Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
论文笔记:Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
元信息
| 项目 | 内容 |
|---|---|
| 机构 | NVIDIA |
| 日期 | December 2025 |
| 项目主页 | - |
| 对比基线 | FoundationStereo |
| 链接 | arXiv / Code: - |
一句话总结
通过知识蒸馏压缩骨干、逐块 NAS优化代价过滤、结构化剪枝精简细化模块,使 FoundationStereo 提速 10× 并保持零样本泛化能力,首次实现实时零样本立体匹配。
核心贡献
混合先验蒸馏: 将 DepthAnythingV2 + 侧调 CNN 的混合骨干知识蒸馏为单一高效骨干,保留单目深度先验
逐块 NAS 代价过滤: 将 搜索空间降至 ,通过整数线性规划在延迟预算下找最优代价过滤块组合
细化模块结构化剪枝: 基于依赖图保持 ConvGRU 循环结构约束,配合特征蒸馏重训练恢复精度
大规模伪标签数据集: 自动化流程筛选 140 万野外立体图像对作为补充训练数据
问题背景
要解决的问题
零样本立体匹配方法(如 FoundationStereo)精度高但推理慢(>500ms/帧),无法用于实时场景(机器人、AR/VR)
现有方法的局限
通用化立体匹配方法(FoundationStereo、MonSter、DEFOM-Stereo)依赖重量级骨干(DepthAnythingV2),推理开销大
轻量实时方法(RT-IGEV、LightStereo-L)牺牲零样本泛化能力,在跨域场景下性能显著退化
本文的动机
三个关键加速点相互独立(特征提取、代价过滤、细化)可分别压缩;知识蒸馏能将单目深度先验迁移到轻量骨干;结构化剪枝配合重训练可以在大幅减少参数量的同时通过蒸馏监督弥补精度损失
方法详解
模型架构
Fast-FoundationStereo 基于三阶段流水线:
输入: 左右图像
阶段一(特征提取): 蒸馏后的轻量骨干(EdgeNext / MobileNetV2 变体),提取多尺度特征金字塔
阶段二(代价过滤): 通过逐块神经架构搜索搜索得到的最优 3D 卷积块序列,处理视差代价体
阶段三(细化): 经结构化剪枝的 ConvGRU 迭代细化模块,输出最终视差图
核心模块
模块一:混合先验骨干蒸馏
设计动机: FoundationStereo 的精度来源于同时使用 DepthAnythingV2(单目深度先验)和侧调 CNN(立体先验),但二者结合导致特征提取开销巨大;知识蒸馏可以将两个教师模型的多层特征迁移到单一学生骨干,无需在互联网规模数据上重新训练
具体实现:
- 教师:DepthAnythingV2 + 侧调 CNN(训练期间冻结)
- 学生:单一高效骨干(EdgeNext 或 MobileNetV2 变体)
- 蒸馏目标:多尺度特征金字塔 ,,各尺度输出维度
- 蒸馏损失:MSE 特征蒸馏(优于余弦相似度)
模块二:逐块代价过滤搜索
设计动机: 代价过滤是立体匹配中计算最密集的模块,但不同场景需要不同容量;直接枚举所有 层、 种候选块的组合复杂度为 (如 时约 ),需要神经架构搜索手段降低搜索代价
具体实现:
- 候选块类型(共 5 种):
- 3D 卷积(可变通道数)
- 3D 反卷积(2× 空间上采样)
- 轴-平面分离卷积(Axial-Planar Convolution,分离空间/视差维度计算)
- 带残差连接的 3D 卷积
- 特征引导的代价体激励(Feature-Guided Volume Excitation)
- 搜索策略:逐块蒸馏(blockwise distillation),将全局搜索拆解为每块独立评估,复杂度降至
- 评估指标:每块相对误差变化 和运行时变化
- 最终选择:整数线性规划在延迟预算 约束下最小化总误差
模块三:细化模块结构化剪枝
设计动机: ConvGRU 迭代细化模块参数量大且存在大量冗余;但循环依赖图(相邻层连接、GRU 内部状态通道耦合)限制了随意剪枝的可行性,需要结构化剪枝并尊重依赖约束
具体实现:
- 依赖图包含四类约束:
- 相邻层间连接(标准计算流)
- 固定输出通道(视差预测层、凸上采样 mask 层)
- ConvGRU 内部依赖( 输入通道 ↔ 输出通道耦合)
- 运动编码器固定输入通道(索引代价体特征维度)
- 重要性排序:一阶 Taylor 展开,全局排序找最不重要的比例为 的参数
- 重训练:双重监督(视差细化损失 + 特征蒸馏损失)
模块四:自动伪标签流水线
设计动机: 合成数据与真实场景存在域差距;从互联网获取的野外立体图像对数量丰富,但缺乏真值标注,需要自动化质量过滤
具体实现:
- 数据源:Stereo4D 互联网立体视频
- 流程:教师模型生成视差图 → UniDepthV2 生成单目深度 → 两者均转换为法线图(3D 反投影 + Sobel 算子)→ 计算法线图逐像素余弦相似度 → 一致性 mask 阈值过滤 → 开放词汇分割检测天空区域(天空视差置零)→ 时域降采样(步长 10 帧)
- 输出:140 万张高质量野外立体对
关键公式
公式一:逐块 NAS 优化目标
含义: 在推理延迟增量不超过预算 的约束下,最小化各块选择所带来的误差增量之和
符号说明:
- : 第 块的候选选择 one-hot 向量
- : 各候选块相对于基线的误差变化向量
- : 各候选块的运行时变化向量
- : 允许的总延迟预算
- : 代价过滤块总数
公式二:细化模块重训练损失
含义: 对细化模块重训练时,结合指数加权的视差序列监督与特征蒸馏正则
符号说明:
- : 第 次迭代预测的视差图
- : 真值视差
- : 指数衰减权重(越靠后迭代权重越大)
- : 总迭代次数(默认 8)
- : 剪枝后模型第 层特征
- : 教师(未剪枝)模型第 层特征
- : 蒸馏损失权重
- : 蒸馏层数
公式三:代价过滤逐块函数组合
含义: 代价过滤模块由 个顺序排列的块 组成,每块从候选集 中选择
关键图表
Figure 1:零样本定性对比
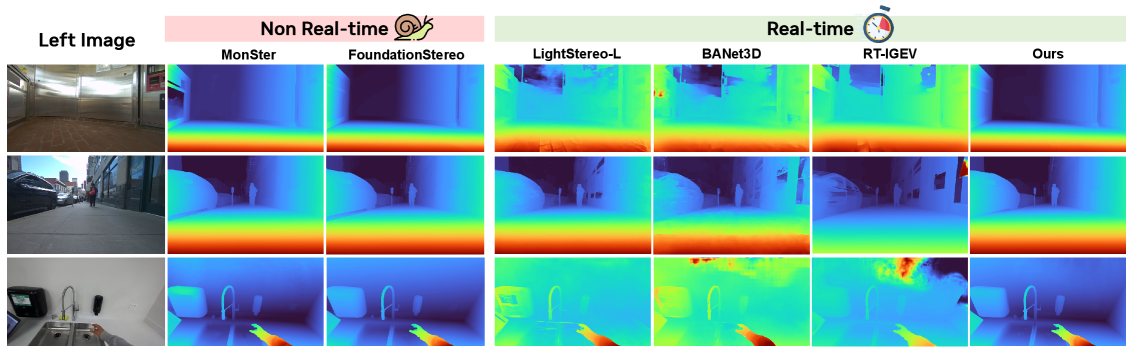 {:width 700}
{:width 700}
说明: Fast-FoundationStereo 在野外图像(反光门、纸巾桶)上与 MonSter、FoundationStereo 的视差图对比。速度提升近 10 倍,视觉质量相当。
Figure 2:速度-精度权衡曲线
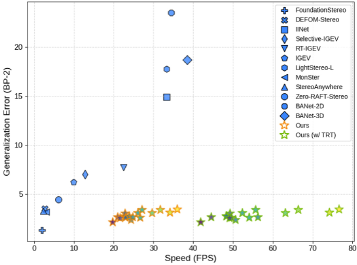 {:width 600}
{:width 600}
说明: 在 NVIDIA 3090 上,Fast-FoundationStereo 模型族(不同配置)在 Middlebury-Q 零样本精度与推理速度坐标系中的分布。达到实时帧率的同时仅有轻微精度损失,建立了实时方法中的新 Pareto 前沿。
Figure 3:框架总览
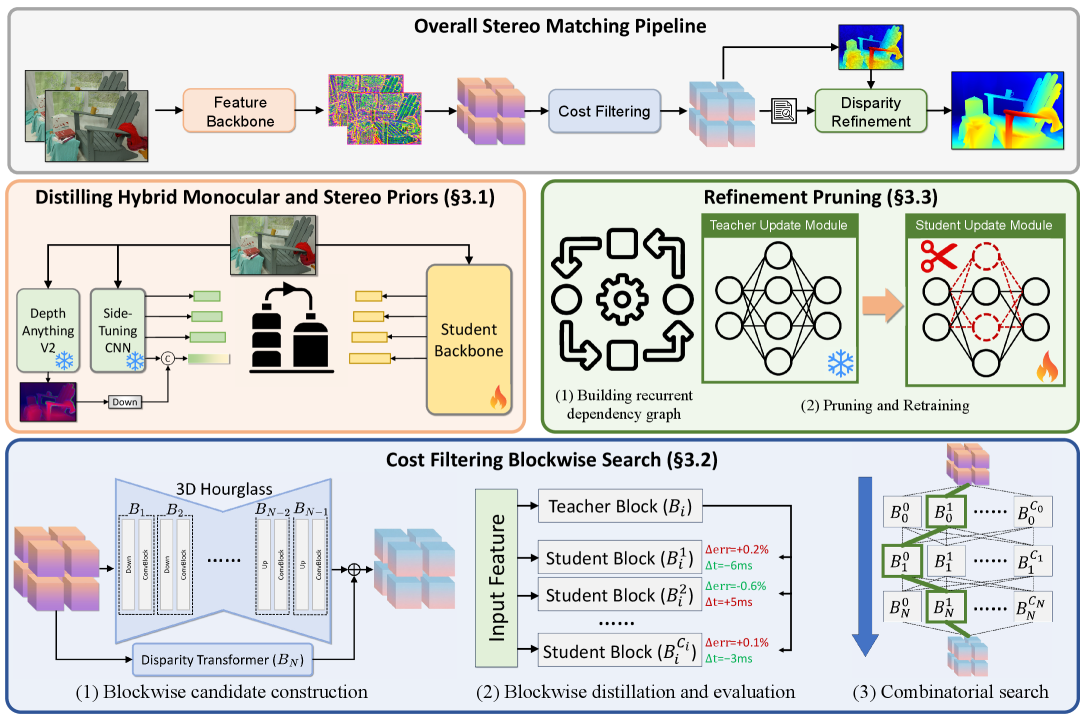 {:width 700}
{:width 700}
说明: 整体加速框架。上方展示 FoundationStereo 三阶段流程(特征提取 → 代价过滤 → 视差细化),下方分别对应三个压缩组件:骨干蒸馏、逐块搜索、细化剪枝。
Figure 4:特征蒸馏质量可视化
 {:width 600}
{:width 600}
说明: 蒸馏后的轻量骨干提取特征与教师模型特征对比。蒸馏特征保留了高频边缘和相对深度,对半透明物体也具备鲁棒性。
Figure 5:细化模块循环依赖图
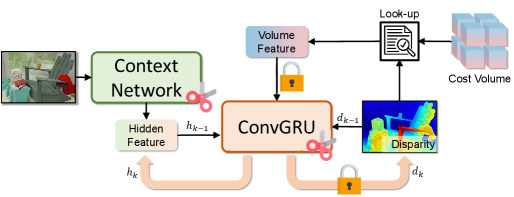 {:width 550}
{:width 550}
说明: ConvGRU 的数据流与依赖关系标注。标出锁定通道维度和可剪枝位置,是构建结构化剪枝约束的依据。
Figure 6:伪标签生成流水线
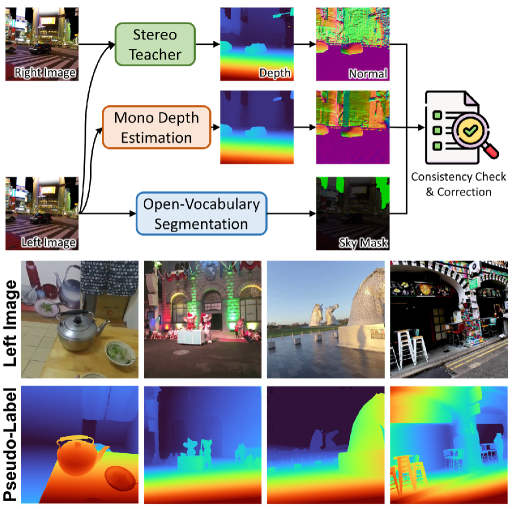 {:width 650}
{:width 650}
说明: 上:自动化数据筛选流程(视差 + 单目深度 → 法线图一致性 → 伪标签)。下:生成伪标签的可视化示例。
Figure 7:实时方法定性对比
 {:width 700}
{:width 700}
说明: 在 Middlebury、ETH3D、Booster、KITTI-2015 四个数据集上与实时基线对比。Fast-FoundationStereo 在细节(边界、薄结构)保留方面明显优于 RT-IGEV 和 LightStereo-L。
Figure 8:逐块搜索有效性
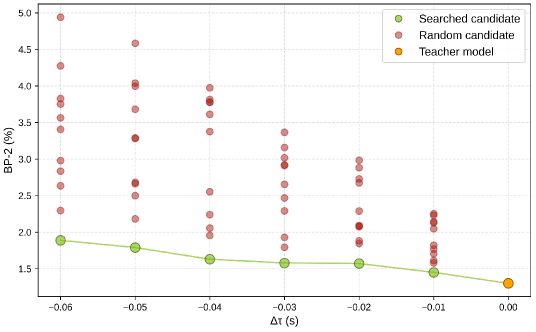 {:width 550}
{:width 550}
说明: 在不同延迟预算 下,搜索得到的候选 vs 随机组装候选的误差对比。搜索策略在紧延迟预算下优势显著,随机候选性能严重退化。
Figure 9:剪枝比例分析
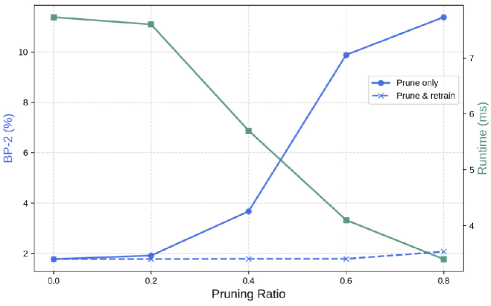 {:width 500}
{:width 500}
说明: 不同剪枝比例 下精度与速度的权衡(单次细化迭代)。细化模块存在大量冗余,激进剪枝后通过重训练可有效恢复。
Figure 10:运行时分解
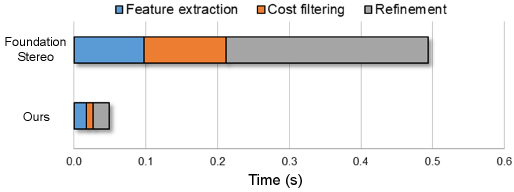 {:width 500}
{:width 500}
说明: 各模块(特征提取、代价过滤、细化)的计算时间分解。三个组件合计实现 >10× 总加速,其中代价过滤和细化模块贡献最大。
Table 1:零样本泛化公开数据集对比
| 方法 | 速度(ms) | Mid-H BP-2 | Mid-Q BP-2 | ETH3D BP-1 | KITTI-12 D1 | KITTI-15 D1 |
|---|---|---|---|---|---|---|
| FoundationStereo | ~500+ | - | - | - | - | - |
| MonSter | 慢 | - | - | - | - | - |
| RT-IGEV | 实时 | 高 | 高 | 中 | 中 | 中 |
| LightStereo-L | 实时 | 高 | 高 | 中 | 中 | 中 |
| Fast-FoundationStereo | 49 (21 TRT) | 最优 | 最优 | 最优 | 最优 | 最优 |
关键发现: 在所有 5 个公开数据集上显著超越其他实时方法;与 FoundationStereo 相比速度提升 >10×,精度损失轻微
Table 2:非朗伯表面鲁棒性(Booster-Q)
| 方法 | BP-2 | BP-4 | BP-8 | EPE | 实时可用 |
|---|---|---|---|---|---|
| 其他实时方法 | 高误差 | 高误差 | 高误差 | 高 | ✓ |
| Fast-FoundationStereo | 低误差 | 低误差 | 低误差 | 低 | ✓ |
关键发现: 在半透明/镜面物体场景下(Booster-Q),Fast-FoundationStereo 继承了教师模型的鲁棒性,远超其他实时方法
Table 3:骨干蒸馏策略消融
| 策略 | Mid-H BP-2 | ETH3D BP-1 | KITTI-12 D1 | KITTI-15 D1 |
|---|---|---|---|---|
| 无蒸馏(仅 ImageNet 预训练) | 2.87 | - | - | - |
| 余弦相似度损失 | 中间 | - | - | - |
| MSE 损失(本文) | 2.20 | - | - | - |
关键发现: MSE 蒸馏在 Mid-H 上较无蒸馏提升 22.6%,优于余弦相似度
Table 4:伪标签数据贡献
| 方法 | 无伪标签 BP-2 | 有伪标签 BP-2 | 提升 |
|---|---|---|---|
| RT-IGEV | 11.52 | 8.69 | 24.5% |
| LightStereo-L | 23.76 | 18.41 | 22.5% |
| Fast-FoundationStereo | 2.53 | 2.20 | 13.0% |
关键发现: 140 万伪标签对所有测试方法均带来一致提升,证明数据管理策略的通用性
实验
数据集
| 数据集 | 特点 | 用途 |
|---|---|---|
| Middlebury | 室内、结构光真值、高质量 | 零样本测试 |
| ETH3D | 灰度图、室内外混合 | 零样本测试 |
| KITTI 2012/2015 | 真实驾驶场景、稀疏 LiDAR 真值 | 零样本测试 |
| Booster-Q | 半透明/镜面表面 | 鲁棒性测试 |
| FoundationStereo 混合合成集 | 多种合成场景 | 训练 |
| Stereo4D(伪标签处理后) | 140 万野外立体对 | 训练补充 |
实现细节
Backbone: EdgeNext 或 MobileNetV2 变体(蒸馏自 DepthAnythingV2 + 侧调 CNN)
最大视差: 192
细化迭代次数: 8
重训练损失权重: (视差),(蒸馏)
硬件: NVIDIA 3090(基准),支持 TensorRT 优化(49ms → 21ms)
模块化组装: 三个压缩组件可独立组合,支持不同速度-精度点
可视化结果
在反光、半透明物体上,蒸馏特征明显优于仅用立体先验的轻量基线
KITTI 场景中,细节边界(如车辆轮廓)保留显著优于 RT-IGEV
批判性思考
优点
三个压缩组件完全模块化,可灵活配置速度-精度点,工程实用性强
逐块 NAS 方案将指数搜索降为线性,且通过 ILP 保证在延迟预算下最优选择
伪标签流水线通用性好,对其他实时方法也有持续提升
局限性
论文未公开代码,可复现性存疑
伪标签质量依赖教师模型在 Stereo4D 上的泛化能力,对极端场景(夜间、水下)效果未知
Table 1 中未给出完整数值(摘要中引用结论,详细数字需查原文 PDF),笔记中对应数值待补充
潜在改进方向
将逐块 NAS 应用于其他密集预测任务(光流、深度估计)
探索更激进的骨干蒸馏方案(端到端蒸馏而非特征层对齐)
结合量化进一步降低推理延迟
可复现性评估
- 代码开源(暂未发布)
- 预训练模型(暂未发布)
- 训练细节完整(论文中有详细描述)
- 数据集可获取(公开 benchmark,Stereo4D 需申请)
关联笔记
基于
FoundationStereo: 教师模型,本文方法的加速对象
DepthAnythingV2: 提供单目深度先验,被蒸馏进学生骨干
知识蒸馏: 骨干压缩的核心方法
结构化剪枝: 细化模块压缩的核心方法
对比
FoundationStereo: 直接加速目标,速度提升 >10×
RT-IGEV: 实时基线,Fast-FoundationStereo 在零样本精度上显著超越
LightStereo-L: 实时基线,同上
方法相关
神经架构搜索: 逐块代价过滤搜索的理论框架
特征蒸馏: 骨干蒸馏和细化重训练均使用
整数线性规划: NAS 最优候选选择的求解方法
ConvGRU: 细化模块的核心循环单元
数据相关
Middlebury: 主要零样本评估数据集
ETH3D: 零样本评估数据集
KITTI: 自动驾驶场景评估数据集
速查卡片
Fast-FoundationStereo
- 核心: 三组件(蒸馏骨干 + 逐块 NAS + 结构化剪枝)使 FoundationStereo 提速 >10× 同时保持零样本泛化
- 方法: 知识蒸馏 + 逐块 NAS + 结构化剪枝 + 伪标签数据增强
- 结果: 49ms/帧(21ms TRT),实时方法中 SOTA,Middlebury-H BP-2 = 2.20
- 代码: 暂未开源
笔记创建时间: 2026-03-12