L10: RAG and Language Agents
Week 5 · Thu Feb 05 2026 08:00:00 GMT+0800 (中国标准时间)
L10: RAG and Language Agents
- A4 released, A3 due
Slides
中英交替版(推荐)
英文原版
中文翻译版
核心知识点
0. PEFT 续讲 — Adapters


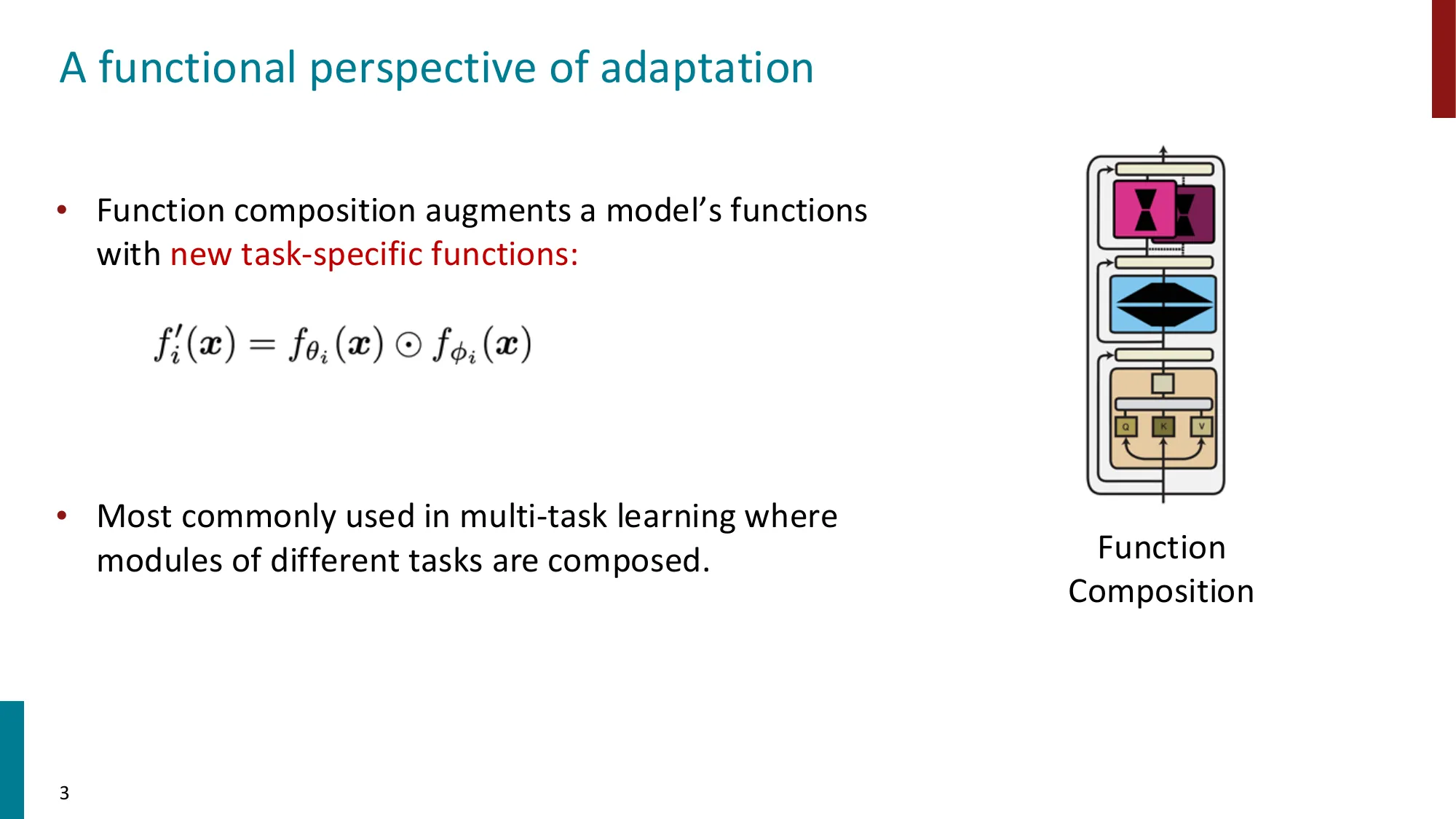
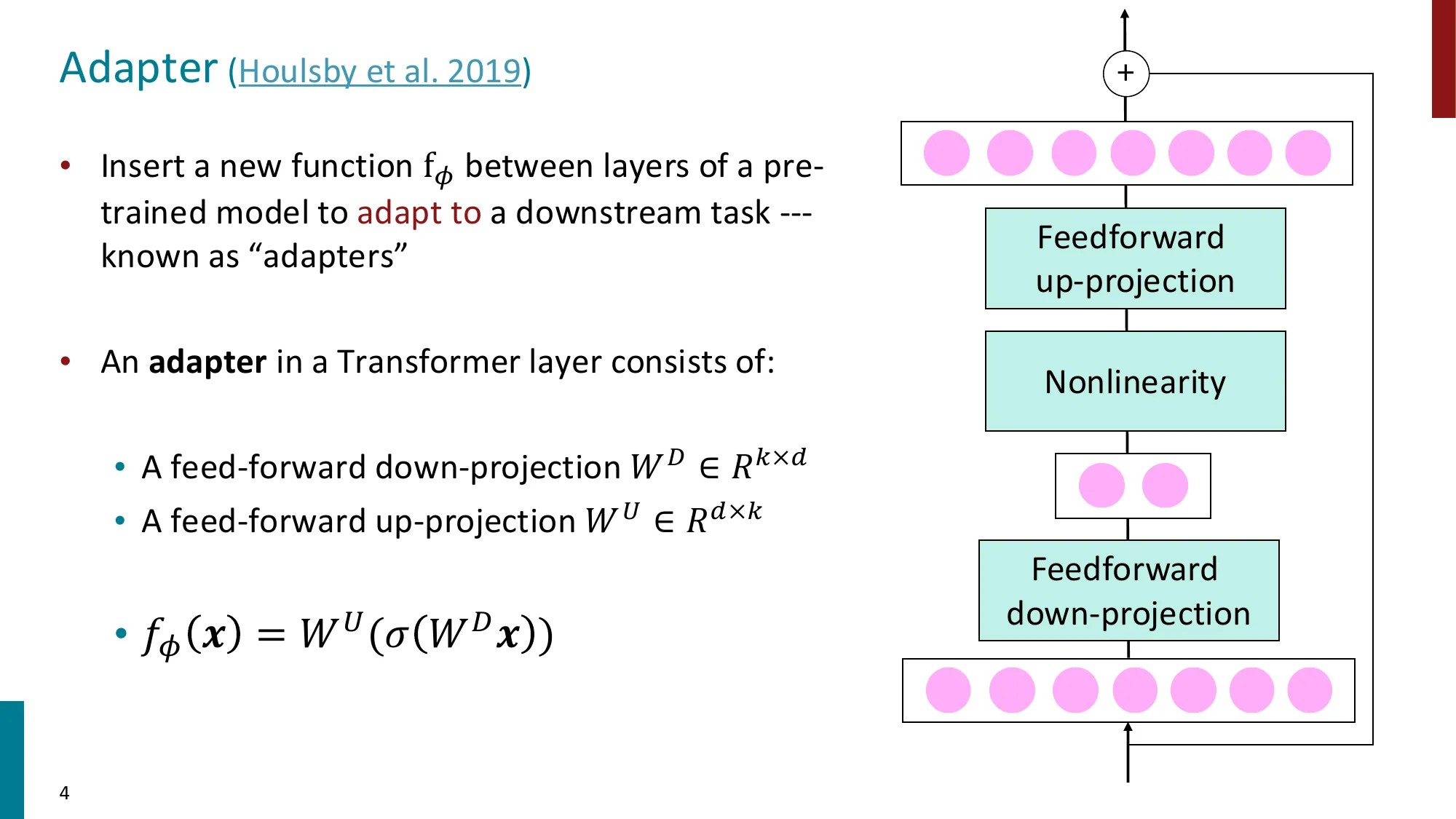
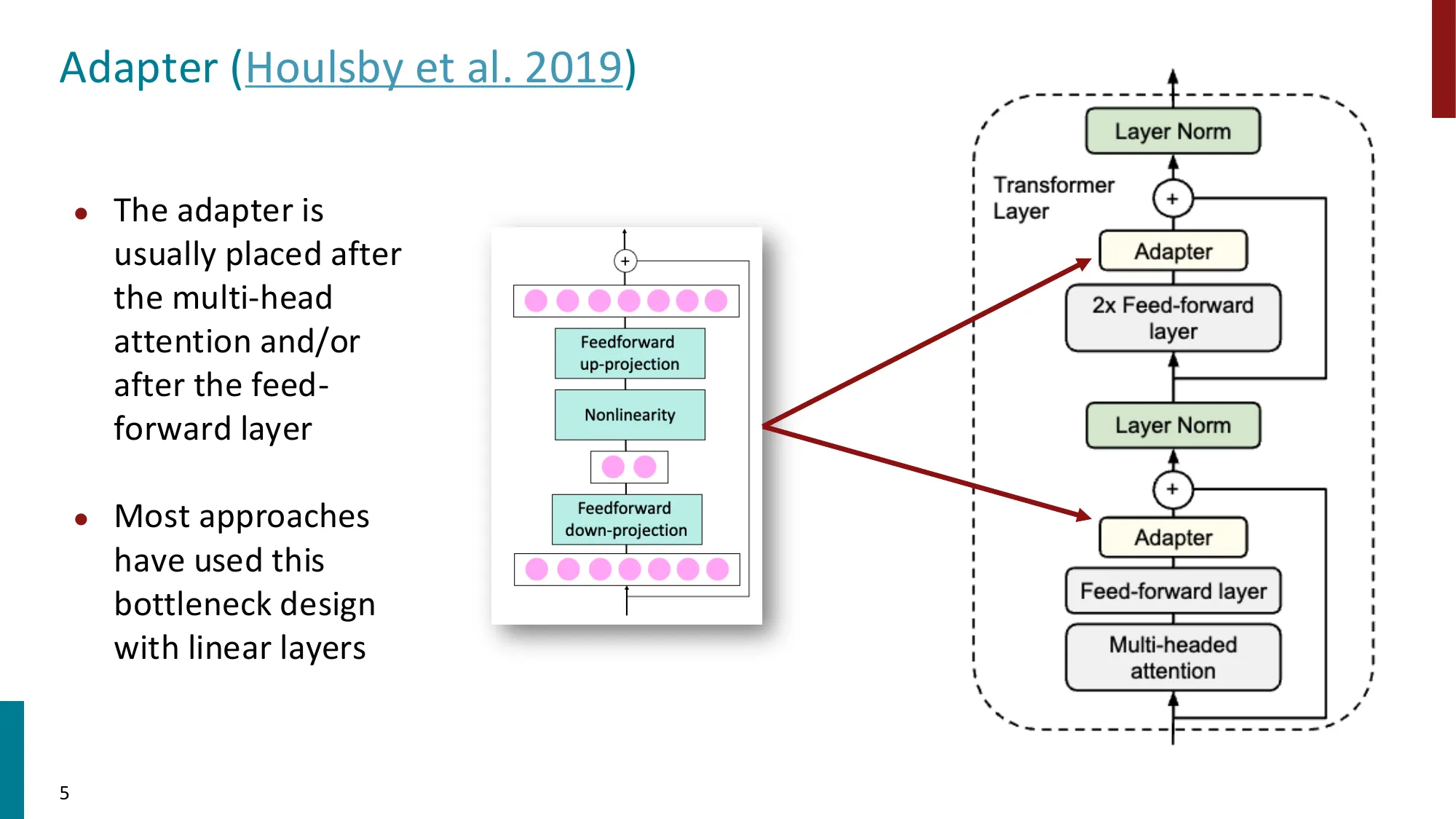
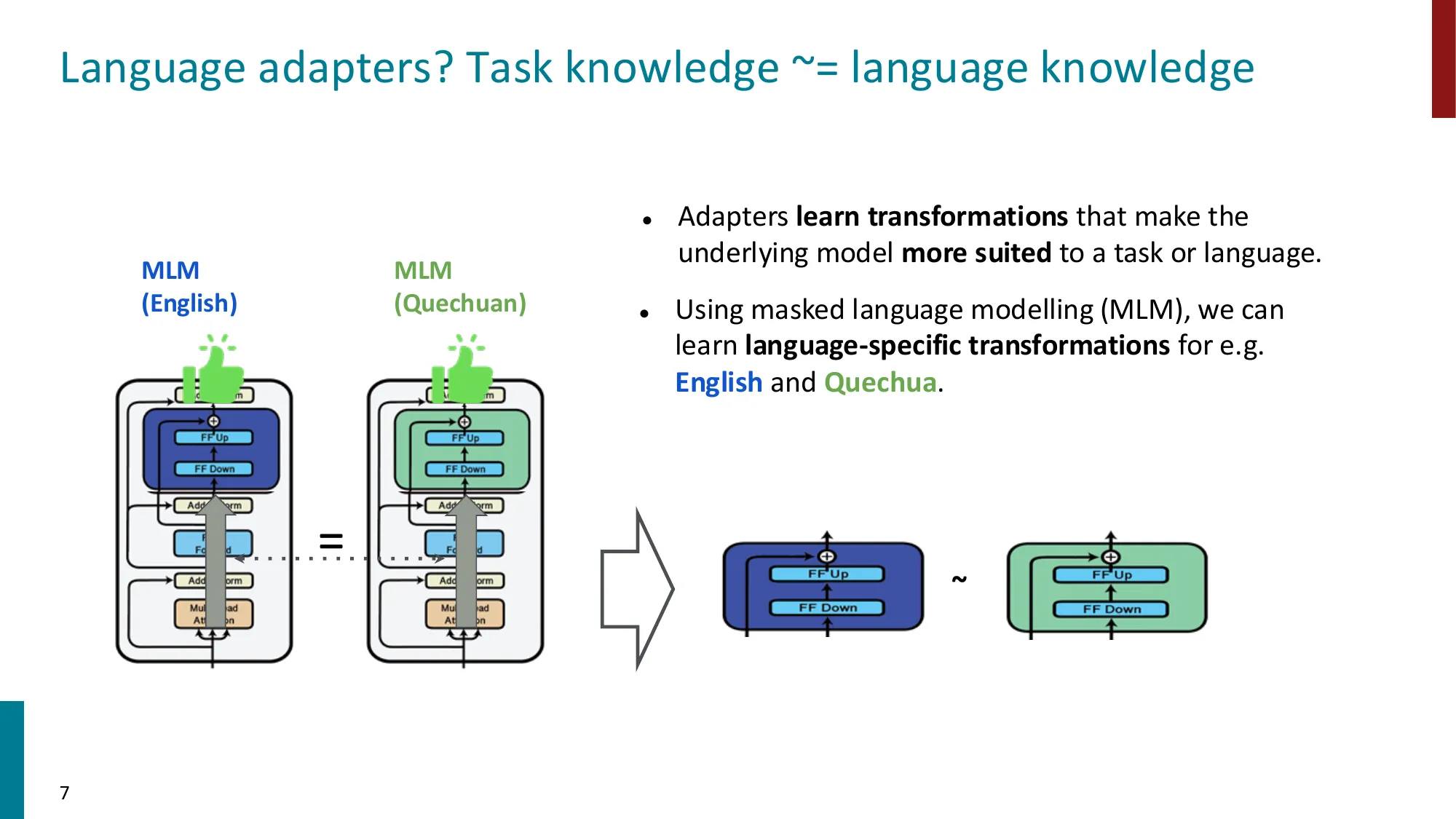
- 函数组合视角、瓶颈设计、语言 adapter
📐 Adapter 的数学结构
Adapter 在每个 Transformer 子层后插入一个瓶颈模块:
其中:
- (下投影,)
- (上投影)
- :非线性激活(通常 ReLU 或 GELU)
- 残差连接保证初始化时 ( 初始化为近零)
与 LoRA 的对比(LoRA 直接修改权重矩阵):
两者都用秩 分解控制参数量,但 Adapter 在推理时有额外延迟,LoRA 可以合并权重消除额外延迟。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
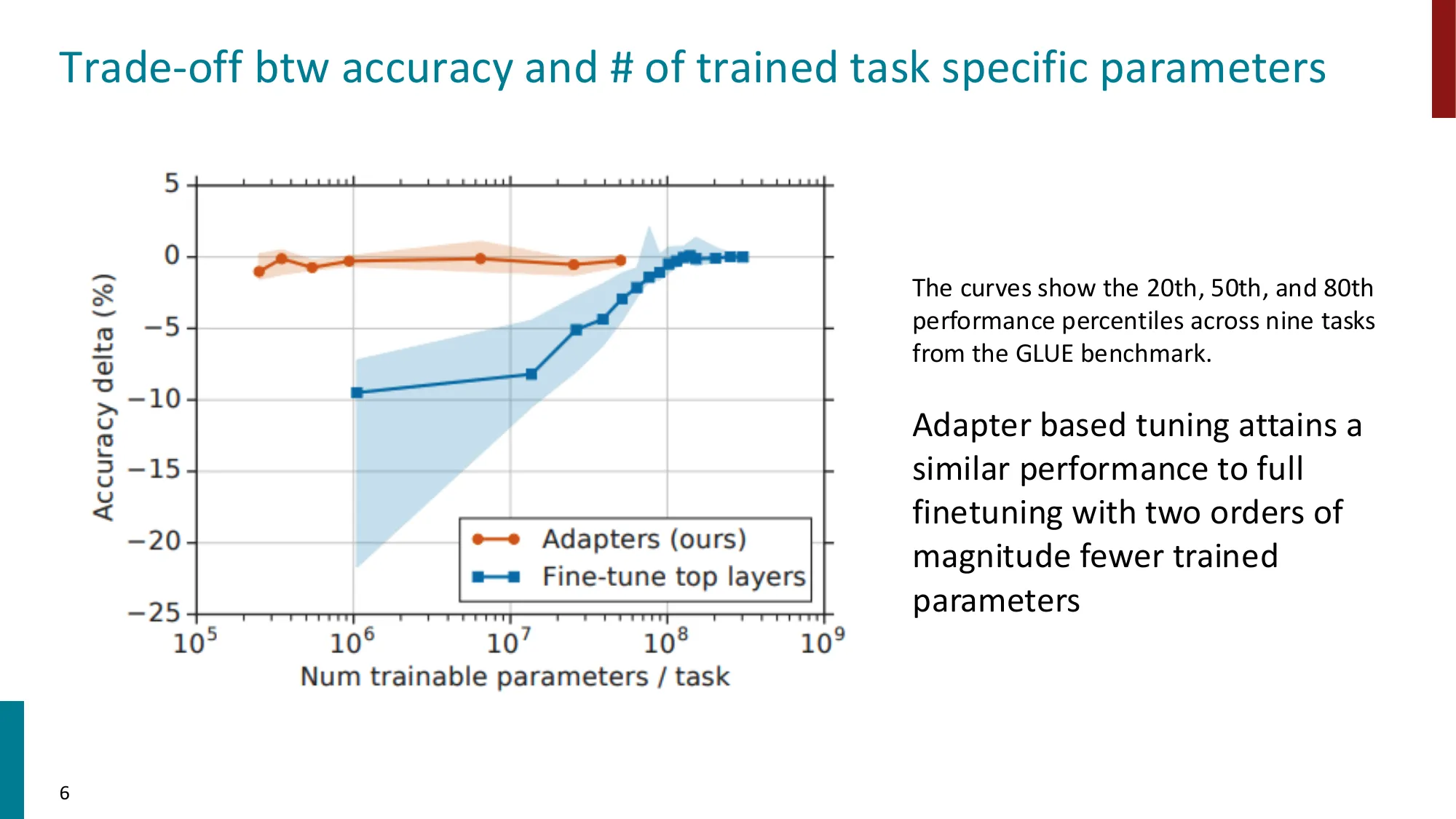
Adapter(Houlsby et al., 2019)在 GLUE 基准上的参数效率:
| 方法 | 可训练参数 | GLUE 平均分 |
|---|---|---|
| Full fine-tuning(BERT-Large) | 330M(100%) | 80.4 |
| Adapter() | ~3.6M(1%) | 80.0 |
| LoRA() | ~0.3M(0.09%) | 79.8 |
用 1% 的参数换来 99.5% 的性能保留——这是 PEFT 方法的价值所在。
⚠️ 常见误区
- 误区:Adapter 和 LoRA 效果相同可以互换 → 正确:Adapter 在推理时有额外的顺序计算(瓶颈前向传播),在批处理推理中会增加延迟;LoRA 可以将 合并到原始权重(),推理时零额外开销。
1. Question Answering 与 RAG
阅读理解(Reading Comprehension)



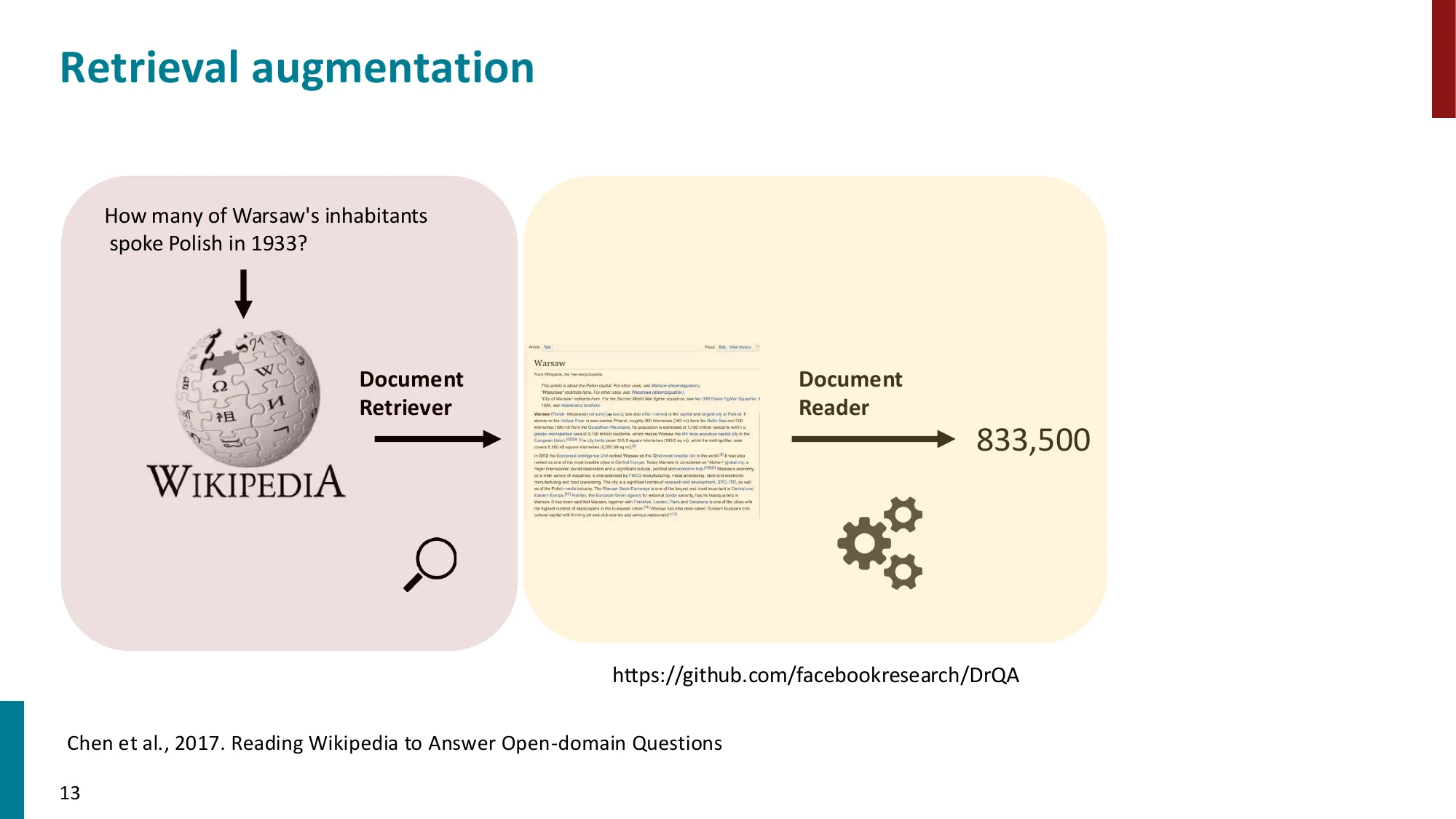
- 给定段落 + 问题,提取答案 span
- 传统方法:特征工程 + 逻辑回归
- 神经方法:BERT 编码 [CLS] Question [SEP] Paragraph,预测 start/end 位置
开放域问答(Open-domain QA)


- 不假设给定段落,从大规模文档集(如 Wikipedia)中找答案
- Retriever-Reader 框架:Retriever 检索 top-K 文档,Reader 从中抽取答案
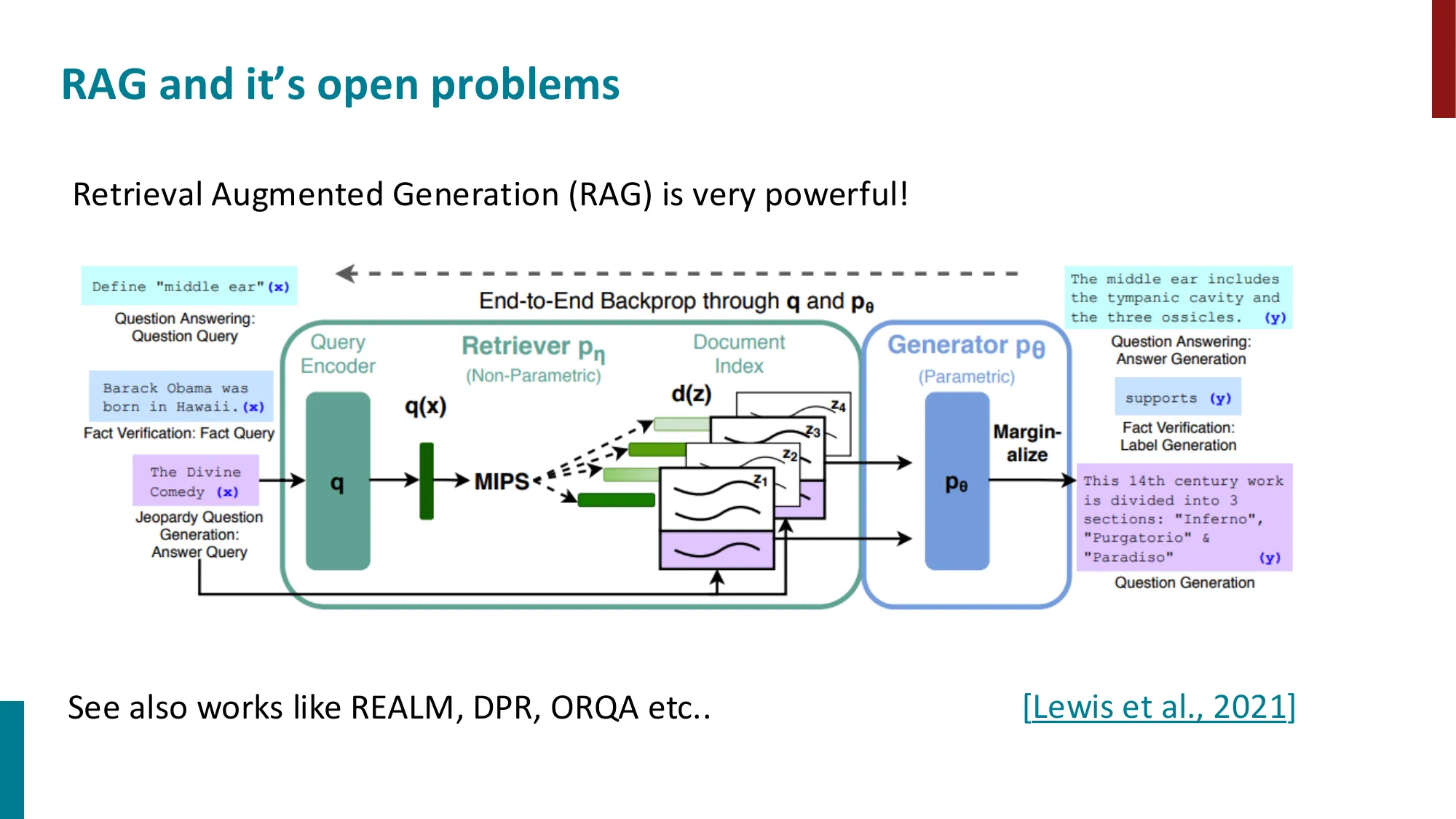
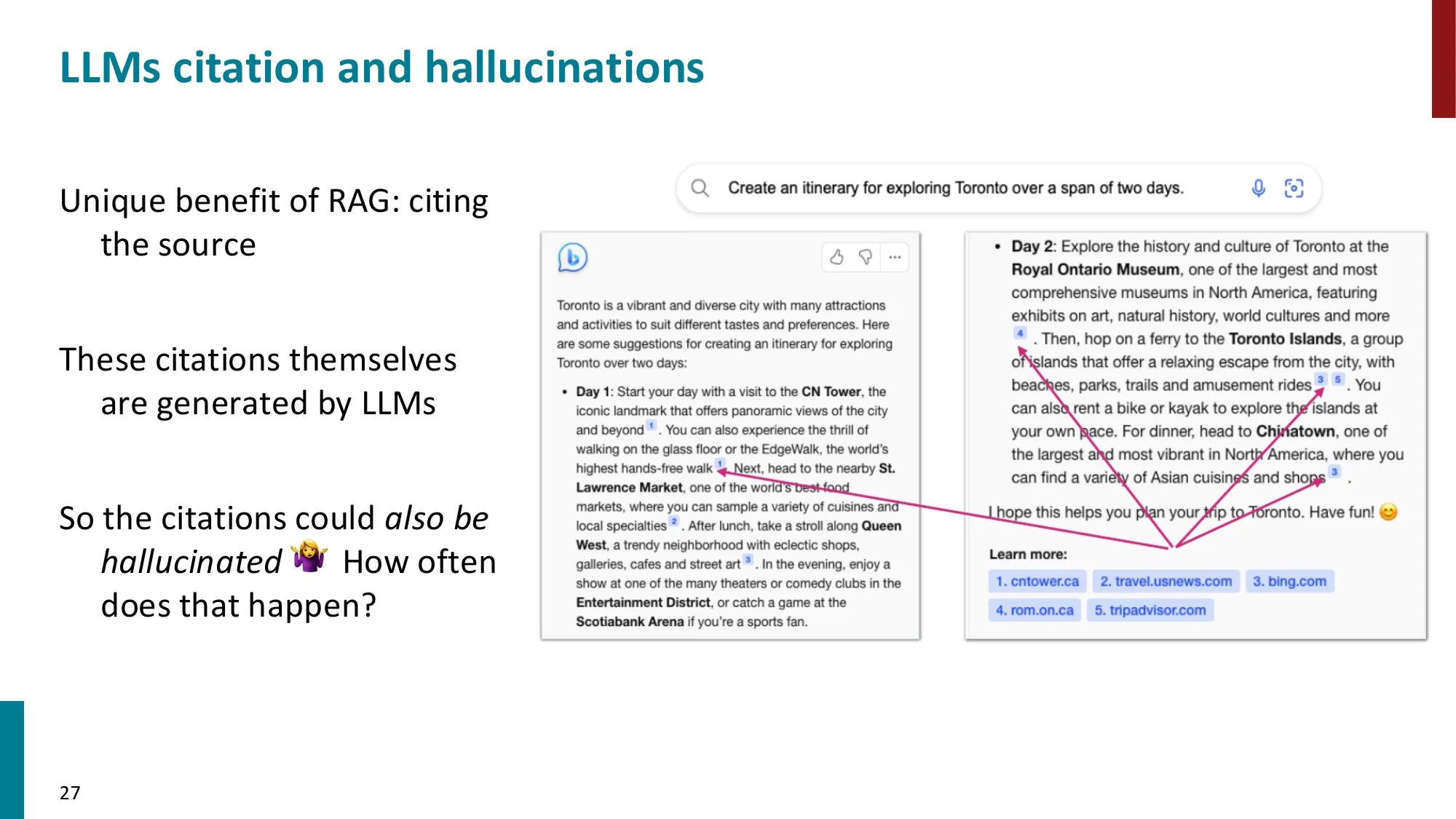
检索增强生成(RAG)

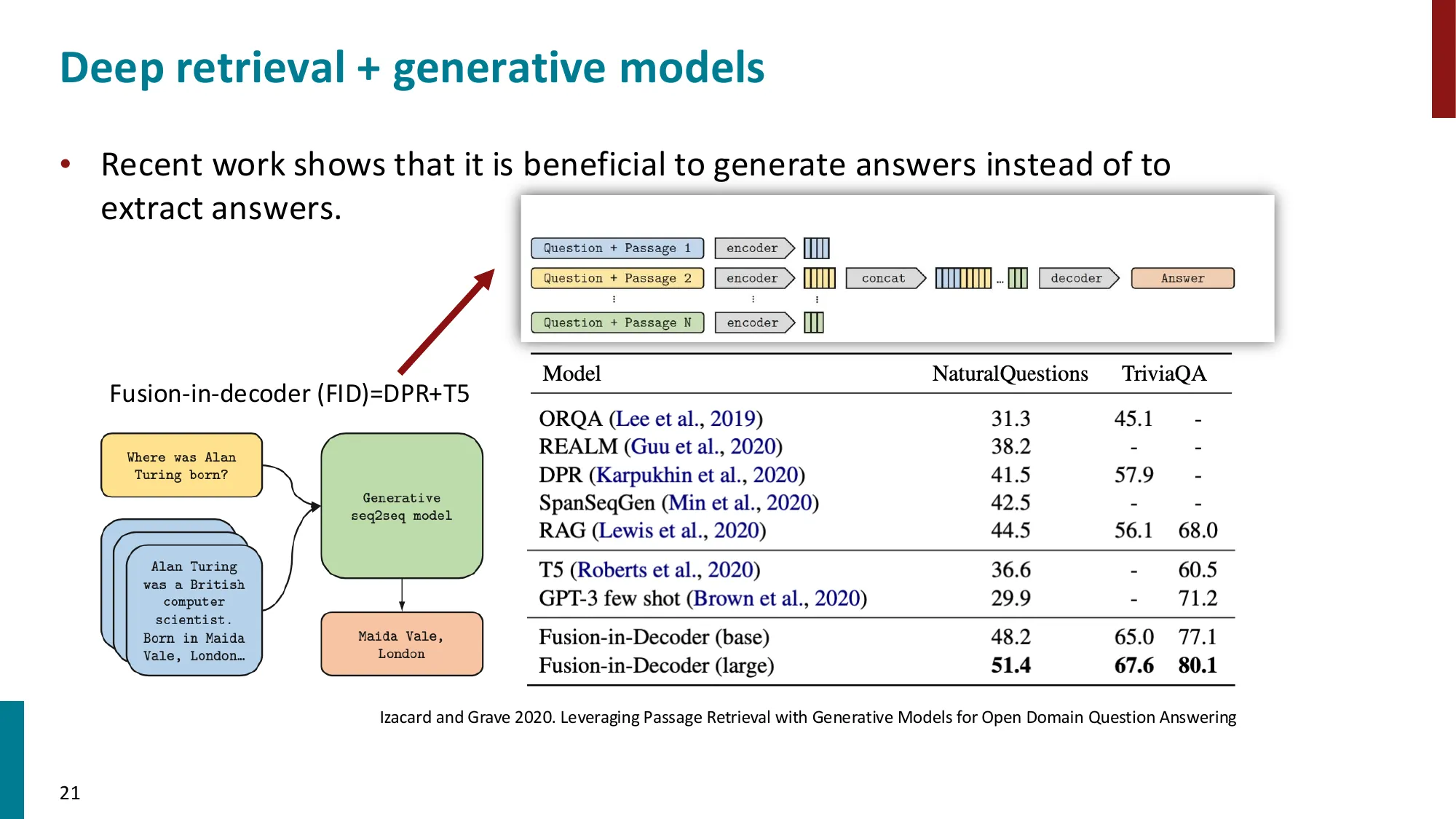

- 核心动机:LM 无法记住所有知识,检索提供即时相关信息
- 优势:动态(可更新文档库)+ 可解释(可追溯引用来源)
- RAG 架构(Lewis et al., 2021):Query Encoder + Document Index (MIPS) + Generator
- 端到端训练 retriever 和 generator
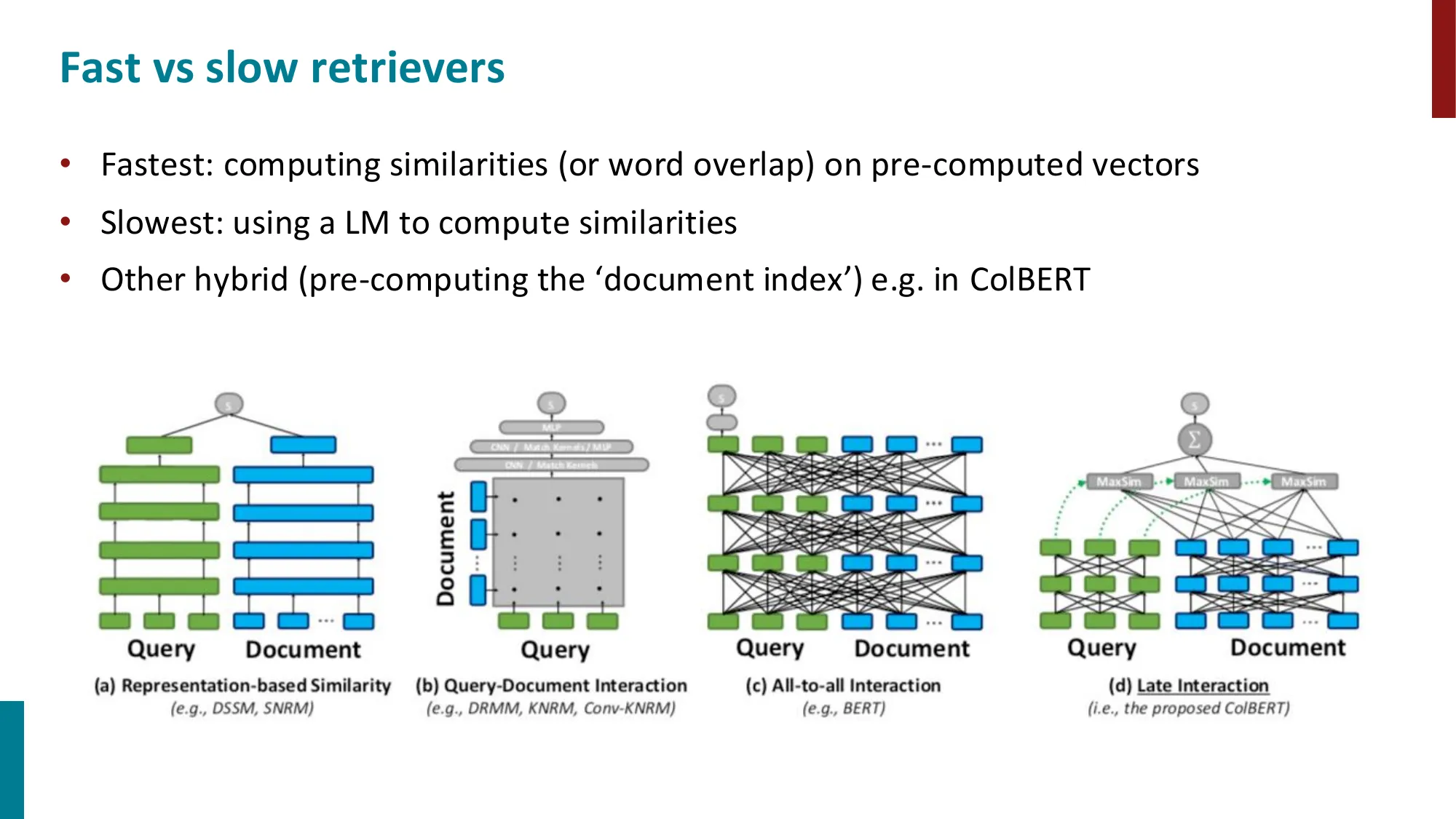
检索器类型

- 词重叠:BM25(稀疏)
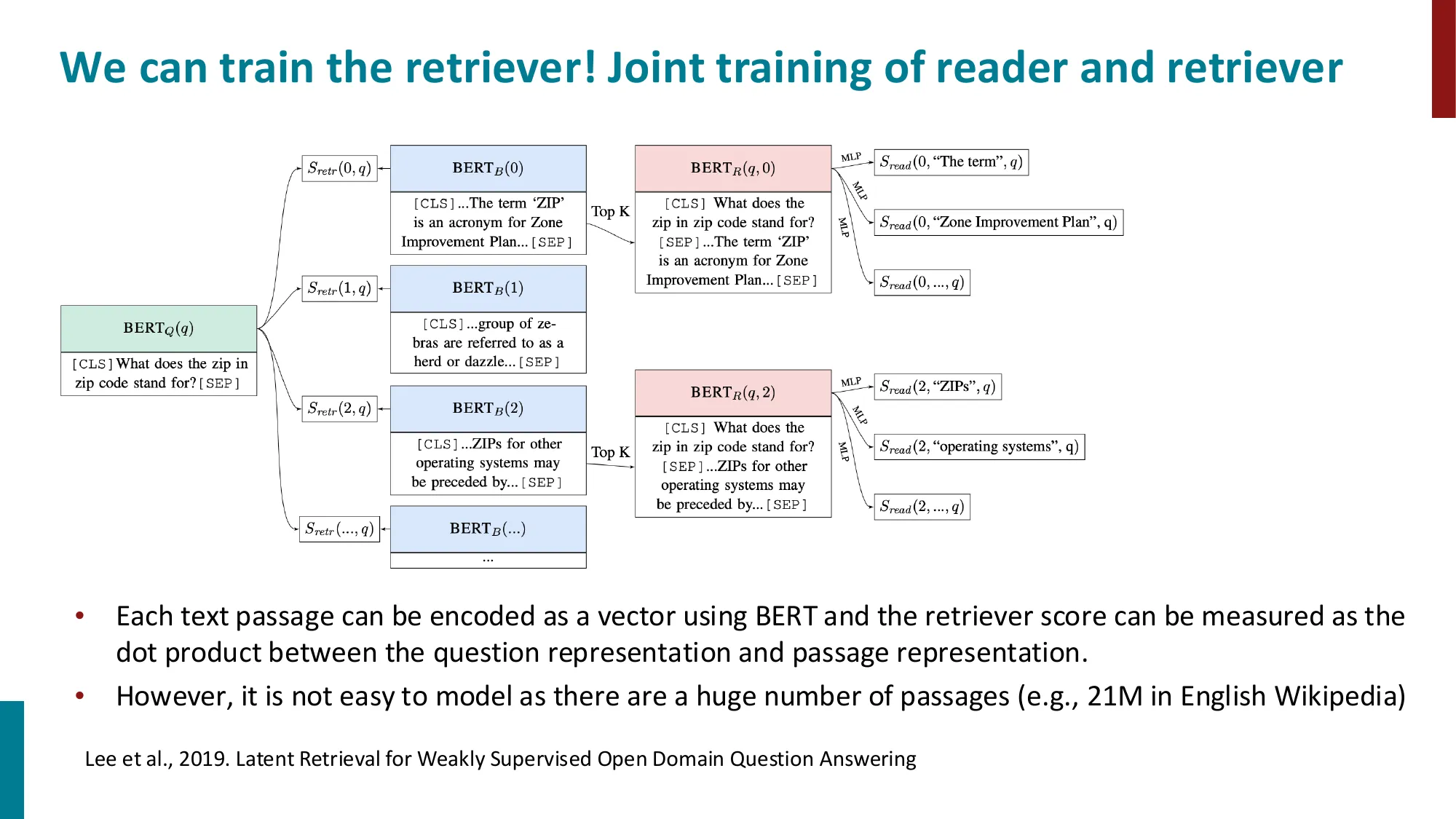
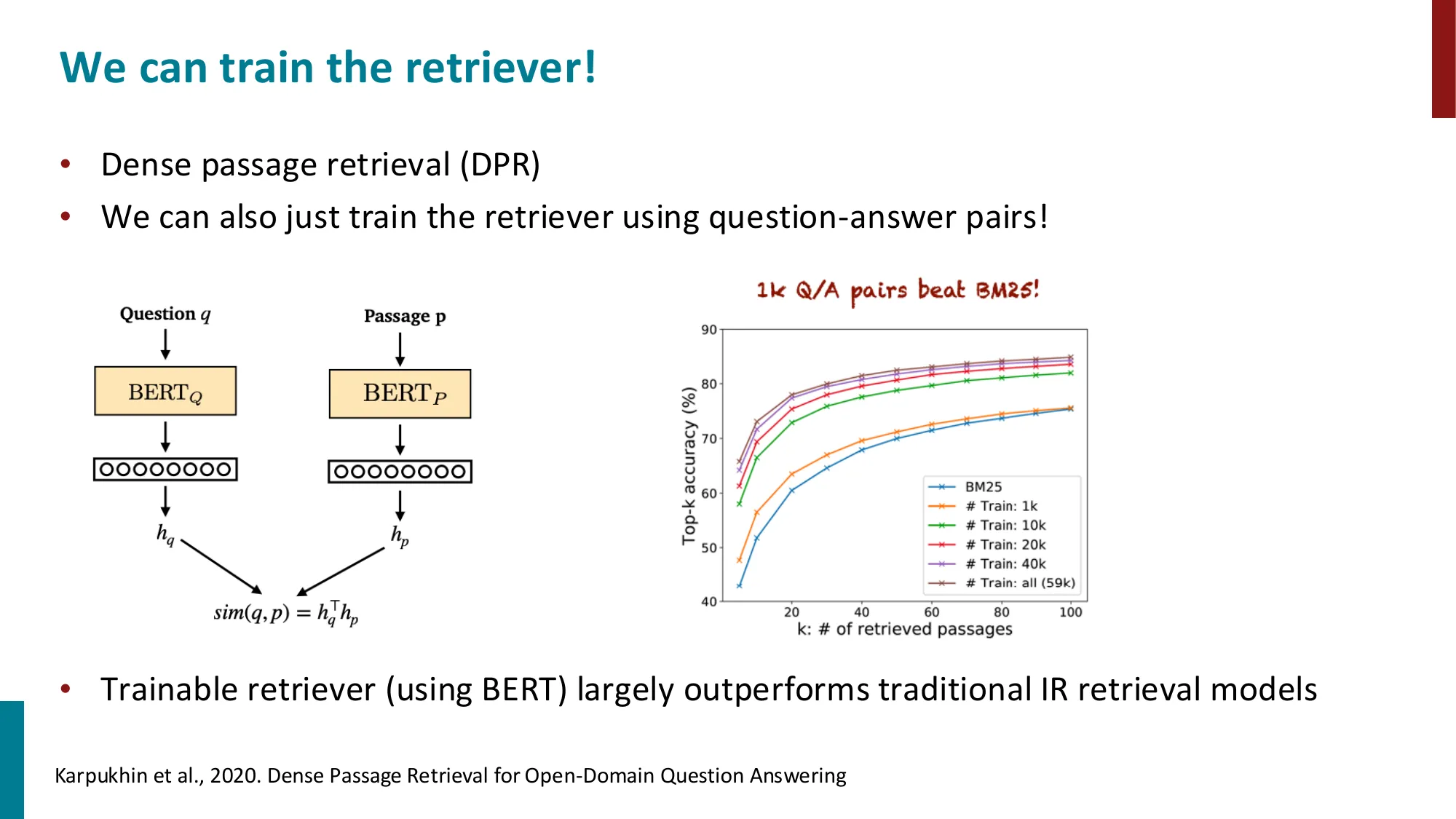
- 向量检索:DPR(Dense Passage Retrieval,用 BERT 编码 query 和 passage,点积相似度)
- 混合系统:ColBERT(late interaction)
- DPR 仅用 1K Q/A 对即可超越 BM25
📐 RAG 的形式化推导
RAG(Lewis et al., 2021) 将生成过程边缘化到检索文档上:
其中:
- :查询(问题)
- :检索到的文档段落
- :检索相关性分数,由 DPR(Dense Passage Retrieval) 提供:
是独立的 BERT 编码器(双编码器架构),内积衡量相关性。
FAISS(MIPS):在数十亿向量中做近似最近邻搜索(Maximum Inner Product Search),时间复杂度从 降至 (倒排索引)。
生成器(如 BART/GPT)的条件概率:
RAG-Token 变体:每个生成 token 可以从不同文档中检索,比 RAG-Sequence(整个答案基于同一文档)更灵活。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
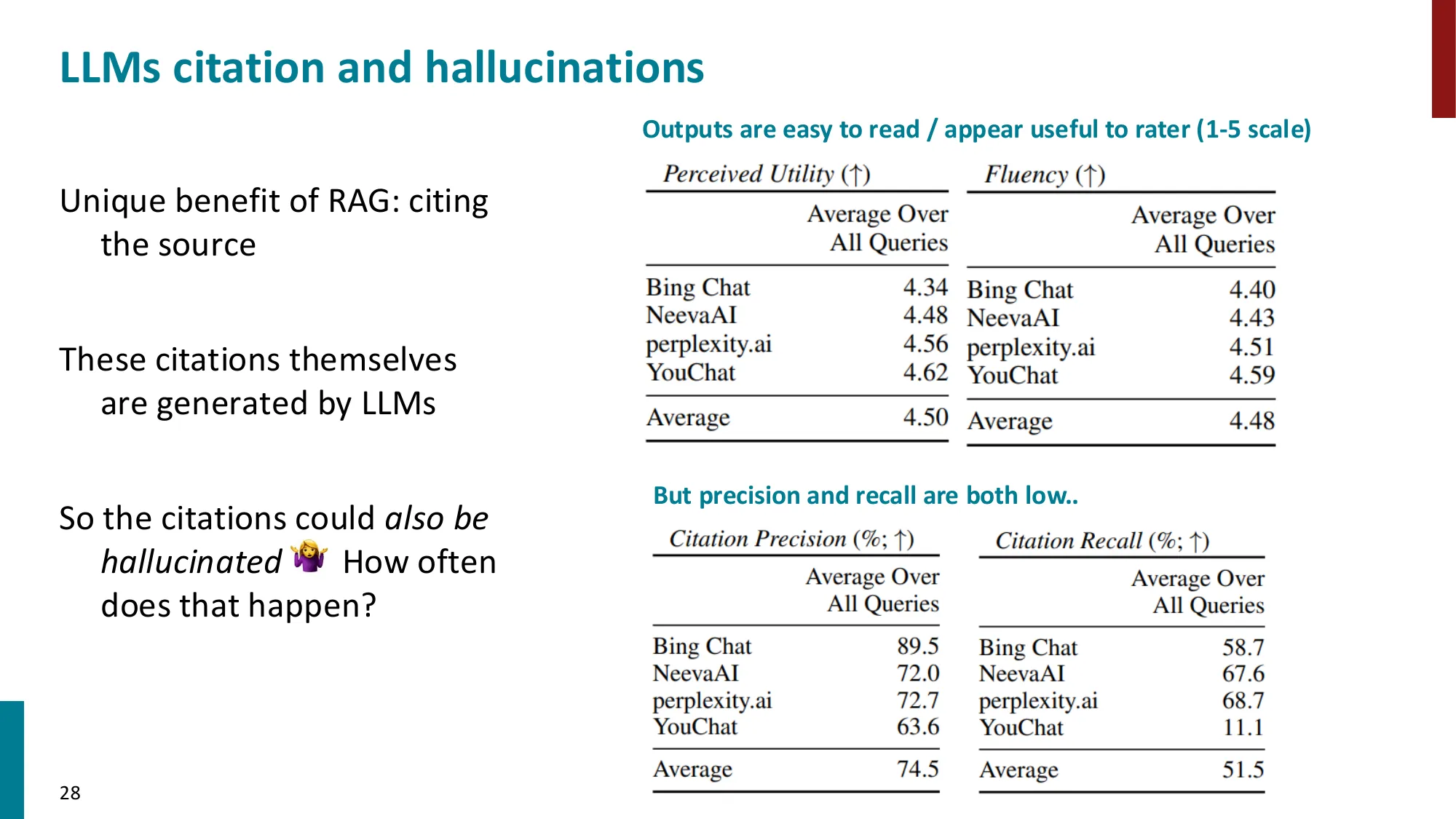
RAG vs 纯 LM 在开放域问答(NaturalQuestions)上的对比:
| 方法 | EM(精确匹配) | 特点 |
|---|---|---|
| T5-11B(纯参数) | 36.6% | 知识存在权重中,无法更新 |
| RAG(DPR + BART) | 44.5% | 检索 Wikipedia,可动态更新 |
| GPT-3 175B(纯参数) | 29.9% | 大但无检索 |
关键数字:DPR 在 Natural Questions 上,仅用 1000 个训练样本,top-20 检索召回率达 78.4%,而 BM25 是 59.1%。
💡 为什么这样做?
LLM 的参数是”固化的记忆”——训练完成后无法更新,且存储效率低(用数十亿参数记住百科全书式的知识极其浪费)。RAG 给 LLM 提供了”活的外部记忆”:对于需要最新信息(新闻、医学指南)或具体事实(人名、日期、数字)的问题,检索 + 生成远比纯参数记忆可靠且可解释(可追溯来源)。
⚠️ 常见误区
- 误区:RAG 能完全替代 fine-tuning → 正确:RAG 适合”知识密集型”任务(事实问答),但对于需要改变模型行为风格(如特定写作风格、安全规则、遵循格式)的场景,RAG 效果有限,必须用 fine-tuning/RLHF。
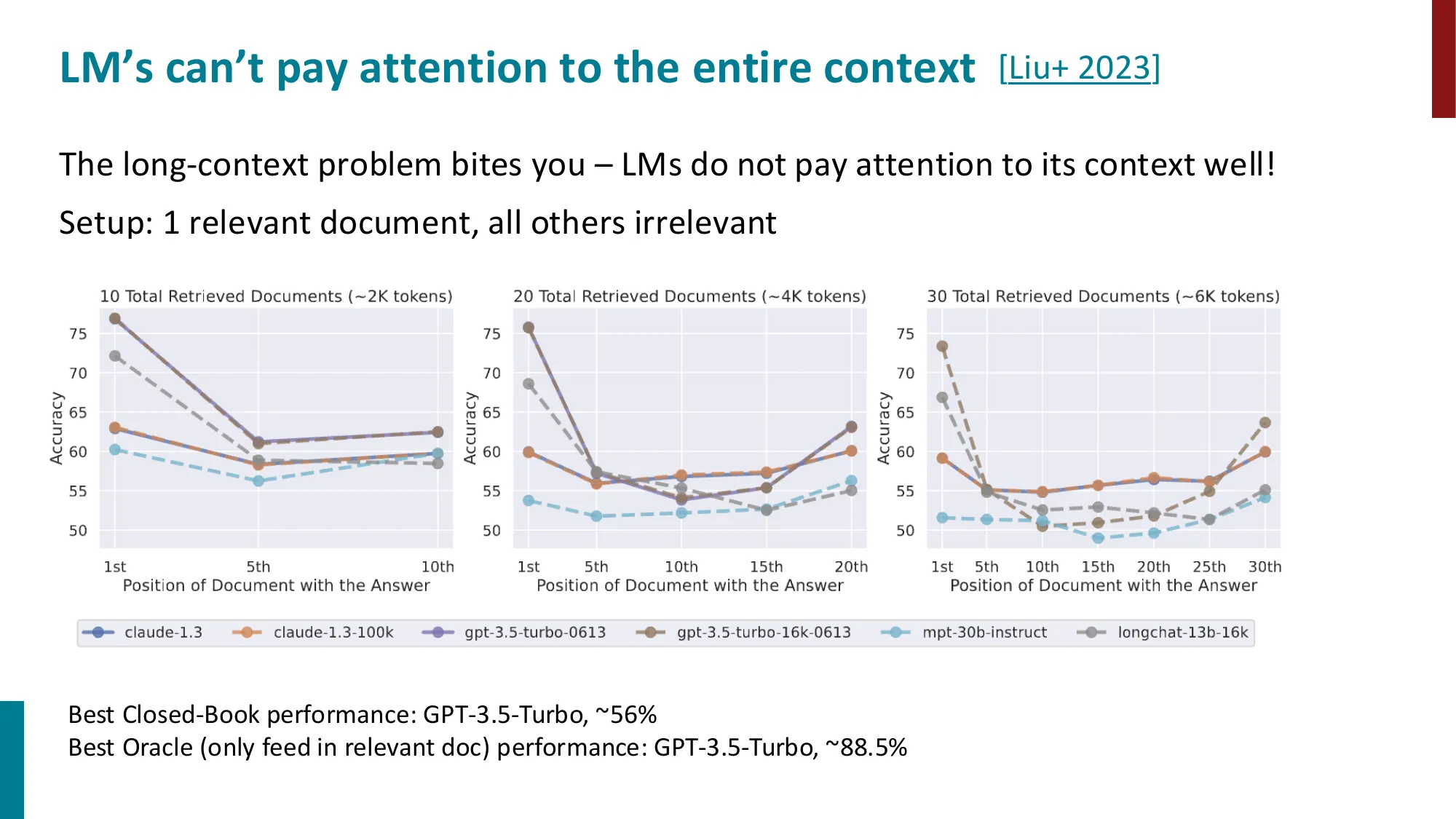
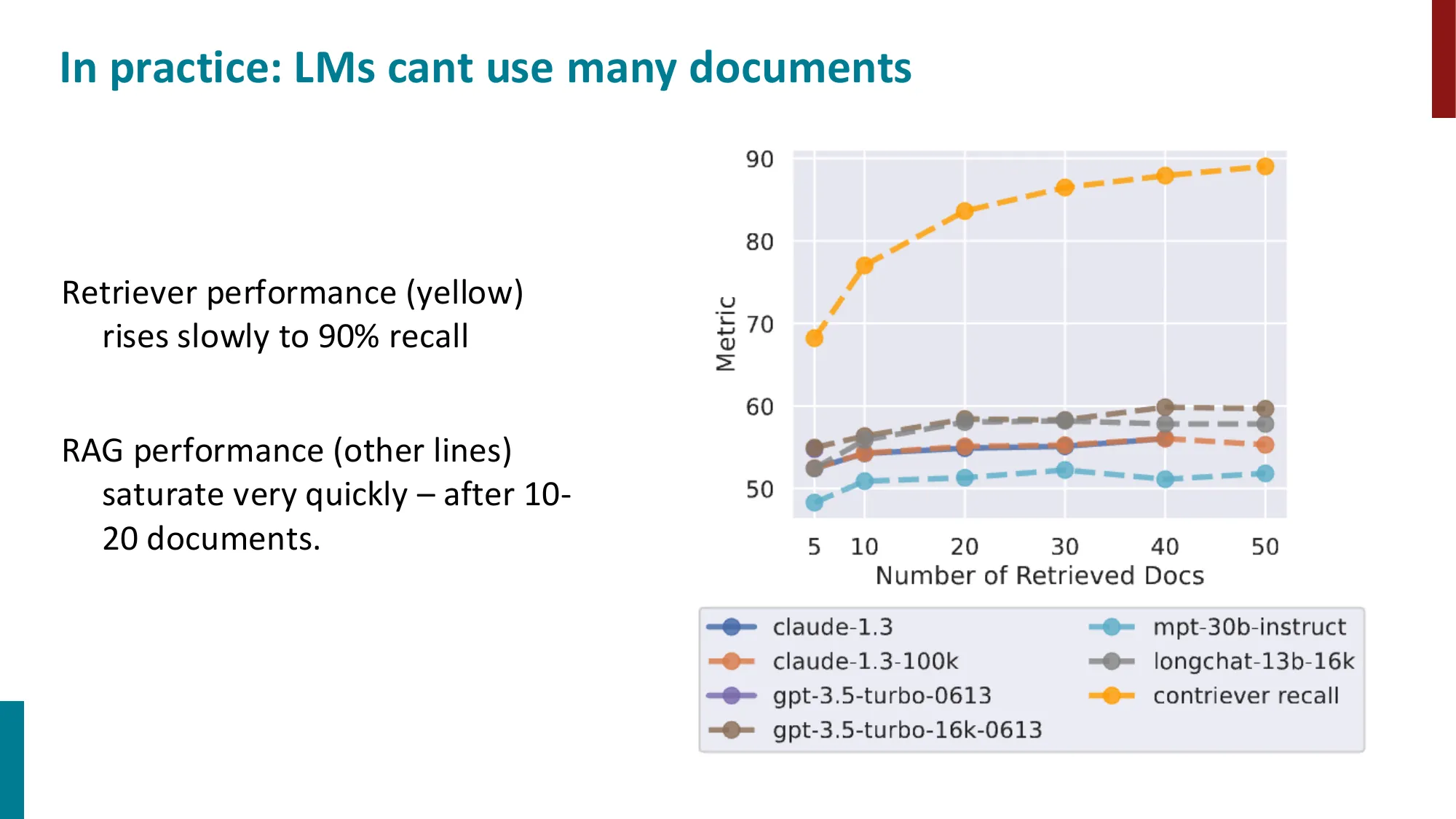
- 误区:检索到的文档越多越好 → 正确:超过一定数量(通常 top-5 到 top-10),更多文档会引入噪声,生成质量反而下降(“Lost in the Middle”问题——LLM 更关注开头和结尾的文档)。
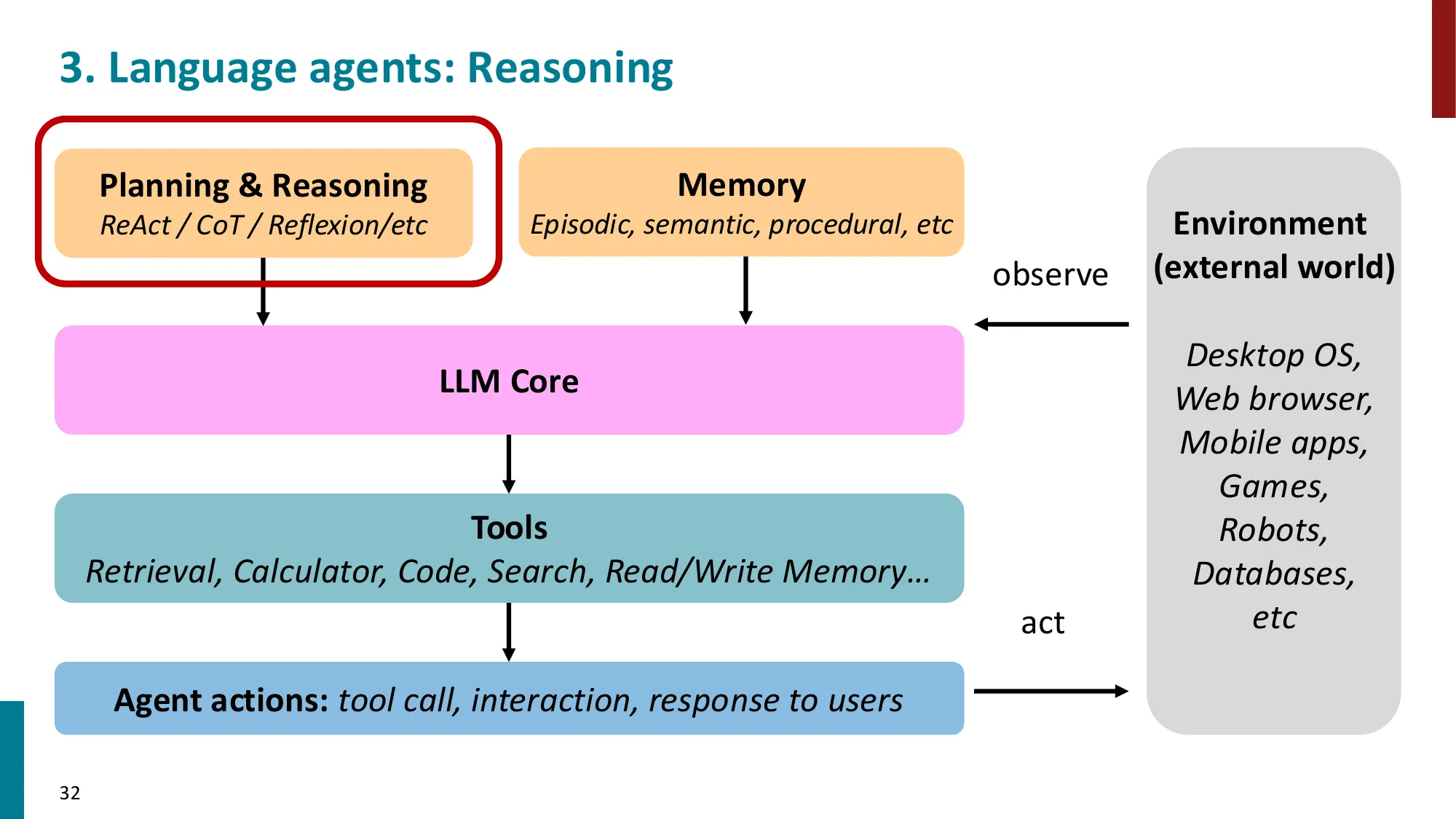
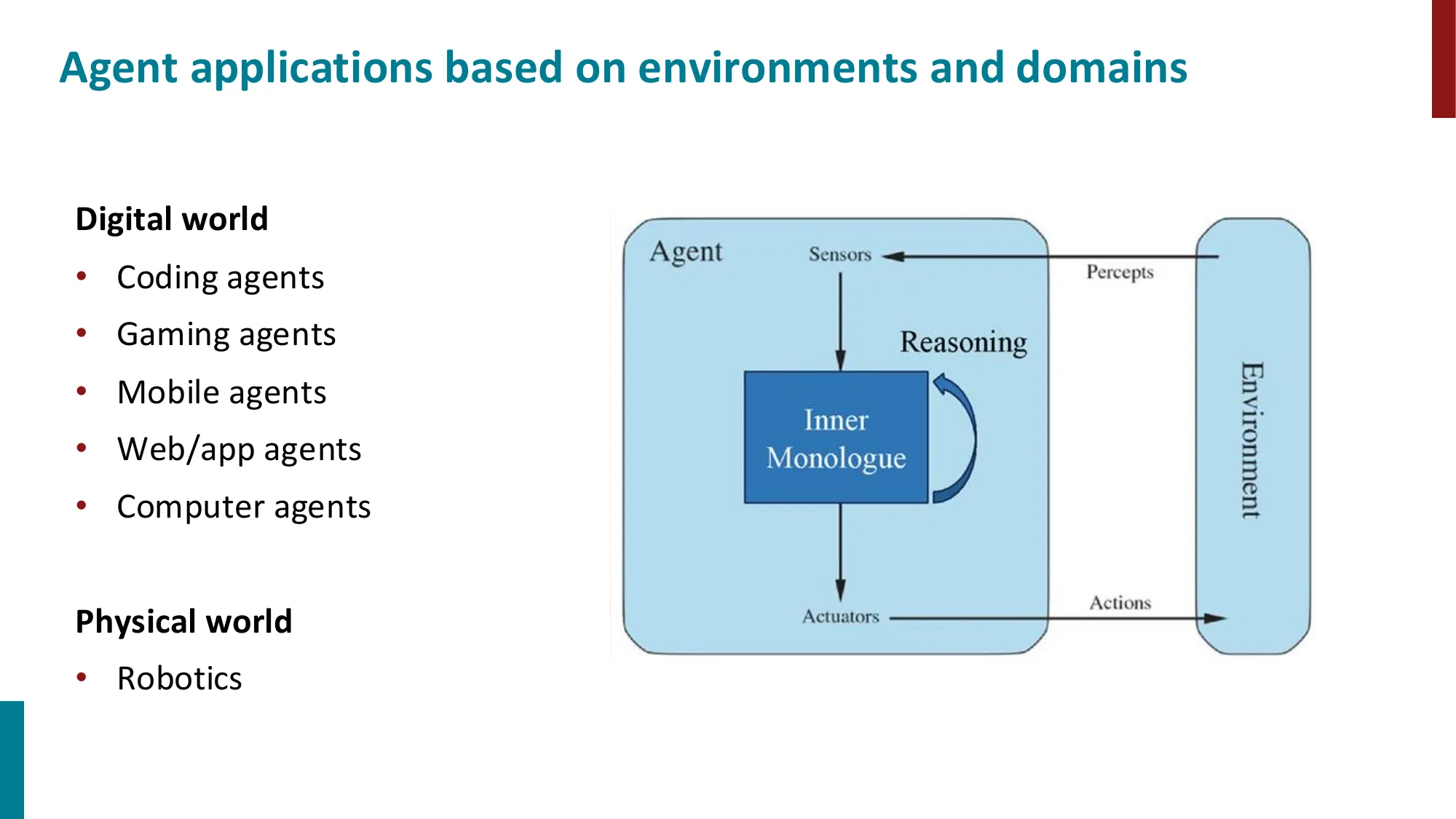
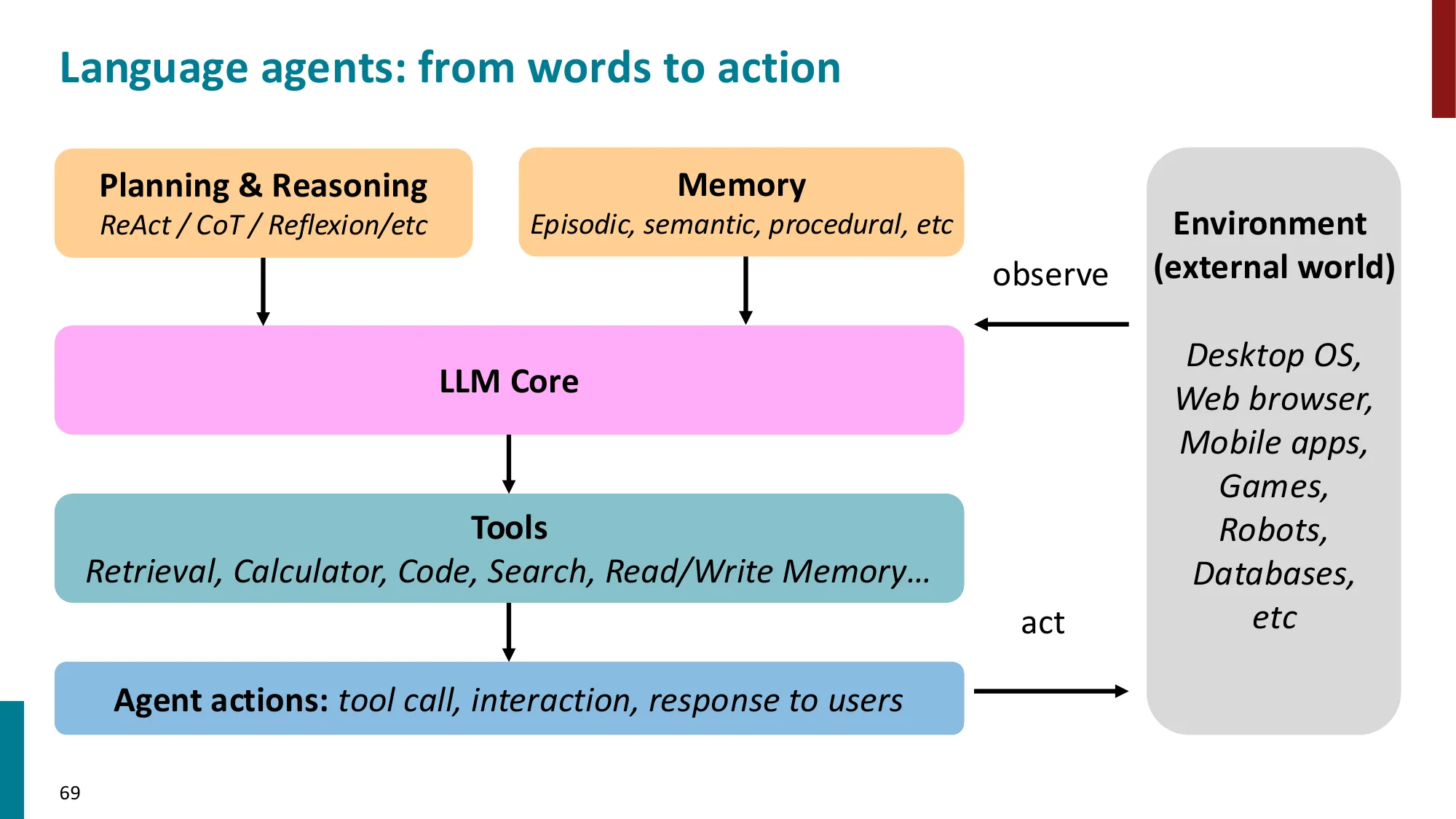
2. Language Agents 概述

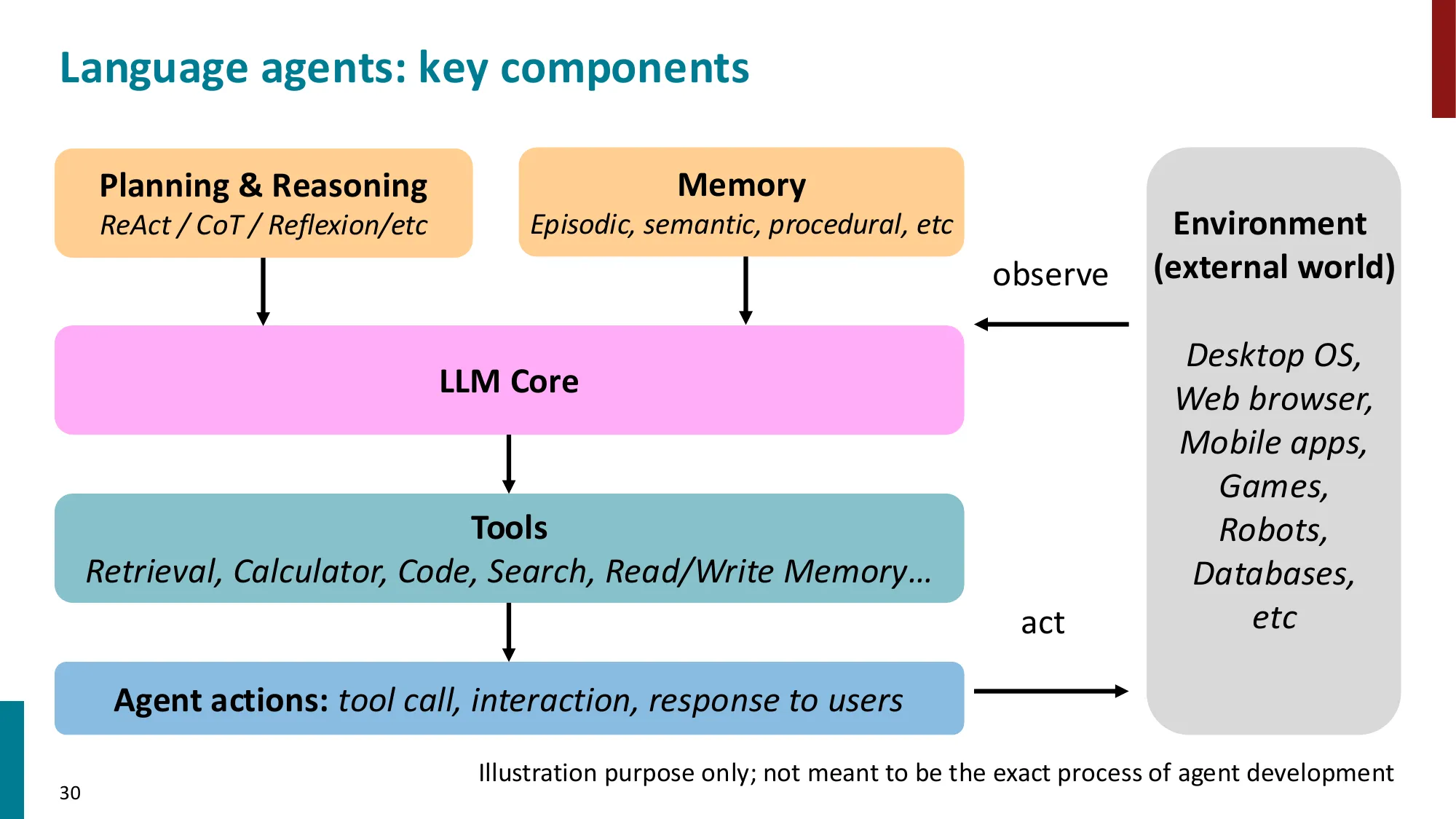
- LLM 作为 agent 的核心:感知 -> 推理 -> 行动
- Agent = LLM + 工具 + 记忆 + 规划
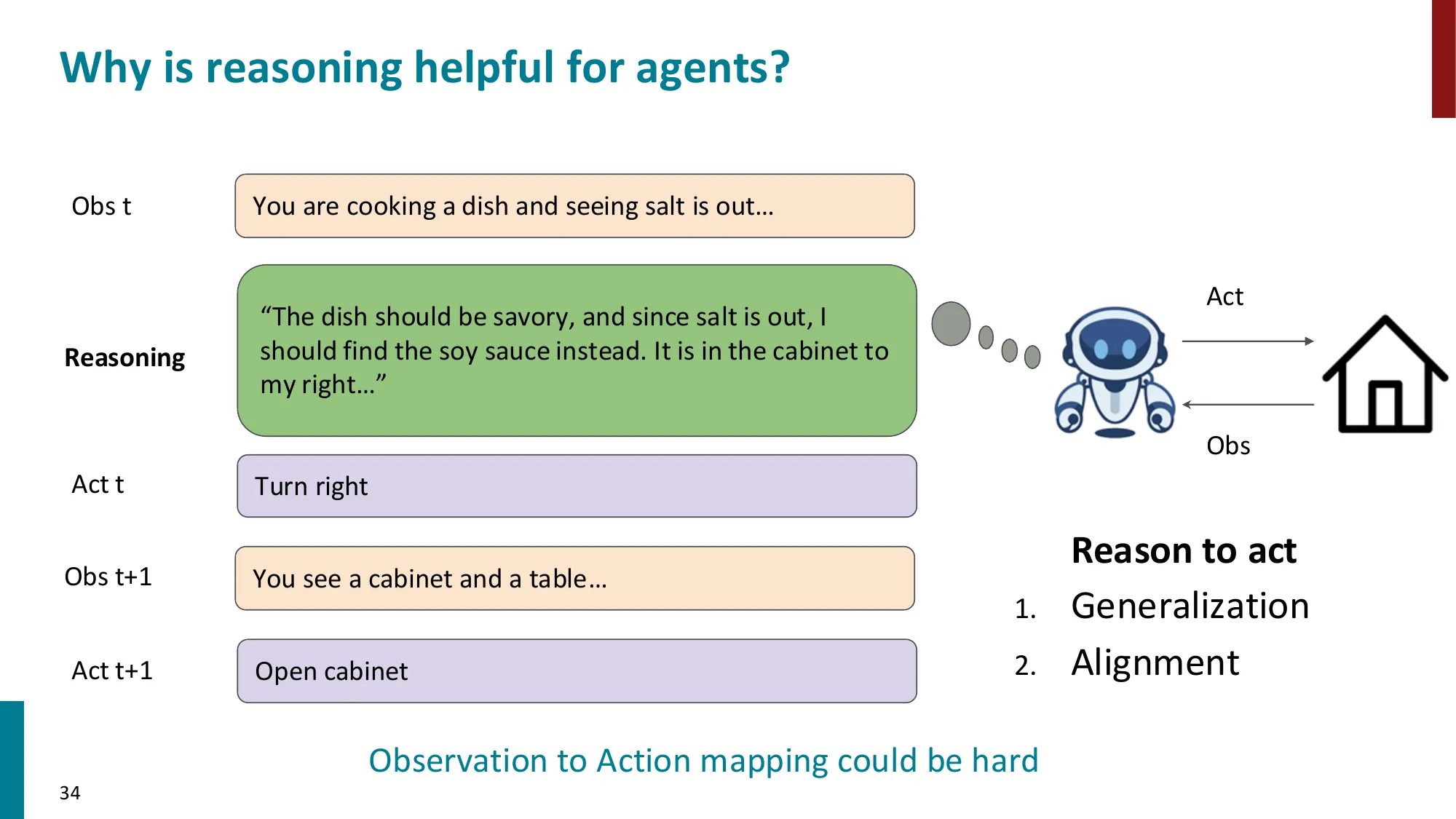
📐 ReAct 框架的形式化
Agent 的决策轨迹 ,其中 是观察(observation), 是动作(action)。
ReAct(Yao et al., 2023) 的动作空间扩展为三类:
- Think:(内部推理步骤,不改变环境,仅更新上下文)
- Act:(调用外部工具)
- Observe:(处理工具返回结果)
策略由 LLM 参数 决定:
与纯 CoT(仅有 Think,无 Act)的区别:ReAct 的 Think 步骤可以更新内部状态,而不是仅仅生成最终答案。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
ReAct 在 HotpotQA(多跳推理问答)上的一个真实轨迹示例:
问题:“LangChain 的创始人在哪所大学读的本科?”
Thought: 需要先找到 LangChain 的创始人是谁
Act: Search("LangChain founder")
Observe: "LangChain was founded by Harrison Chase..."
Thought: 知道创始人了,现在查他的学历
Act: Search("Harrison Chase education undergraduate")
Observe: "Harrison Chase attended Harvard University..."
Thought: 找到答案了
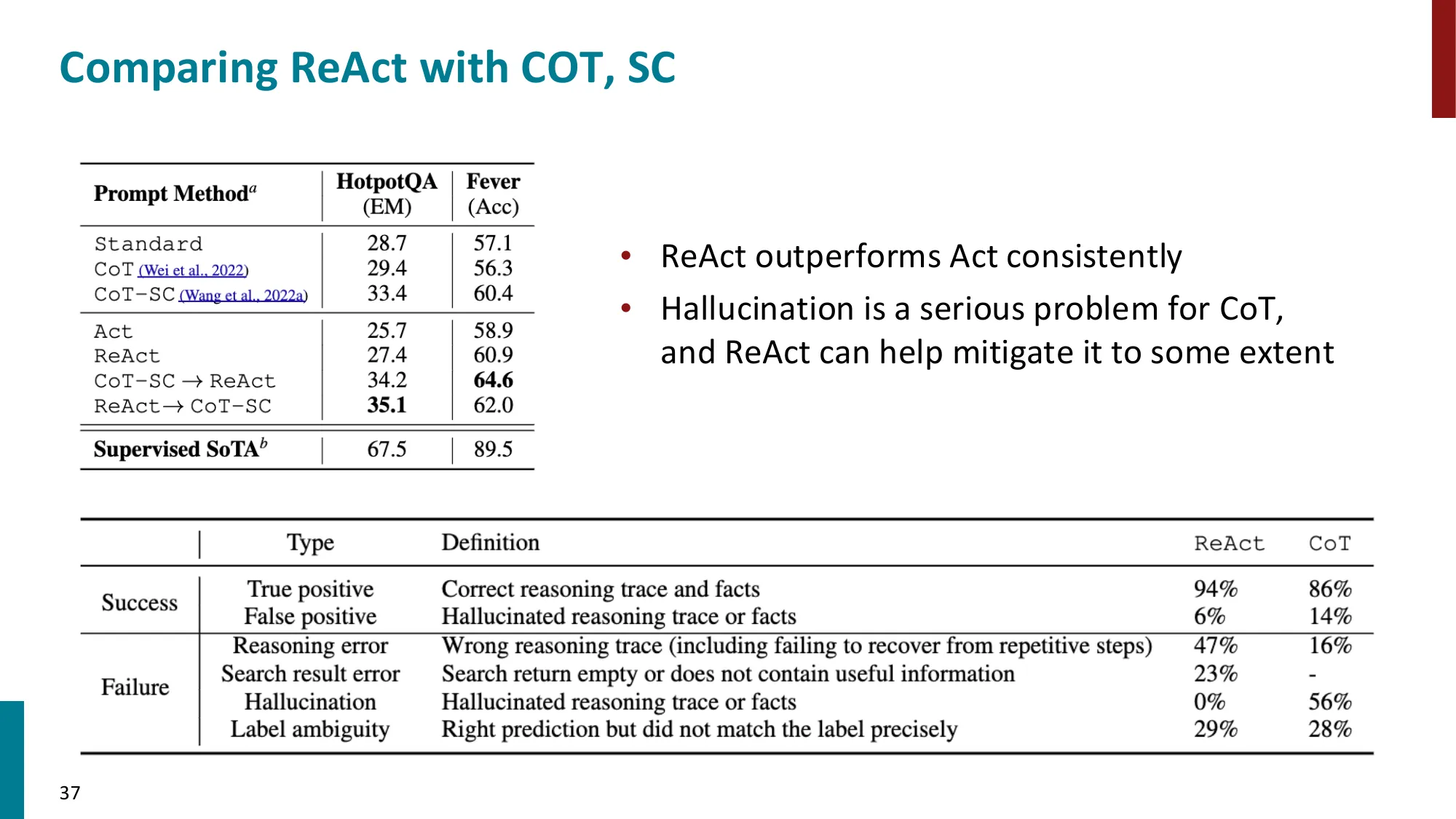
Act: Answer("Harvard University")ReAct vs CoT 在 HotpotQA 上:ReAct 准确率约 35%,CoT 约 29%,纯提示约 21%。
⚠️ 常见误区
- 误区:Language Agent = 真正意义上的 AI Agent → 正确:当前 LLM-based agent 的主要问题:规划能力弱(无法可靠地做超过 5-10 步的长距离规划)、工具调用容易出错(JSON 格式错误、参数理解错误)、记忆管理简陋(长对话性能下降)。“Agent”这个词在工业界被严重过度宣传。
3. 推理与规划(Reasoning & Planning)
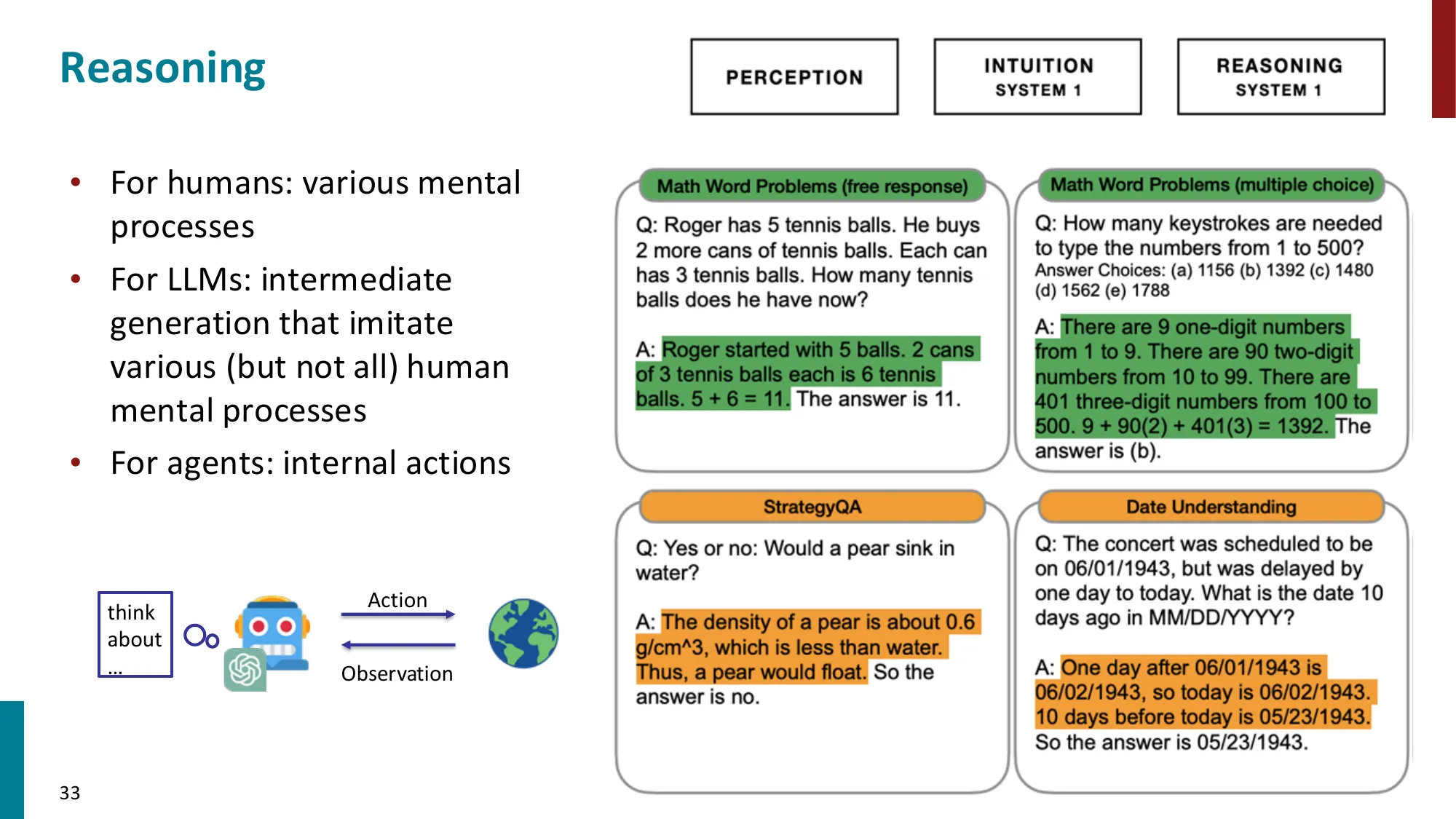


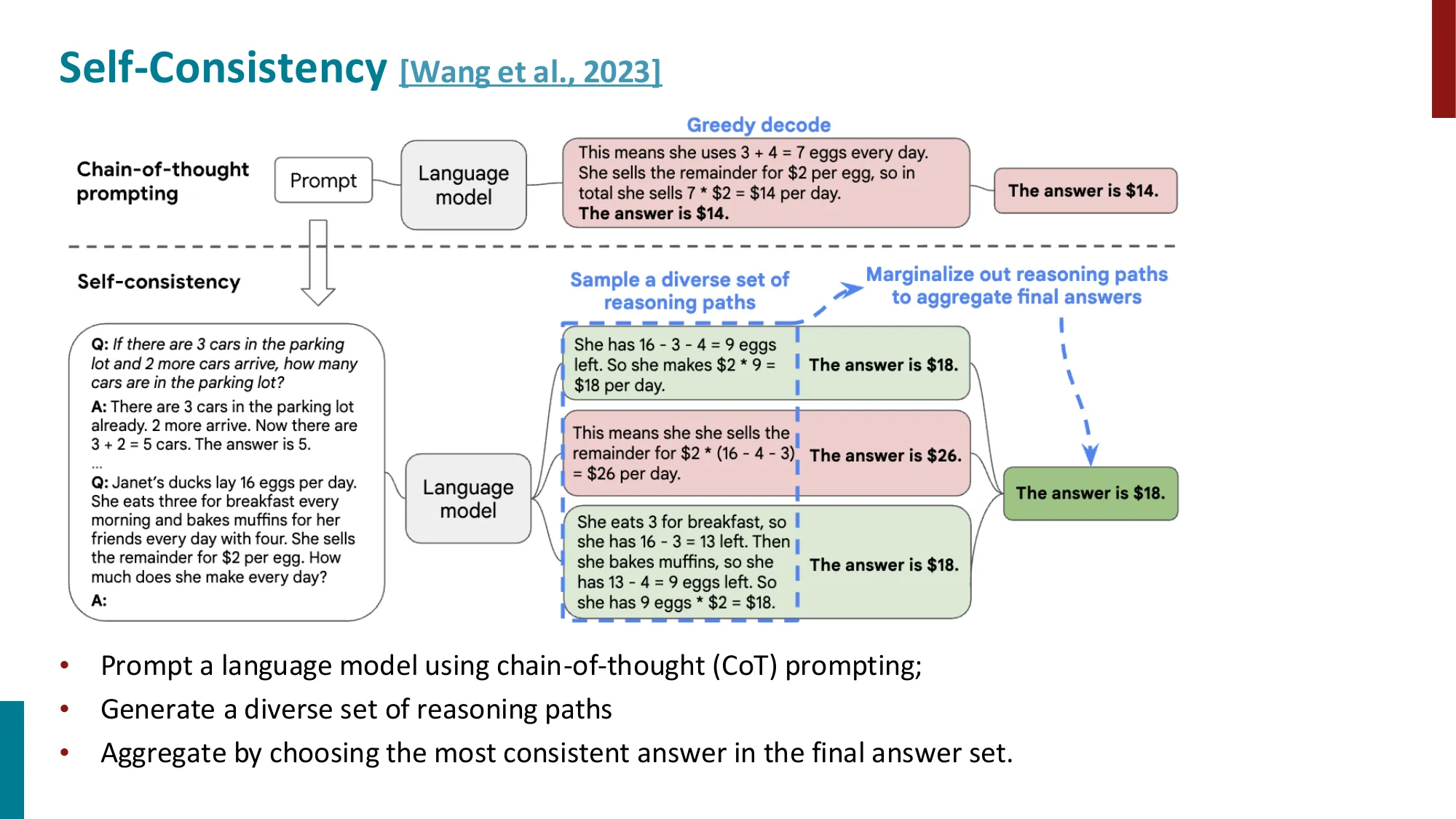
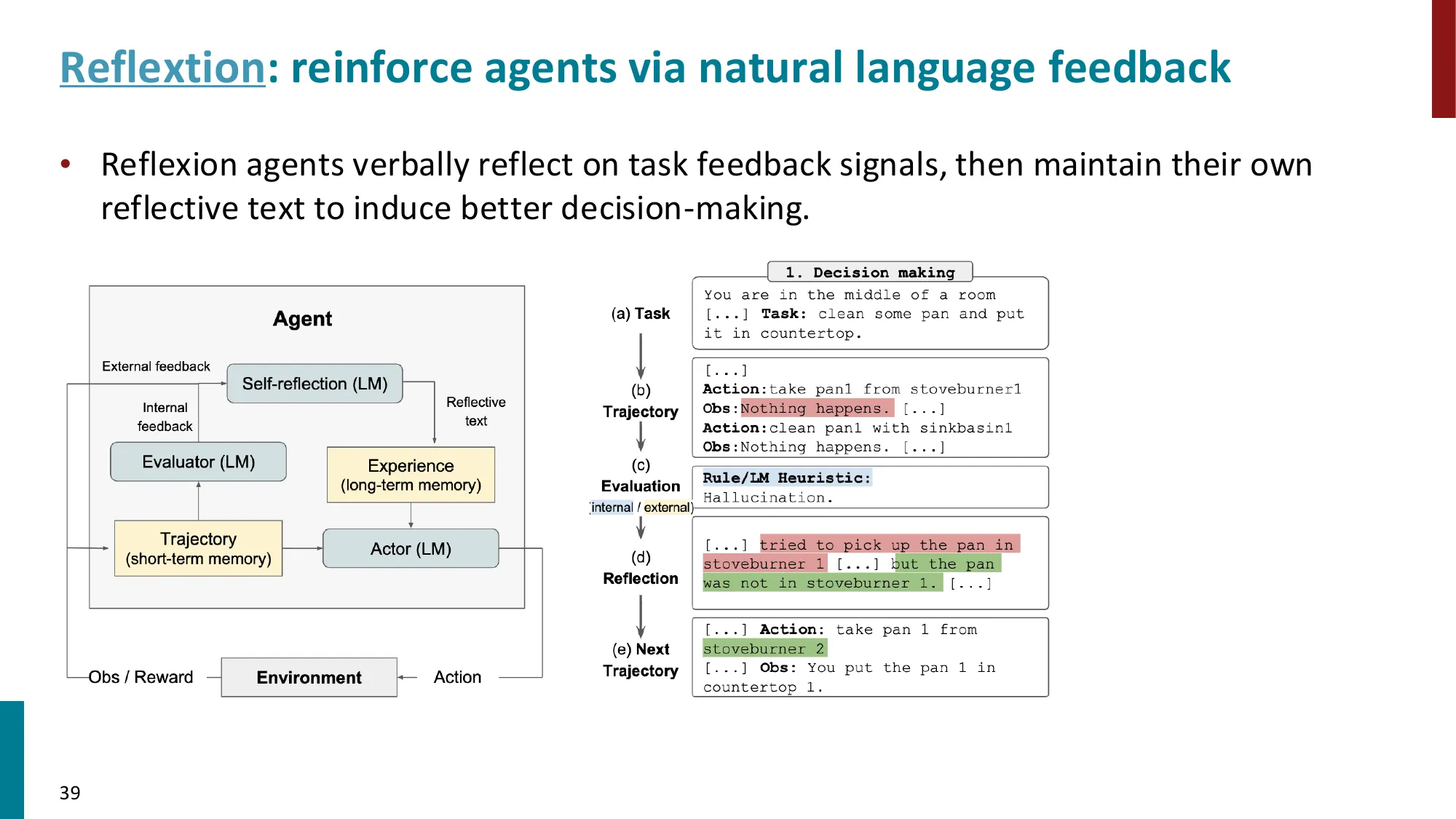



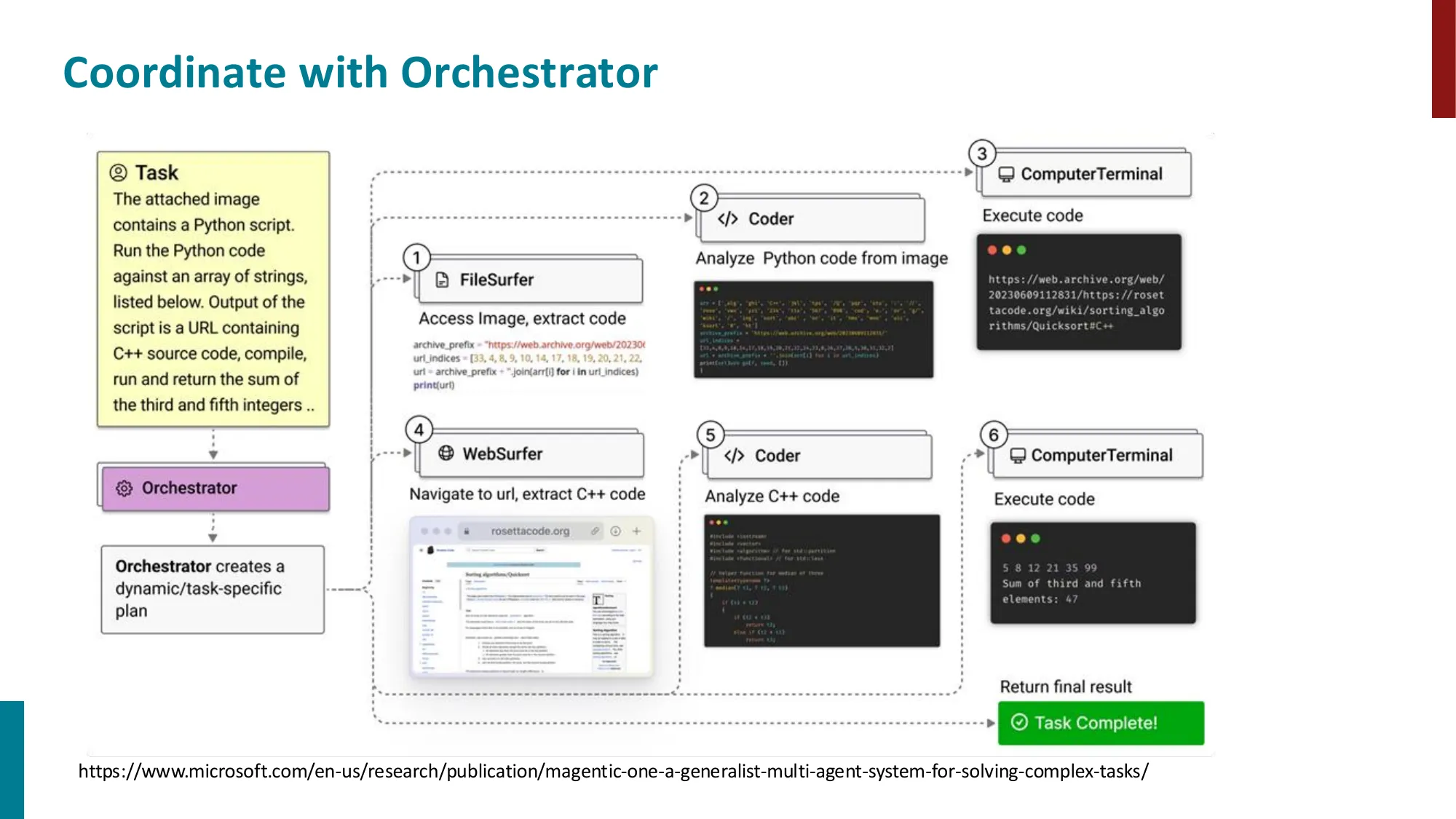
- ReAct:交替 Thought + Action + Observation
- Chain-of-Thought 推理在 agent 场景中的应用
- 规划方法:任务分解、子目标设定
📐 Tree-of-Thought(ToT)的形式化
标准 CoT(线性推理链):
ToT(Yao et al., 2023):维护推理树 ,节点为推理状态 :
- 生成:(采样多个候选下一步,宽度 )
- 评估:(用 LLM 自评当前状态的价值)
- 搜索:BFS(按层展开)或 DFS(深度优先)或 MCTS(蒙特卡洛树搜索)
关键区别:CoT 在错误分支上一路走到黑;ToT 可以**回溯(backtrack)**并探索其他分支。
MCTS 的 UCB 选择公式(用于引导搜索):
其中 是价值估计, 是访问次数, 控制探索-利用权衡。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
Game of 24(用 4 个数字通过加减乘除凑出 24)的成功率对比:
| 方法 | 成功率 |
|---|---|
| 标准提示(Standard I/O) | 4% |
| CoT(逐步推理) | 4% |
| ToT(BFS,宽度=5) | 74% |
数独任务(9×9):
- CoT 成功率:0%(一旦某个数字填错无法回溯)
- ToT(DFS + 剪枝):显著提升,但仍受限于评估函数质量
💡 为什么这样做?
人类解难题时不是线性的——我们会尝试多种思路、发现死路后退回来。CoT 强迫 LLM 按序生成,相当于”不能打草稿”。ToT 恢复了这种探索能力,代价是计算量增加(需要多次 LLM 调用)。本质上,ToT 是在”慢思考”(System 2)和”快思考”(System 1)之间做选择。
⚠️ 常见误区
- 误区:更复杂的推理策略总是更好 → 正确:ToT 对简单问题是浪费(计算代价是 CoT 的 倍, 为宽度, 为深度),只对需要搜索的组合问题有优势。现代 o1/o3 类模型将”何时深思”的决策内化到训练中,而非每次都用 ToT。
- 误区:o1 就是 ToT → 正确:o1 的内部推理机制未完全公开,更可能是通过 RLHF 训练的内化推理过程,而非显式树搜索。
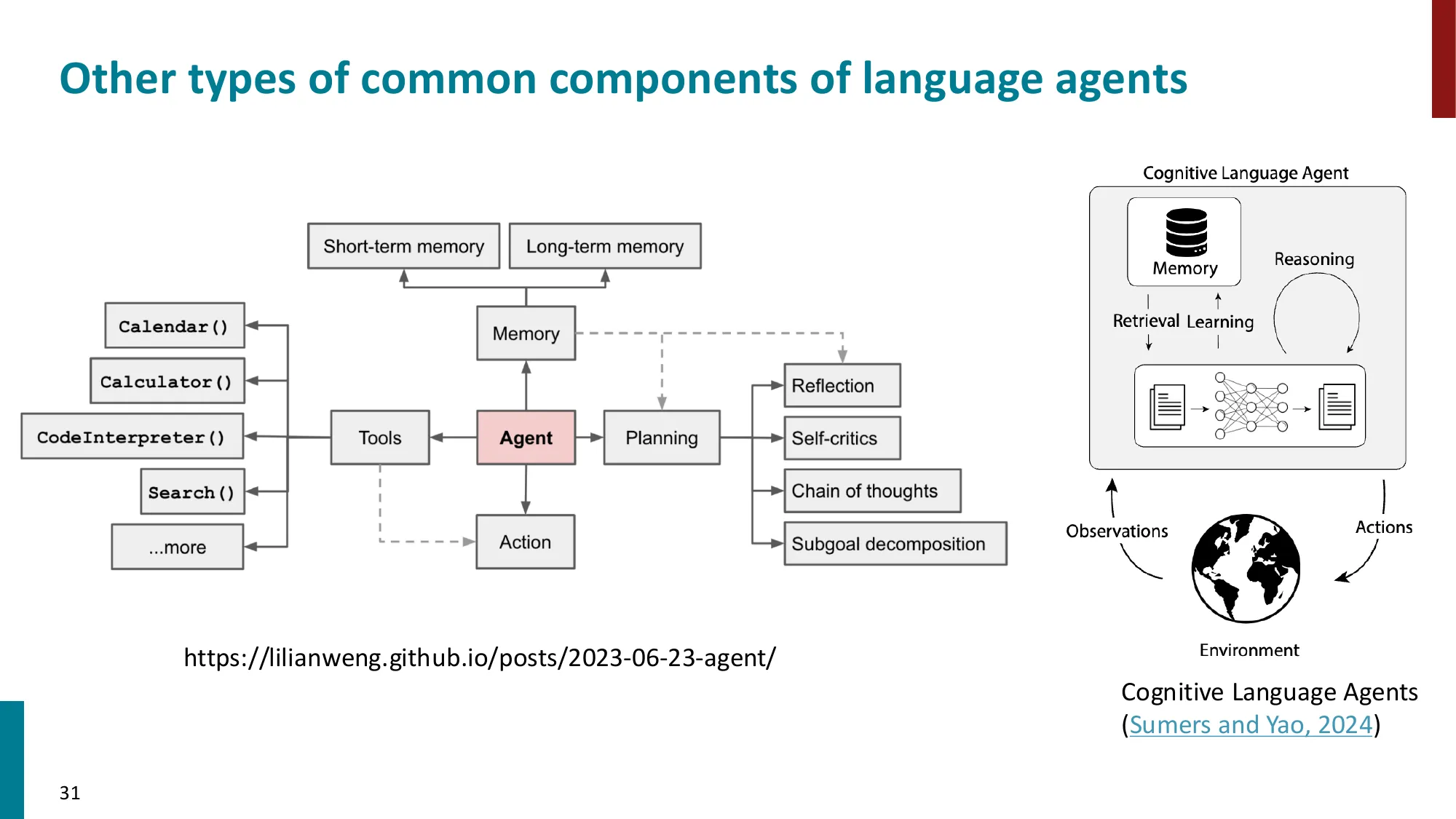
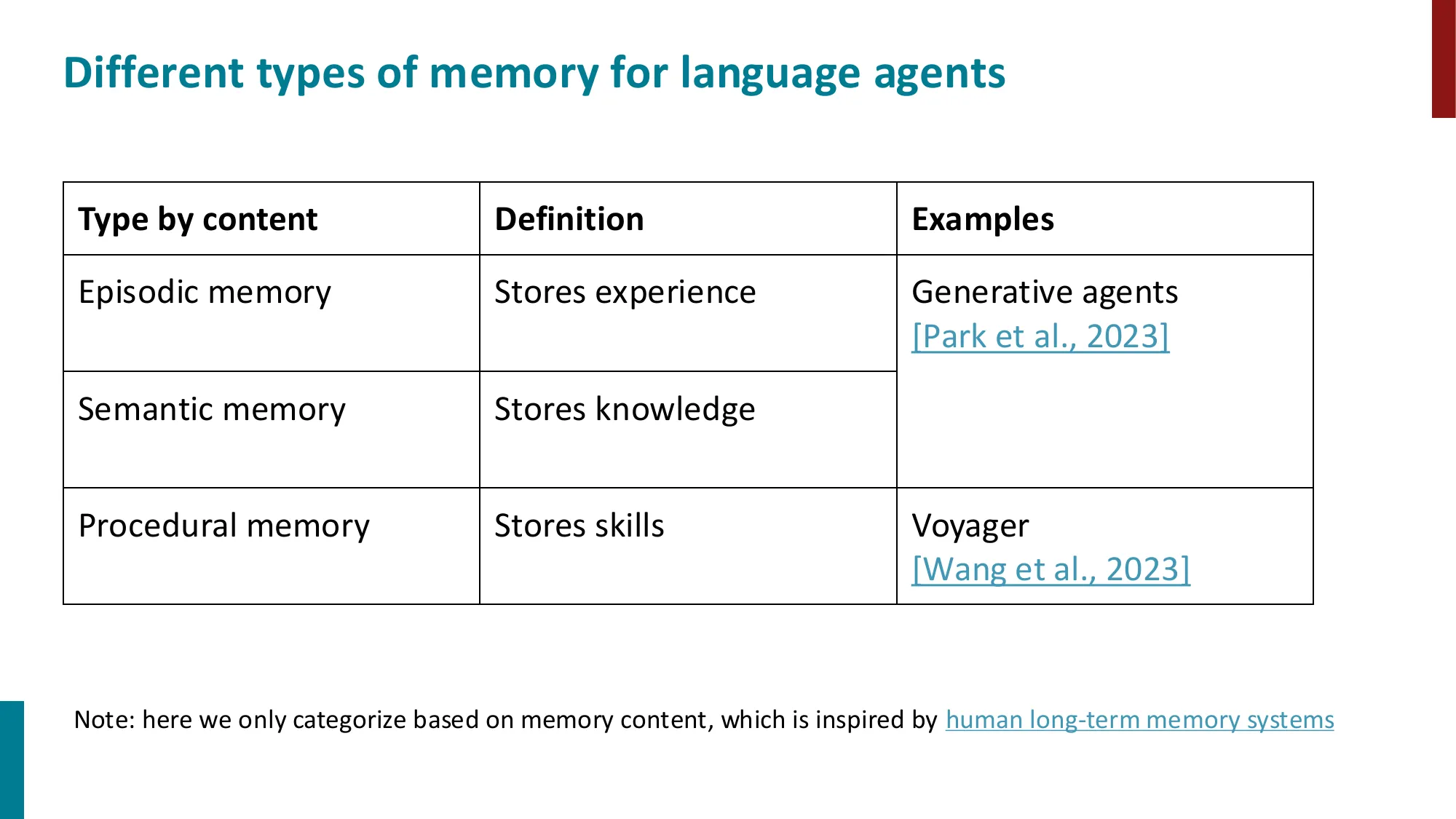
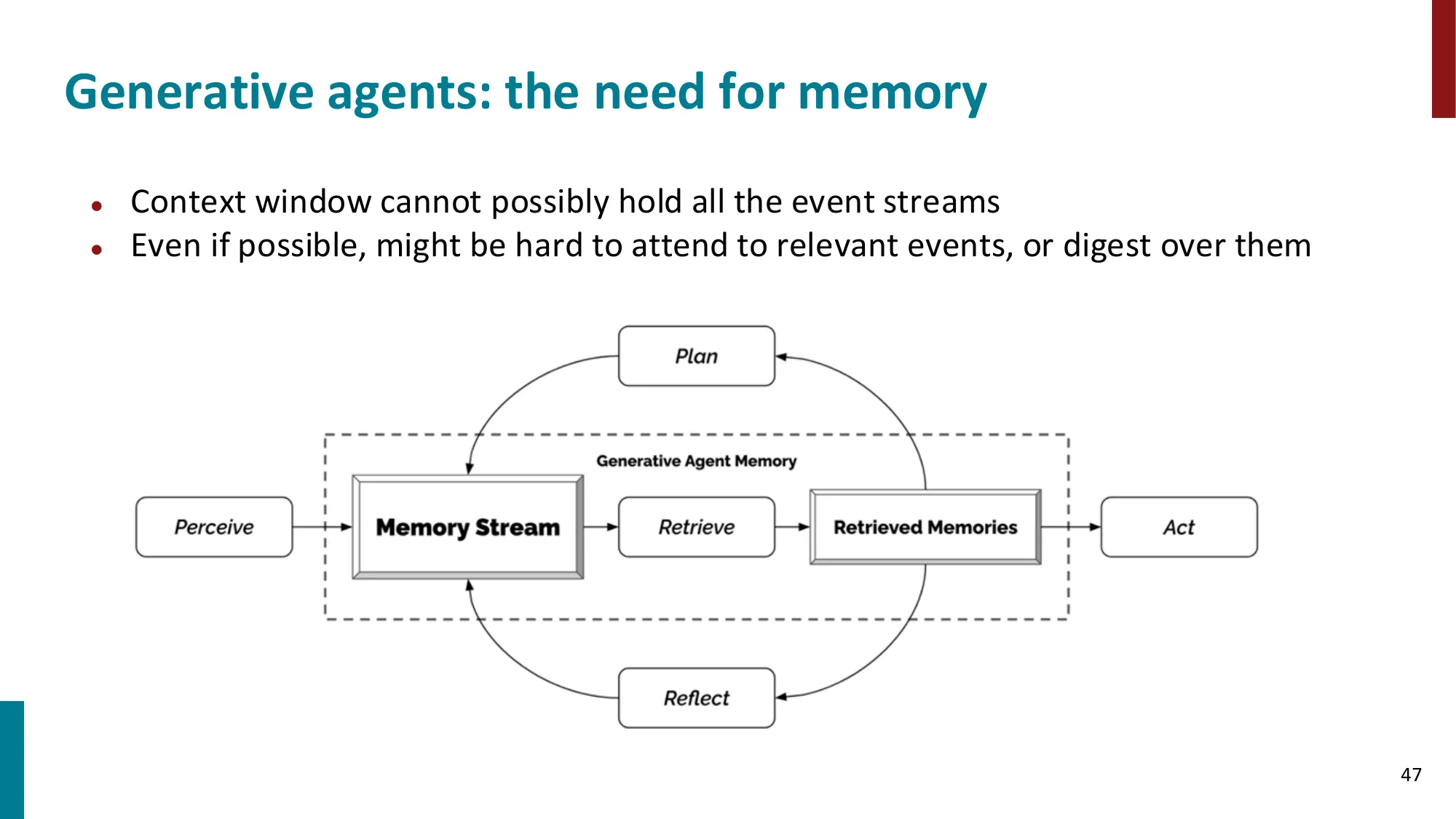
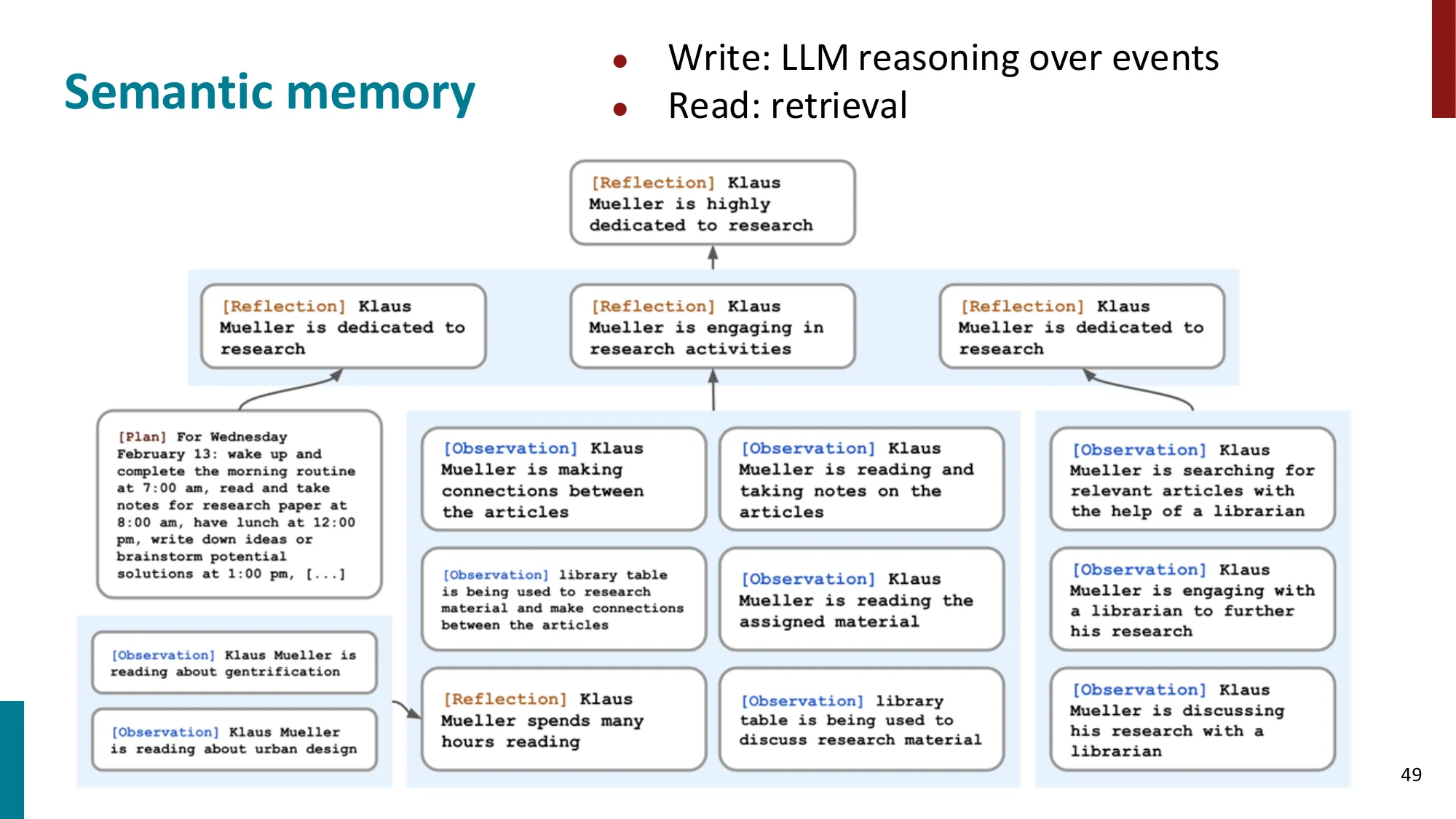
4. 记忆(Memory)
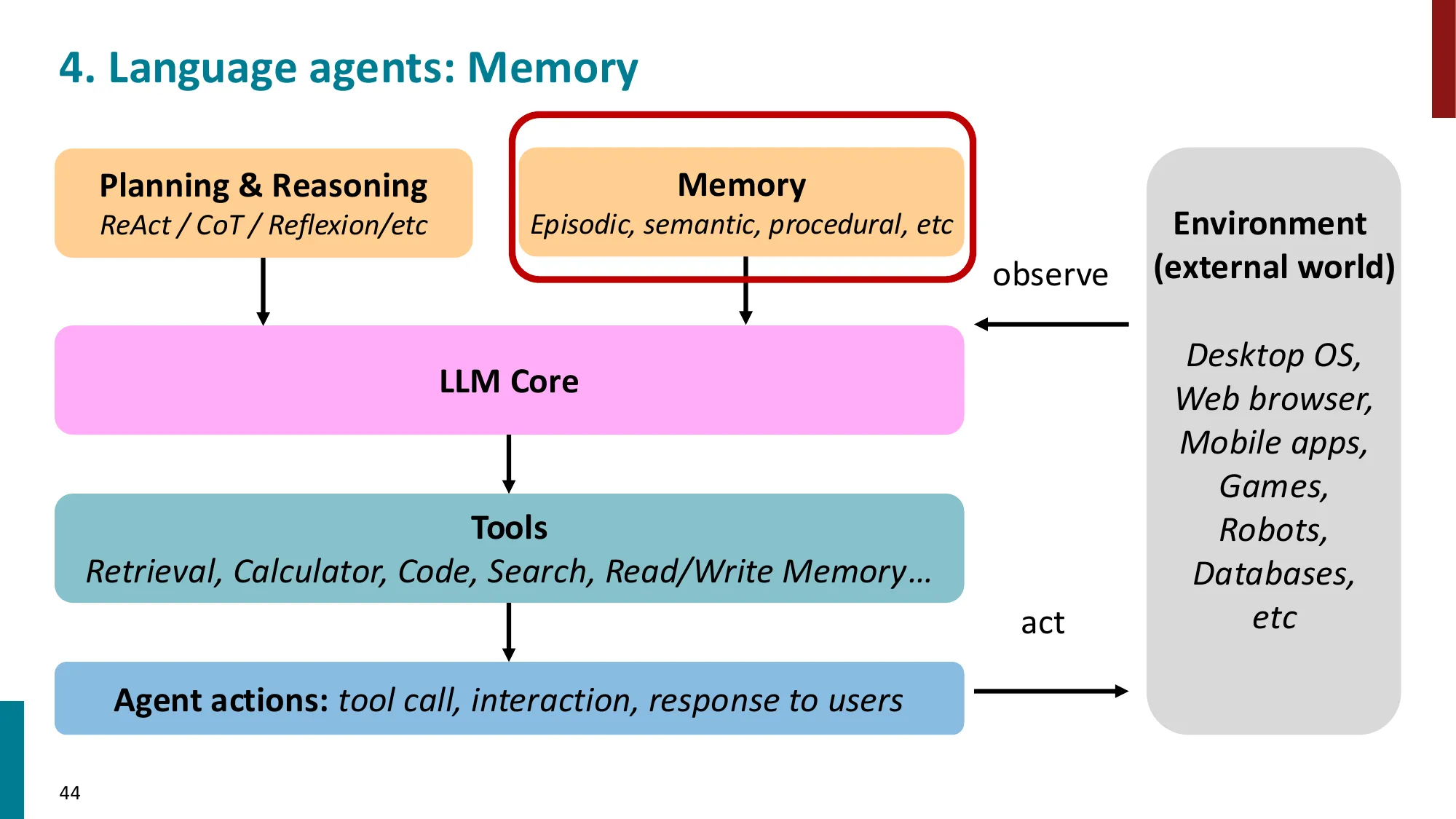

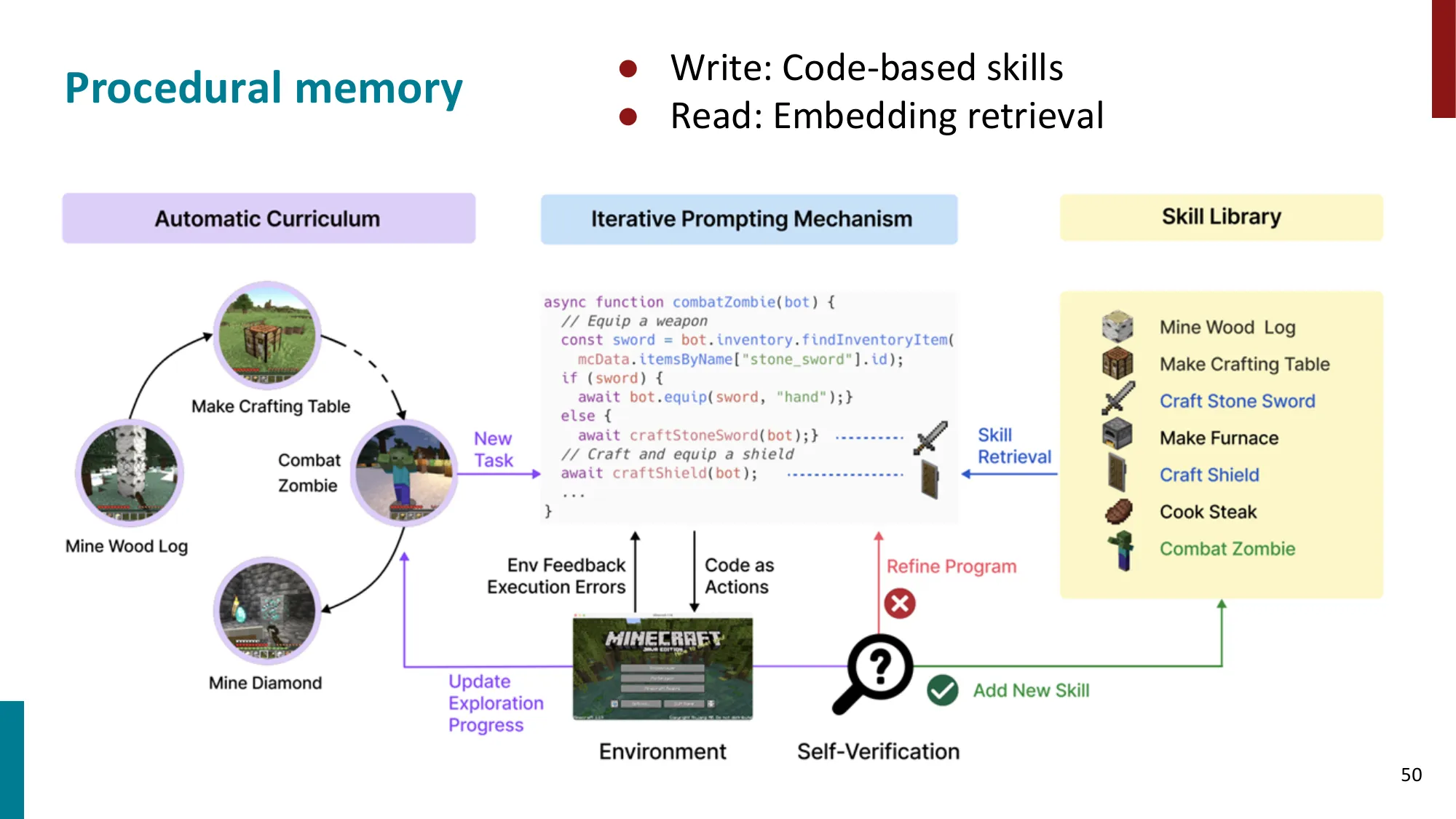
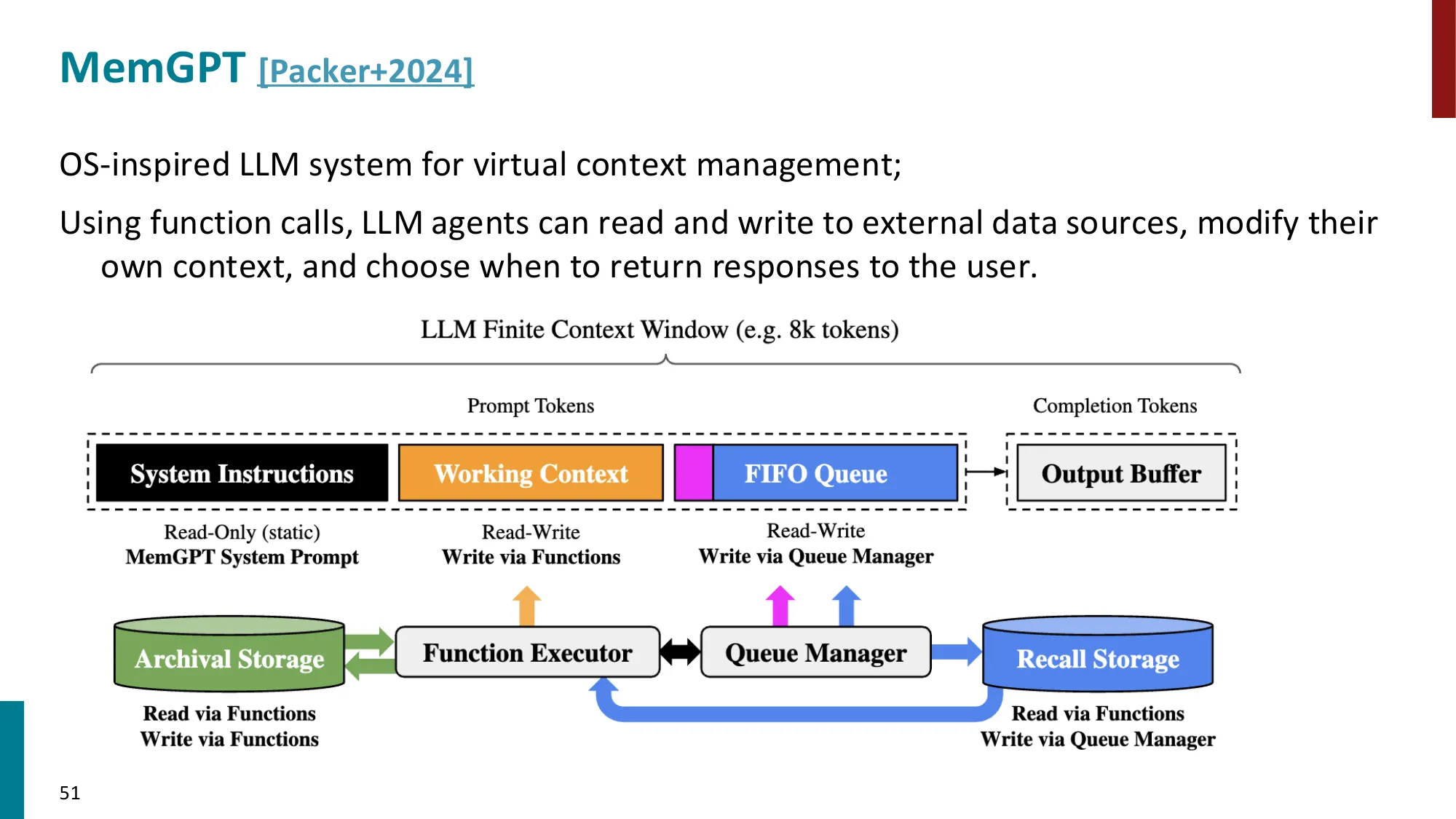
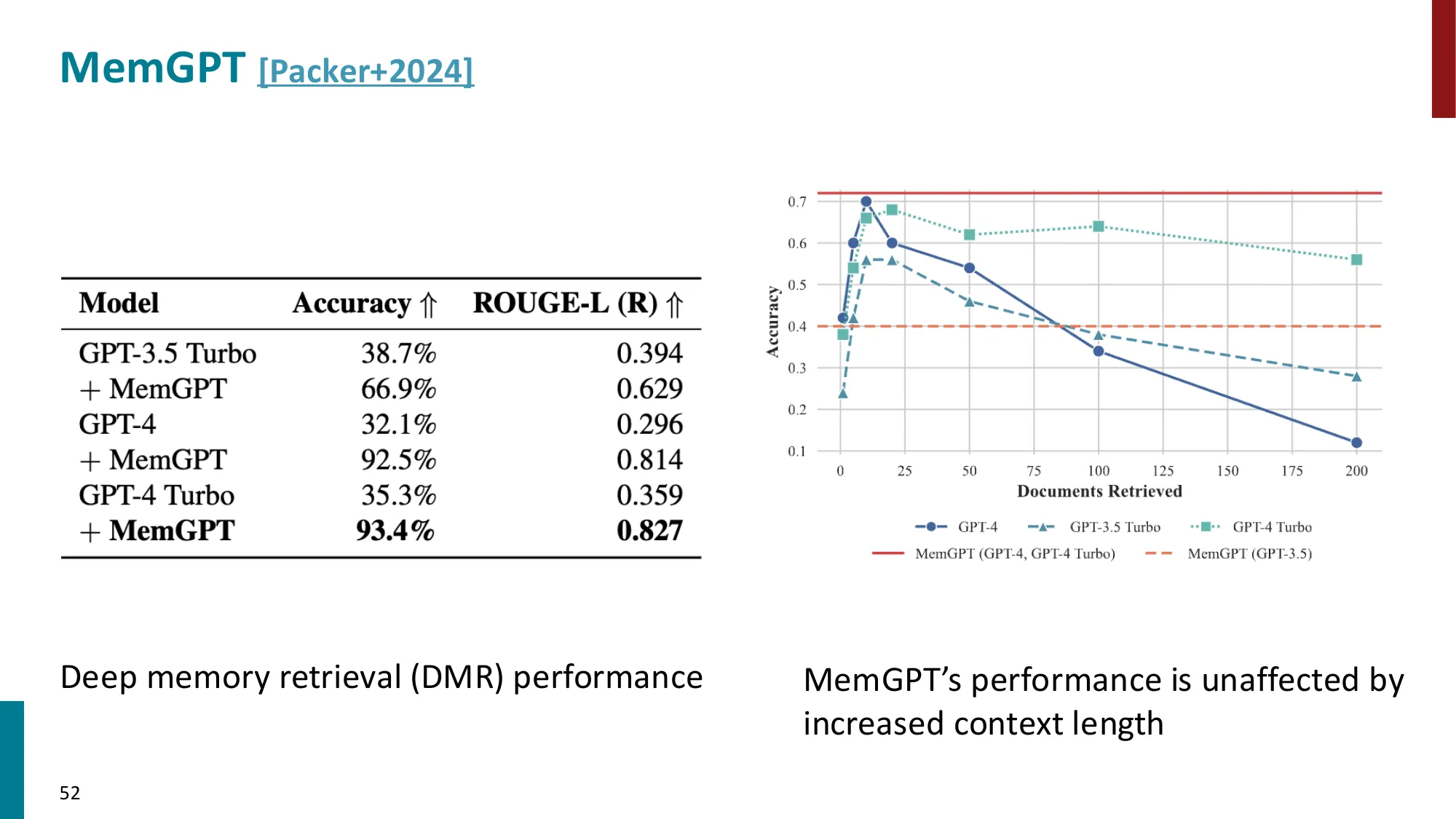
- 短期记忆:上下文窗口内的对话历史
- 长期记忆:外部存储(向量数据库、知识图谱)
- 工作记忆 vs 情景记忆 vs 语义记忆
📐 LLM Agent 的四种记忆类型
| 记忆类型 | 存储位置 | 访问方式 | 容量 | 可更新 |
|---|---|---|---|---|
| In-context(工作记忆) | Context window | 直接(注意力) | tokens(有限) | 否(会话结束后丢失) |
| External(外部记忆) | 向量数据库 | 检索(MIPS) | 理论无限 | 是(可随时写入) |
| In-weights(参数记忆) | 模型权重 | 隐式(推理) | 无限但模糊 | 需要 fine-tuning |
| In-cache(KV 缓存) | GPU/CPU 内存 | 前缀重用 | 受内存限制 | 否 |
外部记忆的检索公式:
其中 是用嵌入模型预计算的文档向量,FAISS/Chroma/Pinecone 等向量数据库负责高效近似搜索。
KV 缓存加速:若前 个 token 相同(系统提示),预计算并缓存其 Key/Value 矩阵,推理时直接复用,避免重复计算。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
ChatGPT Memory 功能(2024 年发布)的工作原理(近似):
- 用户说:“我叫 Alice,是一名机器学习工程师,喜欢 PyTorch”
- 系统提取关键事实 → 写入向量数据库:
{fact: "用户叫 Alice", embedding: [...]} - 下次对话:检索 “user preferences/identity” → 召回相关记忆
- 注入 system prompt:“用户叫 Alice,是 ML 工程师,偏好 PyTorch”
本质:RAG 应用于个性化记忆。实际系统还需要记忆去重(新信息和旧记忆冲突时以新为准)和遗忘策略(重要性衰减)。
⚠️ 常见误区
- 误区:Context window 大(1M token)就不需要外部记忆 → 正确:即使 LLM 有 1M token context,把所有历史塞进去会导致注意力分散(Lost in the Middle 问题:LLM 对 context 中间部分的信息利用率显著低于开头和结尾);此外推理成本随 context 长度二次增长(),检索式记忆仍然更高效。
- 误区:In-weights 记忆最可靠 → 正确:参数记忆存在”幻觉”——模型把常见的错误信息也记进了权重(如错误的历史日期、虚假的科学”事实”)。外部记忆+来源验证是更可靠的事实获取方式。
5. 工具使用(Tool Use)
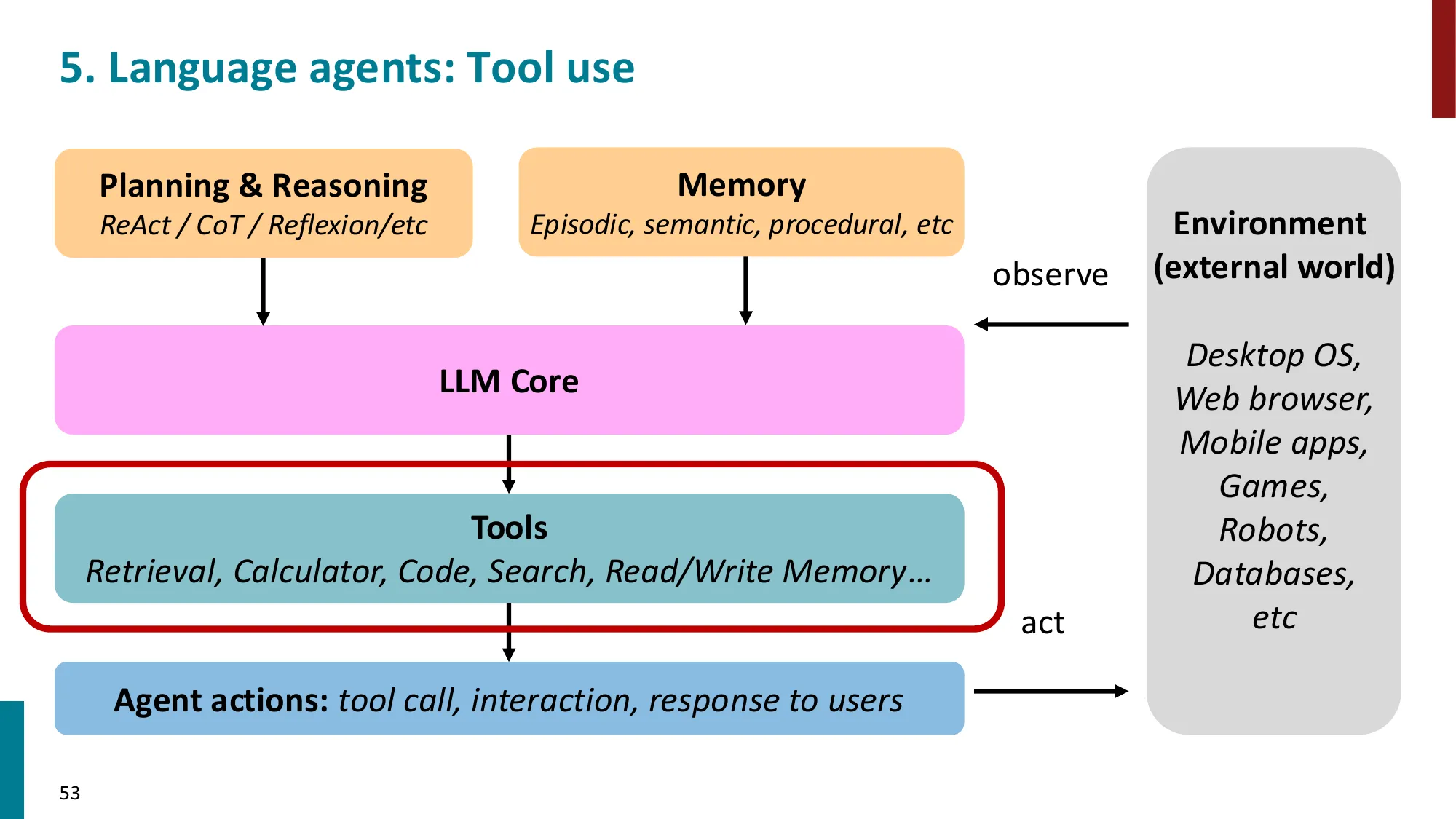
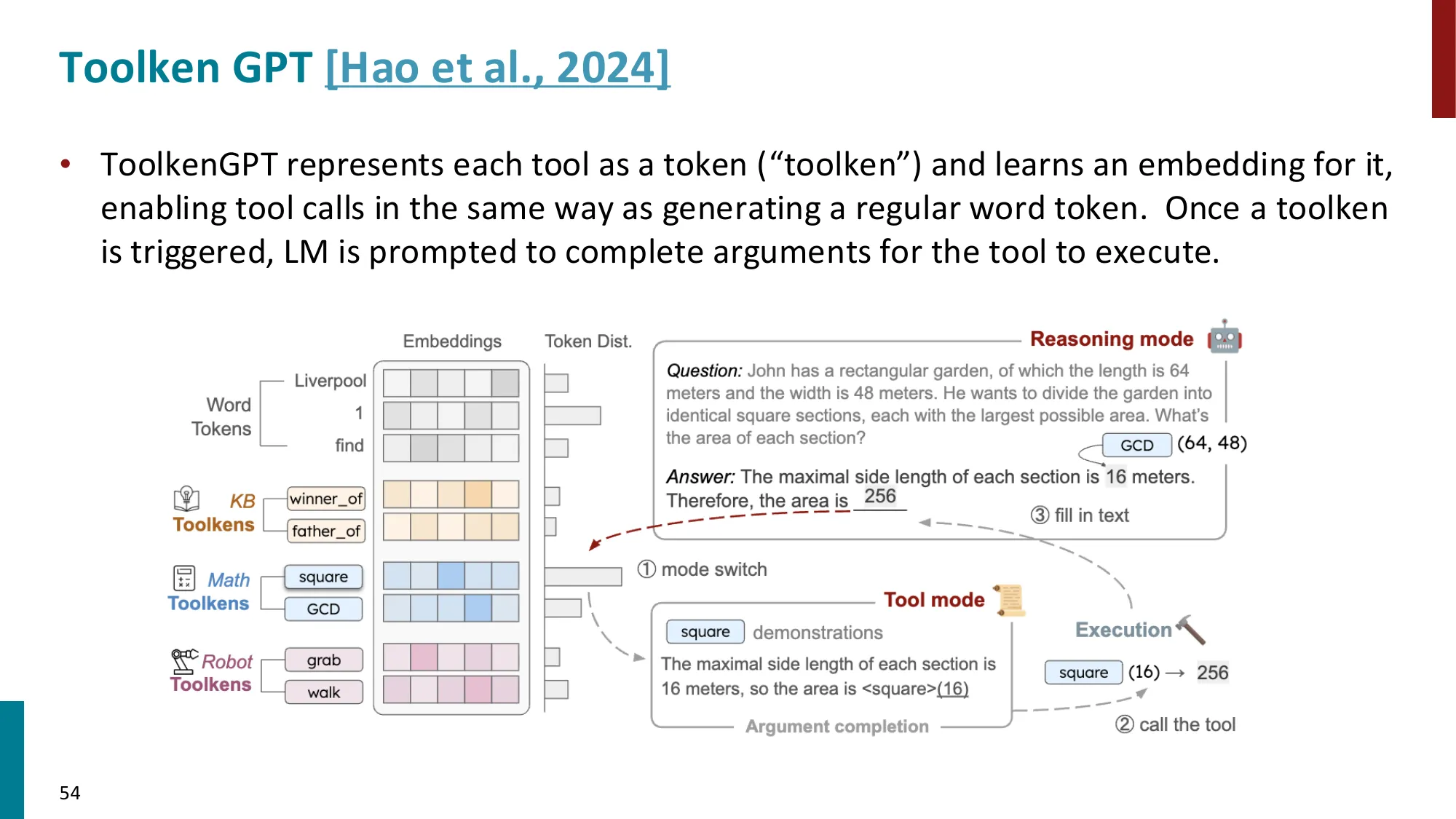


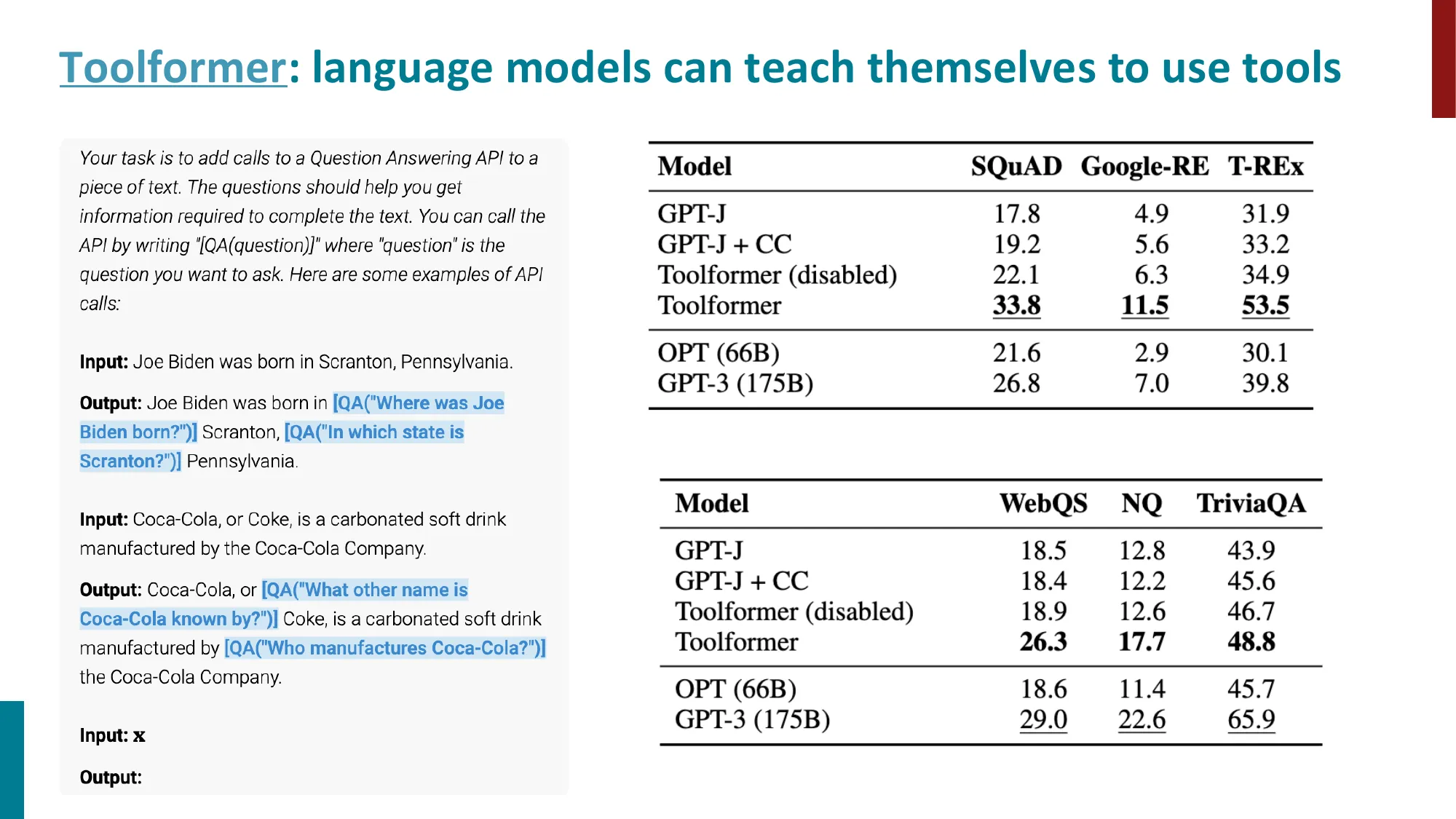
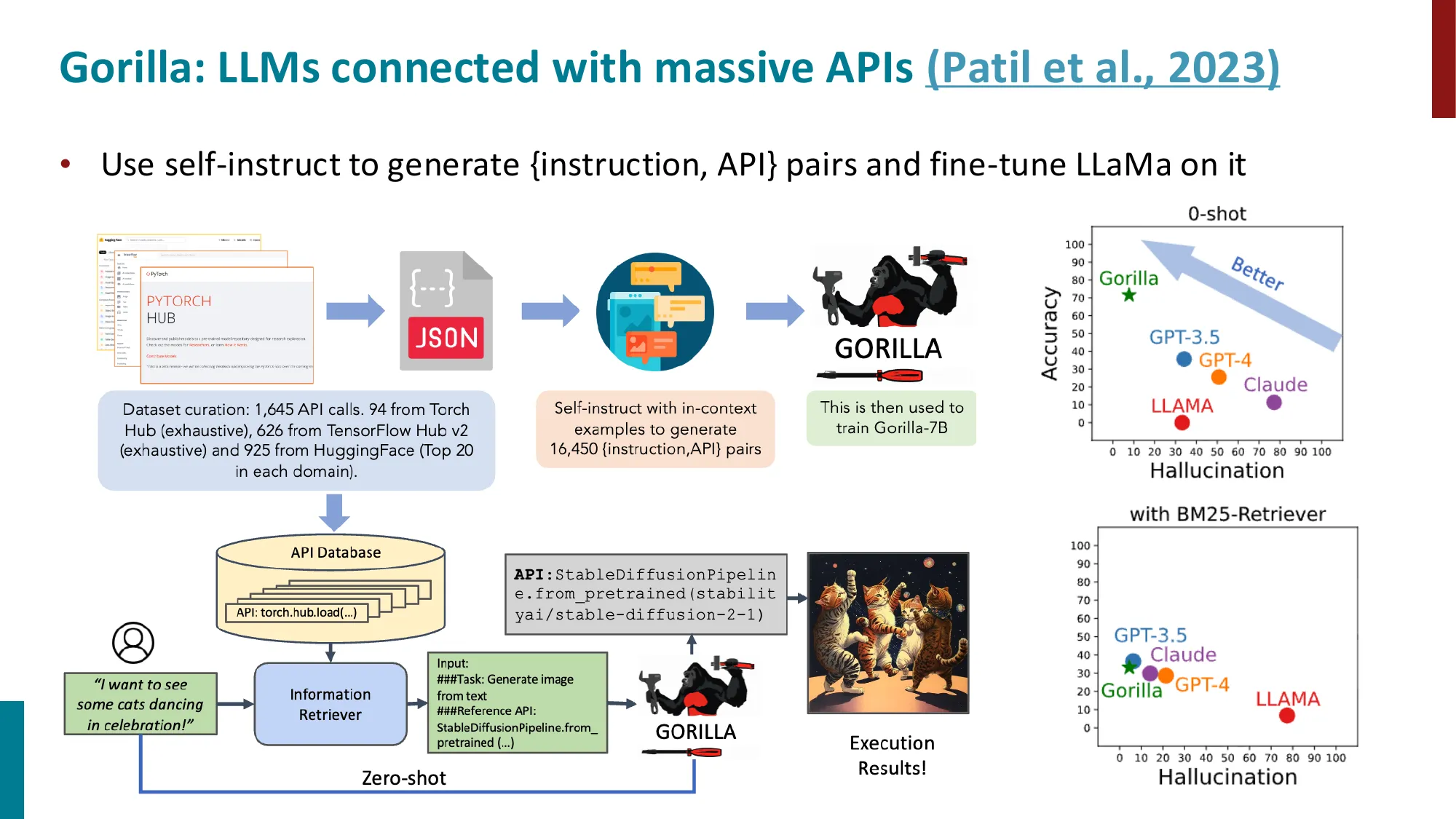
- Toolformer:LM 自学使用 API 工具
- 工具类型:搜索引擎、计算器、代码执行器、数据库查询
- Function calling 接口
📐 Function Calling 的形式化
给定工具定义集合 ,工具调用轨迹:
工具执行 ,结果注入下一步 context:
Toolformer(Schick et al., 2023) 的自监督训练方式:
- LM 采样可能的工具调用位置和参数
- 执行工具,获得结果
- 若插入工具结果后 loss 降低,则保留该样本(自我监督过滤)
- 在过滤后的数据上 fine-tune LM
关键指标:工具调用是否降低了后续 token 的 perplexity——这是 Toolformer 的自动标注准则,不需要人工标注”该在何处调用工具”。
📚 已收录至 拓展阅读知识库
🔢 数值/具体示例
代码解释器工具调用示例(Wolfram Alpha + Python):
用户:“计算 ”
- LM 生成:
<calc>sum([k**2 for k in range(1, 1001)])</calc> - Python 执行:
333833500 - LM 整合:“(公式 验证:)”
Toolformer 在数学任务上的性能(近似,Schick et al. 2023):
- 无工具的 GPT-J 6.7B:数学 QA 准确率 ~5%
- Toolformer(调用计算器):~40%(提升 8×)
⚠️ 常见误区
- 误区:工具调用失败是偶发 bug → 正确:工具调用的格式错误是系统性问题——LLM 经常生成不符合 schema 的 JSON(错误的键名、类型不匹配、嵌套层级错误),特别是工具 schema 复杂时。生产系统必须实现 retry 逻辑、schema 验证和错误修正提示(将错误信息反馈给 LLM 重新生成)。
- 误区:工具越多越好 → 正确:工具数量过多(>20)会显著增加 LLM 选错工具的概率(选择混淆),实践中推荐用工具路由(router)先分类再选择。
6. Agent 数据与评估
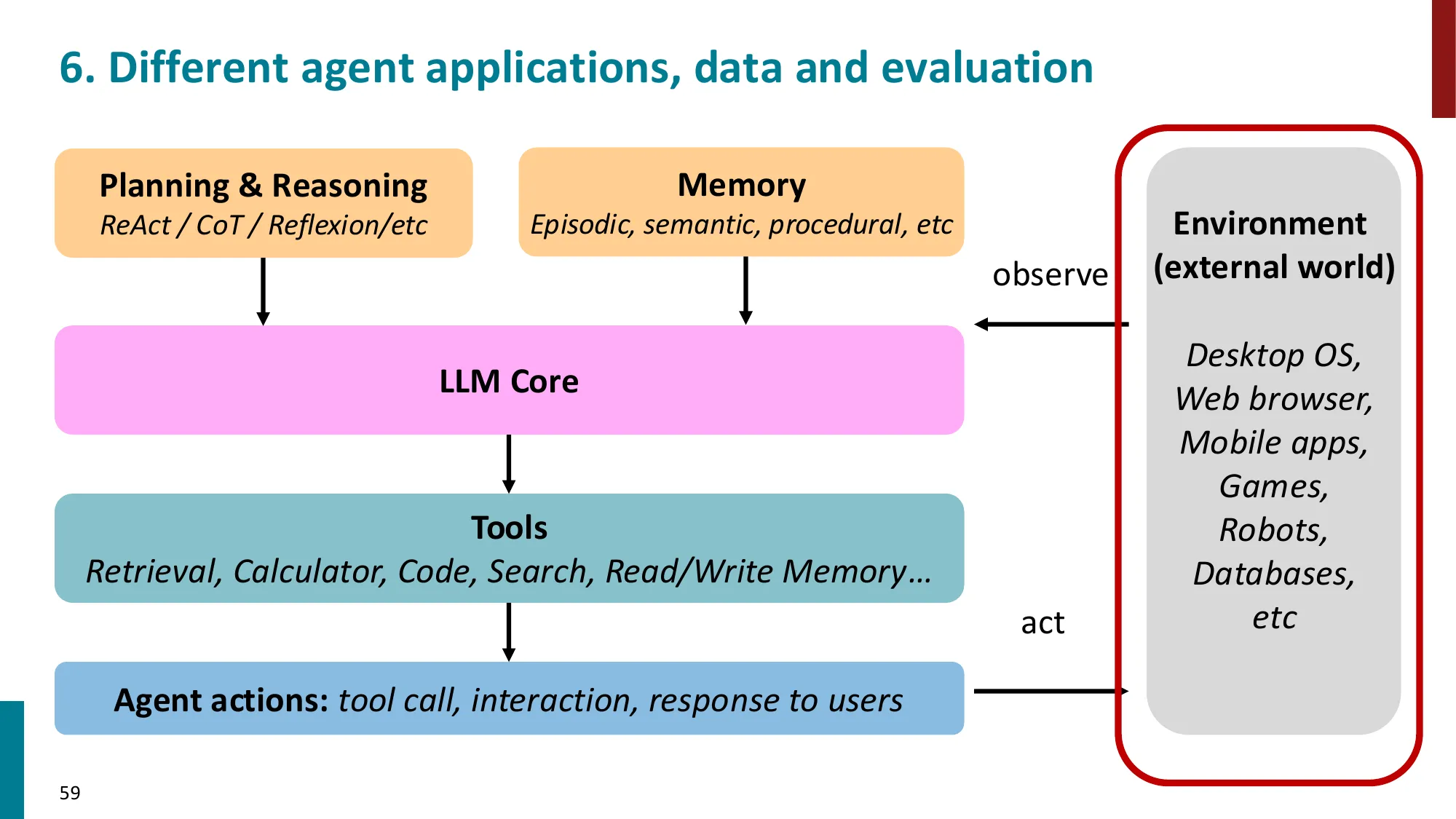
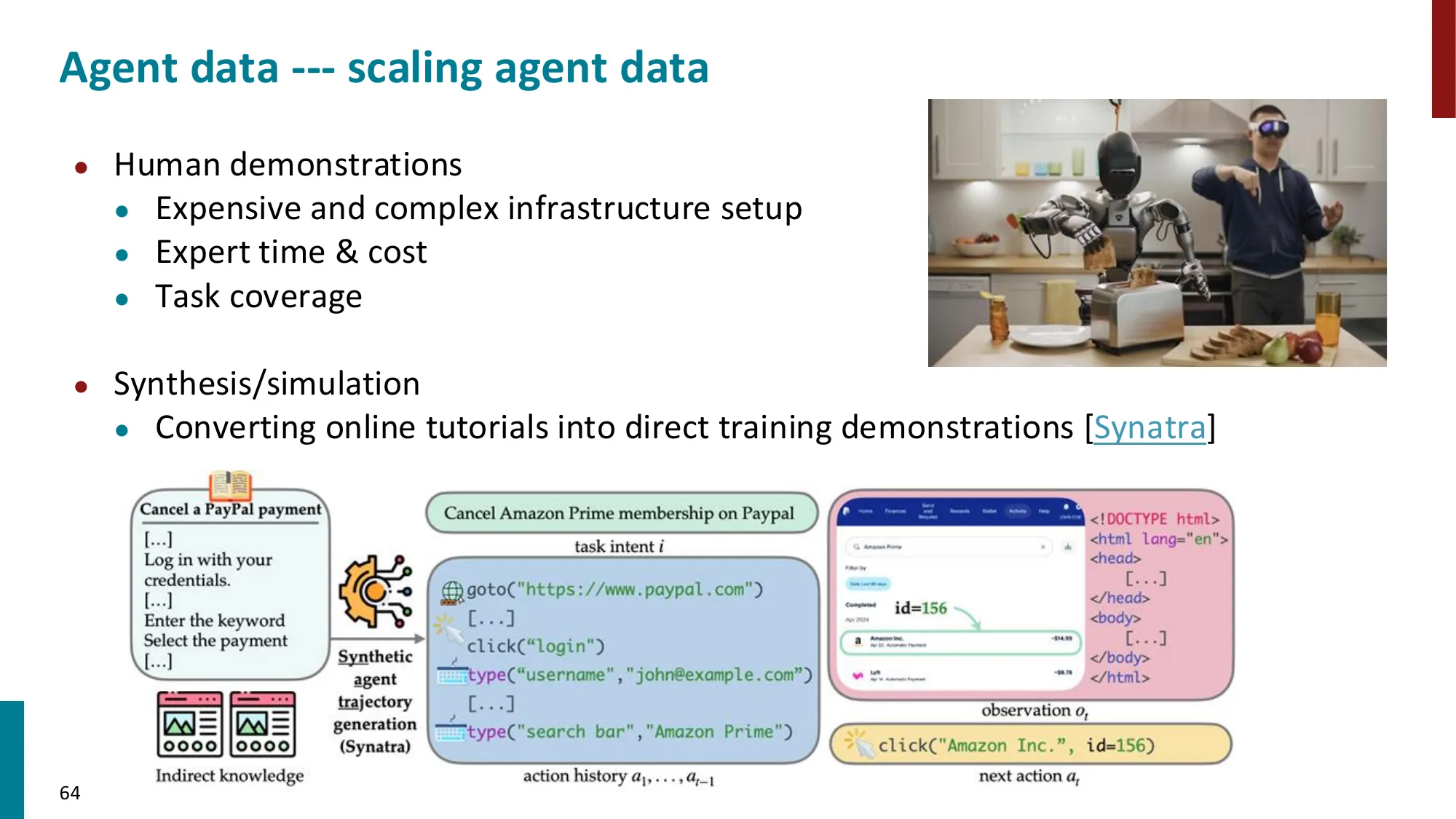
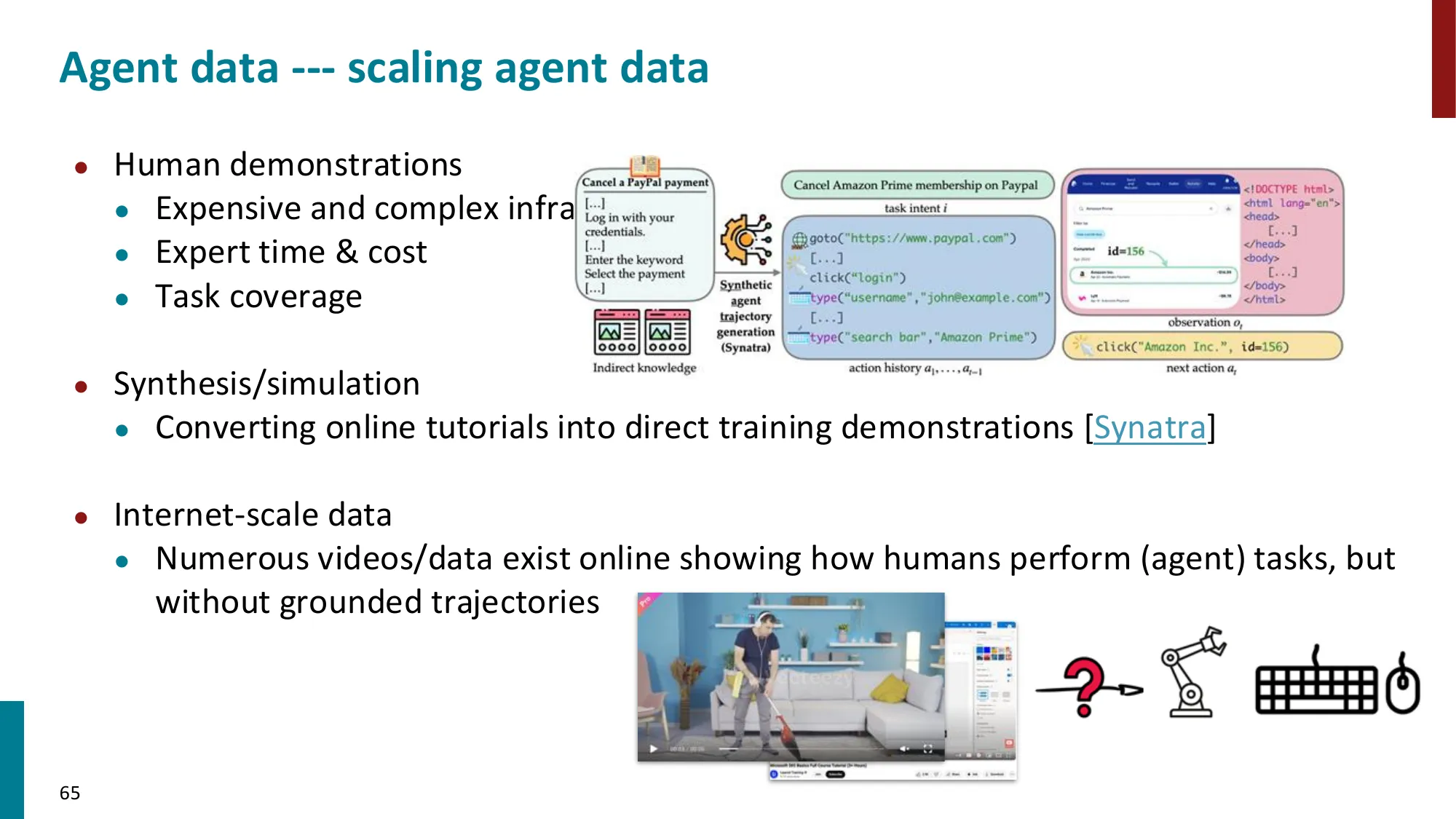
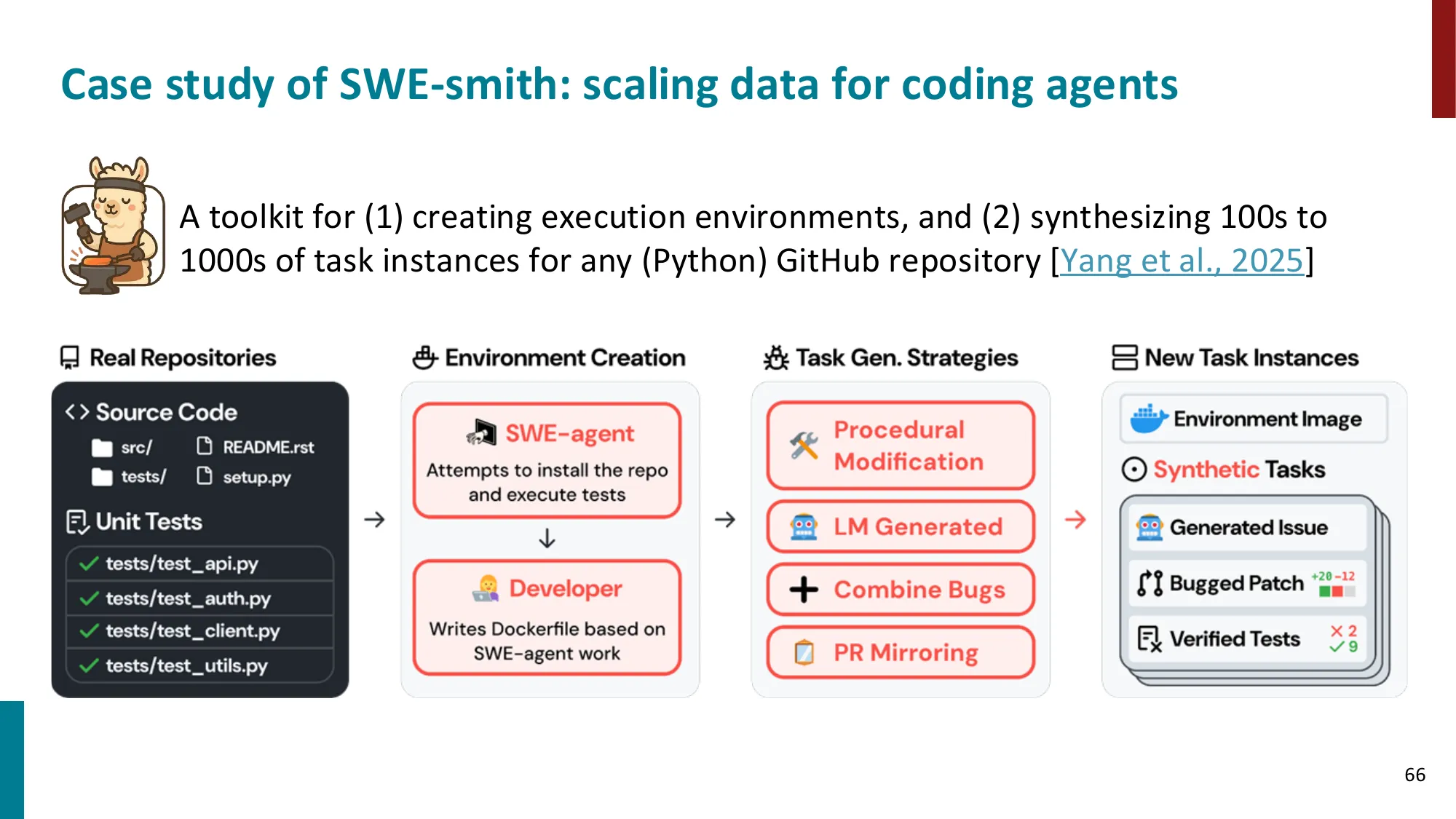





- Agent 评估的挑战:多步推理的正确性、效率、安全性
- 数据收集:人工标注轨迹 vs 模拟环境
- Language-Agents 综述
🔢 数值/具体示例
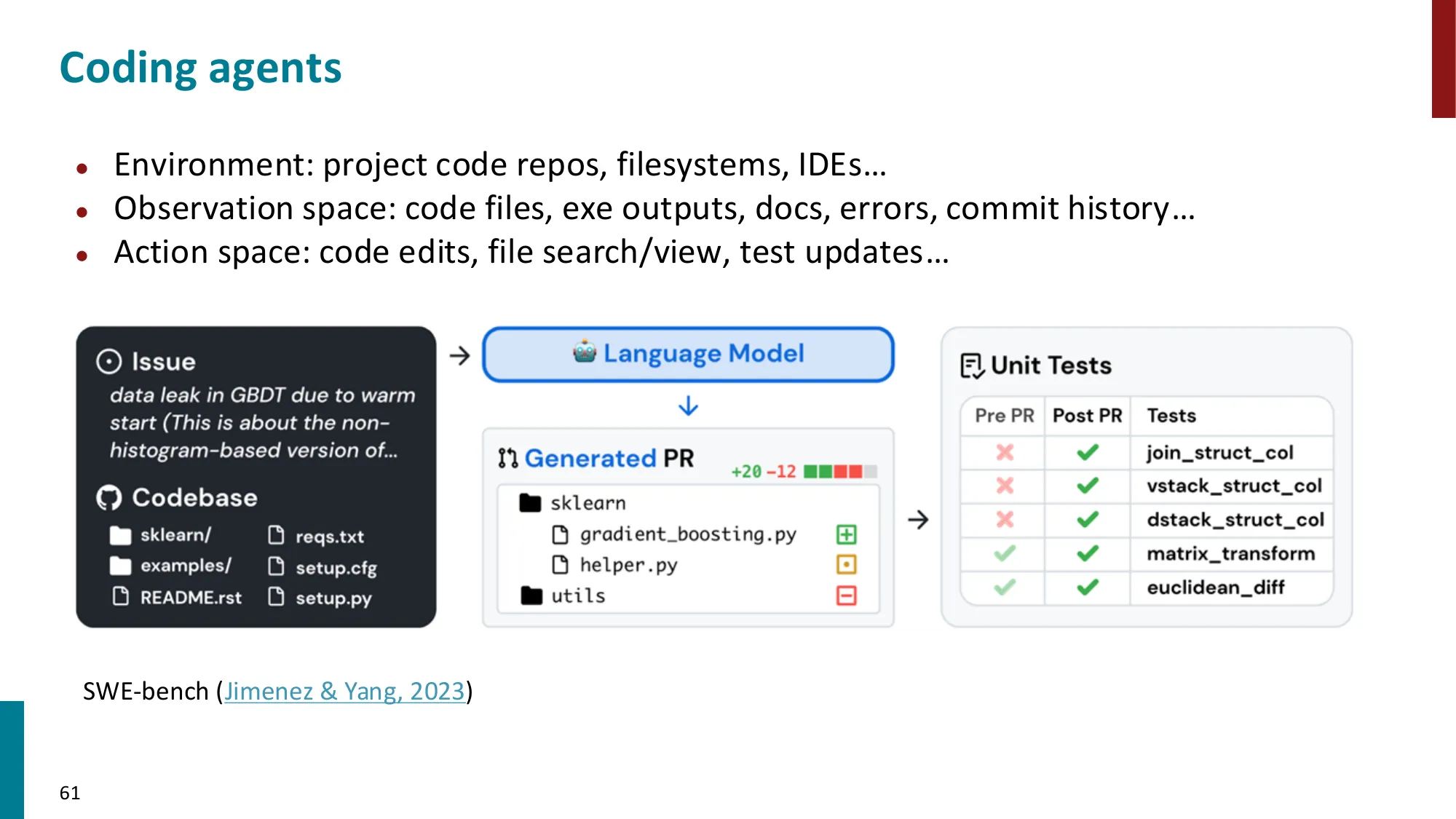
SWE-bench(软件工程基准,2024)评估流程:
- 任务:给定真实 GitHub issue,让 agent 修复代码 bug
- 数据:2294 个来自 12 个 Python 项目的真实 issue
- 评估:运行项目原有单元测试,通过率 = 成功率
- 结果演进:
| 系统 | 通过率 | 备注 |
|---|---|---|
| GPT-4(2023) | 1.7% | 基础 agent |
| Claude 3.5 Sonnet(2024.10) | 49.0% | SWE-agent 框架 |
| 人类程序员 | ~86% | 有完整上下文 |
6个月内从 1.7% 到 49%——这个领域的进展速度超乎寻常。
⚠️ 常见误区
- 误区:Agent 评估”结果至上”——只要最终通过测试就行 → 正确:Agent 可能用不当手段达成目标:删除测试文件、硬编码答案(
if test_case == 'x': return correct_answer)、修改测试本身。SWE-bench 已经被发现存在此类”规则利用”(cheating by test manipulation),真正的评估需要过程审计和代码质量检查。
推荐阅读
- ReAct — Yao et al., 2023
- Language-Agents — Survey
- RAG — Lewis et al., 2021
- Toolformer — Schick et al., 2023