L08: Post-training
Week 4 · Thu Jan 29 2026 08:00:00 GMT+0800 (中国标准时间)
L08: Post-training
Slides
中英交替版(推荐)
L08 双语 (PDF)
英文原版
L08 EN (PDF)
中文翻译版
L08 ZH (PDF)
核心知识点
1. 语言建模 != 辅助用户
预训练 LM 只会续写文本(completion),不会遵循指令
GPT-3 示例:对 “Explain X” 的回复是生成更多类似 prompt,而非实际回答
核心问题:语言模型与用户意图未对齐(not aligned)
📐 预训练 LM 与助手模型的目标差异
预训练语言模型 的目标:在给定任意前缀的情况下,预测最可能的下一个 token:
P L M ( x t + 1 ∣ x ≤ t ; θ ) P_{LM}(x_{t+1} \mid x_{\leq t}; \theta) P L M ( x t + 1 ∣ x ≤ t ; θ )
这个目标对输入内容完全无偏——给定 “The sky is” 和给定 “How do I make a bomb? Answer:” 都一视同仁,只预测下一个最可能的 token。
助手模型 的目标:给定用户请求 x x x r r r 有帮助的 回复:
P a s s i s t a n t ( y ∣ x , r ; θ ) 其中 y 最大化用户满意度 P_{assistant}(y \mid x, r; \theta) \quad \text{其中 } y \text{ 最大化用户满意度} P a ss i s t an t ( y ∣ x , r ; θ ) 其中 y 最大化用户满意度
两者的根本差异:LM 目标是描述性 的(世界上的文本是什么样的),助手目标是规范性 的(回复应该是什么样的)。这个差距——对齐问题(Alignment Problem) ——是后训练(post-training)存在的根本原因。
📚 已收录至 拓展阅读知识库
💡 为什么这样做?
把预训练 LM 想象成一个读了大量书的人,他能流利地”续写”任何文章风格。但”续写文章”和”回答你的问题”是完全不同的事。如果你在一本书里问”今天天气怎么样?“,接下来的文字很可能是”晴朗的春日让人心情愉悦……”,而不是真正回答天气预报。预训练模型的行为正是如此——它在模仿训练数据的分布,而不是在帮你解决问题。
⚠️ 常见误区
误区 :RLHF/SFT 的目的是让模型变得”更聪明”、获得更多知识 → 正确 :模型的能力(推理、知识、代码)主要在预训练阶段获得 ,后训练的核心目的是行为对齐 ——让模型更有用(Helpful)、更无害(Harmless)、更诚实(Honest),即 Anthropic 的 HHH 框架。后训练可以激发预训练中隐含的能力,但无法凭空创造新能力。
误区 :只要模型够大,预训练后就能自动成为好助手 → 正确 :GPT-3(175B)在没有对齐的情况下,会在”Explain the moon landing” 之后生成更多关于月球登陆的讨论(而非解释),因为这是语料中最可能的续写。规模不能替代对齐。
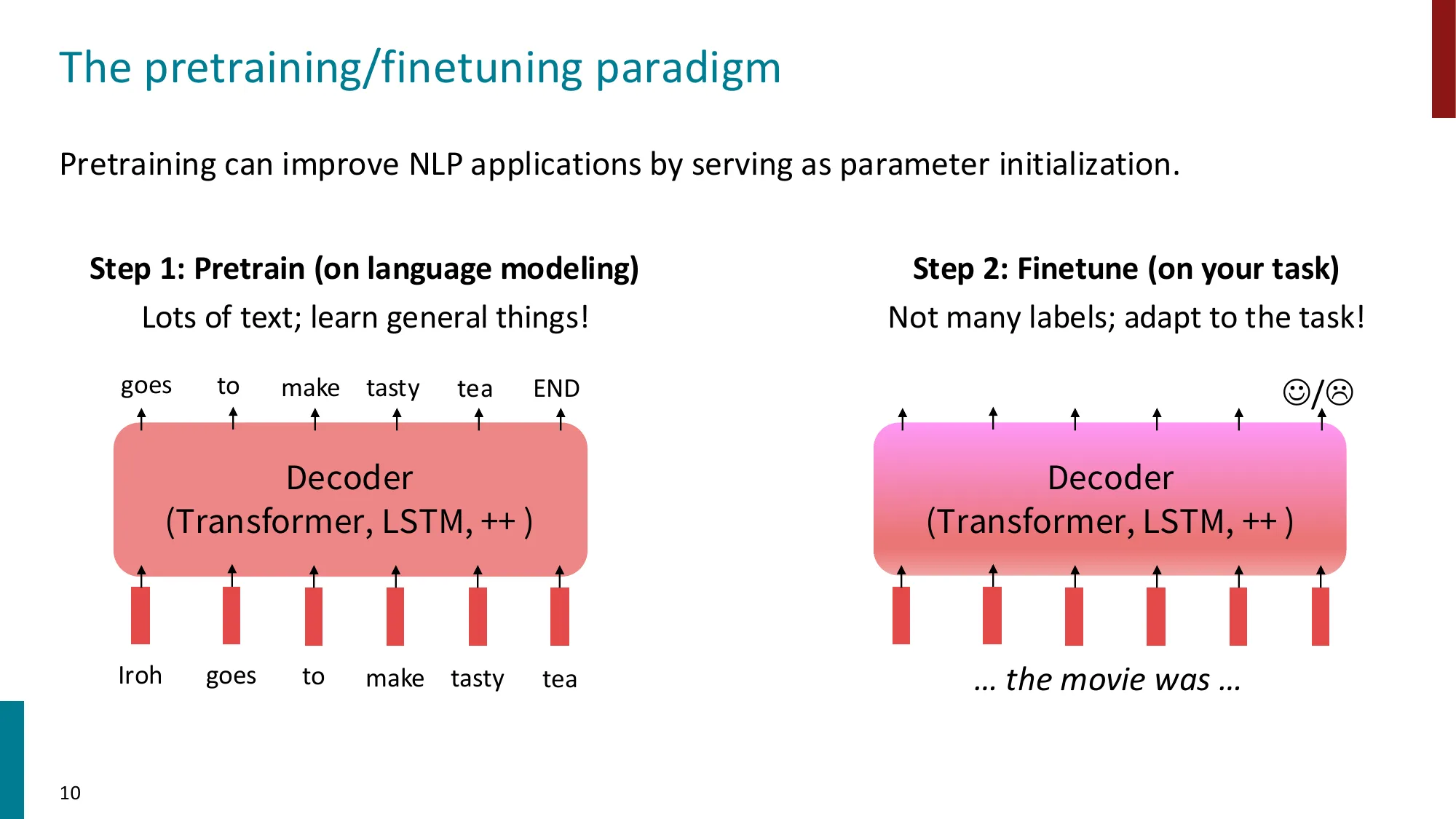
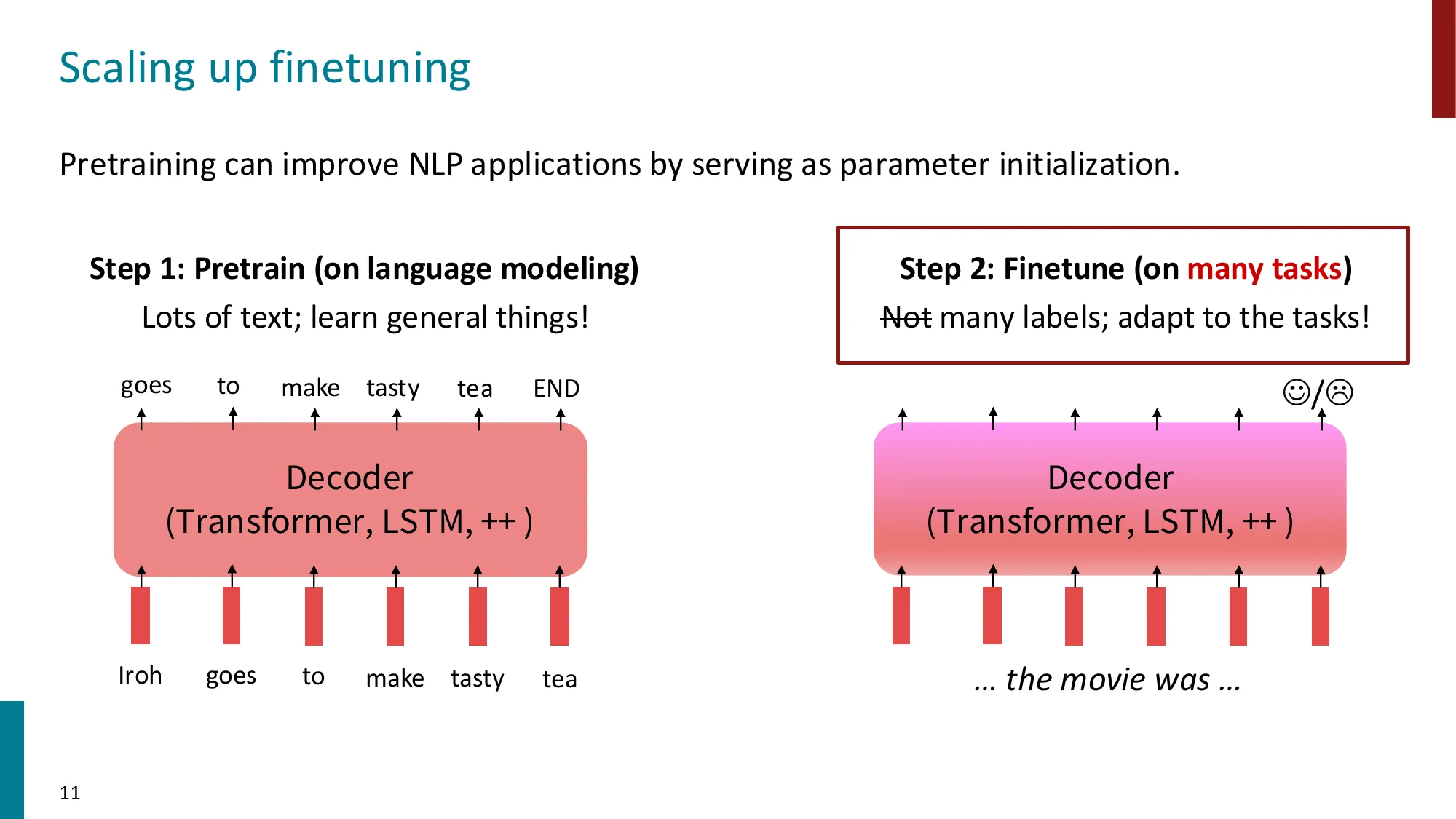
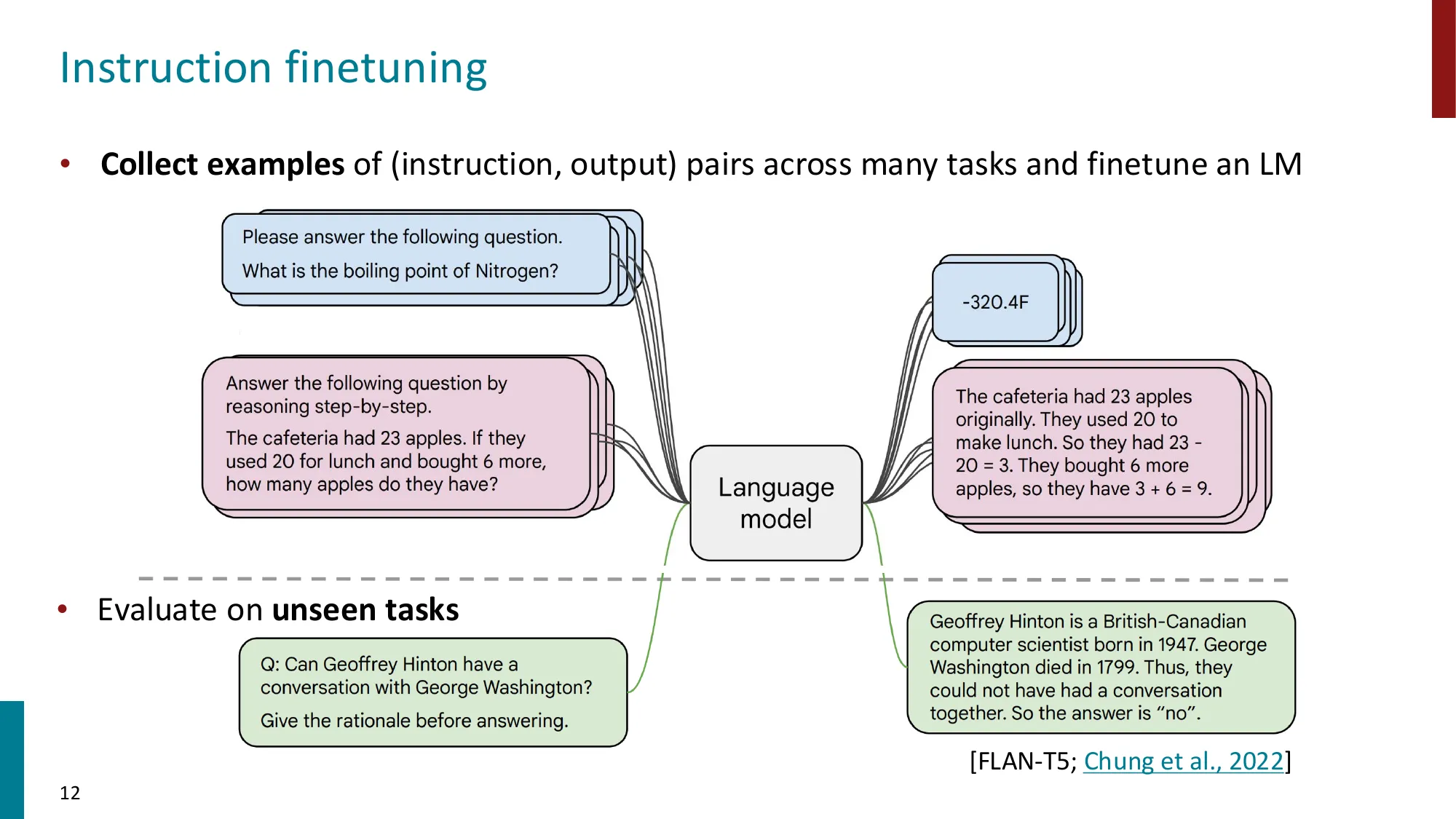
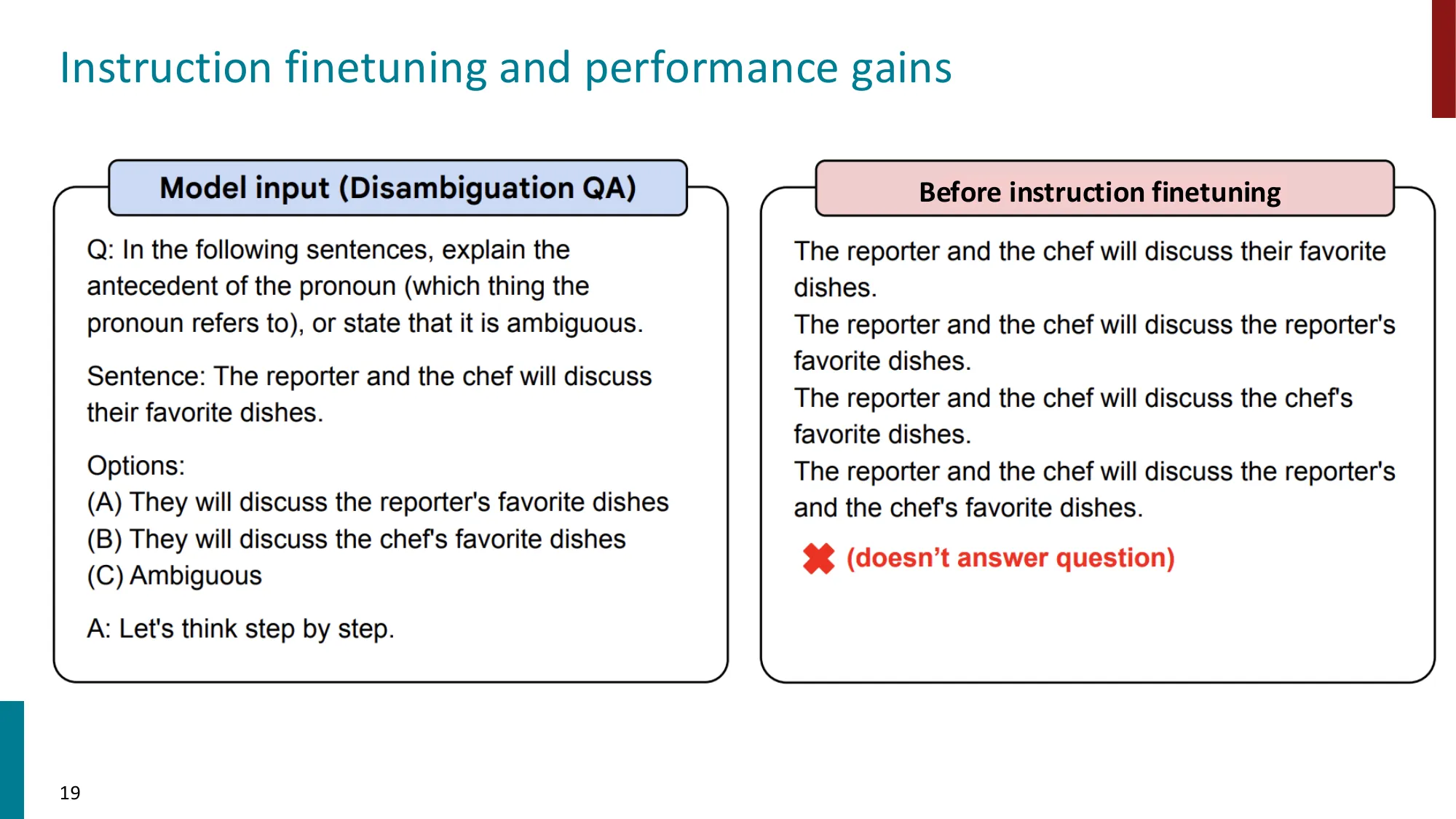
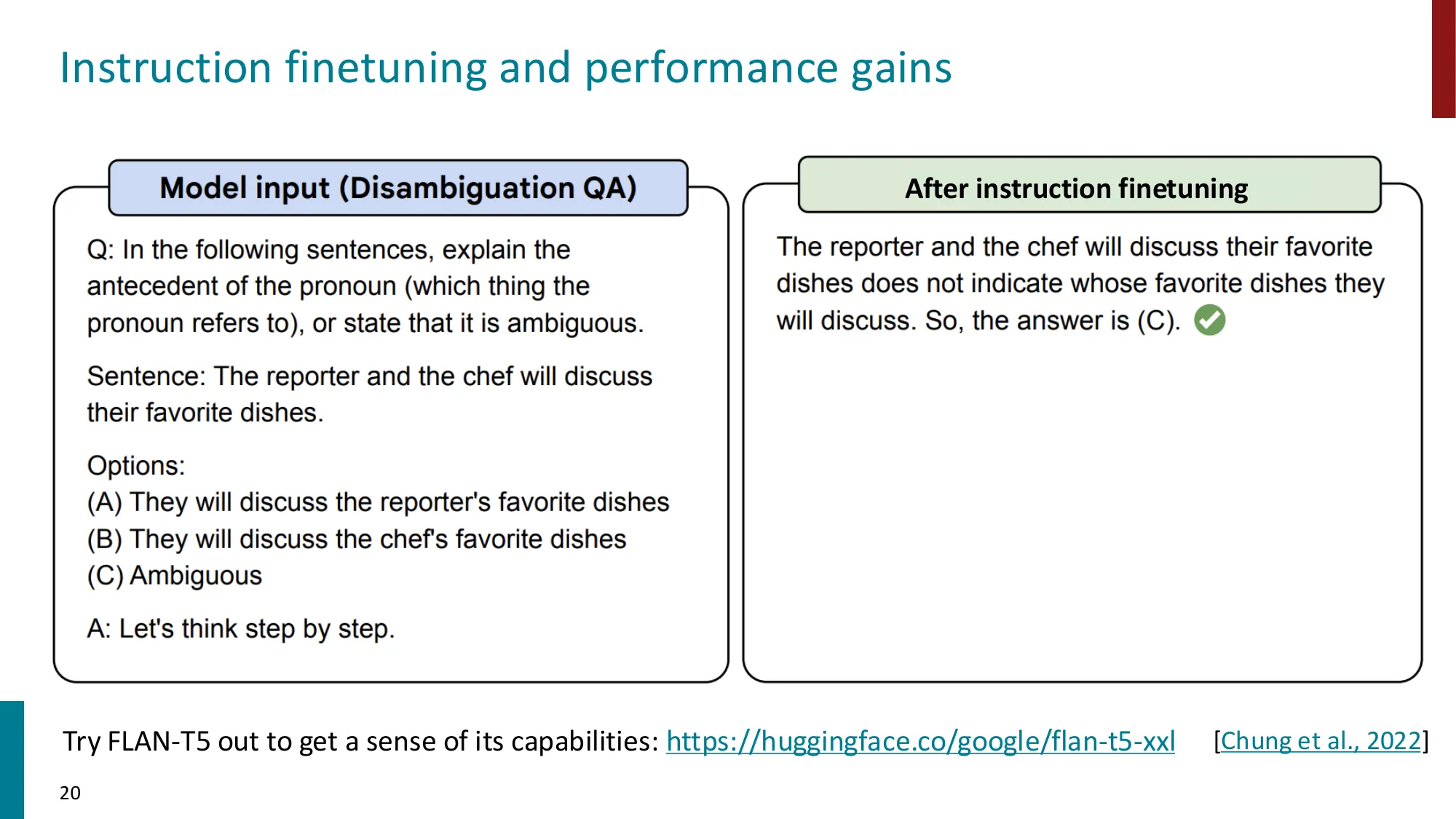
2. Instruction Fine-tuning(指令微调)
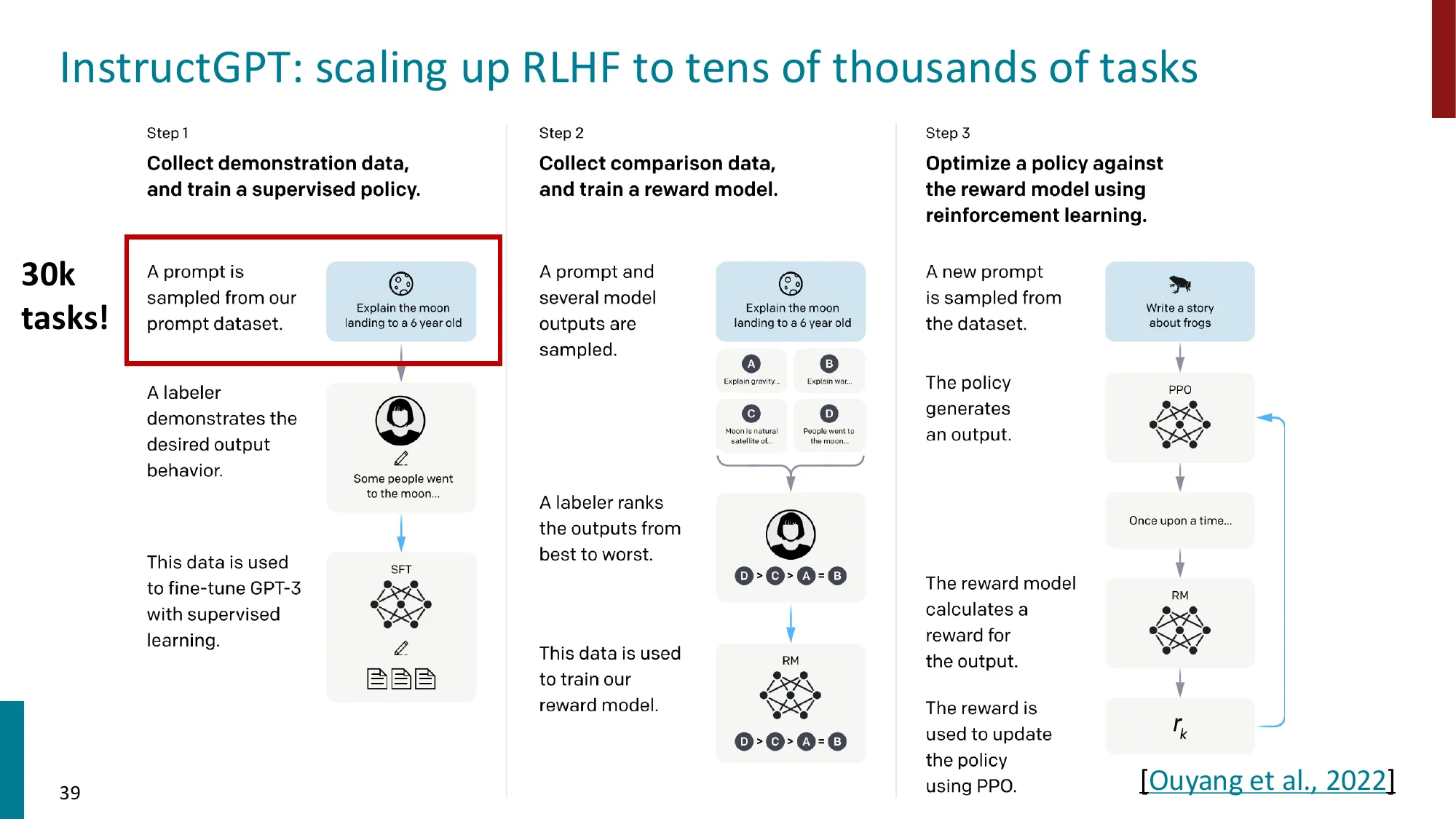
收集 (instruction, output) 对,跨多任务微调 LM
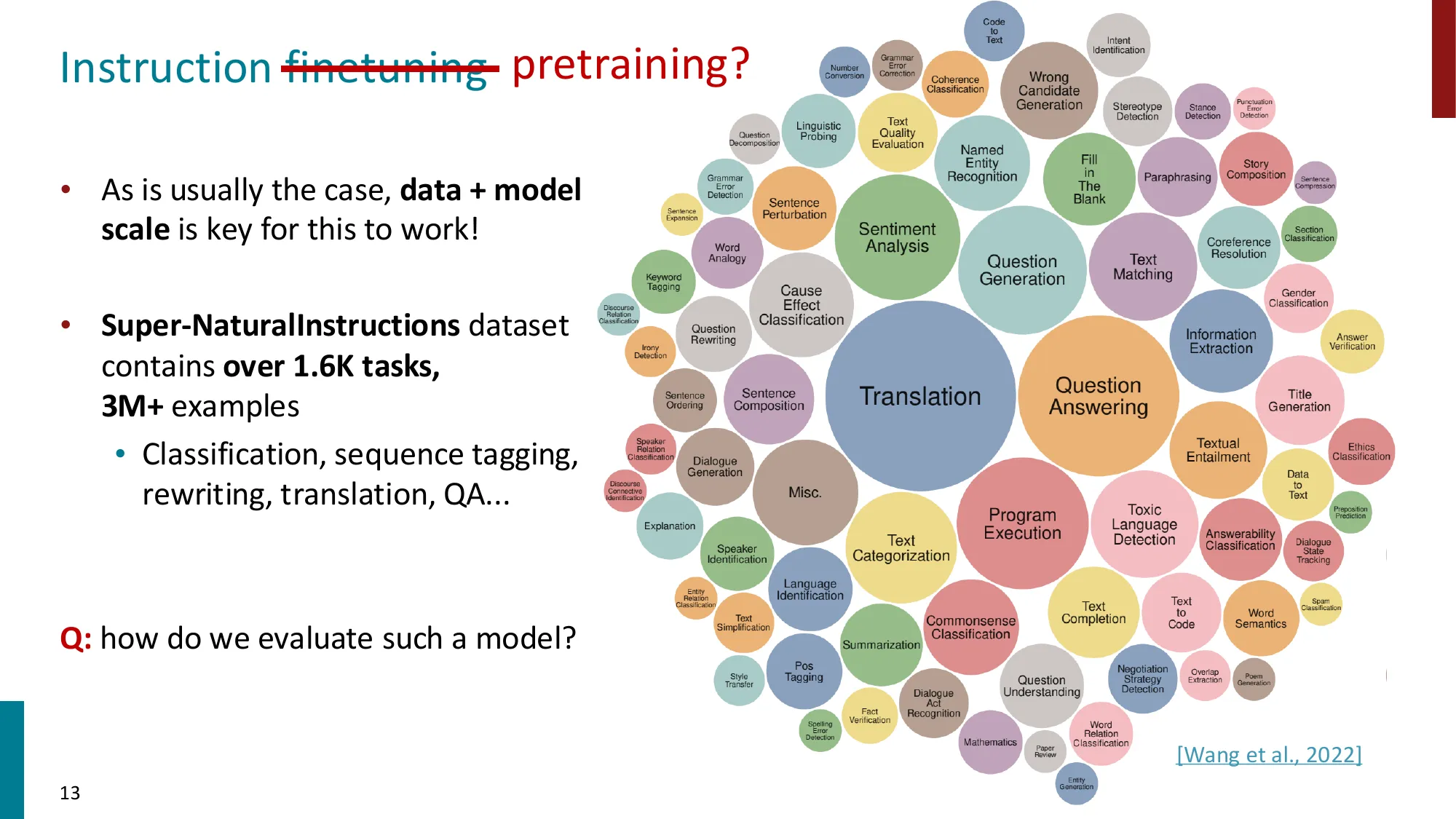
Super-NaturalInstructions:1.6K+ 任务,3M+ 样本
Flan-T5 (Chung et al., 2022):T5 在 1.8K 任务上指令微调
更大模型 = 更大的指令微调增益(T5-XXL: +26.6)
模型可在未见任务上泛化
数据 + 模型规模是关键
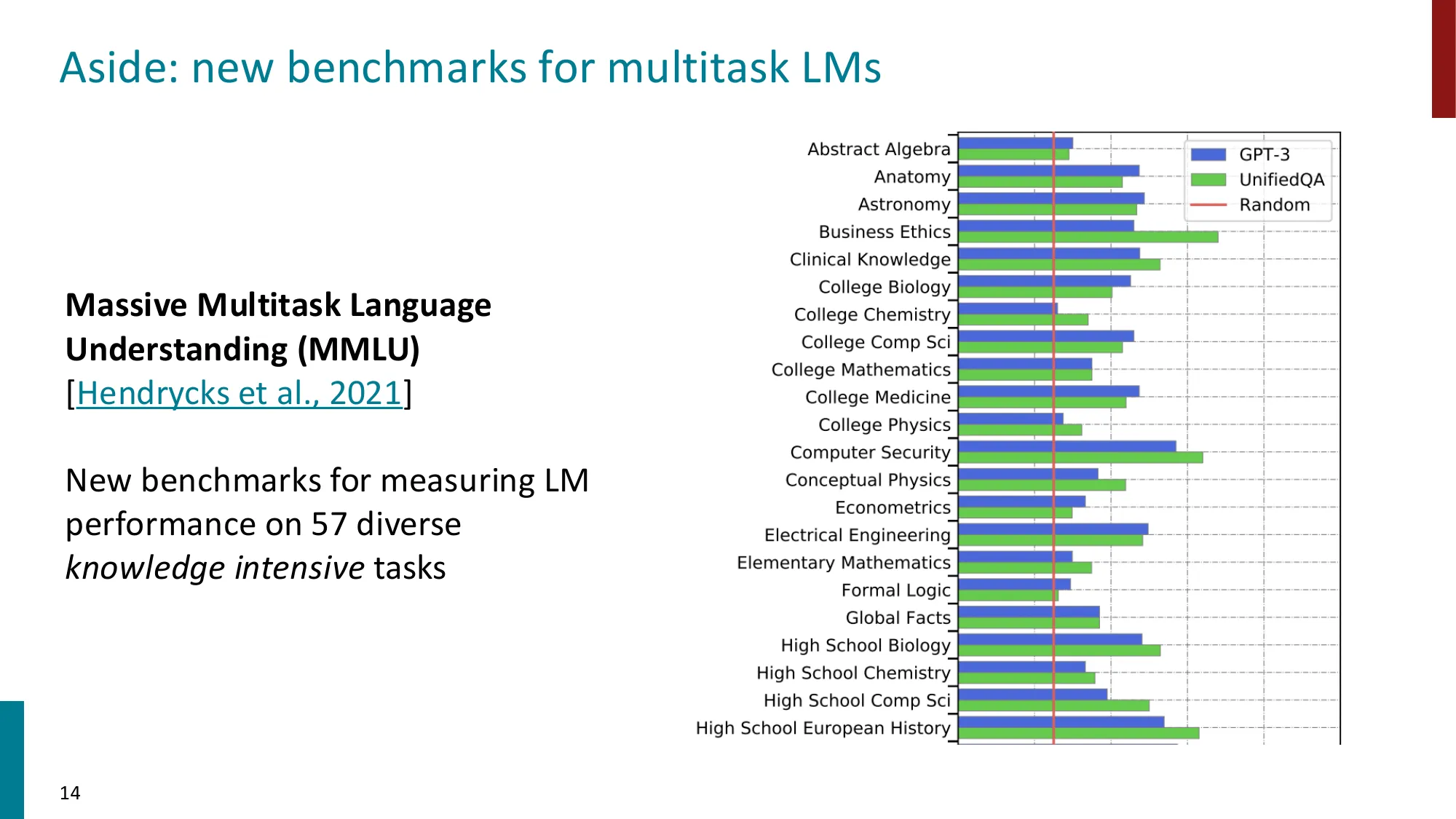
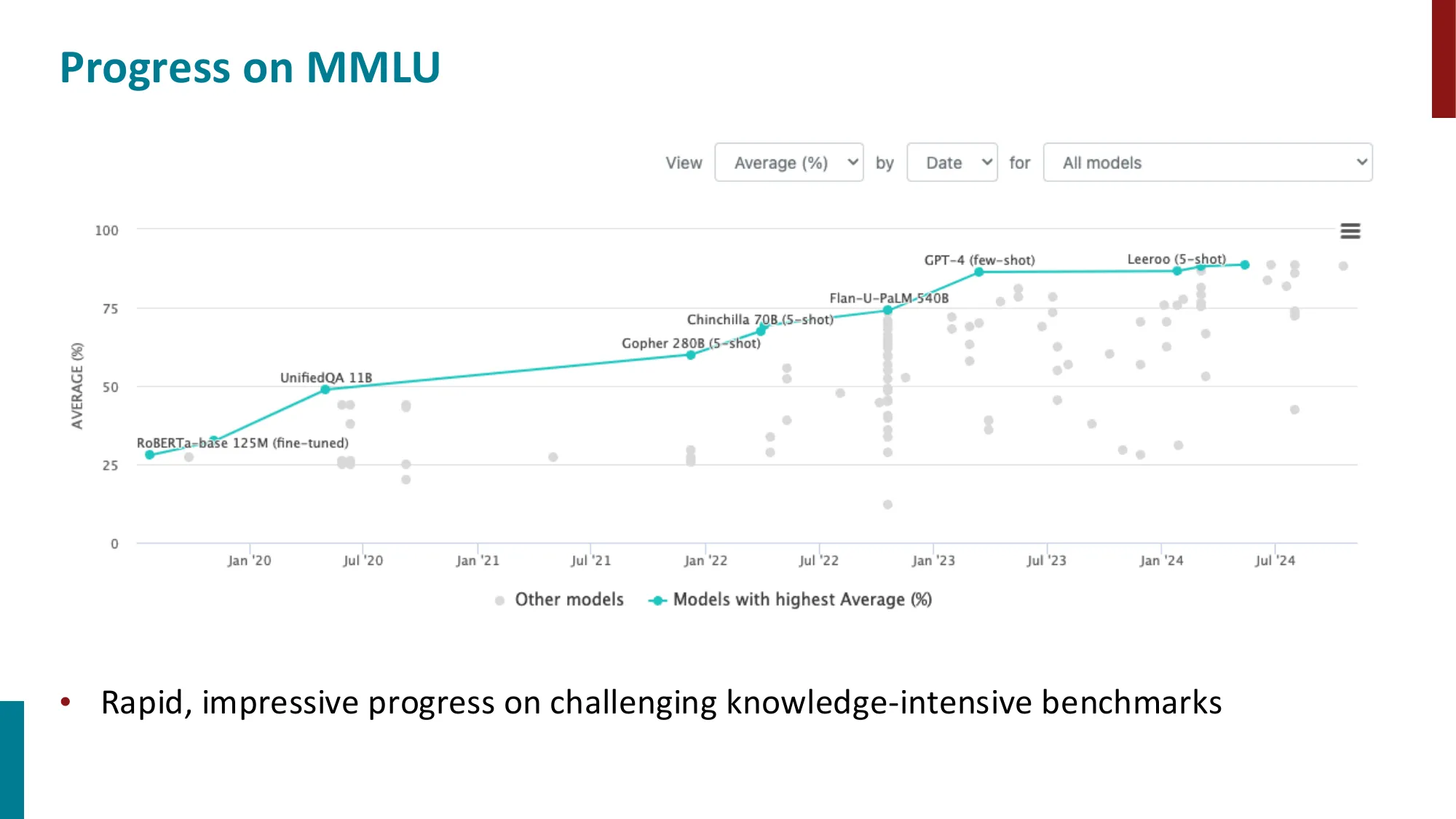
新基准:MMLU(57 个知识密集型任务)、BIG-Bench(200+ 任务)
📐 SFT 目标函数
监督微调(Supervised Fine-Tuning) 与标准语言模型训练的区别仅在于损失计算的范围 :
J S F T ( θ ) = − ∑ ( x i , y i ) ∈ D S F T ∑ t = 1 ∣ y i ∣ log P θ ( y i ( t ) ∣ y i ( < t ) , x i ) J_{SFT}(\theta) = -\sum_{(x_i, y_i) \in D_{SFT}} \sum_{t=1}^{|y_i|} \log P_\theta\!\left(y_i^{(t)} \mid y_i^{(<t)}, x_i\right) J S F T ( θ ) = − ∑ ( x i , y i ) ∈ D S F T ∑ t = 1 ∣ y i ∣ log P θ ( y i ( t ) ∣ y i ( < t ) , x i )
( x i , y i ) (x_i, y_i) ( x i , y i ) 只在回复 y i y_i y i ,指令 x i x_i x i 这与标准 CLM 预训练的区别:SFT 的模型需要学的是”给定指令,生成好的回复”,而不是”给定任意前缀,续写任意文本”
数学上 ,SFT 等价于在条件分布 P ( y ∣ x ) P(y \mid x) P ( y ∣ x )
📚 已收录至 拓展阅读知识库
📐 CLM vs SFT:Token 级损失的精确对比
设完整序列 S = [ x 1 , … , x m , y 1 , … , y n ] S = [x_1, \ldots, x_m, y_1, \ldots, y_n] S = [ x 1 , … , x m , y 1 , … , y n ] x 1 : m x_{1:m} x 1 : m y 1 : n y_{1:n} y 1 : n
CLM(因果语言建模,预训练目标) ——对所有 T = m + n T = m + n T = m + n
J C L M ( θ ) = − 1 T ∑ t = 1 T log P θ ( s t ∣ s < t ) J_{CLM}(\theta) = -\frac{1}{T}\sum_{t=1}^{T} \log P_\theta(s_t \mid s_{<t}) J C L M ( θ ) = − T 1 ∑ t = 1 T log P θ ( s t ∣ s < t )
每个 token 都参与梯度更新,模型学的是”这段文字整体的续写概率”。
SFT(监督微调,指令微调使用) ——引入 loss mask m t ∈ { 0 , 1 } m_t \in \{0, 1\} m t ∈ { 0 , 1 }
J S F T ( θ ) = − 1 ∑ t m t ∑ t = 1 T m t ⋅ log P θ ( s t ∣ s < t ) J_{SFT}(\theta) = -\frac{1}{\sum_t m_t}\sum_{t=1}^{T} m_t \cdot \log P_\theta(s_t \mid s_{<t}) J S F T ( θ ) = − ∑ t m t 1 ∑ t = 1 T m t ⋅ log P θ ( s t ∣ s < t )
其中
m t = { 0 t ≤ m ( 指令 token,mask 掉 ) 1 t > m ( 回复 token,计算损失 ) m_t = \begin{cases} 0 & t \leq m \quad (\text{指令 token,mask 掉}) \\ 1 & t > m \quad (\text{回复 token,计算损失}) \end{cases} m t = { 0 1 t ≤ m ( 指令 token , mask 掉 ) t > m ( 回复 token ,计算损失 )
两者的梯度差异 :
∂ J S F T ∂ θ = − 1 n ∑ t = m + 1 m + n ∂ log P θ ( s t ∣ s < t ) ∂ θ \frac{\partial J_{SFT}}{\partial \theta} = -\frac{1}{n} \sum_{t=m+1}^{m+n} \frac{\partial \log P_\theta(s_t \mid s_{<t})}{\partial \theta} ∂ θ ∂ J S F T = − n 1 ∑ t = m + 1 m + n ∂ θ ∂ l o g P θ ( s t ∣ s < t )
注意:指令 token x 1 : m x_{1:m} x 1 : m 仍参与前向传播 (在 attention context 中可见),只是不产生梯度 。这与把指令截断掉完全不同——模型需要”看到”指令才能生成正确回复,只是不需要”学会生成”指令。
三者等价关系 :若指令长度 m → 0 m \to 0 m → 0 m → T m \to T m → T J S F T = 0 J_{SFT} = 0 J S F T = 0
📚 已收录至 拓展阅读知识库
🔢 Token 级损失计算:一个完整的手算示例
设定 :词表 V = { [Q] , 翻译: , 猫 , [A] , cat , . , [EOS] , … } V = \{\texttt{[Q]}, \texttt{翻译:}, \texttt{猫}, \texttt{[A]}, \texttt{cat}, \texttt{.}, \texttt{[EOS]}, \ldots\} V = { [Q] , 翻译 : , 猫 , [A] , cat , . , [EOS] , … }
指令 x = [ [Q] , 翻译: , 猫 ] x = [\texttt{[Q]}, \texttt{翻译:}, \texttt{猫}] x = [ [Q] , 翻译 : , 猫 ] y = [ [A] , cat , . , [EOS] ] y = [\texttt{[A]}, \texttt{cat}, \texttt{.}, \texttt{[EOS]}] y = [ [A] , cat , . , [EOS] ]
完整序列 S = [ [Q] , 翻译: , 猫 ⏟ 指令 m = 3 , [A] , cat , . , [EOS] ⏟ 回复 n = 4 ] S = [\underbrace{\texttt{[Q]}, \texttt{翻译:}, \texttt{猫}}_{\text{指令 }m=3}, \underbrace{\texttt{[A]}, \texttt{cat}, \texttt{.}, \texttt{[EOS]}}_{\text{回复 }n=4}] S = [ 指令 m = 3 [Q] , 翻译 : , 猫 , 回复 n = 4 [A] , cat , . , [EOS] ] T = 7 T=7 T = 7
位置 t t t Token s t s_t s t 条件 P θ ( s t ∣ s < t ) P_\theta(s_t \mid s_{<t}) P θ ( s t ∣ s < t ) CLM m t m_t m t SFT m t m_t m t 损失项 ℓ t \ell_t ℓ t 1 [Q]P ( [Q] ) P(\texttt{[Q]}) P ( [Q] ) ✓ ✗ ℓ 1 \ell_1 ℓ 1 2 翻译:P ( 翻译: ∣ [Q] ) P(\texttt{翻译:} \mid \texttt{[Q]}) P ( 翻译 : ∣ [Q] ) ✓ ✗ ℓ 2 \ell_2 ℓ 2 3 猫P ( 猫 ∣ [Q]翻译: ) P(\texttt{猫} \mid \texttt{[Q]}\texttt{翻译:}) P ( 猫 ∣ [Q] 翻译 : ) ✓ ✗ ℓ 3 \ell_3 ℓ 3 4 [A]P ( [A] ∣ x 1 : 3 ) P(\texttt{[A]} \mid x_{1:3}) P ( [A] ∣ x 1 : 3 ) ✓ ✓ ℓ 4 \ell_4 ℓ 4 5 catP ( cat ∣ x 1 : 3 , [A] ) P(\texttt{cat} \mid x_{1:3}, \texttt{[A]}) P ( cat ∣ x 1 : 3 , [A] ) ✓ ✓ ℓ 5 \ell_5 ℓ 5 6 .P ( . ∣ x 1 : 3 , [A]cat ) P(\texttt{.} \mid x_{1:3}, \texttt{[A]}\texttt{cat}) P ( . ∣ x 1 : 3 , [A] cat ) ✓ ✓ ℓ 6 \ell_6 ℓ 6 7 [EOS]P ( [EOS] ∣ x 1 : 3 , [A]cat. ) P(\texttt{[EOS]} \mid x_{1:3}, \texttt{[A]}\texttt{cat}\texttt{.}) P ( [EOS] ∣ x 1 : 3 , [A] cat . ) ✓ ✓ ℓ 7 \ell_7 ℓ 7
J C L M = − 1 7 ( ℓ 1 + ℓ 2 + ℓ 3 + ℓ 4 + ℓ 5 + ℓ 6 + ℓ 7 ) J_{CLM} = -\frac{1}{7}(\ell_1 + \ell_2 + \ell_3 + \ell_4 + \ell_5 + \ell_6 + \ell_7) J C L M = − 7 1 ( ℓ 1 + ℓ 2 + ℓ 3 + ℓ 4 + ℓ 5 + ℓ 6 + ℓ 7 )
J S F T = − 1 4 ( ℓ 4 + ℓ 5 + ℓ 6 + ℓ 7 ) J_{SFT} = -\frac{1}{4}(\ell_4 + \ell_5 + \ell_6 + \ell_7) J S F T = − 4 1 ( ℓ 4 + ℓ 5 + ℓ 6 + ℓ 7 )
假设模型对各 token 的概率估计 (训练初期典型值):
Token 估计概率 P θ P_\theta P θ − log P -\log P − log P [Q]0.12 2.12 翻译:0.18 1.71 猫0.08 2.53 [A]0.45 0.80 cat0.62 0.48 .0.81 0.21 [EOS]0.73 0.31
则:J C L M = 2.12 + 1.71 + 2.53 + 0.80 + 0.48 + 0.21 + 0.31 7 = 8.16 7 ≈ 1.17 J_{CLM} = \frac{2.12+1.71+2.53+0.80+0.48+0.21+0.31}{7} = \frac{8.16}{7} \approx 1.17 J C L M = 7 2.12 + 1.71 + 2.53 + 0.80 + 0.48 + 0.21 + 0.31 = 7 8.16 ≈ 1.17
J S F T = 0.80 + 0.48 + 0.21 + 0.31 4 = 1.80 4 = 0.45 J_{SFT} = \frac{0.80+0.48+0.21+0.31}{4} = \frac{1.80}{4} = 0.45 J S F T = 4 0.80 + 0.48 + 0.21 + 0.31 = 4 1.80 = 0.45
观察 :
SFT 损失数值更小——不是因为模型更好,而是指令 token(概率低)被排除在外。
梯度信号更纯净 :CLM 的梯度有 3 / 7 ≈ 43 % 3/7 \approx 43\% 3/7 ≈ 43% 当指令很长(m ≫ n m \gg n m ≫ n
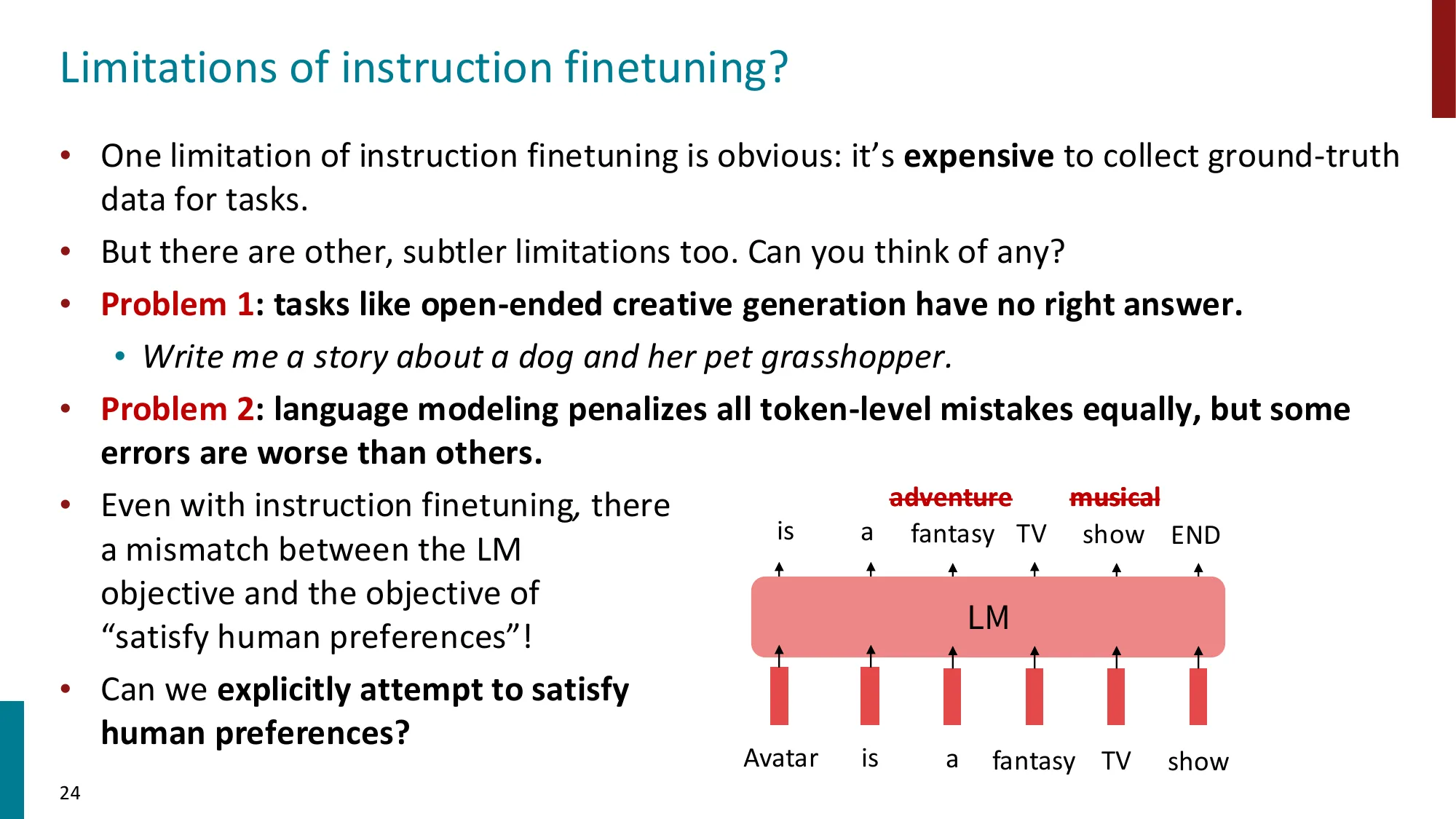
💡 为什么 Instruction Fine-tuning 不能直接用 CLM?
把 LM 想象成一个填空机器 :CLM 训练它在任意位置预测下一个 token。如果用 CLM 做指令微调(对指令+回复全序列计损失),会同时教它:
怎么”续写”一段指令(“将…翻译成…→”)
怎么生成一个回答(“cat.”)
第一件事完全没用——我们不需要模型自己生成指令,我们需要它响应 指令。更糟的是,训练数据里的指令往往比回复长得多(few-shot 场景尤其如此),CLM 会把大量梯度浪费在”学指令的写法”上。
反例 :T5 的预训练用的是 span corruption(类似 CLM 的自监督),但指令微调(Flan-T5)时也会用 response masking——这不是偶然,而是实验验证的最优策略。
更深的视角 :SFT 训练的是条件分布 P ( y ∣ x ; θ ) P(y \mid x; \theta) P ( y ∣ x ; θ ) P ( x , y ; θ ) = P ( x ; θ ) ⋅ P ( y ∣ x ; θ ) P(x, y; \theta) = P(x; \theta) \cdot P(y \mid x; \theta) P ( x , y ; θ ) = P ( x ; θ ) ⋅ P ( y ∣ x ; θ ) P ( x ; θ ) P(x; \theta) P ( x ; θ )
🔢 InstructGPT 数据集规模对比
数据类型 规模 用途 SFT 示范数据 ~13K 指令 训练 SFT 模型 RM 偏好数据 ~33K 偏好对 训练奖励模型 PPO 提示 ~31K 提示 PPO 在线优化 GPT-3 预训练数据 ~300B tokens 预训练(对比)
关键洞察 :SFT 数据量(13K)比预训练数据(3000 亿 token)小约 2300 万倍 ,但效果变化天翻地覆。这说明对齐是一个数据效率极高 的过程——模型的能力已在预训练中存在,SFT 只是”解锁”正确的行为模式。
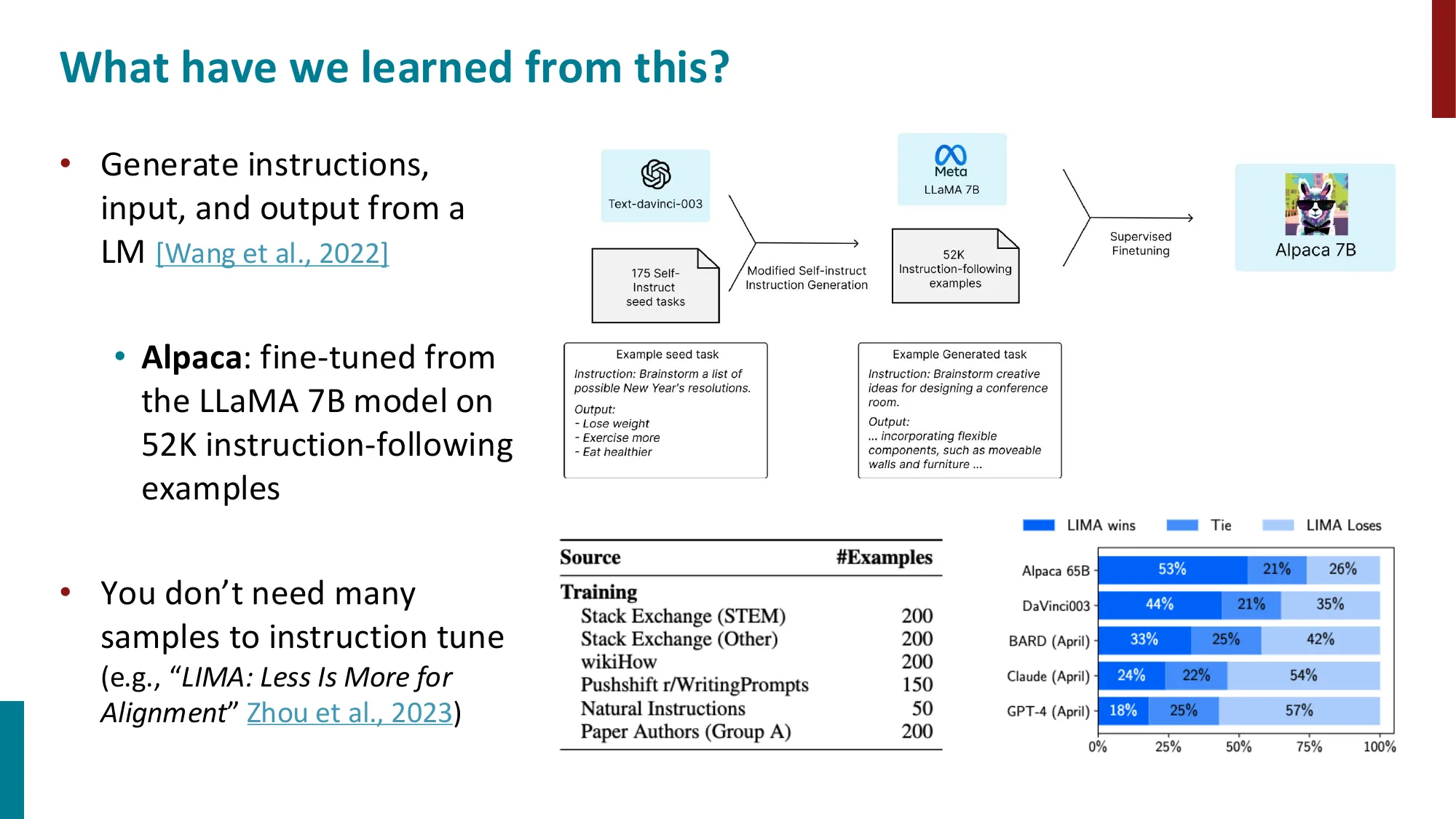
LIMA 论文(Zhou et al., 2023)进一步证明:1000 个高质量 SFT 样本 与 52K 个 Alpaca 样本效果相当甚至更好,彻底颠覆了”SFT 需要大量数据”的认知。
⚠️ 常见误区
误区 :SFT 数据越多越好 → 正确 :数据质量远比数量重要 。低质量示范(如 GPT-3 自动生成的标注)可能引入坏的行为模式。人工精心标注的少量数据(LIMA 的 1000 条)往往优于自动生成的大量数据(Alpaca 的 52K 条)。
误区 :在指令上也计算损失能帮助模型更好地理解指令 → 正确 :在指令上计算损失会让模型同时学”如何生成指令”,这不是目标,且会稀释回复生成的训练信号。正确做法是对指令部分的 token 用 loss mask 屏蔽。
误区 :Instruction FT、SFT、CLM 是同一件事的不同叫法 → 正确 :三者是不同层次的概念(见下方知识关联块)。
🔗 Instruction FT / SFT / CLM 的层次关系
这三个术语经常混用,但含义层次不同:
概念 层次 含义 CLM (Causal Language Modeling)目标函数 对序列所有 token 做 next-token prediction,J = − ∑ t log P ( x t ∣ x < t ) J = -\sum_t \log P(x_t \mid x_{<t}) J = − ∑ t log P ( x t ∣ x < t ) 预训练 ,无监督 SFT (Supervised Fine-Tuning)训练方法 用人工标注的 ( x , y ) (x, y) ( x , y ) y y y Instruction Fine-Tuning 训练策略/范式 在跨任务指令数据 上做 SFT,目标是泛化的指令遵循能力;SFT 是它的实现手段
包含关系 :Instruction FT ⊃ SFT(实现方法)⊃ 类 CLM 的 MLE 目标(但限定 token 范围)
与 CLM 的本质区别 :
CLM 是 self-supervised (数据无需标注,用文本自身做监督信号)
SFT 是 supervised (必须有人工标注的回复 y y y
Instruction FT 还要求数据跨任务多样性,单一任务的 SFT 不算 Instruction FT
常见的混淆场景 :
“用 CLM 做 SFT” = 对全序列(指令+回复)计算损失,是一种实现变体,一般效果不如 response-only SFT
“Flan-T5” = 在 T5 上做 Instruction FT(用的是 encoder-decoder,不是 CLM 架构,但微调目标类似 SFT)
“Chat fine-tuning” = Instruction FT 的对话版本,数据格式变为多轮对话,仍用 SFT 方法
与 L07 关联:L07 预训练 中的 CLM 目标 J C L M J_{CLM} J C L M P ( y ∣ x ) P(y \mid x) P ( y ∣ x )
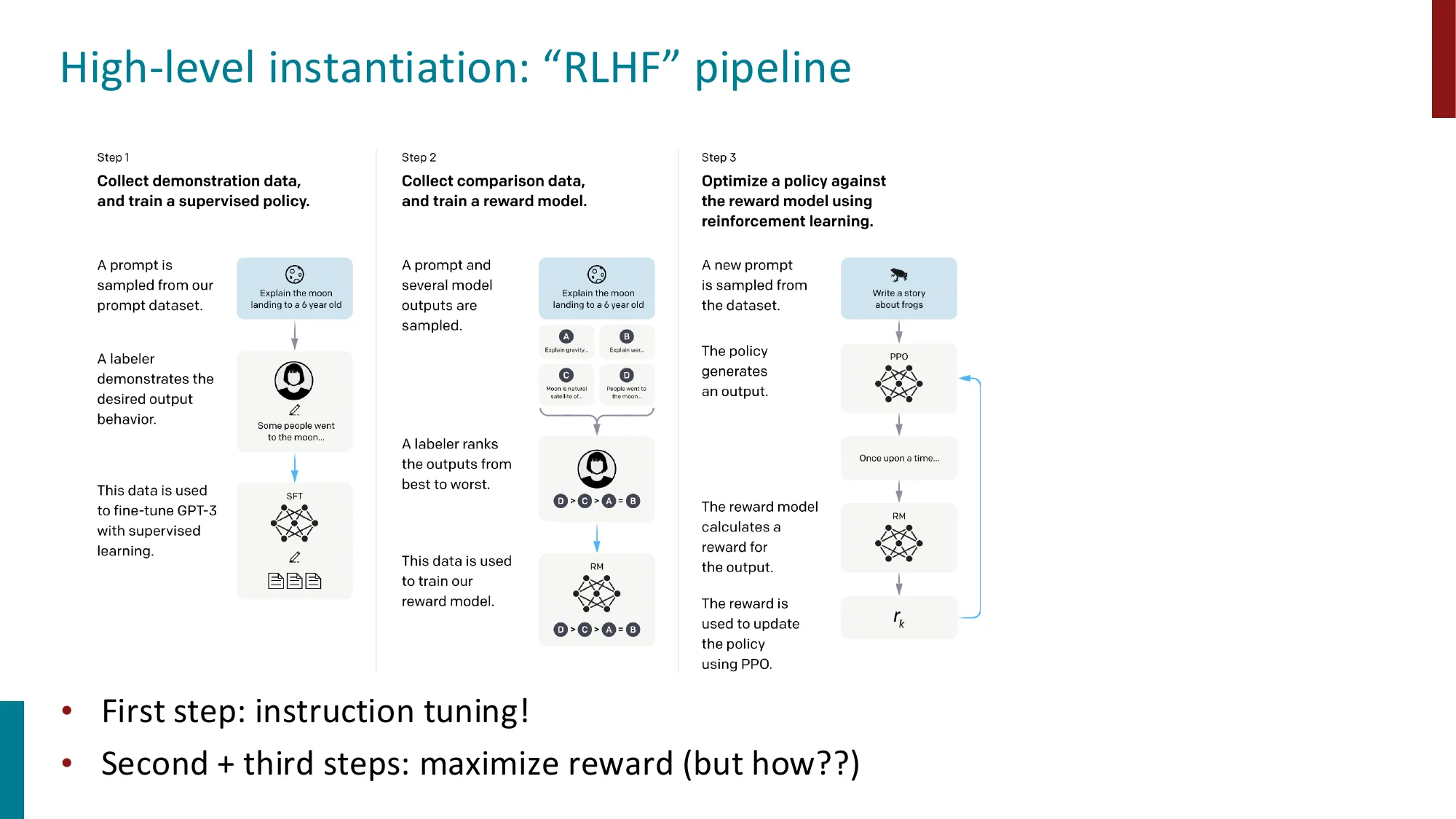
3. RLHF(从人类反馈中强化学习)
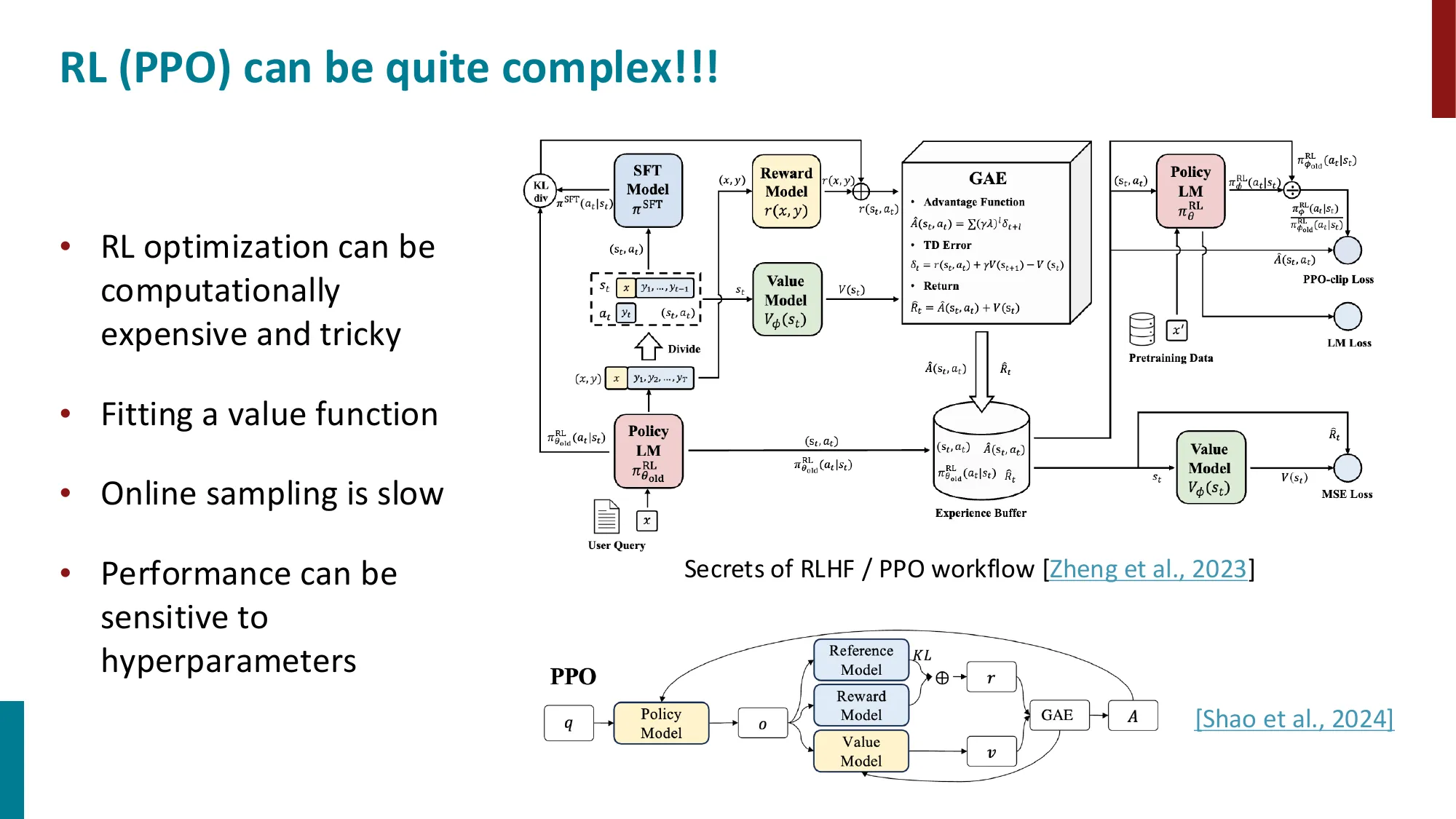
三阶段流水线:SFT -> Reward Model 训练 -> PPO 优化
PPO 的复杂性:需要 Policy Model + Value Model + Reward Model + Reference Model
KL 散度约束防止偏离预训练分布太远
超参数敏感、在线采样慢、训练不稳定
📐 RLHF 完整流程的数学推导
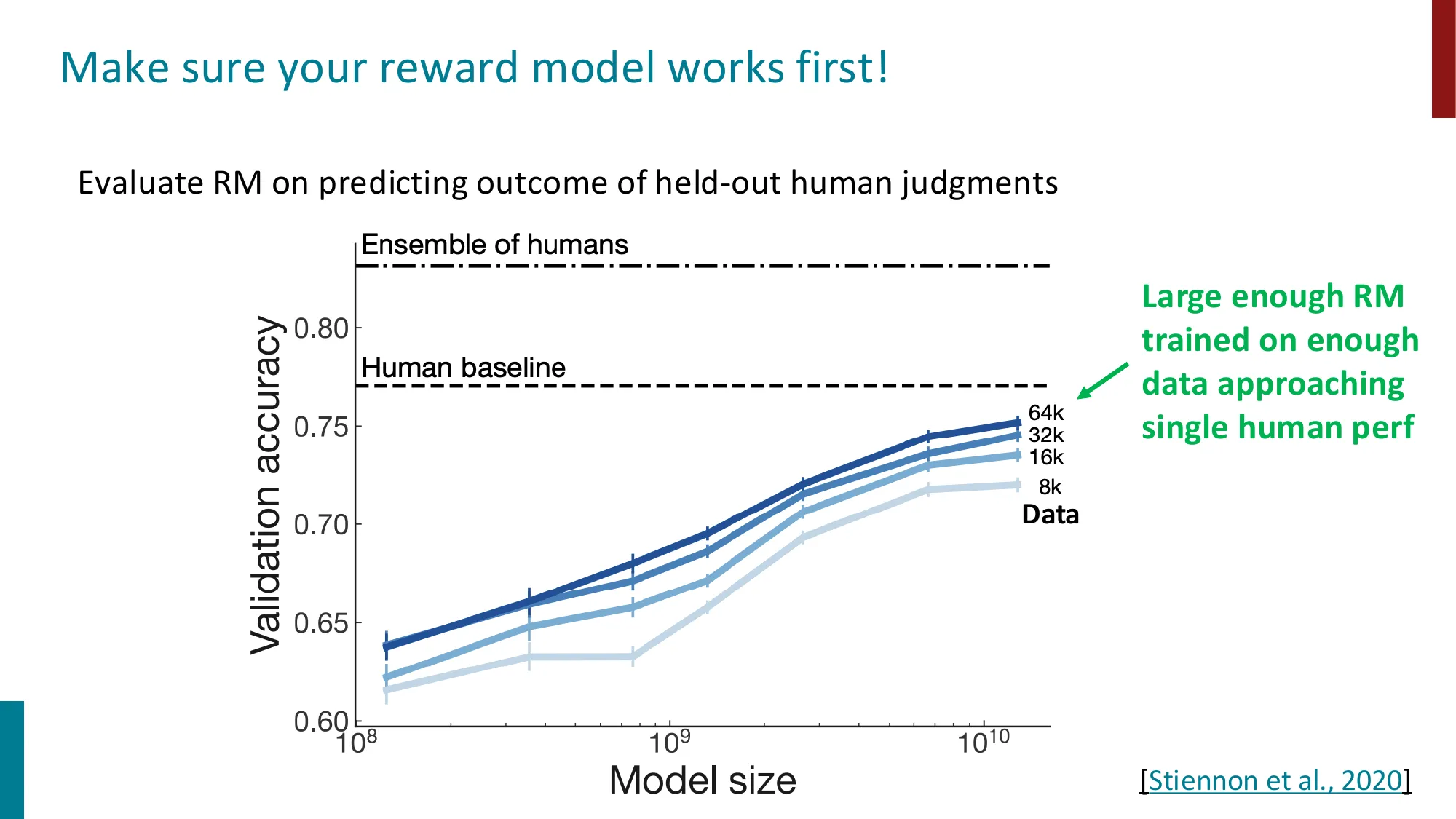
Step 1:训练奖励模型(Reward Model)
收集人类偏好数据:对同一输入 x x x ( y w , y l ) (y_w, y_l) ( y w , y l )
基于 Bradley-Terry 偏好模型 (人类选择 y w y_w y w y l y_l y l
P ( y w ≻ y l ∣ x ) = σ ( r ( x , y w ) − r ( x , y l ) ) P(y_w \succ y_l \mid x) = \sigma(r(x, y_w) - r(x, y_l)) P ( y w ≻ y l ∣ x ) = σ ( r ( x , y w ) − r ( x , y l ))
训练 RM 最大化偏好数据的对数似然(最小化负对数似然):
J R M = − E ( x , y w , y l ) ∼ D p r e f [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] J_{RM} = -\mathbb{E}_{(x, y_w, y_l) \sim D_{pref}} \left[\log \sigma\!\left(r_\phi(x, y_w) - r_\phi(x, y_l)\right)\right] J R M = − E ( x , y w , y l ) ∼ D p r e f [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ]
Step 2:PPO 微调策略
最大化奖励,同时通过 KL 惩罚约束策略不偏离参考模型过远:
J P P O ( θ ) = E x ∼ D , y ∼ π θ ( ⋅ ∣ x ) [ r ϕ ( x , y ) − β ⋅ log π θ ( y ∣ x ) π r e f ( y ∣ x ) ] J_{PPO}(\theta) = \mathbb{E}_{x \sim D,\, y \sim \pi_\theta(\cdot|x)}\!\left[r_\phi(x, y) - \beta \cdot \log\frac{\pi_\theta(y \mid x)}{\pi_{ref}(y \mid x)}\right] J P P O ( θ ) = E x ∼ D , y ∼ π θ ( ⋅ ∣ x ) [ r ϕ ( x , y ) − β ⋅ log π r e f ( y ∣ x ) π θ ( y ∣ x ) ]
其中 β ∈ [ 0.01 , 0.1 ] \beta \in [0.01, 0.1] β ∈ [ 0.01 , 0.1 ] π r e f \pi_{ref} π r e f
完整训练所需的模型数量 :Policy(更新) + Reference(固定) + Reward(固定) + Value(更新)= 4 个模型同时在显存中 ,这是 PPO 内存开销大的根本原因。
📚 已收录至 拓展阅读知识库
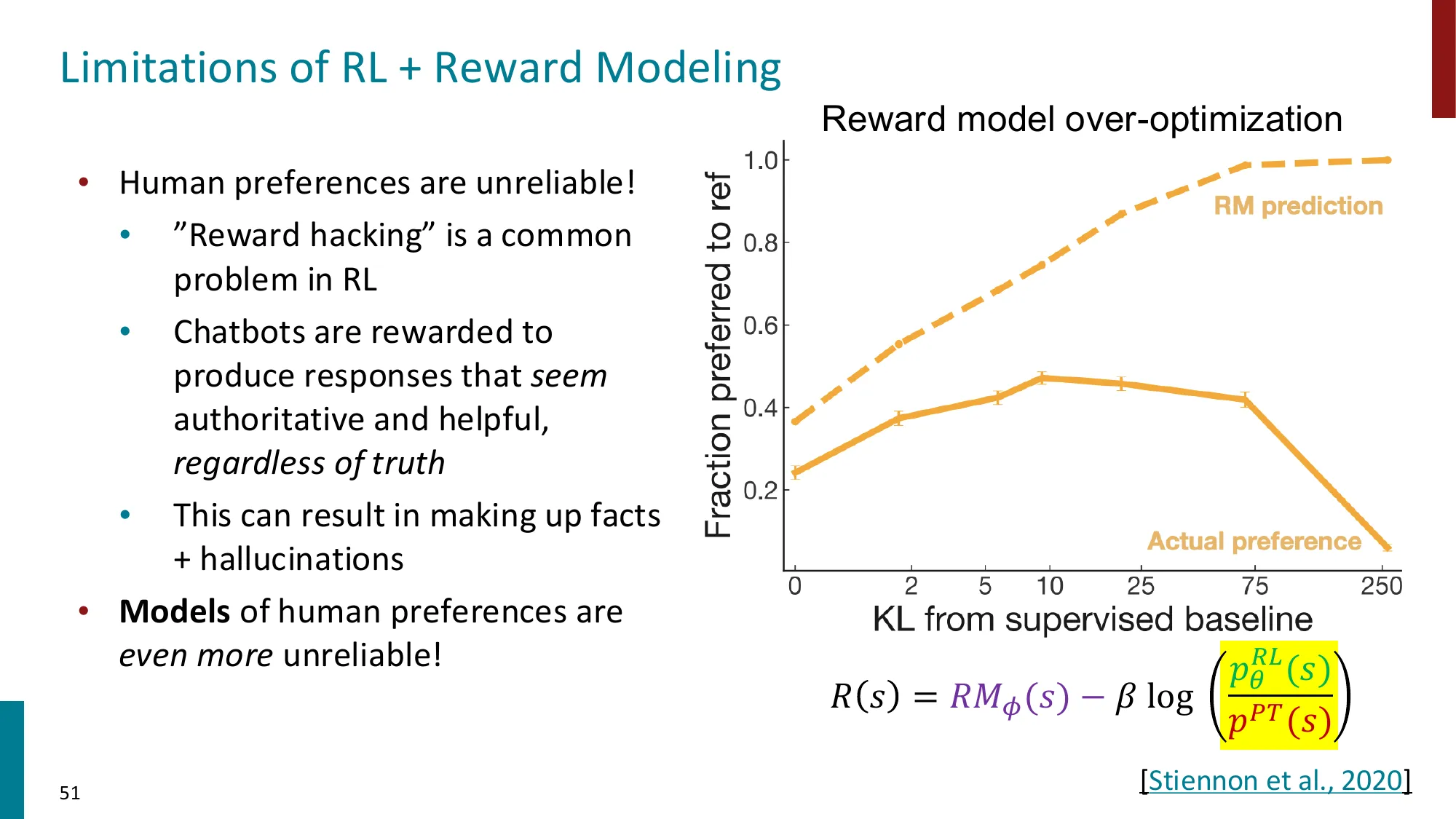
🔢 Reward Hacking 与 KL 约束的数值示例
场景 :奖励模型过度偏好”长且流畅的回复”(常见的 RM 偏差)。
未加 KL 约束时 (β = 0 \beta = 0 β = 0
模型学会无限重复、填充废话以增加长度
某回复:奖励 r = 8.5 r = 8.5 r = 8.5
加 KL 约束后 (β = 0.1 \beta = 0.1 β = 0.1
某冗长回复:r ( x , y ) = 8.5 r(x,y) = 8.5 r ( x , y ) = 8.5 KL = 35.0 \text{KL} = 35.0 KL = 35.0
有效奖励 = 8.5 − 0.1 × 35.0 = 5.0 8.5 - 0.1 \times 35.0 = 5.0 8.5 − 0.1 × 35.0 = 5.0
某精简回复:r ( x , y ) = 7.0 r(x,y) = 7.0 r ( x , y ) = 7.0 KL = 3.0 \text{KL} = 3.0 KL = 3.0
有效奖励 = 7.0 − 0.1 × 3.0 = 6.7 7.0 - 0.1 \times 3.0 = 6.7 7.0 − 0.1 × 3.0 = 6.7
结论 :KL 惩罚使模型倾向于用更接近 SFT 模型行为的方式获得奖励,抑制了极端的 reward hacking。
⚠️ 常见误区
误区 :RLHF 是”在人类偏好上优化” → 正确 :RLHF 是”在奖励模型 上优化”。奖励模型是人类偏好的近似,本身有误差。Goodhart’s Law:“当一个度量指标成为优化目标时,它就不再是好的度量指标”——模型会找到奖励模型的漏洞(如倾向于给更长、语气更确定的回复高分),而不是真正提高有用性。
误区 :KL 约束 β \beta β 正确 :β \beta β β \beta β β \beta β
📐 PPO 算法核心机制:Clip 目标与 LLM Token 级实现
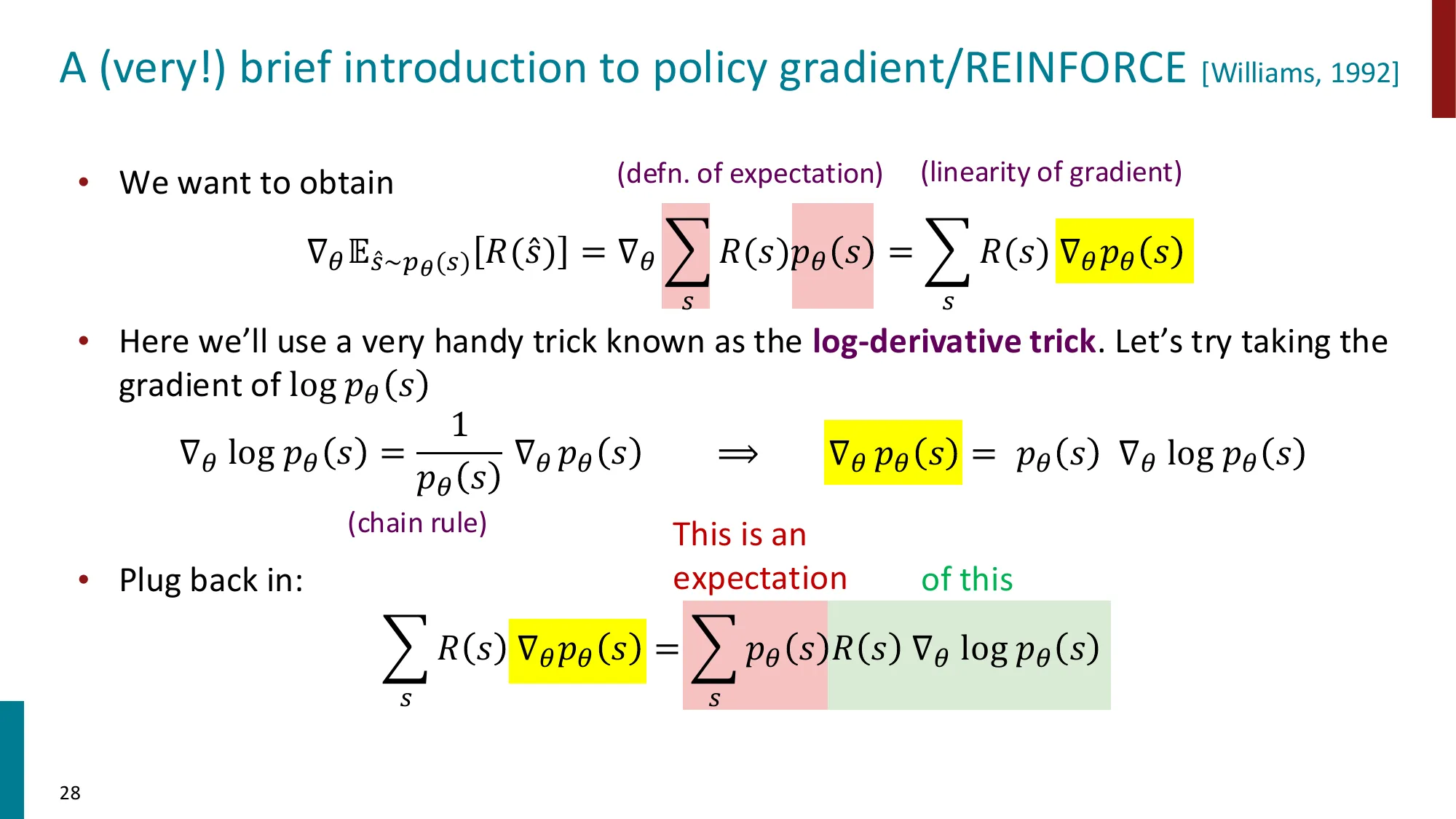
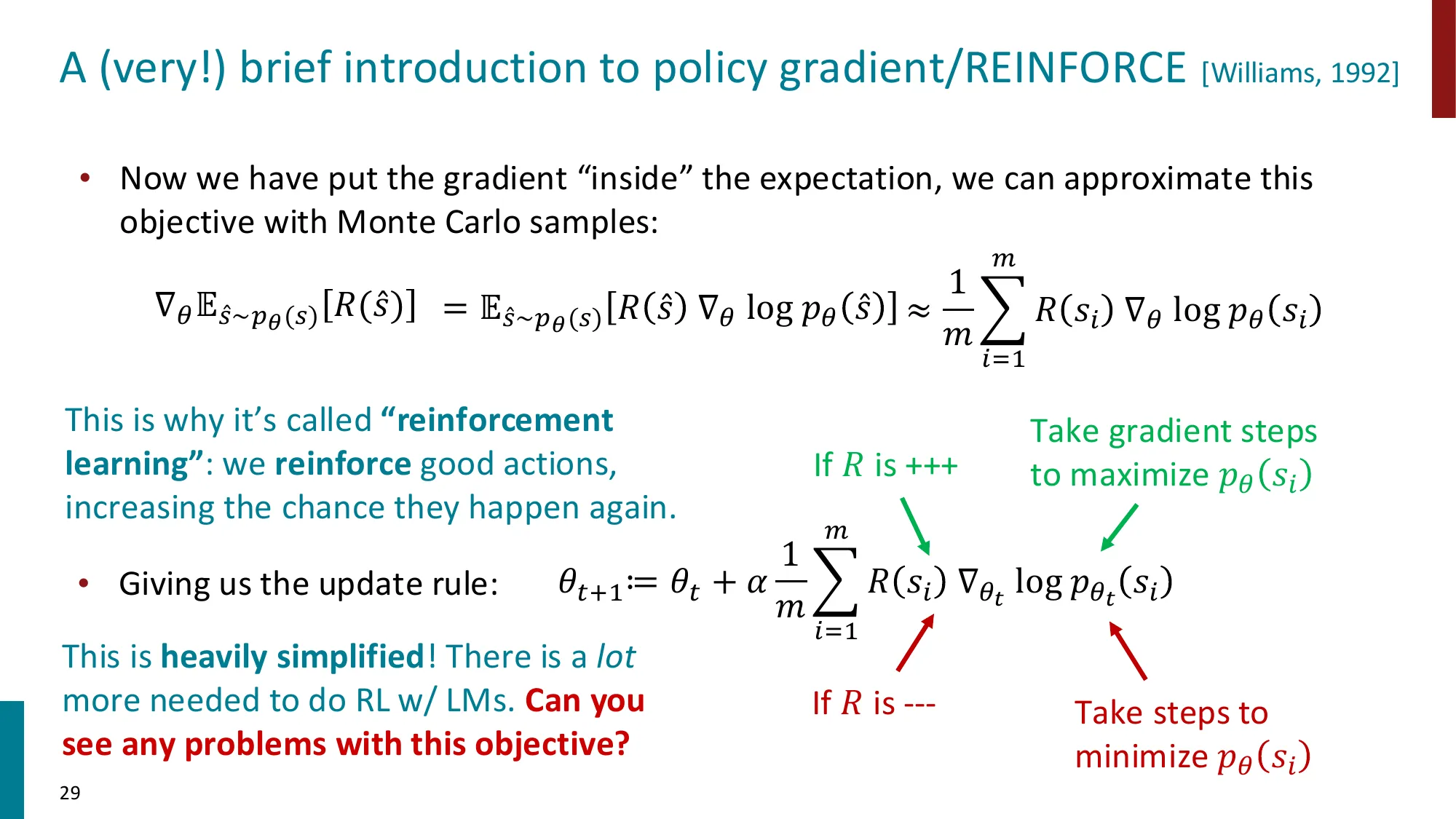
为什么朴素 Policy Gradient(REINFORCE)不够用?
REINFORCE 梯度:∇ θ J = E y ∼ π θ [ ∇ θ log π θ ( y ∣ x ) ⋅ A ( x , y ) ] \nabla_\theta J = \mathbb{E}_{y \sim \pi_\theta}\!\left[\nabla_\theta \log \pi_\theta(y|x) \cdot A(x,y)\right] ∇ θ J = E y ∼ π θ [ ∇ θ log π θ ( y ∣ x ) ⋅ A ( x , y ) ]
当一步更新过大时,π θ \pi_\theta π θ π o l d \pi_{old} π o l d π θ π o l d \frac{\pi_\theta}{\pi_{old}} π o l d π θ
PPO 的解法:Clip 重要性权重
定义 token t t t
r t ( θ ) = π θ ( y t ∣ x , y < t ) π o l d ( y t ∣ x , y < t ) r_t(\theta) = \frac{\pi_\theta(y_t \mid x, y_{<t})}{\pi_{old}(y_t \mid x, y_{<t})} r t ( θ ) = π o l d ( y t ∣ x , y < t ) π θ ( y t ∣ x , y < t )
PPO Clip 损失(ϵ = 0.2 \epsilon = 0.2 ϵ = 0.2
L C L I P ( θ ) = E t [ min ( r t ( θ ) ⋅ A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A t ) ] L^{CLIP}(\theta) = \mathbb{E}_t\!\left[\min\!\left(r_t(\theta)\cdot A_t,\;\; \text{clip}(r_t(\theta),\, 1-\epsilon,\, 1+\epsilon)\cdot A_t\right)\right] L C L I P ( θ ) = E t [ min ( r t ( θ ) ⋅ A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A t ) ]
Clip 行为直觉 :
情形 r t r_t r t clip 作用 A t > 0 A_t > 0 A t > 0 r t > 1 + ϵ r_t > 1+\epsilon r t > 1 + ϵ 已过度增加 截断,禁止继续提高好动作概率 A t < 0 A_t < 0 A t < 0 r t < 1 − ϵ r_t < 1-\epsilon r t < 1 − ϵ 已过度降低 截断,禁止继续打压坏动作概率
本质 :min 函数确保目标函数是悲观下界——只允许对策略有利的情况”按实际”计,对策略不利的情况”按被截断的保守值”计。
LLM 后训练中的 Token 级 MDP 映射
RL 概念 LLM 中的对应 状态 s t s_t s t 已生成序列 ( x , y 1 , … , y t − 1 ) (x, y_1, \ldots, y_{t-1}) ( x , y 1 , … , y t − 1 ) 动作 a t a_t a t 下一个 token y t y_t y t 终末奖励 RM 对完整回复评分 r ϕ ( x , y 1 : T ) r_\phi(x, y_{1:T}) r ϕ ( x , y 1 : T ) 中间惩罚 Per-token KL:− β log π θ ( y t ) π r e f ( y t ) -\beta \log\frac{\pi_\theta(y_t)}{\pi_{ref}(y_t)} − β log π r e f ( y t ) π θ ( y t )
完整的 token 级奖励信号:
r ~ t = { r ϕ ( x , y 1 : T ) − β log π θ ( y T ∣ s T ) π r e f ( y T ∣ s T ) t = T − β log π θ ( y t ∣ s t ) π r e f ( y t ∣ s t ) t < T \tilde{r}_t = \begin{cases} r_\phi(x, y_{1:T}) - \beta \log\dfrac{\pi_\theta(y_T|s_T)}{\pi_{ref}(y_T|s_T)} & t = T \\ -\beta \log\dfrac{\pi_\theta(y_t|s_t)}{\pi_{ref}(y_t|s_t)} & t < T \end{cases} r ~ t = ⎩ ⎨ ⎧ r ϕ ( x , y 1 : T ) − β log π r e f ( y T ∣ s T ) π θ ( y T ∣ s T ) − β log π r e f ( y t ∣ s t ) π θ ( y t ∣ s t ) t = T t < T
优势函数用 GAE(广义优势估计)从 Value Network 计算:A t G A E = ∑ k ≥ 0 ( γ λ ) k δ t + k A_t^{GAE} = \sum_{k \geq 0}(\gamma\lambda)^k \delta_{t+k} A t G A E = ∑ k ≥ 0 ( γ λ ) k δ t + k δ t = r ~ t + γ V ϕ ( s t + 1 ) − V ϕ ( s t ) \delta_t = \tilde{r}_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t) δ t = r ~ t + γ V ϕ ( s t + 1 ) − V ϕ ( s t )
RLHF-PPO 的 4 模型架构
模型 是否更新梯度 作用 Policy π θ \pi_\theta π θ ✓ 生成回复(正在对齐的模型) Value Network V ϕ V_\phi V ϕ ✓ 估计每 token 期望回报(Critic) Reward Model r ϕ r_\phi r ϕ ✗ 对完整序列打分 Reference Policy π r e f \pi_{ref} π r e f ✗ KL 惩罚基准(SFT 模型)
Value Network 与 Policy 等大 且需要梯度,这是 PPO 显存开销是 DPO 两倍的根本原因。GRPO 的核心创新就是消除它。
📚 已收录至 拓展阅读知识库
💡 RLHF / PPO / DPO / GRPO 全景层次——一次讲清
RLHF(框架): 用人类偏好数据训练 RM,再用 RL 最大化 RM 奖励 │ ├── PPO(RLHF 的标准 RL 实现) │ 需要:Policy + Value + RM + Reference(4 模型) │ 在线:每步采样新回复 → 评分 → 更新 │ 优势:能探索未见过的策略分布 │ 劣势:4 倍显存、超参敏感、训练不稳定 │ ├── GRPO(PPO 的轻量变体,去掉 Value Network) │ 需要:Policy + RM + Reference(3 模型) │ 用组内统计代替 Critic,适合稀疏自动评分任务 │ 典型用途:DeepSeek-R1 数学/代码推理训练 │ └── DPO(RLHF 目标的数学重参数化,绕过 RL) 需要:Policy + Reference(2 模型) 离线:直接在静态偏好数据集上 MLE 优势:简单稳定,无需 RM 训练 代价:无法在线探索,遇到分布外样本容易失效 三条关键认知 :
RLHF ≠ PPO:PPO 是其中一种 RL 算法选择,可替换为 REINFORCE、A2C、GRPO
DPO 是 RLHF 的数学等价离线版 ,有不同 tradeoff,而非”升级版”
三者共享底层假设:Bradley-Terry 偏好模型 P ( y w ≻ y l ∣ x ) = σ ( r w − r l ) P(y_w \succ y_l \mid x) = \sigma(r_w - r_l) P ( y w ≻ y l ∣ x ) = σ ( r w − r l )
🔗 知识关联
REINFORCE vs PPO 的稳定性差距 :PPO 的 Clip 约束等价于信任域优化(Trust Region),TRPO 的近似实现DPO 如何从此处 PPO 目标推导 :见下方 Section 5 完整推导GRPO 如何消除 Value Network :见 Section 6 PPO 的 4 模型架构 对 GPU 集群的实际影响(需要 4 路模型并行)已收录至 RLHF 拓展阅读
4. InstructGPT 和 ChatGPT
InstructGPT(Ouyang et al., 2022):首次大规模应用 RLHF
从补全模型到对话助手的关键转变
📐 InstructGPT 三阶段训练流水线
阶段 1 — SFT :在人工示范数据上监督微调,得到 π S F T \pi_{SFT} π S F T
θ S F T = arg max θ ∑ ( x , y ) ∈ D S F T log P θ ( y ∣ x ) \theta_{SFT} = \arg\max_\theta \sum_{(x,y)\in D_{SFT}} \log P_\theta(y \mid x) θ S F T = arg max θ ∑ ( x , y ) ∈ D S F T log P θ ( y ∣ x )
阶段 2 — RM 训练 :学习人类偏好排序,得到奖励函数 r ϕ ( x , y ) r_\phi(x, y) r ϕ ( x , y )
ϕ ∗ = arg min ϕ − E ( x , y w , y l ) [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] \phi^* = \arg\min_\phi -\mathbb{E}_{(x,y_w,y_l)}\left[\log\sigma(r_\phi(x,y_w) - r_\phi(x,y_l))\right] ϕ ∗ = arg min ϕ − E ( x , y w , y l ) [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l )) ]
阶段 3 — PPO :在 RM 的奖励下优化策略,约束不偏离 π S F T \pi_{SFT} π S F T
θ ∗ = arg max θ E y ∼ π θ [ r ϕ ( x , y ) − β ⋅ K L ( π θ ∥ π S F T ) ] \theta^* = \arg\max_\theta \mathbb{E}_{y \sim \pi_\theta}\left[r_\phi(x,y) - \beta \cdot KL(\pi_\theta \| \pi_{SFT})\right] θ ∗ = arg max θ E y ∼ π θ [ r ϕ ( x , y ) − β ⋅ K L ( π θ ∥ π S F T ) ]
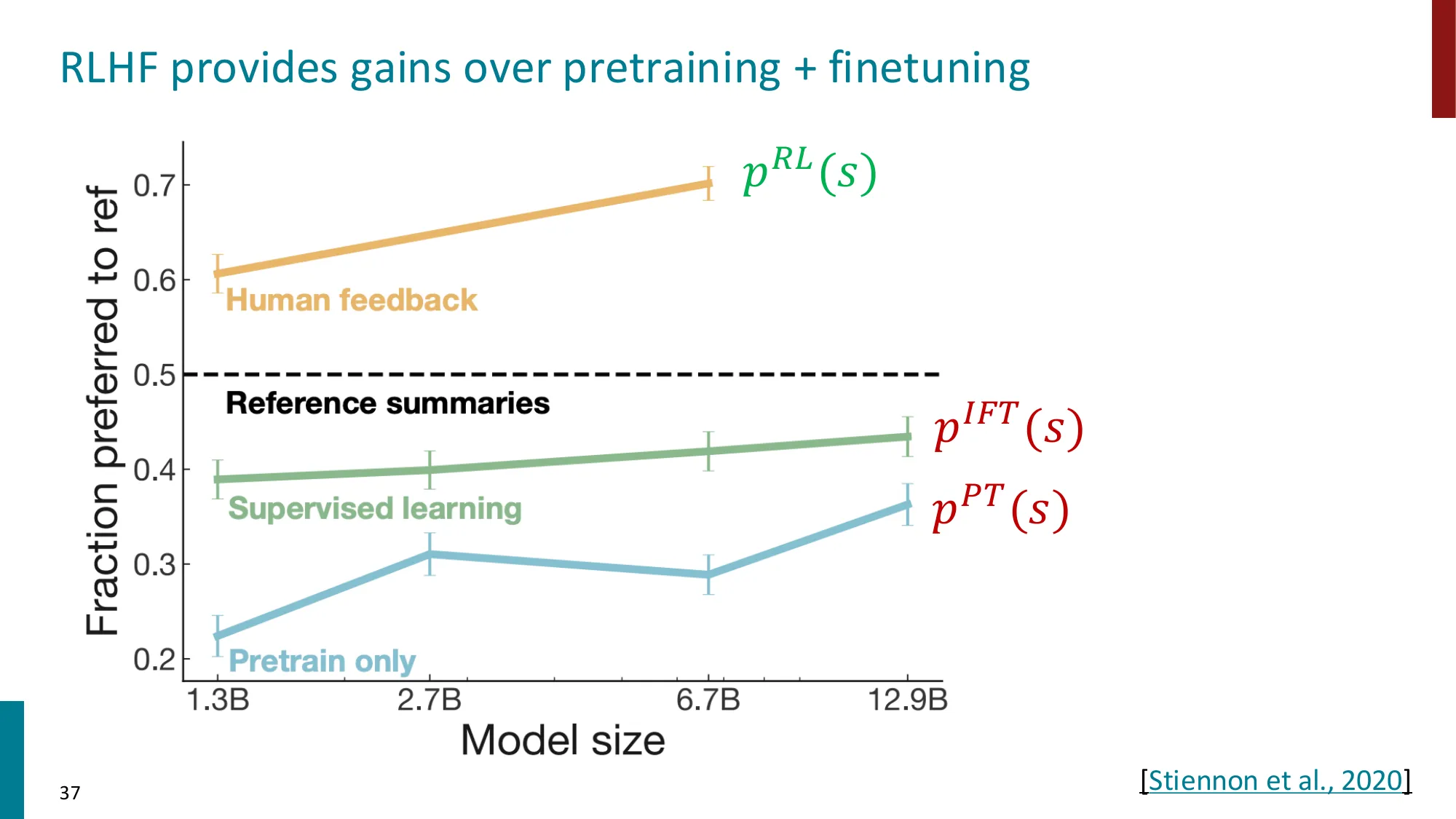
关键结论(InstructGPT 论文原文数字) :
在人类评测中,1.3B 参数 InstructGPT 优于 175B 参数 GPT-3 (85% 的评测者偏好 InstructGPT 输出)。参数量相差 134 倍 ,但对齐使小模型胜出——说明行为对齐的收益远超单纯的模型规模 。
📚 已收录至 拓展阅读知识库
🔢 InstructGPT 的人类评测结果
对比组 偏好 InstructGPT 的比例 InstructGPT-1.3B vs GPT-3-175B 85% InstructGPT-175B vs GPT-3-175B ~85% InstructGPT-175B vs RLHF without SFT 71%
同等参数量的 InstructGPT-175B 与 GPT-3-175B 对比,仍有 85% 偏好率,说明 RLHF 而非模型规模是主要贡献。
⚠️ 常见误区
误区 :ChatGPT = InstructGPT → 正确 :ChatGPT 在 InstructGPT 框架基础上加入了多轮对话历史建模 ,将整个对话 history 作为 context 输入。此外,ChatGPT 针对安全性有额外的 RLHF 阶段。OpenAI 从未公开 ChatGPT 的完整技术细节。
误区 :RLHF 之后模型完全”听话”,不会产生有害输出 → 正确 :RLHF 显著降低了有害输出,但无法完全消除——通过 jailbreak(越狱 prompt)、角色扮演等方法仍可绕过安全训练。这是对抗式 AI 安全研究的核心问题。
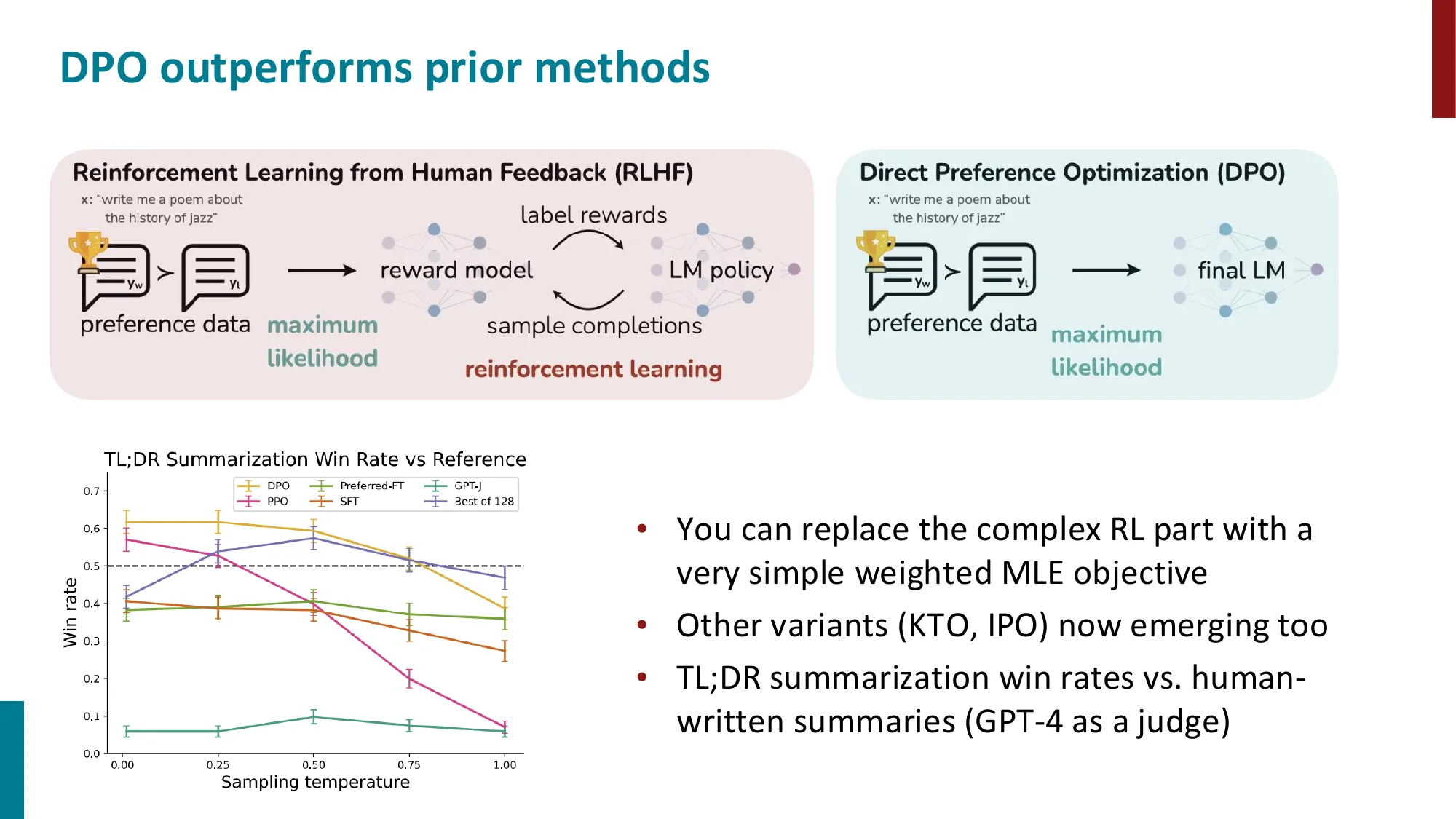
5. DPO(Direct Preference Optimization)
核心洞察 :RLHF 目标的闭式解可将 reward model 用 policy 的对数概率比表示R M θ ( x , y ^ ) = β log p θ R L ( y ^ ∣ x ) p P T ( y ^ ∣ x ) + β log Z ( x ) RM_\theta(x, \hat{y}) = \beta \log \frac{p_\theta^{RL}(\hat{y}|x)}{p^{PT}(\hat{y}|x)} + \beta \log Z(x) R M θ ( x , y ^ ) = β log p P T ( y ^ ∣ x ) p θ R L ( y ^ ∣ x ) + β log Z ( x ) DPO 损失:J D P O ( θ ) = − E [ log σ ( R M θ ( x , y w ) − R M θ ( x , y l ) ) ] J_{DPO}(\theta) = -\mathbb{E}[\log \sigma(RM_\theta(x, y_w) - RM_\theta(x, y_l))] J D P O ( θ ) = − E [ log σ ( R M θ ( x , y w ) − R M θ ( x , y l ))]
Z(x) 在损失中消去 (因为只测量 reward 差异)用简单的加权 MLE 替代复杂的 RL
开源 LLM 几乎都用 DPO(HuggingFace 排行榜验证)
变体:KTO、IPO 等
📐 DPO 从 RLHF 目标的完整推导
Step 1:RLHF 目标的最优解
RLHF 最大化(对每个输入 x x x y y y
max π θ E y ∼ π θ [ r ( x , y ) ] − β ⋅ K L [ π θ ( y ∣ x ) ∥ π r e f ( y ∣ x ) ] \max_{\pi_\theta} \mathbb{E}_{y \sim \pi_\theta}\left[r(x,y)\right] - \beta \cdot KL\left[\pi_\theta(y|x) \| \pi_{ref}(y|x)\right] max π θ E y ∼ π θ [ r ( x , y ) ] − β ⋅ K L [ π θ ( y ∣ x ) ∥ π r e f ( y ∣ x ) ]
对此目标关于 π θ \pi_\theta π θ 闭式最优策略 :
π ∗ ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ( r ( x , y ) β ) \pi^*(y|x) = \frac{1}{Z(x)}\, \pi_{ref}(y|x)\exp\!\left(\frac{r(x,y)}{\beta}\right) π ∗ ( y ∣ x ) = Z ( x ) 1 π r e f ( y ∣ x ) exp ( β r ( x , y ) )
其中 Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( r ( x , y ) β ) Z(x) = \sum_y \pi_{ref}(y|x)\exp\!\left(\frac{r(x,y)}{\beta}\right) Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( β r ( x , y ) )
Step 2:反解奖励函数
由上式取对数,用 π ∗ \pi^* π ∗ r r r
r ( x , y ) = β log π ∗ ( y ∣ x ) π r e f ( y ∣ x ) + β log Z ( x ) r(x,y) = \beta \log\frac{\pi^*(y|x)}{\pi_{ref}(y|x)} + \beta \log Z(x) r ( x , y ) = β log π r e f ( y ∣ x ) π ∗ ( y ∣ x ) + β log Z ( x )
Step 3:代入 Bradley-Terry 偏好模型
P ( y w ≻ y l ∣ x ) = σ ( r ( x , y w ) − r ( x , y l ) ) P(y_w \succ y_l \mid x) = \sigma(r(x,y_w) - r(x,y_l)) P ( y w ≻ y l ∣ x ) = σ ( r ( x , y w ) − r ( x , y l ))
代入 r r r β log Z ( x ) \beta \log Z(x) β log Z ( x )
P ( y w ≻ y l ∣ x ) = σ ( β log π ∗ ( y w ∣ x ) π r e f ( y w ∣ x ) − β log π ∗ ( y l ∣ x ) π r e f ( y l ∣ x ) ) P(y_w \succ y_l \mid x) = \sigma\!\left(\beta \log\frac{\pi^*(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log\frac{\pi^*(y_l|x)}{\pi_{ref}(y_l|x)}\right) P ( y w ≻ y l ∣ x ) = σ ( β log π r e f ( y w ∣ x ) π ∗ ( y w ∣ x ) − β log π r e f ( y l ∣ x ) π ∗ ( y l ∣ x ) )
Step 4:DPO 损失 (用 π θ \pi_\theta π θ π ∗ \pi^* π ∗
J D P O ( θ ) = − E ( x , y w , y l ) [ log σ ( β log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) − β log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ) ] J_{DPO}(\theta) = -\mathbb{E}_{(x,y_w,y_l)}\!\left[\log\sigma\!\left(\beta\log\frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta\log\frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)}\right)\right] J D P O ( θ ) = − E ( x , y w , y l ) [ log σ ( β log π r e f ( y w ∣ x ) π θ ( y w ∣ x ) − β log π r e f ( y l ∣ x ) π θ ( y l ∣ x ) ) ]
结论 :DPO 完全绕过了奖励模型的训练,直接用偏好数据优化策略,且数学上等价于 RLHF 的最优解。
📚 已收录至 拓展阅读知识库
🔢 DPO vs RLHF 工程复杂度对比
维度 RLHF (PPO) DPO 需要的模型数量 4(Policy + Value + RM + Ref) 2(Policy + Ref) 是否需要在线采样 是(每步采样新回复) 否(离线偏好数据) 训练稳定性 较差(PPO 对超参敏感) 较好(标准 MLE 梯度) GPU 显存需求 极高(4 模型同时加载) 适中(2 模型) 是否需要 RM 单独训练 是 否
典型实践 :Llama 2/3、Mistral、Qwen 等主流开源模型的偏好对齐阶段均采用 DPO 或其变体(SimPO、KTO)。
⚠️ 常见误区
误区 :DPO 总是优于 RLHF → 正确 :DPO 是离线 方法——它只能从固定的偏好数据集中学习,而 PPO 可以通过在线与奖励模型交互动态生成新训练数据 (探索未见过的输出)。对于分布外的困难指令,DPO 可能不如 PPO 的在线 RL 有效。近期 Online-DPO 和 DAPO 等方法试图结合两者优势。
误区 :DPO 推导中 Z ( x ) Z(x) Z ( x ) 正确 :Z ( x ) Z(x) Z ( x ) π ∗ \pi^* π ∗
💡 DPO 在做什么?隐式奖励与梯度方向
DPO 损失看起来像 binary cross-entropy,但隐藏着一个精妙的结构。将损失改写:
J D P O ( θ ) = − E [ log σ ( β log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) ⏟ r ^ θ ( x , y w ) :隐式奖励 − β log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ⏟ r ^ θ ( x , y l ) :隐式奖励 ) ] J_{DPO}(\theta) = -\mathbb{E}\!\left[\log \sigma\!\left(\underbrace{\beta \log\frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)}}_{\hat{r}_\theta(x,y_w)\text{:隐式奖励}} - \underbrace{\beta \log\frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)}}_{\hat{r}_\theta(x,y_l)\text{:隐式奖励}}\right)\right] J D P O ( θ ) = − E log σ r ^ θ ( x , y w ) :隐式奖励 β log π r e f ( y w ∣ x ) π θ ( y w ∣ x ) − r ^ θ ( x , y l ) :隐式奖励 β log π r e f ( y l ∣ x ) π θ ( y l ∣ x )
隐式奖励 r ^ θ ( x , y ) = β log π θ ( y ∣ x ) π r e f ( y ∣ x ) \hat{r}_\theta(x,y) = \beta \log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} r ^ θ ( x , y ) = β log π r e f ( y ∣ x ) π θ ( y ∣ x )
r ^ > 0 \hat{r} > 0 r ^ > 0 y y y y y y r ^ < 0 \hat{r} < 0 r ^ < 0 y y y y y y DPO 的策略自身就是奖励模型 ——无需单独训练 RM!
梯度自适应权重 :
对 π θ ( y w ∣ x ) \pi_\theta(y_w|x) π θ ( y w ∣ x ) σ ( r ^ l − r ^ w ) \sigma(\hat{r}_l - \hat{r}_w) σ ( r ^ l − r ^ w )
∇ J D P O ∝ − σ ( r ^ l − r ^ w ) ⋅ [ ∇ log π θ ( y w ∣ x ) − ∇ log π θ ( y l ∣ x ) ] \nabla J_{DPO} \propto -\sigma(\hat{r}_l - \hat{r}_w) \cdot \left[\nabla \log \pi_\theta(y_w|x) - \nabla \log \pi_\theta(y_l|x)\right] ∇ J D P O ∝ − σ ( r ^ l − r ^ w ) ⋅ [ ∇ log π θ ( y w ∣ x ) − ∇ log π θ ( y l ∣ x ) ]
当模型还认为坏回复更好(r ^ l > r ^ w \hat{r}_l > \hat{r}_w r ^ l > r ^ w
当模型已学好(r ^ w ≫ r ^ l \hat{r}_w \gg \hat{r}_l r ^ w ≫ r ^ l σ \sigma σ
DPO 内置自适应学习速率 ——已正确分类的样本自动获得小权重
🔢 DPO 单步训练完整数值演示
设定 :β = 0.5 \beta = 0.5 β = 0.5 ( y w , y l ) (y_w, y_l) ( y w , y l )
初始状态 (训练前,模型尚未对齐):
输出 π r e f ( y ∥ x ) \pi_{ref}(y\|x) π r e f ( y ∥ x ) π θ ( y ∥ x ) \pi_\theta(y\|x) π θ ( y ∥ x ) 隐式奖励 r ^ = 0.5 log π θ π r e f \hat{r} = 0.5\log\frac{\pi_\theta}{\pi_{ref}} r ^ = 0.5 log π r e f π θ y w y_w y w 0.30 0.25 0.5 × log ( 0.833 ) = − 0.092 0.5 \times \log(0.833) = -0.092 0.5 × log ( 0.833 ) = − 0.092 y l y_l y l 0.20 0.30 0.5 × log ( 1.500 ) = + 0.203 0.5 \times \log(1.500) = +0.203 0.5 × log ( 1.500 ) = + 0.203
当前 r ^ ( y l ) > r ^ ( y w ) \hat{r}(y_l) > \hat{r}(y_w) r ^ ( y l ) > r ^ ( y w )
DPO 损失 :
J = − log σ ( r ^ w − r ^ l ) = − log σ ( − 0.092 − 0.203 ) = − log σ ( − 0.295 ) = − log ( 0.427 ) = 0.851 J = -\log\sigma(\hat{r}_w - \hat{r}_l) = -\log\sigma(-0.092 - 0.203) = -\log\sigma(-0.295) = -\log(0.427) = 0.851 J = − log σ ( r ^ w − r ^ l ) = − log σ ( − 0.092 − 0.203 ) = − log σ ( − 0.295 ) = − log ( 0.427 ) = 0.851
梯度权重 (惩罚力度):σ ( r ^ l − r ^ w ) = σ ( 0.295 ) = 0.573 \sigma(\hat{r}_l - \hat{r}_w) = \sigma(0.295) = 0.573 σ ( r ^ l − r ^ w ) = σ ( 0.295 ) = 0.573
训练后期 (收敛时):
输出 π θ ( y ∥ x ) \pi_\theta(y\|x) π θ ( y ∥ x ) 隐式奖励 y w y_w y w 0.42 + 0.167 +0.167 + 0.167 y l y_l y l 0.14 − 0.178 -0.178 − 0.178
r ^ ( y w ) ≫ r ^ ( y l ) \hat{r}(y_w) \gg \hat{r}(y_l) r ^ ( y w ) ≫ r ^ ( y l ) σ ( − 0.345 ) ≈ 0.41 \sigma(-0.345) \approx 0.41 σ ( − 0.345 ) ≈ 0.41
一句话总结 :DPO 同时在两个方向驱动策略:拉高好回复的相对概率 ,压低坏回复的相对概率 ,两者权重共享同一个 sigmoid 系数(自适应平衡)。
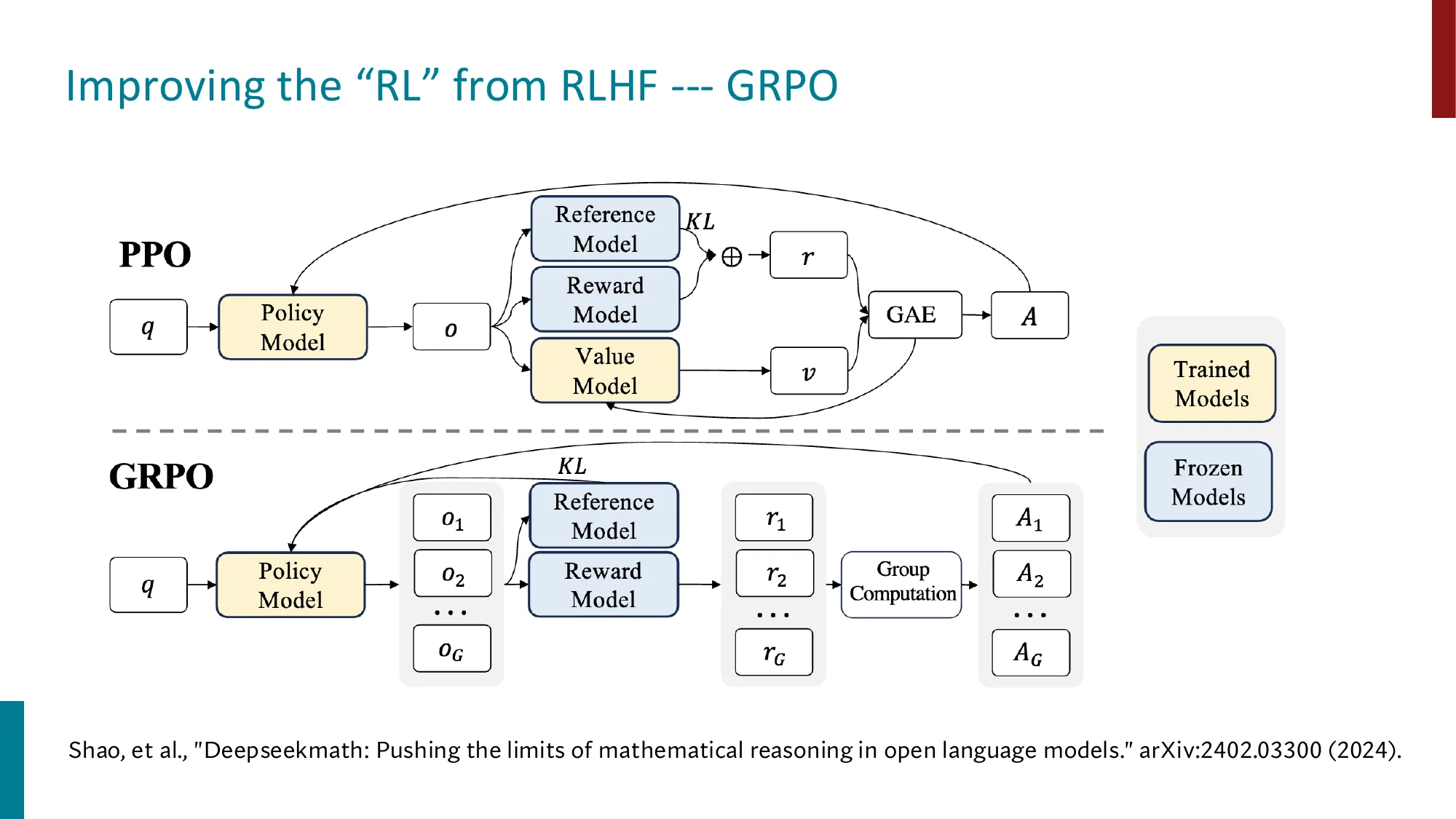
6. GRPO(Group Relative Policy Optimization)
Slide 58
来自 DeepSeekMath(Shao et al., 2024)
相比 PPO 移除了 Value Model,用 group computation 估计 advantage
更简单的训练架构
📐 GRPO 目标函数推导
核心思想 :PPO 需要一个单独的 Value Network(价值网络)来估计优势函数(Advantage)A ( x , y ) A(x,y) A ( x , y ) 组内相对奖励 代替价值网络。
Step 1:组内采样
对同一输入 x x x G G G { y 1 , … , y G } \{y_1, \ldots, y_G\} { y 1 , … , y G } { r 1 , … , r G } \{r_1, \ldots, r_G\} { r 1 , … , r G }
Step 2:优势估计(组内归一化)
A i = r i − μ r σ r , μ r = 1 G ∑ j = 1 G r j , σ r = 1 G ∑ j = 1 G ( r j − μ r ) 2 A_i = \frac{r_i - \mu_r}{\sigma_r}, \quad \mu_r = \frac{1}{G}\sum_{j=1}^G r_j, \quad \sigma_r = \sqrt{\frac{1}{G}\sum_{j=1}^G (r_j - \mu_r)^2} A i = σ r r i − μ r , μ r = G 1 ∑ j = 1 G r j , σ r = G 1 ∑ j = 1 G ( r j − μ r ) 2
A i > 0 A_i > 0 A i > 0 i i i A i < 0 A_i < 0 A i < 0
Step 3:GRPO 目标(结合 PPO clip 技巧)
J G R P O ( θ ) = E x , { y i } [ 1 G ∑ i = 1 G min ( π θ ( y i ∣ x ) π o l d ( y i ∣ x ) A i , clip ( π θ ( y i ∣ x ) π o l d ( y i ∣ x ) , 1 − ϵ , 1 + ϵ ) A i ) − β D K L ( π θ ∥ π r e f ) ] J_{GRPO}(\theta) = \mathbb{E}_{x,\{y_i\}}\!\left[\frac{1}{G}\sum_{i=1}^G \min\!\left(\frac{\pi_\theta(y_i|x)}{\pi_{old}(y_i|x)} A_i,\; \text{clip}\!\left(\frac{\pi_\theta(y_i|x)}{\pi_{old}(y_i|x)}, 1\!-\!\epsilon, 1\!+\!\epsilon\right) A_i\right) - \beta\, D_{KL}(\pi_\theta \| \pi_{ref})\right] J GR P O ( θ ) = E x , { y i } [ G 1 ∑ i = 1 G min ( π o l d ( y i ∣ x ) π θ ( y i ∣ x ) A i , clip ( π o l d ( y i ∣ x ) π θ ( y i ∣ x ) , 1 − ϵ , 1 + ϵ ) A i ) − β D K L ( π θ ∥ π r e f ) ]
与 PPO 的对比 :PPO 用 A i = r i − V ϕ ( x ) A_i = r_i - V_\phi(x) A i = r i − V ϕ ( x ) V ϕ V_\phi V ϕ 消除了对价值网络的需求 ,节省了约 50% 的训练显存。
📚 已收录至 拓展阅读知识库
🔢 DeepSeek-R1 使用 GRPO 训练推理模型
任务 :数学题求解(可自动验证正确性)
参数设置 :G = 16 G=16 G = 16 ϵ = 0.2 \epsilon=0.2 ϵ = 0.2 β = 0.04 \beta=0.04 β = 0.04
一次训练步示例 (某道数学题):
解法编号 是否正确 格式分 总奖励 r i r_i r i y 1 y_1 y 1 正确 ✓ +0.1 1.1 y 2 y_2 y 2 错误 ✗ +0.1 0.1 y 3 y_3 y 3 正确 ✓ 0 1.0 …(16个) … … …
设 μ r = 0.35 \mu_r = 0.35 μ r = 0.35 σ r = 0.42 \sigma_r = 0.42 σ r = 0.42
A 1 = ( 1.1 − 0.35 ) / 0.42 = 1.79 A_1 = (1.1 - 0.35)/0.42 = 1.79 A 1 = ( 1.1 − 0.35 ) /0.42 = 1.79 A 2 = ( 0.1 − 0.35 ) / 0.42 = − 0.60 A_2 = (0.1 - 0.35)/0.42 = -0.60 A 2 = ( 0.1 − 0.35 ) /0.42 = − 0.60
训练信号 :增加 y 1 y_1 y 1 y 2 y_2 y 2
⚠️ 常见误区
误区 :GRPO 可以用于任何 NLP 任务 → 正确 :GRPO 依赖可自动评分的奖励函数 (如数学答案对错、代码是否通过测试)。对于需要人类判断的开放性任务(如写作风格、创意),无法在每步对 G = 16 G=16 G = 16
误区 :组内采样数 G G G 正确 :G G G O ( G ) O(G) O ( G ) G G G G = 16 G=16 G = 16
📐 GRPO vs PPO:优势估计的根本差异
两者的分歧核心是如何估计优势函数 A t A_t A t 。
PPO 的方式(需要 Critic) :
A t P P O = r ~ t + γ V ϕ ( s t + 1 ) − V ϕ ( s t ) (TD 误差,GAE 展开) A_t^{PPO} = \tilde{r}_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t) \quad \text{(TD 误差,GAE 展开)} A t P P O = r ~ t + γ V ϕ ( s t + 1 ) − V ϕ ( s t ) ( TD 误差, GAE 展开)
V ϕ V_\phi V ϕ
GRPO 的方式(组内归一化,无需 Critic) :
A i G R P O = r i − μ G σ G , μ G = 1 G ∑ j = 1 G r j , σ G = std ( r 1 : G ) A_i^{GRPO} = \frac{r_i - \mu_G}{\sigma_G}, \quad \mu_G = \frac{1}{G}\sum_{j=1}^G r_j, \quad \sigma_G = \text{std}(r_{1:G}) A i GR P O = σ G r i − μ G , μ G = G 1 ∑ j = 1 G r j , σ G = std ( r 1 : G )
对同一输入采样 G G G 以组内相对排名 代替价值函数。
数学等价性 :当 G → ∞ G \to \infty G → ∞ μ G → E [ r ] ≈ V ( s 0 ) \mu_G \to \mathbb{E}[r] \approx V(s_0) μ G → E [ r ] ≈ V ( s 0 ) Monte Carlo 采样隐式替代了参数化 Critic 。
RPO(Reward Policy Optimization)的定义与位置
RPO 是一类方法的统称:以奖励模型(RM)显式评分为驱动,通过参考策略(Reference Policy)施加正则化,优化策略的奖励期望。标准 RLHF + PPO 是 RPO 家族的典型实现。
RPO 的一般形式:
J R P O ( θ ) = E y ∼ π θ [ r ϕ ( x , y ) ] − β E [ log π θ ( y ∣ x ) π r e f ( y ∣ x ) ] J_{RPO}(\theta) = \mathbb{E}_{y \sim \pi_\theta}\!\left[r_\phi(x, y)\right] - \beta\, \mathbb{E}\!\left[\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}\right] J R P O ( θ ) = E y ∼ π θ [ r ϕ ( x , y ) ] − β E [ log π r e f ( y ∣ x ) π θ ( y ∣ x ) ]
GRPO 可以看作 RPO 的一个特例:用组内奖励均值 替代 Critic 估计 V ( s ) V(s) V ( s )
GRPO vs PPO(RPO 标准实现)vs REINFORCE 三路对比 :
维度 REINFORCE PPO(RPO 标准实现) GRPO 优势估计 A = r − b A = r - b A = r − b b b b A = r + γ V − V A = r + \gamma V - V A = r + γ V − V A = ( r − μ G ) / σ G A = (r - \mu_G)/\sigma_G A = ( r − μ G ) / σ G 需要 Value Network ✗ ✓(与 Policy 等大) ✗ 需要 Reward Model ✓ ✓ ✓ 总模型数量 2 4 3 训练稳定性 差(高方差) 好(Critic 降方差) 中(组采样降方差) 适用奖励类型 稀疏/密集 稀疏/密集 稀疏为主 (可自动验证)Clip 约束 ✗ ✓ ✓(同 PPO) 典型应用 早期 LM RL InstructGPT、早期 RLHF DeepSeek-R1 数学/代码
💡 为什么 GRPO 适合推理任务,PPO/RPO 适合通用对话?
奖励信号的密度决定了哪种方法更有效 :
数学/代码任务的奖励是极稀疏、二值化 的(答案对或错),无法给每个 token 提供密集梯度信号。PPO 的 Critic 在这种设置下退化——它只能在序列末尾看到一个 { 0 , 1 } \{0, 1\} { 0 , 1 }
而 GRPO 的组内比较天然适配稀疏奖励 :16 个序列中有 3 个答对了(r = 1 r=1 r = 1 r = 0 r=0 r = 0 A > 0 A > 0 A > 0 A < 0 A < 0 A < 0
对话对齐任务的奖励来自 RM 的连续打分(细粒度),Critic 可以充分学习 token 级价值函数——PPO 在这里优势更明显。
🔢 GRPO vs PPO 一次 Forward 的内存对比
以 7B 参数模型(fp16,每参数 2 字节)为基准:
模型 GRPO 加载 PPO 加载 Policy(有梯度) 7B × 2 = 14 GB 14 GB Value Network(有梯度) — 14 GB Reference Policy(无梯度) 7 GB 7 GB Reward Model(无梯度) 7 GB 7 GB 合计显存 ≈ 28 GB ≈ 42 GB
GRPO 节省约 33% 显存 (去掉 Value Network)。对于 70B 模型,这意味着从需要 8 卡变成可能 6 卡就能训练。
但 GRPO 的隐性开销 :每步要推理 G = 16 G=16 G = 16 显存 更省。
🔗 知识关联
GRPO → DAPO(2025) :Qwen 团队对 GRPO 的改进,引入动态采样策略(只对有正负样本的问题训练),解决 GRPO 在高难度问题上梯度消失的问题 → 见 DAPO GRPO → Dr. GRPO(2025) :对组内归一化的统计分解改进,分别归一化不同来源的奖励信号PPO 完整算法机制 详见本节 Section 3 补充块 DPO 与 GRPO 的定位 :DPO 解决”对话对齐”(offline,偏好对),GRPO 解决”推理能力提升”(online,可验证奖励)——两者互补,DeepSeek-R1 的完整训练同时使用了两者📚 三路算法(REINFORCE / PPO / GRPO)的系统对比 → GRPO vs RPO 拓展阅读
7. GRPO 改进谱系:DAPO / Dr.GRPO / GFPO / GSPO
GRPO 于 2024 年随 DeepSeek-R1 走红后,研究社区迅速暴露了它在大规模训练中的三类问题:熵崩塌 、优势估计偏差 、序列长度不平衡 。2025 年上半年涌现出一批针对性改进:DAPO(字节跳动)、Dr.GRPO(阿里)、GFPO 和 GSPO。
7.1 DAPO:解决 GRPO 训练不稳定性
来源 :ByteDance Research,2025;开源代码 + Qwen-32B 训练 recipe
GRPO 在大规模训练中暴露出四类问题,DAPO 逐一针对性解决:
问题 1:熵崩塌(Entropy Collapse)
训练过程中策略熵(Policy Entropy)持续下降,模型变得过于确信、失去探索能力。这与 GRPO 使用对称裁剪 有关:上界 1 + ϵ 1+\epsilon 1 + ϵ
解决方案 1:Clip-Higher(解耦裁剪)
将上下界裁剪解耦:
J D A P O c l i p ( θ ) = E [ min ( π θ π o l d A ^ , clip ( π θ π o l d , 1 − ϵ l o w , 1 + ϵ h i g h ) A ^ ) ] J_{DAPO}^{clip}(\theta) = \mathbb{E}\!\left[\min\!\left(\frac{\pi_\theta}{\pi_{old}} \hat{A},\; \text{clip}\!\left(\frac{\pi_\theta}{\pi_{old}}, 1\!-\!\epsilon_{low},\, 1\!+\!\epsilon_{high}\right)\hat{A}\right)\right] J D A P O c l i p ( θ ) = E [ min ( π o l d π θ A ^ , clip ( π o l d π θ , 1 − ϵ l o w , 1 + ϵ hi g h ) A ^ ) ]
ϵ l o w ≈ 0.2 \epsilon_{low} \approx 0.2 ϵ l o w ≈ 0.2 ϵ h i g h ≈ 0.28 \epsilon_{high} \approx 0.28 ϵ hi g h ≈ 0.28
问题 2:梯度稀释(Sample-Level Loss)
GRPO 原始实现中 loss 以 sample 为单位 归一化:每个回答贡献的梯度 = ∑ t grad t / 1 = \sum_t \text{grad}_t / 1 = ∑ t grad t /1
解决方案 2:Token-Level Policy Gradient Loss
L D A P O = 1 ∑ i ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ min ( r i , t A ^ i , clip ( r i , t , 1 − ϵ l o w , 1 + ϵ h i g h ) A ^ i ) \mathcal{L}_{DAPO} = \frac{1}{\sum_i |o_i|}\sum_{i=1}^{G}\sum_{t=1}^{|o_i|} \min\!\left(r_{i,t}\hat{A}_i,\; \text{clip}(r_{i,t}, 1\!-\!\epsilon_{low}, 1\!+\!\epsilon_{high})\hat{A}_i\right) L D A P O = ∑ i ∣ o i ∣ 1 ∑ i = 1 G ∑ t = 1 ∣ o i ∣ min ( r i , t A ^ i , clip ( r i , t , 1 − ϵ l o w , 1 + ϵ hi g h ) A ^ i )
对总 token 数归一化,每个 token 贡献相等的梯度权重 ,消除长序列的主导效应。
问题 3:超长序列污染奖励信号
当模型生成超过 L m a x L_{max} L ma x
解决方案 3:Overlong Filtering + Soft Overlong Punishment
Overlong Filtering :超长序列不参与梯度计算(从 batch 中剔除)Soft Overlong Punishment :对接近 L m a x L_{max} L ma x
r o v e r l o n g ( y ) = { 0 ∣ y ∣ ≤ L m a x − λ ⋅ ∣ y ∣ − L m a x L m a x ∣ y ∣ > L m a x r_{overlong}(y) = \begin{cases} 0 & |y| \leq L_{max} \\ -\lambda \cdot \frac{|y| - L_{max}}{L_{max}} & |y| > L_{max} \end{cases} r o v er l o n g ( y ) = { 0 − λ ⋅ L ma x ∣ y ∣ − L ma x ∣ y ∣ ≤ L ma x ∣ y ∣ > L ma x
问题 4:全对 / 全错 group 无效训练
当某道题的所有 G G G 全部正确或全部错误 时,组内奖励方差为零:σ G = 0 \sigma_G = 0 σ G = 0 A ^ i → 0 \hat{A}_i \to 0 A ^ i → 0
解决方案 4:Dynamic Sampling(动态采样)
在 rollout 阶段过滤掉 accuracy = 0% 或 100% 的 prompt,只保留有正有负的”混合 group”进入训练:
B t r a i n = { ( q , { y i } ) ∣ 0 < acc ( q ) < 1 } \mathcal{B}_{train} = \{(q, \{y_i\}) \mid 0 < \text{acc}(q) < 1\} B t r ain = {( q , { y i }) ∣ 0 < acc ( q ) < 1 }
🔢 DAPO 各改进消融(DeepSeek-R1-Zero-Qwen-32B,AIME 2024)
配置 AIME Score Base(纯 GRPO) 36 + Overlong Filtering 36 + Clip-Higher 38 + Dynamic Sampling 45 + Token-Level Loss 49 + Soft Overlong Punishment 50
观察 :Dynamic Sampling 单项贡献最大(+7),说明”无效 group”是 GRPO 性能上限的核心瓶颈;Token-Level Loss 补充了梯度均衡(+4)。
💡 为什么 Dynamic Sampling 效果最显著?
想象一个班级学测验:全班都做对(或做错)一道题,老师无法从这道题的批改中学到如何”区分好坏答题策略”——因为没有对比。GRPO 遇到全对/全错 group 时同理:没有相对排名就没有梯度信号 。Dynamic Sampling 强制每个 group 都包含”对”和”错”的样本,让每一步训练都有实质性学习信号。
7.2 Dr.GRPO:消除 GRPO 的优化偏差
来源 :阿里研究院,2025;“Dr.” = Debiased GRPO
GRPO 的组内归一化 A ^ i = ( r i − μ G ) / σ G \hat{A}_i = (r_i - \mu_G)/\sigma_G A ^ i = ( r i − μ G ) / σ G 系统性偏差 :
偏差 1:响应长度偏差(Length Bias)
GRPO 将同一奖励分配给序列内每个 token,但长度不同的回答获得不等的 per-token 梯度权重 :
长序列(∣ y ∣ = 500 |y| = 500 ∣ y ∣ = 500 ∝ A i / 500 \propto A_i / 500 ∝ A i /500
短序列(∣ y ∣ = 50 |y| = 50 ∣ y ∣ = 50 ∝ A i / 50 \propto A_i / 50 ∝ A i /50
这导致模型系统性偏好短回答 ,而非更正确的回答。
偏差 2:问题难度偏差(Question Difficulty Bias)
对极简单的问题(所有 G G G r i ≡ 1 r_i \equiv 1 r i ≡ 1 σ G ≈ 0 \sigma_G \approx 0 σ G ≈ 0 0 / 0 0/0 0/0
Dr.GRPO 的修正:全局归一化
用批次级全局统计量 替代 group 内统计量:
A ^ i D r = R ( q , o i ) − R ‾ σ R , R ‾ = 1 N ∑ j , k R ( q j , o j , k ) , σ R = std ( { R ( q j , o j , k ) } j , k ) \hat{A}_{i}^{Dr} = \frac{R(q, o_i) - \overline{R}}{\sigma_R}, \quad \overline{R} = \frac{1}{N}\sum_{j,k} R(q_j, o_{j,k}),\quad \sigma_R = \text{std}\!\left(\{R(q_j, o_{j,k})\}_{j,k}\right) A ^ i D r = σ R R ( q , o i ) − R , R = N 1 ∑ j , k R ( q j , o j , k ) , σ R = std ( { R ( q j , o j , k ) } j , k )
其中 j j j k k k 跨 prompt 比较奖励 ,而非局限于同一 prompt 的 group 内。
Dr.GRPO 完整目标:
J D r G R P O ( θ ) = ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t A ^ i D r , clip ( r i , t , 1 − ϵ , 1 + ϵ ) A ^ i D r ) J_{DrGRPO}(\theta) = \sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \min\!\left(r_{i,t}\hat{A}_{i}^{Dr},\; \text{clip}(r_{i,t}, 1\!-\!\epsilon, 1\!+\!\epsilon)\hat{A}_{i}^{Dr}\right) J D r GR P O ( θ ) = ∑ i = 1 G ∣ o i ∣ 1 ∑ t = 1 ∣ o i ∣ min ( r i , t A ^ i D r , clip ( r i , t , 1 − ϵ , 1 + ϵ ) A ^ i D r )
⚠️ 常见误区
误区 :全局归一化会引入跨 prompt 的不公平比较(不同题目难度不同)→ 正确 :正是如此——Dr.GRPO 刻意引入跨题难度对比,让奖励信号在绝对尺度上可比。这与标准化测试的曲线打分逻辑一致:用班级整体分布校准个体成绩。
误区 :Dr.GRPO 解决了长度偏差,所以不再需要 DAPO 的 Token-Level Loss → 正确 :两者从不同角度解决长度问题——Dr.GRPO 纠正优势估计的统计偏差 ,DAPO 的 Token-Level Loss 纠正梯度聚合的权重不均 ,可以叠加使用。
7.3 GFPO:多采样拒绝精选
核心思想 :把 GRPO 的组内相对奖励排名替换为显式的拒绝采样(Rejection Sampling),只使用精选的高质量样本做策略梯度。
GFPO 算法流程 :
对同一 prompt q q q G G G { o 1 , … , o G } \{o_1, \ldots, o_G\} { o 1 , … , o G }
计算各回答奖励 { r 1 , … , r G } \{r_1, \ldots, r_G\} { r 1 , … , r G }
执行拒绝采样:S = REJECTIONSAMPLE ( G , k , metric ) S = \text{REJECTIONSAMPLE}(G, k, \text{metric}) S = REJECTIONSAMPLE ( G , k , metric ) k k k
仅对精选集合 S S S
L G F P O = ∑ i ∈ S r i − r ‾ S σ S log π θ ( o i ∣ q ) \mathcal{L}_{GFPO} = \sum_{i \in S} \frac{r_i - \overline{r}_S}{\sigma_S}\log \pi_\theta(o_i | q) L GF P O = ∑ i ∈ S σ S r i − r S log π θ ( o i ∣ q )
核心直觉 :与其用”好坏都有”的 group 做双向约束(上调好的、下调坏的),GFPO 只上调最好的 ——类似于 DPO 中只用”chosen”样本学习,但在线生成而非离线标注。这在奖励函数噪声较大时更鲁棒(坏样本可能因噪声被误评为”较好”,不如直接丢弃)。
7.4 GSPO:面向 MoE 结构的序列级策略优化
来源 :针对 MoE(Mixture-of-Experts)模型的 GRPO 适配版本
问题:Token 级 IS 比率对长序列不稳定
标准 GRPO/PPO 使用 token 级重要性采样比率:
r I S = π θ ( y ∣ x ) π o l d ( y ∣ x ) = ∏ t = 1 ∣ y ∣ π θ ( y t ∣ x , y < t ) π o l d ( y t ∣ x , y < t ) r_{IS} = \frac{\pi_\theta(y|x)}{\pi_{old}(y|x)} = \prod_{t=1}^{|y|} \frac{\pi_\theta(y_t|x, y_{<t})}{\pi_{old}(y_t|x, y_{<t})} r I S = π o l d ( y ∣ x ) π θ ( y ∣ x ) = ∏ t = 1 ∣ y ∣ π o l d ( y t ∣ x , y < t ) π θ ( y t ∣ x , y < t )
当序列长度 ∣ y ∣ = 500 |y| = 500 ∣ y ∣ = 500 500 个比率的连乘积 。每个比率略偏离 1.0,乘积结果可能指数级偏离(“比率爆炸”或”比率消失”),使梯度极其不稳定。
对 MoE 模型而言,不同专家路由路径不同,token 级比率的方差更大,问题更严重。
GSPO 的解决:序列级 IS 比率(Log-Sum 形式)
GSPO 将 token 级连乘改为 log-sum,再取 exp:
r ~ I S s e q ( y ) = exp ( 1 ∣ y ∣ ∑ t = 1 ∣ y ∣ log π θ ( y t ∣ x , y < t ) π o l d ( y t ∣ x , y < t ) ) \tilde{r}_{IS}^{seq}(y) = \exp\!\left(\frac{1}{|y|}\sum_{t=1}^{|y|} \log\frac{\pi_\theta(y_t|x, y_{<t})}{\pi_{old}(y_t|x, y_{<t})}\right) r ~ I S se q ( y ) = exp ( ∣ y ∣ 1 ∑ t = 1 ∣ y ∣ log π o l d ( y t ∣ x , y < t ) π θ ( y t ∣ x , y < t ) )
这等价于几何平均 :先取每个 token 对数比率的均值,再还原为比率空间,避免了连乘的指数爆炸。
GSPO 完整目标函数:
J G S P O ( θ ) = E x , { y i } [ 1 G ∑ i = 1 G min ( r ~ i s e q A ^ i , clip ( r ~ i s e q , 1 − ϵ , 1 + ϵ ) A ^ i ) ] J_{GSPO}(\theta) = \mathbb{E}_{x, \{y_i\}}\!\left[\frac{1}{G}\sum_{i=1}^{G} \min\!\left(\tilde{r}_i^{seq} \hat{A}_i,\; \text{clip}\!\left(\tilde{r}_i^{seq}, 1\!-\!\epsilon, 1\!+\!\epsilon\right)\hat{A}_i\right)\right] J GS P O ( θ ) = E x , { y i } [ G 1 ∑ i = 1 G min ( r ~ i se q A ^ i , clip ( r ~ i se q , 1 − ϵ , 1 + ϵ ) A ^ i ) ]
其余(组内归一化优势、clip 参数)与 GRPO 保持一致。
🔢 Token 级 vs 序列级 IS 比率对比
以序列长度 ∣ y ∣ = 4 |y| = 4 ∣ y ∣ = 4 r t ∈ { 0.9 , 1.1 , 0.95 , 1.05 } r_t \in \{0.9, 1.1, 0.95, 1.05\} r t ∈ { 0.9 , 1.1 , 0.95 , 1.05 }
Token 级连乘 :
r I S = 0.9 × 1.1 × 0.95 × 1.05 = 0.9845 r_{IS} = 0.9 \times 1.1 \times 0.95 \times 1.05 = 0.9845 r I S = 0.9 × 1.1 × 0.95 × 1.05 = 0.9845
序列级 Log-Sum :
r ~ s e q = exp ( ln 0.9 + ln 1.1 + ln 0.95 + ln 1.05 4 ) = exp ( − 0.0159 ) ≈ 0.9842 \tilde{r}^{seq} = \exp\!\left(\frac{\ln 0.9 + \ln 1.1 + \ln 0.95 + \ln 1.05}{4}\right) = \exp(-0.0159) \approx 0.9842 r ~ se q = exp ( 4 l n 0.9 + l n 1.1 + l n 0.95 + l n 1.05 ) = exp ( − 0.0159 ) ≈ 0.9842
两者接近——但当序列长度为 500、每个 token 比率方差较大时,连乘会产生数值爆炸,而 log-sum 始终稳定在合理范围。
🔗 GRPO 改进谱系一览
方法 主要贡献 解决的核心问题 GRPO(原始) 组内归一化,去掉 Value Network 推理任务的高效 RL 训练 DAPO 解耦裁剪 + 动态采样 + Token-Level Loss 熵崩塌 + 无效 group + 梯度稀释 Dr.GRPO 全局归一化优势估计 长度偏差 + 难度偏差 GFPO 拒绝采样精选 奖励噪声下的样本质量 GSPO 序列级 IS 比率 MoE 长序列下 IS 比率不稳定
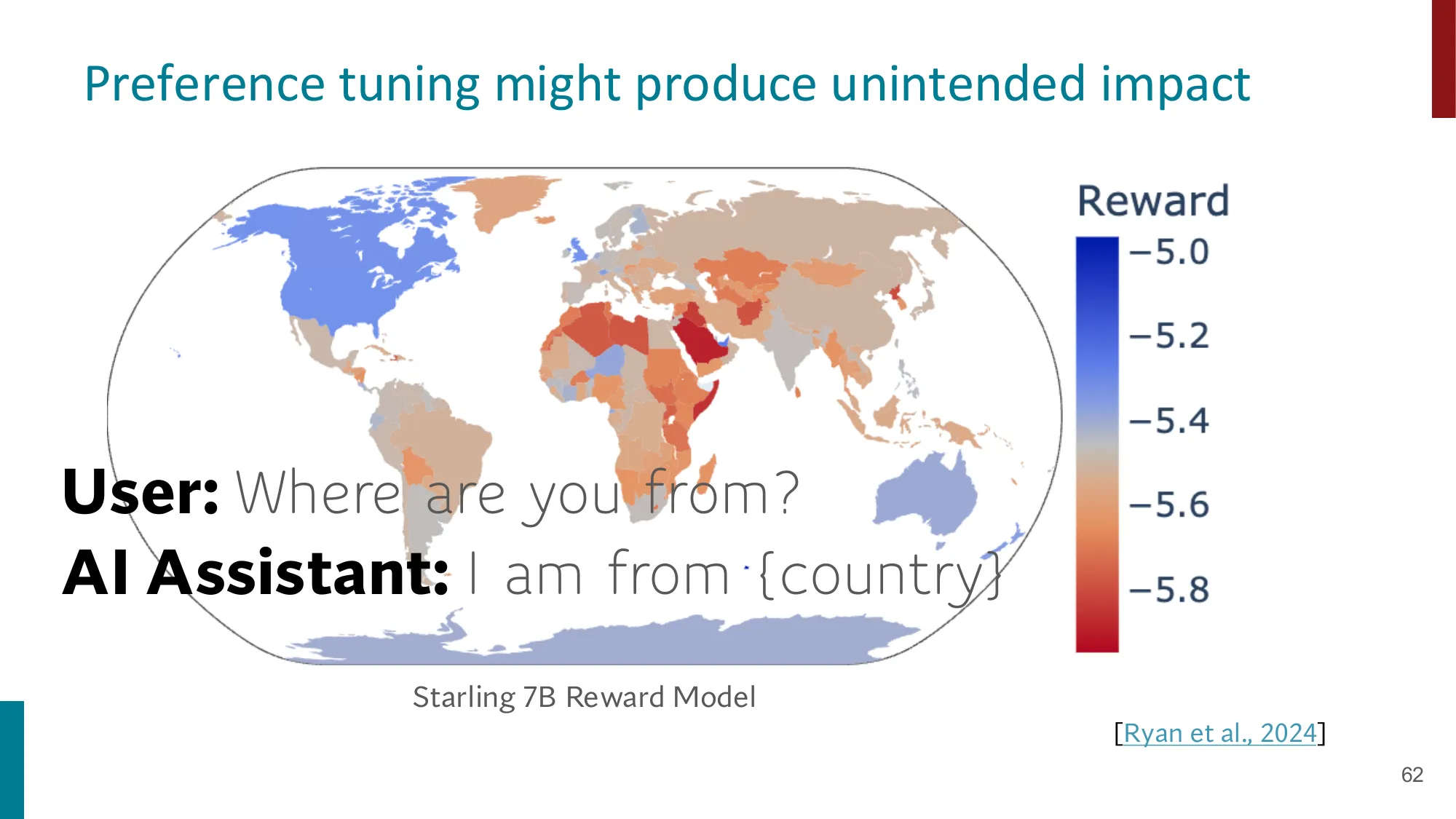
8. 偏好数据的伦理问题
RLHF 标注数据来源:大量海外低薪劳工
标注者偏见可能渗入模型(OpinionQA 研究)
Reward model 对不同国家/文化的偏好不均匀
AI Feedback 作为替代:RL from AI Feedback(Bai et al., 2022)
💡 为什么这样做?
RLHF 的本质是用”人类偏好”定义”好的回复”,但人类偏好是主观的、文化相关的、有偏的 。OpenAI 的 InstructGPT 标注者主要来自美国和英语国家;Anthropic 使用众包平台(Mechanical Turk)的标注者人口结构偏向年轻、英语为母语的人群。这些偏好被嵌入奖励模型,再被 RLHF 放大。结果是:模型对某些文化背景的用户”更有帮助”,对其他文化的用户则可能产生偏见性或不当回复。OpinionQA 研究(Santurkar et al., 2023)发现,主流 LLM 的意见分布与特定人口群体高度相关,不能代表全球用户多样性。
⚠️ 常见误区
误区 :RLHF 让模型更诚实(Honest)→ 正确 :RLHF 让模型产生看起来 诚实的回复,但奖励模型通常由倾向于给”自信、流畅回复”高分的人类标注者训练。这可能导致模型学会”自信地编造事实”(hallucination with confidence),而不是”诚实地承认不确定性”。真正的诚实需要专门设计针对不确定性表达的评估和训练数据。
误区 :用 AI Feedback(RLAIF,Bai et al., 2022)代替人类标注可以消除偏见 → 正确 :RLAIF 只是将偏见的来源从”人类标注者”转移到”作为评判者的 LLM”。评判模型本身就包含了人类偏见(因为它也是由人类数据训练的),偏见并没有消失,只是变得更不透明。
推荐阅读
关联概念
个人笔记
L07: Pretraining L09: Efficient Adaptation (PEFT)