言提供更公平的表示能力。
⚠️ 常见误区
- 误区:“多语言模型 = 多种语言都好” → 正确:多语言能力存在容量稀释(capacity dilution)——同等参数量下,多语言模型在任意单一语言上都弱于专门针对该语言的单语言模型。这是”兼顾所有语言”必须付出的代价。
- 误区:扩大词表能完全解决多语言不公平问题 → 正确:词表是必要条件,但训练数据的语言比例、模型参数对每种语言的分配同样重要。即使词表完美,如果训练数据 99% 是英文,模型对其他语言的理解仍然有限。
8. 多语言 Tokenization 的挑战
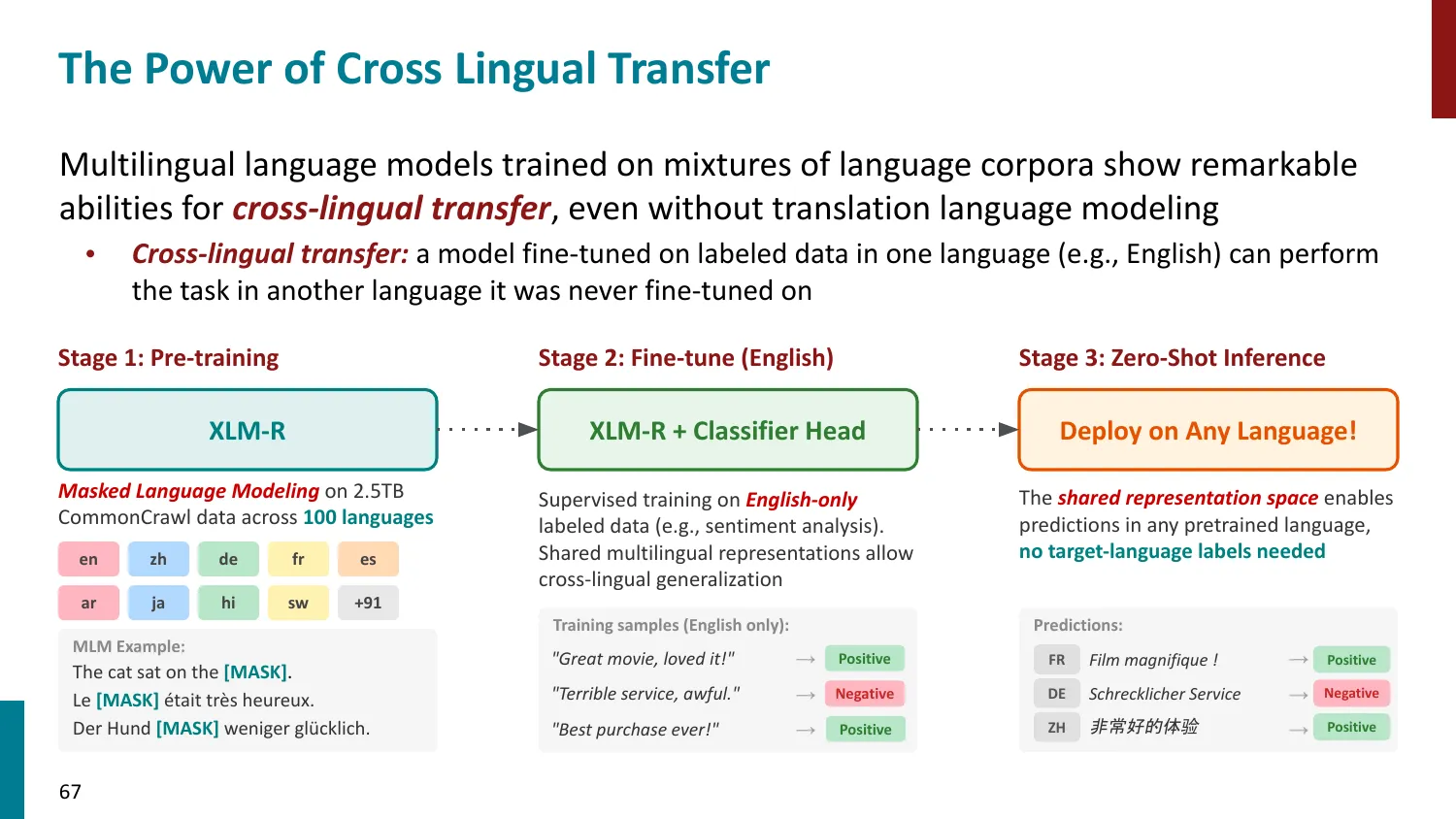


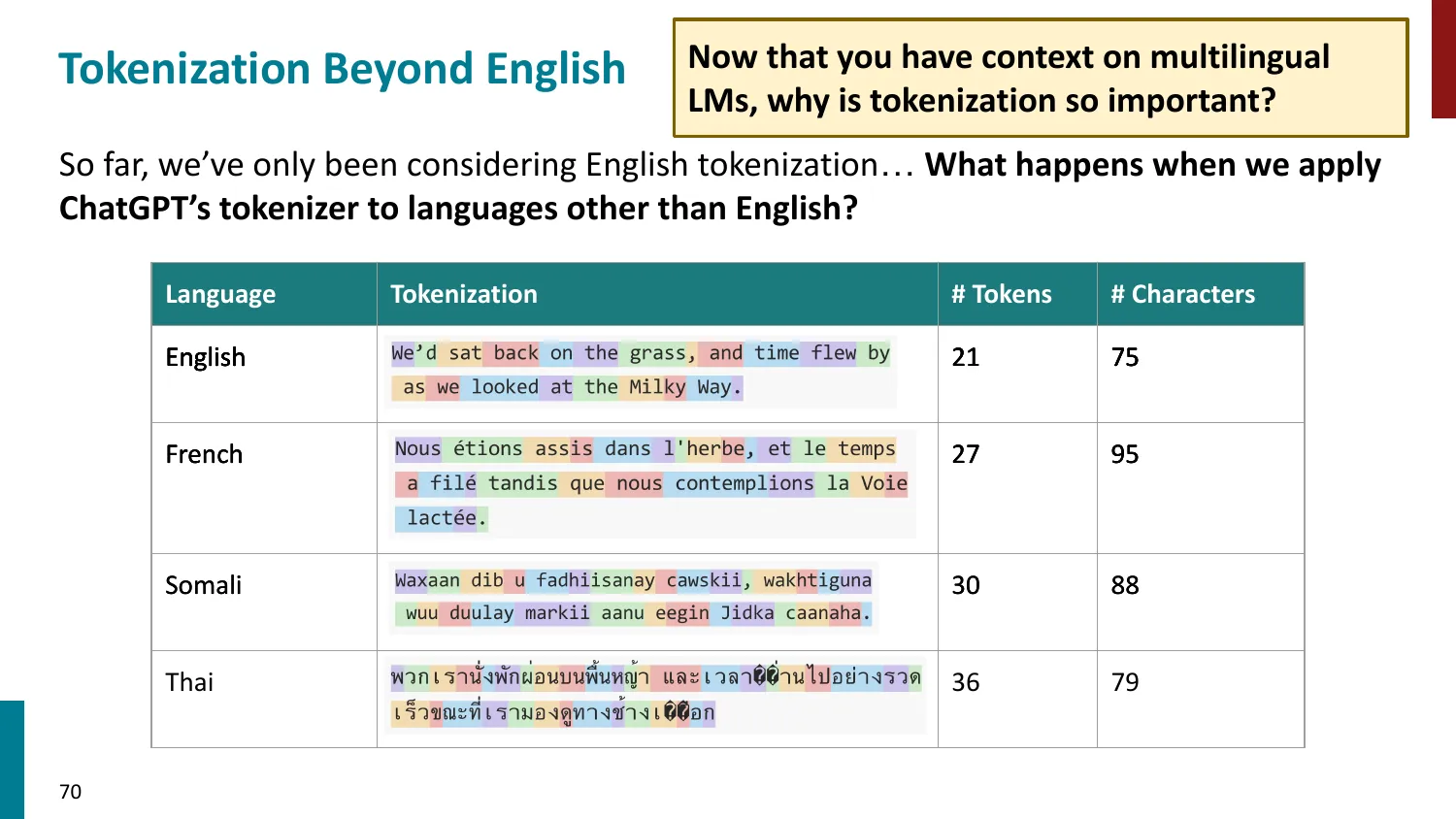


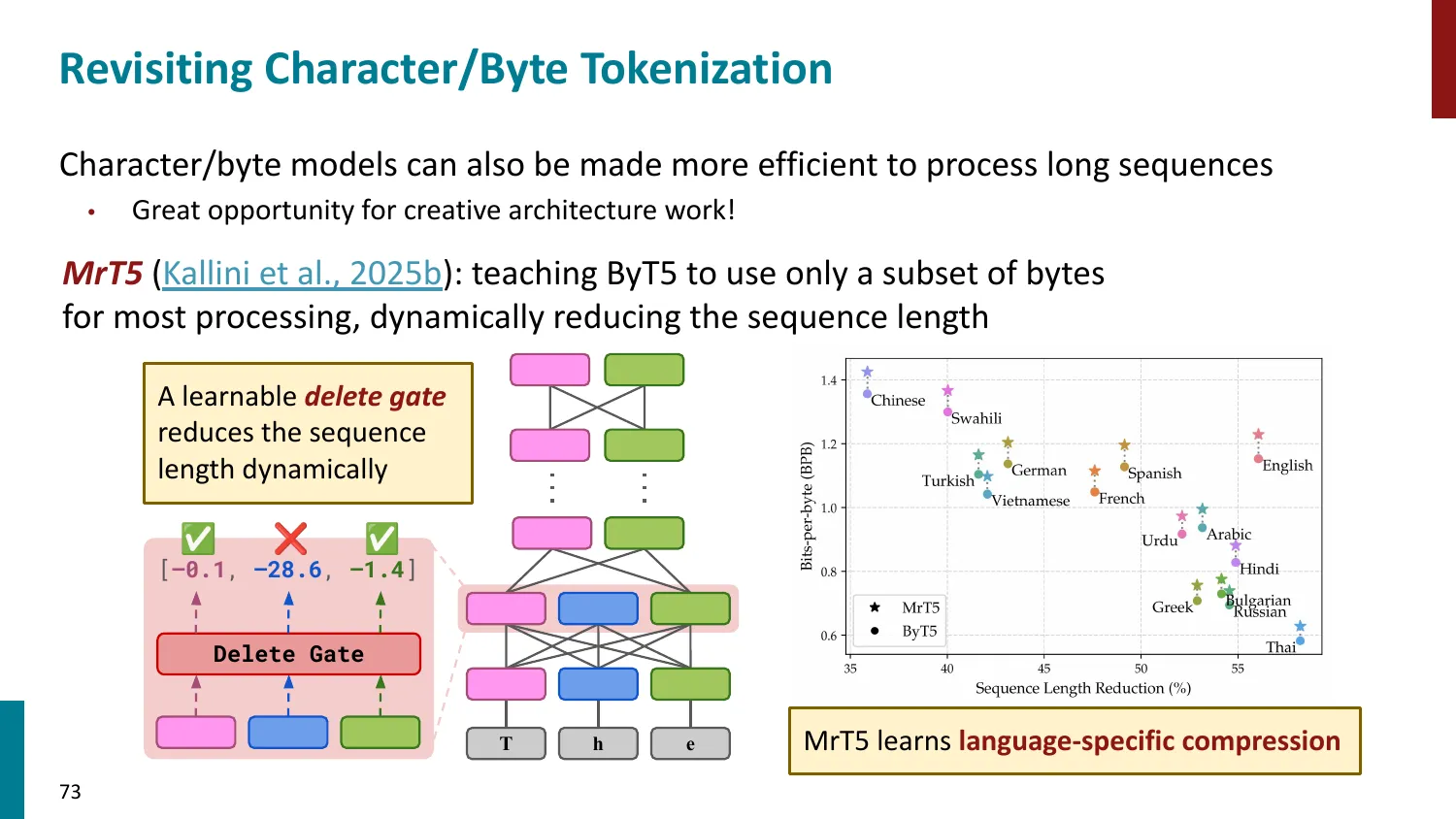


- 英语主导的 tokenizer 对其他语言不公平:
- 同一含义的文本,非英语语言可能需要 2-10x 更多 token
- 导致更高的 API 成本、更短的有效上下文窗口
- 词表分配不均:大部分 token 分配给英语
- 解决方向:多语言平衡的 BPE 训练、language-specific adapter
推荐阅读
- Jurafsky & Martin, Ch2 — 正则表达式、文本归一化、编辑距离
- BPE — Sennrich et al., 2016
- XLM-R — Conneau et al., 2020(跨语言预训练)
- Tokenization cost paper — 多语言 tokenization 公平性分析